
Abstract
Domain adaptation (DA) aims to train a robust predictor by transferring rich knowledge from a well-labeled source domain to annotate a newly coming target domain; however, the two domains are usually drawn from very different distributions. Most current methods either learn the common features by matching inter-domain feature distributions and training the classifier separately or align inter-domain label distributions to directly obtain an adaptive classifier based on the original features despite feature distortion. Moreover, intra-domain information may be greatly degraded during the DA process; i.e., the source data samples from different classes might grow closer. To this end, this paper proposes a novel DA approach, referred to as inter-class distribution alienation and inter-domain distribution alignment based on manifold embedding (IDAME). Specifically, IDAME commits to adapting the classifier on the Grassmann manifold by using structural risk minimization, where inter-domain feature distributions are aligned to mitigate feature distortion, and the target pseudo labels are exploited using the distances on the Grassmann manifold. During the classifier adaptation process, we simultaneously consider the inter-class distribution alienation, the inter-domain distribution alignment, and the manifold consistency. Extensive experiments validate that IDAME can outperform several comparative state-of-the-art methods on real-world cross-domain image datasets.
Introduction
Traditional machine learning algorithms, which have achieved remarkable results, usually assume that the distributions of the training and testing datasets are similar or even identical. However, this assumption is often invalid in real-world applications; thus, we have to relabel large amounts of data instances that follow the same distribution as the testing dataset to guarantee the model’s performance, which is very labor-intensive and time-consuming [25, 34]. To deal with this challenge, domain adaptation (DA) has been proposed by leveraging the rich source labeled data instances (training dataset) to learn a robust classifier for a newly coming and totally unlabeled target domain (testing dataset) from a very divergent distribution [27]. The key to achieving DA is to reduce the distribution divergence between the target and source domains; thus, the knowledge of the domains can be expectantly shared, and label consumption for the target domain is largely mitigated.
Concerning visual recognition technology for autonomous vehicles, it is impractical to collect all the possible visual images in the real-world, as this would be expensive, and potentially dangerous. An alternative and feasible strategy is to simulate the real-world images as sufficiently as possible to save time and labor. Then, we utilize these simulated visual images to train the model to assist the autonomous vehicles in their object recognition systems. However, there is still a very large gap between the real-world and simulated visual images, so the performance of the recognition systems is poor. To this end, a classification model trained on the simulated visual images needs to be adapted to help make predictions for the real-world visual images. In such cases, DA is an effective technique that can compensate for this challenge and narrow the gap between the real-world and simulated visual images by aligning their distributions.
In the past several years, researchers have developed various DA approaches to reduce the cross-domain distribution difference. In summary, there are three main types: (a) re-weighting the source data instances according to some weighting techniques so that the effect of the “bad” instances is reduced while the contribution of the “good” instances is enhanced [8, 14, 17, 28, 29, 32]; (b) conducting feature adaptation by minimizing a predefined distribution distance that ably characterizes the cross-domain discrepancy [2, 18, 21, 24, 26]; and (c) directly designing an adaptive classifier by minimizing inter-domain label distribution difference [3, 10, 20, 30].
The approaches of re-weighting the source data instances are effective only when the cross-domain distribution difference is small, while the distributions of different domains differ greatly due to their feature or label distribution misalignment in many real-world scenarios [22]. Recently, many approaches [1, 5, 12, 15, 19, 30] have been devised to address this challenge by elaborately aligning the feature distributions, or directly designing an adaptive classifier by considerably reducing the label distribution discrepancy. However, there still exist several challenges that are not solved satisfactorily. First, feature adaptation can only reduce, rather than remove, feature distribution discrepancy. Second, directly designing an adaptive classifier based on the original features can match their label distributions but ignores their feature distortion [16]. Third, intra-domain information might be lost as the inter-domain distribution difference is reduced. For instance, the source data samples from different classes are probably closer than before, which might degrade the classifier behavior and influence the final DA performance.
To address these challenges, we propose a novel approach involving inter-class distribution alienation and inter-domain distribution alignment based on manifold embedding (IDAME) for domain adaptation. Specifically, IDAME commits to adapting the classifier on the Grassmann manifold by using structural risk minimization, which can not only reduce the inter-domain feature/label distribution divergence but also preserve the label distribution difference among source data instances that are from different classes. IDAME can be divided into two stages to achieve DA. In the first stage, the specific features can be learned on the Grassmann manifold to align feature distributions of different domains to avoid feature distortion in the original space, and the target pseudo labels are exploited using the distances on the Grassmann manifold. In the second stage, with the manifold aligned features, an adaptive classifier based on structural risk minimization is modeled, where the inter-domain label distribution alignment and the manifold consistency are regarded as the regularization terms of the classifier. This paper proposes inter-class label distribution discrepancy preservation in the source domain, and we consider this preservation as another regularization term to mitigate the degradation of classification performance since the source data samples from different classes are probably closer than before. In summary, the contributions of this paper are as follows. We aim to adapt the classifier on the Grassmann manifold by using structural risk minimization, where inter-domain feature distributions are aligned to alleviate the original feature distortion and where the target pseudo labels are exploited using the distances on the Grassmann manifold. During the classifier adaptation process, we reduce the inter-domain label distribution difference and preserve the intra-domain label distribution discrepancy to further achieve domain adaptation and prevent intra-domain information degradation. Extensive experiments validate that IDAME can outperform several comparative state-of-the-art methods on real-world cross-domain image datasets.
Related works
This section discusses the current DA approaches on feature adaptation and classifier adaptation that are most related to our work.
In most feature adaptation methods, a latent shared feature space is extracted and discovered to statistically reduce the feature distribution difference between the source and target domains. Pan et al. [26] proposed transfer component analysis (TCA) to minimize the inter-domain feature distribution difference measured by the maximum mean discrepancy (MMD). Long et al. [18] presented joint distribution analysis (JDA) to improve TCA by jointly minimizing the marginal and conditional feature distribution distances between the two different domains using target pseudo labels predicted by some base classifiers. In addition, transfer joint matching (TJM) was developed to explore not only feature matching but also instance re-weighting [19]. Other methods exploited common features of the source and target domains by searching for their intermediate subspaces to geometrically reduce the feature distribution shift. Gopalan et al. [23] used intermediary projections of the two domains along the shortest geodesic path and therefore connected them on the Grassmann manifold. Additionally, Gong et al. [2] presented geodesic flow kernel (GFK) based on the Grassmann manifold, to learn the domain-invariant features by integrating infinite subspaces lying on the geodesic flow. Zhang et al. [12] further explored joint geometrical and statistical alignment (JGSA) to match the feature distributions. Generally speaking, in statistical and geometrical strategies, these methods reduce the feature distribution divergence between the two different domains, but they still cannot remove this divergence. Unlike these methods, this paper not only conducts feature adaptation to mitigate feature distortion but also further adapts the classifier by effectively aligning the label distributions.
Some models were recently developed to devise an adaptive classifier directly based on the original features. Yang et al. [33] proposed the extreme learning machine based domain adaptation (EDA) method, which established manifold regularization to leverage an adaptive classifier. Long et al. [20] utilized adaptation regularization based transfer learning (ARTL) to learn an adaptive classifier based on structural risk minimization with inter-domain label distribution alignment. Cao et al. [30] developed distribution matching machine (DMM) to exploit a domain-transfer support vector machine by using distribution matching and data instance weighting regularization. To mitigate the influence of feature distortion in the original data space, Wang et al. [11] constructed manifold embedded distribution alignment (MEDA), which aligns the inter-domain feature distributions and then leverages an adaptive classifier in this feature space. However, the intra-domain information might be lost during the DA process, i.e., the source data samples from different classes probably become closer than before. To address this problem, we propose inter-class distribution alienation to preserve the source label distribution discrepancy during the classifier adaptation process.
The proposed IDAME approach is derived from ARTL and MEDA, but is distinctly different from them. First, IDAME obtains the initial target pseudo labels by using the distances on the Grassmann manifold so that the geometrical properties can be desirably passed down in the subsequent iteration process. In addition, IDAME preserves the source label distribution discrepancy in case the final classification performance is degraded during the process of inter-domain label distribution alignment.
Proposed approach
In this section, some notations and the problem statement are introduced. Then, we revisit several essential formulas related to our approach. Finally, the proposed IDAME approach is presented in detail.
Notations and the problem statement
For clarity, notations frequently used in this paper are shown in Table 1.
Notations and their descriptions
Notations and their descriptions
For convenience, we first revisit the technical core of relevant methods as follows.
According to [2], the geodesic distance between any two data samples on the Grassmann manifold can be computed by Equation (1), which can be utilized to label data samples that comply with the distance similarity. In addition, utilizing the geodesic distance, manifold features can be obtained to achieve feature distribution alignment. Specifically, as mentioned in [11], the manifold features can be learned with
where
To address the shortcomings of both the feature and classifier adaptation DA methods, we propose a two-stage IDAME approach.
In the first stage, IDAME finds the manifold features on the Grassmann manifold by using the GFK approach to mitigate the influence of feature distortion based on the original features. Specifically, as mentioned before, the manifold features can be learned with
In the second stage, an adaptive classifier f can be modeled in the manifold feature space by minimizing the structural risk function (Equation (3)) with Laplacian regularization, which can preserve the geometrical property of the data manifold (Equation (5)). To further achieve domain adaptation and prevent intra-domain information degradation during the DA process, we reduce the inter-domain label distribution discrepancy by using Equation (4) and preserve the intra-domain label distribution difference by using inter-class distribution alienation (Equation (6)). Next, we describe the inter-class distribution alienation.
Therefore, in the second stage, IDAME utilizes the manifold features to learn an adaptive classifier, which can be formulated as follows
Then we incorporate Equation (8) into Equation (3) using the manifold features to obtain
where
and
Finally, we substitute Equations (9), (10), (12) and (14) for each quantity into (7) to obtain
Let ∂f/ ∂α =
Note that
By substituting α into Equation (8), we obtain the adaptive classifier f. In summary, IDAME is presented in Algorithm 1.
This section conducts comprehensive experiments on real-world object and handwritten digit recognition datasets to compare the proposed IDAME approach with several state-of-the-art methods and evaluate the performance of our approach.
Dataset descriptions
We use the benchmark datasets, i.e., Office 10 + Caltech 10 [2,7, 2,7] (Amazon, DSLR, Webcam, Caltech) and USPS+MNIST [18] (USPS, MNIST) which are widely utilized to demonstrate the effectiveness of domain adaptation (DA) algorithms. Descriptions of these datasets are presented in Table 2.
Dataset descriptions
Dataset descriptions
We compare our approach with 8 baseline methods: 1-nearest neighbor (1-NN) [13], TCA [26], GFK [2], JDA [18], ARTL [20], MEDA [11], JGSA [12], and TJM [19].
Since the target data instances are totally unlabeled, we estimate the optimal parameters by using the empirical searching strategy instead of cross validation. In the comparative study, we also utilize this strategy to evaluate the baseline methods, and their best results are reported accordingly. Specifically, the parameters in this paper are set as T = 10, p = 10, λ = 10, σ = 0 . 1, and d = 20. In addition, the manifold regularization parameter is set as γ = 0 . 1, 1, and 8 for the Office 10 + Caltech 10 (SURF features), Office 10 + Caltech 10 (Decaf6 features) and USPS+MNIST datasets, respectively. For the kernel function, the radial basis function (RBF) kernel is adopted in the structural risk minimization loss, and the trade-off parameter is set as β = 0.1.
We adopt the evaluation metric classification accuracy, which is widely utilized in the literature [2, 26], to evaluate the effectiveness of our approach compared with the aforementioned methods. Specifically, the classification accuracy is formulated as follows
where f (
Experimental results
The reported results of IDAME and other comparative methods are shown in Tables 3, 4 and 5. As shown, the overall average classification accuracy of IDAME is higher than that of all baseline methods. The 1NN method trains the classifier on the source domain to directly predict the target labels based on their original features without the DA process. Therefore, 1NN performs worst on all DA tasks, thereby indicating that the DA technique is essential to the cross-domain problem. TCA and GFK align the marginal feature distributions statistically and geometrically, respectively; thus, they behave better than the non-DA method 1NN. Based on TCA, JDA and TJM consider the conditional feature distribution alignment and source instance re-weighting strategy, respectively, so that their corresponding accuracies are notably high. JGSA aims to match the feature distributions statistically and geometrically, thereby further boosting DA performance. However, all 5 DA methods pertain to feature adaptation strategies, and recent studies state that this kind of strategy can only reduce, rather than remove, the inter-domain distribution difference. Therefore, ARTL is proposed to leverage an adaptive classifier by minimizing their label distribution discrepancy, while the feature distribution shift is ignored, which easily causes the feature distortion problem. As such, ARTL does not outperform JGSA on all DA tasks. Unlike these methods, the proposed IDAME aligns the inter-domain feature distribution while the adaptive classifier is exploited. Therefore, IDAME outperforms these 6 methods on most DA tasks (20/26 tasks).
Accuracy (%) on Office 10 + Caltech 10 (SURF features)
Accuracy (%) on Office 10 + Caltech 10 (SURF features)
Accuracy (%) on USPS+MNIST
Accuracy (%) on Office 10 + Caltech 10 (Decaf6 features)
Compared to the best baseline method (MEDA, which also incorporates feature adaptation into adaptive classifier learning), we obtain the initial target pseudo labels computed by the distances on the Grassmann manifold. Moreover, we propose the regularization of inter-class distribution alienation to preserve the label distribution discrepancy of the source domain so that the negative impact on classifier learning is largely mitigated. Therefore, the accuracy results of IDAME are still higher than those of MEDA on most DA tasks. In particular, the average accuracy of our approach on the Office 10 + Caltech 10 dataset with SURF feature has 1.5% improvement compared with the MEDA results, thus indicating that the proposed IDAME can be regarded as an extension of MEDA.
To verify the rigor of our approach, we first inspect the trends of inter-class label distribution distance on different DA tasks. As shown in Fig. 1, the original inter-class label distribution distances (yellow bars) without DA are the maximum among the 3 methods. As discussed before, the inter-class label distribution distances are smaller during the DA process, thus indicating a large decline in the inter-class label distribution distances (blue bars) under MEDA; this decline accords with our motivation. To this end, this paper proposes to maximize the inter-class label distribution distance to respect the intra-domain label distribution discrepancy. Therefore, the decline in the inter-class label distribution distances is smaller under our IDAME than under MEDA, thus verifying the effectiveness and rigor of our approach.
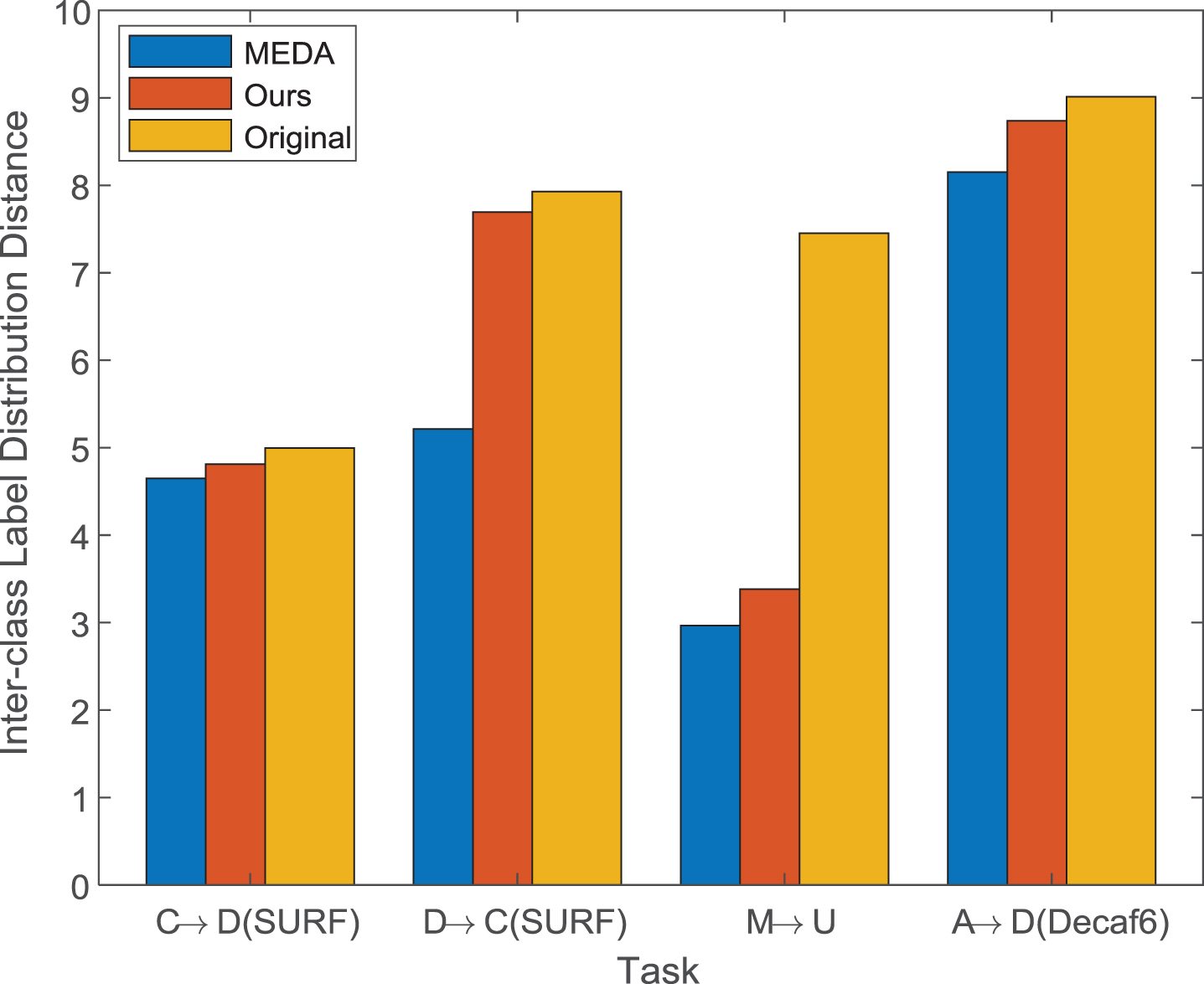
Inter-class label distribution distance of Ours, MEDA and Original.
We also conduct an ablation study with respect to the strategy to initialize pseudo target labels, which are computed by the distances on the Grassmann manifold (Our-I), or the regularization term of inter-class distribution alienation (Our-II). Due to space limitations, we run MEDA, Our-I and Our-II on only several selected DA tasks. As shown in Fig. 2, both Our-I and Our-II can outperform MEDA. Specifically, Our-II outperforms MEDA by 0.8% on average, which verifies that the regularization term of inter-class distribution alienation is important to preserve the intra-domain label distribution discrepancy. Moreover, the average classification accuracy of Our-I has a 1.7% improvement compared with MEDA. Therefore, the initial target pseudo labels obtained on the Grassmann manifold are effective for adaptive classifier learning.
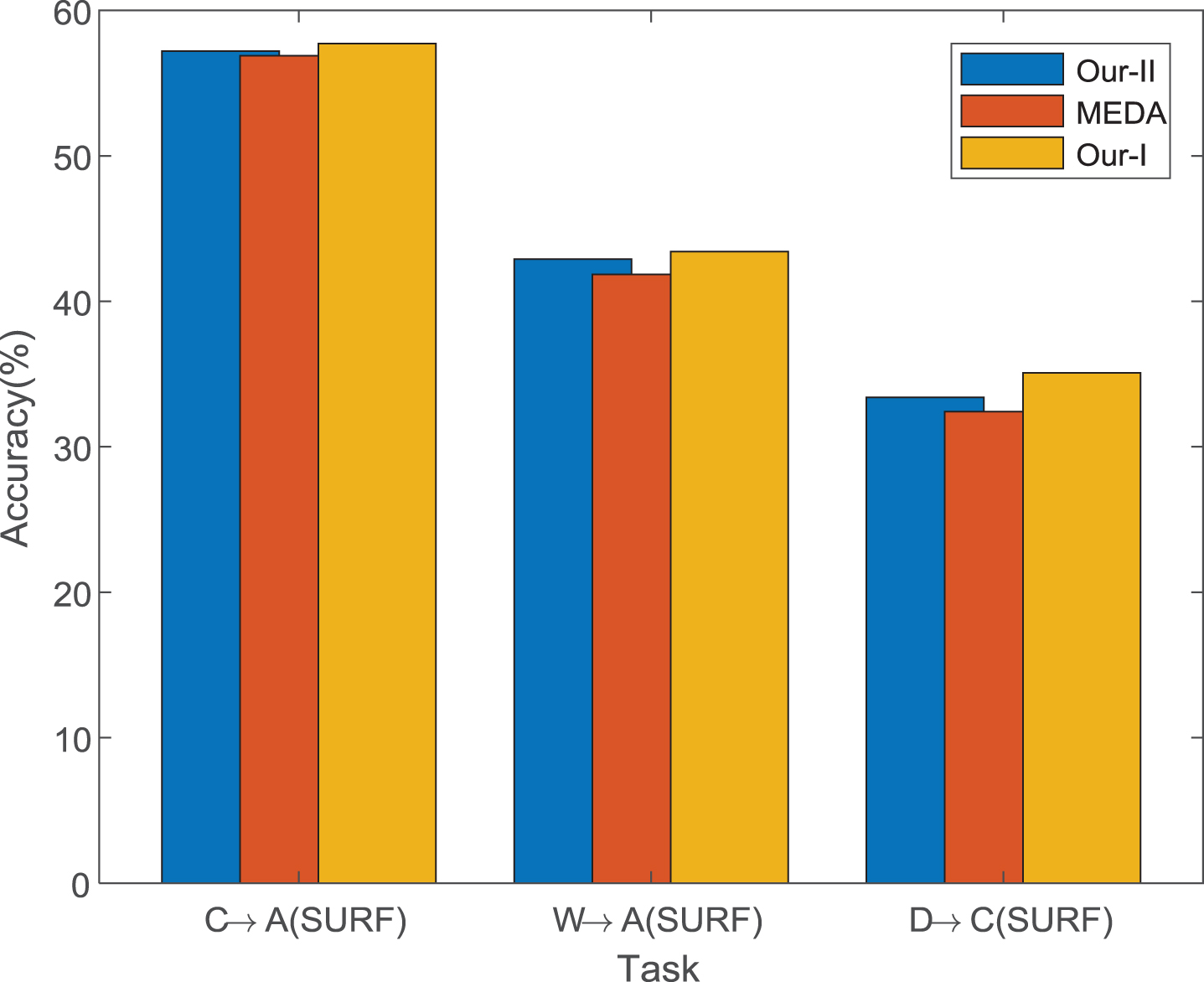
Classification accuracy of MEDA and two variants of Ours (i.e., Our-I and Our-II).
Because we have verified that DA performs better in all DA tasks when we set p = 10, λ = 10, σ = 0 . 1, and d = 20, we discuss the parameter sensitivity of IDAME only with respect to γ, β and T. The results on the tasks of D⟶A (SURF), U⟶M and D⟶C (Decaf6) are reported, while similar trends on all other DA tasks are not shown due to space limitations.
Here, γ is the manifold regularization parameter. The classification accuracy of IDAME with different values of γ from 0 to 10 is shown in Fig. 3(a), which indicates that γ has a wide range to obtain the optimal results. Moreover, the accuracy of IDAME with γ = 0 is still the highest for the object dataset, thus indicating that manifold consistency is insignificant for the object dataset in our IDAME.
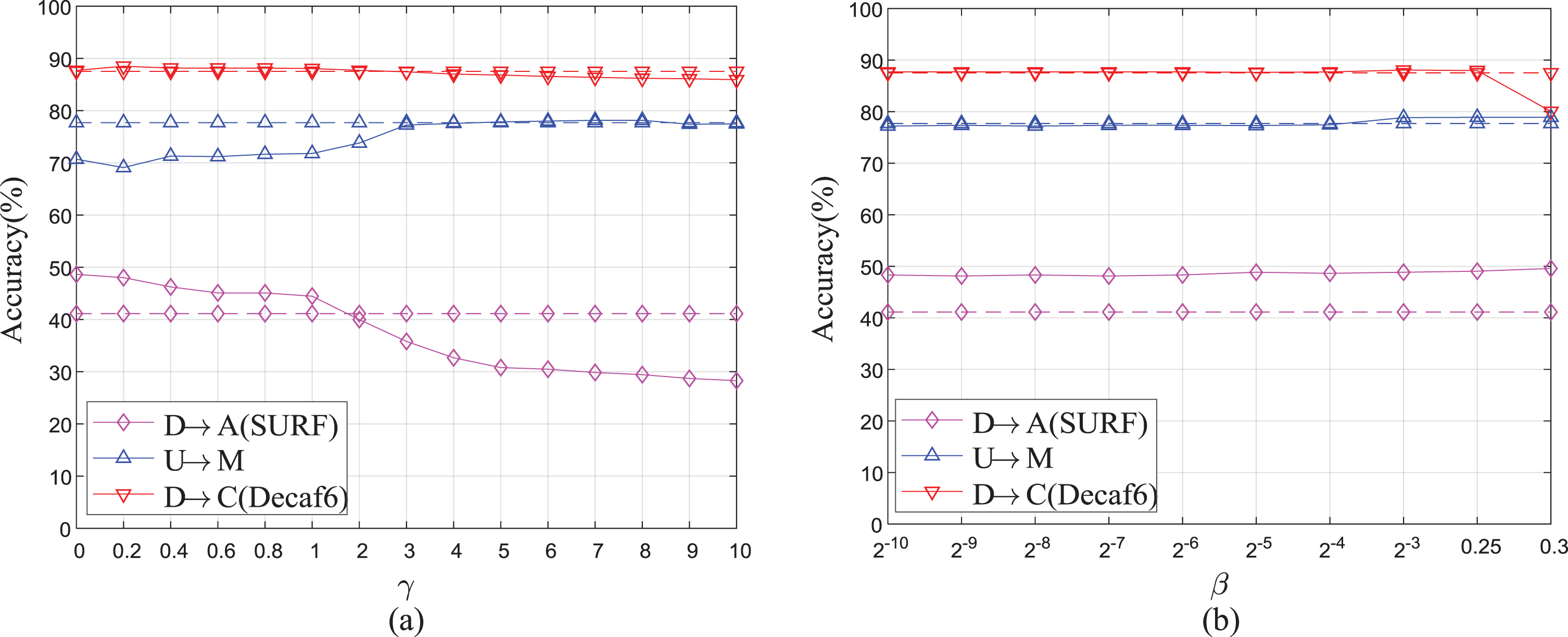
Parameter sensitivity of IDAME (dashed lines are the best baseline results): (a) Manifold regularization γ. (b) Inter-class distribution alienation regularization β.
In addition, β is the trade-off parameter to regularize the importance of inter-domain distribution alignment and inter-class distribution alienation. Larger values of β enable inter-class distribution alienation regularization to be more significant. The accuracy of IDAME with different values of β from 2-10 to 0.3 is illustrated in Fig. 3(b), thus indicating that IDAME is robust over a wide range of β (β ∈ [2-10, 0 . 25]).
Finally, in Fig. 4, we plot the convergence curves of the classification accuracy of our approach with different iterations from 1 to 20; the figure indicates that IDAME converges in only a few iterations (T < 10).
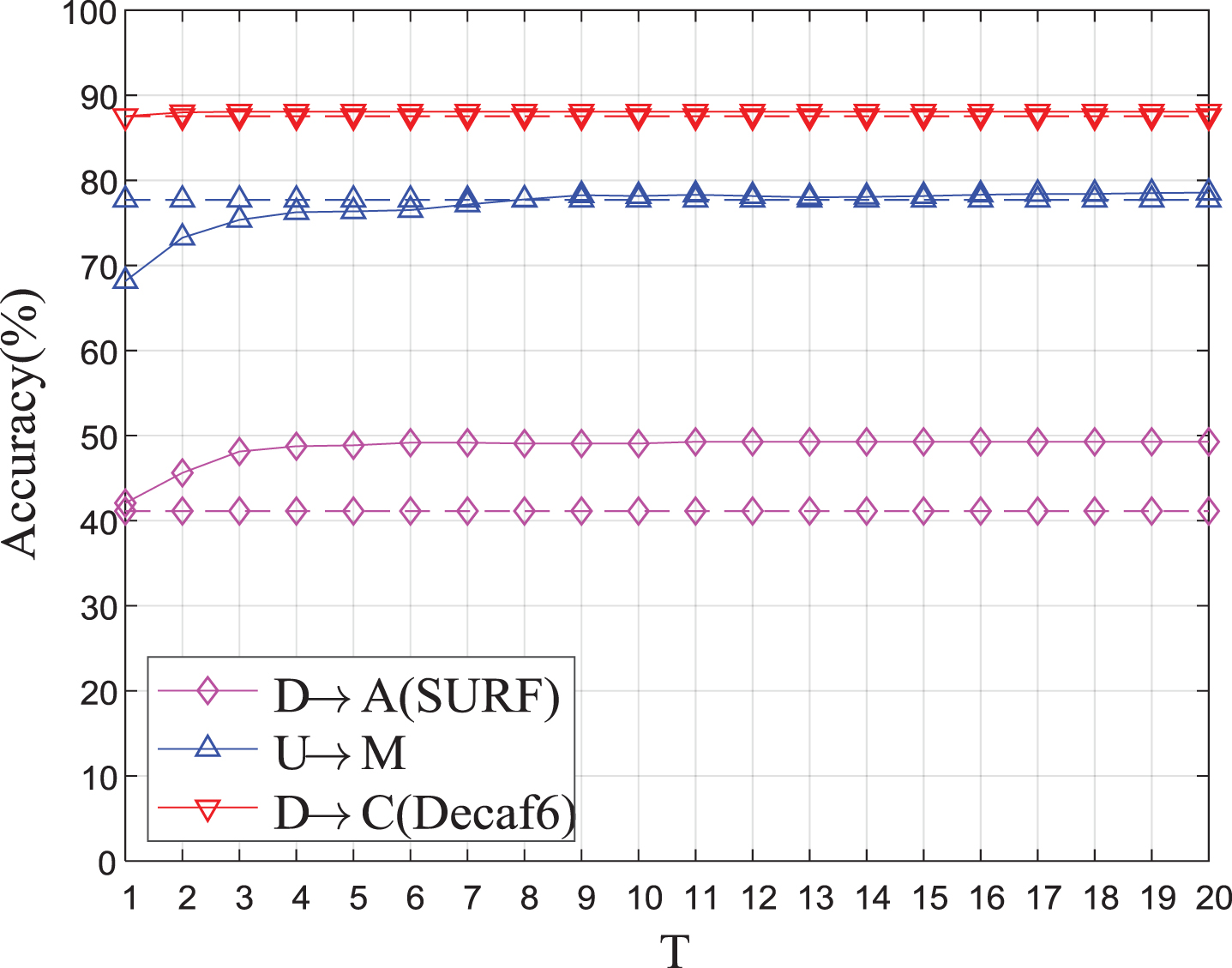
Empirical convergence analysis.
In this paper, we propose a novel domain adaptation approach referred to as inter-class distribution alienation and inter-domain distribution alignment based on manifold embedding (IDAME). IDAME exploits an adaptive classifier on the Grassmann manifold based on structural risk minimization, where the inter-domain feature distributions are matched and where the initial target pseudo labels are computed by the distances on the Grassmann manifold. Additionally, not only are the inter-domain label distributions aligned, but also the label distribution discrepancy of the source domain is favorably preserved. We conduct comprehensive experiments on different types of image recognition datasets, and the results demonstrate that IDAME outperforms several comparative state-of-the-art methods. However, the proposed approach still performs the feature and label distributions alignment in a separate strategy, which might limit their mutual promotion to some extent. Moreover, IDAME cannot deal with negative transfer incurred by irrelevant source data instances. In future work, we will focus on devising a more general domain adaptation (DA) model to compensate for these challenges.
Funding
Program for Outstanding Young Teachers in Higher Education Institutions of Anhui Province, China (No. gxyq2020103).
Footnotes
Acknowledgments
The work was supported in part by the National Nature Science Foundation of China (Nos. 91546108, 71901001, 61806068), the Major Special Science and Technology Project of Anhui Province, China (No. 201903a05020020), the Natural Science Foundation of Anhui Province, China (No. 1708085MG169, 2008085QA16), and the Social Science Research Project of the Education Department of Anhui Province, China (No. JS2017AJRW0135).