
Abstract
Dysarthria is a speech disorder caused by stroke, Parkinson’s disease, neurological injury, or tumors that damage the nervous system and weaken the speech quality. Developing a unique voice command system for Dysarthric speech helps to recognize impaired speech and convert them into text or input commands. Hidden Markov Model (HMM) is one of the widely used generative model-based classifiers for Dysarthric speech recognition. But due to insufficient training data, HMM doesn’t provide optimal results on overlapping classes. We propose an ensemble Gaussian mixture model to recognize impaired speech more accurately. Our model converts the sequence of feature vectors into a fixed dimensional representation of patterns with varying lengths. The performance efficiency of the proposed model is evaluated on the Dysarthric UA-speech benchmark dataset. The discriminatory information provided by the proposed approach yields better classification accuracy even for shallow intelligibility words compared to conventional HMM.
Introduction
Speech requires timely and synchronized contraction of many muscle groups. For the speech process, these muscle groups use the laryngeal function, respiration, articulation, and airflow direction. Many medical factors affect this synchronized work in the human body. Identifying the therapeutic factors which cause speech disorder can help the diagnosis of the disorder also will help in better treatment. Neurologic impairments cause most of the speech disorders in the human body. It is categorized into apraxia, stuttering, and Dysarthria [1].
Dysarthria: A speech disorder
Dysarthria is a motor speech disorder that is caused by neuromuscular control. Damage of the peripheral nervous system or central nervous system is also a cause of Speech impairments, which may lead to “weakness, slowing, in-coordination, altered muscle tone and inaccuracy of oral and vocal movements”. Based on the implication of part of the nervous system, Dysarthria is categorized into Flaccid Dysarthria, Spastic Dysarthria, Hypokinetic Dysarthria, Hyperkinetic Dysarthria, Ataxic Dysarthria, and Mixed Dysarthria.
Dysarthria severely affects the quality of life of a concerned person, and he may also suffer from various psychosocial effects, including perceived stigmatization and emotional disruptions [2].
Causes of dysarthria
Dysarthria is a neuromotor speech disorder caused due to traumatic brain injury like a stroke. It is also caused because of following diseases [3]: Parkinson’s Alzheimer’s Multiple sclerosis Amyotrophic lateral sclerosis
Dysarthria is classified based on the speech intelligibility and articulation, each of which has different expressed speech characteristics; For example, mild, moderate, and severe classifications were used.
Voice command system for Dysarthria
Automatic Speech Recognition (ASR) systems or voice-command systems are the computer programs that recognize Dysarthric speech. Generally, they are the cognitive computing intelligent systems which are speaker-dependent. Cognitive computing is a branch of computer science focusing on technology platforms like speech recognition systems with the use of artificial intelligence, machine learning, and signal processing [4, 5]. The following are the steps involved in the process of a voice-command or speech-recognition system development: Step 1: Feature extraction from the user speech: Drawing out the linguistic matter and other acoustic variations from the speech signal. Step 2: Train and develop reference models: The extracted features are used to train and build reference models for each voice-command. Step 3: Voice-command prediction: The features derived from the speech are presented to all the reference models developed in step 2. The corresponding sound unit of the model with the maximum confidence measure is returned as a prediction.
Challenges in Dysarthric speech-recognition
Many trivial changes in speech can influence the accuracy of the speech recognition system. The Dysarthric speech is not consistent, and the reasons are as discussed in sub-section 1.1. The inconsistency in the Dysarthric speech is a significant preclusion for its recognition. In Dysarthric speech, there will be more than one pronunciation for a single phone, and some of the pronunciations are the same for different phones. A machine learning-based speech recognition task consists of two phases mainly, training and prediction. The pre-recorded user speech samples for each voice command are used in the training phase. Based on the consistency between the samples of single voice command, the features are extracted and are used by the prediction module to map the given speech sample to one of the voice commands. Hence, if the speech is not consistent, it troubles the feature extraction, and thereby the inconsistent or wrong prediction makes the system useless.
In this paper, an ensemble Gaussian Mixture Model is applied using Hidden Markov models (HMMs). HMMs are a mathematical tool for modeling many real-time series data. The HMMs are used as the brain of many artificial intelligence systems to classify the real-time data. Computational biology, pattern recognition, data compression are some of the essential applications of HMMs. They have also been used in object tracking and image sequence modeling processes in the Computer vision domain [6].
Related work
The implementation of fundamental concepts in statistics is Probability density function (pdf) estimation. Ensemble learning has applied for density estimation for designing averaging a single Gaussian Mixture Model (GMM) proposed by Michael Glodek et al. [7]. The ensemble approach has used to increase the precision and stability of the overall pdf. Finally, GMM calculated for approximation and classification of non-gaussian pdf.
The widely used classification algorithm is a random forest implemented in the area of recovery of information. Instead of separate clustering algorithms, Jan Janoušek et al. [8] cluster forest specifies a unique domain that provides better evaluation than individual clustering algorithms. The latest ensemble clustering algorithm depends on the cluster forest is GMM. The GMM parameters have calculated by the expectation-maximization algorithm.
Matthew Nicholas Stuttle et al. [9] proposed GMM estimation parameters from the spectrum of speech using the EM algorithm. The set of parameters directly implies the linear range for normalization of vocal tract length and compensation techniques for additive noise. The noise present in the GMM parameters overcome by two noise compensation methods. One is the front-end extraction stage, and the other is a model compensation method. Increased GMM component mean feature with the standard MFCC feature vector, the error rate is reduced on both approaches. Statistically notable improvements have achieved on the RM task.
Yaxin Zhang et al. [10] proposed a word recognition system in a speaker-independent way. The combined method of hidden Markov modeling with vector quantization techniques have implemented. They offered a statistical clustering algorithm, and expectation-maximization algorithms implemented for improving the recognition accuracy.
Sid-Ahmed Selouani et al. [11] proposed an automatic evaluation of dysarthric speech. They offered a combined hierarchical perceptrons multilayer structure with the class posterior distribution. Finally, the output showed the consequence of rhythm metrics, and the effectiveness of the hybrid classifier used to differentiate the levels of Dysarthria severity.
Prasad D. Polur et al. [12] proposed speech recognition through a computer with a separate Dysarthria person. They offered ten state ergodic Hidden Markov Models (HMM), and an artificial neural network has carried out. At last, a rehabilitation control tool to direct a Dysarthria motor with a separate person has carried out successfully. The central nerve system degenerative disorder is Dysarthria, which has affected the articulation and pitch control. Therefore the challenging task is speaker recognition of Dysarthria.
Aref Farhadipour et al. [13] proposed a feature- extraction method. They offered a goal for finding a speaker has affected from Dysarthria. At the end of the result, the most exceptional accuracy has achieved 97.3%.
Human listeners have very tough to understand the Dysarthria affected a person’s conversion. Using an automatic speech recognition system (ASR), even a naive person also understood the dysarthric speech has proposed by Kinfe Tadesse Mengistu et al. [14]. Finally, the performance has increased up to 79.78% by using a single-word multiple-choice test.
Mark Hasegawa-Johnson et al. [15] proposed a method for Dysarthria-caused persons, which reduced or deleted all consonants and painstaking stutter for three affected persons. They have introduced HMM-based recognition and have succeeded for two persons but have failed for one person to delete all consonants. In contrast, digit recognition methods have successful for two persons but failed for one person with the stutter.
Myungjong Kim et al. [16] proposed a technique for dysarthric speech recognition called Convolutional long short-term memory recurrent neural networks (CLSTMRNNs). They suggested the method to use CLSTM-RNNs. Finally, they achieved some improvements among nine dysarthric affected persons using the above approach.
Toru Nakashika et al. [17] proposed an investigation of Dysarthric speech recognition. They offered a convolutive bottleneck network (CBN) plan for feature extraction reduces the naïve speaking problem caused by athetoid. A motor speech disorder is a Dysarthria.
Concentrating phonetic variation using the Kullback-Leibler divergence based hidden Markov model (KL-HMM) has proposed by Myungjong Kim et al. [18]. They suggested posterior phoneme probabilities implemented in the acoustic model of deep neural networks for preserving the speaker-specific data.
Miller et al. [19] used the Dragon VoiceSripe system to develop a voice command recognition system. It is observed that the ability to repeat the same voice command with a consistent speech by the individuals with cerebral palsy is a crucial challenge and quality attribute on which the system’s accuracy depends. Lee et al. [20] used another speech recognition system by Interstate Voice Products and reported that only 70% accuracy is achieved even after retraining. Carlson and Bernstein [21] highlighted that the accuracy of their speech recognition system varies from speaker to speaker because of the cerebral palsy and the resultant inconsistency in the speech. Good enough and Rosen [22] highlighted the trade-off between voice command set size and the systems’ accuracy. It is observed that the prediction rate degenerated even for a voice command set size of 30.
Ren and Liu utilized the deep belief networks to produce a continuous dysarthric speech recognition system using the TORGO database with more than 8400 dysarthric utterances. Isolated-word based models and traditional algorithms for speech recognition like Gaussian Mixture Models (GMMs) were producing promising results for Dysarthric speech recognition [23]. The continuous speech recognition ability is required for a voice command system for the dysarthric speech [24, 25]. The GMM-based generic speech recognition approaches may have difficulties in model Dysarthric speech [26]. As a step to overcome these difficulties, alternative methods to revise the false pronunciation were proposed in [27, 28]. However, improved performance is expected from the Dysarthric speech recognition systems to utilize them in real.
Although the performance of some recent attempts was reported to be successful in Dysarthric speech recognition, it should be noted that the voice command set size is limited. And a dysarthric speech recognition system with a broad set of voice commands is still not available.
The following drawbacks in the traditional speech recognition systems like Hidden Markov models (HMMs) and GMMs are limiting their use in Dysarthric speech recognition [15]: The Dysarthric speech input representations can-not be Gaussian distributed as expected by a GMM. The training process ignores the voice command context information because of its default assumption that the observation probability of every hidden state is independent. Although the GMM is proved to an efficient classifier over high dimensional data, the complexity of the model affects the performance. The lack of extensive training data for Dysarthric speech is a limitation to use GMM, as it needs more training data to generate a robust model.
Gaussian ensemble for Dysarthric speech recognition
A Gaussian Mixture Model (GMM) is defined as a linear superposition of multiple Gaussian distributions defined by their mean vectors and covariance matrices.
It is recommended to use a Gaussian Ensemble (GE) rather than a single GMM. Ensembling is a type of aggregating or averaging multiple classification models into a combined model. Statistically and computationally, the GE is proved better than individual GMMs in terms of accuracy and stability to avoid local optimums.
The proposed work is composed of two phases; the first involves the weighing of various mixture models involved.
The weighing mechanism works by considering the relative accuracy of each model for each other. The architecture of the proposed GE is shown in Fig. 1. A small portion of the training data, preferably 20%, is taken as T1 and the rest as T2. The training data available is treated by each mixture model GMM1, GMM2, GMM3, and GMM4. For each model, the accuracy is calculated, and finally, relative accuracy is calculated. The model that gives maximum accuracy is held as the benchmark. All other mixture models are meant to have a translated accuracy provided the above model.
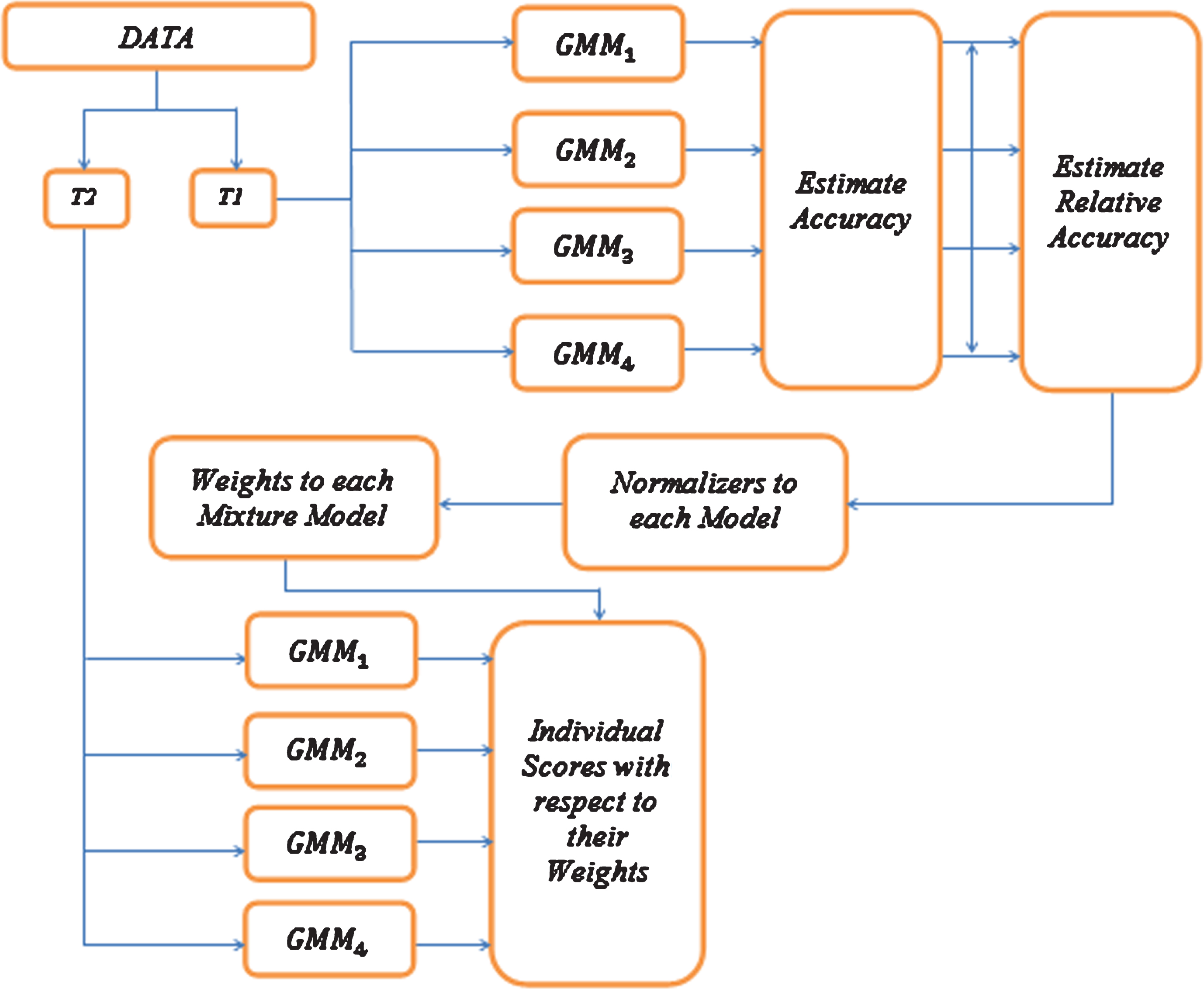
Architecture of the proposed Gaussian Ensemble for Dysarthric Speech Recognition.
Algorithm-1 describes the use of an ensemble classifier for prediction. The training data is divided into multiple split and allocated to every mixture model. The resulting accuracies are forwarded to Algorithm-2 that returns the weight of each model. The relative accuracy is then normalized. There is no way of ignoring any model completely due to obvious reasons. For weighing, k% of the total relative accuracies are taken and split equally among every model. The rest of the weight comes from the relative accuracy of the model.
The procedure of normalizing the weights is represented in Algorithm-2 (Normalizer). The maximum of accuracies is taken, and all other models are made to have relative accuracies concerning it. 10% of the sum of the relative accuracies (k = 10) is distributed equally among all models to ensure there is no zero weighing to any model. It gets added to the normalized accuracy and, ultimately leading up to the weight of the model. This weight of the corresponding model is useful when that model is used for testing purposes.
For each class C_k in the dataset T2, a score is calculated by multiplying two values. The first value is the weight of the Gaussian Mixture Model (GMM). The second value is the probability value that was predicted by that model for class C_k. The resulting class predicted is the class that ends up with the maximum score. It was also clear that the ensemble model never produced a wrong class when at least one of the models predicts the right class.
In the current study on the effectiveness of a GE than individual GMM for a Dysarthric speech recognition system, we have used 5 unique models named GMM1, GMM2, GMM3, GMM4, and GMM5 to develop a GE. The number of hidden states and the number of mixtures for GMM1 is 7 and 5, respectively.
Similarly, the number of hidden states for GMM2, GMM3, GMM4, and GMM5 are 11, 13, 17, and 20, respectively. The number of the mixture used for the above models are 7, 9, 15, and 19, respectively. These design details are as described in Table 1.
Parametric design details of individual GMM models used in the study
Parametric design details of individual GMM models used in the study
Accuracy is the parameter that decides the superiority of a speech recognition system and is measured using Equation (1).
Five different Dysarthric speech datasets, namely, T0, T02, T03, T04, and T05, have been used to test the GMM models. The accuracy of all the models tested on five different Dysarthric speech datasets was as reported in Table 2. GMM1 has produced at most 49.6% accuracy with T04, and for other data set, it performs very poorly. The mean accuracy of GMM1 with all five data set is 46.21%. Similarly, the GMM2, GMM3, GMM4, and GMM5 models have performed well with T04. But with other data set, the accuracies are not consistent, and the models behave differently and produce varying accuracies. The mean accuracies of the GMM models are also very less, and the maximum is 58.05%. But, when the GMMs are ensembled, the mean accuracy is 61.30%, which is higher than the individual mean accuracies.
Comparison of accuracies of individual GMMs and GE
Besides the accuracy of each GMM model and ensemble GMM, we also tested the Precision, Recall, and F-Measure values for the proposed speech-recognition system. The precision ensures the relevancy property of results and recall ensures the correctness of the relevant results achieved. The F-Measure indicates the best and worst cases of precision and recall values.
The performance of the proposed GE model over various severity levels of dysarthric speech is as reported in Table 3.
Precision, Recall and F-Measure statistical parameters
The precision, recall, and F-Measure calculations are as described by the Equations (2), (3) and (4).
Where, TP (True Positive) – Refers to the number, a voice command is correctly recognized as the same. FP (False Positive) – Other voice commands that are wrongly recognized as the candidate voice commands. TN (True Negative) – A correct recognition that the supplied sample is not the candidate voice command. FN (False Negative) – A wrong recognition of the candidate voice command as some other voice command.
The precision, recall, and F-Measure values are calculated for high severity, low severity, and medium severity cases of Dysarthric speech. Among the three severities, the high severity cases have produced maximum values of precision, recall, and F-Measure values. The Gaussian Ensemble model has provided the mean as 0.587, the mean recall as 0.5568, and mean F-Measure as 0.574.
Table 4 presents the detailed confusion matrix for a set of twenty-voice command recognition. Generally, the confusion matrix displays the result of the classification model or prediction model. The proposed GE model has exhibited a promising precision and recall, as reported in Table 4.
Confusion matrix produced by the GE for the twenty voice-command sets
A rigorous statistical study has been performed to analyze the performance of the proposed model on Dysarthric speech recognition. Several iterations of cross-fold testing were performed by varying the test set size as 5, 10, 15, 20, and 25 percentages. While the test set size 20%, the proposed system has performed well among the other size. Especially for high severity cases of Dysarthria speech disorder, the system has produced 62.5% of accuracy. Table 5 describes the result comparison of accuracies produced by the proposed method with varying test set size.
Comparison of accuracies of the GE model for various test set sizes
The accuracy of the GE model is the normalized relative accuracy of individual models, and no particular model is completely ignored. For weighing, k% of the total relative accuracies are taken and split equally among every model. The rest of the weight comes from the relative accuracy of the model. The study on accuracy changes concerning k-value is reported in Table 6. In this scenario, the proposed system outperformed well with 62.35% when the k-value is 10.
Comparison of accuracies concerning k-value
A comparison of accuracy exhibited by the proposed GE model, when tested with several datasets of dysarthric speech with three severity levels of Dysarthria, namely High, Medium, and Low, is reported in Table 7.
Comparison of accuracies for various severity levels of dysarthric speech
In datasets T01, T02, and T04, the proposed Gaussian Ensemble model system has produced the highest accuracy for high severity cases. Whereas, in data-sets T03 and T05, they have produced the highest accuracy for medium severity cases.
The highest accuracy for high severity is 68.25% produced in T04. For low severity, the highest accuracy is 56.85% produced by the T04 set. The T05 dataset has given the highest accuracy of 61.05% for medium severity cases. The average accuracy for high severity, low severity, and medium severity case have also been computed. The proposed system has produced 61.38% average accuracy for high severity cases, 54.98% for low severity cases, and 59.19% average accuracy or medium severity cases.
The current research is a feasibility study to decide whether a Gaussian Ensemble multi-label classification model is suitable for dysarthric speech recognition to develop a unique cognitive computing intelligent system for voice command recognition. The proposed method has been ensembled with different Gaussian Mixture Models (GMM). Five GMMs with varying numbers of hidden states and varying mixtures have been tested individually and in ensembled form. From the test results, it is proved that Gaussian Ensemble has outperformed well in terms of average accuracy. Also, the precision and recall by the proposed Gaussian Ensemble model were promising. The proposed system has also been tested with high, low, and medium severity of Dysarthria disorder. The result in terms of average accuracy shows that the proposed method outperforms in high severity cases. Eventually, robust voice command recognition systems, especially for dysarthric speech, can be expected in the near future, supporting the need of the Dysarthria patients. The study of developing such voice command systems has to be continued, and better accuracy rates are expected with minimal or zero false recognitions, to develop robust assistive cognitive computing intelligent systems.
Footnotes
Acknowledgments
The authors gratefully acknowledge the Department of Science & Technology, India. The authors also acknowledge SASTRA Deemed University, Thanjavur for extending infrastructural support to carry out this research work.