
Abstract
Mobile Cloud Computing (MCC)’s rapid technological advancements facilitate various computational-intensive applications on smart mobile devices. However, such applications are constrained by limited processing power, energy consumption, and storage capacity of smart mobile devices. To mitigate these issues, computational offloading is found to be the one of the promising techniques as it offloads the execution of computation-intensive applications to cloud resources. In addition, various kinds of cloud services and resourceful servers are available to offload computationally intensive tasks. However, their processing speeds, access delays, computation capability, residual memory and service charges are different which retards their usage, as it becomes time-consuming and ambiguous for making decisions. To address the aforementioned issues, this paper presents a Fuzzy Simplified Swarm Optimization based cloud Computational Offloading (FSSOCO) algorithm to achieve optimum multisite offloading. Fuzzy logic and simplified swarm optimization are employed for the identification of high powerful nodes and task decomposition respectively. The overall performance of FSSOCO is validated using the Specjvm benchmark suite and compared with the state-of-the-art offloading techniques in terms of the weighted total cost, energy consumption, and processing time.
Keywords
Introduction
The three various predominant paradigms: Mobile Computing (MC), Cloud Computing (CC), and networking, have attained significant advances in the resource-constrained devices, such as Smart Mobile Devices (SMDs). SMDs have been developed into a piece of formidable equipment providing functionalities equivalent to desktop computers or laptops [1]. SMDs/smart phones are the ruling devices of this decade due to the latest developments and enhancements in the mobile applications catering to the needs of the users. According to market research report by Newzoo, “the number of smart phone users across the globe was 3 billion in 2018 and will hit up to 3.8 billion by 2021” [2]. SMDs are expected to run computation-intensive applications, such as face detection and recognition, interactive gaming, real-time translation services, augment reality, intelligent video acceleration, speech recognition etc. Owing to limited processing power, finite battery lifetime, insufficient memory, it is quite challenging to support the above-mentioned energy-hungry applications. To address the above said setbacks, Mobile Cloud Computing (MCC) is anticipated as a promising approach, as it utilizes cloud resources for the provision of external computation facilities and storage utilities of SMD users. Nowadays, the MCC has evolved dramatically by providing cloud services via SMDs and wireless network interfaces [3]. The definition of MCC given by the MCC forum is “MCC refers to an infrastructure such that both the data processing and the data storage occur outside of the mobile devices” [4]. The generic view of MCC is shown in Fig. 1. It consists of three major components: SMDs, Wireless network, and cloud resources. MCC architecture supports Computational-offloading techniques that enables users to improve energy consumption, increase the computing capability of SMDs, reduce delay, and provides integrated access to the cloud resources at any time. The computational offloading can be achieved by partitioning the computational-intensive applications into two kinds of tasks: non-off loadable tasks and offloadable tasks. The former specifies the tasks performed on the mobile devices based on the dependencies among the tasks or hardware dependencies. The later can be implemented by offloading the particular tasks to the remote server like Cloud Service Provider (CSP) [7], cloudlet [8], and local proximate mobile cloud [9]. This methodology accommodates the resource-constrained devices to run sophisticated applications and alleviate the high computation job on mobile devices [10].
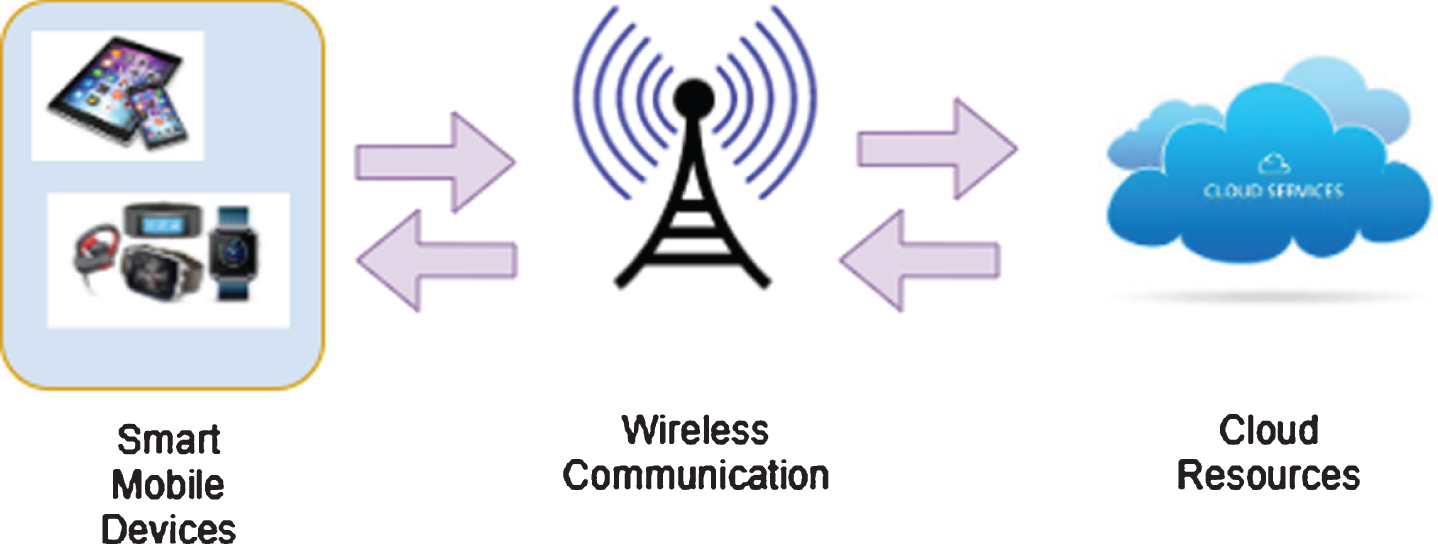
Generic View of MCC.
Computational offloading alleviates power consumption, a substantial amount of energy and processing time, which can be perpetuated on SMDs. It prolongs the lifespan of the SMDs without compromising its mobility and portability [11]. The computational offloading techniques are broadly classified into three: fine-grained, coarse-grained, and a combination of both techniques (hybrid). The fine-grained technique is based on a programmer who will determine the program partitioning and how to adapt the program partitioning with respect to the network settings for offloading. It reduces energy consumption and improves the performance of the SMDs [7, 12–14]. In the coarse-grained technique, the entire program or individual parts of the program are offloaded to the cloud in an automated fashion. It reduces the programmer’s burden since the program does not require modification for offloading [15, 16]. A hybrid approach includes the pros of both fine-grained and coarse-grained techniques.
On the other hand, various computational offloading techniques are developed for the single-site offloading issues [17–19] whereas, the methods for multi-site offloading improves the offloading performance in real-world context [10, 20–22]. Furthermore, several cloud services and resourceful servers are available to offload computationally intensive tasks. However, their processing speeds, access delays, computation capability, residual memory and service charges are different, as it becomes time-consuming and ambiguous for making decisions. Moreover, the optimal offloading with minimal execution time, weighted total cost, and energy consumption have not been explored due to the presence of NP-complete nature in multi-site offloading problems.
To address the above-mentioned issues, this article presents a Fuzzy Simplified Swarm Optimization based cloud Computational Offloading (FSSOCO) for optimal multi-site offloading with the minimum weighted total cost, energy consumption, and processing time. The proposed approach (FSSOCO) integrates the fuzzy logic with simplified swarm optimization to make an efficient offloadable decision. Fuzzy logic is a many-valued logic that deals with approximate rather than fixed or exact reasoning. It provides a mechanism of linguistic constructs such as high, low, medium. The usage of fuzzy logic clusters the available nodes in the resourceful server into different categories based on computational and communication capabilities such that high-configured nodes are easily identified and can be utilized for execution. In addition, fuzzy logic is more appropriate owing to the following benefits (i) handling indistinctness values caused by the dynamic nature of network and computational capability of cloud, (ii) best for nonlinear systems which have arbitrary complexity and more number of inputs and (iii) it can be simply tuned using proficient method by adjusting fuzzy rule. Similarly, simplified swarm optimization technique obtains an optimal offloading solution in a reasonable time. Android and Windows Emulators are used to replicate existing and proposed cloud offloading procedures and analyze the performance of the techniques in a typical real-world scenario. The significant contributions of this work can be summarized as follows: Fuzzy logic-based node(s) classification has been proposed for the identification of high powerful nodes to reduce the computational overhead of computationally intensive mobile applications. Simplified Swarm optimization algorithm has been used for task decomposition, and integration of tasks to reduce the weighted total cost. FSSOCO has been developed to achieve optimal multi-site offloading and it is validated in terms of minimal weighted total cost, processing time and energy consumption using the Specjvm benchmark suite.
The paper is organized as follows: Section 2 presents the existing works related to the mobile cloud computing offloading. Section 3 demonstrates the proposed FSSOCO algorithm. Section 4 discusses the simulation results of FSSOCO. Section 5 concludes the article.
Computational offloading in MCC has attained considerable attention from both the academicians and industrial communities, and an extensive investigation have been conducted to obtain optimal offloading that improves the performance of SMDs.
Single –site offloading:
The author Venus Haghighi stated, “The offloading decisions are made by comparing the energy consumption for local task execution and the energy required for offloading the tasks” [23]. Wang et al. [24, 25] considered the sequence of tasks (arranged in linear topology) to minimize the energy consumption of mobile devices concerning the defined time constraints. Moreover, the majority of the existing offloading techniques were employed to handle single-site offloading problems (an application is divided between the mobile device and a single remote cloud server or application are migrated to a single public cloud). Shuiguang Deng et al. proposed a Genetic Algorithm based Computational Offloading (GACO) algorithm that employs mobility-enabled and fault-tolerance offloading strategy for mobile service workflows [18]. Byung-Gon Chun et al. developed the Clone Cloud model to minimize the total energy consumption of mobile application execution for a thread-based relation graph obtained via static analysis and dynamic profiling [26]. DejanKovachev et al. presented Mobile Augmentation Cloud Services (MACS) middleware to offload the multiple Android services to achieve the minimum energy consumption, memory usage, and execution time of mobile applications. The relation graph of application is built using static analysis of application services profiling information that is based on code size, offloadable or non-offloadable tasks, and memory cost [27]. Jianwei Niu et al. proposed a novel partitioning scheme that comprises Branch-and-Bound based Application Partitioning (BBAP) algorithm and Min-Cut based Greedy Application Partitioning (MCGAP) algorithm to obtain the optimal partitioning for smaller mobile applications and sub-optimal partitioning for large-scale applications, respectively. Weighted Object Relation Graphs(WORGs) is constructed for static analysis and dynamic profiling to extract the actual structure of mobile applications with minimal complexity on resource-constrained devices [28]. Eduardo Cuervo et al. presented MAUI (fine-grained offloading approach) to execute the mobile applications on SMDs (local execution) and in the infrastructure (remote execution) and identified the remote execution methods. Further, MAUI profiles all the processes in an application and utilizes serialization to regulate their network shipping costs. The optimization problem is addressed through Integer Linear Programming (ILP) [29]. Lomotey and Deters et al. proposed Mobile Ubiquitous Brokerage as a Service (Mu Baas), a cloud-based application middleware that enables users to acquire cloud services from heterogeneous devices promptly via load balancing. MuBaaS, a distributed architecture increases the scalability compared to the centralized architecture [30]. Kaushik and Kumar employed genetic algorithm for solving the partition problem by considering communication energy & computation energy and found Service level negotiated waiting time [31].
Multi-Site offloading
The above-stated works are not always beneficial to obtain the optimal offloading with minimal time. Henceforth, multi-site offloading [35], offloading to multiple remote cloud servers may result in more parallel computation and hence reduces the response time and energy consumption in the mobile device. The applications can be offloaded to several sites to get better results in terms of energy consumption, and the computational time came into practice to obtain better offloading than the single-site offloading. Sinha and Kulkarni developed a multi-way partitioning algorithm based on energy minimization for appropriate partitioning of applications at compile time and neglects runtime parameters like bandwidth and energy consumption resulting in imprecise solutions [21]. Niu et al. proposed an energy-Efficient Multisite Offloading (EMSO)algorithm which works on branch-and-bound approach to obtain precise offloading for mobile devices in terms of both energy consumption and execution time. However, the NP-complete nature in multi-site offloading made the optimal partitioning inefficient when the size of the application and number of sites increases [22]. Wu and Huang et al. [32] presented a Multifactor Multi-site Risk-based Offloading (MMRO) model, which utilizes ant colony optimization algorithm to optimize execution time and energy consumption of multi-site offloading issues and addresses the privacy & trust risk factors in offloading. Ezhilarasie R et al. employed Adaptive Genetic Algorithm –Partcle Swarm Optimization to schedule the offloadable codes and to achieve minimum execution time and reduced energy consumption on smart devices [36]. Arivudainambi, D and Dhanya, D introduced [37] three way scheduler to determine the memory scheduling and find optimal virtual machines byimplementing grey wolf optimization algorithm to achieve high storage, low energy consumption and high QOS in cloud computing. Mohammad Terefe et al. [20] proposed an Energy-efficient Multisite Offloading Policy (EMOP) implements Markov Decision Process (MDP) and Value Iteration Algorithm (VIA) to obtain optimal offloading for multisite application execution. Ezhilarasie et al. presented an algorithm called Grefenstette bias based Genetic Algorithm to schedule the applications to be offloaded in multisite execution environment in order to achieve the solution in less convergence time [38]. In [39] authors used teaching learning optimization algorithm to schedule offloaded components on multisite cloud to reduce the energy consumption efficiently. Goudrazi et al. presented an Efficient Multisite Computation Offloading (EMCO) algorithm that employs a genetic algorithm to achieve an efficient offloading in a different multisite context [33]. Further, he extended the work to obtain an optimal and near-optimal offloading solution in terms of the execution time, energy consumption, and weighted total cost through Fast Hybrid Multi-site Computation Offloading (FHMCO) algorithm [10].
The work presented in [18, 34] performs single site offloading and fails to consider the impact of bandwidth variations while offloading heavy intensive modules. Further, the works carried out in [10, 35] focuses is on multi-site offloading. In specific [20, 22] their proposed model neglects the weighted total cost for computationally intensive applications. Similarly, the work presented in [35] fails to consider the energy consumption and processing time reduction for heavy intensive applications, which leads to high computational cost. To address these issues, this paper presents a Fuzzy Simplified Swarm Optimization based cloud Computational Offloading (FSSOCO) that employs fuzzy logic and simplified swarm optimization algorithm to achieve optimal multi-site offloading.
Proposed Methodology: FSSOCO Architecture
In this section, a Fuzzy Simplified Swarm Optimization based cloud Computational Offloading (FSSOCO) has been proposed to find the optimum multisite offloading. In the proposed algorithm, the fuzzy logic is incorporated with the simplified swarm optimization technique to achieve the fitness function within minimal time, and the possibility of attaining a higher iteration count is eliminated. FSSOCO architecture is depicted in Fig. 2. It has two phases, namely the partitioning phase and the deployment phase. The former phase decides whether the tasks or modules (of application) to be executed either in local execution or remote execution based on the computation capabilities of SMDs. In this phase, proposed approach set the threshold value for computation capability of SMDs, whichever the task requires computation beyond threshold can offload to server. The secondary phase offloads the tasks or modules of application that require higher computational requirements like processing time, energy consumption, etc.
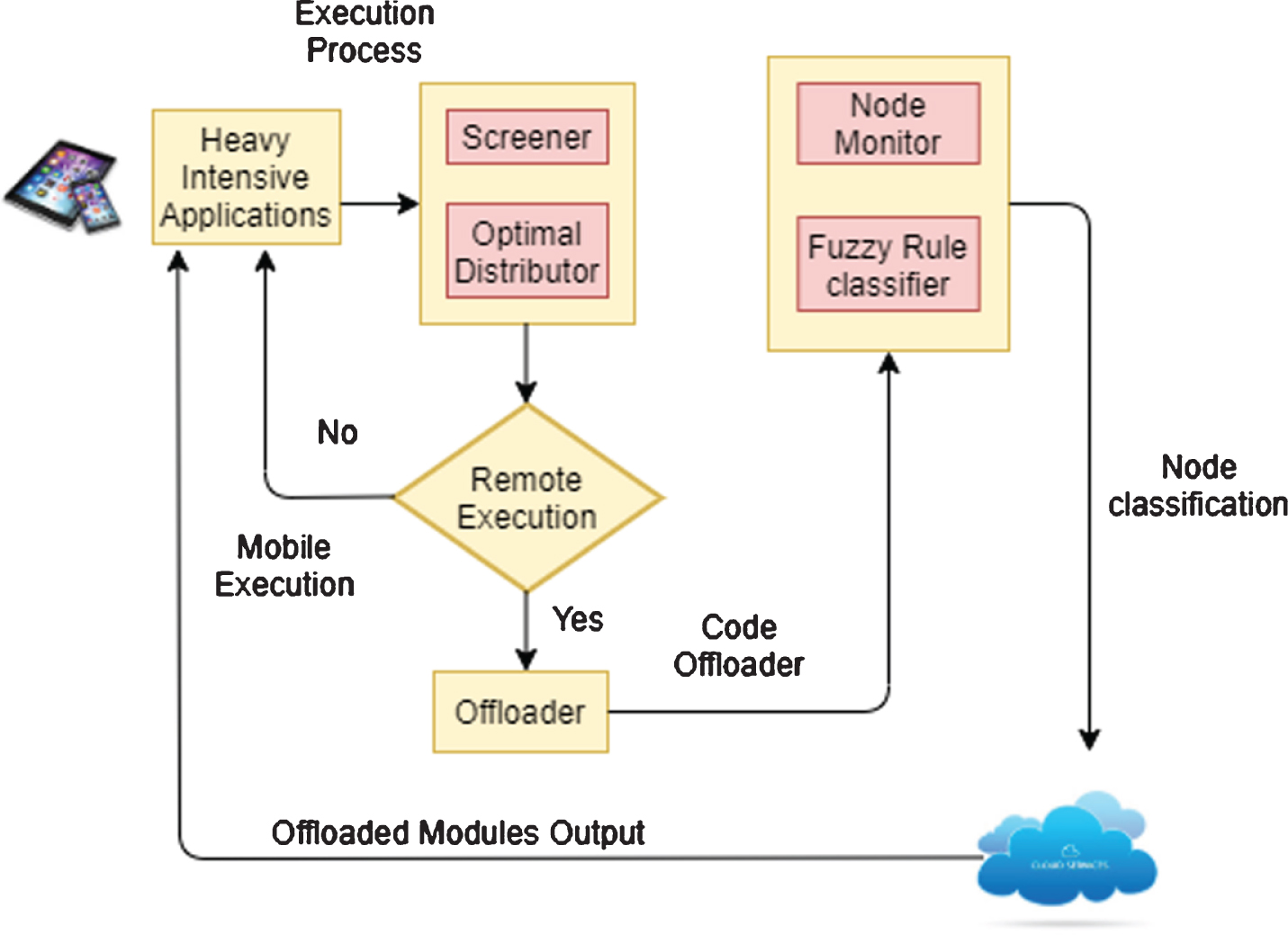
FSSOCO Architecture.
The working of FSSOCO is demonstrated as follows:
Phase-1: Partitioning Phase
In the first phase, the tasks or modules that need less computational requirements are allowed to execute in the mobile phone itself (local execution). The tasks or modules that need high computation capabilities are offloaded to the resourceful remote server for their execution. Computation offloading can be done using the following sub-components involved in the partitioning phase: Screener-It gathers the profiling [34] information of tasks such as CPU requirements, energy consumption, processing time, memory requirements, etc., to identify the heavy intensive tasks. Optimal Distributor-The tasks that require lesser execution time are executed in a local mode, and the tasks that require more execution time must be executed remotely. It is assumed the execution time of jobs that requires greater than 0.05 milliseconds need to be offloaded. Offloader Manager-This is responsible for maintaining the heavy intensive tasks that need to be offloaded (This component is responsible for offloading the heavy computation component on to the resourceful server. It outputs the series of the element to the fuzzy ruler).
For instance, consider a face recognition application that comprises different modules like Match result, CheckImageSizeCompatability, ImageDistanceInfo, Matrix2D, etc., with the processing time of 19.40, 3.45, 0.001, 3.72 milliseconds (Screener). Among these modules, Match result, CheckImageSizeCompatability, and Matrix2D are heavy intensive tasks which is to be offloaded (Optimal Distributor and Offloader Manager).
Phase-2: Deployment Phase
The modules that need to be offloaded are deployed on the nodes in the cluster to minimize the weighted total cost, energy consumption, and processing time of the application. Offloading can be achieved with the following. Node Monitor-Monitors the configurations of available nodes in the cloud. Initially, a sample program has to be executed in all the nodes that are available in the cloud to know their processing power and is maintained in a database. Further, it is used by fuzzy rule classifier to classify the nodes based on the requirement of the components. Fuzzy Rule Classifier-Based on the processing power of the nodes available in the cloud, they are clustered based on their communication and computation capabilities. The following fuzzy rule has been formulated to deploy the modules on to the nodes in order to avoid the random selection of nodes that are available in the cloud and are categorized as three clusters to execute the offloaded units with a minimum weighted total cost.
Where ρ x is the processing power of node Nx, ∀ x ∈ {0, 1, ⋯ , n} and ρ m is the maximum processing power available in the cloud. The nodes which has equivalent processing capability of ρ m will be considered as cluster C0 (high) and nodes which has processing capability more than half and less than three quarters of of the processing capability of ρ m will be considered as cluster C1 (medium) and nodes which has greater than one quarter and less than one half of the processing capability of ρ m will be considered as cluster C0 (low). For instance, maximum computation power ρ m is 2000 MIPS, 1.74GB is available in the cloud. Say for example N1,N2,N3,N4 has computation power 500 MIPS, 1000 MIPS, 2500 MIPS, 750 MIPS respectively. According to Equation (1), N1 ∈ C3, N2 ∈ C2, N3 ∈ C0, N4 ∈ C2. The FSSOCO offloading framework is based on the calculations using available nodes’ computational capability and communication capability (Equation (1)). Nodes from N0 ⋯ N x are categorized into different clusters from C0 ... Cy, ∀ y ∈ {0, 1, 2, 3} depending on the computational and communication capability of available individual nodes where Nx∈Cy∈U C. The classification process is illustrated in Figs. 3 and 4 for clear understanding. Figures 3 and 4 illustrates the four nodes (N0,N1,N2,N3) and three clusters (C0,C1,C3 (C3is out of range in this paper)) such that the node N0 withhigher computational and communication capabilities are categorized into cluster C0 (N0 or so∈C0 -high performance nodes); node N1 with higher computational capability and lower communication capability and also vice-versa belongs to the cluster C1 (N1,N2 or so∈C1-moderate performance nodes);node N2 with low computation and high communication capability are characterized into cluster C3 (N3 or so∈C3-low performance nodes).
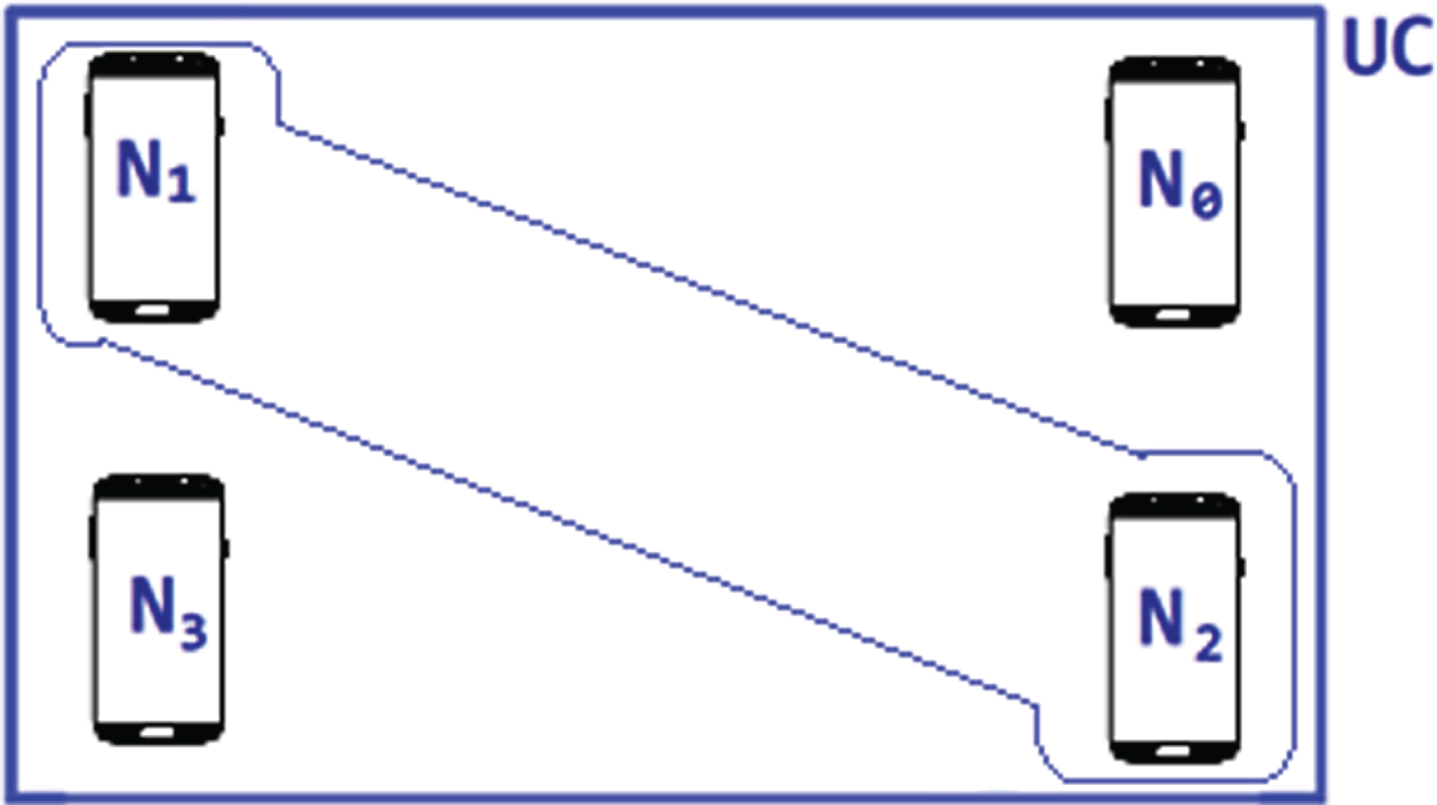
Node Classification Strategy.
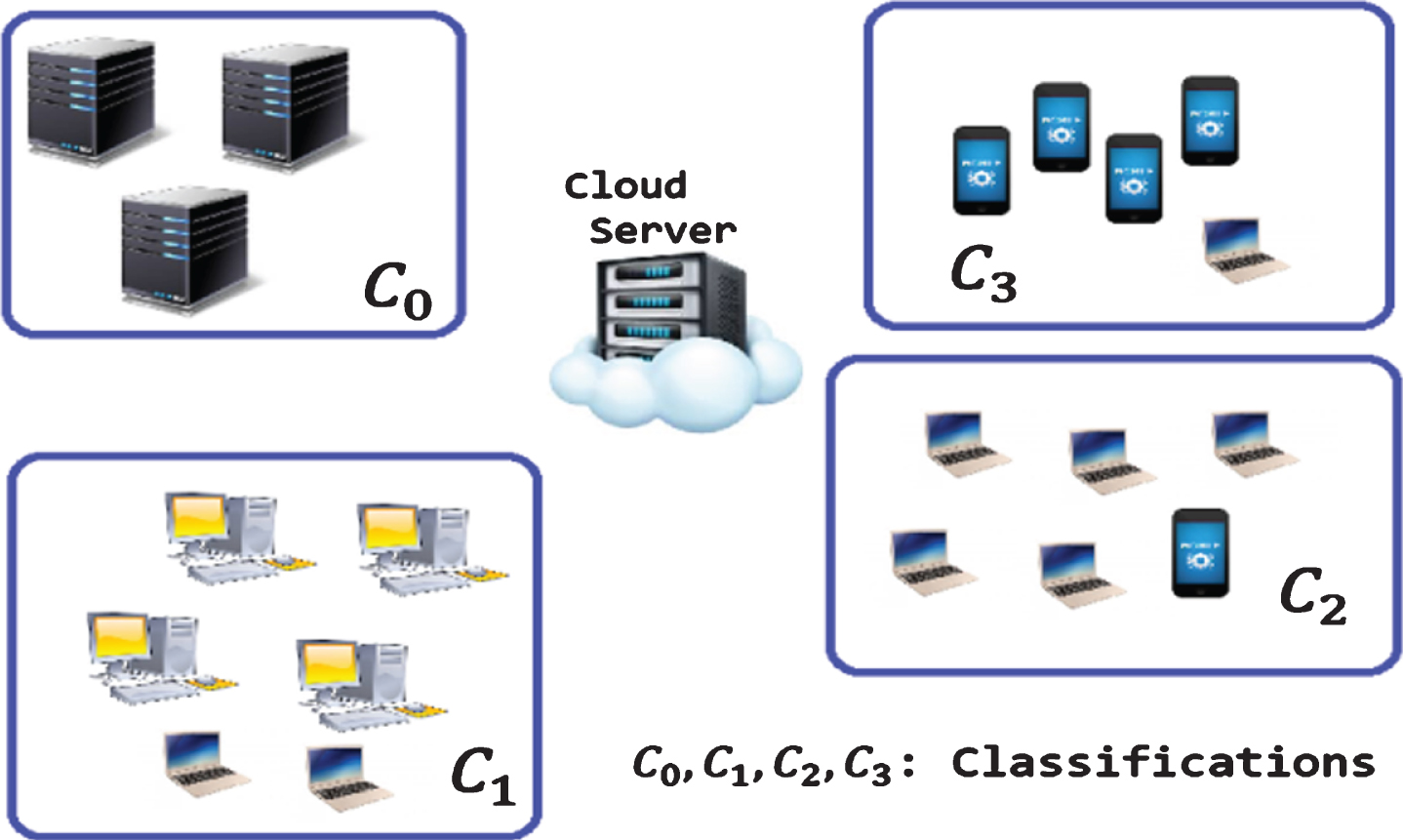
Cluster Representation.
The generalized fuzzy set property for all node classifications is attained as
Where loc refers local (without offloading) performance index and opt is the optimum (perfect offloading) performance index.
For cluster level offloading, each Fuzzy node classification
Nomenclaturein FSSOCO
To achieve optimal offloading for computation-intensive applications with minimal time in MCC is a difficult task. Thus, FSSOCO algorithm is proposed to obtain the optimal offloading with minimum time. The pseudocode of the FSSOCO algorithm is elaborated below. In FSSOCO, the application component parameters like maximum iteration number(I) and Swarm Size (SS) are initialized. Here, the number of components (i.e., modules in the application) and site (cloud server) should be taken in equal number. Assign each site to each component, called as particle to know the execution time of an application. For instance, consider a facebook application with an assumption of five modules (M1,M2,M3M4,M5). Similarly, the number sites (S1,S2,S3,S4,S5) that is cloud servers must be five. Then, initially assign each module to each site (M1 ⟶ S1,M2 ⟶ S2,M3 ⟶ S3,M4 ⟶ S4,M5 ⟶ S5). In original PSO, Original Swarm(OS) is employed (step 11). Goundarzi et al. [10] defined Reserved Swarm(RS)in order to diversify the particles in OMPSO algorithm (step 12). In addition to these, Fuzzy Swarm (FS) has been employed (step 13) in the proposed FSSOCO algorithm to obtain the optimal offloading solution with a smaller number of iterations compared to the OMPSO algorithm. Particles with different configurations in the OS are preserved in FS. The components assigned site in the FS is higher (Equation (5)) when compared to the RS (Equation (4)) and OS (Equation (3)) in terms of processing power, energy consumption and weighted total cost based on I and SS.
This results in higher fitness value. Similar to the RS defined and initialized, the fuzzy swarms are also initialized in two ways such as first few particles are with predefined particles and rest with random particles. Generate a particle such that the modules local execution time was recorded and further, it helps to obtain the effective particles such that their processing costs are smaller compared to the local execution. The swarms OS, RS, and FS are sorted in terms of fitness function to obtain best particle and it is considered as a gbest value of OS, RS and FS. A flow of proposed FSSOCO algorithm is depicted in Fig. 5.
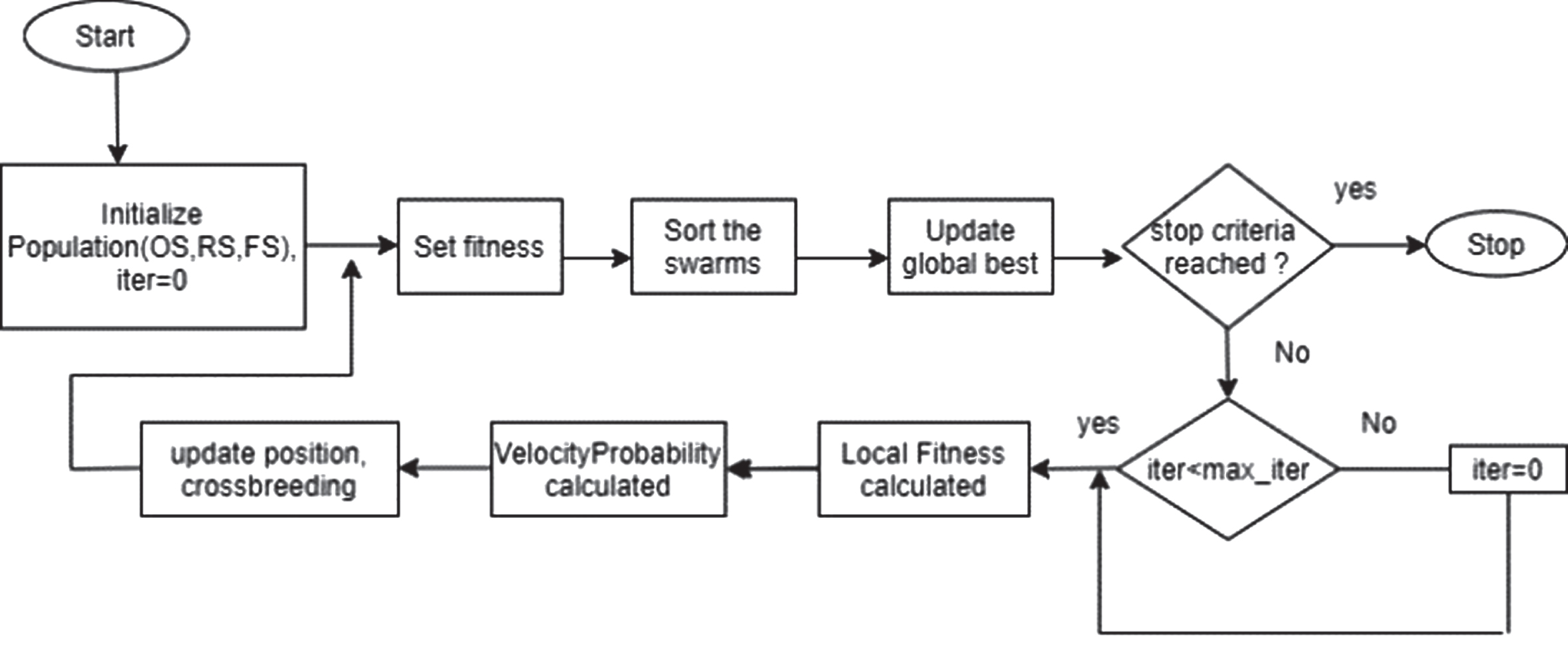
Flow of FSSOCO algorithm.
Fitness Function:
The weighted cost function for multisite offloading that includes total execution time and total energy consumption is given in the following equation.
Where
Where Θ (X) are the total execution time and energy consumption of an application, Θ
Local
are the local execution time and energy consumption of the mobile device [10]. If w
Θ
= 1 and w
φ
= 0, then W (X) model used for calculating total execution time. In other words if w
Θ
= 0 and w
φ
= 1, then W (X) model used for calculating total energy consumption. Fitness function for original swarm is employed using Equation (2), and the fitness function of reserved swarm optimization is given as Equation (4) [5].
Where SS is the swarm size, P i is the i th particle from Original Swarm and P r is the selected particle from Reserved Swarm RS. In FSSOCO, a novel fuzzy swarm is employed by the following fitness Equation (5).
This equation produces optimized fuzzy swarms with minimum weighted total cost, processing time and energy consumption in terms of iterations and swarm sizeswhich is considered to be the fitness for FSSOCO.
Position Update:
Swarm positions are updated towards convergence to new sites using the probabilities kept in the velocity. Three best particles are selected and compared with local fitness of the corresponding component. The particle position update for Original Swarm is performed using the following Equation (6)
where, c
d
i
is the execution cost of i
th
component of original swarm,
The Particle position update for Reserved Swarm is performed using the following Equation (7)
Where d
z
(p
i
) and d
z
(p
r
) are functions used to get the Z
th
component of i
th
particle from original swarm and r
th
particle from reserved swarm. In FSSOCO, the Fuzzy Swarm particle position update Equation (8) is given
The velocity update probability equation for original swarm is as follows.
Where
The velocity update probability equation for reserved swarm is as follows.
Where
The velocity of update probability equation for Fuzzy Swarm is as follows.
Where
After that each swarm’s particles in FS, RS, OS either change their sites assigned by velocities or may be retained in same site. To have diversity, the particles are first crossbred with the original swarm and reserve swarm and in the second stage, they are crossbred again with the first stage output and fuzzy swarm. So that a new swarm is formed based on local fitness equation. So that more effective particles can be preserved by calculating their fitness equations up to swarm size and allow it for further iterations. This is explained in position update algorithm. In FSSOCO, the optimization loop terminates only when the fitness function is satisfied and the fuzzy incorporation reduces the time to achieve fitness function. The possibility of reaching higher iteration count is eliminated by introducing the fuzzy fitness value for the particles.
The efficiency of the proposed (FSSOCO) algorithm has been evaluated using SPECjvm benchmark suite that comprises real graph, benchmark applications like DB, Ray Trace, R4, JESS, image processing and video rendering. The above-mentioned applications are executed in two different modes namely, local execution (i.e., Android and Windows Emulator) and remote execution. For remote execution, a HP Proliant DL160 Gen 9 server is leased as a cloud server. It is equipped with 1×Intel® Xeon® E5-2620v4 (2.1 GHz/8-core/20MB/85W-2.1 GHz 8 core processor with 20 MB L1 cache memory) Processor, 1×16 GB DDR4-2400 R Memory (in 16 memory slots), 3×HP 1.2 TB 12 G SAS 10 K RPM SFF 2.5” Hard Drive (in 8 SFF drive bays total) and powered by 240 V 1.8 KW power supply unit. Android and Windows emulator act as the offloader and HP Proliant DL160 Gen 9 server is offloaded. The performance of the FSSOCO algorithm has been analysed in terms of Weighted total cost, processing time, and energy consumption based on the number of iterations and bandwidth. The number of iterations and bandwidth are evaluated for optimal offloading. The weighted total cost comprises decision-making time, processing time, energy consumption, and network communication cost. Parameter configurations are tabulated in Table 2.
Parameter configurations set in experiment
Parameter configurations set in experiment
To achieve the optimal offloading the swarm size and the bandwidth values are kept as constant by varying number of iterations. The number of iterations of FSSOCO is less compared to the SPSO, MMRO, and OMPSO because the tasks are offloaded to optimal nodes in the cluster. The optimal nodes in the cluster are determined by increasing the swarm size and iterations. The value of weighted total cost based on iterations for two applications are plotted in Fig. 6(a,b). The ‘Local Value’ of weighted total cost for all the application is set to 1, which means that the applications are executed in either Android or Windows emulator. The ‘Optimum Value’ obtained for DB, RayTrace, R4, JESS, Image Processing and Video Rendering are 0.4208, 0.4228, 0.4816, 0.4812, 0.2109 and 0.4788 respectively indicates better optimal values compared to the state-of-the-art offloading techniques like SPSO, MMRO, and OMPSO. Figure 6(a,b) shows the weighted total cost for DB and RayTrace application is minimum compared to the SPSO, MMRO, and OMPSO with minimal number of iterations.
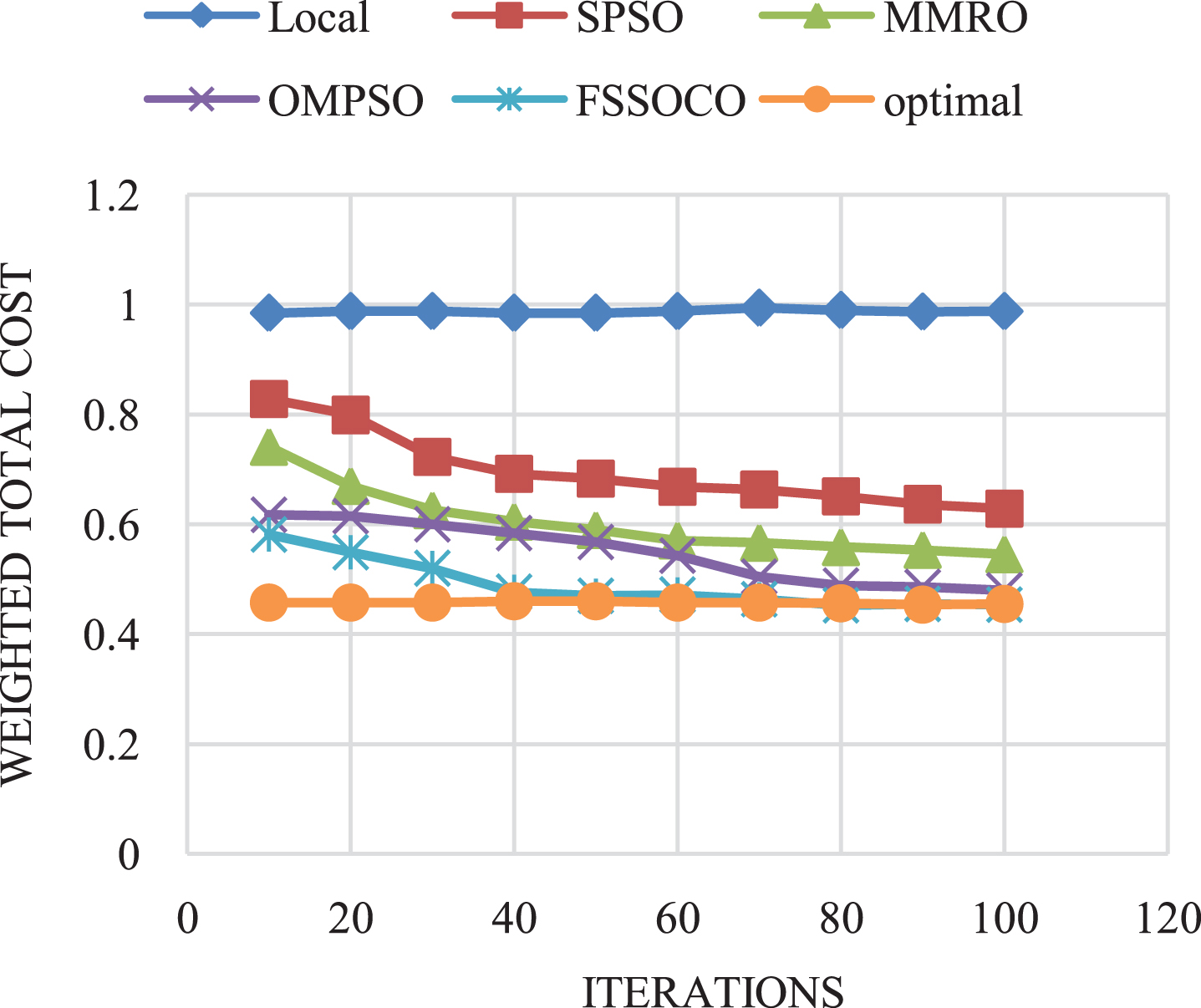
Weighted total cost based on iterations for DB benchmark application.
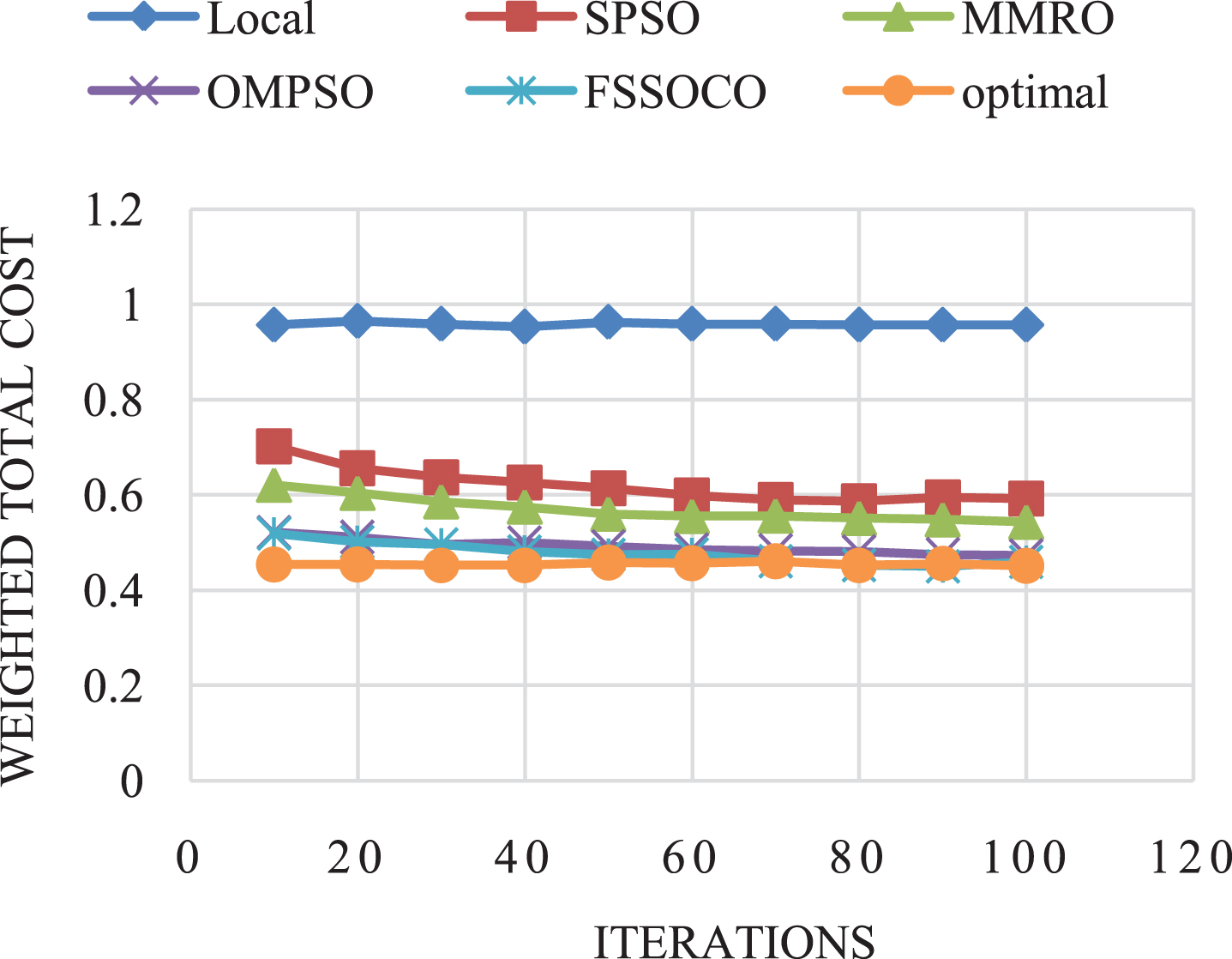
Weighted total cost based on iterations for Ray Trace benchmark application.
Now, the swarm size is kept constant and the bandwidth is varied from 10 kbps to 100 kbps. It indicates the impact of different data transfer rates for offloading. The weighted total cost value gradually decreases with increase in bandwidth. This is illustrated in Table 3(a,b). The ‘Local Value’ of weighted total cost for all the applications is set to 1. The ‘Optimum Value’ of WTC based on bandwidth for DB, Ray Trace, R4, JESS, Image Processing and Video rendering are 0.42, 0.42, 0.48, 0.48, 0.2 and 0.4 respectively. This shows the Local and Optimum values for any process does not get affected based on the number of iterations or bandwidth.
Weighted total cost based on bandwidth for DB application
Weighted total cost based on bandwidth for DB application
Weighted total cost based on bandwidth for RayTrace application
Processing time is one of the very important parameters to be considered while comparing computational offloading methods. In this implementation, processing time based on iterations are metered for applications DB and Ray Trace and plotted as graphs in Fig. 7(a, b) respectively.
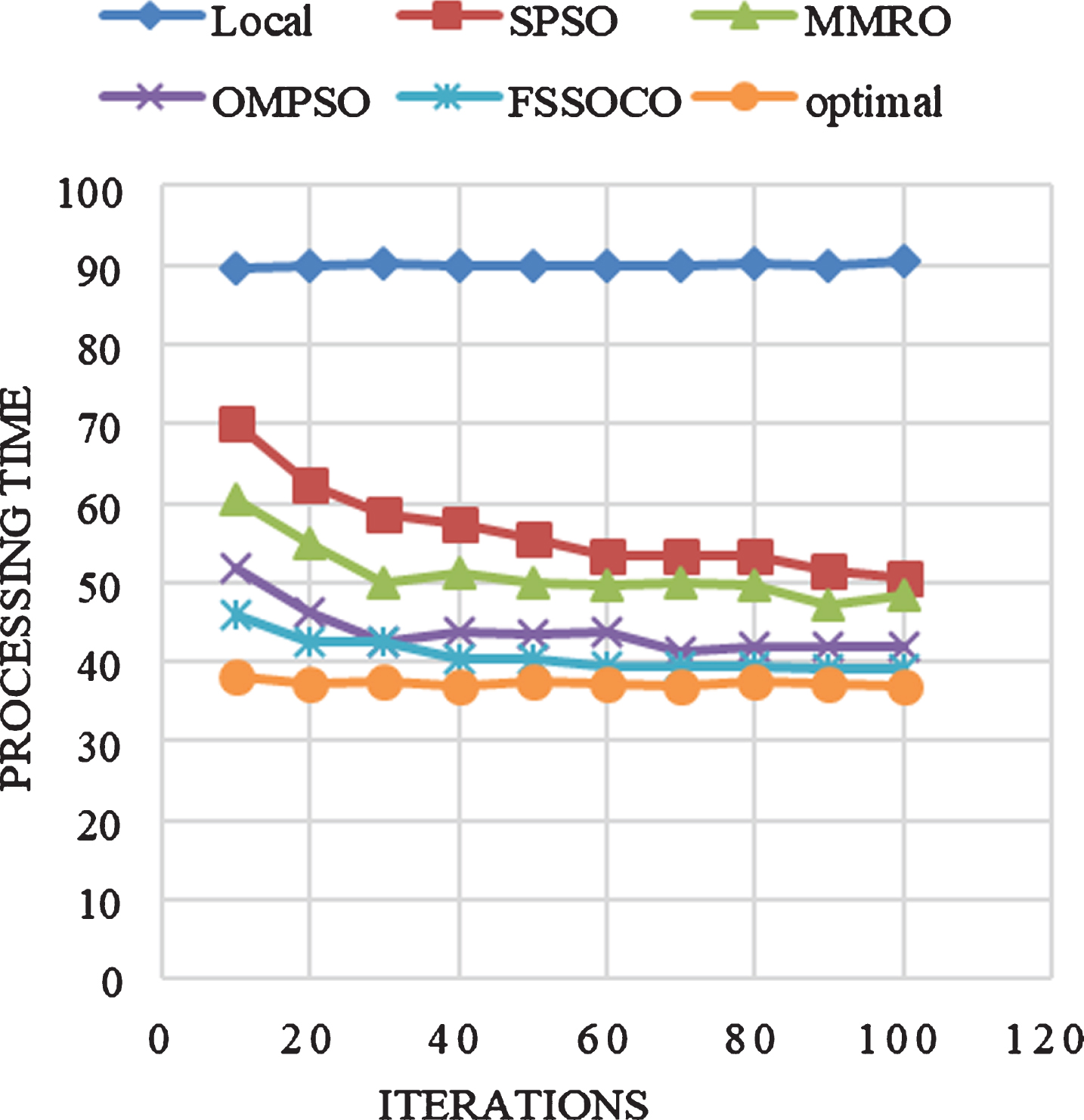
Proceesing time based on iterations for DB.
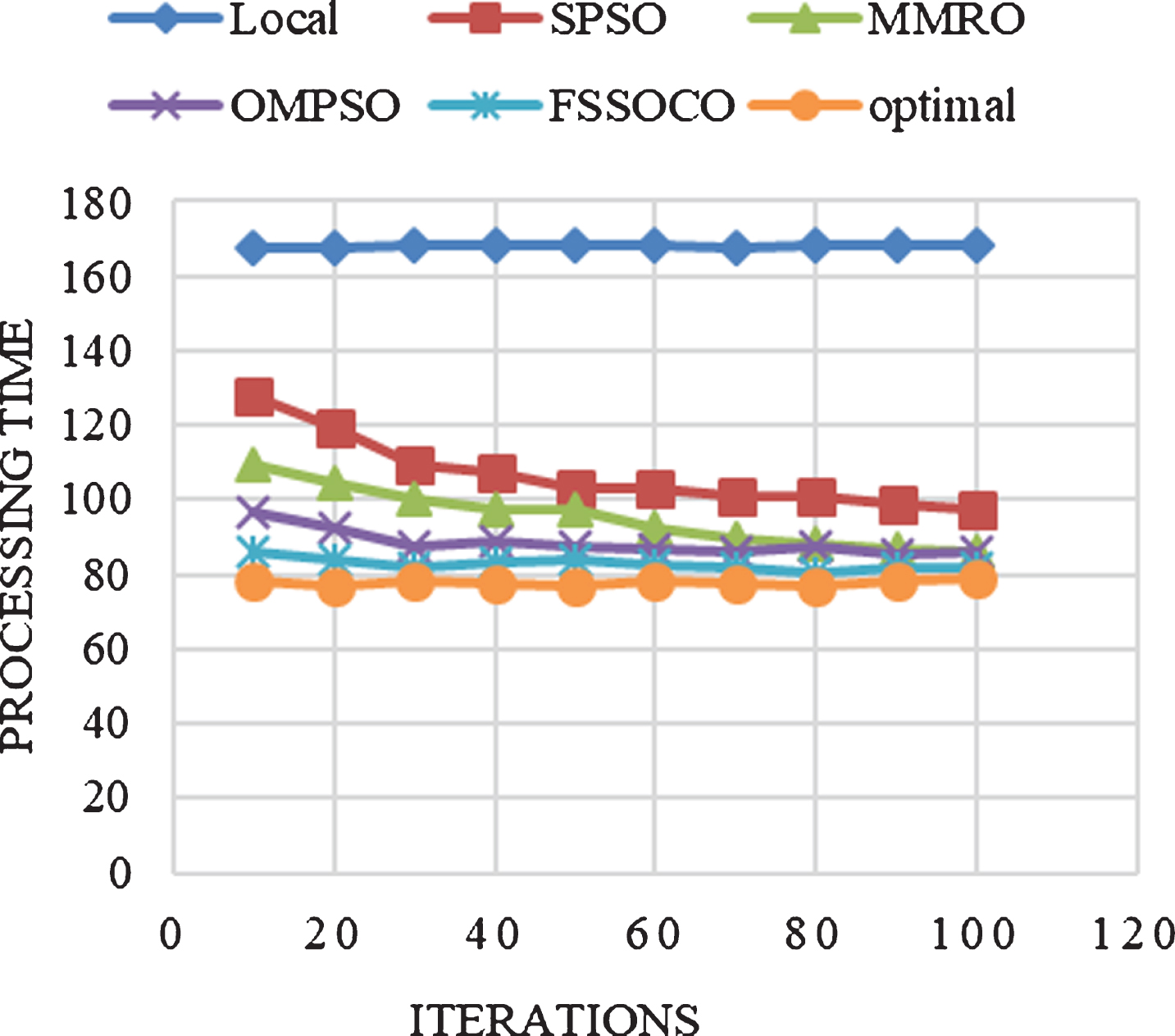
Processing time based on iterations for Ray Trace.
Changing the Processing time based on the available bandwidth for cloud offloading. The variations measured for all the applications (DB, Ray Trace, R4, JESS, Image Processing and Video Rendering) are tabulated in Table 4(a,b).
4(a) Processing time based on bandwidth for DB application
4(a) Processing time based on bandwidth for DB application
Processing time based on bandwidth for Ray Trace application
Power consumption is one of the key factors in mobile networks because many of the nodes are battery operated. A good cloud offloading procedure should produce more computational outcomes, at the same time it has to reduce the power consumption. By minimizing energy consumption, a mobile node can be operated for more time in a single charge. The energy consumption for all applications is shown in Fig. 8(a,b).

Energy consumption based on iterations for DB benchmark applications.
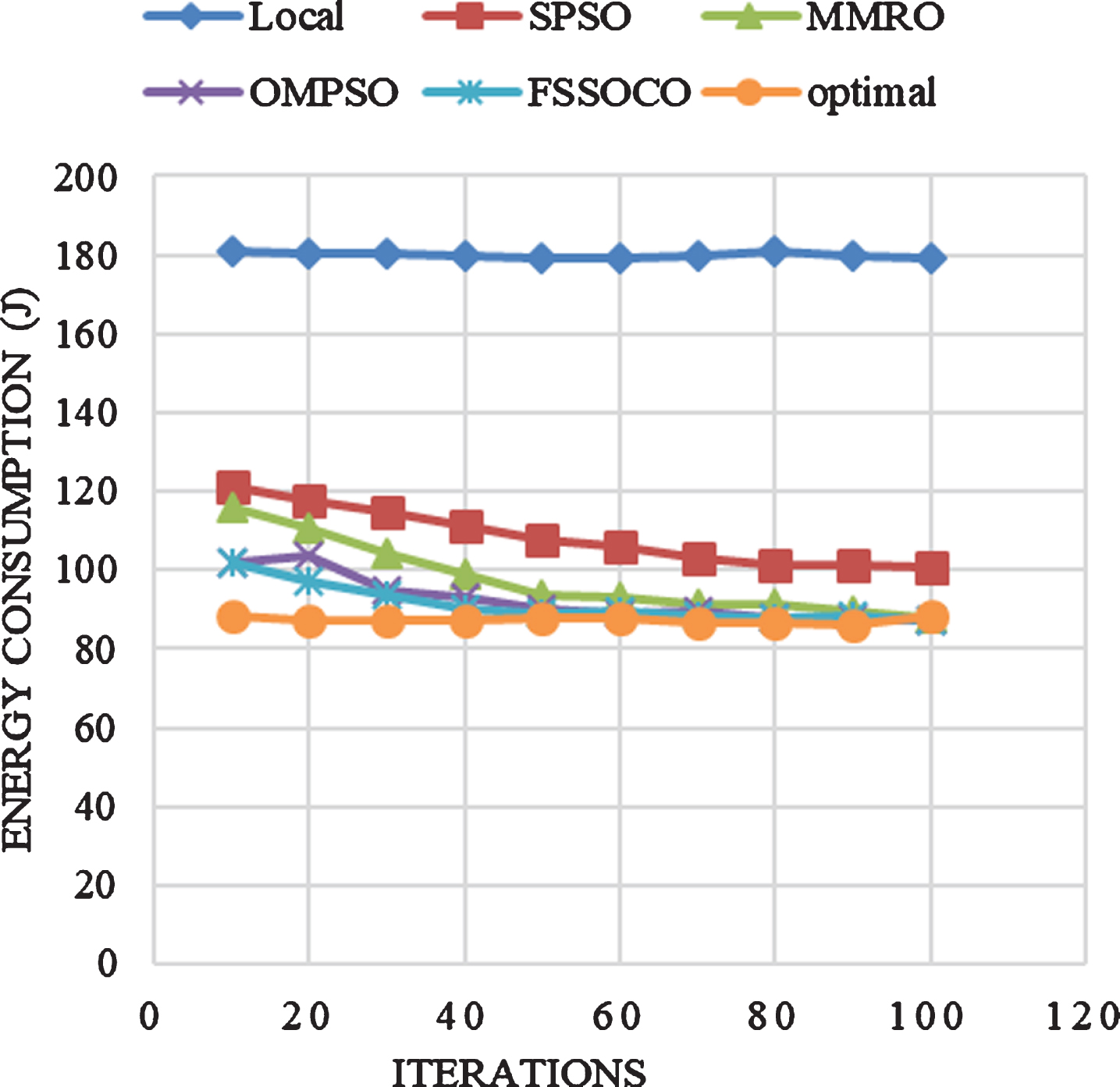
Energy consumption based on iterations for Ray Trace.
Energy Utilization is measured based on the available bandwidth from 10 kbps to 100 kbps and the results forall the applications are shown in the Table 5(a, b). Execution energy used for the applications DB, Tay Trace, R4, JESS, Image Processing and Video Rendering without offloading are 36, 180, 68, 26, 45 and 160 Joules respectively. For optimum distribution, energy consumption for those applications are 16, 80, 34, 15, 36 and 80 Joules respectively. For all the tasks, energy consumption is maintained lower than other offloading procedures.
Energy consumption based on bandwidth for DB application
Energy consumption based on bandwidth for DB application
Energy consumption based on bandwidth for Ray Trace application
The proposed approach has achieved optimal offloading with minimum weighted total cost, processing time and energy consumption by incorporating fuzzy logic and simplified swarm optimization algorithm in mobile cloud computing. Adopting fuzzy rule helps to find high powerful nodes in cloud rather than random selection of nodes to deploy the offloaded modules. The results dictate that FSSOCO outperforms the existing techniques. The proposed approach may not give better solutions with respect to mobility nature and communication changes.
Mobile Cloud Computing (MCC) offers a new paradigm to relieve the pressure of rising data, which demand and augment the capabilities of resource-poor mobile devices. Thus, FSSOCO algorithm has been developed to achieve the optimal offloading in multisite environment. The fuzzy logic has been incorporated into the proposed methodology to identify high powerful nodes and offload the heavy computational tasks into powerful nodes. The FSSOCO algorithm has been evaluated by varying the number of iterations and bandwidth. The proposed work has achieved optimal solution in less number of iterations. The optimal offloading is achieved with minimum weighted total cost, processing time, and energy consumption using fuzzy simplified swarm optimization algorithm. The results demonstrated that the FSSOCO is better compared to the other offloading techniques like SPSO, MMRO, and OMPSO. As the future enhancement, new algorithm can be devised that should consider the mobility nature and communication changes, with minimal time complexity.