
Abstract
A robust disruption prediction system is mandatory in a Tokamak control system as the disruption can cause malfunctioning of the plasma-facing components and impair irrecoverable structural damage to the vessel. To mitigate the disruption, in this article, a data-driven based disruption predictor is developed using an ensemble technique. The ensemble algorithm classifies disruptive and non-disruptive discharges in the GOLEM Tokamak system. Ensemble classifiers combine the predictive capacity of several weak learners to produce a single predictive model and are utilized both in supervised and unsupervised learning. The resulting final model reduces the bias, minimizes variance and is unlikely to over-fit when compared to the individual model from a single algorithm. In this paper, popular ensemble techniques such as Bagging, Boosting, Voting, and Stacking are employed on the time-series Tokamak dataset, which consists of 117 normal and 70 disruptive shots. Stacking ensemble with REPTree (Reduced Error Pruning Tree) as a base learner and Multi-response Linear Regression as meta learner produced better results in comparison to other ensembles. A comparison with the widely employed stand-alone machine learning algorithms and ensemble algorithms are illustrated. The results show the excellent performance of the Stacking model with an F1 score of 0.973. The developed predictive model would be capable of warning the human operator with feedback about the feature(s) causing the disruption.
Introduction
Over two decades, an unresolved issue with stable tokamak operations is the disruption prediction and avoidance. Disruption is the extinction of confined plasma current for a short scale of time (in millisecond), leading to a) damages in plasma-facing components due to high heat fluxes b) high level of eddy and halo currents induced on surrounding vacuum vessels and c) runaway electrons. A statistical investigation on disruption prediction necessitates the development of a new mathematical tool for positive anticipation, as the theoretical models failed for advanced devices like SPARC and ITER. Researchers have addressed disruptions using various statistical models in recent years. Machine learning and deep learning techniques have played a significant role in data-driven methods for disruption prediction. Disruption precursors are different from device to device, where scientists published inspiring works based on passive learning techniques.
Fusion community faces the real challenge with the physics of disruption in understanding and forecasting magnetohydrodynamic instabilities for disruption mitigation. Many researchers are working on developing disruption prediction algorithms for the available fusion reactors like are ADITYA [1, 2], SST-1 [3], ASDEX-U [4, 5], Alcator C-Mod [6], EAST [7], DIII-D [8], JET [9], JT60-U [10, 11], J-TEXT [12] and NSTX [13]. The empirical causes leading to disruptions were recently examined in the Joint European Torus (JET). In case of unintentional disruptions [14, 15], the significant factors are Mode-locking amplitude (20.1%), instabilities at edge radiations (51.8%), instability at vertical positions (3.9%), internal kink mode growth (4.4%) and very low safety factor Q (2.5%). The primary carrier or influencer for disruptions is Mode-locking, which can be caused due to one of the three classes: error fields with low density (10.3%), locked neoclassical tearing mode (6.7%) and current ramp-up formed during instabilities at edge kink modes (3.1%). Our work addresses disruptions that occur due to factors such as Mode-locking and instabilities at edge radiation.
The goal of ensemble classifiers is to develop multiple base classifiers whose predictive output are fed to a meta-classifier. Typically, decision trees are applied in ensemble learners such as random forest and boosting due to its fast learning, interpretability, simplicity, and utilization of short trees as weak learners. In this work, disruption prediction is performed using an ensemble learner for classifying normal and disruptive shots. The stacking technique, which can be employed in both supervised and unsupervised problems, is utilized in this work. The training data is fed to the base classifiers. Various parameters such as cross-validation (CV) folds, the seed value for randomizing the data, batch size, size of data used for pruning are chosen differently for the base learners.
The base learners generate probability distributions for one of the two classes (normal and disruptive). The meta-classifier with the input from the base learners produces a precise probability distribution for the classes. The ensemble learners proposed in this work deploy REPTree as base learners. REPTree [16] utilize reduced-error pruning on its input to avoid overfitting. A simple Multi-response linear regression (MLR) [17] is used as the meta-learner replacing the widely employed Logistics regression. The performance is assessed using a dataset derived from GOLEM Tokamak [18]. From the derived 187 shots, 117 non-disruptive and 70 disruptive shots are utilized.
The research highlights of this work are structured as follows. Section 2 discusses the existing techniques used for fusion reactors. The basic setup of GOLEM Tokamak with the description of features and the details of the ensemble classifier used for disruption prediction are presented in Section 3. In Section 4, the results obtained after the assessment of the predictors are discussed. Finally, Section 5 provides the concluding remarks and probable ideas for enhancing the work.
Related work/literature overview
In Aditya tokamak [19], a Neural Network (NN) based disruption predictor is designed based on the time series predictor model where a series of previous values are collected to predict its importance in the future. The system uses 4 Mirnov coil probes, Hα, and one soft x-ray as the indicative signal for the NN model. The limitation of the system is the usage of minimal diagnostic signals used for training the prediction model. In JET, [20] forecasting the disruption is modelled using an NN based system with multiple diagnostic signals as input to the model. The models are trained using datasets collected from successfully terminated pulses and pulses that disrupted during the operation. The study focused on disruptions of flat-top type as they act as an identifier to control plasma. The flat-top disruptions achieve quasi-stationary plasma current and steady-state equilibrium shape and position.
A model based on Multi-Layer Perceptron [MLP] using nine significant diagnostic signals is proposed in [21]. A self-organizing map had been designed to select the samples of the shots for training. The major shortcoming of the work is that it was developed using only disruptive pulses for training and utilize both non-disrupted and disrupted pulses for testing. Training a system based on disruption (minority) class may lead to uncertainty in the output prediction.
An unsupervised and unbiased learning method for disruption prediction in JET is designed using K-means and CART as a hierarchical technique. The work claims to have 80% success rate in prediction, which is relatively low for a critical environment like plasma operations control. An adaptive predictor for ASDEX [22, 23] in real-time is designed using NN with seven diagnostic signals. The authors excluded the disruptive signals that occurred during massive gas injection, ramp-up phase, ramp-down phase, and vertical displacement events. Most disruption signals are collected during tearing mode growth, thermal confinement degradation, and cooling edge disruptions. The utilization of a self-organizing map for database size reduction makes the system more linear to specific disruptive types. A real-time prediction on JET [24] using a genetic algorithm is designed for improved feature selection. The author presented their work based on a recent predictor of an Advanced Predictor of Disruptions (APODIS). The dominant random diagnostic signals of GA are mean and standard deviation. However, the best signal that is selected may not be used for an extended period as the system upgrades.
A simulated real-time environment [25] based on advanced disruption prediction is performed using a combination of signal information acquired from the frequency domain and Support Vector Machine (SVM) classifiers. The authors utilized 13 signals and generated the power spectrum of the signal for deriving feature components after the removal of the DC component in signals. The primary outcome is the utilization of spectral components of higher frequencies as a precursor for disruption prediction. The authors used an extensive database of JET shots ranging from the years 1997 to 2007 (42815-70722). The overall success rate is 92% with a false alarm of 7%. Adaptive probabilistic disruption predictors [26] from scratch is designed with a high learning rate using Venn predictors. The authors performed a multiclass predictor and calculated the success rate using tardy detection, premature alarm, and a valid alarm. The system consists of two phases induction and deduction, and the significant outcome of this system is the utilization of probabilistic predictors using Venn predictor and Bayes decision for classification.
Disruption prediction in DIII-D and Alcator C-Mod [6] using machine learning techniques is performed using random forest. The authors chose to use the same feature from two devices to predict the disruption by training on one device’s data and testing on the other using the same classifier. The poor performance of the classifier is visualized in C-Mod while using molybdenum penetration. However, the predefined classifiers trained for a specific system should not be used for multiple devices. In [27], an adaptive predictor based on probabilistic SVM is designed for the disruption mitigation analysis of JET. The prediction is performed using a two-class SVM classifier utilizing Bayesian probability to identify the disruptive discharge of a shot. The author’s claim that their system correctly detects 97.3% of the disruptions with a low false alarm of 4.6% and a longer warning time average of 300 ms.
In [28], a disruption predictor is formulated for JT-60U based on sparse modelling using an exhaustive approach for the SVM classifier. The SVM is used as a linear discriminator for a two-class system of disruptive and non-disruptive shots. The author used two different sets of features like instantaneous features and time derivative features for modelling wherein; sparse modelling is incorporated to extract the best features for modelling a disruption predictor.
The authors in [29] performed a survival analysis for classification using Random Forests (RF) classifier. They provided a statistical framework based on time to disrupt through the existing disruption prediction algorithms and estimator for survival probability analysis. The RF and Kaplan-Meier technique was applied in Alcator C-Mod based on plasma discharges and tested via triggering alarms.
In [30], a real-time machine learning-based disruption predictor is designed for the DIII-D reactor using RF ensemble. The authors worked on the Plasma Control System (PCS) framework where most of the predictor generates alarms for a few milliseconds before the disruption. But the work concentrates on PCS for steering plasma in a stable state. The system works on the identification of signals that caused the disruption. The authors used the RF for classification of the signal corresponding to disruption. An accuracy of 95% is reported, which may not be acceptable for ITER.
The authors [31] concentrated on the transfer of adaptive predictors from one machine to another machine for disruption prediction. The adaptive predictor is designed based on ensemble classifier using a combination of CART and RF. They achieved a 94.7% success rate and 7.7% false alarm in the prevention of disruption by providing profile indicators as inputs to classifiers. The drawback of the work is that a small dataset is utilized as the focus is on smaller devices rather than next-generation machines.
The authors [32] propose a combination of stacking and data reduction on seven datasets from the UCI repository. Data reduction is applied to level-0 (base) classifiers. Clusters are generated from a variant of k-means clustering based on fuzzy logic. From the clusters, data reduction is performed through agent-based population algorithm. The stacked output is compared with various stand-alone algorithms such as CART, C4.5 and RF. Comparison is carried out with accuracy as the only metric, which is not good enough for a classification problem.
In [33], both stand-alone and stacking methods were implemented for the forecasting root wall thickness (RWT) in soil property. Data engineering is performed on the soil dataset, which has five features and 98 instances. CV of 15 folds is carried out on the training dataset on the base and stacking learners. MLR, ANN, SVM and RF are the base learners, and a generalized linear model is used as the meta-learner. Since it is a regression problem, a comparison with all root means square value show stacking with superior result. In our work, MLR is used for classification.
ANN, Extreme Gradient Boosting (XGBoost) and two stacked ensemble models are utilized for classifying applicants risk score to choose the right insurance policy [34]. Preprocessing with feature engineering such as label encoding for categorical data, replacing missing values with mean and penalized negative values is done. For the first Stacking model, logistics regression and KNN are used as level-0 learners and decision tree as a level-1 learner. RF and Adaboost are used as level-0 learners and Gradient Boosting as a level-1 learner for the second stacking model. A 10-fold CV is performed on the training data for all the models. ANN and XGBoost performed well on two different configurations.
Our work implements stacking as the ensemble classifier with REPTree as the base-learner and MLR as the meta-learner. REPTree is faster than C4.5 and CART decision trees that are commonly employed in RF and Adaboost. REPTree functions like C4.5 algorithm with the difference in pruning. REPTree follows reduced-error pruning to avoid overfitting and minimizes bias and variance. An easier to interpret MLR is employed as meta-learner instead of the logistics regression. The overall complexity of the ensemble algorithm is reduced with the selection of the base learners and its reduced output dimension, (described in Section 3.1.2), and MLR as meta-learner. The results from Stacking show high-performance metrics.
Disruption prediction
The goal of our work is to contribute a disruptive prediction system with significant performance metrics.
GOLEM Tokamak
GOLEM tokamak [35–37] is functional at the Faculty of Nuclear Physics and Physical Engineering (FNPPE), Czech Technical University in Prague with its exclusive benefit of handling remote system through the Internet. The tokamak vessel has a major radius of R = 0.4 meter and minor radius b = 0.1 meter. GOLEM tokamak is a stainless-steel vessel on a well-equipped poloidal limiter (Molybdenum) of radius a = 0.085 meter. The Tokamak is provided with an established set of the diagnostic system to measure signals such as plasma current, loop voltage, visible emission, and toroidal magnetic field. Figure 1 depicts the schematic representation of the GOLEM Tokamak. The reactor is equipped with an array of Mirnov coils, bolometers, a visible spectrometer, a fast camera, and twelve Langmuir probes in a radial array. GOLEM tokamak functions at a determined toroidal magnetic field of a range up to 0.8 T. The temperature of the central electron is below 100 eV, with maximum plasma density average 1019 m-3, the length of the maximum pulse is around t < 30 milliseconds. Table 1 gives the list of signals that are considered for classification on GOLEM Tokamak. Table 1 gives the list of signals that are considered for machine learning classification on GOLEM Tokamak.
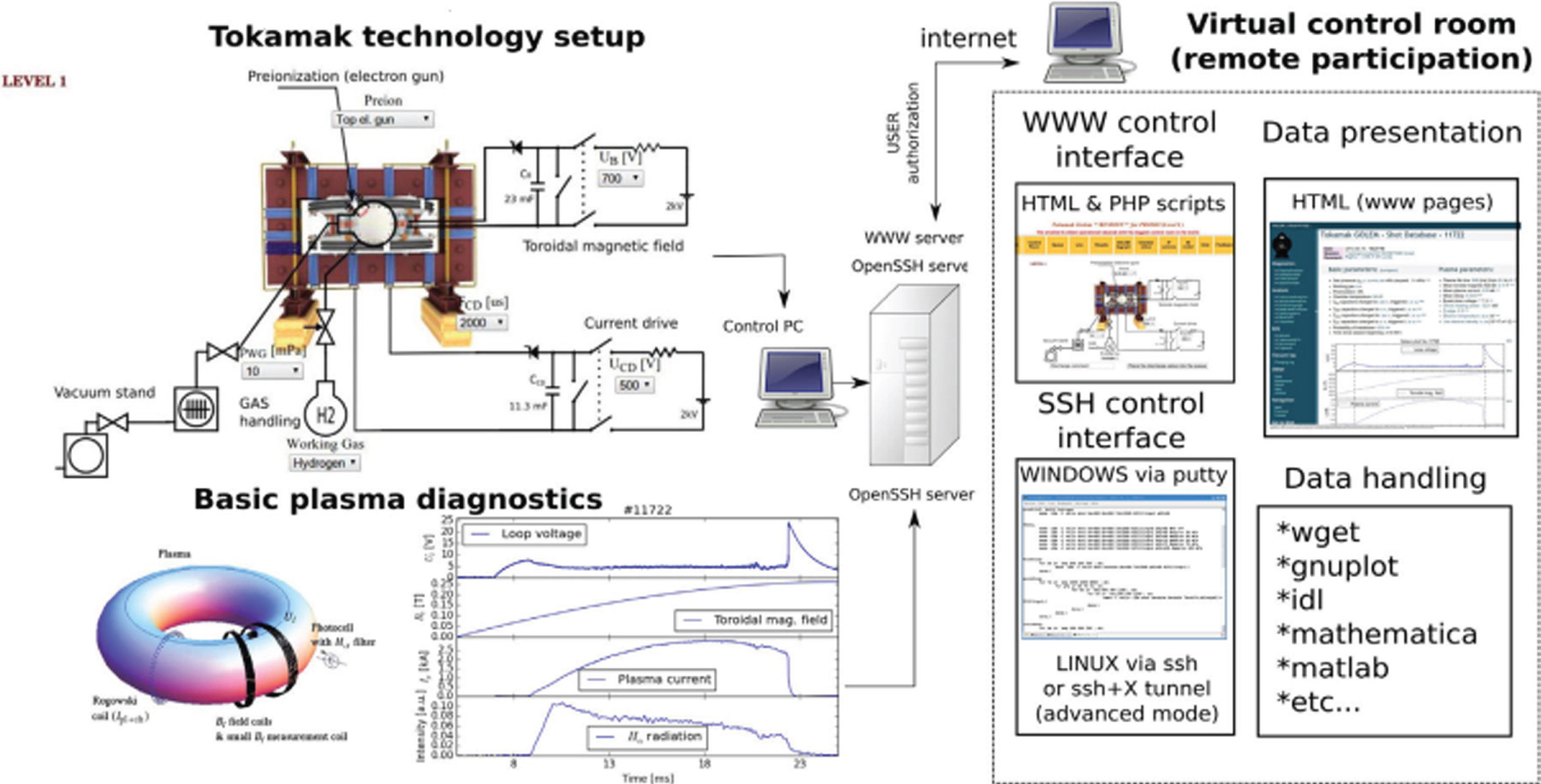
Schematic Representation [38] of GOLEM Tokamak Experimenter.
Signals in GOLEM tokamak
Figure 2 shows the working flow of the developed ensemble model. Out of the 187 shots, 132 shots consisting of 82 normal and 50 disruptive shots are used for training. Different values for CV folds, seed for randomizing the data, batch size and the portion of data required for pruning are used for the four base learners. Diversification among the base learners is achieved by selecting different hyperparameter values. The class distribution probability from each of the base learners forms the input to the meta-learners. The base learners with pruned REPTree does not overfit due to the use of CV. The meta-leaner model renormalizes the class probabilities and avoids the overfitting. The validation of the resulting model is performed on the unseen data. The test data or unseen data contains 55 shots that include 35 normal and 20 disruptive shots. The performance of the stacking model on the test data provides the generalized performance of the model.
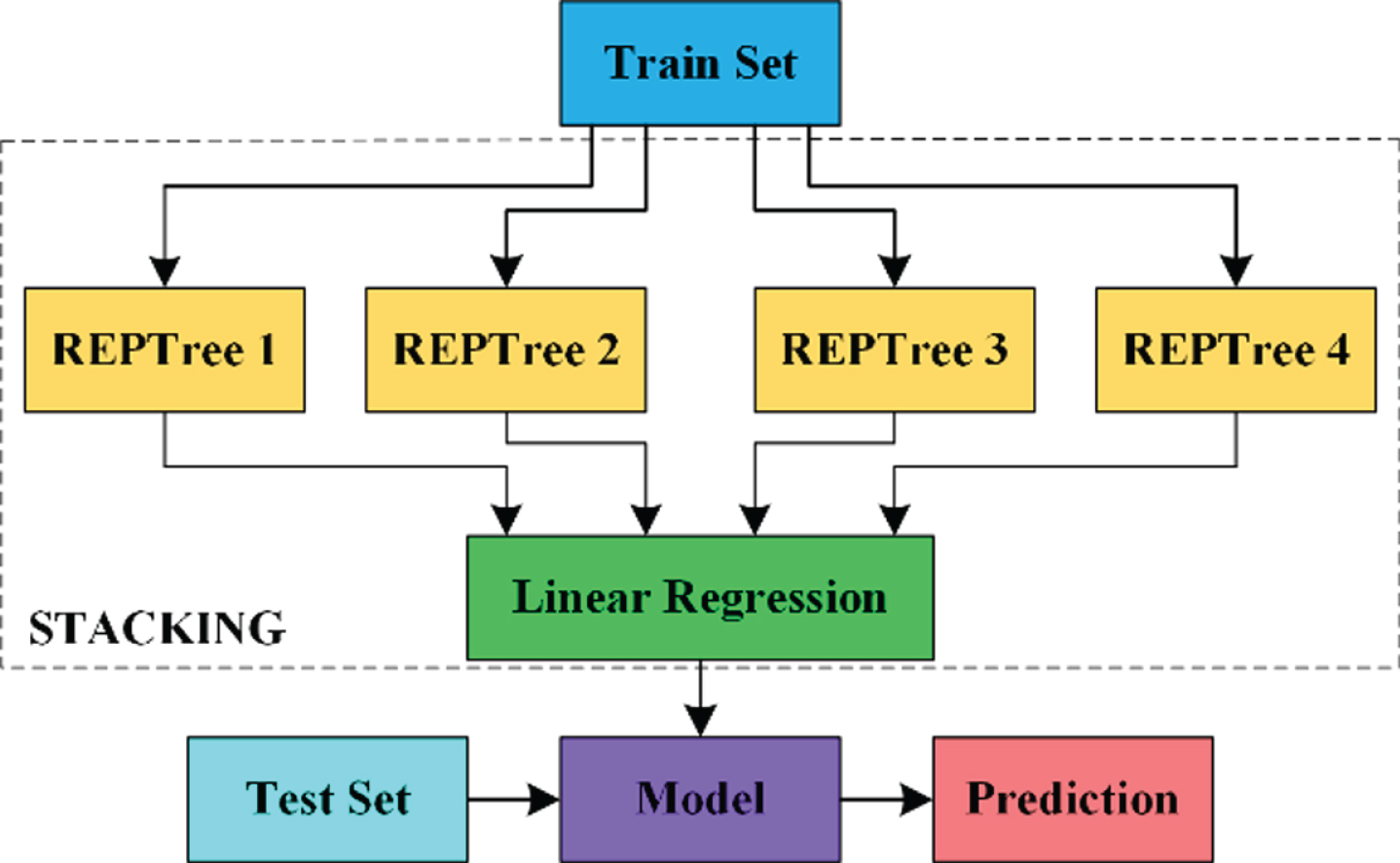
Ensemble learning – Stacking.
Table 2 depicts the Stacking algorithm. The function of stacking or blending is to combine predictions of base learners or original classifiers (level-0 models) using a meta learner (level-1 models), which provides the final prediction. The base learners can be the same algorithms or different algorithms or a combination of both. The outputs from the base learners are not a single class prediction but a probability estimate of each class. User-defined CV is performed by the base learners on the training data. The class probability distributions, which conveys both the prediction information and the confidence of classes are given as input to meta-learner. Irrespective of the base learner, Ting and Witten [39] introduced MLR as the level-1 classifier. The MLR discovers a linear function for every class by predicting the degree of confidence in class membership. After normalization, the expected degree of confidence is decoded as a class probability. The stacking method [40] used in this work employs MLR proposed in [33] and differs from the conventional stacking introduced by Wolpert [41]. The traditional stacking utilizes all the class probabilities from the base learners, while the variant of stacking used in this work utilizes only the class probabilities that are of interest. In our case, the class in focus is the disruptions in the Tokamak. The change is relevant even for two-class problems. Since the sum of all class probability distribution equals one, from the probability of one class (disruption), the probability of the other class (normal) is easily calculated. Specifics of the output from the base and meta learners is described in section 3.2.3. The modified stacking helps in faster training due to the reduced dimensionality input to the meta classifier.
Algorithm for Stacking
Algorithm for Stacking
Figure 3 depicts a part of the generated REPTree, which mentions the split criterion for the attributes, entropy value, number of instances of an attribute at the nodes, the normal and disruptive class distribution.
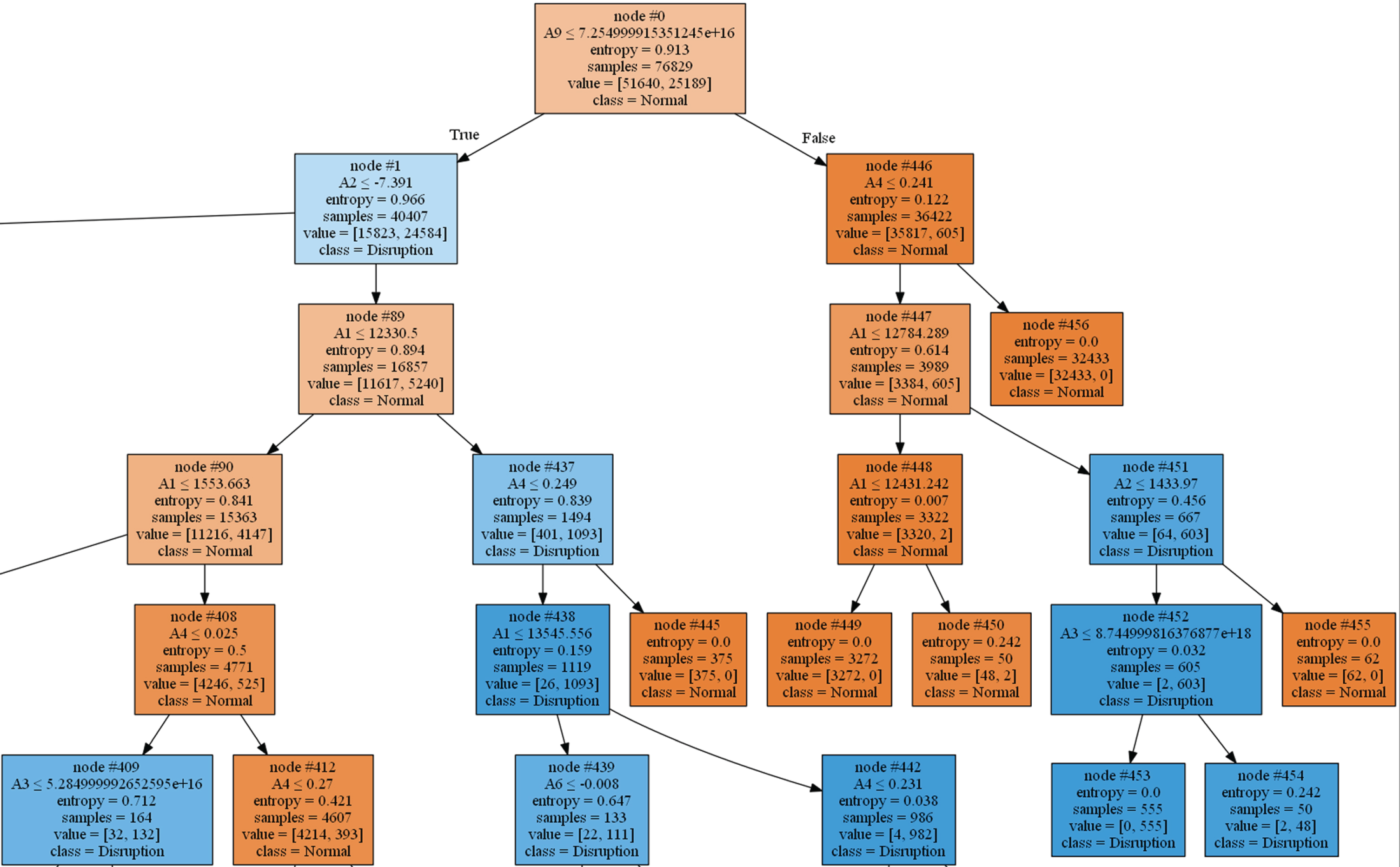
Part of Graphical Depiction of Tree in Stacking Ensemble Classifier.
The functioning of REPTree is the same as the C4.5 algorithm [42] in building a decision or regression tree, and they differ from C4.5 in the way pruning is done. Like C4.5, REPTree builds tree utilizing the information gain or variance reduction and handles the missing values by dividing instances into parts. REPTree algorithm sorts the numerical attributes only once. Other variable parameters are the minimum total weight of instances per leaf, maximum depth of the tree, and the size of folds used for pruning.
3.2.2.1. Gain criteria for tree generation. If X is the set of instances then the number of instances in X that belong to the class y
i
is denoted as freq (y
i
, X). The number of instances is represented by |X|. The probability of selecting one example from a set of X instances and declaring that it belongs to y
i
(classifromoutputy) is given by
The information to a class member is given by summing the classes in proportion to the frequencies as
After X is split to k subsets on attribute A, the expected information is the weighted sum over the subsets and is represented as
The information gained by partitioning X with attribute A is
As entropy increases, the information gain decreases and vice versa. The split occurs where the information gain is high, which is equivalent to a high reduction in entropy.
The gain criterion which helps classification is
If the split is trivial, split information is less, and the gain criterion is unstable, which is avoided by selecting attribute A to maximize the gain ratio whereas the information gain should be significant. Equation 3 can be written as
For binary classification, entropy is minimum when all the instances belong to the same class and maximum when either class is 50% or 0.5
If n
c
, d
c
and t
c
represent the normal, disruption and total count in the Golem dataset; the entropy is
The average information required to encode the class label for a random instance from the dataset is around 1 bit.
All the attributes in the Golem dataset are continuous. The steps to find the threshold t that maximize the splitting criterion are The instances in X are sorted according to their values as v1, v2, v3 … . vn
Each pair of adjacent values form a valid threshold vi + (vi + 1)/2 and a corresponding partition. The threshold with the best value of splitting criterion is chosen as the split point.
For an attribute say A1, the information gain is given as
Let us consider the split for attribute A1. Let the left and right split from attribute A1 be represented as L (node 90) and R (node 437). Each node indicates the distribution of the instances for normal and disruption class. The instances or count at node 90 is denoted as [n
lc
, d
lc
] and node 437 as [n
rc
, d
rc
]. The total count at node 90 is denoted as t
lc
and node 437 as t
rc
respectively. Let T
c
= t
lc
+ t
rc
. From Fig. 3,
As indicated in node 89 of Fig. 3, for attribute A1,
The entropy at node 90 (L) is calculated as
Similarly, the entropy at node 437 (R) is given by
Information after including attribute A1 is
From equation 8, info gain is
Table 3 lists the entropy calculation for six values of attribute A1 and their corresponding information gain.
Entropy and Information Gain for Attribute A1
The split occurs at attribute A1 for the value where the information gain in maximum (0.0529).
3.2.2.2. Pruning. Decision trees follow a greedy approach to generate the tree. The splits on the nodes continue until there is information gain, which leads to deep trees. Overfitting occurs due to the depth of trees resulting in weak performance on test data. The process of replacing subtrees with simpler subtrees or leaf nodes with little effect on classification accuracy is called pruning. The difference in the accuracy of the unpruned and pruned trees should be negligible. Pruning avoids complex model and overfitting.
The difference between C4.5 and REPTree algorithms is that C4.5 a pessimistic approach for pruning and REPTree utilize reduced error pruning. In REPTree, the training dataset is divided into two, namely growth and pruning dataset. The first tree is generated on the growth dataset. Pruning dataset is used to minimize the error from the growth tree by adopting the bottom-to-top approach. The growth and pruning datasets are re-split at each cycle of the algorithm. The splitting enables covering all instances of the training data by both the datasets. When the next split in the dataset is used, each parent examines the error of the child nodes. If the error of the parent node is greater than the child node, then the child nodes are removed. The challenge is using REPTree is that a large training data is needed for training, and the criteria should be different for creating the growth and pruning datasets. C4.5 algorithm before reduced error pruning produced 527 nodes and 264 leaves and after pruning generated 369 nodes and 185 leaves. There is a reduction of about 30% in the number of nodes and leaves after pruning.
3.2.2.3. Splitting and stopping criteria. For numerical attributes, binary splits are produced, and for categorical attributes, k - way splits are produced. The numerical attributes are sorted, and each value is considered as split points. The stopping criteria is a minimum of two children per leaf. Only splits where information gain values are better than average value is considered for a split to mitigate highly imbalanced data partitioning.
3.2.2.4. Computational complexity. For a tree with n instances and m attributes, the standard depth of the tree with n leaves is given by
With m attributes, at each tree depth, the whole set of n instances need to be taken into account. For log n depths within the tree, the volume of work for one attribute is
All the attributes are considered at each node, and hence the complexity of building the trees are O (mn log n). The numeric attributes must be sorted only once, and with an appropriate algorithm, the initial sort requires O (n log n) for each of the m attributes. For pruning, through subtree replacement, an error estimate at every tree node is made with the tree having a maximum of n leaves. For a binary tree, with a numeric attribute, there would be 2n - 1 nodes. The subtree replacement complexity is
Lastly, the complexity of subtree lifting must be considered. At worst, each instance is reclassified at every node, and it’s a two-step operation with one being performed at the root with O (log n) and one of average depth is
Combining all the operations, the total complexity of the C4.5 algorithm is
Linear regression is used to find the relationship between input and output and is widely applied in statistics and in machine learning is suitable only for regression problems. MLR is derived from the linear regression algorithm with least-squares. A dataset having real-values as attributes intended for classification can be adapted as an MLR task. y0, y1 are the individual classes for the classification task. If y0 or y1 equals zero in a classification task; the corresponding linear value in regression is also zero. Likewise, regression value is one the if y0 or y1 equals one.
Let J denote the dataset with
For the REPTree algorithm, let l
i
denote the number of instances from the training data with class i at leaf l. Let us assume i an i′ denote class 0 and 1 respectively, then by Laplace transform, probability of class i (0) is,
The probability of other class i′ (1) is,
If i denote the class, the probability of i
th
class output on training instances x of the base learners is given as P
ri
(x). In our case, i = 2 (0 and 1) and r = 1, 2, … R. When one class probability is produced, the likelihood of another class is easily derived. Hence, minority class (0) probabilities from all the base learners (R = 4) are denoted as
The final model with y0 as output is given by
Table 4 presents a comparison of the widely used machine learning algorithms along with ensemble classifiers like bagging, boosting, and voting for the GOLEM Tokamak. The investigation was conducted on the Tokamak dataset with training – testing split of 70%–30% thereby experimenting 132 for training and 55 for testing. In general, tree algorithms performed better than the probabilistic models such as Bayes Net and Naive Bayes. Among the ensemble models, voting registered the least score. CART as the decision tree gave the best result for both Bagging and Boosting (AdaBoostM1, Gradient Boosting) techniques. The performance of Random Forest decreased due to the recall metric.
Comparative results for different algorithms
Comparative results for different algorithms
The number of instances identified correctly.
Precision (P)
The ratio of correct disruptions to the total instances classified as disruptions by the model.
Recall (R)
The ratio of correct disruptions to instances that belong to the disruption class in the dataset.
F1 Score
Defines the trade-off between precision and recall through a harmonic mean of precision and recall.
False positive rate
The ratio of normal instances classified as disruptions to the total number of normal instances.
ROC and precision-recall curve
Figure 4 shows the ROC curve of the developed ensemble model for both normal and disruptive shots.
The trade-offs between False Positive Rate (X-axis) and True Positive Rate (Y-axis) summarizes the predictive performance of the ensemble learners. The ROC curve separates the error cost calculations from the performance of the ensemble learners and is invariable under dynamic class distributions.
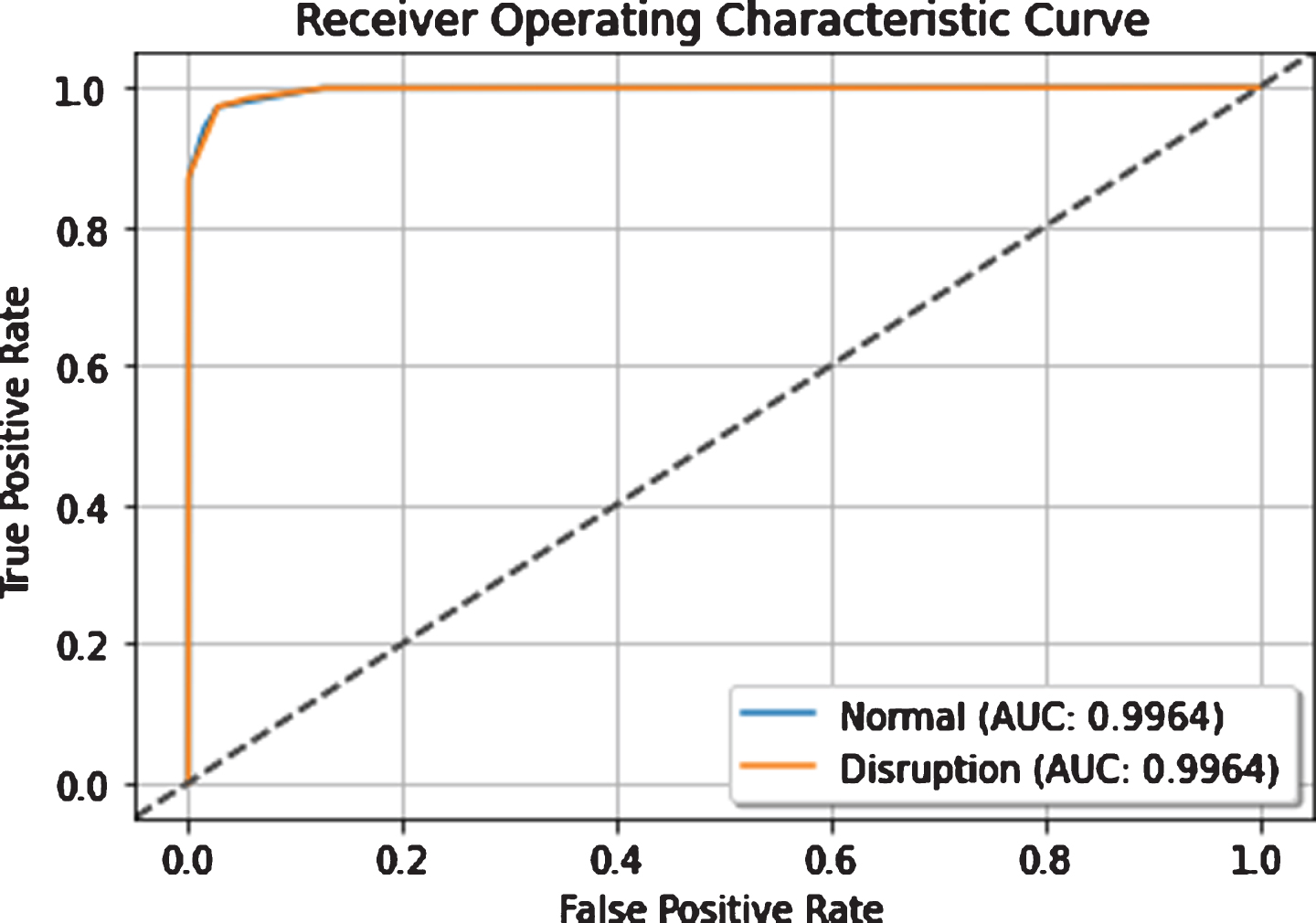
ROC curve of the stacking model.
Figure 5 shows the Precision-Recall (PR) curve for both normal and disruptive shots. PR is a useful diagnostic method for binary classification when the class distribution is imbalanced. It is a plot with Recall (X-axis) and Precision (Y-Axis).
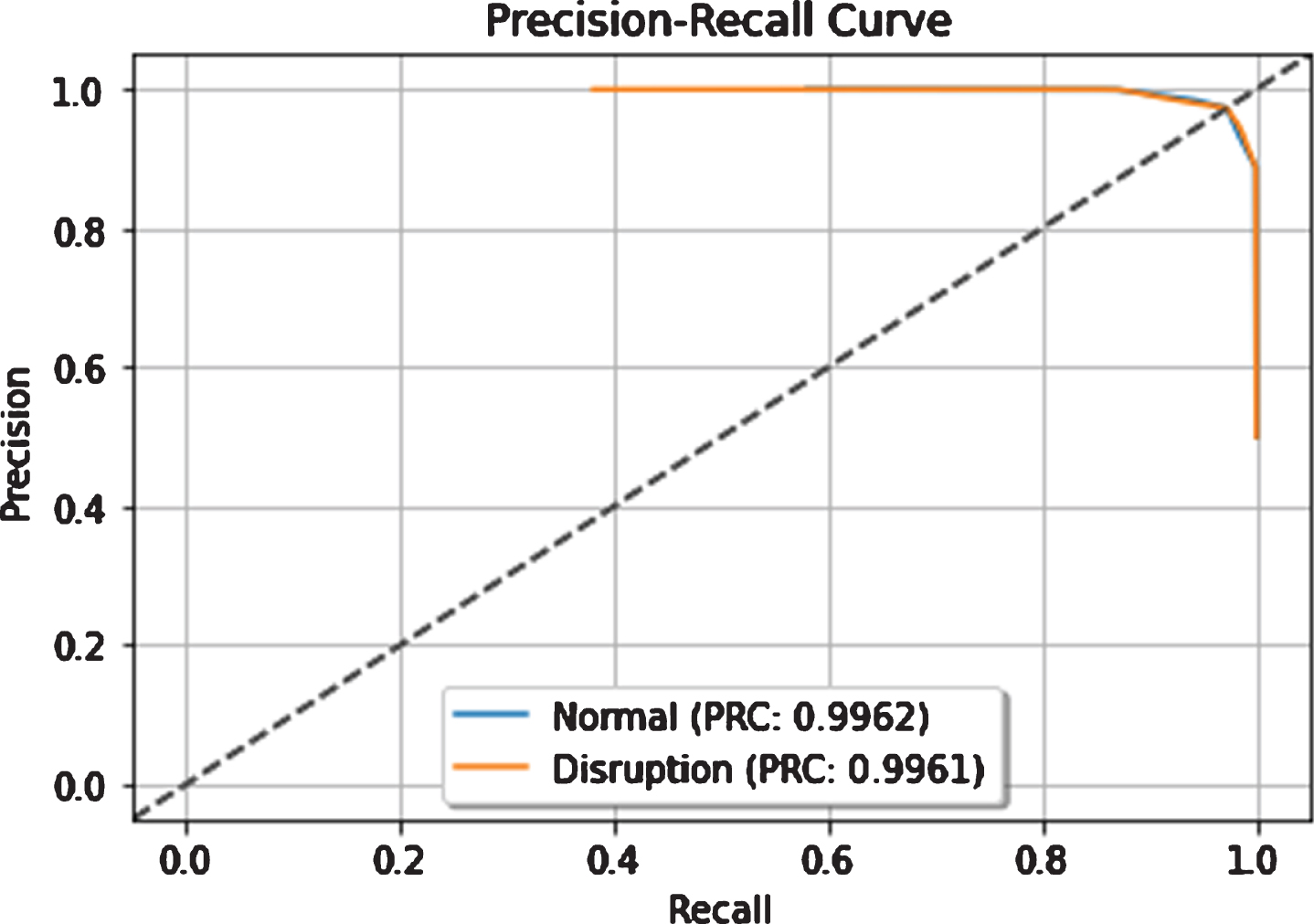
Precision-recall curve of the stacking model.
Disruptions in a Tokamak system must be detected at the earliest to avoid significant damage to the components and the vessel. There has been substantial literature in disruption prediction with machine learning and ensemble methods. Our implementation of stacking has reduced complexity and faster training than other ensemble methods. The short decision trees resulted in a reduction in tee size of about 33% from the regular trees both with nodes and leaves. Further, MLR, which is employed mainly in regression, is exercised as meta-learner for classification. The stability of our model is substantiated with its minor accuracy variation over its thirty iterations of train and test. A comparative study comprising decisive metrics executed over the standard train-test split of the dataset is demonstrated with often used algorithms. Stacking prevailed over other algorithms in terms of quantitative results. However, it must be noted that the stacking is implemented on the GOLEM Tokamak dataset. Performance of stacking might vary with other datasets and may not generalize to other applications.
Probable future works are a) experimenting a stacking ensemble classifier in a real-time environment and datasets from other domain b) to implement neural networks with more data c) operate on raw sensor data and provide an end-to-end solution through deep learning techniques d) exploring the transformation of the dataset to a time-series forecasting problem e) determining effective ways to give feedback to the plasma control system.