
Abstract
Industry has always been in the pursuit of becoming more economically efficient and the current focus has been to reduce human labour using modern technologies. Even with cutting edge technologies, which range from packaging robots to AI for fault detection, there is still some ambiguity on the aims of some new systems, namely, whether they are automated or autonomous. In this paper, we indicate the distinctions between automated and autonomous systems as well as review the current literature and identify the core challenges for creating learning mechanisms of autonomous agents. We discuss using different types of extended realities, such as digital twins, how to train reinforcement learning agents to learn specific tasks through generalisation. Once generalisation is achieved, we discuss how these can be used to develop self-learning agents. We then introduce self-play scenarios and how they can be used to teach self-learning agents through a supportive environment that focuses on how the agents can adapt to different environments. We introduce an initial prototype of our ideas by solving a multi-armed bandit problem using two ε-greedy algorithms. Further, we discuss future applications in the industrial management realm and propose a modular architecture for improving the decision-making process via autonomous agents.
Introduction
Recent industrial developments, such as Industry 4.0 [1, 2], self-operating cars, [3, 4] and maritime industry [5, 6], have highlighted a real problem: automated is not autonomous. Automated processes should not be mistaken with autonomous entities as the real world repercussions could be drastic. Some efforts have been made to define a truly autonomous system [7], unfortunately, there is still some confusion with the difference between automated and autonomous. This paper focuses on the learning mechanisms required for an entity to be autonomous, while at the same time, we are going to try and define the difference between automated and autonomous systems.
Automation has been linked to either increased industrial productivity, profits, or both. This has led to a never-ending pursuit to automate as much as possible. Modern types of automation rely on a mixture of hardware as well as software, which has led to the digitisation of many processes in and around all forms of industry, including processes for manufacturing, quality control, and management. Quite often, statistical modelling or neural networks can be used to evaluate the effectiveness of an automation process [8], before it is applied to real world scenarios. Such digital representations can be called extended reality, where it is a mixture of real life and the virtual world, for example, digital twins are an example of such technology [9].
Digital twin technology can follow the physical laws and allow an agent to interact with the virtual environment with as much realism as possible [10]. One of the advantages of digital twin technology is the ability to rapidly change the parameters and mimic the effects of real world changes, without the change physically happening. From this environment, we can simulate the complex effects of real world scenarios without the constraints associated with the real world events. This article focuses on using interactive-based learning and self-playing agents to improve or optimise scenarios in extended reality environments [11].
We have structured the article in the following way: Section 2 discusses the three core terms, which are key to this project: 1. Automated vs autonomous systems, 2. eXtended Reality (XR) and 3. Data augmentation. Section 3 focuses on reinforcement learning as a possible way to achieve interaction-based learning, and in Section 4 we define a conceptual architecture for a system to learn by combining autonomous systems, self-play, and XR environments. Section 5 proposes a conceptual design and explores an initial prototype. Finally, we conclude our findings and present the future direction for our research.
Research methods and concepts
Below we present a literature review of the core concepts, which will reveal some of the inherent problems with current methods and set the foundation for our proposed solution. We follow a soft systems methodology (SSM) by framing a problem formulation (model learning) and an action plan (conceptual model for learning) aimed at future research [12]. In [13] the authors state that SSM consists of an analysis of the current status of the system. This includes inherent problems and activities, and a definition of the system that derives the actual goal of the targeted system (root definition) in order to propose a conceptual system model.
Requirements for autonomous systems
Researchers have tried to define what it means for a system to be autonomous since the 1950s [7, 15]. Despite their efforts, we often find their definitions more suitable for automated, rather than autonomous, as solutions lack the flexibility to adapt to new behaviours and implementations have tended to cover relatively narrow, software localised areas. We believe that an autonomous system should have the freedom to govern itself, which includes some form of understanding of repercussions for one’s actions. Independence within an environment is also a notion that should be associated with an autonomous entity, and a mere exploitation of historical data is not sufficient. We suggest that an entity whose intelligence is derived from a rule-set or a neural network trained on historical data, will likely fail a test of true autonomy.
A similar standpoint has been taken by organisations regulating and standardising the automotive industry [16]. The Society of Automotive Engineers (SAE) through the On-Road Automated Vehicle Standards Committee is responsible for defining levels of driving automation for cars and provides a classification of levels from 0-5. In the SAE classification, the highest level, "Level 5 (steering wheel optional)" is defined as a fully automated system, and not as an autonomous system [17].
There have been several methods proposed for creating agents, e.g. fuzzy logic or neural networks. In [18] the authors use the concept of intelligent agents for describing an important property of the entity. Intelligence or rather reasoning, allows an agent to react to different defined circumstances or even unforeseen circumstances. Some early considerations realised the challenge of defining a globally validated view of a contained entity, with so called artificial intelligence. Instead, they highlighted that at the essence of an intelligent entity is an ability to perform subjective probability analysis over both logical and natural (physical) conditions, [19] and [18] approach this through an expert system governed by fuzzy logic and highlight certain abilities an agent must achieve to be considered intelligent. For example, an agent must be able to plan a set of actions and needs to adapt its plan to changing conditions. [7] provide a classification of properties an agent may have.
Following emerging concepts such as cortical conductor theory that specify some design requirements for consciousness [20], we can break down an autonomous system into four core concepts: learning, reasoning, control, and selection [21]. This paper focuses primarily on the learning mechanisms which occur from the interactions and from observing the environment, while also describing some industrial environments where interactive learning can occur. Our position is that without an interactive learning mechanism and an ability to self-improve, a system cannot be considered autonomous, although there are more criteria which also need to be fulfilled.
Extended reality
The term eXtended Reality (XR) has become known as a common term for fields where digitally enhanced environments and human-interaction are combined for various purposes. This includes Virtual Reality (VR), Mixed Reality (MR), and Augmented Reality (AR). Compared to, for example, autonomous driving, these environments may offer AI researchers an important and relatively low-cost setting for implementing human-interacting algorithms. Perhaps most importantly, these digital environments allow us to study an agent’s decision making while altering the environment to simulate certain changes. Thereby, offering a feed-back loop between the agent-environment-user, while also allowing discovery of randomness (untrained behaviour) in the agent’s decision making.
To collect data, the traditional approach was often to gather the data from users, e.g. while they are playing a game, and then train on this data. Today, the deep networks’ need for massive data combined with relatively complex training scenarios for reinforcement learning, presents researchers with a problem that is often better solved by augmenting additional data, than using real data for training the networks. Data augmentation methods depend on the problem at hand, an agent may for example have to learn how to deal with object recognition, spatial actions to take in relation to detected objects, or temporal differences in scenarios, to name a few. The following sub-section reviews some of the relevant literature regarding the performance of data augmentation for training agents.
Data augmentation
Data augmentation has gained prominence as a studied method for extending available datasets [22]. The ability to train deep networks often depends on the availability of big data. The fields of both image recognition and voice recognition have been strongly influenced by deep learning methods [23, 24], and this has motivated the emergence of data augmentation. For Reinforcement Learning (RL) many of the same concepts can be utilised, but there is also a need for methods that work particularly in the temporal dimension.
Traditional naïve approaches tend to manipulate the investigated environment or dataset in various ways. For visual tasks, these have included scaling of objects, translating i.e. moving objects spatially to various positions, rotation of objects at various angles, flipping objects as to remove bias from any direction, adding noise, changing lightning conditions, and transforming perspective of a known object by changing the angle of view [22, 25].
For audio tasks, data augmentation often includes deformations into a temporal dimension. Approaches include time stretching by changing audio speed, pitch shifting by raising or lowering the tone frequency by various degrees, dynamic range compression, and introducing background noise using Gaussian or natural noise methods [26].
The naïve date augmentation approaches tend to produce limited alternative data for RL agents to learn from an extended reality setting. For an RL agent to learn new abilities, data augmentation must support the agent’s scenario learning process. As suggested by [27], we shift from learning to generalise on spatial data to reacting to continuous-time dynamical systems without a-priori discretisation of time, state, and action.
Several approaches exist for the creation of these scenarios. An important method is adversarial learning, as it can produce new and complex augmented datasets by pitting a generative model against an adversary [28]. A generative model in combination with XR, can also address the exploration problem, as exploring some states in the physical reality could be very costly and dangerous. This combination also allows the system developer to understand which state spaces in the virtual environment has been visited and trained upon, and the model’s ability to generalise in the extended reality environment. These generative techniques for extending the learning environment are further explored in the following section.
Reinforcement learning
Although XR is slowly receiving more recognition, AI and machine learning’s use of XR to enhance learning is lagging behind. XR could help improve an AI’s behaviour by providing information from either pure virtual or semi-real environments. Reinforcement learning is a machine learning technique which, when combined with XR, could produce interesting and beneficial results for many applications, such as driverless cars, autonomous factories, smart cities, gaming and more.
RL’s primary purpose is to calculate the best action an agent should take when an environment is provided. With RL, we could be able to calculate what best action to take by maximising the cumulative reward from previous actions, thus learning a policy. RL has long roots from areas such as dynamical programming [29], for a historical review see [30]. However, recently it has received a lot of attention for its potential to advance and improve applications in gaming, robotics, natural language processing (including dialogue systems, machine translation, and text generation), computer vision, neural architecture design, business management, finance, healthcare, intelligent transportation systems, and other computer systems [31].
Attention and memory are two parts of RL which, if done impetuously, could negatively affect performance. Attention is the mechanism that focuses on the salient parts. Whereas memory provides long term data storage, and attention is an approach for memory addressing [31]. By using XR and self-play, agents may be able to learn desired behaviour before an action becomes crucial to their performance. As an example, autonomous helicopter software could learn fundamental mechanisms for flight using virtual data in simulations in order to achieve high level of attention using the memory required, without the risks posed by real world applications. Once the attention has reached a desired level, it can be applied to real agents in the physical world.
General value functions can be used to represent knowledge. RL, arguably, mimics knowledge in the sense that it (generally) learns from the results of actions taken. Thus, one may be able to represent knowledge with general value functions using policies, termination functions, reward functions, and terminal reward functions as parameters [32]. Doing so, an agent may be able to predict the values of sensors, and policies to maximise those sensor values, and answer predictive or goal-oriented questions.
Generative Adversarial Networks (GANs) estimate generative models via an adversarial process by training two models simultaneously [28], a generative model G to capture the data distribution, and a discriminative model D to estimate the probability that a sample comes from the training data but not the generative model G. Such an approach could be extended to XR by training a generative model G on virtual / simulated test data and then a discriminative model D to estimate the probability that a sample comes from the real world. This could help tackle some of the issues with RL within virtual environments and then be extended to the real world. RL and XR could be used before the agent is applied to a real environment, this could save on resources and make autonomous systems a more viable option for general use.
GANs together with transfer learning could advance self-play using virtual environments for real world agents [33]. By combining virtual data, generative models, and transferring the learning model to a discriminative model, we may be able to accurately express what was learned from the virtual learning environment to the real agent. Again, unforeseen problems will inevitably arise due to the nature of modelling. By using RL both in the virtual learning phase and embedded into the real agent, we may drastically improve a real agent’s learning time. Adaptive learning is considered a core characteristic for achieving strong AI [34]. Several adaptive learning methods have been proposed which utilise prior knowledge [31, 36]. [35] proposed to represent a particular optimisation algorithm as a policy, and convergence rate as reward. [31, 36] proposed a flexible recurrent neural network (RNN) model to learn to handle a family of RL tasks, improve sample efficiency, learn new tasks with a few samples, and benefit from prior knowledge.
The notion of self-play is one of the biggest advancements of modern AI. AlphaGo is Deepmind’s Go playing AI [37], that learns, tabula rasa, superhuman proficiency in a challenging domain. Starting with the basic rules, they used self-play for the AI to learn strategies by playing against itself and storing efficient / rewarding moves. Fictitious Self-Play is a machine learning framework that implements fictitious play in a sample-based fashion [38]. The three strategies that are compared are: learning by self-play, learning from playing against a fixed opponent, and learning from playing against a fixed opponent while learning from the opponent’s moves as well [39].
Self-play scenarios and architectures
Generalising from training into real scenarios is not easy for self learning agents. This problem is known as the reality gap [40]. In the initial stages of AI research, the training of self-learning agents included rules or limited scenarios where they can learn and improve upon competition against other players. Interestingly, video games have emerged as one of the main source of benchmark environments for the training and testing of such agents, mostly due to its realistic, yet controlled approach to the real world, and the easy access to large amounts of data. For example, an AI agent is trained by playing with a perfect copy of itself without any supervision [41]. In this scenario, a set of basic rules of the game have been introduced at the beginning and the agent improves much faster using a vector of rewards instead of the classical scalar quantity [42].
Initially, self-playing agents were trained to play board games (such as chess and GO, among others) [37] but since then, this method has been successfully extended from the classic and simpler Atari 2600 video games [43] to more complex first-person shooters; Role Playing games, including the Massively Multiplayer Online type of games: Warcraft [44]; Real-Time Strategic Games: Starcraft [45] and more recently Multiplayer Online Battle Arena (Dota 2, [46]). For a more comprehensive review see the work by [47].
Motivation for studying self-play scenarios has increased in recent years mainly due to the advances in neural network architectures suitable to the reinforcement learning paradigm: DQN [43], AC3 [48], DSR [49], dueling networks[50], among others, as well as the development of powerful and accessible graphics processing unit (GPU) computing resources. This area of research is broadly known as Deep Reinforcement Learning [31, 52].
The challenge of training self-playing agents in order to develop more complex policies inside realistic and highly specific or general environments remain as an open problem. Most of the recent developments tend to focus on very particular properties of the learning agent or the way that they interact with their surroundings. To address this issue, we have identified two general mechanisms that can be improved in order to design a better self-learning agent: self-play scenarios and self-learning architectures.
Improving self-play scenarios and self-learning agents. Closing the reality gap
Constructing realistic self-play scenarios plays a fundamental role in training self-learning agents. Once an agent is immersed in a specific environment, we expect (independently of the self-learning architecture) that it will learn a set of policies accordingly to the received experiences 1 . A problem which is widely understood, is that when agents learn from strict simulated scenarios, they may not be prepared for unexpected situations when the environment changes, such as a pigeon flying towards the sensor of a driverless car. Here, we propose a general scheme that uses the versatility of video games or simulators as a source of synthetic data and the wide array of capabilities of modern extended reality technologies, to enrich the properties of the real environment during the training of self-learning agents. An agent may learn independently, but the environment can be controlled to persuade the agent to learn a set of additional policies for unexpected scenarios. In addition to the enriched data, the self-learning agent may be trained using purely synthetic data. But the limitations of this method rely in the accuracy of the representation of the real scenarios.
For the self-learning mechanism, we have identified three key steps which could improve the design of architectures for self-learning agents, which in turn may improve policies both in terms of effectiveness and robustness. The three areas are: data collection, task generalisation and emergent behaviour (see Fig. 1). For a given agent, in the first stage the agent will need to interact with the environment, possibly by accessing a data collection, then the agent should be able to generalise a set of given tasks and, simultaneously, new skills should emerge (independently or due to the task generalisation). In the final stage, the emergent and the generalisation skills interact with the environment to create a continuous self-learning agent.
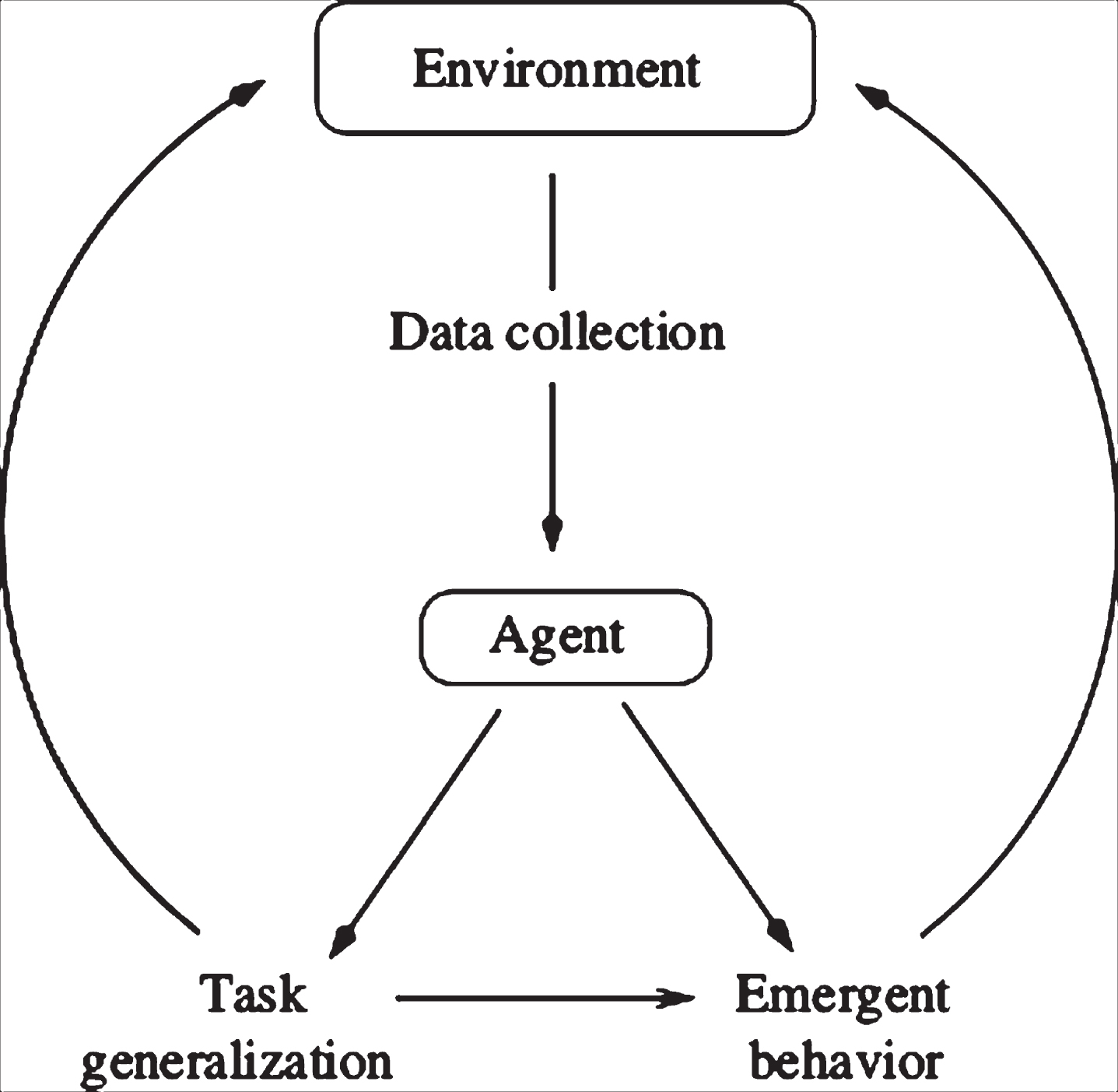
Proposed general architecture for a self-learning agent interacting with its environment.
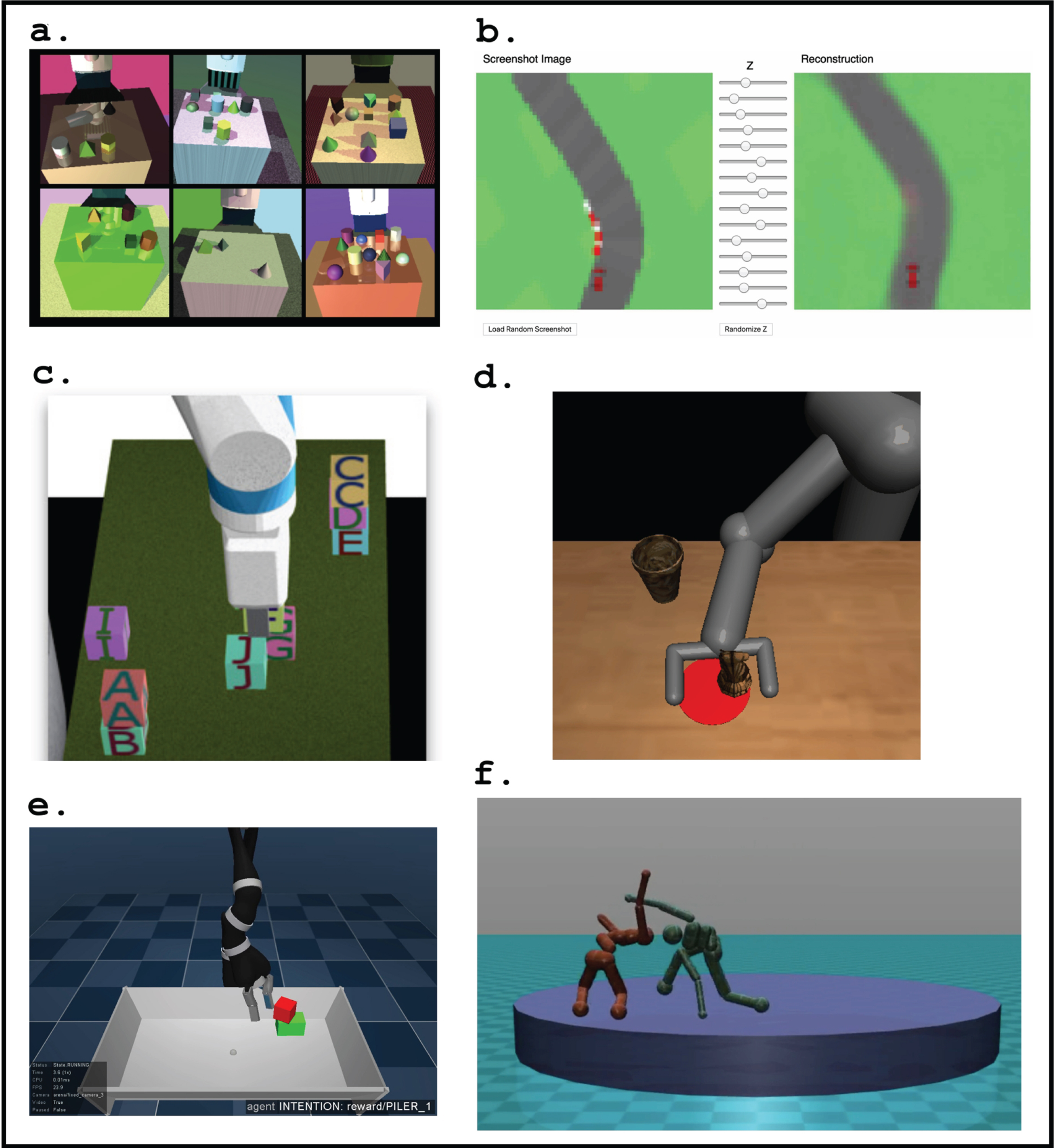
To illustrate the steps, we present a set of representative developments in the area of (deep) reinforcement learning. Note that this list is not comprehensive, but the examples are presented to highlight their specific properties that we then introduce for our general model (see Fig. 2). Each can be used as a building block inside a complete self-play scenario, for example, Fig. 2a shows low-fidelity rendered images with random camera positions, lighting conditions, object positions, and non-realistic textures that are used to train a self-learning agent [53]; Fig. 2b shows an agent which uses a compressed representation of a real scenario to learn a set of policies which are then successfully transferred back to the real environment [54]. Fig. 2c shows an image of a robot used as a one-shot imitation example during the training stage [55]. Fig. 2d shows another image of a robot used during a training stage to teach a robot to place an object in a target position [56], Fig. 2e depicts an agent stacking two blocks, behaviour learnt from sparse rewards [57] and Fig. 2f illustrates one competitive environment where one of the agents develops a new set of skills [58]. Data collection: Domain randomisation (DR): DeepMind has recently shown how an agent can be trained on artificially generated scenarios. In their paper [53], the authors successfully transferred the knowledge from a neural network purely trained on low resolution rendered RGB images: domain randomisation. This method can be extensively used for training agents in the case that the amount of data available is low or when the separation between the real and the training environment is immense. World models (WM): Self-learning agents can be trained in a compressed spatial and temporal representation of real environments [54]. This method is highly powerful because an agent can learn in a more compact or hallucinated universe and then go back to the original environment exporting the set of learned abilities. One of the main advantages of this method is the possibility to perform a much faster and accurate in situ training of the agents by using less demanding computational resources. Task generalisation: One-shot imitation learning (OSIL): the authors present an improved method that uses a meta-learning framework built upon the soft attention model [59] named one-shot imitation learning [55]. Here, the agents are able to learn a new policy and solve a task after being exposed to a few demonstrations during the training stage. One-shot visual imitation learning (OSVIL): Meta-imitation learning algorithm that teaches an agent to learn how to learn efficiently [56]. In this work, a robot reuses past experiences and then upon a single demonstration develops new skills. Emergent behaviour: Scheduled auxiliary control (SAC): another research team from DeepMind introduced a new framework that allows agents to learn new and complex behaviours in presence of a stream of sparse rewards [57]. Multiagent competition (MAC): in a paper by a research team from OpenAI, the authors showed that multiagents that self-play on complex environments can produce behaviours which can be more complex than the environment itself [58]. The emergent skills can improve the capabilities of the agents upon unexpected changes in the real environment.
To summarise, Fig. 1 illustrates how an agent retrieves data from an environment and then generalises to a specific task and simultaneously develops new abilities. The new skills can emerge independently or due to the task generalisation process. In the final stage, the environment gets modified by the agent itself. A combination of such methods could be used to create more effective architectures for teaching self-learning agents. The novelty of this idea is that it builds upon the concept of modularity to create more complex architectures which develop new untrained behaviours. This notion has been explored before to improve learning agents, for instance by synergistically combining two modelling methods such as type-based reasoning and policy reconstruction [60]. Interestingly, it has been stated recently that this is still a promising area under research [61]. In addition, the proposed architecture establishes a general framework for the design of intelligent agents or rational agents searching to maximise their reward upon interaction with an external environment [62] via specific goals (task generalisation and emergent behaviour). Once an architecture is defined, targeting the most adequate general policies are dependent on the external information gathered by the agent. In the data collection module, the main goal is to optimise the data used by the agent for learning. In the general case however, a proper design should include a non-static complete representation of the environment for exploring extensively all possible scenarios.
In the next section, we present a complete general design for a self-learning agent including an extra module for extending the description of the world experienced by the agent and then, upon an ad-hoc division and by using the concept of multiagent [63]. We discuss the design of a central autonomous agent able to provide via rational decision-making strategies to tackle the possible consequences derived from changes on any stage of a specific industrial infrastructure.
As already discussed, our goal of designing general self-play scenarios for teaching self-learning agents may be tackled by separating the data retrieved from the environment and the agent’s self-learning architecture. In this spirit, we present a general scheme in which we divide the general architecture into two modules. In Module 1, the agent retrieves the data from its surroundings as a combination of information from the real world and synthetic data (or pure synthetic data), and in Module 2 (equivalent to the structure of the Fig 2), the agent creates its final policies. The general scheme is depicted in the Fig 3.

Two module design of a general architecture for a self-learning agent interacting with its enriched or altered environment.
For a self-learning agent inside a specific self-play scenario, there is no difference between synthetic or real data. Here we consider real data to be the information extracted from the physical world without any previous or further digital modifications. The agent uses the information exclusively, in terms of raw bytes, independently of the sensors that connect it with the environment. The use of synthetic data arises from the need to expose the self-learning agent to unexpected situations or conditions that allow it to create a set of related policies. Sub-section 5.1 presents an initial modular prototype that exploit the occurrence of random perturbations as a way to detect when new policies are needed.
For our long-term general design goal, the representation of the real world can also be done via pure synthetic data, however the best case scenario is such where the synthetic data is used to extend the real world. The agent can also modify its own environment during the learning process, and if the whole process is fully done in a simulation environment, the use of digital twins that mimic the physical rules of the real world become necessary. The proposed general design can be encapsulated and used as a basic element in a more complex multiagent based learning architecture [63]. The communication among its moieties can be performed via the local information modules that represent their individual real worlds. Posteriorly, a central agent retrieves and updates its state providing a final decision. Several mathematical strategies can be applied to interchange the information, for instance, by defining scalar, vectorial or probabilistic representations.
In the next part we present a partial prototype using multi-armed bandits and provide a conceptual example of how to move forward and build a minimal supra-modular architecture for the specific case of industrial management. We discuss the advantages and the characteristics for the modular parts of the design, as well as review (not exhaustively), the state-of-the-art developments for learning agents in decision making.
Here we present an initial prototype which partly use our proposed architecture for identifying when new policies should be learned. Our benchmark solves a multi-armed bandit problem using the ε-greedy algorithm [42] (as a generalisation tasker). We implemented two Bernoulli-distributed bandits with assigned probabilities p1 and p2. We trained our ε-greedy model with a static ε value. The module that contains the emergent behaviour system is a similar ε-greedy with an ε initialised with a constant value, then we induced a regular dynamic behaviour by changing its value by taking a new one from a normal distribution centred at its initial value, with certain time periodicity.
The results of our prototype are depicted in the Fig. 4. Here the blue line (static) shows the result of the greedy algorithm with static ε. As expected, the line shows a constant behaviour in the normalised reward after a certain amount of steps. We have induced a new random change, by changing one of the probabilities of the bandits from p → p′. In the orange line (dynamic) we see how the agent reacts to the sudden change by reducing its total reward, but then continues to explore and finally recovers after several thousands of steps. In the other result, plotted in the green line (dynamic+random), we modified the greedy algorithm with a random change in the value of ε. This modified agent perceives the changes in the reward and changes ε accordingly, if the reward changes below the value of the static ε at a step i, then it uses the max(ε i , εi-1). If the change does not improve the reward with respect to the agent with the static ε, then in the next step, the modified agent uses min(ε i , εi+1). Inserted at the bottom right of the Fig. 4, we have in log scale the change in the epsilon at each step. Our prototype shows clearly the advantages of having two agents, one for task generalisation (static ε-greedy) and the other for emergent behaviour (dynamic ε-greedy). The synergy between the two agents makes the learning process faster.

Results from the ε-greedy algorithms. The solution to two unperturbed Bernoulli-distributed bandits is shown in the blue line. Upon a random perturbation, the dynamic system with the same ε is presented in orange. The solution using two connected ε-greedy algorithms is shown in green.
The aforementioned improvements can be employed in specific applications using specific designs. In particular, by using the new and open simulation frameworks such as OpenAI Gym 2 or Dopamine 3 among others. Here we discuss a particular application for industrial environments solving a managerial problem, however the developed ideas can be used for other purposes.
In the industrial regime, decision-making is one of the key elements of the adaptive business intelligence discipline [64, 65]. Despite the advances in the computational tools, still many relevant decisions are taken by real persons. Here, we propose a general model where self-learning agents can be trained to make decisions by themselves on industrial scale via self-play using extended reality training scenarios. We devised a strategy where an industrial infrastructure is divided ad-hoc in three independent sections managed by three independent self-learning agents (see Fig. 5). Each agent replicates the physical process but it has the property to explore (and improve) in its own learning space based in the perturbation via self-learning mechanisms. Upon external perturbations in their environments, the final decision is done by a central agent which learns thanks to the information gathered for the independent agents. This multiagent Reinforcement Learning (MARL) structure will bring a modularity structure that can be exploited in the industrial realm to improve and optimise the decision-making processes. Our example focuses mainly in the type of manufacturing industry, but the methodology can be extended easily to other industrial fields. Similar conceptual frameworks have been presented and described in the literature [66, 67] and in some cases including full computational frameworks or software applied on specific industrial environments [68, 69] were described. The niche of industrial management is a fruitful source of academic research with the application of the cutting-edge methods for the design of intelligent systems. For instance, in a recent work [70] a Deep Reinforcement Learning algorithm was used for inventory optimisation using as benchmark the famous beer distribution game [71]. This work shows the importance of using intelligent agents to optimise industrial processes 4 . The proposed division in three different entities: Supply Chain Management (SCM), Warehouse or Inventory Management and Digital Twin responds to the fact that a lot of work on modelling and creation of autonomous agents has been done in the last years independently in each area, therefore a low level description of an autonomous agent for industrial management is possible by following our proposed architecture (see Fig. 3). In the next subsection we present a non exhaustive review of methods by highlighting some of the relevant strategies employed in the creation of autonomous systems.
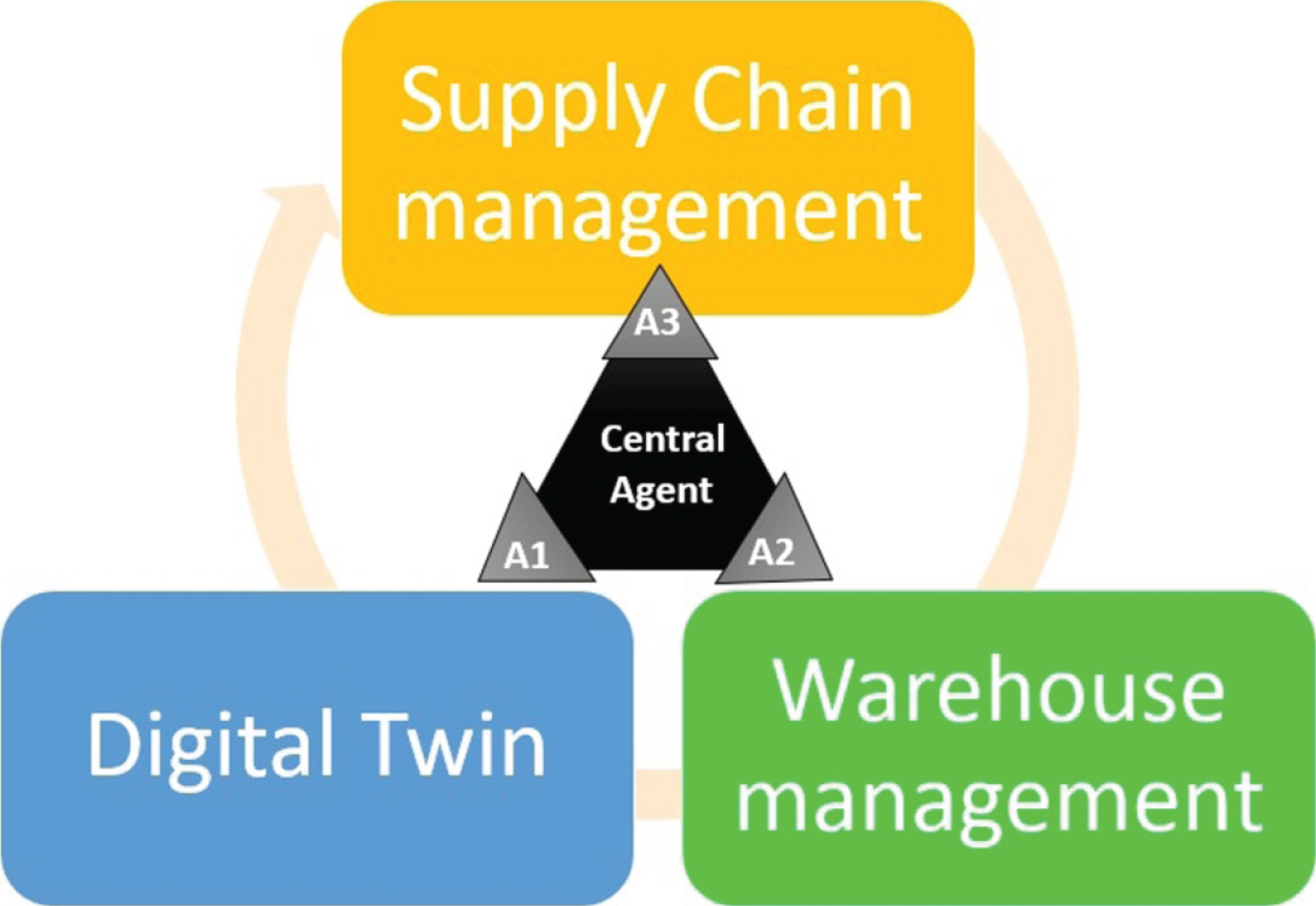
Proposed architecture for a reinforcement learning agent in Autonomous Industrial Management (AIM) for adaptive industrial infrastructure.
The use of RL for optimisation in SCM has been discussed largely recently [72], in particular, multiagent systems for the optimisation of tasks in the SCM [73], that solves the multiagent problem as a semi-Markov decision problem [74], that reduces the complexity by dividing the agents into three components (in a similar concept presented in this work), among others. Here, the self-learning agent must be able to decide about the different suppliers (external and internal) in coordination with the warehouse manager agent.
Warehouse or Inventory Management
Models for warehouse management have been developed in parallel to the state-of-the-art technological developments to achieve short and optimised responses in delivering goods meanwhile an optimal stock level is maintained [75]. In particular, it is worth to highlight two types of warehousing systems: automatic and automated warehousing systems. Several methods for self-learning agents in warehouses have shown to be effective in solving real problems, for instance, Stochastic Learning [76], temporal difference Actor-Critic algorithm [77] or more recently Deep Reinforcement Learning [78]. In general, the information can be controlled and retrieved via an optimised wireless network of sensors inside the warehouse [79]. In this case, the self-learning agent must be able not only to gather the internal information about the location of the goods inside the warehouse but also optimise the architecture of the network via self-play mechanisms.
Digital Twin
The use of digital tools in industry has outgrown the level in which only individual applications were able to be modelled accurately for very specific topics in the sixties, towards a complete simulation of the system during the whole entire life cycle in modern times [80]. The concept that includes a detailed model and description of a product, system or component in all its possible phases (product design, production system engineering, production planning, production execution, production intelligence and closed-loop optimisation) is known as digital twin[81, 82]. In general terms, the digital twin is an extension of the model-based systems engineering (MBSE) concept [83]. A company providing a physics-based digital twin software for industrial processes and tooling is Mevea [84].
Conclusion & future work
The design of self-learning and self-play scenarios is an area of fruitful development and research. Many critics have pointed out that AI research is limited by its own ideas [85] as well as its usefulness for industrial purposes. The creation and discussion of general architectures can open the door to new proposals, in particular, for the final emergence of the expected autonomous systems (see Section 2.1). Despite a boom in the field during the last years, there are many open questions about how to enable self-learning agents to achieve specific tasks without any supervision. We propose to tackle this question by using our general architecture, which can be, in principle, limited by the modular developments and the availability of specific datasets or sensors.
In this work we grounded our position in autonomous systems by providing a definition of requirements and presented a general review of the relevant literature. We provided a proposal for a design of a general architecture for self-learning agents. Our design included two separate modules, one for the creation of the data and the second for the independent self-learning of an agent. We conclude by stating that the second module is, in general, divided into three stages, where each stage is in charge of accomplishing an independent task: data collection, task generalisation and emergent behaviour. In very particular designs, generalisation can influence emergent behaviours, but only in one direction. For testing our approach, we present an initial prototype in which we implemented a basic version of the proposed design. Here, a double Bernoulli-distributed multi-armed bandit is solved using two ε-greedy algorithms, one uses a static ε value, and the second includes a ε that changes randomly in time. Upon perturbation, the combination of both algorithms solves the bandits more efficiently than using the initial static model. We expanded our findings by presenting a concrete example of our ideas in the industrial manufacturing sector. Here we suggest a division in three modular elements that feed a central agent for decision-making. Each module is able to explore and learn from all possible scenarios and available data, taking into account changes or disruptions in its own infrastructure and the information provided by the other modules. Future research goals of this project include an extension of our model to tackle more complex scenarios and reinforcement learning algorithms. Our focus will be to build upon benchmark problems and then expand to industrial cases (e.g. complex supply chain structures).