
Abstract
With the deepening of people’s research on event anaphora, a large number of methods will be used in the identification and resolution of event anaphora. Although there has been some progress in the resolution of the current event, the difficult problems have not yet been completely resolved. This study analyzes the English information anaphora resolution based on SVM and machine learning algorithms and uses the CNN three-layer network as the basis to model the structure. Moreover, this study improves the semantic features by adding semantic roles and analyzes and compares the performance of the improved semantic features with those before the improvement. In addition, this study combines semantic features to compare and analyze each feature combination and uses a dual candidate model to improve the system. Finally, this study analyzes the experimental results. The results show that the performance of the system using the dual candidate model is better than that of the single candidate model system.
Introduction
With the rapid development of computer technology and the Internet, the informatization of society has developed to a whole new stage. The transmission and exchange of information has become an important foundation for the operation of modern social life, and all kinds of information are exploding. While enjoying the convenience provided by massive amounts of information, people are also faced with the dilemma of finding the content they need from the vast amount of Some technologies that integrate the achievements of natural language processing, such as information retrieval, information extraction, text classification, automatic summarization, machine translation, and multilingual information processing systems, meet people’s need for accurate positioning of information from different angles, which greatly facilitates users who are tired of massive information. However, people find that these systems still cannot really understand and meet the needs of users, so they must improve the level of natural language processing technology from all aspects [1]. Natural language is an interdisciplinary subject, which involves linguistics, mathematics and computer science and spans three major knowledge areas of liberal arts, science and engineering. In the information society, the knowledge level of language information processing and the total amount of information processed each year have become one of the important indicators to measure the modernization level of a country [2]. Natural language provides people with a rich means of expressing thoughts, and different people have different expression habits. When describing the same definite thing, different people have different expressions. Even for the same article, different people have different understanding of the article. It is very difficult for computers to deal with natural articles that humans can understand. How to make machines understand natural language is a huge challenge for researchers of natural language processing. One of the challenges is how to deal with anaphora. Anaphora is a common linguistic phenomenon in natural language, which refers to the use of a pronoun in a text to refer to a previously spoken language unit. The common expressions of anaphora s include abbreviations, proper nouns, pronouns and other language phenomena. This phenomenon is often carried out throughout the article and widely exists in various expressions of natural language. No matter from the discussion of the law of language itself or from the perspective of application, anaphora resolution is a problem that linguists and computational linguists cannot ignore. Anaphora digestion plays a very important role in many areas of NLP (Nature Language Process). In fact, a fascinating article must use multiple expressions to represent the same entity. However, for natural language processing systems, this undoubtedly greatly increases the difficulty of processing. With the development of other related work of natural language, anaphora dissolution has become the bottleneck of natural language processing [3].
In the field of computational linguistics, anaphora resolution also shows unprecedented importance. Anaphora resolution is an indispensable part of text understanding in natural language processing. Moreover, anaphora resolution is involved in many applications such as text summarization, machine translation (Machine Translation), multilingual information processing, and information extraction.
Related work
The method based on syntactic knowledge makes full use of syntactic knowledge, and it is applied to anaphora resolution in a heuristic way. The literature [4] proposed a RAP algorithm that uses McCord’s Slot Grammar to obtain the syntactic structure of the document and calculates the saliency of each antecedent candidate by manually weighting various language features (such as subject and object). Moreover, the algorithm uses filtering rules to determine the antecedent, and achieves the elimination of third-person pronouns and reflexive pronouns within and between sentences. The literature [5] modified and expanded the RAP algorithm to avoid building a complete parse tree and preprocessed with natural language processing tools to obtain shallow information such as part-of-speech tagging and syntactic function tagging to determine the antecedent. The literature [6] quantified different language features on the basis of part-of-speech tagging and used the method of calculating weights to complete the ranking of possible candidates, so as to select antecedents and solve the pronoun resolution. However, the language features in the above work are manually weighted. In order to realize the automation of language feature weighting, the literature [6] improved the RAP algorithm and explored the use of the maximum entropy model to automatically determine the weight of various language features.
With the continuous emergence of annotated corpora and the rapid development of the Internet, it is becoming more and more convenient to obtain experimental corpora. Recently, most researches on anaphora digestion tend to be based on corpus-based anaphora digestion methods. The specific methods can be roughly divided into the following three categories: 1) Rule-based methods: The literature [7] used the center theory to first classify the antecedent candidates according to the difference between the foresight or the foresight center, and then used various center acquisition algorithms to select the antecedent. As a rule-based system representing the current international advanced level, literature [8] proposed a multi-agent strategy based on restriction rules, which has achieved considerable success. The system results in the MUC.6 test corpus have a recall rate of 65.8%, an accuracy rate of 84.7%, and an F value of 73.9%. The system results in MUC.7 have a recall rate of 55.7%, an accuracy rate of 82.8% and an F value of 66.5%.2) Statistical-based methods: The literature [9] gives priority to those antecedents that have higher co-occurrence antecedent candidates as pronouns, and conducts research on the dissection of the pronoun “it”. Literature [10] proposed a method based on Bayesian probability statistical model to resolve the third person singular pronouns in the text. The literature [11] proposed to use the clustering method to resolve the same finger of noun phrases. The basic idea is to collect the basic noun phrases in the chapter, cluster the noun phrases according to the features of the phrases and determine whether the two nouns belong to the same category. The recall rate of the system in MUC.6 is 55%, the accuracy rate is 53%, and the F value is 54%) Classification-based methods: The literature [12] converted the problem of judging antecedent into a classification problem, and judged whether there is a anaphora relationship between the pronoun and each antecedent candidate through a classifier. This idea has opened up a brand-new path for the future research on anaphora resolution. The literature [13] give detailed and complete implementation steps and designed and developed a learning-based system to resolve noun phrases in unrestricted text. The system is divided into 5 parts in total:1)identify candidates, 2) construct noun phrase feature vectors, 3) construct training examples, 4) train classifiers, 5) identify test documents, and construct a referral chain. The performance of the classifier in the system [13], the classification ability of each attribute in the feature vector, and the cause of the error are analyzed in detail. The F value s that the system finally resolved on the MUC.6 and MUC.7 corpora are 62.6 and 60.4, respectively. In recent years, many researchers have expanded the system to varying degrees based on the literature [13] and have made some progress. Typical systems include: The literature [14] extracted 53 different lexical, grammatical, and semantic features. The literature [15] proposed a dual candidate model to directly learn the competitive relationship between the proactive language candidates to better determine the proactive language. The literature [16] continued to explore the role of semantic information in the antecedent candidate anaphora chain in the pronoun (especially neutral pronoun) anaphora resolution. On this basis, literature [17] further uses context information and network mining technology to automatically identify the semantic category of pronouns, thereby better solving the anaphora resolution of pronouns (especially neutral pronouns). At present, most of the anaphora resolution systems use a local optimization method, that is, for each anaphora, the best antecedent is selected according to different algorithms. In order to achieve global optimization, the literature [18] used a Bell tree to represent the search space, in order to find the optimal anaphora resolution scheme. The literature [19] selected the best partitioning scheme from different systems according to the advantages and disadvantages of different systems.
The literature [20] used the lattice framework to propose the idea of anaphora classification in a context-sensitive semantic environment and give the corresponding algorithm. The literature [21] proposed the HNC-based anaphora resolution method, which utilizes the type features of various semantic blocks and the structural features between semantic blocks to use exclusion rules within and between semantic blocks. Moreover, the principle of partial focus priority (similar to the central theory) is used for priority selection to achieve the elimination of personal pronouns between sentence sequences. The literature [22–24] used a method based on weakened linguistic knowledge to solve the elimination of personal pronouns and combined with a anaphora selection strategy to conduct research on anaphora elimination.
Undirected graph model
CRFs can be regarded as an undirected graph model or Markov domain. The global condition is on the random variable X representing the observation sequence. Formally, G = (V, E) is used to represent an undirected graph. Among them, V is a set of nodes, and E is an undirected edge between nodes. The node y represents a set of continuous or scattered random variables, and each node v (v ∈ V) in V corresponds to an random variable of element Y v of y. The graph model is related to the joint probability distribution of the random variables represented by the nodes in the graph. The parameters of these probability distributions depend on the direct conditional independence of random variables in the graph.
If the directed graph model G = (V, E) has identified the conditional independence relationship between the topologically ordered sets of nodes in G, the joint probability distribution of the directed graph model can be decomposed into the product of conditional probabilities. The joint probability of the random variable represented by node V = v1, v2, ⋯ , v
n
can be expressed as formula (1).
In the formula, v πi is the parent node set of node v i . The parameters of the Markov random domain are different from those of the directed graph model.
The first step in parameterizing the undirected graph model G = (V, E) is to find the set of nodes that each local function acts on. In order to find this set, the concept of conditional independence is introduced. A, B, C represent three disjoint subsets. If node set V B separates V A and V C , then we can think that the random variable represented by node set V A is conditionally independent of the random variable represented by V C under the condition that node set V B is given. For an undirected graph model, a simple graphical separation theory concept is used. Under the condition that V B is given, V A is independent of V C , that is, the path from any node V{i|i∈A} in V A to any node V{i|i∈C} in V C passes through at least one node V{i|i∈C}B in V B . In order to identify the part of the node where the local function works on its nodes, according to the conditional independent properties of the undirected graph model G, if there are no edges between the two nodes v i and v j in the graph G, it means that under the condition that all other nodes in the graph are given, these two nodes must be conditionally independent. Therefore, when choosing a local function, it must be ensured that the joint probability distribution can be decomposed to prevent v i and v j from appearing in the same local function.
The simplest way to achieve this decomposition requirement is to ensure that the nodes acting on this local function form a fully connected node subset or clique in G. Obviously, this ensures that no local function acts on any pair of nodes that are not directly linked. Moreover, if two nodes appear in a clique at the same time, a connection is established by a local function defined on the clique where these two nodes are located. To further refine the concept of local functions, each local function is defined on a largest clique or a clique whose nodes cannot be expanded and whose nodes remain fully connected. Then, it is meaningless to define a potential function on any clique corresponding to this subset of the largest clique. Therefore, the simplest local function set corresponding to the conditional independence of graph G is the set of functions defined on V C that may be involved in the largest clique C of G. These local functions ΨV C (V C ) are called potential functions and are strictly non-negative real function forms.
However, the product of a set of non-negative real number functions does not satisfy the axiom of probability. Therefore, in order to satisfy these axioms and ensure that the product is indeed the joint probability distribution of the random variables represented by the nodes in G, and a normalization factor Z is defined:
Among them, C is the set of all largest cliques in graph G. Therefore, the joint probability can be calculated using the following formula:
By using the Hammersley-Clifford (J. Hammersley, 1971; Peter Clifford, 1990) theorem, we get the above formula.
CRFs are a framework of undirected graph models, which can be used to define the joint probability distribution of a labeled sequence, under a set of observation sequences to be labeled is gave. If it is assumed that X and Y respectively represent the joint distribution random variable of the observation sequence to be marked and its corresponding marking sequence, the conditional random field (X, Y) is an undirected graph model with the observation sequence X as the global condition.
Generally, we define G = (V, E) to be an undirected graph, and Y ={ Y
v
|v ∈ V }, that is, each node in V corresponds to the component Y of the label sequence represented by a random variable. Therefore, the condition of the entire graph and the distribution category associated with the graph is X, so the form of the joint distribution category associated with G is p (Y1, ⋯ , Y
n
|X), where Y
i
and x are the category sequence and the observation sequence, respectively. If each random variable Y
v
satisfies the Markov attribute on G and all random variables Y(u|u≠v,{u,v}∈V) except X and Y
v
are given, then the probability expression of the random variable Y
v
is:
Among them, u ∼ v indicates that u and v are adjacent in graph G, and (X, Y) is a conditional random field.
Theoretically, if the graph G shows the conditional dependency relationship between the tag sequences to be modeled, its structure can be arbitrary, and it describes the conditional independence in the tag sequence. But when used to model sequence labeling tasks, the simplest and most common graph structure encountered is that the nodes corresponding to the elements of Y form a simple first-order chain. We refer to this conditional random field as Linear-chain CRFs, as shown in Fig. 1:
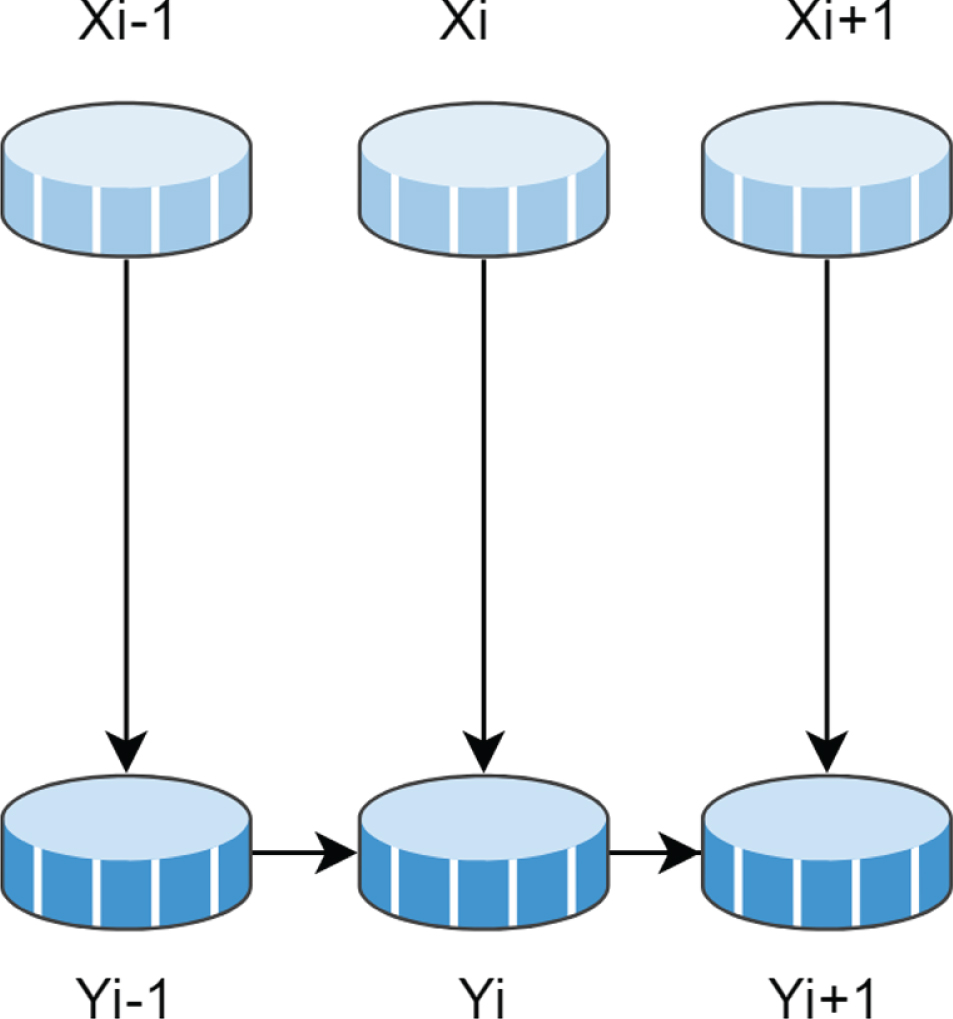
Model structure of linear CRFs.
Since we want to define a probability distribution P (Y|X), the random variable representing y is only a part of graph G. In addition, there is no graph structure among the elements of X. The reason is that we only use the observation sequence as a condition and do not make any independent assumptions about X.
As a probability automaton, each state transition of CRFs corresponds to a non-normalized weight. The non-normalized nature of these weights means that the transitions in the CRFs model are treated differently. Therefore, for any given state, the probability distribution passed to the subsequent state may be enlarged or reduced, and the weight of any state sequence is given by the global normalization factor, so that CRFs avoid the problem of label bias.
The graph structure of CRFs can be used to decompose the joint distribution of Y v into a product of a normalized potential function. The potential function comes from the concept of conditional independence and is strictly non-negative, real-valued function. Among them, Y v is an element of y. The vertices in G involved in each potential function represent a subset of random variables. According to the independent definition of the undirected graph model, if there are no edges between two vertices in G, it means that the random variables represented by the two vertices are independent of other given vertices in G. Therefore, the potential function must ensure that the joint probability can be decomposed so that random variables with independent conditions will not appear in the same potential function. The easiest way to meet this requirement is to ensure that each potential function acts on a set of random variables, and the vertices corresponding to these variables form a largest clique. Under the CRFs of the chain structure, each potential function g acts on the adjacent labeled variables Y i and Yi+1.
In the case where the observation sequence X is given, Lafferty et al. defined that the probability of labeling sequence Y is a normalized form of the product of the potential function. Among them, the form of each factor is shown in formula (5):
Among them, t j (Yi-1, Y i , X, i) is the feature function of the entire observation sequence and position and the label of i and i - 1, and s k (Y i , X, i) is the feature function of the entire observation sequence and position i. The parameters λ j and μ k are the feature weights related to the feature functions t j and s k respectively obtained during training. The range o F value s of j and k depends on the number of features in the template.
When defining the feature function, the set of real-valued features b (X, i) of the observation sequence can be constructed to describe the empirical distribution features of the training data. These features have the same distribution as the model. The following introduction is an example:
Each feature function represents a real-valued observed feature b (X, i). If the current state (state function) or the previous state and the current state (transfer function) have specific values, then all the feature functions are real-valued. For example, the following transfer function is:
In the following description, we use formula (8) to represent the state function:
In formula (9), the feature function f
j
(Yi-1, Y
i
, X, i) is a state feature function s
k
(Y
i
, X, i) or a transfer feature function t
j
(Yi-1, Y
i
, X, i). Therefore, for a given observation sequence X = X1, X2, ⋯ , X
i
, ⋯ , X
n
, the probability of its corresponding label sequence Y = Y1, Y2, ⋯ , Y
i
, ⋯ , Y
n
is:
Then, we can express P (Y|X).
Now, we have built a statistical model of P (Y|X) using CRFs. The labeling task for solving the sequence is to find Y* to make the maximum value of P (Y|X). Z (X) has nothing to do with Y, so Y* is:
The optimal solution Y* can be obtained using dynamic optimization methods such as Viterbi.
The main task of establishing the CRFs model is to estimate the feature weight λ from the sample data. CRFs parameter estimation can use Maximum Likelihood Estimation (MLE) and Bayes Estimation. The following mainly introduces the parameters of CRFs model using maximum likelihood estimation.
In the training set Y* T = { 〈 X
k
, Y
k
〉 }, the maximum likelihood parameter estimation is a function that assumes that P (Y|X, λ) is λ. The λ that maximizes the logarithm of P (Y|X, λ) is the estimated value, and its likelihood value is:
The maximum value is:
Since L∧ is a convex function and the zero point of the derivative is the maximum point, this global maximum can converge to.
To obtain the maximum value of L∧, we have to maximize the difference between the correct path and all candidate paths. Therefore, the trained CRFs model will distinguish the correct path from all other paths, which can avoid the problem of category deviation.
Therefore, when differentiating λ, the partial derivative formula is:
It can be abbreviated as:
If maximum likelihood estimation is used directly, over-learning problems may occur. This problem can be solved by introducing a penalty function. For example, when using the penalty term
Its derivative becomes:
Therefore, the parameter estimation problem of λ can be solved by the optimization method. The iterative methods such as GIS and IIS can be used. The implementation of this paper uses L-BFGS (Limited-memory Brayden-Fletcher-Goldfarb-Shannon) algorithm.
For a chain of CRFs, we can add a start state tag and an end state tag to each sentence to mark the sequence. Y0 and Yn+1 represent the start tag and end tag respectively. When an observation sequence x is given, the probability P (Y|X, λ) of labeling sequence F can be effectively calculated using a matrix.
We set Ψ to be the alphabet of marks, Y′ and Y″ are the marks from this alphabet. Moreover, we define the set of n + 1 matrices as {M
i
(X) |i = 1, ⋯ , n + 1 } 1). Among them, M
i
(X) is |Ψ × Ψ| matrix, and the matrix element form is:
When the observation sequence X is given, the conditional probability of the label sequence F without normalization can be expressed as the product of the elements of the n + 1 matrix:
Similarly, the normalization factor Z (X) of the observation sequence X can be calculated from the M
i
(X) matrix by using the Closed Semirings method. The algebraic structure is a general framework to deal with the path problem in the graph. The value of Z (X) is given by the product of the M
i
(X) matrix from the start position to the end position. It is expressed as:
Therefore, we only need to get M i (X) to calculate the value of Z (X).
In the parameter estimation process, whether iterative convergence or gradient-based methods are used, in order to calculate the maximum likelihood parameters, for each observation sequence X
k
in the training data, we must effectively calculate the expect EP(Y|X
k
) [F
k
(Y|X
k
)] of each feature function related to the distribution of the CRFs model.
It is not advisable to calculate the above formula in a simple way. The reason is that it needs to be summed on the label sequence: if the observation sequence X k has n elements, then Y k corresponds to n|Ψ| elements, and the cost of summing these items is very high. Therefore, the forward-backward algorithm similar to HMM is usually used to solve this problem.
We define the forward vectors α
i
(X) and backward vectors β
i
(X) as:
The recursive definitions are:
Therefore,
Then, we can quickly find the feature expectation, so that we can use the machine learning method to calculate the model feature weight λ.
The model constructed in this study is based on SVM and machine learning technology, and the model structure is based on the CNN three-layer network. The most basic CNN neural network is usually composed of three layers: input layer, hidden layer and output layer. The data enters the hidden layer through the input layer, and the sampling layer in the hidden layer maps the features extracted by the convolution layer. Finally, the features enter the output layer to obtain the classification results. The structure is shown in Fig. 2.
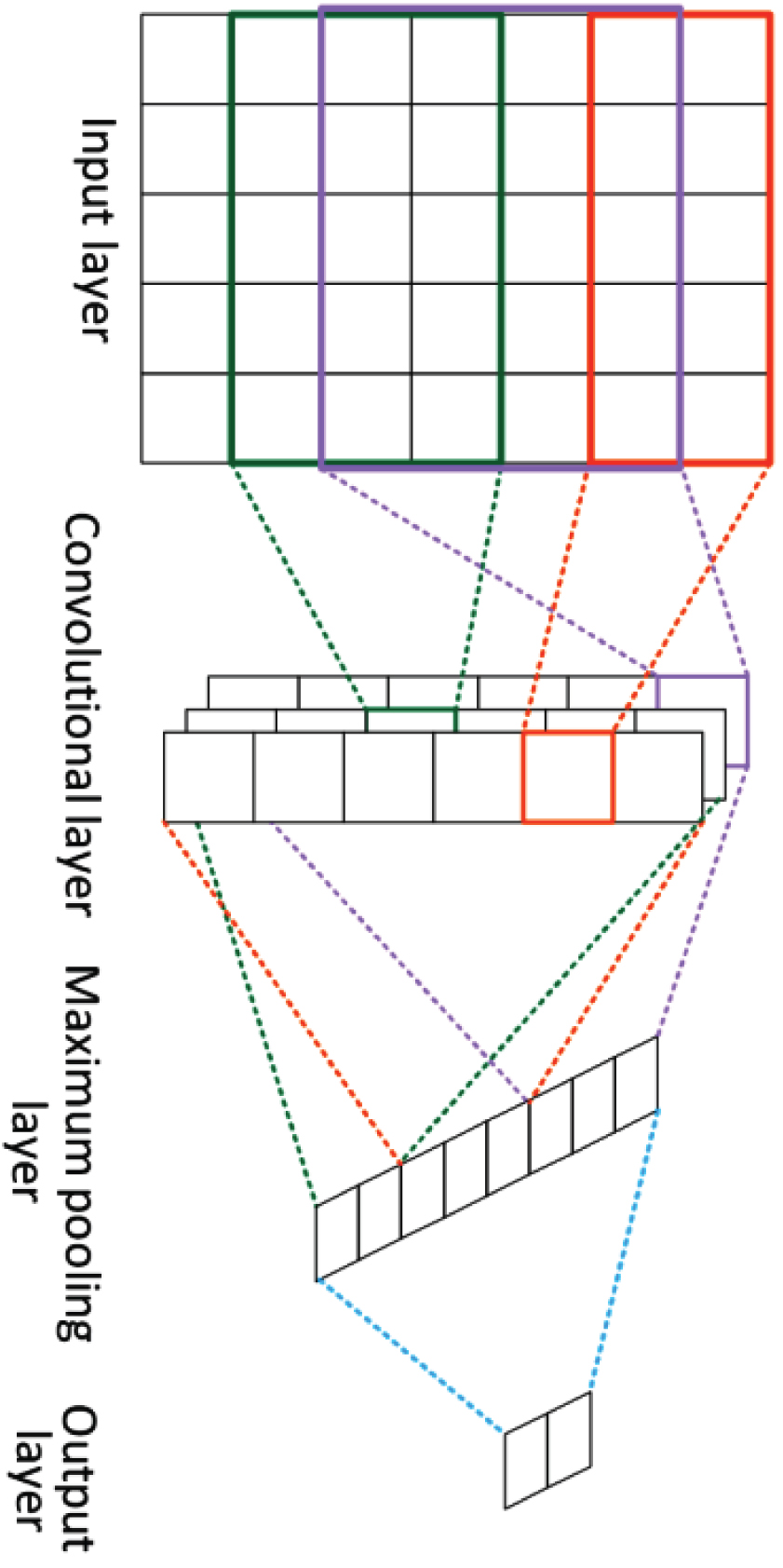
The structure diagram of convolutional neural network.
The anaphora resolution system of English information in this article uses the same framework as the benchmark system, as shown in Fig. 3.
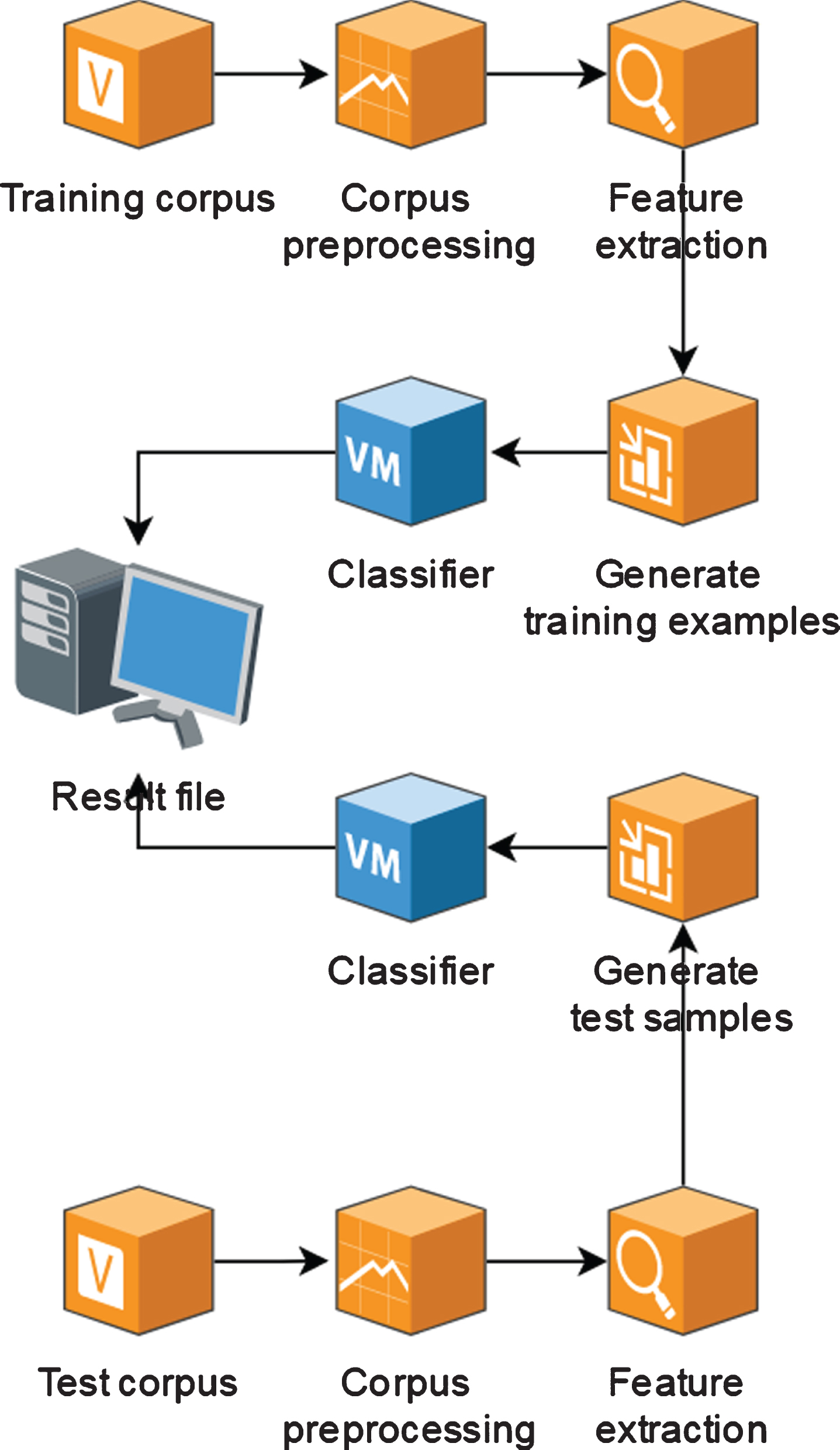
The anaphora resolution platform based on machine learning and SVM.
The experiment is conducted on the English corpus of OntoNotes 4.0 using the positive and negative examples balance method, and the samples were generated according to the sample generation method. The ratio of positive and negative examples reached about 1 : 11. This article then uses the first step of the method to filter the samples. The experimental results are shown in Table 1 and Fig. 4 below. After the first step of filtering, the ratio of positive and negative examples changes from about 1 : 11 to about 1 : 3.5. It can be seen from this that the first step of this method can effectively reduce negative cases. Moreover, from the experimental results of the system, it can be seen that after the first step of processing, the system’s recall rate and system performance have been improved. This shows that reducing the proportion of negative examples can indeed improve the performance of the system, but the imbalance of positive and negative examples still exists. Next, this study uses the second step of the positive and negative examples balance method to filter negative examples. The second step uses named entity recognition features. If a noun phrase belongs to a person’s name, organization name or place name, then this noun phrase is basically impossible to represent an event. Therefore, this article filters all the noun phrases in the sample. If the filtered noun phrase belongs to the name of a person, institution, or place, then all the examples containing this noun phrase will be removed from the sample. After the second step of filtering, the ratio of positive and negative examples is reduced from about 1 : 3.5 to about 1 : 3. Although the accuracy rate has decreased, the recall rate and system performance have been improved. This shows that the method of filtering negative examples using central theory and named entity recognition is effective.
Statistical table of the impact of different positive and negative cases on the system
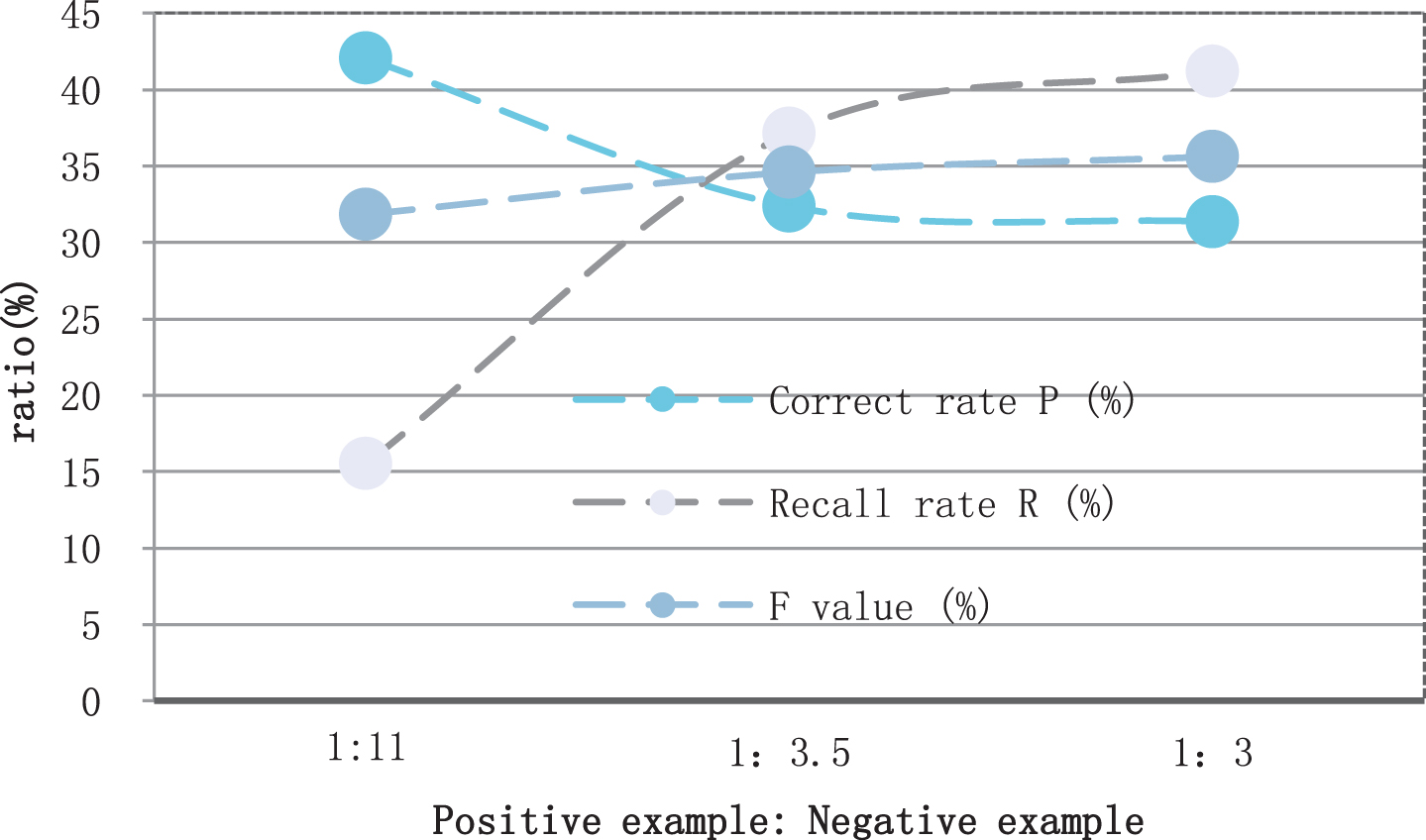
Statistical diagram of the impact of different positive and negative cases on the system.
Through the above two steps, the ratio of positive and negative examples was reduced from about 1 : 11 to about 1 : 3. However, due to the particularity of anaphora and antecedent in event reference, this problem cannot be resolved like entity reference. The balance of positive and negative examples is achieved according to the filter rules such as part-of-speech and singular and plural of anaphora and antecedent. Therefore, based on the first two steps to filter the negative examples, the third step is carried out, and the positive examples are copied under the condition that the negative examples remain unchanged to continue to adjust the positive and negative examples. Table 2 and Fig. 5 show the performance of the event anaphora resolution system when the positive and negative examples are balanced using the positive and negative examples balance method.
Statistical table of positive and negative balance methods

Statistical diagram of positive and negative balance method.
As can be seen from Fig. 5, as the ratio of positive examples to negative examples decreases, the recall rate tends to decrease, and the accuracy rate increases. The system performance showed a trend of increasing first and then decreasing. The ratio of positive and negative examples reached a stable range from 1 : 1.1 to 1 : 1.3 and the system performance reached the highest at 1 : 1.1. Therefore, the experiments in this paper use the experimental results of the ratio of positive and negative examples of 1 : 1.1 in subsequent experiments.
In this paper, after using SVM machine learning to achieve the best performance, considering the possibility of continuing to improve the performance of the system, in the model, the SVM system can be used to build the system model alone, or the machine learning can be used to build the model, or the two can be combined to build a dual model. This article uses a dual candidate model to try to improve the performance of the system. Moreover, this study analyzes the performance of these models, the experimental results are shown in Table 3 and Fig. 6. It can be seen from Table 3 and Fig. 6 that the single-candidate model has a lower recall rate than the benchmark system, but the accuracy and system performance are improved. This shows that the new semantic features given in this paper have a positive effect on the resolution of noun phrase event reference. Secondly, after using the dual candidate model, the accuracy, recall and overall performance of the system are improved. Compared with the single candidate model, the accuracy rate is increased by 1.75%, the recall rate is increased by 1.85%, and the overall performance is improved by 2.03%. Compared with the benchmark system, the accuracy rate is increased by 2.24%, the recall rate is increased by 0.29%, and the overall performance is increased by 2.23%. This shows that the dual candidate model has a positive influence on the event-referential resolution system of noun phrases.
Comparison of results between single candidate model and double candidate model

Comparison chart of results between single candidate model and double candidate model.
Anaphora resolution can be divided into entity referral resolution and event referral resolution according to different targets. Since the attention of the event anaphora is far less than that of the entity anaphora, the event anaphora resolution has been treated as a whole with the entity anaphora resolution as a whole. However, as the amount of information increases, information is often transmitted with the occurrence of events. The continuous development of information extraction technology makes the demand for event anaphora resolution increasingly higher, and event anaphora resolution is of great significance. Moreover, this paper has done related research work on English information anaphora and explored the role of structured syntactic information in the resolution of event noun phrase anaphora. In addition, this study uses two semantic roles to improve the semantic role expansion tree in structured features and combines semantic features to compare and analyze each feature combination and uses a dual candidate model to improve the system. Finally, this study analyzed the experimental results. The results show that the performance of the system using the dual candidate model is better than that of the single candidate model system.