
Abstract
The application of artificial intelligence and machine learning algorithms in education reform is an inevitable trend of teaching development. In order to improve the teaching intelligence, this paper builds an auxiliary teaching system based on computer artificial intelligence and neural network based on the traditional teaching model. Moreover, in this paper, the optimization strategy is adopted in the TLBO algorithm to reduce the running time of the algorithm, and the extracurricular learning mechanism is introduced to increase the adjustable parameters, which is conducive to the algorithm jumping out of the local optimum. In addition, in this paper, the crowding factor in the fish school algorithm is used to define the degree or restraint of teachers’ control over students. At the same time, students in the crowded range gather near the teacher, and some students who are difficult to restrain perform the following behavior to follow the top students. Finally, this study builds a model based on actual needs, and designs a control experiment to verify the system performance. The results show that the system constructed in this paper has good performance and can provide a theoretical reference for related research.
Introduction
The more prosperous education, the more prosperous the country, and the stronger the education, the stronger the country. Education is the basis for a country to become rich and powerful. Our country is now in a transition period from an economic power to a world power. Therefore, higher education is needed to provide more medium- and high-end technical and skilled talents to the country. In particular, the “New People Promotion Law” implemented in 2017 loosened the development of colleges and universities so that they can quickly respond to the needs of society and the country and train qualified personnel. As artificial intelligence is promoted to the national strategy, it will have a profound impact on various industries in my country. Universities should keep up with the trend of the times, grasp the footsteps of the “artificial intelligence” era, and apply “artificial intelligence” to the education and training of students. However, how to adopt “artificial intelligence +” is still a problem. This article will discuss how the application of artificial intelligence to teaching management in colleges and universities will affect the development of the school [1]. If colleges and universities want to better integrate artificial intelligence technology with teaching management, they need to have a deep understanding of artificial intelligence technology and have a clear direction and overall design on how to use it. Moreover, this study explores what changes and how those technologies of artificial intelligence can be applied to teaching management. Moreover, this study discusses the application countermeasures of intelligent applications in teaching, which has guiding significance for teachers to use intelligent optimization teaching in the future, students to use intelligent applications to achieve personalized learning, and teaching managers to use intelligent applications to improve work efficiency. It has become a reality for universities to apply artificial intelligence technology to teaching and learning. Moreover, teachers use artificial intelligence to assist themselves in the process analysis of pre-class preparation, teaching courses, correcting homework and after-school counseling. Through the study of the process of artificial intelligence on students’ personalized learning, autonomous learning, and after-school practice, it is found that artificial intelligence can change the disadvantages of traditional classroom teaching and make teaching and learning more intelligent, precise, and personalized [2]. The use of artificial intelligence can make teaching management more efficient, simplify the process of teaching management, reduce the cost of teaching management, and improve the level of teaching management. The use of artificial intelligence technology in teaching management can make the management more just and transparent, make the rights and responsibilities clear, and make managers more responsible. The intelligent management system can make the management data public, and can enable teachers, students, parents, etc. to participate in the teaching management, so that the teaching management is supervised by everyone and do a good job in service. What an enterprise sells are a product, and whether this product is popular in the market is a criterion that determines the quality of this enterprise. What the school “sells” are excellent “talents” that meet the development requirements of the enterprise, can bring performance to the enterprise, and make the enterprise healthy and sustainable. Employment is the foundation of national development and one of the important indicators of national economic development to measure the stability of the country’s political constitution. Therefore, whether the students trained by colleges and universities can meet the needs of enterprises after graduation and whether the training results can meet the requirements of enterprises in their positions is an important issue that all colleges and universities in China must face. This requires colleges and universities to work hard on talent training and teaching management optimization, and should closely follow the development of the times, seize new technologies and new opportunities, and apply new technologies such as artificial intelligence, Internet of Things, and information technology to teaching services. Moreover, colleges and universities need to intelligently manage matters such as teaching management models, teacher teaching, student learning, comprehensive evaluation, and student employment evaluation, and improve efficiency to train more outstanding talents for the school and build their own brands [3].
Related work
The literature [4] made a breakthrough in the field of deep learning of neural networks, so that humans once again saw the possibility of machines achieving intelligence and surpassing humans, which is a landmark event in the progress of artificial intelligence technology. The literature [5] in the field of Go, where humans believe that machines cannot beat humans, defeated South Korean chess player Li Shishi, which once again triggered an upsurge in artificial intelligence. As Internet giants such as Google, Baidu, Ali, and Tencent entered the battlefield of artificial intelligence research and development, another round of artificial intelligence frenzy was launched. At present, artificial intelligence technology is increasingly mature and applied to people’s daily life. People are happy and need them to integrate into life. This wave of artificial intelligence may realize the intelligence of human beings and make science fiction movies a reality. Artificial intelligence is the scientific technology that studies the way people think and learn through machines, and is the scientific technology that extends human intelligence, such as: speech recognition, deep learning, sentiment analysis, learning analysis, and intelligent behavior. Artificial intelligence allows machines to think and act like humans, and eventually replace humans for tasks that only humans can accomplish. The literature [6] proposed that computers or robots using artificial intelligence systems can evolve on their own and can produce more advanced artificial intelligence systems than themselves. Faced with artificial intelligence, we can neither overestimate its impact on us nor underestimate the convenience it brings to life and work. The main research technologies of artificial intelligence are expert system [7], natural language understanding [8], machine learning [9], distributed artificial intelligence, machine learning [10], pattern recognition [11] and so on. In recent years, the rapid development of computer hardware technology has led to a significant increase in computer performance. The global popularity of the Internet provides a large amount of data foundation for big data technology and deep learning technology, so that the two technologies have been further developed. Artificial intelligence has achieved rapid development and is widely used in many fields such as family life, medical care, transportation and so on. Moreover, various industries are actively exploring how to use artificial intelligence technology to solve industry problems, and education is no exception [12]. The literature [13] believed that artificial intelligence is a technique for increasing ability, using ability and empowering ability, which is divided into subjectivity and assistance and used in teaching. Subjectivity refers to teaching systems built using artificial intelligence technology, such as intelligent teaching assistants, intelligent teaching platforms, intelligent robots, etc. Assistance refers to integrating functional modules or some technologies of artificial intelligence into teaching resources, teaching tools, teaching management, teaching evaluation, and transforming them into media or tools to exert their functions, such as intelligent teaching platforms and adaptive learning platforms, intelligent teaching management, intelligent evaluation, etc. [14]. Only a combination of artificial intelligence, VR, AR, behavior analysis, learning analysis, and intelligent robot technology can have a profound impact on teaching. The impact of using only one technology on teaching is very limited [15]. Therefore, the research and application of machine learning, natural language understanding, pattern recognition, big data, learning analysis and other technologies to teaching are the opportunities and challenges brought by artificial intelligence to teaching. Pattern recognition is to use a computer to identify existing things, and then put it into the same or similar patterns. By studying how to make the computer recognize objects, videos, audio and other information, the computer can listen to sounds, see objects and feel nature like humans. To apply pattern recognition to teaching, we must first collect students’ voice, emotion, behavior and other data, and carry out in-depth analysis of these data to obtain a data model. According to this data model, the machine will provide students with personalized learning services [16]. Pattern recognition can be used in teaching to improve teaching effectiveness. For example, in the practical operation course, the machine can scan the student’s operation and compare it with the standard operation to correct and guide the student’s operation. A large amount of high-quality data provides the most fundamental support for the realization of artificial intelligence. The traditional data volume is small, the diversity is insufficient, and the circulation speed is not high, while the big data has the characteristics of huge data volume, high-speed circulation, diversity, and authenticity [17]. The in-depth development of big data technology has brought opportunities for machine learning and intelligence as well as opportunities for future intelligent education [18].
Teaching optimization algorithm
The specific implementation steps of the TLBO algorithm are as follows [19]:
Step 1: The number of students P
n
, the maximum number of iterations Gmax, the number of courses D
n
, and the upper and lower limits of course grade (U
L
, L
L
) are initialized. A student j has a grade of
Step 2: Population initialization, that is, all students and teachers form a class, which is expressed by the following matrix:
Among them, the column average of the matrix represents the average score M i of all students in different courses.
Step 3: We assume that the grade distribution of students in the class meets the normal distribution, the distribution function is
Step 4: The teaching process of the first stage of the algorithm is shown in Fig. 1 above. The students’ grades are relatively low, and their average score is Mean
A
. At this time, the best grade T
A
is the teacher. After a certain period of teaching, the student’s performance was improved to be close to the teacher’s performance Mean
B
. At this time, it was difficult for the teacher T
A
to take up the teaching role, and the teacher changed to the best performing T
B
at this time. In the first process, the improvement of student performance is mainly achieved by the difference between the teacher’s performance and the student’s average score [20]. that is:

Schematic diagram of teaching optimization algorithm.
Among them, r i is a random number in the range of [0, 1]. The teaching factor T F = round [1 + rand (0, 1) { 2 - 1 }] is a random value between 1 and 2.
According to formula (2), the updated formula of the teaching process is obtained:
Step 5: The second stage of the algorithm is the learning process. The two students were arbitrarily chosen to communicate, report, discuss, etc., so that the current students can gain more knowledge from better classmates, thereby improving their grades. The two classmates X
i
and X
j
were randomly selected. When X
i
’s grade
Otherwise, if X
j
’s grade
The updated score cannot be regarded as the final score, and it can be determined only by comparing fitness values. Only if the fitness value of X new is better than X old , X old is updated. Otherwise the original value is retained.
Step 6: If the termination condition is satisfied, it will end and output the final result. Otherwise step 4 is returned.
The basic TLBO algorithm flow chart is shown in Fig. 2 [22].

Basic teaching optimization algorithm flow chart.
Each particle in the particle swarm optimization (PSO) algorithm is a vector, which is used as a solution in the optimization problem. Each PSO particle in the D-dimensional space has three attributes: the current position x i = [xi,1, xi,2, ⋯ , xi,D], the particle historical optimal position p i = [pi,1, pi,2, ⋯ , pi,D], and the velocity v i = [vi,1, vi,2, ⋯ , vi,D]. For the function optimization problem, each particle in the particle swarm optimization algorithm determines its next position through its own historical optimal position and its neighborhood optimal or global optimal position, and its own speed adjustment direction and step size. The particle position update method in the PSO algorithm is shown in Fig. 3 [23].

PSO particle position update map.
Among them, the particle velocity and position update formulas are as follows:
In the formula, v i (t + 1) is the speed at the next moment, ω is the speed weight, and v i (t) is the current speed. Meanwhile, c1c2 is the learning factor, x i (t + 1) is the position at the next moment, an pbest,i (t) is the current optimal position. gbest,i (t) is the optimal position in the neighborhood, and x i (t) is the current location. In the above formula, the ω value in the first inertial term has a greater influence on the flying speed of the particle. The larger the ω value, the faster the flying speed of the particle, which means that the particle will have a larger step size and faster speed to conduct a global search. If the ω value is smaller, it means that the particles will perform a local search at a smaller particle speed. Formula (6) uses the updated speed formula to update the original position [24–26].
In the calculation of the D-dimensional space search process, the speed and position range of the particle swarm algorithm are [vmin, vmax] and [xmin, xmax], respectively, and the updating formula force of each particle at time t is:
Among them, r1r2 is a random number between [01]. The first term on the right side of formula (5) is the inertia term, which means that the particles have the characteristics of maintaining the original speed of movement and are used to balance the ability of global search and local search. The second term is the cognition term, which means that the particles have the characteristic of remembering their own optimal position, so as to enhance the algorithm’s global search ability and avoid falling into the local optimum. The third item is the social item, which has the characteristic of optimal approach to the neighborhood, indicating that the particles communicate and share operations.
The implementation steps of the PSO algorithm are as follows:
Step 1: The population size, the maximum number of iterations, the speed and position of particles in the population are initialized. Each particle contains D variables, and D is the dimension of the search space. The current position is the historical optimal position of the particle, and the neighborhood optimal position is inf
Step 2: The fitness value of the particle is calculated, the historical optimal position of the particle when the fitness value of the particle is optimal is stored as p best , and the optimal location of the neighborhood of the particle when the fitness value is optimal is stored as g best .
Step 3: According to equation (7) and equation (8), the particle velocity and position are updated;
Step 4: The particle fitness value is recalculated. If the updated fitness value is smaller after comparison, the updated position is used instead of the historical optimal position p best of the particle. At the same time, the current historical optimal value of the particle and the optimal fitness value of the neighborhood are compared, and the better individual is reserved as the optimal position of the domain g best .
Step 5: It is judged whether the maximum number of iterations has been reached. If the maximum number of iterations has been reached, the optimal solution is output. Otherwise, the algorithm iteration number is increased by 1 and the algorithm returns to step 2.
The flow chart of the PSO algorithm is shown in Fig. 4.
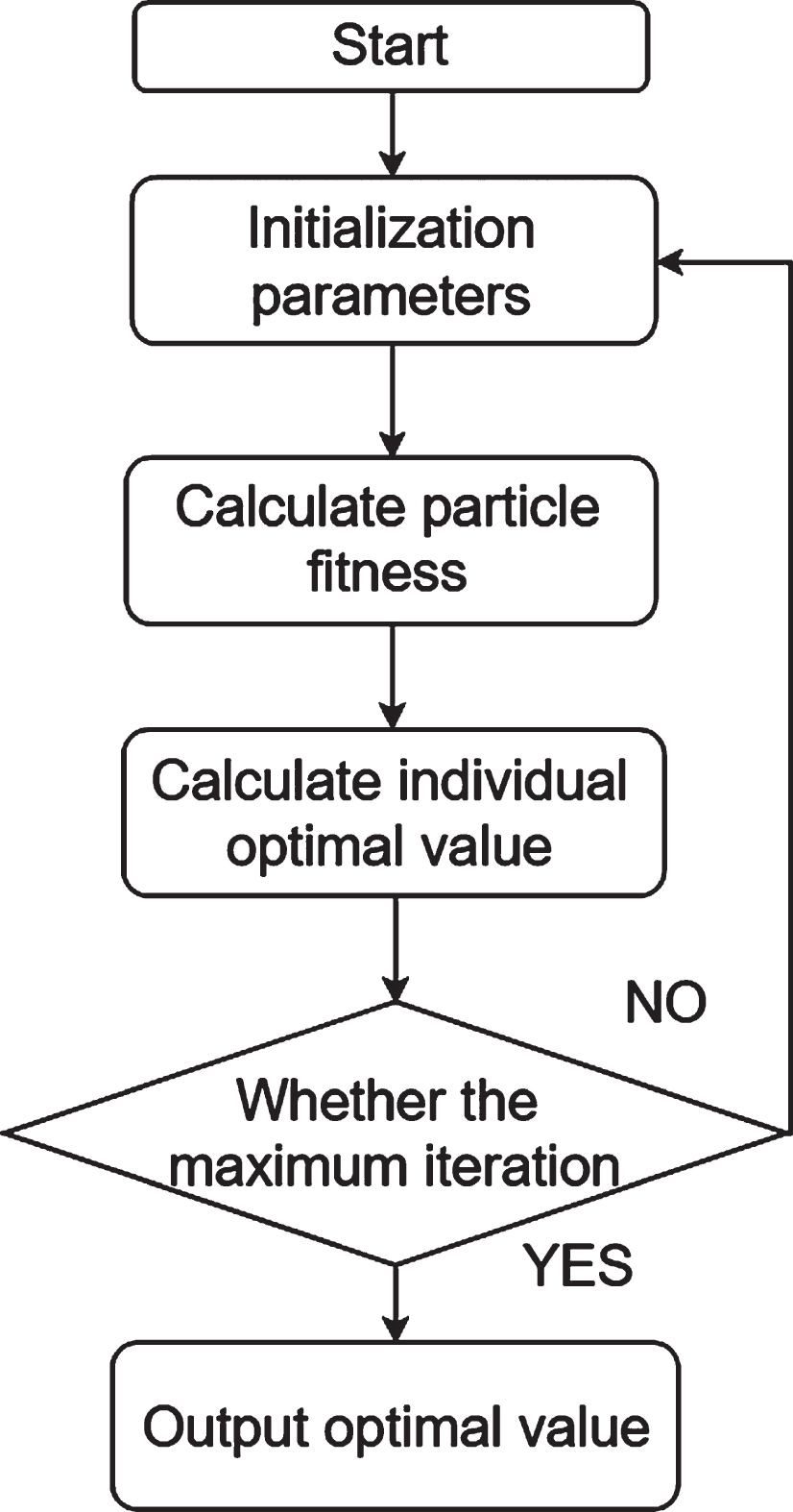
PSO algorithm flowchart.
This study designed to add tutor self-study parameters to the teaching optimization algorithm to achieve extracurricular learning, details as follows:
Among them, w self is the self-learning weight, X t is the tutoring score, and rand () is the random number between (0, 1). At the same time, w tatur is the tutoring weight, G is the current iteration number, and Gmax is the maximum number of iterations. wmax is the maximum weight, and wmin is the minimum weight.
It can be seen from the weight formula that as the search process progresses, the impact of tutoring will be correspondingly weakened, and the self-study part may produce a benign effect and may also cause a decline in grades.
The self-optimal and neighborhood optimal trends are balanced by improving the learning factor c1c2 in the basic PSO algorithm. At present, there are many ways to choose the learning factor: constant value, linear decrease, c1 linear decrease, c2 linear increase, and nonlinear change.
In the intersection area, 10% of the particles are randomly selected as individual particles to be crossed. After the individuals to be crossed are randomly paired with each other, the paired parents are used to generate the position and velocity of the children.
Among them, r is the random number between (0, 1), xp,1 and xp,2 are the position of the parent individual, and vp,1 and vp,2 are the speed of the paired individual. Meanwhile, x new and v new are the position and velocity of the individual offspring.
After using replacement operators to replace the particles to be crossed with new particles, a new population is obtained. The new population inherits the original population according to the fitness value.
S-shaped weights are used in the formula (5) instead of fixed weights as the product of speed. The non-linear weight has a small change in the early and late speeds of the iteration, that is, the early search speed is kept at a relatively fast level, and the speed does not drop too fast at the end of the search. When the search speed is in the middle of the S shape, the speed drops faster, which allows the particles to move faster to the global best. The following formula is used to set the weight ω
PSO
value:
In the formula, ωmax is the maximum weight, ωmin is the minimum weight, and G is the current number of iterations. Meanwhile, Gmax is the maximum number of iterations, and c speed is the speed change adjustment coefficient. As the value of inertia c speed becomes larger, the falling speed of weight ω PSO in the middle section gradually becomes larger, that is, the particles in this process will quickly move to the global best.
HPTLBO algorithm implementation steps are described as follows:
Step 1: The population number p n , dimension D, maximum iteration number Gmax, maximum and minimum weights wmin and wmax, external learning parameters w tatur and w self , and learning factor c1c2 are initialized.
Step 2: Individuals p n /2 are randomly selected as PartA to execute the optimal extracurricular learning teaching optimization algorithm. The other half as PartB executes the cross-variable weight particle swarm algorithm;
Step 3: The fitness values are calculated separately. In Part A, the selection of teachers is determined, and the teaching/learning process is selected to determine whether to update the student’s grades. In PartB, the historical optimal position of the individual particles and the optimal position of the neighborhood are calculated;
Step 4: PartA performs the self-learning process, PartB updates p best and g best , and the fitness value is recalculated
Step 5: The results of PartA and PartB are mixed and with p mnter probability, mutation is carried out;
Step 6: It is determined whether the maximum number of iterations is reached. If the maximum iteration is reached, the final result is output, otherwise step 2 is returned.
The HPTLBO algorithm flow chart is shown in Fig. 5.

HPTLBO algorithm flow chart.
Since the teaching process performed in the teaching process depends on two factors: the teacher’s level X teacher and the student’s acceptance of the teacher’s content T F , the presence of the teacher is particularly important.
The random teaching factor proposed in this paper follows the random characteristics of the teaching factor in the basic TLBO, and its calculation method is as follows:
Among them, σ is the variance of the teaching factor, randn () is a random number that meets the standard normal distribution, and rand () is the random number between (0, 1). Meanwhile, μmax is the upper limit of the average teaching factor, and μmin is the lower limit of the average teaching factor.
The artificial fish school realizes its visual process through the following methods:
As shown in Fig. 6, the visual range of the artificial fish is Visual, the moving step is Step, the position of the artificial fish at the current moment is X, the viewpoint position at a certain moment is X
V
. When the food concentration at the viewpoint position X
V
is greater than the food concentration at the current position X, then the artificial fish moves from X to X
next
with a certain probability, otherwise it will continue to tour other positions in the field of vision. As the number of artificial fish patrols continues to increase, its knowledge of the situation in the field of vision is more specific, which helps the artificial fish to make corresponding judgments and decisions. The specific implementation formula is as follows:

Visual map of artificial fish.
Among them, the current position X = (x1, x2, ⋯ , x n ), the viewpoint position X V = (x v 1 , x v 2 , ⋯ , x v n ), and rand () are random numbers between (0, 1). If the current position is a two-dimensional point, it means that (x1, x2) is the center, and any position (y1, y2) with the radius of Visual can be visually observed.
There are four basic behaviors of fish schools: foraging behavior, rear-end behavior, group behavior, and random behavior, among them:
(1) Swarm behavior: In order to ensure its own survival advantages or avoid danger, fish groups will instinctively gather to a center. This kind of swarm behavior follows two principles: first, the fish group should be as close as possible to the center of the same type; Second, overcrowding is avoided;
(2) Rear-end behavior: The artificial fish with the highest food concentration in the field of vision is followed, prompting the artificial fish trapped in the local optimum to escape quickly, and speeding up the optimization.
Combined with the description of the above artificial fish school algorithm, in the minimum problem, the rear-end behavior of artificial fish occurs at n f /δ ≤ 1, and the fish in the field of view all swim towards the optimal fish in the center of the field of view. Otherwise, some of the artificial fish whose food concentration is higher than y j · n f /δ choose the rear-end behavior, and the remaining artificial fish choose the foraging behavior. As n f /δ decreases, the probability that the rear-end behavior is selected is higher. Swarming behavior occurs in a part of mermaids that have a food concentration y central · n f /δ higher than the center of the visual field, and the rest of mermaids behave as foraging. The clustering behavior is similar to the rear-end behavior. As n f /δ decreases, the probability of being selected is higher.
Inspired by rear-end and clustering behaviors in artificial fish schools, this chapter proposes a neighborhood search strategy that uses adaptive Visual, adds a crowding factor δ l , and specifies that when the number of students surrounding the teacher reaches the upper limit n upper , that is, when n upper /δ l > 1, some students whose grades are better than y teacher · n upper /δ l break away from the teacher’s unified teaching and give up learning to the teacher and perform the learning process. In the teaching process, the fewer the students around the teacher, the better the teaching effect. There are excellent students who account for 5% of the total number of students in the class. As the core person of extracurricular teaching in the learning process, they guide other students and impart knowledge to them. Before making the selection of top students, we should first eliminate the possible same score phenomenon, and ensure that the top 5% of the students’ results are unique, so as to avoid uncertainty in the direction of learning. Similarly, in the process of searching for the best, the fewer students who are supervised by top students, the better the effect.
The steps to implement the neighborhood search proposed in this section are as follows:
Step 1: The parameter crowding factor δ l and the upper limit of the number of students n upper is initialized,
Step 2: n upper /δ l is calculated to determine whether the teacher is crowded, if n upper /δ l ≤ 1, that is, there is still a margin of teaching resources to continue to teach students to perform step 3. Otherwise, some students whose grades are better than y teacher · n upper /δ l will directly perform step 4;
Step 3: The teaching process is executed, and the teachers screened out by the fitness value guide the students to improve the student’s achievements, and enter step 5;
Step 4: A top student in the field of vision and the top 5% of the score is randomly selected as the core to perform clustering behavior, and the level of these students is used as the learning standard for the learning process:
Among them, Visual is the vision of students.
Step 5: Process effectiveness statistics are carried out. If the failure probability is higher than P fail , a chaotic search operation is performed.
Validity testing is added to the TLBO algorithm to determine the long-term impact of the teaching process and learning process on the progress of student performance. If the student performance is updated, ac
t
and ac
l
are separately recorded as a criterion for whether chaotic search is required in the future. The formula for calculating the effectiveness of the teaching process and learning process is:
Among them, count t and count l are used to count the number of times of entering the teaching process and learning process, respectively. If the ineffectiveness in the teaching and learning process is too large, that is, (1 - ef t ) ≥ P fail or (1 - ef l ) ≥ P fail , then the chaotic search operation needs to be performed.
The idea of chaotic sequence optimization algorithm comes from three unique properties of chaotic phenomena: randomness, ergodicity and regularity. In the optimization field, regularity and randomness make chaotic sequences between deterministic and random, with rich spatiotemporal states, and ergodicity can be used as an optimization mechanism to avoid falling into local extremums during the search process.
The description of chaos search is as follows: Chaos is a general non-linear phenomenon, and the motion state with randomness obtained by deterministic equations is generally called chaos. The following sequence can be used to traverse the chaotic sequence of interval [0, 1]:
Among them, l n is the value of the mixed stew variable at the nth iteration, μ is the control parameter of the mixed pure sequence, μ = 4 is taken, and L ={ l1, l2, ⋯ , l m } is the set of chaotic sequences composed of all l n ∈ (0, 1).
Some students in the teaching process are arranged according to the fitness value. The last 10% of the individuals are adjusted by the chaotic sequence L, and the current teacher’s score is used as the goal to avoid blind self-search:
Among them, L i is the i-th number in the L sequence in the chaotic sequence, G is the current number of iterations, and Gmax is the maximum number of iterations. Meanwhile, X teacher is the current teacher.
After the chaotic search, the fitness value of the student is calculated. If the fitness value of the newly acquired student is better, the new score of the student is used to replace the original score. At the same time, from multiple students who have been updated by chaos, according to the fitness value, the new teacher is found to replace the original teacher, and continue to perform the next operation.
The educational auxiliary system based on artificial intelligence and neural network constructed in this paper was applied to actual teaching, and the problems in teaching were found, and the teaching process was effectively verified. This article used experimental teaching methods to verify model performance. This study used Class A and Class B for verification, Class A is the experimental group, and Class B is the control group. The experimental group adopted the system constructed in this paper to assist in teaching, found problems and corrected them in time. The experiment lasted for one semester. The results obtained after the experiment are shown in Table 1 and Fig. 7.
Statistical table of experimental teaching results
Statistical table of experimental teaching results

Statistical diagram of experimental teaching results.
As shown in Fig. 7, there is a clear stratification between the experimental group and the control group, that is, the experimental group’s score is significantly higher than the control group. The scores of the two groups of people are subtracted, and the statistical results are shown in Table 2 and Fig. 8.
Statistical table of the score difference between the experimental group and the control group
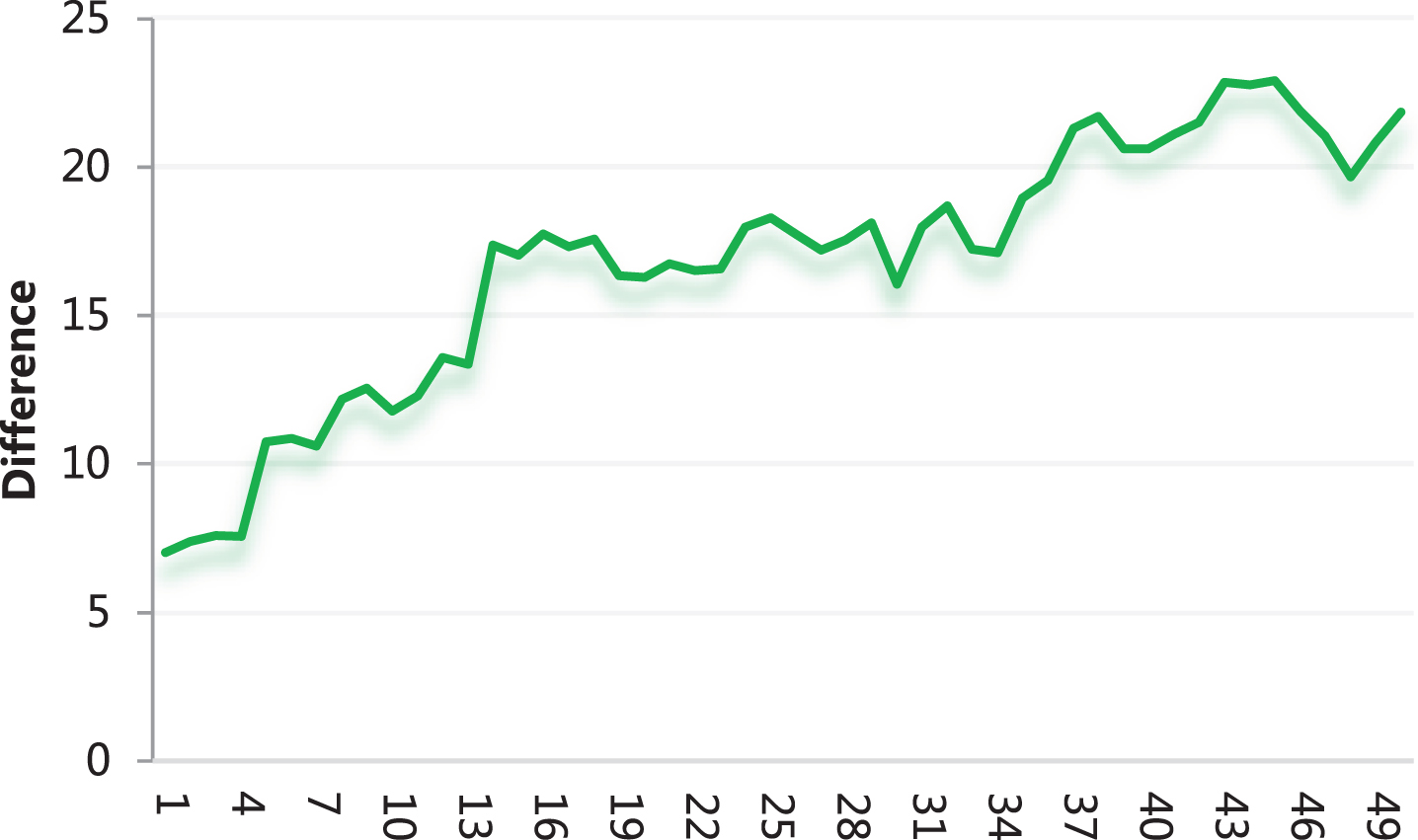
Statistical table of the score difference between the experimental group and the control group.
As shown in Fig. 8, the scores of the experimental group are 7–22 points higher than the control group, which shows that the system constructed in this paper has good performance. When it is applied to teaching, it can effectively improve students’ achievements.
Artificial intelligence teaching optimization algorithm is a simple, efficient and fast intelligent optimization algorithm proposed recently. This algorithm has been fully applied in many fields since it was proposed. This paper first briefly discusses the research background, research significance and research status of teaching optimization algorithms, and then explains and analyzes its basic principles, time complexity and space complexity. On this basis, in order to improve the practicability, efficiency and robustness of teaching optimization algorithms, this study proposes a computer-aided teaching system based on computer artificial intelligence and neural networks and a hybrid particle swarm teaching optimization algorithm. The particle swarm algorithm is concise, easy to implement, has fast convergence, and has strong global search capabilities. In addition, this study proposes a teaching optimization algorithm (MFTLBO) inspired by fish behavior. The clustering behavior in the artificial fish swarm algorithm improves the stability of the algorithm convergence, and the following behavior enhances the algorithm search ability. In addition, this study designed control experiments to verify system performance. The results show that the system constructed in this paper has good performance, and when it is applied to teaching, it can effectively improve students’ grades.
Footnotes
Acknowledgment
This paper was supported by (1) The Soft Science Research Project of Hebei Provincial Department of Science and Technology in 2019, “Research on the Cultivation Mode of Teaching Ability of Local Normal University Students Based on The Dual Tutorial System” (No. 18456234); (2) key project of teaching and Research Reform of Cangzhou Normal University in 2019 “Exploration and Practice of Training Mode of “Double Mentors” of Vocational Ability of Normal University Students” (No. 2019JGA002).