
Abstract
Although the data trading platform has accelerated the flow of data, the current data trading platform still has many problems. According to the characteristics of the blockchain technology, from the aspects of the attack behavior in the blockchain and the security application of the blockchain technology in power transactions, this paper studies the security of the blockchain. Moreover, this article focuses on the privacy protection of the ciphertext strategy in the CP-ABE scheme, and protects the privacy information of the access strategy by designing appropriate ciphertext and key structures and access structure forms. In addition, the system efficiency is improved by computing outsourcing, and solutions to problems in outsourcing computing are proposed. Meanwhile, two efficient and flexible support policy hidden multi-authorization center access control schemes are constructed. Finally, this study analyzes the performance of the model through controlled experiments. The research results show that this scheme has excellent performance.
Introduction
Network security problems have always troubled people and caused greater losses to users. In 2016, hackers hacked into the US presidential election voting system and the Hilary mail system. Moreover, the criminals used the vulnerability of the website to invade the information network of Shandong candidates. Hackers can paralyze the entire network by attacking the network center. They can also enter the network center to tamper with data, steal and falsify identity information, lure users into network traps, and use centralized databases and single points of failure to attack network. The rapid development of Internet technology is accompanied by more and more attention to Internet security issues. At present, computer network security still hides large hidden dangers and is greatly threatened. In response to network security problems, it is necessary to take effective measures to protect computer network security. Macroscopically, improving the level of computer network security will greatly promote the development of my country’s overall computer technology. However, in the face of endless security problems such as information leakage and data loss, traditional security methods cannot effectively prevent the occurrence of network attacks and incalculable losses to users. Therefore, researching and adopting new technologies to meet the actual security needs is a current problem [1]. When the application of cloud computing technology, big data technology, Internet of Things and other technologies is in full swing, blockchain technology, as a heavyweight information technology, has attracted more and more attention [2], and has been favored in various fields. Innovative enterprises, technology giants, cross-border alliances and even central banks and governments of various countries have invested in the research and application of blockchain technology [3]. In 2016, the Central Securities Exchange (NSD) of the Russian Federation announced a pilot project based on blockchain technology. In July 2016, IBM opened a blockchain innovation research center in Singapore. In July 2017, Tsinghua University established the Blockchain Technology Joint Research Center. The open source projects of R3 and HyperLedger abroad are relatively well-known, devoted to the research and experiment of asset contracts, energy transactions, Internet of Things and other aspects, and realize the exchange of value in virtual and digital forms. Blockchain technology is being studied and valued due to its advantages of being decentralized, safe, and difficult to tamper with. The Bitcoin trading platform based on blockchain technology has been operating safely and autonomously since its birth. This aroused great interest from researchers and began to pay attention to the underlying blockchain technology. Blockchain is a decentralized and de-intermediate distributed database, and a credible data network technology. Moreover, it is the core supporting technology of the digital encryption currency system represented by Bitcoin and provides a technical foundation for the construction of trusted and peer-to-peer data security sharing [4]. The characteristics of blockchain technology include transparency, decentralization, distrust, collective maintenance (unchangeable), anonymity, etc. It uses data encryption, time stamping, distributed consensus and economic incentives to ensure the safety of operations. Based on the distributed system, the nodes in the network can achieve point-to-point data sharing, coordination and collaboration, which provides a solution to the problems of high cost, low efficiency and insecure data storage that are common in centralized organizations. The analysis of security technology based on blockchain was developed under this background and demand.
The information age has arrived, and more and more emerging technologies are emerging, and technology can better serve us and solve many of the difficulties we are facing. However, when we are faced with the cross-domain interconnection of different types of databases, there is a problem how to safely, efficiently store, transfer, and share sensitive data. When the amount of data in some areas is large and the amount of data in some areas is small, how to balance the problems that need to be solved urgently. With the development of science and technology, these problems become more and more difficult to ignore. In the information age, all kinds of data are spread across terminal devices, networks, and clouds. The owner and custodian of the data are often not one person, but the authenticity and security of the data during the transmission process are solely the responsibility of the custodian.
Related work
The literature [5] proposed a blockchain method for access control management and secure data storage. This solution stores encrypted data in a trusted third-party escrow service and records event logs on the blockchain. However, there is no trusted third party in the real world, which brings the risk of data disclosure, and it also faces many difficulties for data owners to upload data to the cloud. The literature [6] proposed a blockchain-based data sharing system and used Ethereum’s smart contracts as the basis to propose a distributed information management system, called MedRec, which is used as a decentralized record management system for EMR. They provide miners with access to the original data and reward the data to the bookkeeper. However, the efficiency of data usage is not satisfactory, and it is illegal to collect patient data and use them as rewards. The literature [7] introduced in detail the disadvantages of using cloud storage technology to establish a data sharing system in the medical field. Moreover, the literature also raised the possible challenges of using blockchain technology in medical data sharing such as privacy protection. In another field, the existing time synchronization solutions can certainly achieve time synchronization, but most of the solutions are time stamps that can be utilized by malicious nodes in the network. If the slave nodes need to synchronize with the master node through multiple hops, they cannot resist attacks from malicious time stamps. The malicious timestamp can infect or act as an intermediate node, walk around the slave node with the wrong precise time, and spread the wrong time from the slave node to other nodes, which will cause the entire system time to be unavailable. Similar to other distributed systems, literature [8] proposed a robust flood time synchronization protocol (FTSP) suitable for low communication bandwidth. This protocol is suitable for medium-sized multi-hop networks and has strong robustness to topology changes and node failures. Moreover, the protocol is particularly suitable for applications requiring strict accuracy in wireless platforms with limited resources. However, the security of data usage is not satisfactory, and malicious time stamps can easily replay or bind attacks on the system. The literature [9] introduced in detail the security authentication version of NTP, called ANTP, which is used to prevent asynchronous attacks. It is designed to minimize public key operations on the server side by rarely using public key cryptography to perform key exchanges, and then only rely on symmetric cryptography to process subsequent time synchronization requests. Symmetric cryptosystem is the core of the scheme security, so it actually determines that the scheme’s ability to resist attacks is limited. The characteristics of the blockchain’s ledger disclosure are verifiable and the data cannot be tampered with, which naturally has an advantage in the security and trustworthiness of private data. The various nodes of the system coordinate and cooperate with each other to achieve the safe and efficient sharing of private data [10]. However, there are problems such as the efficiency of encryption and decryption, and the low efficiency of data upstream and downstream.
In terms of blockchain security, attacks against blockchain mainly include double-flower attacks, selfish mining, witch attacks, and eclipse attacks. According to the existing research literature, the selfish mining attack is a mining strategy that selectively publishes blocks and is a mining pool composed of some mining nodes. Foreign scholars mainly study and analyze selfish mining from the aspects of mining strategy and prevention strategy. A selfish miner can increase his relative mining income by hiding blocks. Related research shows that transactions conducted without the confirmation of the block are unsafe. The more confirmed the number, the safer the transaction [11]. Eyal and Sirer of Cornell University first proposed the concept of selfish mining and studied it. When using selfish mining attacks, a mining pool that initially had only 33% of the mining power can gradually obtain more than 50% of the mining power [12]. In the early days of research, selfish mining was considered as a block discard attack [13]. The literature [14] discussed the influence of propagation delay factors on the effectiveness of blockchain attacks in selfish mining attacks. For selfish mining, literature [15] proposed a measure that uses unforgeable timestamps to prevent selfish mining. The literature [16] adopted a subversive mining strategy to design a specific and practical block to resist attacks. In order to ensure the security of the system, the literature [17] studied the computing power threshold of selfish mining and proposed a strategy to limit the computing power of selfish mining, which is similar to the research in this paper. The literature [18] proposed a backward compatible defense block hiding mechanism, and a block that has not been published will be ignored.
Scheme construction
This section details a series of algorithm steps of the access control scheme proposed in this chapter, including system initialization, attribute anonymization, data encryption, access authorization, data decryption, and user revocation.
System initialization will complete system parameter settings, including global initialization and attribute authorization center initialization.
Global initialization can be expressed as:
CA first selects a system safety parameter λ, and then selects two multiplicative cyclic groups G and G
T
of prime order p. We set g to be the generator of G and G
T
, and set e : G × G → G
T
to bilinear mapping. CA chooses two hash functions: H : { 0, 1 } * → G
T
maps the identity identifier to group elements, and H′ : G
T
→ Z
p
maps the group elements to integers. Then CA chooses random number η ∈ Z
p
to generate global common parameter GP [19]:
In addition, all AA and users must register with CA to obtain globally unique identifiers aid and uid that prove their legal identity.
Property authorization center initialization
In the system, the attributes managed by each AA are different from each other. AA with identifier aid is defined as AA
aid
, and the set of attributes it manages is S
aid
. When AA
aid
is initialized, for each attribute x in S
aid
, the random number α
aid
, β
aid
, h
x
, γ
x
∈ Z
p
is selected, and then the attribute public key and attribute private key of AA
aid
are calculated as follows:
Finally, AA
aid
randomly selects φ
aid
, ψ
aid
∈ Z
p
and calculates the attribute conversion key:
Attribute conversion:
When the system executes the user attribute conversion algorithm, it inputs the global common parameter GP, attribute conversion key ATK
aid
, and attribute set S. For each attribute x in the attribute set S, the following calculation is performed:
Each attribute in S is anonymized, so that anonymized attribute set S′ is obtained. The algorithm can achieve anonymization of attributes to protect the sensitive information contained in the attributes, thereby protecting the privacy information contained in the access strategy [20].
Data encryption
First, the data owner DO sends the attribute set corresponding to the access policy T to the AA, and the AA performs the attribute conversion algorithm to calculate the anonymous attribute set
A is defined as the secret sharing matrix of l × n, and function ρ maps one row of the matrix to an attribute in
In the ciphertext, C′, C1,i, and C2,i are attribute ciphertexts for decryption, D1,i and D2,i are used for attribute authentication, and C v is used to verify the correctness of the outsourced decryption calculation. Then, the ciphertext will be sent to the cloud server for storage.
End users who want to request data from the cloud server need to obtain system access authorization first. The end user’s access authorization is achieved through the attribute authorization center issuing keys related to their attributes to the user. The following is the detailed process of the key generation algorithm [21].
Key generation
When an end user whose user identifier is uid wants to access data, the private key belonging to the end user is first obtained from the relevant AA.
The difference from the traditional scheme is that in this scheme, when the authorization center AA aid assigns an attribute set Said,uid to the end user EU aid ,
AA aid must first perform an attribute conversion algorithm to anonymize each attribute in Said,uid to obtain an anonymous attribute set S′aid,uid, and send the set to the cloud server. On the cloud server, S′aid,uid associated with the user identity identifier uid will be stored in the attribute database belonging to EU aid . When the user requests decryption, the proxy server will read the anonymous attribute related to the user from the database.
For each attribute x ∈ S′aid,uid, AA
aid
generates an attribute authentication key:
Then, AA
aid
calculates separately
Thus, the proxy decryption key is obtained:
Finally, AA
aid
chooses a random number σ
uid
∈ Z
p
and calculates the user decryption key belonging to EU
aid
:
After completing the above calculation, AA aid sends the user decryption key USK uid to EU aid , and sends the key set {ProxKaid,uid, UAKx,aid} to the cloud server.
Through the above process, user EU aid is authorized to perform data access according to the permissions corresponding to his attribute set.
When an end user whose user identifier is uid initiates an access request, PS needs to read the user’s attribute set and proxy key from the cloud server. In order to prevent illegal users from maliciously requesting proxy decryption and occupying PS’s computing resources, in this solution, the CSP will first run the attribute authentication algorithm to match the correct anonymous attribute and proxy key for the user, and then run the proxy decryption algorithm after passing the authentication. The ciphertext is decrypted, and finally the plaintext is recovered by the user.
The following will introduce the details of attribute authentication, proxy decryption, proxy decryption result verification, and user decryption algorithm.
Attribute authentication
After receiving the data access request, the CSP selects the constant set {c
i
∈ Z
p
} to make ∑c
i
A
i
= (1, 0, ⋯ , 0). The following calculation is performed to obtain the authentication result indicator:
When v uid = 1, CSP finds the attribute set S′ uid matching uid and the relevant proxy key, and then sends it to PS. PS executes the proxy decryption algorithm; otherwise, v uid ≠ 1, it failure to match the correct anonymous attribute and proxy key indicates that the request was maliciously initiated by an illegal user, and CSP will reject the request.
Proxy decryption
The prerequisite for proxy decryption algorithm execution is v
uid
= 1. When the conditions are met, PS chooses the constant set
Then the partially decrypted ciphertext is calculated:
Then the PS sends the obtained agent decrypted ciphertext to the user.
Proxy decryption verification
Since the proxy server is semi-trusted, part of the decrypted ciphertext may be attacked when it is sent to the end user, so that the part of the decrypted ciphertext received by the end user is wrong, and the correct plaintext cannot be recovered. And once this happens, the end user cannot know.
Therefore, the scheme in this chapter proposes a verification method for confirming the correctness of partially decrypted ciphertext. The specific process is as follows.
The input is ciphertext CT and partially decrypted ciphertext CT′. The user calculates whether the following equation holds:
If the equation holds, then we set v Proxy = 1, which means that the result of the outsourcing calculation is correct. Otherwise, v Proxy = 0, which means that the proxy server returned the wrong part of the decrypted ciphertext.
User decryption:
After receiving the CT′, the end user uses the user’s decryption key USK
uid
to perform the following calculations:
Then the user runs the proxy decryption verification algorithm to get the verification result v
Proxy
. If v
Proxy
= 1, it indicates that the decryption result of the proxy is successfully verified, and the end user performs the following calculations:
After the above calculation, the user gets the data plaintext M requested for access.
User revocation:
When the cloud server receives the user’s cancellation instruction (a user’s user identifier uid), the key set {ProxKaid,uid, UAKx,uid} and attribute set S uid belonging to the user will be deleted from the corresponding database on the cloud server to obtain the updated proxy key and attribute list (L′ K , LS′attr).
After the two pieces of data are deleted, the proxy server cannot obtain the corresponding key, and cannot perform outsourced decryption. Therefore, the end user will not be able to obtain part of the decrypted ciphertext, and the plaintext cannot be recovered. In this way, the user’s access rights are revoked. In addition, the user does not need to update the key and re-encrypt the ciphertext during the revocation process, so it is very efficient [21].
(1) Data decryption calculation
For i ={ 0, 1, 2, ⋯ , n }, Σiωiλi = s is known. Then
Therefore
(2) Attribute authentication calculation
According ω
i
= A
i
· ω, we can know that ω · (1, 0, ⋯ , 0) = 0. Then,
In summary, this solution satisfies the correctness.
Next, the security analysis of the program is carried out, which mainly includes access policy hiding analysis, data confidentiality analysis, anti-collusion analysis, and CPA security certification.
(1) Access policy hiding
This solution has designed a method of escrow and authentication of anonymized attributes on the basis of anonymization of attributes, so as to realize the privacy protection of the access policy more safely. It mainly includes the following two aspects.
1) Attribute anonymization
In this scheme, a one-way anonymous key agreement protocol is used to anonymize each attribute x to x′ = e ((g φ uid ) ψ aid , H (x)). Due to the confusion of index ψ aid , without key material H (x) ψ aid , no entity can derive x through x′. Before AA publishes attributes, each attribute is anonymized by an attribute conversion algorithm, and after the attribute is published, it will be stored securely in the cloud server.
2) Anonymous attribute authentication
This scheme designs an attribute authentication algorithm, and introduces authentication materials D1,i, D2,i, and H (uid) in the ciphertext and attribute authentication key, respectively. There is an intermediate result of e (H (uid) , g1) ω i during the authentication process. Only when the identifier uid of the end user requesting decryption is the same as the uid contained in the key material can the authentication result v user = 1 be calculated. At this time, the verification is successful, otherwise the verification fails, and CSP cannot start the proxy decryption service. This ensures that the anonymous attribute hosted on the cloud server can be correctly matched with the user, thereby ensuring that the PS only responds to the decryption request of the legitimate user. The process of attribute authentication is secure, and at the same time, this process does not reveal any information about user attributes.
In short, on the one hand, this solution anonymizes user attributes and access policies; on the other hand, for this anonymized attribute, this solution designs an authentication scheme to ensure the verifiability of the attribute. In this way, it is ensured that the attribute information is not leaked, and the efficiency and security of the data access system are not reduced. Therefore, this solution meets the privacy protection of the access policy.
(2) Data confidentiality
For illegal users, as described in the attribute verifiability analysis described above, they cannot pass the user authentication process, so they cannot request the anonymous attribute set promulgated by the AA from the CSP and cannot perform the proxy decryption process. It is impossible to restore the ciphertext to the correct plaintext, thus ensuring the data confidentiality of the system.
For users whose attribute set does not satisfy the access policy in the ciphertext, ω i ∈ Z p cannot be found to make Σiωiλi=s. Analysis of the correctness of decryption calculations shows that users who do not meet the access policy will not be able to complete the proxy decryption operation and will not be able to obtain part of the decrypted ciphertext. So that the final decryption cannot be completed.
Common consensus mechanisms are classified according to the application scenarios of public chains, alliance chains, and private chains. This section mainly classifies consensus mechanisms from the scope of the consensus mechanism. The consensus mechanism is a mechanism that the blockchain system relies on to achieve consistency, and all participating nodes will be in the node pool. According to the role of the node, the consensus mechanism can be divided into three parts: transaction consensus, accounting consensus and verification consensus, as shown in Fig. 1. 1. Transaction consensus: The transaction node first processes the transaction on the blockchain, changes the read and write status of the transaction, then generates a transaction request to execute the smart contract, and broadcasts the transaction request to the blockchain network. 2. Accounting consensus: After receiving the transaction request, the accounting node executes the smart contract according to the transaction request, stores the resulting contract execution result and transaction request in the brought-out block, and broadcasts the block.3. 3. Verification consensus: After the block is broadcast, the verification node verifies the rationality of the block. Generally, it takes 6 blocks to verify. If the block is legal, the block is valid, and the block is on the chain.
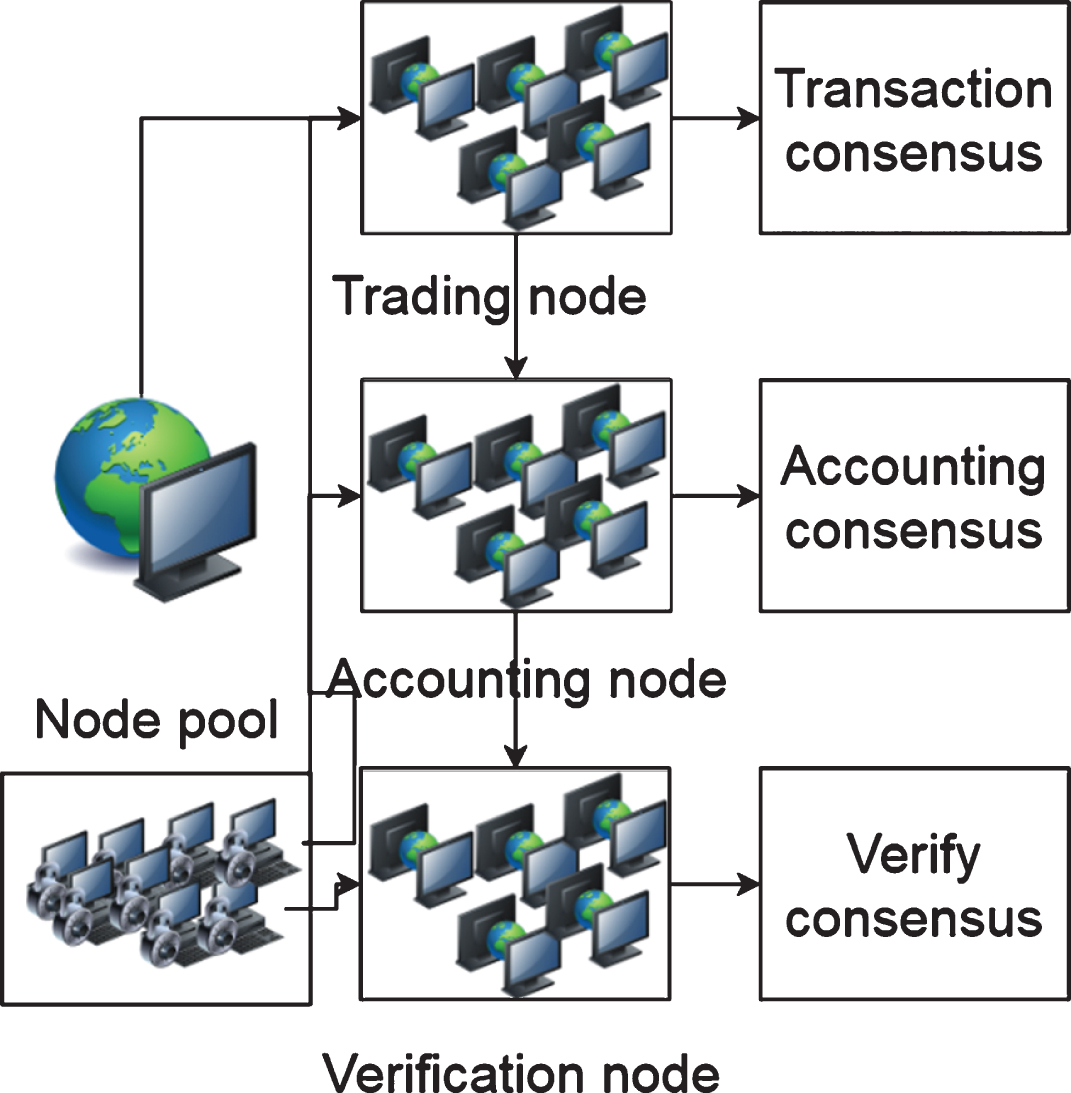
Classification of consensus nodes.
We classify the existing main consensus mechanisms according to transaction consensus, accounting consensus and verification consensus, as shown in Fig. 2.

Classification of consensus mechanism.
For the hierarchical verification processing of transaction information, the system architecture is shown in Fig. 3, which mainly includes five parts: users, transaction consensus, accounting consensus, verification consensus and blockchain.

System architecture.
In this process, in order to achieve transaction consensus, accounting consensus and verification consensus, we adopt a supervisable consensus mechanism based on improved DPOS+PBFT.
The scheme based on multi-channel off-chain transaction processing is shown in Fig. 4, which mainly includes 4 modules: user, smart contract, miner and blockchain.

System structure diagram of transaction processing in multi-channel chain.
The blockchain ledger is the core of the model, and has the characteristics of openness, transparency, and tamper resistance. The list of transactions screened by the miners is connected through the Merkle tree in the blockchain ledger. If the total number of transactions is assumed to be n, the specific process of processing n transactions is as follows: (1) We assume that T = T1,T2,⋯Tn is transaction information; (2) H(T) = F(H (first half of T), H (second half of T)); (3) H is a hash function, and F is a one-way function;4. In the blockchain, H = F = SHA256. Note: When n is not an index value of 2, the half-hash transaction can be directly uploaded from the hash value corresponding to the child node to the hash value corresponding to the parent node. The formation of Merkle is shown in Fig. 5.
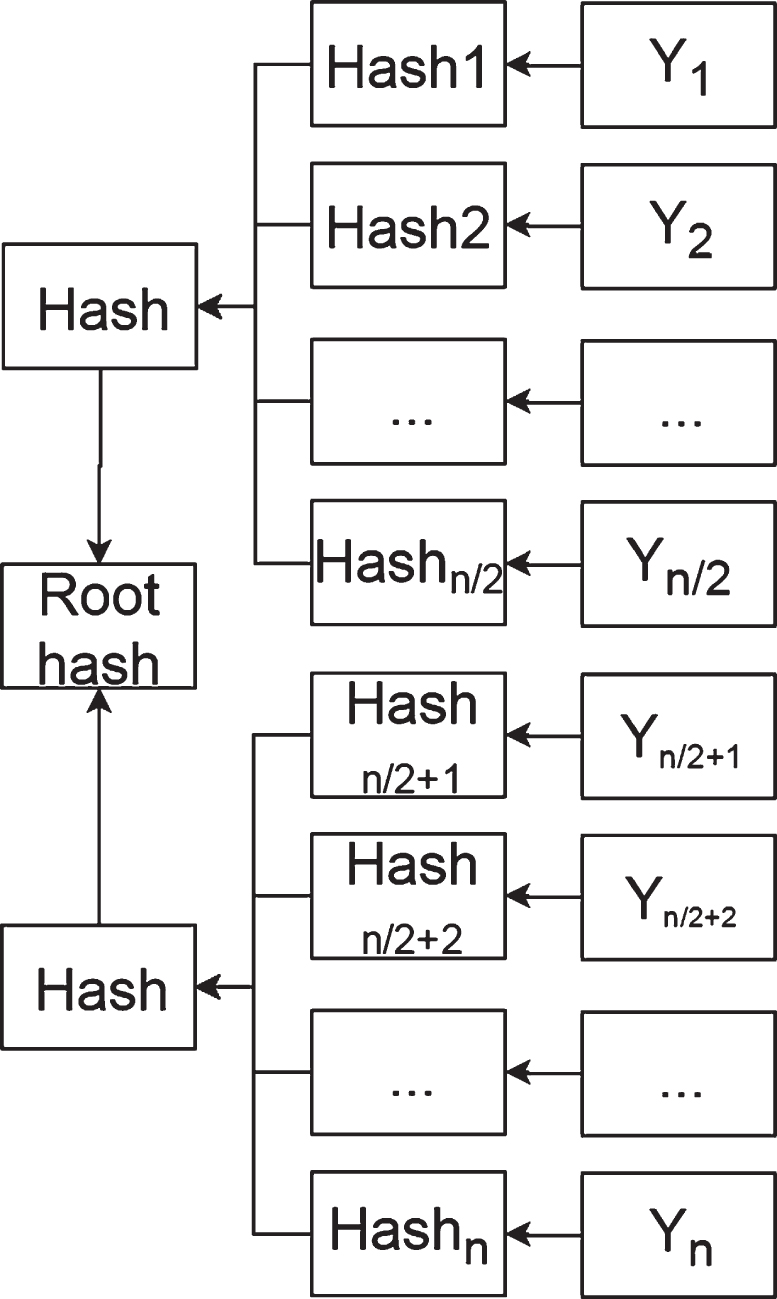
Merkle formation process.
Multi-channel and single-channel based HTLC are combined, as shown in Fig. 6. Because the principle of each channel is the same as the HTLC of a single channel, both need only use the same random number R and hashed number H(R).

Multi-channel HTLC transaction structure diagram.
If A wants to pay 1.5 BTC to B through the three channels above, each channel pays 0.5 BTC to B. At this time, the assumed handling fee is 0.01 BTC, and the actual handling fee for third parties is much lower than this. The transaction process is shown in Fig. 7, which ensures the security of the transaction process.

HTLC transaction process diagram.
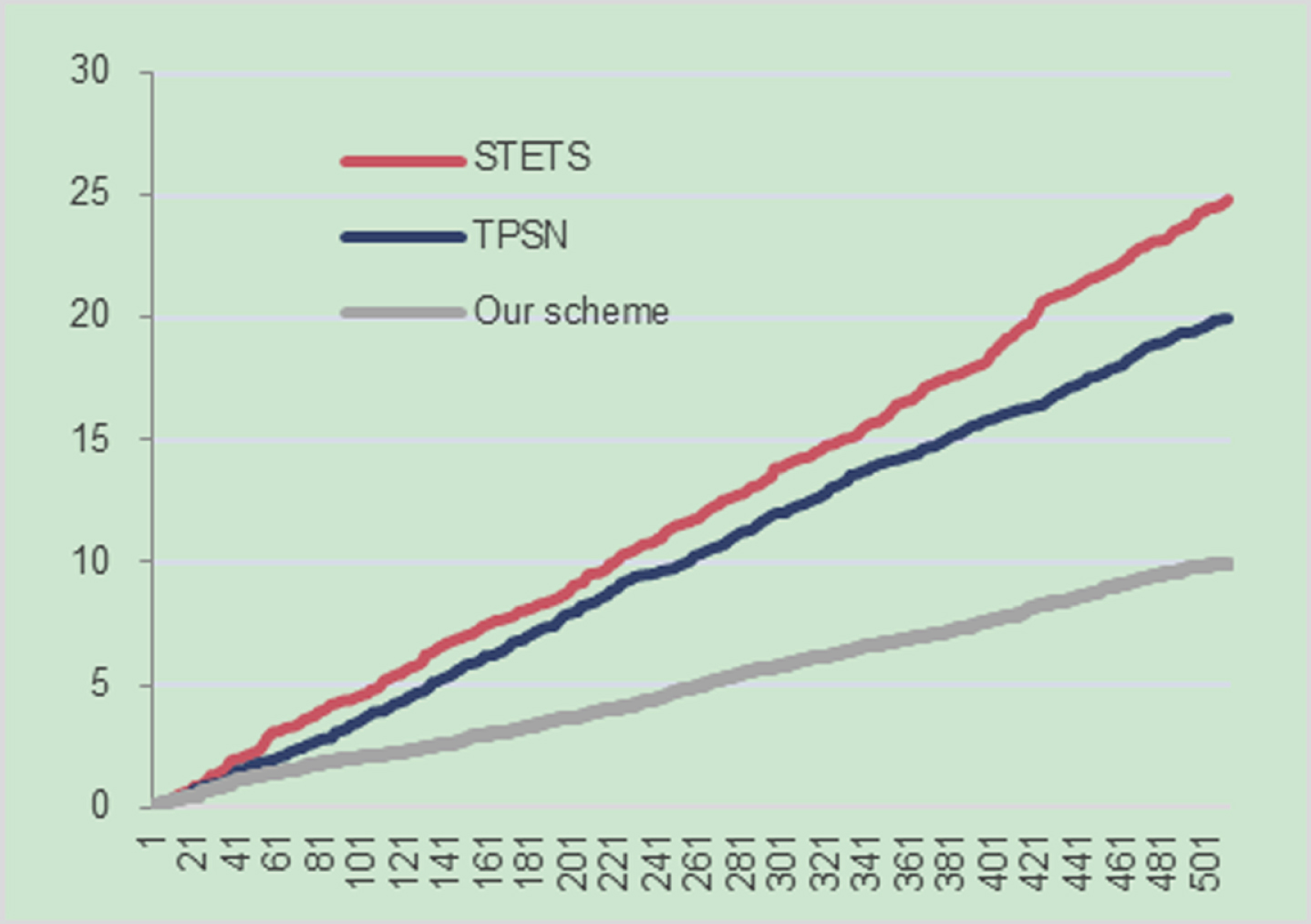
In the process of time synchronization, if the adjacent node of the time source is a malicious node, it may cause a very bad impact. Since the subsequent nodes cannot distinguish the time received from other nodes by themselves, they need to seek the help of the system. If the system cannot help the node to identify the time inaccuracy, the node will have a time synchronization error, which may affect the time synchronization accuracy of subsequent nodes. We assume that some neighboring nodes of the time source are malicious. According to the difference between the malicious nodes and the time source, the analysis system may be affected. We compared this scheme with STETS and TPSN, and then analyzed the safety performance of this scheme through simulation results. The results are shown in Fig. 8 and Table 1.

Comparison diagram of different system security.
Comparison table of different system security
Considering the consensus process and the convergence process are two independent processes.The simulation results show that when the number of nodes and the number of devices increase, it will lead to an increase in the convergence time of our scheme. In distributed time synchronization mode and flooding time synchronization mode, normal neighboring nodes can only synchronize with four nodes. In our solution, time nodes can synchronize with up to 200 nodes or devices at the same time. When the number of nodes is less than 200, the distributed time synchronization protocol requires multiple hops between nodes to complete time synchronization. In addition, the more hops required, the longer the time required. In an ideal situation, our scheme only needs one round to achieve time synchronization, which makes our scheme converge faster. When there are too many time nodes and terminal devices, the broadcast efficiency of time nodes will become one of the key factors limiting the convergence time. If the number of nodes requiring synchronization time in one round is greater than 200, then the time node needs another round to synchronize the time of the remaining nodes. The greater the number of time nodes or terminals to be synchronized, the less obvious the advantage. We conducted an experimental simulation on the computer, and the measured data is shown in Table 2 and Fig. 9.
Comparison table of convergence time of different systems (Partial)
Comparison diagram of convergence time of different systems.
Blockchain model infrastructure,How to choose a reasonable consensus mechanism for different application scenarios, how to ensure system security and efficiency, and how to effectively solve the network congestion problem when the block capacity is limited have become some of the first problems to be solved. The accurate time distribution and protection scheme of the Internet of Things based on the blockchain is to ensure that the synchronized time is real and effective through the consensus mechanism of the blockchain. Moreover, it relies on the verifiable characteristics of the distributed ledger to ensure that the node will not maliciously tamper with the precise time to affect the time synchronization.
This article focuses on the privacy protection of the ciphertext strategy in the CP-ABE scheme, and protects the privacy information of the access strategy by designing appropriate ciphertext and key structures and access structure forms. Moreover, this study improves the system efficiency by computing outsourcing, and proposes solutions to the problems in outsourcing computing, and constructs two efficient and flexible multi-authorization center access control schemes that support policy hiding. The time service system in the scheme allows multiple time sources to provide time services for blockchain systems in different application scenarios. After simulation and analysis verification, it is found that the scheme has excellent performance.
Footnotes
Acknowledgments
This work was supported in part by Key Research and Development Program of Shandong under grant 2019GNC106034, in part by Facility Horticultural Laboratory Funding Project in Shandong universities under grant 2019YY003, and in part by Weifang University of Science and Technology Doctoral Fund Project under grant 2017BS19.”