
Abstract
Based on the cloud computing artificial intelligence model, the English interactive teaching model summarized and analyzed in an in-depth manner, the characteristics of the smart classroom explored, and the interactive teaching model reform practiced. This article has studied and analyzed the classic teaching model. Finally, based on constructivism, the advantages of the constructivism teaching model, cooperative teaching model, and mastering learning model selected to construct the teaching model of artificial intelligence courses. Through the questionnaire survey of the current teaching status of artificial intelligence courses, and the investigation of each link of the constructed model, according to the results of the survey to optimize the construction of artificial intelligence courses teaching model to make it more perfect. Based on the cloud computing technology, the system architecture and function module division of the network open class platform designed based on the overall needs, and developed and implemented on this basis. Through global and local two-level authentication, user information synchronization, and interconnection between homogeneous clouds, the identity management function realized. With the help of the e-schoolbag function, the learning results continuously and accurately evaluated, so that every learner can get a good learning experience.
Introduction
Technological progress and knowledge renewal are like gears that never stop. They are turning faster and faster, making people under tremendous invisible pressure in the changes in this rapidly changing era. To seek adaptability to social changes, people must not only live until they learn well but also cultivate individuals to adapt actively to changes in the social environment to relieve pressure and arm them intellectually and spiritually [1]. However, after going out of school, social needs, and the rhythm of life, it has become a luxury to have a special time to replenish knowledge for yourself, so it is the best choice to use the fragmented time to meet your own knowledge needs. The convenience of open educational resources in the information environment is in line with people’s need to use the debris time to get opportunities for further education in first-class schools. The popularity of the Internet and the function of curriculum recurrence have enabled education, learning, and discussion to cross time and space barriers [2]. With the development of modern technology, artificial intelligence (English name Artificial Intelligence, referred to as AI) has slowly entered all aspects of social life, involving in various fields, the rise of AI will not only have a great impact on our society, but also It has caused changes in the economic structure, social ecology and work, and this will also have an impact on the pattern of world economic development. As we all know, artificial intelligence will play a decisive role in global development [3]. At present, artificial intelligence has attracted attention and attention on a global scale. Many countries have listed AI as a national strategy and issued relevant policies and rules to occupy the commanding heights of AI development [4].
Dai S and others believe that this new learning model is to make full use of modern teaching techniques to meet the personalized learning style and then to achieve the personalized customization of teaching to achieve the best teaching effect [5]. Kong F believes that traditional learning and blending There are big differences between the two modes of learning, the former needs to go through five modes during the transition to the latter, namely the supplementary mode, the central market mode, the buffet mode, the substitution model and the completely online mode [6]; Kong J and others believe that hybrid learning The model is to combine distance education and face-to-face teaching [7]. It is not required to use web pages for teaching in the classroom, but to integrate face-to-face teaching and online learning to the greatest extent, fully combining the advantages of the two [8]; Zhao N believed that adopting the hybrid learning model can help the communication between teachers and students [9]; Alam A believes that adopting the hybrid learning model is to use various advanced technologies to integrate the expected goals [10]; Shen C et al. proposed the “5 R definition” In their view, blending is a combination of five aspects of the learning model, namely technology, object, knowledge and skills, time, and learning style, to achieve the best teaching effect under this condition [11]. Li S surveyed the hybrid learning model. From the survey results, this learning model will show different effects due to the differences in the disciplines of learning. This discovery has caused widespread concern among scholars [12]; Liu D builds a model based on a hybrid learning environment to study the relationship between student satisfaction and needs and recognizes learning outcomes and motivation [13]. Han J F studied the social network of college students in a mixed learning environment and analyzed the impact of perception and knowledge building level on actual teaching [14]. Fan J H explores the usability factors in a mixed learning environment and studies the impact of external support on college students using the Moodle platform [15]. Qiao F believes that under the hybrid learning model, the course design process needs to consider the students’ subjectivity, putting the students’ feelings first, and analyzes the status of the curriculum design under the hybrid learning model [16]. In essence, the blended learning model is to use Internet technology in teaching to improve the teaching effect and ensure that the teaching purpose can be easily achieved [17]; Zou D believes that the blended learning model mixes multiple learning methods, including discovery learning, autonomous learning, acceptance learning, and collaborative learning [18]; Hwang G J believes that under the hybrid learning model, teaching with the help of a network platform will have an impact on performance, and analyzes the influencing factors, summing up the three most important influencing factors, the technical characteristics of the network platform, the complexity, and structure of the learning task [19]; Shuo C builds a model to analyze student satisfaction with the hybrid learning model, and believes that the direct factors affecting student satisfaction include three points, respectively It is the learning atmosphere, learning motivation and interactive behavior [20].
In the field of education, technologies such as artificial intelligence education platforms are becoming increasingly mature. The use of artificial intelligence technology to promote education and teaching reform to meet the development of education modernization has become a broad consensus in the education industry. With the continuous development and progress of network information technology, the hybrid learning method has attracted more and more attention and attention. The information age has provided a broad development space for hybrid learning [21]. Therefore, it is of practical significance to apply the hybrid learning model combining the intelligent learning platform and traditional teaching to English teaching in high schools to reform the traditional teaching model. This article takes ordinary high school English course teaching as the research object, uses intelligent tools, and adopts a mixed learning model in teaching so that students can use the intelligent platform to pre-train online before class so that they can occupy an active position in the classroom and start with the teacher. Good interaction, use platform online resources for efficient review after class, fully integrate the advantages of online and offline teaching, and achieve a hybrid learning model. Doing so can better enable teachers to have more innovative practices in English teaching so that students have a strong interest in English learning and improve learning efficiency.
Cloud computing artificial intelligence interactive teaching design
Cloud computing artificial intelligence model analysis
The originally required Information Technology (IT) resources are virtualized into a cloud and presented to users in the form of services. In the cloud computing architecture, the old self-reliance informatization technology has been transformed into a clear division of labor, collaboration, and mutual assistance operation mechanism, users no longer need to rectify and allocate information resources [22]. Users can request from the pool according to their own needs, and this process does not require manual interaction with the supplier. The operation is relatively simple, users only need to submit their service requests, and the cloud platform can be quickly allocated and deployed as needed. When users have resource usage requirements, they can use various terminals to obtain the required resources on the Internet anytime, anywhere. The resources requested by the user can be quickly expanded and released, and these operations are imperceptible to the user. For users, the available resources are inexhaustible and available on demand.
Synthesizing the solutions of several cloud computing service providers, the general structure is composed of four layers as shown in Fig. 1. The physical resource layer is the infrastructure layer of the architecture, which includes computers, storage devices, network devices, databases, and related software; the resource pool layer is a resource pool that integrates massive resources of the same type into a homogeneous configuration or similar to the homogeneous configuration, And integrate and manage it; the role of the management middleware layer is the big housekeeper, responsible for allocating resource pools so that all resources can maximize and safely support the use of the upper layer, and play a role in inheriting; service-oriented architecture (SOA) The construction layer packages its computing power into standard protocol Web Services, and puts it into the SOA architecture for deployment. Among them, the core part of the system is the management middleware and resource pool layer, and the function of the SOA building layer depends on the supply of external facilities [23–25].
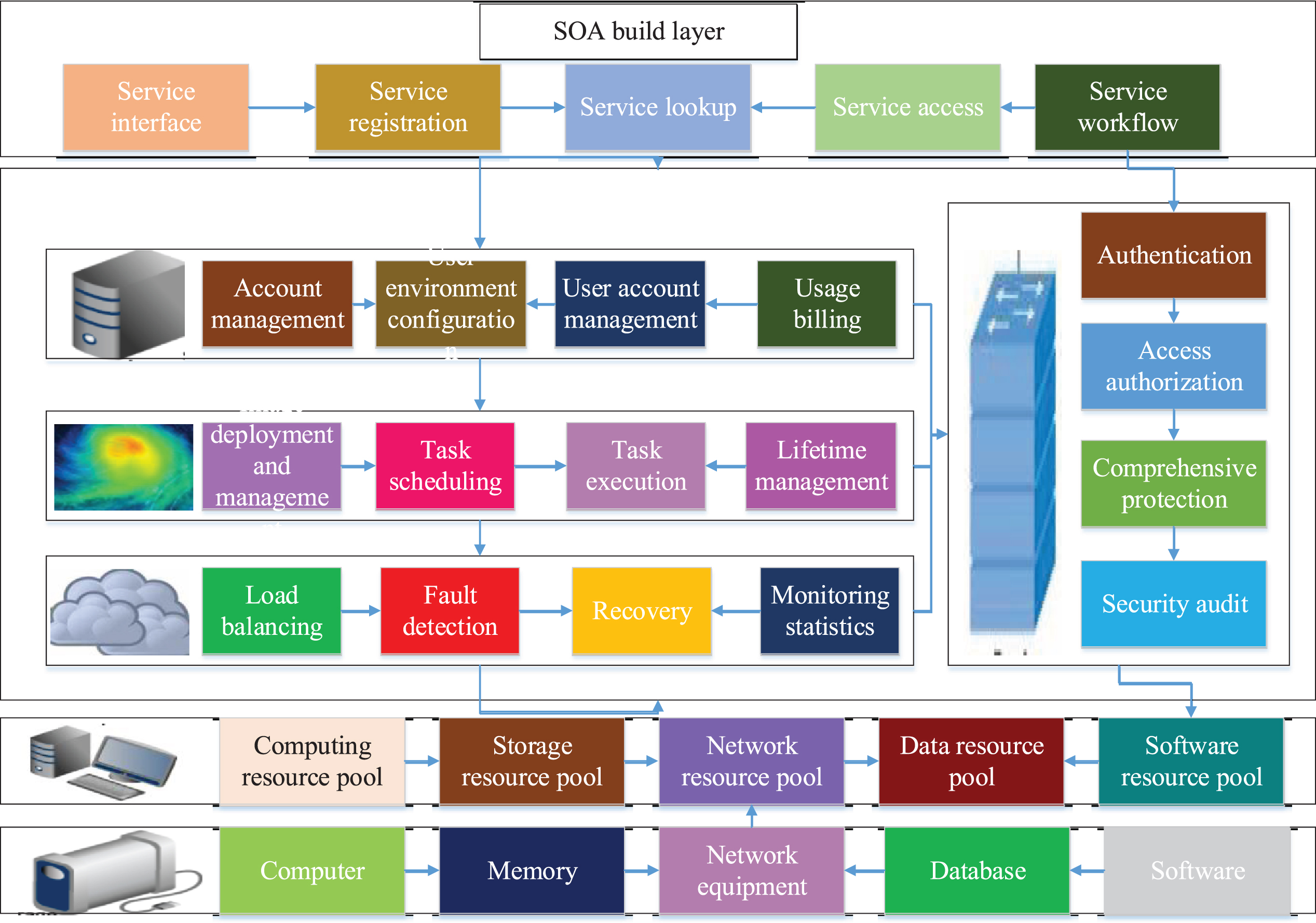
Cloud computing technology architecture diagram.
Use a controller RNN to get a sub-network structure in the search space, and then use this network structure to train on the data set and test it on the validation set to get the accuracy rate. The accuracy rate returned to the RNN for the next adjustment [26–30]. Continue to optimize to get the network structure, so repeat until the result of stable convergence, the entire process completes the neural network structure search. In this version of the neural network structure search, RNN only generates the size, number, and sliding steps of the convolution kernel, etc., and does not involve the network connection method. The parameter S in the controller is the variable that the RNN optimized and is passed to J through S, to maximize the expectation of this accuracy rate. Here, its calculation method is:
However, the accuracy rate is a discrete variable after each update, and it is not continuous, so it cannot be differentiated like a conventional CNN, so the author uses a first-order approximation to train this network. The approximate expression of this method is More convenient solution mode:
In this way, a DAG-like convolution operation obtained, but this formula is the same as the discrete structure we dealt with within the first two subsections. There are still no continuous values and differentiable expressions. The above relationship is remapped to other operations to complete continuity. Currently, the edge weights and operations of the neural network are vectorized into a continuous variable α. At this time, the operation of discretization into a continuous numerical form can be written as:
At this point, reconsider, if the operation and the weight assigned to a number at the same time, then the nature of this number is a network structure. Discretization is the existence of nodes and weights separately. Continuous operations put these two values on the same number, so the structure that combines these two points must be a network. With this network, you can move towards the goal at this time and derive the continuous value, you can find the optimal value based on this result, that is, the current optimal structure. Using gradient descent to solve the above network, we get:
The above form is almost the same as our gradient descent-based solution in the convolutional neural network, and then the calculation according to the relevant rules can correspond to a good α structure. In the actual implementation process, some optimization methods such as first-order approximation used to make the solution faster.
An important assumption to do this is that the channel subset can be used as an approximation to the full set. However, due to the randomness of sampling, the network training process may be unstable, so the Edge Normalization algorithm introduced to weaken the edge weights, and an additional set of edge selection hyper parameters added. Thanks to the partial connection strategy, the algorithm can increase the batch size. Selecting 1/q channel can reduce memory by q times accordingly. The batch size can be increased n times, and finally, the overall network accelerated m times, the training speed improved. At the specific implementation level, the algorithm proposes to directly set the channels passed to the output part to 0 using a mask, so that formula (3) can be rewritten as:
However, there are still problems in practice. Random sampling will make the network results unstable and cause large-scale oscillations, that is, the results are good and bad. On this point, there are many things in practice. If you analyze it theoretically, the reader can understand that under independent and identically distributed data, there will be periodic oscillations. If more samples are taken, the instability will also be reduced. This corresponds to the fact that in information theory, the entropy will increase when the information decreases. This entropy corresponds to a large-scale shock in the network. When this happens, it is not conducive to the network to search for the optimal solution in a larger local area, but it will fall into some non-optimal solution. To this end, this article proposes its solution, which is to add an edge regularization, so that the randomness reduced. It has been stated before that the operations on edge weights and nodes are vectorized into a sequence of values, that is, α, if you want to add regularization of edges, you need to display the edge weights in PC-DARTS, The visually redefined edges (i, j) are expressed as:
In the update process, the strategy evaluation completed first, and then the strategy improved. First, calculate the feedback value of all actions in the next state, and then select the optimal state (the difference in the formula is the selection process). For discrete problems, this method is feasible. However, for a continuous problem, it is no longer suitable, because it is impossible to list all possible strategies at this time. To this end, a gradient strategy update method introduced. The update method of the strategy gradient is:
According to the available literature, the gradient calculation formula of the random strategy can be written as:
A gradient update strategy is to select the action strategy as a random strategy to ensure sufficient exploration of various possibilities, and the deterministic strategy adopted for the evaluation strategy.
Using neural networks to approximate value functions and deterministic strategies. For deep neural networks, the loss function of action strategy and evaluation strategy is defined as:
According to the platform structure, it is divided into multiple levels, and the communication between each level is through the API so that the readability and maintainability of the system will be better, and the loose coupling will be maintained. Because the PaaS service directly utilized, the design of the IaaS layer is beyond the scope of this platform. As shown in Fig. 2, the platform divided into four layers: infrastructure layer, platform as a service layer, software as a service layer, and client.
Interactive overall architecture diagram.
The platform service layer plays a role of inheritance and can provide a variety of services based on the resources provided by the underlying infrastructure, and upwards provides the operating environment and basic support work for the application layer. It can support the dynamic expansion and fault tolerance mechanisms. Its services include Provides an interface for standard reference models of textbooks, basic data storage functions, consistently trusted identity verification, and question and evaluation standard models prepared by the US federal government. The textbook standard reference model provides a set of common specifications and interface services for the production and content development of digital teaching content or textbooks to meet the goal of courseware sharing. Structured and unstructured databases used for unified data management. Apart from the large space occupied by the course video files, there are not much management work required, so special interfaces selected for the course video files to achieve docking features.
The application service layer provides targeted services for applications, such as customized educational application services [31]. We provide external services such as website and related interfaces and provide an open platform Open API mechanism for subsequent expansion calls. Using cache technology can relieve system pressure when many users’ flood into the platform for access at the same time, improve system response speed and user experience.
Teaching evaluation needs an evaluation system that inherits innovative traditions to achieve student-centered status under the new curriculum standard. Smart classroom teaching evaluation can see the classroom teaching according to the students’ learning, and evaluate the students’ learning situation. The students’ learning divided into online and offline in the smart classroom. Online learning is learning on the smart cloud system platform, Offline learning is the classroom teacher teaching-learning. Formative evaluation and summary evaluation are traditional teaching evaluation methods in middle schools. This evaluation has a one-sided characteristic. Wisdom teaching evaluation is more abundant. The main body of evaluation changed from traditional teacher evaluation to student evaluation to multiple evaluations of teachers, students, students, and self-evaluation. The evaluation methods and contents have undergone more changes. The online evaluation mainly shows that when students use the intelligent platform to learn, the system will recognize students’ learning conditions, learning habits, preferences, and other behaviors. These data can provide students with personalized online evaluation. Offline evaluation is the evaluation of students’ actual learning actions. This includes teacher lectures, student learning tasks, discussion and exchange, cooperation and sharing, results reporting, teacher and student comments, etc. Although offline evaluation does not have accurate statistical data online, it is still very important for students’ classroom learning status, such as the popularity of participating in discussions, the attitude of attention and attention, and the results of completing tasks.
A total of 520 questionnaires published, of which 354 questionnaires were recovered, including 308 valid questionnaires. The total questionnaire recovery rate in this survey was 86.74%, as shown in Table 1.
Investigation and distribution and recycling
Research procedure design
At present, the “artificial intelligence preliminary” module is only open. From the perspective of learner analysis, a comprehensive understanding of all aspects of high school students’ qualities can better teach them based on their unique characteristics and explore appropriate teaching methods. Based on this, we will conduct a detailed analysis from the four aspects of cognitive development characteristics, skill characteristics, learning environment characteristics, and future development, to maximize the teaching effect as much as possible, and then better develop the personality of students to teach according to their aptitude.
Students who have grown up in the information environment, as “digital natives", could contact various information technology equipment from an early age in their growing environment. The use of information technology equipment is an indispensable part of their daily learning life. The generations who have grown up on the Internet and the digital environment have very different ways of thinking than digital immigration. Students who have grown up in an information environment have mastered the basic knowledge of information technology in the application of information technology in life and the learning of elementary and junior high schools. They can proficiently browse the web, search for information, download software, and use word processing. At the same time, you can connect information devices to the network and pay attention to the security of network information, as shown in Fig. 3.
Schematic diagram of interactive steps.
High school students who grew up in this environment can use the Internet to search for information and find information proficiently. At the same time, students at this stage can analyze and solve problems. Through the Internet, students can obtain themselves faster and more effectively. The development of the region and economic construction are inseparable from the planning of the development system of education informatization management. Effectively formulating a reasonable development plan is not only a region’s guarantee for the establishment of a high-quality education system but also work for the education informatization management of the region the full-scale development of China paves the way. Therefore, the education administrative department of Shijiazhuang City should further plan the planning of the basic education informatization management system, improve the establishment of the education informatization system, and reform the basic education informatization management system better and faster.
The core ideas of connectivity include four aspects: knowledge view, learning view, practice view, and innovation view. Knowledge built on each node, and maintaining the flow of knowledge is a key step. The ability to continue learning and access to knowledge is more important than mastering current knowledge; learning may exist in new learning equipment; learning needs to maintain each Connection between networks; the ability to see the connection between ideas and concepts in different fields is crucial. In today’s digital age, knowledge is constantly changing, and the proposition of the communist learning theory has brought great help to learners in the Internet age and has provided theoretical support and method references for the application of online learning space for college students.
A variety of learning resources plus reasonable and scientific design, and then arrange the learning tasks and learning forms. It designs after-school assignments and personalized counseling after class according to the characteristics of the knowledge points learned. Homework push: Homework is an extension of the classroom and in the process of learning and consolidating the knowledge learned in the class. The form and content of the homework pushed using the Sequoia intelligent platform. The form of the homework includes listening, speaking, reading, and writing. Compared with the previous teaching, the advantages of this model are more prominent. At the same time, homework questions can be kept on the student side, so that students can have enough time to think and improve the efficiency of students to consolidate review. After-class testing: Testing is an important method for feedback on learning effectiveness. After-class tests are based on multiple-choice questions. Objective questions generally distributed through unified examination papers. Teachers design examination practice in advance. The platform will automatically collect the examination papers after the examination time reached, correct the examination papers, and publish the statistical scores. Non-objective questions can only be completed online by the teacher. Personalized tutoring and learning: After the students conduct the after-school tests on the Sequoia Tree intelligent platform, teachers can conduct targeted one-on-one personalized coaching through the test situation and can send messages online to students for a certain knowledge point The explanation can also be explained offline, and the platform can also re-test the test based on the knowledge points that the student missed, improving the student’s proficiency in knowledge. Students can stratify their selective ability to improve learning or review basic knowledge according to their situation.
The evaluation of students’ learning not only observes students’ learning degrees and attitudes from one aspect. This model achieves the diversification of evaluation subjects and the diversification of evaluation methods through group evaluation, teacher evaluation, intelligent platform evaluation, etc. The purpose is to make evaluation non-uniform, and evaluation starts from the course to the end of the course. Evaluation is not the goal, but to reflect students’ learning status and inspire students to adjust their learning status and further study. Its advantage is to provide guidance and help to students’ learning, to achieve the improvement of learning effect. Online learning records the student’s ability to learn, the student’s learning effectiveness, the student’s score, and the student’s degree of homework completion. The platform will count every data of students in each stage. The statistics for each activity are very detailed. After the course completed, a table automatically generated and archived as a basis for evaluation. In face-to-face group mutual evaluation, teacher evaluation is mainly to evaluate students’ classroom participation, the number of student interactions, the degree of student learning and cooperation, and the display of students’ learning results.
As shown in Fig. 4, in this system, the management node acts as a relay station, communicates with the Client deployed in the application upwards, receives and feeds back the requested information; forwards the operation instructions downwards, and receives the status information of the child nodes; Management system metadata, file directory and file block information; feedback file metadata to the client. The data called by the user stored on a specific sub-node. When an application needs to access certain data, it needs to obtain the IP address of the sub-node first, and then create an interconnection with it to obtain the file metadata named after the user name. In this way, you can learn the stored data information, and then use the application program to establish a direct connection with the storage node of the data block to obtain the required information. A single file is composed of multiple blocks, and a single block is composed of multiple sectors.
Flow chart of system node evaluation.
In summary, we can know that the management node contains the following three aspects of information: one is the user name; the second is the IP address of the child node where the user name file is located; the third is the comprehensive information of all child nodes, such as IP address, total Information such as capacity and available capacity. The information in these three areas stored in the root.dat and node.dat files. The user name, the IP address, and port number of the node where the data configuration file is located stored in root.dat in user Info data format. The storage node’s IP address, port number, number of users, the total capacity of the node, and available capacity of the node stored in node.dat in the data format of node info.
The role of the child node is to process the read request sent by the file block from the application, find the corresponding path in the local file block table according to the file block code, and find the corresponding file block according to the path and output it to the Client; when processing the application When writing a request, the data is input to the specified file block, and the updated file block information is fed back to the management node. Receiving the instructions from the application and completing tasks according to the instructions are its main tasks. Specifically, it needs to complete the following five steps: get the data input request; add relevant information in the description of the file block; implement the writing and storage of the data block; Start the calculation function; complete the integration of storage and calculation.
Model performance analysis
Set up a 100 M LAN in the cloud infrastructure, connect the virtual machine to the LAN through the virtual gateway, the User Service performance test developed using three programming languages of C, C++, and Java, and calls the User Service. Record the response time of 200 calls to each interface and take the average cost value, as shown in Fig. 5.
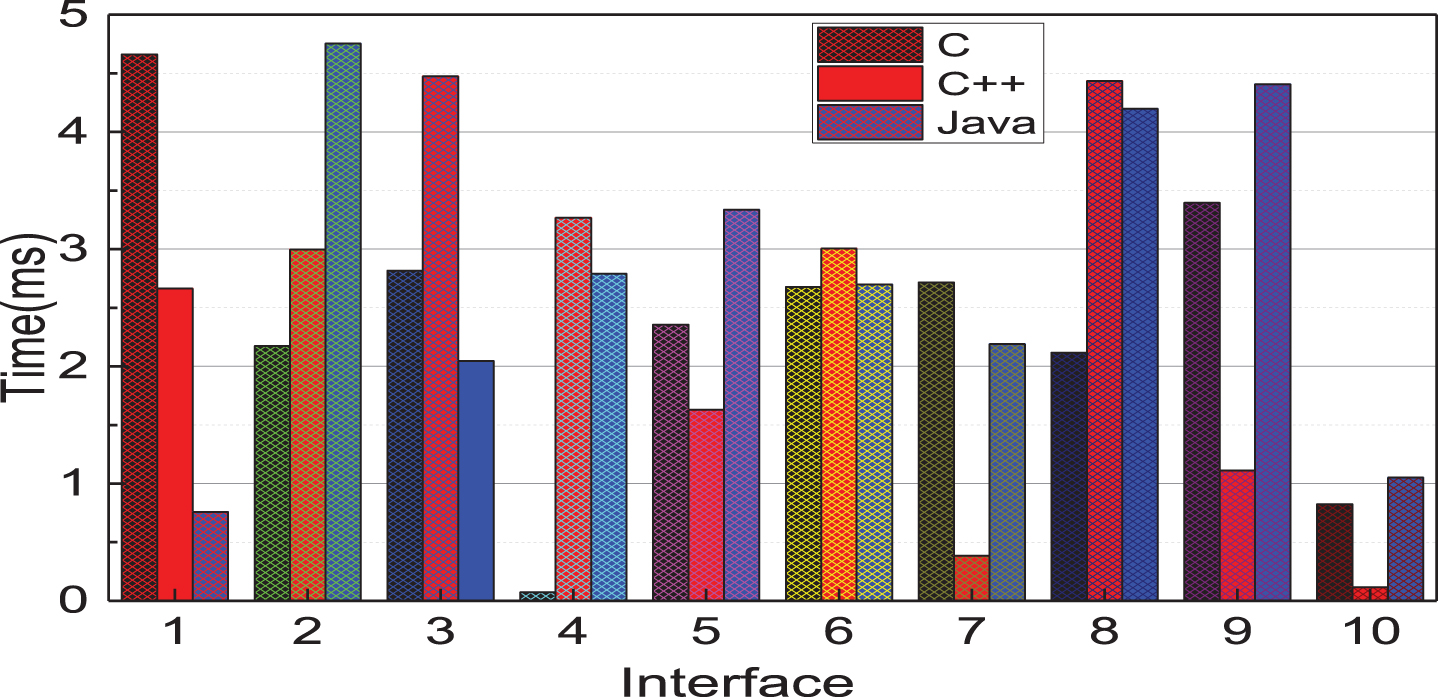
Average time of interface call.
Compare the performance of the local authentication mechanism (UNIX), LDAP, and PAM/NSS modules in the Linux OS environment, and analyze the impact of running PAM and NSS simultaneously on application performance. Figure 6 shows the average response time required to call the PAM/NSS module interface of this machine or log in to the SSH server of this machine 200 times.
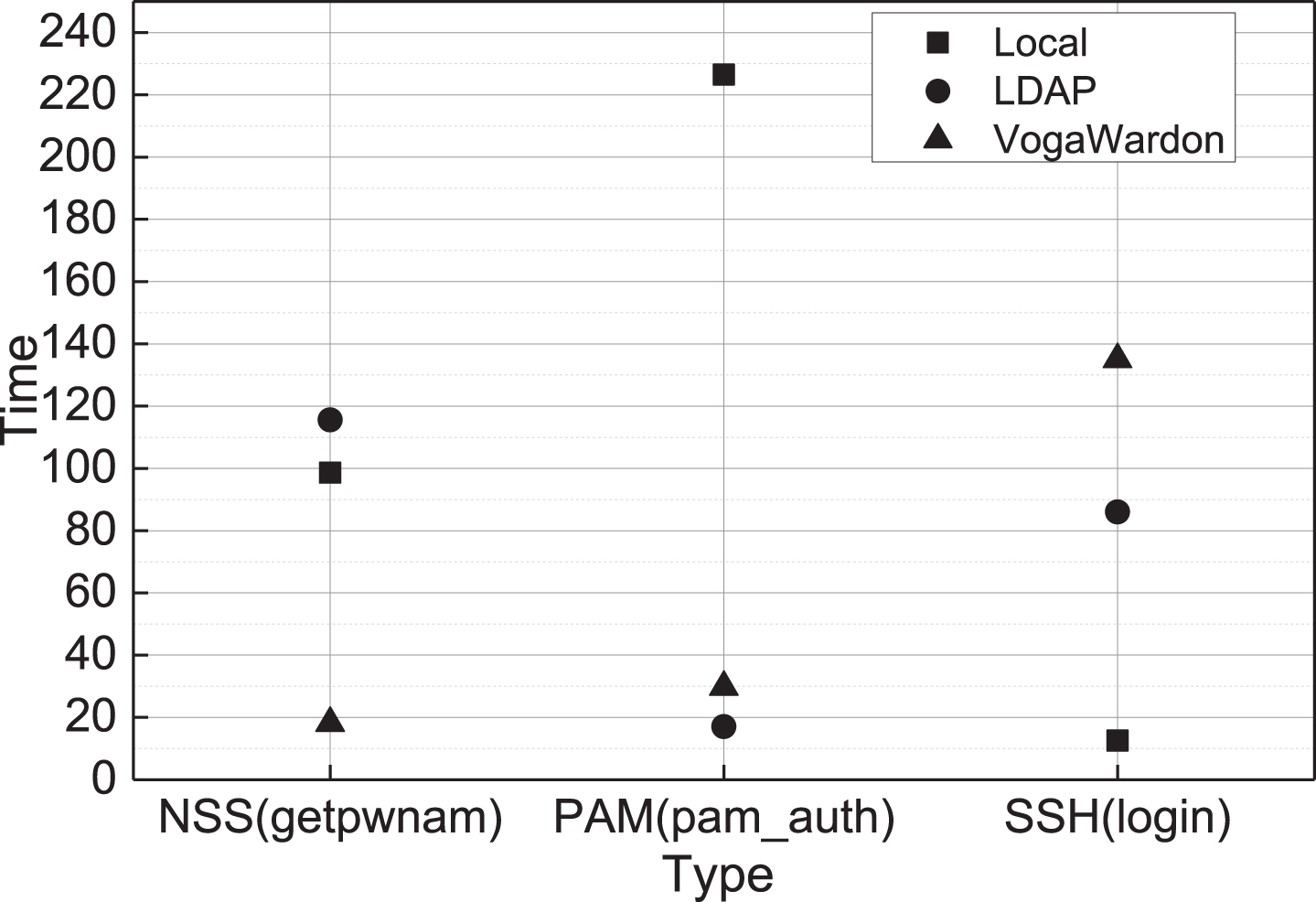
Average call time for login.
Set up eight virtual machines. SSH on all virtual machines verified using PAM/NSS. Local SSH login requests initiated on all virtual machines at the same time and 0–8 cycles run to connect to the same User Service. As shown in Fig. 7, 30 cycles of experiments were performed in the concurrent number interval, and the average time of SSH login request overhead time.
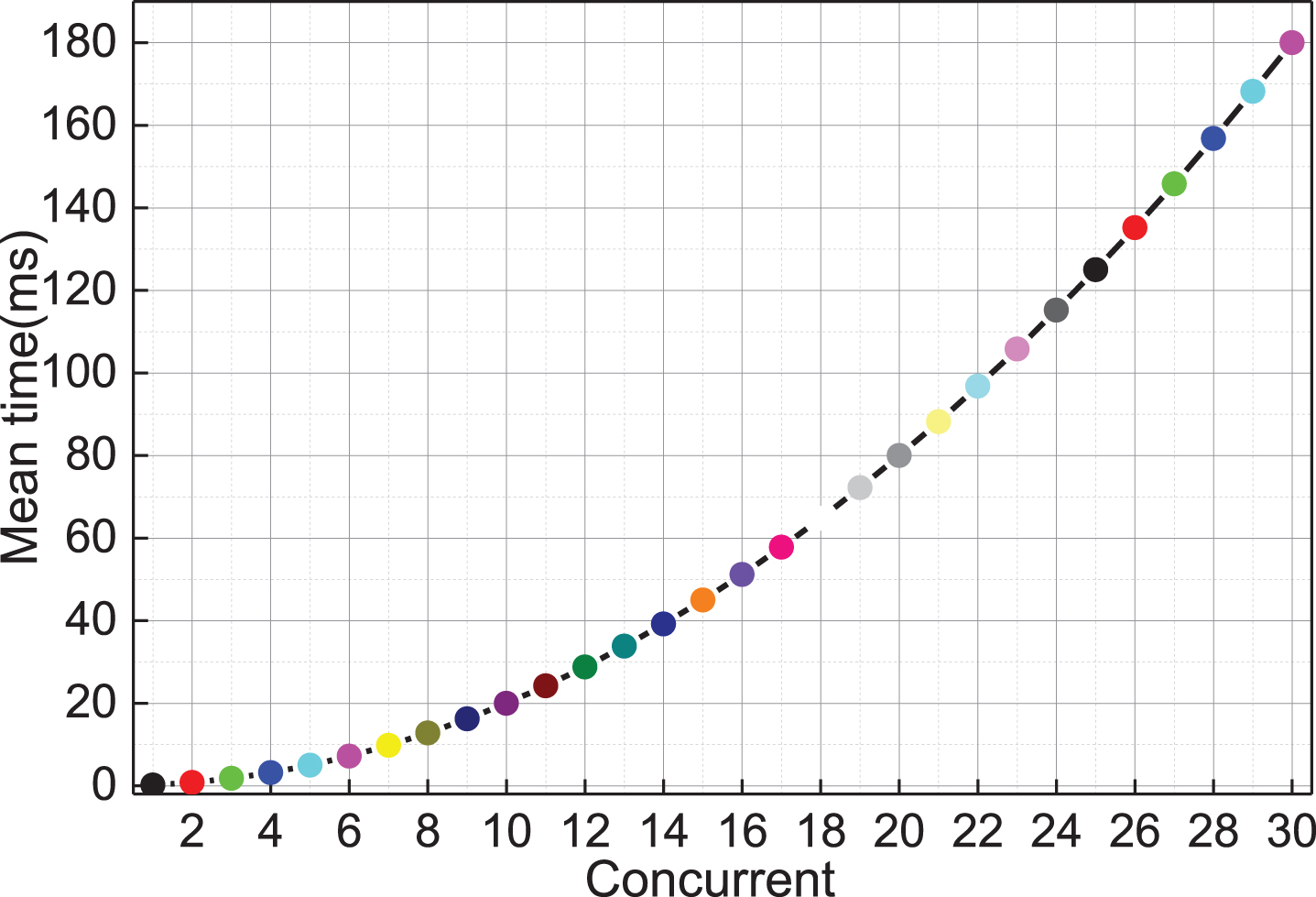
Average call time.
When the horizontal axis is between 1 and 16, the curve tends to be flat, indicating that there is no significant change in response time. When the number of horizontal axes grows from 12 to 24, the curve begins to slope and the response time begins to increase linearly. When reaching more than 48, the average response time is about 1.5 times that of 1 to 16 concurrent requests. As the number of concurrencies continues to rise, the system overhead shows an exponential upward trend. When 32 concurrent requests reached, the average response time has doubled. In the actual operating environment, user authentication requests not synchronized and only operate once during authentication, so their high-density concurrency risk is low. The test results show that it does not have high density and high concurrency, and is suitable for a cloud environment with a certain scale.
It can be seen from Fig. 8 that the average final grade of class 280 in the experimental group is 101.3, and the average grade of final class 292 in the control group is 96.3. The average grade of students in class 271 in 2018 is 5 points higher than the average score of class 292. It can be seen from Fig. 8 that the personalized teaching system based on cloud computing artificial intelligence divides the students’ scores into excellent [102, 120], good [84, 102), qualified [72, 84), and unqualified (0, 72). In the score section, in the final results of this period, the number of people in the experimental group in the excellent range is 28 higher than the 27 in the control group; the number of people in the experimental group in the good range is 27 is slightly higher than 20 in the control group; The number of people in the interval is 4 people slightly lower than 17 people in the control group; the number of people in the experimental group in the unqualified interval is 0 lower than that of the control group. Based on this, it can be seen that the number of people in the experimental group in the excellent and good sections is significantly more than that in the control group, and the number of people in the qualified and unqualified sections is significantly lower than that in the control group. To improve, we use SPSS 24 to scientifically test the above analysis.
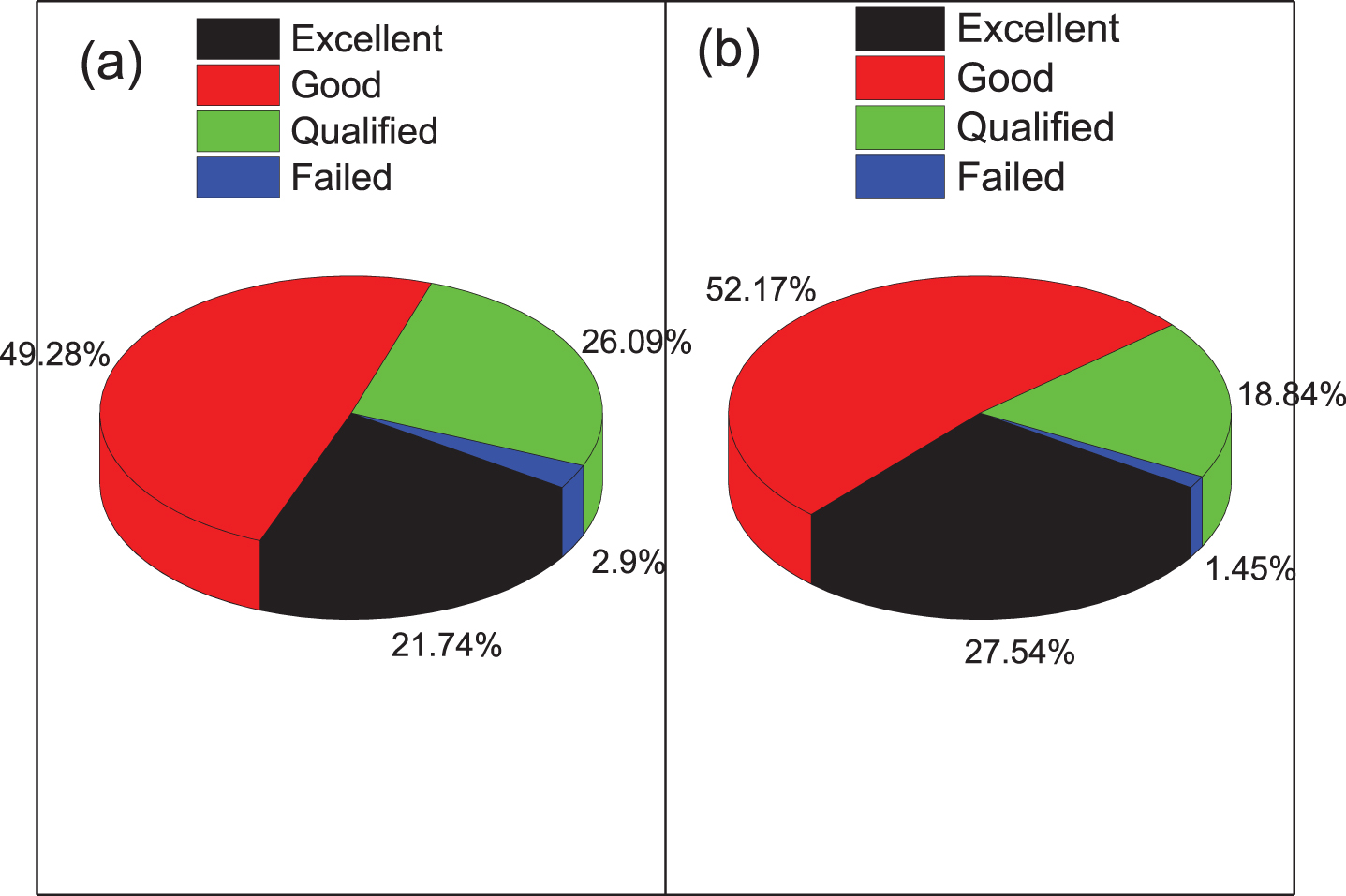
Comparison of the final test results of the experimental group and the control group.
To verify the scientificity and accuracy of the above views, and to analyze the results of the two classes, we used SPSS software to conduct an independent sample T-test of the class results. The specific analysis results are shown in Fig. 9.
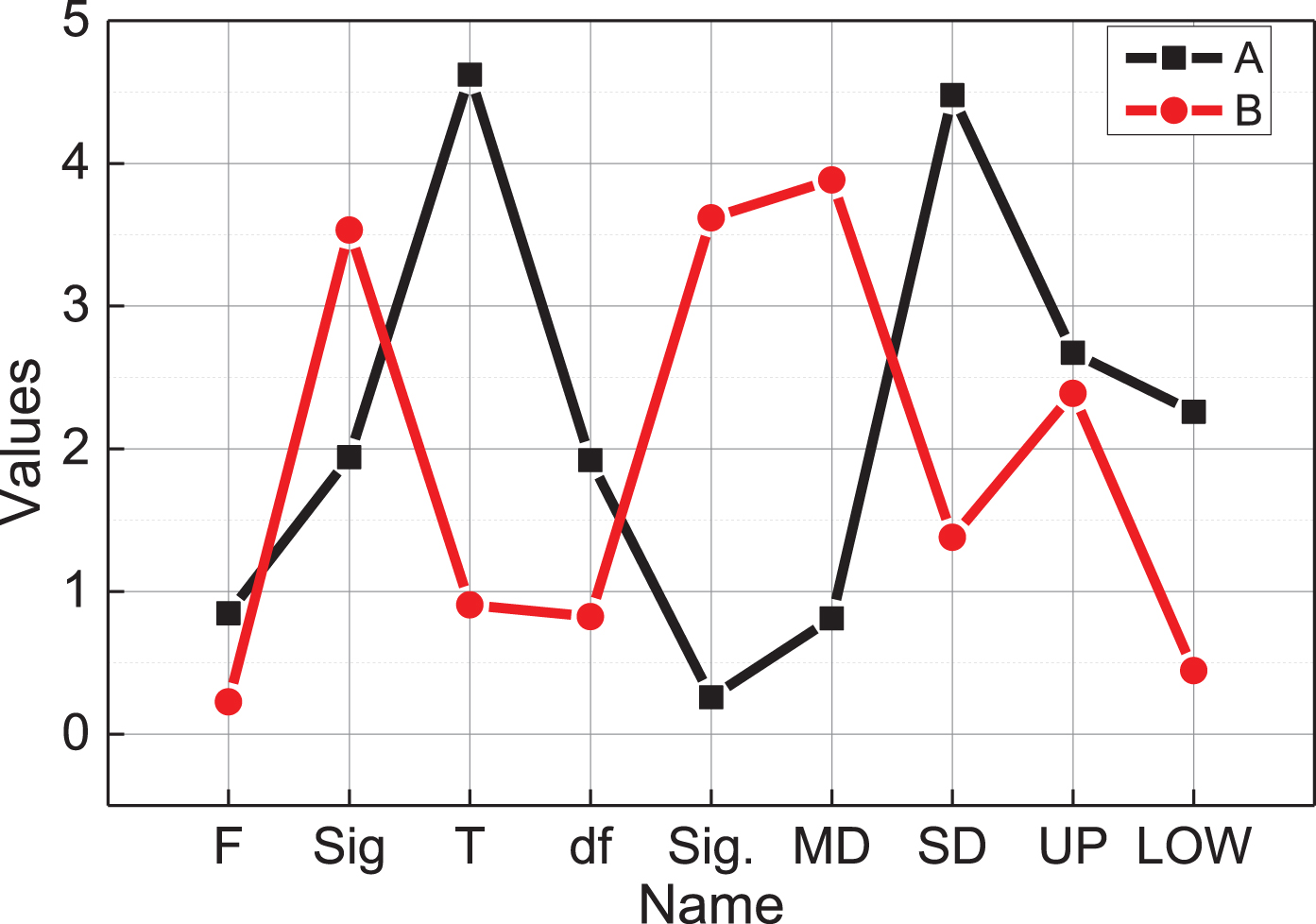
Group statistics and independent sample T-test results.
According to SPSS data analysis, the average final grade of the 279 class in the experimental group is 101.26, and the average grade of the 279 class in the control group in the final exam is 97.26. The average grade of the 279 students in the 2018 class is 5 points higher than the average score of the 279 class the independent sample T-test of SPSS software used to test the difference between the experimental group and the control group. The test results show that F = 7.046 P = 0.009 < 0.05, the variance is uneven. T-test results showed that: Sig = 0.048 < 0.05, indicating that there was a significant difference in the results of the experimental group and the control group. Even after using the cloud computing artificial intelligence personalized classroom teaching system, there are significant differences in grades, indicating that the cloud computing artificial intelligence-based personalized teaching system has improved the students’ math scores.
Through the analysis of the examination results and final examination results of the students in the experimental group and the control group, it can be seen that before the teaching of the personalized teaching system based on big data is applied without the application of the same teaching materials and learning content, The two groups are based on the examination results, and it can be concluded that there is no significant difference in the academic performance of the two groups. After applying the personalized teaching system to the experimental group, the final academic performance of the two groups of students tested. According to the comparison of the test results, it can be concluded that the experimental group’s academic performance is significantly higher than that of the control group. Significant differences have markedly improved the performance of students in the experimental group. The experimental results show that the personalized teaching system based on big data has a significant boosting effect on students’ learning.
Some other poorly performing networks will not be described in this article. The main reason: when too many structures embedded in the subnet, it will cause the subnet to learn hard and cannot obtain a better solution in further training. This point is also a reminder. When we design neural networks or let the network do a structural search on its own, a simple combination is often effective. The use of simple combinations may allow the network to play better performance. In the beginning, it fell into local optimization and no longer can be optimized. It can still be seen from the above table that there is always a “competitive relationship” between structure (V) and structure (VIII), that is, they are ahead of each other. To explore these two networks, this article does further analysis of the VOC2012 data set. Figure 10 explores the performance of these substructures.
IOU and F1 analysis results.
As can be seen from the above four pictures, the substructure proposed in this article has improved performance in both UNet and DFA. In UNet, the structure of this paper surpasses the original research results, and it shows good robustness during the training process. In the subsequent DFA experiments, the performance far exceeded the existing results. On a lightweight network (DFA-Net), the effect of using (VIII) is often superior to other structures, because the structure of the information sampling method is changed under limited parameters, that is, as many samples as possible in a single time, The information uses a large convolution kernel. On a complex network (U-Net), the effect of using a simple module makes it easier for the network to “jump out” of the local solution, resulting in better performance later. The inspiration for the design after this article is that the network is too deep to use a simple module, and the lightweight network uses a large convolution kernel module. This is very helpful for guiding a NAS network. The evaluation of this model is a process evaluation. The quantitative evaluation is mainly carried out by the Sequoia Tree intelligent platform for data statistics and recording. The statistical objects include teachers’ evaluation of the students’ learning status and learning effect. The qualitative evaluation includes the evaluation among the members of the group and the evaluation of the teacher’s performance during the teaching process. The evaluation process follows multi-agent participation and comprehensive and diversified evaluation.
In this paper, a cloud computing artificial intelligence model used to study the English interactive teaching model. Most students can accept the hybrid learning model based on the intelligent platform, and this model can improve the satisfaction of English teaching. Through the pre-class teacher release task book students use online intelligent platform resources to learn independently to break through the difficult and difficult knowledge; in-class teacher face-to-face student cooperative learning online smart platform limited-time test to master the learning content; after class students use the online intelligent platform to autonomously The review mode can improve students’ English performance and learning autonomy. The design starting point, overall framework, technical implementation route and architecture, business logic design, system deployment, and user identity management, e-book bag, and homework implementation methods of the network open class platform elaborated in detail. Finally, test some functions and interfaces of the platform designed in this article to confirm whether it meets the original design requirements. As new educational concepts continue to be known and accepted by everyone, the system designed in this paper will be widely adopted and applied. With the advancement of technology and the development of people’s expectations, this research also needs to be continuously upgraded and iterated to meet people’s expectations.
Footnotes
Acknowledgments
This work was supported by The Higher Education Teaching Reform Research and Practice Project of Hebei Department of Education: The Teaching Reform of College English Majors under the Guidance of Ideological and Political Courses: Taking basic English as an example Project number: 2019GJJG495