
Abstract
Due to the explosive increase of data scale, the traditional database management technology can no longer satisfy and analyze these data. Data acquisition technology is a tool that can process data effectively. The research of data acquisition has produced many new concepts and methods, which enrich and improve the data acquisition technology and establish the theoretical system. The relevant extraction criteria are an important branch of data extraction and one of the most important research fields. The use of genetic algorithms to mine related standards has been widely used, but traditional genetic algorithms are easy to be used. Therefore, under the best conditions, the application of better genetic algorithm to mine the relevant standards is a key problem to be dealt with in this paper.
Introduction
With the rapid development of information technology, the ability to collect, store and process data will increase. As a result, the database will gradually expand and diversify, its scope of application is wider. The maturity of data management technology contributes to the computerized development of society and the modernization of public business services, including the rapid growth of information on the network, resulting in a large amount of data. Therefore, in order to analyze the large amount of data generated, the database has been expanded and widely used in business and science. With the development of database technology, database technology has also increased. Traditional database management techniques can not satisfy and analyze the hidden knowledge of these data because of their explosive expansion. it is obvious that database management technology is no longer able to process large data sets. therefore, data acquisition technology is the effective tool we want to process large volume data. we hope that this will help us to better understand the status of the data.
Data extraction is usually defined as a process through which a large amount of data is collected to obtain information. At present, data acquisition plays an increasingly important role in all sectors, not only to describe the development process of past data, but also to determine the development model that can predict the results. In fact, from any point of view, knowledge is implicit information, it is necessary to classify the data when there is data. Therefore, with the development of science and technology and the increase of information, the classification of massive data is becoming more and more important.
The research of data acquisition has produced many new concepts and methods, which enrich and improve the data acquisition technology and establish the theoretical system. the collection of these standards is an important branch of data acquisition research. using genetic algorithms to mine relevant standards has been widely used, but traditional genetic algorithms are often the most suitable conditions. therefore, better application of genetic algorithms to mine relevant standards is a key issue to be addressed in this paper.
Related work
About the improved genetic algorithm, the literature [1] analyzed the phenomenon of convergence of traditional genetic algorithms. the reasons are mainly related to the selection of genetics, population distribution and problem allocation. it lists some individuals who can have a significant impact on convergence of genetic algorithms and combine the concept of the joint role of these individuals and environmental evolution literature [2] analysis combines traditional genetic algorithms into static optimization research through algorithm selection, intersection and mutation. the model theorem can not guarantee that traditional genetic algorithms follow the optimal approach when solving optimization problems [3] literature, the inherent algorithm parallelism of genetic algorithms is studied, and the choice to achieve this is summarized. Parallel genetic algorithms discuss the possible fields of general algorithm parallelism. Document [4] designed an arithmetic option with control parameters, introduced the concept and mathematical basis of the design, analyzed the relationship between arithmetic selection and control parameters, compared the weak defects of adjustment scale and global convergence used in the selection of arithmetic, and adopted the “power gradient method” to control the selection of selective arithmetic [5] the literature, some suggestions for improvement are put forward, which are based on the traditional genetic algorithm accumulated in the early stage, which recognizes the direction of evolution and uses this index to guide gene chromosome adaptation. A modified gene algorithm [6] developed in literature. This algorithm proposes a particle swarm optimization method and combines it with a digital coding gene algorithm. Using a series of chaos to produce the initial population, the selection process uses nonlinear classification, the progressive method based on competitive selection, and the genetic algorithm is improved by optimizing the particle mass to create new individuals [7] literature, the algorithms of particle mass, synthetic mass, ant and artificial immunity are analyzed, including: genetic algorithm combined with particle mass algorithm, artificial immune algorithm, formed a hybrid genetic algorithm, the advantage is that the polymerization speed is not easy to decline, and a test function is used to verify the effectiveness of particle mass and artificial immunity literature [8] explores the relationship between crossover and variable probability and individual adaptation, and designs crossover and variable probability functions for individuals. during the whole operation, highly adapted individuals are protected from damage and the results are good through the test [1] literature has improved the formula of crossover and variable probability to solve its shortcomings and adapt to the change of crossover and variable probability, and the formula of variation probability evolves relatively slowly in the early stage of development [9] literature describes other genetic activities and macro-operation of biomes and genetic algorithms, including mutations, visible genes, diploid and polyploid structures, etc.
As to the research of the data acquisition system of the relevant standards, the literature [1] focuses on the use of the relevant standard algorithms in large databases. These algorithms are successfully applied to the extraction of massive data through analysis and improvement. Literature [10] the basic concepts and processes of data extraction, as well as the usual methods and techniques. Document [11] describes the programming of computer standard algorithms and how to extract data about standards from computers literature [12] provides detailed information on the use of WEKA software (a set of machine learning algorithms for data extraction tasks) for pre-data processing, classification, regression, and grouping. Literature [13] introduces the methods and techniques used in data acquisition, and analyzes these methods in combination with biological data acquisition cases. Document [14] provides a vision: an overview of new data acquisition research areas and a detailed description of the data acquisition process and related data acquisition methods. Information [1] literature has studied the method of mining related standards by using genetic algorithm to improve the structure and data coding of adaptive function to avoid premature variation adaptability [1] literature, a mining algorithm based on multi-level correlation genetic algorithm is proposed. according to the common characteristics of multi-level data, a preliminary self-definition of critical value is proposed to improve mining efficiency and improve the accuracy of mining a better simulated annealing genetic algorithm has been merged [1] the literature. in order to be applicable to the relevant standards, a new mining algorithm is proposed according to the improved simulated annealing gene algorithm. within the framework of this algorithm, the intersection and mutation possibility of the algorithm are selected by dynamic adjustment [15] literature suggests improving the gene algorithm and improving the efficiency of the gene algorithm [16] literature has incorporated simulated annealing algorithms into genetic algorithms and cited a new adaptive function for standard algorithms to build partnerships to determine support standards and reliability [17] literature, the degree index of interest in the connection standard algorithm is adopted, which effectively avoids the error standard, and makes appropriate dynamic adjustments to the crossover probability and variable probability.
In short, with the increase of data in the database, the simple application of connection rules is inefficient. Search by genetic algorithm can greatly increase the efficiency. Almost all researchers improve the overall search ability by studying genetic algorithm. And it is used in the mining of relevant standards.
Basic analysis of traditional algorithm
Analysis of common algorithm for data mining
Data mining methods are as follows:
(1) Statistical methods: statistical analysis of scale data in databases using statistical principles. Statistics play a very important role in the whole data collection process and provide a series of traditional methods for data use, including regression analysis (multiple regression, spontaneous regression, etc.), differential analysis (BAYES standards, fishery standards, non-standardization, etc.), group analysis (systematic grouping, dynamic grouping, etc.), exploratory analysis (meta-analysis, correlation analysis), etc.
(2) Neural network method: a nonlinear prediction model based on neural structure, based on research. The usual algorithms include front-end neural network (BP algorithm), self-organized neural network.
(3) Tree decision method: Tree decision method is to use the information advantage in information theory to find the most informative attribute field in database for searching, which is a very important classification and mining method, among which the most famous methods include: ID3、IBE and so on.
(4) Fuzzy mathematical method: fuzzy mathematics is an important new mathematical thing, in the field of data extraction, it is mainly comprehensive distinction fuzzy, connection fuzzy, grouping fuzzy and fuzzy classification.
(5) Genetic algorithms: algorithms that simulate the natural selection of biological communities, mainly by selecting operators’ cyclic calculations, cross accounts and variables, which have overcome the problem of nonlinear optimization and polarization in some places.
An overview of association rule algorithm
For a long time, the link standard has become an important field of data extraction research, because it can find the relationship between attributes in the database, and it is one of the first problems to be considered in the extraction process. As shown in Table 1, the scope of application of connection rules is not only limited to sales data, but also increasingly uses connection rules to discover the relationship between various things and their meaning see Table 1 for details.
Basic concepts of association rules
Basic concepts of association rules
Where the support degree of the item set X={A,B} is the ratio of the number of transactions containing both the transaction A and the B to the total number of transactions. Use Sup (X) to represent the number of occurrences of itemsets X. That is, probability P (A∪B).
The ratio of the number of transactions containing A and B to the number of transactions containing A, that is, the confidence of the A=>B is {the degree of support of the A} divided by the degree of support of the item set {A,B}. That is, probability P (A |B).
For the A=>B of this rule, the degree of interest is defined as:
Formula (3) when the interest is 1, it shows that the transaction A does not affect the transaction B, and the interest is more than 1, then the transaction A will lead to the transaction B, which is a rule. When interest is less than 1, the transaction A prevents the B. of the transaction
BP learning process of the pattern is as follows: provide training samples for the network pattern and disseminate data, that is, the difference between the actual output and the actual output. Through learning, the network is gradually stable and the network weight is changed one after another. The actual output of the network will tend to the ideal output and will be kept within the prescribed limit.
BP network is a network composed of access, output and intermediate networks, usually with only one default layer, in special cases, increasing the number of hidden layers as needed. The real data processing is as follows: the input vector of the input layer is usually the value of the sample information characteristic, and after the input layer receives the data, the data is transmitted directly to the ground, which is a set of data in the sample received. Because no special processing of data is required. Thus, the expression is as follows:
Implicit layer: is an effective network processing layer, which usually adjusts the input layer by the activity function in a specific region, receives weighted data from the input layer, and processes the data through a threshold to obtain more data. An expression of the neural i of the hidden layer is as follows:
Connection weights between the hidden layer neuron i and the input layer are as follows:
And the expression of neuron i is:
When the neuron i get the input data, it will be constrained to the expected value by the activation function. The activation function is S type activation function, as shown below.
So the output value of the neuron i after the activation function F(·) constraint is:
Hence the output vector of the whole hidden layer is:(where k is the number of neurons in the hidden layer)
Output layer: the input of the output layer is the weighted sum of the output of the hidden layer, and the received data is processed by the activation function, and then the actual output of the whole network is obtained. An input expression j the output layer neuron is as follows:
Output layer is also a S activation function, which constrains the data of data output layer. and the output of the neuron j is:
So the output vector of the whole network is:
First, the mean square error function of the network is calculated, and its mathematical expression is as follows:
When the error of the network is obtained, the error first reaches the output layer and adjusts the weight of the output layer. The mathematical expression of weight matrix adjustment is as follows:
And after substitution, the above formula is simplified as follows:
The expected output of the general hidden layer is uncertain, and the adjustment formula of the weight matrix of the hidden layer is as follows:
The formula is simplified as follows:
Learn for the second time according to the next set of sample data and repeat until the network performance is optimal see Fig. 1 for details.
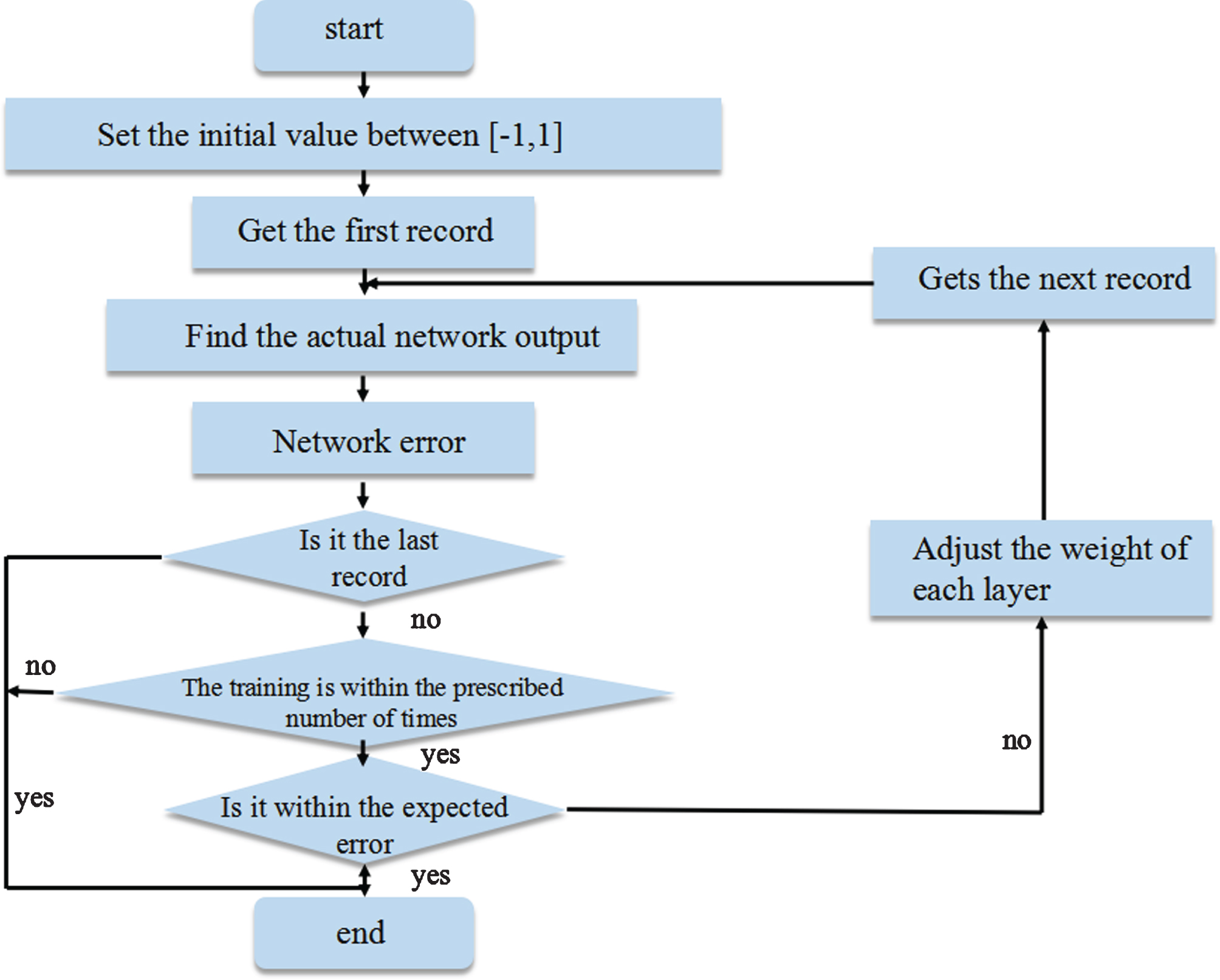
BP Network training process.
GA encode each possible solution as a vector, each chromosome vector element is called a gene. all chromosomes are evaluated according to the expected objective function of each chromosome and the fitness values are assigned according to their respective characteristics. starting from the random generation of certain chromosomes, their adaptability, chromosome selection, exchange, and mutation are calculated by the elimination of low-adaptive chromosomes and the retention of high-adaptive chromosomes; in general, the new chromosome group is larger than the generating group. By analogy, until the optimization goal is achieved, Fig. 2 illustrates the basic principles of genetic algorithms: see Fig. 2 for details.

Schematic diagram of genetic algorithm.
(1) Selecting operators: The basic operation of genetic algorithms includes the selection of screening, intersection and mutation operators, also known as operators, whose function is to determine whether the individual will be eliminated or retained in the next generation, from which the best parents are selected according to their merit. In general, three different types of specific choices in the field are most common when there is a mix of clear options and options:
The specific population is N, individual adaptation is F (i), the individual adaptation is I, the probability of individual selection is the cumulative probability is QI, and the cumulative probability is compared with the R[0.1] random average generated by the probability. Determine which individual replicates in the next generation.
Therefore, the probability reflects the proportion of individual adaptation in the whole group adaptation and the greater the individual adaptation, the greater the possibility of selection: conversely, the higher the probability of selecting each individual in the group.
(2) Cross operator: Cross chromosomes, called “recombination and pairing”, are between two paired chromosomes, exchanging some of their genes in one way or another, resulting in two new chromosomes. The effectiveness of genetic algorithms mainly comes from the selection of cross operations, which play a central role and determine the overall search ability of general algorithms.
The first is to randomly select the two chains of the father’s generation, and then randomly determine the intersection point; finally, the intersection point is L, the length of the chain is L, the intersection point is L-1, the result is see Fig. 3 for details.

Examples of single-point crossover.
(3) Variant: The so-called variant, which includes the selection and intersection of most of the search functions of genetic algorithms, replaces some genetic value of each chromosome with other chromosomes, thus creating a new individual, is the best measure against the general algorithm.
Simulated annealing algorithm was originally proposed in 1953. the algorithm is mainly based on the complexity of the NP. through the optimization process, the partial optimization is achieved. the optimization process is compared with the thermal equilibrium problem of statistical thermodynamics. the physical images and statistical features of the solid annealing process are used as the physical environment to avoid local optimization of the algorithm. the solid reaction is to heat the solid to a sufficiently high temperature so that the molecules are randomly placed, then cooled, and finally the molecules are sorted in a low energy state. Table 2 compares the optimization problem with the solid similarity see Table 2 for details.
Comparison of similarities
Comparison of similarities
The basic concepts of the simulation defense algorithm:
(1) Objective function: the objective function is to optimize the minimum value of the objective function in general when the maximum value of the desired function is converted to the minimum value of the objective function multiplied by -1.
(2) Temperature: Temperature is an important parameter in the simulation cooling algorithm, because the cooling process of solid flame changes with its composition. The distance between the new solution produced by the simulated annealing algorithm and the existing solution is controlled. Secondly, the possibility of accepting the new explanation by the simulated annealing algorithm is determined. The objective function values of these explanations are lower than the current objective function values.
(3) Annealing schedule: Annealing schedule involves the use of algorithms to reduce temperature. The slower the temperature decreases, the slower the annealing decreases. The simulated annealing algorithm is the best solution found at present. The time schedule includes parameters such as initial temperature and control temperature function.
(4) Metropolis criterion: Metropolis criterion is a method explanation of simulated annealing algorithm. This paper is used to optimize the selection of target function to optimize objective function. The possibility of new solution is:
It can be seen from formula (20) that if the new solution is less than the current solution, the higher the temperature, the greater the possibility of the differential solution. Therefore, the simulated annealing algorithm can be optimized locally more easily, and the probability of accepting the differential solution decreases with the decrease of temperature. Metropolis criterion mainly involves simulated annealing algorithm see Fig. 4 for details.

Flowchart of simulated annealing algorithm.
Ideas for genetic algorithm improvement
The basis of genetic algorithm is: choosing to pass the best model of the present individual to the next generation individual for arithmetic, using the cross equation to adjust the structure of the model, some bad models are phased out, and some good models are left behind. And gradually get the best results.
However, in the operation of practical algorithms, multiple models affect the efficiency of genetic algorithms. In the case of limited resources, it is necessary to choose the “best choice “. For example, half of the less suitable models are eliminated each time the gene is operated. Genetic algorithms tend to be highly adaptive models, but because of the limited size of genetic algorithms, it may lead to more reproduction of the next generation of individuals above the average level of individual adaptation. This will continue after some individuals have absolute advantages in the individual group. Genetic algorithm enhances this advantage, the community begins to meet, the individual becomes more and more similar, the bad individual does not have more chance to reproduce, finally, the population will break the deadlock, which causes the genetic algorithm to appear precocious. There are two strategies or ideas for improving genetic algorithms:
The first is to maintain as much diversity as possible, or to ensure that the diversity of populations is not lost, as in small genetic algorithms, if the evolution of genetic algorithms is not complete.
The second is that the loss of group diversity may occur during the evolution, but it provides a mechanism to generate new forms of individual participation in group evolution, thereby increasing group diversity. First, the new methods of individuals are used to increase the diversity of groups, which often combine other algorithms and genes to produce new individuals.
In this paper, the traditional genetic algorithm is improved, the chromosomes of immune mechanism are selected, and mutual adaptation and mutation are carried out according to the model to overcome the precocious phenomenon of genetic algorithm.
Operation of simulated annealing genetic algorithm
Simulated annealing gene algorithm is a combination of gene algorithm and simulated annealing algorithm. Its main operation is screening, interleaving and mutation.
(1) Selective manipulation based on immune mechanisms: Selective manipulation is the selection of the most environmentally appropriate individuals from the population and their use in the next generation of reproduction.
(2) Adaptation to cross-operation: Cross-operation refers to the exchange of the same gene between different individuals to create a new gene, which is an important step to protect the diversity of clusters. This paper adopts a self-contained adaptation method to dynamically adjust the probability of interaction between PC and PM and further reduce the best probability.
(3) Adaptive variability manipulation: mutation manipulation is a heterogeneous transformation of an individual specific gene, another important operation of biodiversity and an important component of analog gene algorithms, based on Metropolis criteria, which will affect the convergence behavior of the whole algorithm. The usual annealing functions are as follows:
Fast cooling: tk=α/+k 1
(Index decline: tk=αt per centk - 1
Decline: tk=(1- k/K) t0
Logarithmic decrease (K number of decay steps): tk=α/log (k + 1)
Application of simulated annealing genetic algorithm in association rule mining
Genetic algorithm is a random search method based on biological natural selection and genetic mechanism. The object is all individuals in the population. The spatial parameters are encoded by effective search technology. The search ability is reviewed by genetic algorithm to find concentration and frequency.
First, the user problem information is processed through a predetermined processor, the information is encoded as information with limited time, then the image is drawn for each attribute, and then the temporary information table is detected in the database SQL the search engine, and then separated.
Application steps
Coding
The coding of genetic algorithm is used to describe the feasible solution of the problem, that is, the feasible solution to decompose the spatial problem is transformed into the search space method which can be processed by genetic algorithm. In this paper, the coding method is adopted. The selection value of each service attribute is represented by the number after the decimal point, the number after each decimal point represents a gene, connects a service attribute, and forms a decimal string.
Design of fitness function
The degree of adaptation is usually used to measure the degree of excellence of a group to achieve or close to the optimization calculation. It is the basis of the application of genetic algorithm. The adaptive function is used to evaluate the degree of adaptation. The criteria for adaptive function are:
The traditional roulette strategy is often immature. Therefore, this paper adopts the selection strategy based on immunization mechanism. The probability is as follows:
The advantages of this approach are as follows: the higher the value of individual adaptation, the greater the possibility of PF adaptation, the greater the possibility of choosing P, the greater the possibility of individual selection (catalytic effect), and the higher the degree of convergence of the accelerated algorithm; the smaller the possibility of PF adaptation, the lower the degree of individual concentration, the lower the likelihood of commodity dependence and the lower the likelihood of commodity selection.
Cross operation is a process in which two matched chromosomes exchange a part of the gene in some way, resulting in two new chromosomes. individuals in this document, the intersection probability and the probability of polychlorinated triphenyl variability were dynamically adjusted using various methods. When the degree of adaptation is different, if the population difference is large, the heterogeneity is large, the possibility of crossover and mutation is small, and the population diversity is low, the adaptation tends to converge or optimize locally, it is allowed to change with the degree of adaptation. The possibility of interlacing and mutation increases, thus effectively preventing “premature” phenomena. The intersecting possibilities of self-adaptation used in this document are as follows:
Variation is a simulation of gene mutations in biological evolution. In this paper, the following adaptive mutations are used:
The basic idea of simulated annealing algorithm: from the point of view of statistical physics, with the decrease of temperature, the energy of matter will gradually approach a lower state, and finally reach a certain level, that is:
If the average adaptation of nearby generations is lower than a certain level, the flow algorithm of the above rules can improve the simulated annealing gene algorithm in Fig. 5: see Fig. 5 for details.

Flowchart of association rules of simulated annealing genetic algorithm.
In the actual coding process, the coding of each attribute is added “0”, indicating that ownership is independent of other attributes (the user does not have to worry about applying random production standards to genetic algorithms).
Table 3 attribute values have been converted to numeric values and appropriate attributes have been selected as needed, and the results of the database tables have been plotted against the above ratios, as follows: see Table 3, and Figs 6–9 shows attribute value mapping results, Breakdown1, Breakdown2 and Breakdown3.
Attribute value mapping results
Attribute value mapping results

Attribute value mapping results.

Breakdown1.

Breakdown2.

Breakdown3.
Coding through real sets facilitates the operation of gene chromosomes. Tables 6 to 9 show the correspondence between populations see Table 4 for details.
Table of correspondence between arrays and attributes
According to the algorithm described above, the association rules are excavated as follows: see Table 5 for details.
Selected association rules mined
This paper introduces the basic theory and development of data extraction more systematically, summarizes the methods, tools and techniques used in data acquisition, describes the data extraction techniques in connection rules more completely, classifies the mining techniques of connection rules, and introduces the steps of the top-down algorithm of traditional connection rules in detail.
Footnotes
Acknowledgment
Inner Mongolia Science and Technology Agency: BeefNet-Construction of cloud platform for precision breeding and breeding system of beef cattle (NO: 2019GG350); Project Supported by Basic Foundation of Inner Mongolia Agricultural University (NO: JC2013001).