
Abstract
In the electronic age, the changes in the mirror space constructed by movies are also brought about by changes in the media. Cinematic space is a four-dimensional space illusion including time created by the use of light and shadow, color, perspective, sound, and the movement of characters and cameras. It is not a real four-dimensional space, but a reflection and reproduction of the real space. With the goal of improving the accuracy of spatially coded structured light 3D reconstruction, this paper conducts in-depth research on several key technologies that affect the reconstruction accuracy and makes corresponding innovations and improvements. Moreover, this paper respectively proposes an adaptive structured light spatial coding algorithm based on geometric features and a color structured light decoding algorithm based on color shift technology. In addition, this paper implements a spatially coded structured light three-dimensional reconstruction system and calibration system. The simulation research shows that the method in this paper has certain reliability.
Introduction
Traditional drama and dance are art forms displayed in two dimensions of real time and space at the same time. In addition to real space, drama and dance will also have their own virtual space. The virtual space here refers to the use of simulation, exaggeration, and deformation of the real thing to be represented, so that it has an imaginary space, which is completely different from the digital virtual. As a time art, literature has no real space. Its spatial form is a thinking space constructed and constructed by words and language. This is the specificity of literary space. Moreover, the space in literature is far more than the place and scene where the story takes place, and it is both real and imaginary, both concrete and abstract, both real and metaphorical. In addition, literature presents the characteristics of elitism. However, with the advent of the printing age, the characteristics of artistic elitism have become less and less obvious [1].
In the electronic age, the changes in the mirror space constructed by movies are also brought about by changes in the media. Cinematic space is a four-dimensional space illusion including time created by the use of light and shadow, color, perspective, sound, plus the movement of characters and cameras. It is not a real four-dimensional space, but a reflection and reproduction of the real space. However, the presentation of movies is still a theater-like specific space. The cinema as a viewing space breaks the pure three-dimensional space of drama, but still has specific elements and meanings of theater. In addition to movies, televisions and other electronic devices are developing rapidly. At this time, an important feature is that artistic performance and display break the boundaries of inherent spatial characteristics and enter daily life. Moreover, the particularity of art has been dispelled, it has become increasingly integrated with daily life and popular culture, and the elitism has completely disappeared. In addition, the specific spatiality of art display at this time also disappears. The modern communication revolution and transportation revolution have brought tremendous changes to the urban space in which humans live, and the new changes in motion, speed, light and sound have led to confusion in people’s sense of space and time. Furthermore, the emergence of the digital age represented by the Internet and mobile phones has a comprehensive and thorough impact on human society. It not only affects people’s daily life, but also has a profound impact on the politics, economy, and culture of the entire world. In addition, various art forms based on digital technology and new media creation are also emerging in an endless stream, which brings freshness to people’s senses and infiltrates various information service industries [2].
In the digital age, traditional art creation is also facing crises and reforms. Research on the reconstruction of the audio-visual art space in the digital age can provide more ideas and ideas for art creation and promote more vigorous development of art creation. Creative life in the digital age is itself an art. Therefore, we can fully tap the great potential of art in the digital age in helping people understand and transform the world, so that art spaces can influence living spaces, create more perfect living spaces, and allow art to better serve life and benefit mankind.
After the audiovisual art space is digitally reconstructed, it has unique presentations in spatial interactive narratives, spatial imagination illusions and spatial immersive experiences, and these presentations in turn expand, extend, and enhance the space itself. Moreover, these changes make audiovisual art construct a unique meaning in digital practice and aesthetic reconstruction. Furthermore, all this has had a great impact on the art space itself, on the creators and participants of the space-people, and this influence will gradually spread and affect the entire social and cultural ecology [3].
Related work
The literature [4] proposed a phase space delay coordinate method that is equivalent to the trajectory space of the dynamic system, which laid a theoretical foundation for the prediction of chaotic time series. The literature [5] proposed a new method to calculate the maximum Lyapunov exponent of chaotic time series. For a small sample, this method has simple and clear calculations and strong reliability. Moreover, the author fully verified the effectiveness and feasibility of this method through a large number of engineering case analyses and numerical simulations. The literature [6] established a new method to determine the embedding dimension and delay time in the phase space reconstruction theory: C-C method. This method can simultaneously obtain the embedding dimension and delay time of the time series by calculation and uses the Lorentz equation to verify the feasibility of the method and obtains good results. The literature [7] proposed the Cao method to determine the embedding dimension of time series and gave an example to illustrate the reliability of this method. In view of the limitations of the C-C method, the literature [8] proposed an improved C-C new algorithm. This method introduces adjustable parameters to measure the calculation accuracy and speed, which can improve the efficiency of model calculation under the condition of slight loss of prediction accuracy. Moreover, the literature verified the effectiveness of the algorithm through simulation. The literature [9] proposed an improved Cao method to determine the embedding dimension and delay time and compared it with the traditional method through simulation of typical nonlinear equations, which proved that the method has obvious improvements and advantages. The literature [10] introduced a new method of fuzzy C-means clustering analysis on the basis of the small data method and conducted simulation experiments. The results proved that the proposed method is more accurate. The literature [11] introduced the phase space reconstruction technology to the prediction of deep foundation pit deformation and applied the largest Lyapunov exponent prediction model to predict the data of each monitoring point of the deep foundation pit and constructed the corresponding prediction model and obtained good application effect. The literature [12] introduced the method of determining the dimension and delay time of phase space reconstruction technology into subway deformation monitoring and established a prediction model by comparing different methods. The literature [13] introduced chaos theory into the slope displacement time series prediction, judged the chaos of the time series according to the chaos theory, and constructed a variety of chaotic prediction models for research and analysis. The results show that it has achieved good results in the slope displacement prediction. The literature [14] applied chaos theory to the study of the deformation law of open-air slopes and established a chaotic neural network prediction model based on phase space reconstruction theory through specific measured data to achieve accurate prediction of open-air slope deformation variables. Moreover, based on this, the literature established a corresponding safety early warning system. The literature [15] applied chaotic time series prediction theory to slope displacement prediction, combined wavelet analysis and extreme learning machine to establish a prediction model and combined with specific engineering examples to verify the reliability of the proposed model. The literature [16] introduced chaos theory and phase space reconstruction technology to the deformation prediction of earth-rock dams, combined with a neural network model optimized by genetic algorithm, to establish a deformation prediction model. The experimental results show that the prediction accuracy of the model is good, which provides theoretical support for judging the safety status of the dam. The literature [17] took the time series of deformation monitoring of a mine shaft as the research object and proposed a method to express the chaotic characteristics of the system with the largest Lyapunov exponent and correlation dimension. Moreover, it reconstructed the sequence by calculating the embedding dimension of the time series and used the reconstructed sequence as the training sample of the support vector machine model to establish the model, thereby effectively predicting the mine shape variables. The literature [18] fully analyzed the characteristics of each subsequence by introducing phase space reconstruction theory, constructed a prediction model based on empirical mode decomposition and wavelet neural network prediction model, and compared it with different models. The results show that the prediction model has certain practical significance in slope prediction. The literature [19] determined the embedding dimension of the deformed time series based on the phase space reconstruction technology, reconstructed the sequence, and used the reconstructed sequence as the input value of the fuzzy neural network. The research results show that the method has fast convergence speed and real-time stability.
From the above analysis, it can be seen that space reconstruction technology is mostly used in civil engineering and the deformation prediction of building structures. The application research in audio-visual media is basically blank, and the research in art research is under development. According to the existing research, this paper takes the nonlinear system as the object of analysis. The literature [24] talks about the construction of directed acyclic graph for video coding algorithms for motion estimation in parallel reconfigurable computing systems. The partitioning algorithm also plays a key role in optimizing the encoding of images. The literature [25] dealt with the exploitation of IoT and BigData Analytics using the Hadoop ecosystem in real-time environments. The implementation of IoT-based Smart City is accomplished through the above-mentioned processes. The article [26] centers around IoT and its noteworthy work in sophisticating the human hones and endeavors. This paper moreover overseen the combination of diverse data from distinctive resources that are related with the web. The article [27] talks approximately the different issues within the vehicular communication field with the proposition of agreeable centralized and distributed spectrum detecting model. Due to the execution of the agreeable cognitive model, obstructions and different hidden issues are minimized. The article [28] discusses the problem, such as the tremendous amount of big data, and introduces the SmartBuddy idea of a smart and intelligent world using individual activities and human resources [29, 30].
Color structured light decoding algorithm
The spatial coding structured light uses the color information of other feature points in the neighborhood of the feature point for decoding. Therefore, it needs to accurately extract the coordinate information and color information of the feature points. For the DeBruijn sequence color fringe space coding in this article, the characteristic point is the center point of the fringe. When encoding, we use 4 colors and the unique neighborhood size is 3 to generate the encoding pattern shown in Fig. 1(b). Therefore, the color fringe sub-sequence with neighborhood 3 in Fig. 1(a) appears and only appears once in the entire color fringe sequence. Therefore, as shown in Fig. 1, the center point of the structured light image stripe needs to be detected as a feature point during decoding, and then a color sequence of length 3 is formed based on the current feature point and the color information of the left and right feature points. After that, we perform a matching search on the entire stripe color information sequence in the structured light coding pattern to determine the matching point coordinates corresponding to the current feature point in the structured light coding pattern, and complete the decoding of the structured light image [20].

Spatial coding structured light decoding process.
As the structured light image is captured by the camera, it is affected by the ambient light, the surface texture of the measured object and other factors, so that the color information of the captured structured light image is seriously lost, which reduces the accuracy of color recognition and the accuracy of feature point extraction during decoding. As shown in Fig. 1(a), the green stripes are affected by the ambient light, making the color almost degenerate to white, losing the original color information. As a result, the corresponding sub-sequence cannot be found when performing matching search in the coding pattern sequence, and the accuracy of color recognition and matching is seriously reduced. Therefore, in response to this problem, this chapter first proposes a color structured light image enhancement method based on color migration technology to improve the accuracy of structured light image color recognition. Then, on this basis, this chapter proposes a two-step precise positioning method for fringe feature points to further improve the accuracy of feature point extraction, and finally achieve high-precision color structured light decoding [21].
In the process of color structured light image enhancement based on color migration, the structured light coding pattern is used as the target image of color migration, the structured light image captured by the camera is used as the original image, and the color distribution of the structured light coding pattern is used as the prior knowledge. At the same time, the color distribution of the structured light coding pattern is transferred to the structured light image to realize the degeneration and restoration of the stripe color of the structured light image, so as to eliminate the influence of the measurement target material and the ambient light on the color recognition. The fringe deformation feature in the structured light image is the result of the modulation of the structured light coding pattern projected on the surface of the measured object by the geometric features of the measured object. It reflects the three-dimensional information of the measured object surface, and the color feature of the fringe is the characteristic of the decoding stage. It is an important basis for point extraction and feature point matching. Therefore, the stripe color enhancement processing of structured light images must ensure the stability of stripe deformation characteristics while restoring structured light coding colors.
In the structured light image enhancement process based on color migration, the color distribution of each color channel of the structured light coding pattern needs to be independently migrated to the structured light image captured by the camera. Generally, the structured light images captured by industrial cameras are mostly color RGB images. Because the channels in the RGB space affect each other, the color migration is usually performed in the conversion to the lαβ color space. In the lαβ color space, each component has an approximately orthogonal relationship. When one component is changed, the other two components will not be affected. Therefore, the migration of statistical information between different channels can be performed independently.
If it is assumed that R and T represent structured light image and structured light coding pattern respectively, and the resolution of the image is both U × V, then the average value and standard deviation of the structured light image and structured light coding pattern in the three channels lα and β are as follows [22]:
Among them, K∈ { l, α, β },
The mean and standard deviation of the color channels describe the color distribution of structured light images and structured light coding patterns. For this reason, we propose a structured light image color migration transformation model based on the mean and variance of each color channel of the structured light coding pattern. The model is shown in formulas (5) to (7):
Among them, R* (i, j) K represents the K channel pixel value of the image R at pixel (i, j) after the color shift transformation, R′ (i, j) K represents the change in the K channel average value of the image R, K∈ { l, α, β }
In addition, the structured light image capture process is usually affected by ambient light, which will also have a great impact on color recognition. Therefore, for the structured light coding pattern in this article, a suitable de-illuminating model is proposed. First, from the color distribution of the structured light coding pattern, it can be known that in the RGB color space, the minimum value of the three-channel pixel of each pixel in the structured light coding pattern is zero. However, due to the influence of illumination on structured light images, the minimum value of its pixels is usually not 0. Therefore, in the illumination model of this article, the minimum value of each color channel of each pixel in image R* is defined as illumination model λ, R* is the image after color migration processing, and the structured light image after de-illumination processing is defined as”. Then, the lighting calculation model is shown in Equations (l1) and (12):
Among them, R* (i, j) X and I (i, j) X represent the x channel pixel value of image R* and I at pixel (i, j), and λ (i, j) represents the illumination X∈ { R, G, B } of the image R* at the pixel point (i, j).
The color structured light image enhancement method of color shift technology can eliminate the interference of surface texture, environmental lighting and camera distortion on the structured light image, so that the structured light image has a color distribution similar to the structured light coding pattern. Based on the color structured light image enhancement algorithm based on color migration technology, this chapter also proposes a sub-pixel two-step positioning method for the center point of the stripe to realize the sub-pixel extraction of the center point. The method first calculates the first-order differential derivative and the second-order differential derivative of the pixel maximum sequence of each row of the structured light image in the RGB color space, and determines the stripe boundary point sequence according to the second-order derivative. After that, the method realizes the coarse positioning of the center point of the fringe according to the first derivative. Then, the method determines the normal direction of the center point of the thick stripe based on the Hession matrix, and uses Taylor’s formula to expand in the normal direction to achieve precise positioning of the stripe center, thereby achieving high-precision extraction of the stripe center.
The structured light image after color shift processing and de-illumination is I, and the resolution of the image is U × V. As shown in Fig. 2, the sequence of dots in the solid frame is the center point of the stripe in one row. The DeBruijn structured light decoding direction is perpendicular to the stripes. Therefore, when extracting the center coordinates during the decoding process, we need to traverse each line of the image I to determine the center coordinates of the stripes in turn. We assume that the maximum value of the three-channel pixel of the structured light image I pixel point (i, j) is normalized to M
i
(j), that is [23]:
Among them,
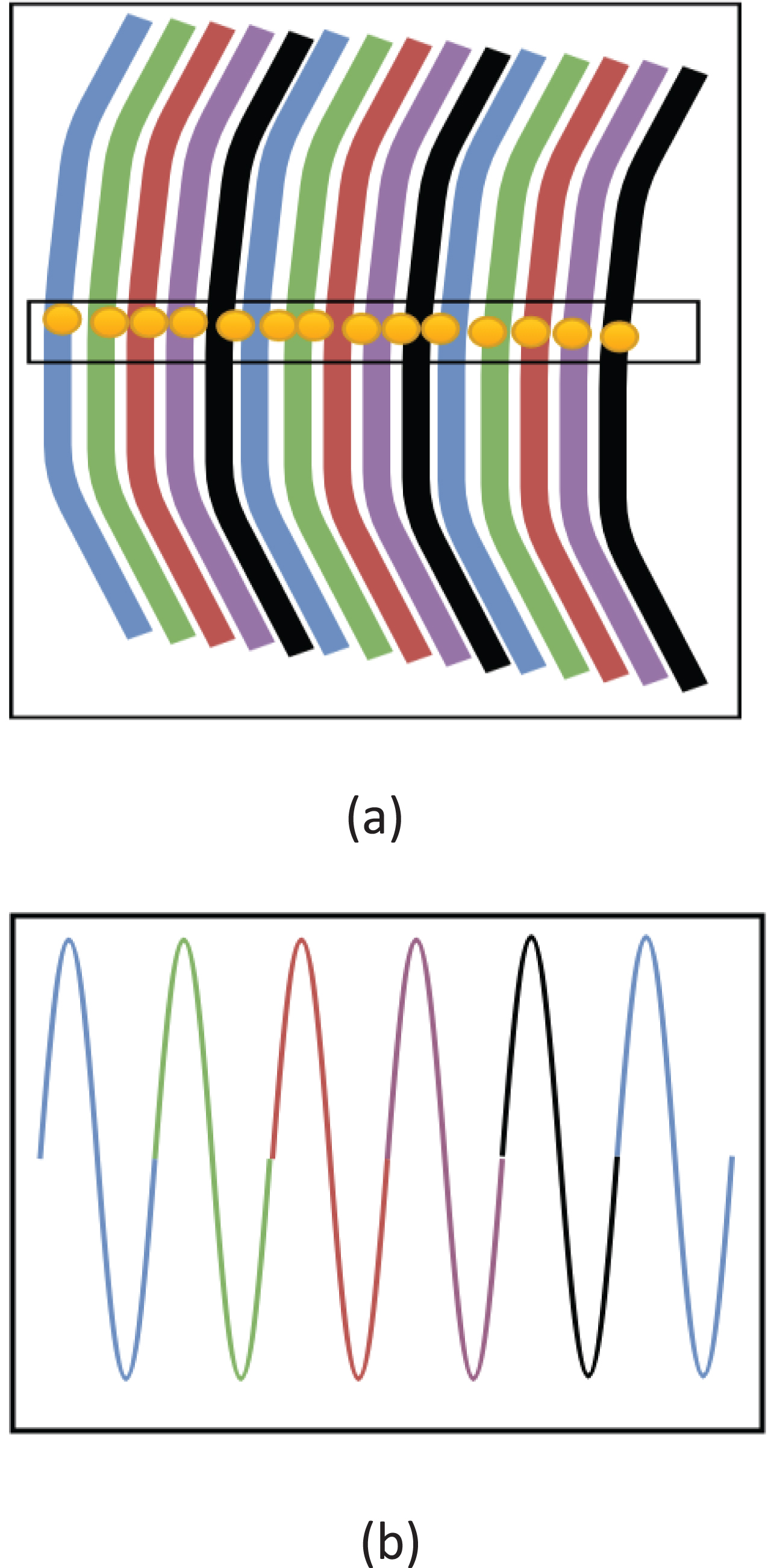
The coordinate position of the center point of the colored fringe of the structured light image.
When detecting the boundary points between the stripes in the i-th row, the algorithm first determines whether each pixel (i, j) in this row is the zero position according to the second derivative of M
i
in the i-th row. Moreover, the algorithm defines the zero-point sub-pixel position as (i, j + Δj), and obtains the zero-point sub-pixel position sequence. The calculation of Δj is shown in Equation (15).
In the formula, dM i (j) is the first derivative of M i (j), S i (j) is the square of dM i (j), and dS i (j) is the first derivative of S i (j), j = 2, ⋯ , V. If the dS i (j) value of the current pixel (i, j) is zero, then (i, j) is the zero position, Δj = 0. If the dS i (j) of the current pixel (i, j) and the dS i (j - 1) value of the previous pixel (i, j - 1) are not zero, and the signs are opposite, the zero position is between j - 1 and j, and its zero sub-pixel is (i, j - 1 + Δj), so as to obtain the zero position sequence of the i-th row on the structured light image.
Then, according to the zero point position sequence, the stripe boundary point position sequence is determined. If the first derivative value dS i (j) of the current zero point position j is greater than zero, and the first derivative value dS i (j + 1) of the next zero point position j + 1 is less than zero, the current zero point position is the fringe boundary point position j. On the contrary, it is not a boundary point. After that, by traversing to determine the value of dS i in the i-th row, we obtain the sequence of the stripe boundary positions in the i-th row on the structured light image.
Finally, the coarse center coordinates are determined according to the position sequence of the stripe boundary points. We assume that the current boundary point is q, its pixel coordinate is (i, f (q)), and the next boundary point q + 1. At the same time, its pixel coordinate is (i, f (q + 1)), and f (q) represents the ordinate of the q-th boundary point in the current row. Then, we define the coordinates of the thick center point of the fringe between q and q + 1 as follows:
In the decoding process, only the center position of the color stripes needs to be determined. Therefore, before determining the center position, it is necessary to determine whether q and q + 1 are black stripes or color stripes. We assume that the number of pixels between q and q + 1 is n, and assume that the M i vector of these n pixels is T. Then, we can get the following results:
The number of increasing points and decreasing points of the vector T are counted separately. That is, when T (k) > T (k + 1), the number of decreasing points increases by 1, and if T (k) < T (k + 1), the number of increasing points increases by 1. Because the black background changes from color to black, the number of decreasing points is smaller than the number of increasing points. However, the color stripes change from black to color, so the number of decreasing points will be greater than the number of increasing points. Therefore, the number of increasing and decreasing points of the vector T can be counted to determine whether the stripes are black background stripes or colored stripes. If it is a color stripe, we determine the coordinates of the coarse center point according to Equation (18). In the above formula, I is the index vector of T, that is:
After obtaining the position sequence of the thick center point of the stripe, based on the normal direction of each thick center point, the precise center point coordinates are obtained by expansion according to the Taylor formula. We assume that the coordinates of the current thick center point is (x, y), and the normal direction of the thick center point can be determined by the eigenvalues and eigenvectors of the Hession matrix. Then, the Hession matrix is as follows:
In the formula, g (x, y) is a two-dimensional Gaussian function. We assume that the unit vector of the normal vector of point (x, y) is n = (n
x
, n
y
). Meanwhile, we take the coarse center point coordinate (x, y) as the base point, and carry out the second-order Taylor formula expansion of the pixel distribution function of the base point along the (n
x
, n
y
) direction. Then, the pixel value of the precise center point can be expressed as:
In the formula, (r
x
, r
y
) is obtained by the image I (x, y) and the Gaussian convolution kernel, which is shown in formula (24) and formula (25):
According to
Then, the precise center point coordinate of the fringe is (x + tn x , y + tn y ).
The structured light three-dimensional reconstruction system is mainly composed of an image collector (camera), a coded pattern projection device (projector), a data processing device (computer) and an object to be measured. The position of the camera, projector and the measured object in the system is in a triangular relationship, as shown in Fig. 4.
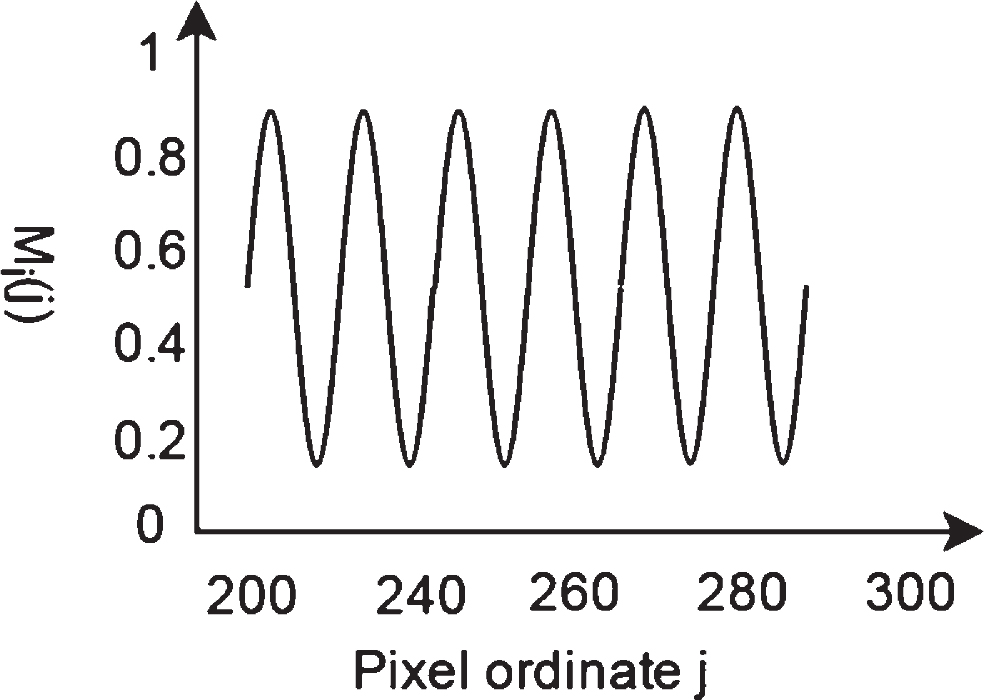
M i distribution curve of colored fringe in structured light image.

Schematic diagram of structured light 3D reconstruction.
Inter-coded structured light is one of the structured light coding strategies. Its feature is that only one structured light coding pattern is needed in the reconstruction process, and the coded value of each feature point in the pattern can be obtained from the coded values of spatial neighboring points. Therefore, it is suitable for three-dimensional reconstruction of dynamic objects. Based on the geometric characteristics of the surface of the measured object, this paper proposes an adaptive structured light space coding algorithm, and this paper is based on the previously proposed coding algorithm and decoding algorithm to complete the final 3D reconstruction of the target object surface, as shown in Fig. 5.

3D reconstruction flow chart.
This paper also compares the reprojection error between the calibration method based on local homography matrix and the calibration method directly based on global homography. The comparison results are shown in Table 1, and the corresponding statistics are shown in Fig. 6.
Comparison table of calibration reprojection error
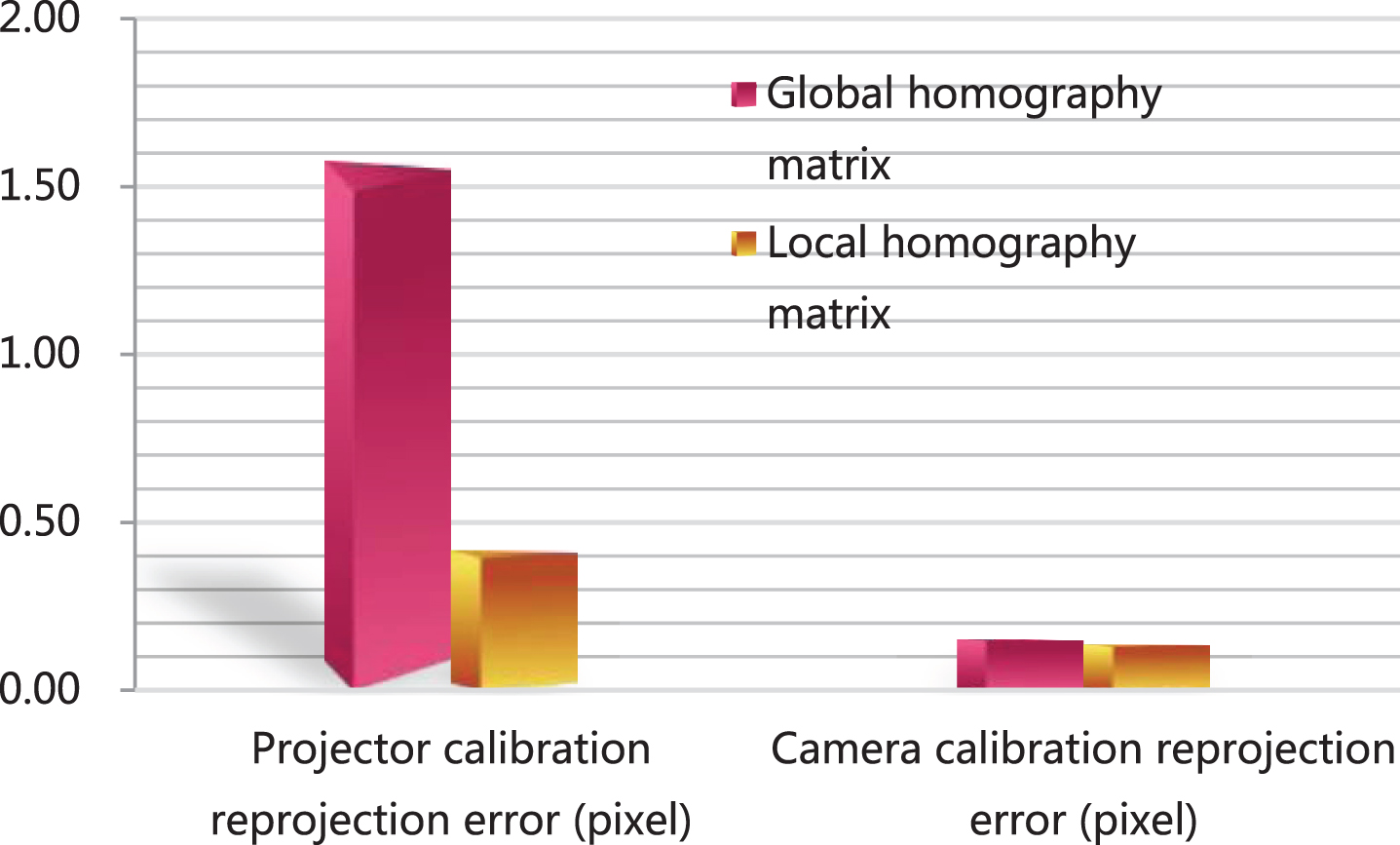
Comparison chart of calibration reprojection error.
The statistical results and measurement results of the 3D point cloud data are shown in Table 2 and Fig. 7 below.
Statistical diagram of 3D point cloud data statistics and measurement results
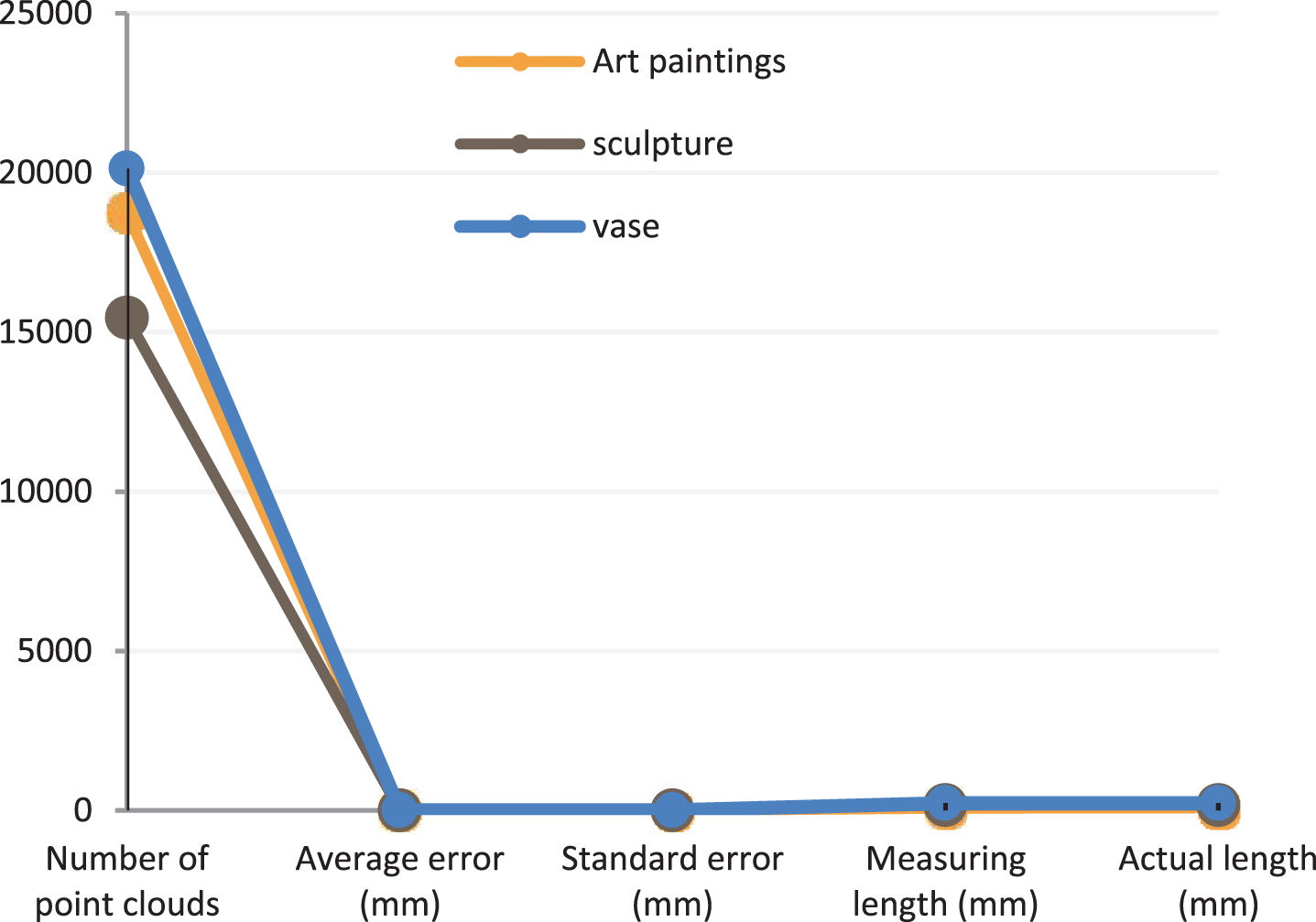
Statistical diagram of 3D point cloud data statistics and measurement results.
The number of point clouds of spatially encoded structured light reconstruction proposed in this paper is more than 15,000. In addition, the average error and standard error can explain the high accuracy of the reconstruction algorithm in this paper. Moreover, the error between the length of the object measured based on the point cloud data after reconstruction and the actual length of the object is small, and both remain within the error range of 3 mm. These experimental data fully verify that the algorithm proposed in this paper effectively improves the accuracy of spatial reconstruction.
According to the research perspective of this article, virtual practice is also divided into two levels. Virtual practice in a broad sense is symbolic practice, that is, people use symbolic intermediary to carry out practical activities in physical space or virtual space, such as drama performance, mirror reflection, traditional film and television practice, and so on. In a narrow sense, virtual practice is all practical activities in which the subject of practice uses digital intermediary means to explore and transform virtual objects in virtual space or mixed space. That is, virtual practice in a narrow sense refers to digital practice. As shown in Fig. 8, the virtual practice pattern diagram has undergone great changes in the composition of the subject, intermediary and object compared with the traditional practice pattern diagram.

Virtual practice mode diagram.
In artistic creation, the biggest feature of virtual practice is “virtualization", including “virtualization” of creative space, “virtualization” of subject, “virtualization” of intermediary, and “virtualization” of object. Virtual practice must first be carried out in a virtual space or a mixed space containing virtual space, because the identity of the subject of the creative space is blurred, and the main form of man-machine coexistence is inseparable from the virtual environment. Moreover, the addition of digital intermediaries led to the emergence of virtual technology. In addition, the artwork itself has begun to be virtualized and digitalized, and the space presented by the artwork has appeared in the form of virtual space and mixed space. Virtual practice is a kind of transcendental thinking and cognition, which is the further development of human transcendence activities in the digital age, and has guiding significance to reality. The traditional practice method believes that “it is always shallow on paper, and you must do it yourself if you know it.” However, if everything is done by yourself, it is a great waste of human and financial resources. However, virtual practice can provide a variety of practical solutions, which are selected in the virtual experience and the best solution is selected in actual practice. In virtual practice, the intervention of digital technology greatly accelerates the efficiency of information calculation and processing, and more practical solutions can be completed in virtual space, which reduces the cost of people in actual practice, improves the efficiency of practice, and also expands people’s ability in actual practice.
The aesthetics of expression affirms that audiovisual works reproduce life, and also propose that life can be created. The basic feature of performance aesthetics is subjectivity, that is, audiovisual art can highlight the creator’s own emotions, experiences, imaginations, etc. Moreover, its performance aesthetics pursues the truth of emotion rather than the truth of life. It allows fictitious storylines, but does not allow the plot to be false. It allows fictional character images, but the character prototype should also be in life. In addition, it can deform the plot and characters, but it cannot be completely divorced from the facts. After digital technology intervenes in audiovisual art, it has caused a violent shock to audiovisual art. Digital technology can virtualize things that don’t exist in the real world, make it more real than reality, and reconstruct a completely non-existent space, so that the audience can be completely immersed in such a space and unable to extricate themselves. At present, aesthetic research on digital art is also rising. However, due to differences in research concepts, objects, methods, etc., this kind of aesthetic research is a reconstruction of the previous aesthetics of performance and aesthetics of representation.
The space of traditional audio-visual art includes the space that exists objectively and real, the imaginary space that exists in the human mind, and the virtual space that exists in the objective space. Stage art is a virtual space that uses objective space to flourish, while film and television art is a space illusion carried by a two-dimensional electronic screen. However, digital art contains an extremely vast virtual cyberspace extending from the plane, and it does not require real space to carry it, and audiences can enter and interact at will.
With the goal of improving the accuracy of spatially coded structured light 3D reconstruction, this paper conducts in-depth research on several key technologies that affect the reconstruction accuracy and makes corresponding innovations and improvements. Moreover, this paper respectively proposes an adaptive structured light spatial encoding algorithm based on geometric features and a color structured light decoding algorithm based on color shift technology and realizes a spatially encoded structured light three-dimensional reconstruction system and a calibration system. The correctness and effectiveness of the algorithm in this paper are verified by the three-dimensional reconstruction and measurement of the surface of multiple different objects.
Footnotes
Acknowledgment
Supported by “the Fundamental Research Funds for the Central Universities” (CCNU16A03023).