
Abstract
College English cross-cultural teaching has changed from offline to online teaching. Under the impetus of MOOC teaching mode, college English cross-cultural teaching online teaching has exposed problems such as insufficient intelligence and poor online teaching effects. In order to improve the efficiency of college English cross-cultural teaching, based on cloud computing technology and artificial intelligence technology, this article improves and analyzes traditional MOOC, improves traditional algorithms according to the actual needs of MOOC teaching, and proposes a new improved model. Moreover, this article sets up functional modules through requirements analysis. In addition, according to actual teaching, this paper designs control experiments to verify and analyze the model performance from experimental teaching and the effect of attracting students’ online learning. The research results show that the model proposed in this paper has good performance and can effectively improve the efficiency of English cross-cultural teaching.
Introduction
Foreign language teaching pays more and more attention to the cultivation of cross-cultural communicative competence. In order to increase the cross-cultural knowledge of college students and develop cross-cultural communicative skills, some universities have set up courses on Chinese and Western cultural background knowledge. However, it is difficult to set up Chinese and Western culture courses in vocational schools alone. At present, English classes have become an important platform for cultivating students’ cross-cultural communication skills. Therefore, teachers in vocational schools must rely on English classrooms to carry out reasonable and effective cross-cultural teaching and combine language knowledge with cross-cultural knowledge teaching to cultivate students’ cross-cultural abilities [1].
MOOC originated from the open education resource movement. Compared with traditional courses, MOOC has the following typical characteristics: First, the participating universities, teachers, students, and input have a certain scale; second, it has open learning objects, teaching models, course content, and educational concepts; third, it is networked, which can be used for active learning and data mining anytime, anywhere; fourth, it has innovated course organization structure, course content, learning methods and course evaluation. On the MOOC platform, a complete teaching process including courseware, videos, assignments, interactive discussions, exams, and qualification certificates can be realized. It transcends the limitations of time and space. As long as there is an electronic device, students can learn the courses of many famous schools around the world anytime, anywhere. It can also realize functions such as user management, communication and interaction, organization, course design, and evaluation management. In addition, the MOOC platform has the function of teaching data analysis, and it can help teachers make better teaching decisions through personalized tracking of students’ learning behavior and visual interpretation [2].
Artificial intelligence can bring more accurate and suitable education for people. More precise and suitable means that artificial intelligence can meet the learning needs of students from two aspects of learning content and methods. Artificial intelligence uses algorithms to process and analyze massive amounts of data accurately and efficiently, providing people with scientific personalized learning. Artificial intelligence technology is changing teaching modes, personalizing teaching tasks, providing teachers with teaching plans, and improving student self-adaptation.
Teaching feedback is a major method and means to improve teaching, improve teaching quality and classroom efficiency, and is a very important part of education and teaching. In order to make the MOOC platform intelligently meet the needs of students’ individualized learning in the teaching feedback link and solve the students’ difficult problems, the intelligent teaching system on the MOOC platform was designed and developed using artificial intelligence technology. The system can enable teachers to answer questions from students from fixed time to random time, and do not need to repeat the common questions in student learning. Because the questions and the answers to the questions can be aggregated into the database, the system can display the relevant answers when the students ask questions. If there are no questions from students in the stored question database, the system can also automatically turn to online search answers to present the search results to the students. At the same time, the answer results can also be stored to prepare teachers for answer screening and update the database [3].
Related work
With the rapid development of artificial intelligence, artificial intelligence technology has brought earth-shaking changes to education. It provides intelligent possibilities for the realization of natural language processing and database retrieval and promotes the development of intelligent question answering systems. Until today, scholars at home and abroad, including educators, computer scientists, and planners, have conducted extensive and in-depth research on the online intelligent question answering system, and have achieved many research results [4].
The literature [5] used machine learning in computer program language learning, and divided students into groups of two, and discusses and solved problems among peers in course activities. The literature [6] believed that machine learning activities can effectively improve student participation, and learners’ cognitive abilities in machine learning activities are improved. The literature [7] found that peer mutual assistance can promote deep learning, and through peer mutual assistance activities, learners’ social communication ability is significantly strengthened. The literature [8] developed a set of peer guidance methods and focused on peer guidance techniques to improve student performance. The literature [9] published the guide “Peer Learning for Each Other: A Framework for Design and Implementation”. The guide provides guidance for the development of machine learning and prompts many universities to try to apply machine learning to medical professional courses to improve students’ professional skills. here is not much in-depth research on machine learning in China, and the domestic is mainly to introduce and refer to the relevant theories of foreign machine learning and peer assistance and draw on foreign experience to conduct local research. The research focuses on the exploration of skills development for teachers, medical professionals and other professionals, as well as the study of applied subjects such as English and physics and chemistry. The target groups in machine learning application scenarios are teachers, nurses, college students and other groups. The reason may be that researchers believe that machine learning, a highly autonomous learning method, is suitable for learners who already know the relevant professional knowledge and have certain professional skills.
The literature [10] attempted to apply peer-assisted learning in high school English grammar teaching and carried out applied research on machine learning. The literature [11] applied peer-assisted teaching strategies to sixth grade English reading teaching and explored the improvement of learners’ reading ability by this method. The literature [12] conducted an empirical study on peer-assisted learning application in college English reading. The literature [13] applies peer-assisted learning to senior high school physics problem classes. The literature [14] conducted the practical application of peer-assisted learning in high school biological experiments. The literature [15] reviewed foreign peer-assisted learning research. Moreover, it believes that adopting peer-assisted learning can improve the traditional single teacher-student-received teaching organization form, which will have a positive impact on the academic performance, social communication skills, and emotional attitudes of different objects. The establishment of peer relationship has a stronger sense of goal joint than group cooperation. The literature [16] selected two schools to carry out exploratory learning activities based on the network learning space and adopted a peer-assisted strategy to encourage learners to help each other in the network learning space. Moreover, it conducts research and analysis on the interaction mode when learners are performing peer-assisted activities in the online learning space, the focus of the learners when performing machine learning, and the means of performing peer-assisted activities. In addition, the literature believed that learners sharing information and providing timely feedback and interpretation of questions raised by peers are beneficial in exploratory learning activities. There are other researchers conducting experiments in colleges and universities and using machine learning methods in college teaching activities. College students already possess certain self-learning ability and professional knowledge. During peer-assisted learning, they can effectively communicate and interact, and further enhance their knowledge construction level [17].
Foreign researchers have conducted in-depth research on machine learning, and the literature [18] conducted quantitative research and analysis on machine learning evaluation research. The literature [19] discussed the problem of low quality of quantitative research in machine learning evaluation and believed that the research results and methods vary from study to study. The literature [20] quantified the practical data of the machine learning classroom and found that machine learning has improved middle and low-grade students. In the case study of machine learning, literature [21] studied the influence of factors such as students’ participation in machine learning, university attribution, gender, and scoring criteria on machine learning results. The article [26] addresses the issue such as enormous volume of bigdata and come up with the concept of SmartBuddy to form brilliantly and savvy environment utilizing human practices and human elements. The article [27] talks almost the development of coordinated non-cyclic chart for video coding calculations for movement estimation in parallel reconfigurable computing frameworks. Moreover, the partitioning algorithm plays a major part to speed up the video processing. The article [28] dealt exploiting IoT and BigData Analytics utilizing Hadoop environment in genuine time situations. Execution of IoT-based Smart City is accomplished by the above-mentioned processes. The article [29] centers around IoT and its significant job in sophisticating the human practices and endeavors. This paper additionally managed the assortment of different information from different assets that are associated with the web. The literature [30] addresses the different issues within the field of vehicle communication with the recommendation of a common bound together and scattered range detecting demonstrate. The application of the shared cognitive paradigm minimizes struggle and different obscure problems [31, 32].
Cloud computing task scheduling model
For the scheduling level in cloud computing, it usually involves two stages of scheduling. The first stage is the scheduling of tasks to virtual machines, and the second stage is the scheduling of virtual machines to physical hosts. This paper mainly studies the scheduling algorithm of task allocation to virtual machines. For the system model of cloud computing scheduling, first, the cloud system extracts heterogeneous physical resources into the resource pool through virtualization technology. When different users submit tasks to the cloud system, the tasks are cached in the waiting queue. After that, the system scheduler assigns tasks to the appropriate virtual machine to complete execution. The system model of task scheduling is shown in Fig. 1 [22].

Model of task scheduling system in cloud environment.
The complex task scheduling model can be defined as: For users, n independent tasks T ={ T1, T2, ⋯ T n } are submitted. The data size of each task is L T ask _ i, and there are m available heterogeneous virtual machines VM s ={ VM1, VM2, ⋯ VM m }. The processing speed of the virtual machine is determined by two factors: the processing speed of the virtual machine VM ips j and the number of processors Penum j .
Unlike the basic task scheduling model, in the complex task scheduling model, due to the large-scale task transmission and bandwidth limitations in cloud computing, the average transmission bandwidth BW
ij
is considered in the scheduling model (BW
ij
is task i transmitted to virtual machine VM
j
via link L
ij
). At the same time, the transmission overhead of the task to the virtual machine is considered. The user’s total cost is the sum of the calculation cost Cproc
ij
and the transmission cost Ctrans
ij
, which is calculated by formula (1) [23].
It is assumed that the calculation fee Cproc
ij
is proportional to the charging unit c
j
and the task execution time ET
ij
. c
j
is the processing cost per unit time on the virtual machine j, and the cost of the virtual machine VM
j
increases as the processing speed of the virtual machine increases. ET
ij
is the execution time on virtual machine j. After this, the execution cost of task i on virtual machine j is as shown in formula (2) [24]:
It is assumed that the transmission cost Ctrans
ij
is related to the charging unit
The cost of task i transferred to virtual machine j is as shown in formula (4),
When a large number of tasks are submitted to the cloud by the user, the tasks are stored in the cache queue and waiting for scheduling. It is assumed that the waiting time of tasks in the queue conforms to the Poisson distribution law, and Wait
ij
represents the waiting time in the queue before task j is assigned to virtual machine i. WET
ij
is the sum of execution time ET
ij
and waiting time Wait
ij
, as in formula (5).
The system model and task scheduling model of cloud computing are given above. For the basic task scheduling model, there are n independent tasks and m virtual machines. When tasks are mapped to virtual machines, the goal of task scheduling is to minimize Makespan. The basic task scheduling model (Basic Task Scheduling, BTSC for short) problem is defined as follows [25]:
Among them, formula (7) is a constraint on the completion time of a task on a certain virtual machine j, (8) represents whether the task i is assigned to the virtual machine j, and (9) is that the task i must be assigned to one of the virtual j to execute.
For Complex Task Scheduling (CTSC) problem, because reducing user’s cost is an important goal of task scheduling, the goal of complex task scheduling is to allocate n tasks to m virtual machines, which must meet the constraints of the deadline D and the user’s maximum budget B to minimize the user’s cost and task span (Makespan). CTSC is described as follows,
Because the PSO algorithm can improve the performance of task scheduling, the algorithm proposed in this chapter is based on an improved version of the PSO algorithm to further improve the performance of task scheduling. This chapter proposes a scheduling algorithm for optimized particle swarm optimization based on Self-Learning Strategy (SLS) and Neighbor Heuristic Mechanism (NHM). The algorithm has the advantages of fast convergence speed and strong search ability. The proposed SLS can improve the diversity of the population, and the NHM can accelerate the convergence rate. In addition, Greedy Policy (referred to as GP) is introduced to initialize the population to quickly improve the quality of the initial solution.
In Table 1, the difference between the proposed algorithm and the current four most advanced algorithms is shown. Simple particle position updating strategy (SPP), fast particle position updating strategy (FPU), space sharing strategy (SS) are included. The comparison of algorithms in Table 1 includes initialization method, Jumping Out of Local Optimum (JLO for short), scheduling objectives, Opti-mizing Global Optimum (OGO) and scheduling model. Comparison algorithms include traditional PSO, simplified particle swarm position update algorithm (SPSO), greedy particle swarm optimization algorithm (G&PSO), space sharing genetic algorithm (SSGA) and the proposed SLNPSO algorithm. Among them, “-” means there is no such method, “√” means there is this method.
Comparison of different scheduling algorithm strategies
Comparison of different scheduling algorithm strategies
Greedy strategies are often used to initialize populations. In the simple task scheduling model, the traditional PSO algorithm is applied to cloud task scheduling, and the initialization of the population is randomly generated. In the complex model, for the proposed SLNPSO algorithm, the greedy algorithm is introduced to initialize the velocity and position of the particles, reduce the solution space to a certain range, and improve the quality of the initial solution. The greedy strategy can quickly find the initial solution G ov and the total expected completion time G ct of the task, and the global optimal value (gbest) of the particle can be calculated by G ct .
In the proposed algorithm, the fitness function of evaluation particles in basic task scheduling model and complex task scheduling model is as formula (18) and formula (19):
Among them, MK is calculated from the basic task scheduling model, and ME is the weighted value of span (MK) and cost (TUB).
The traditional particle swarm optimization algorithm has certain limitations, such as the slow convergence rate, which is easy to fall into the problem of local optimization. This paper proposes a new nearest neighbor heuristic mechanism to overcome these defects. Unlike the traditional particle velocity update strategy, in the nearest neighbor heuristic mechanism, the position update of particles is not only changed by the local optimal value (pbest), but also related to the best position of the neighbor particles. The nearest particle position mparticle calculated from the nearest particle of the i-th particle is denoted as m
i
, as in formula (20). The neighbor information of the current particle is reflected in the particle velocity update formula, as in formula (21). The particle position update is as in formula (22). In addition, a linear inertia weight w is introduced to control the particle search speed as in formula (23).
The number of nearest neighbors in formula (20) is k, and c in formula (21) is the acceleration coefficient. In formula (23), w is the inertial weight, T is the maximum number of iterations, and t is the current number of iterations. Meanwhile, wmax and wmin are the maximum weight and the minimum weight.
In the calculation process of the neighboring heuristic particles, according to the information of the neighboring heuristic particles, the new position of the i-th particle is obtained. i, j are the i-th and j-th particles respectively, P sum is the sum of the particle positions, and sum is the total number of particles in the whole population with better fitness value than the i-th particle.
The algorithm uses a greedy strategy to improve the quality of the initial solution and uses the nearest neighbor heuristic mechanism to accelerate the convergence rate of the particles. In the process, the diversity of the population will decrease. In order to avoid particles converging to the best particles too fast, this paper proposes a self-learning strategy (SLS). Unlike other particles, because the best particle in the world does not have a role model for relative learning, it is easy to fall into the local optimum. This paper proposes SLS, which can help gbest jump out of a local value and obtain a better global optimal value. If gbest finds a better value, it will lead other particles to jump out of the local optimal value and converge to a new field. A new gbest value is obtained through SLS as formulas (24) and (25).
Among them, D is the number of particles, VM
num
is the number of virtual machines, and P
d
is a random integer from 1 to VM
num
. SLS randomly selects the one-dimensional d of particle i from the historical value of gbest, and the corresponding value is P
d
. Among them, the probability of being selected for each dimension is the same. The self-learning strategy obtains
For the update process of the global optimal solution, fit1 is the fitness corresponding to the historical global optimal solution. Through the learning process of k times, the global best position of the particle is changed, and the new position corresponding to the fitness function fit2 is calculated. When the fitness value is good, the learning stops, the new global best position newP is obtained, and the obtained global optimal solution ngbest is calculated.
This system is mainly aimed at the population of college students and in-service staff who have college English cross-cultural teaching needs. This article uses a vertical engine to build the system. Users who use the vertical search engine system will pay attention to the accuracy of the search results, whether the amount and variety of cross-cultural teaching knowledge included in Great English is rich, and whether the system is easy to use and operate. The use case diagram of the system user is shown in Fig. 2.

Use case diagram of system users.
The main function of the information index module is how to complete the establishment of the mapping in the index database and related configuration work before the data is imported into ElasticSearch, to support the corresponding storage of data. After that, it imports the data after the crawler processing into the index database in real time. In the process of importing data, Chinese word segmentation should be performed on the MOOC information data, the index of the data should be established, and special field data processing should be performed on the search suggestion function. After the data is imported, data support is provided for the user retrieval service. The use case diagram of the system administrator of the python module is shown in Fig. 3.
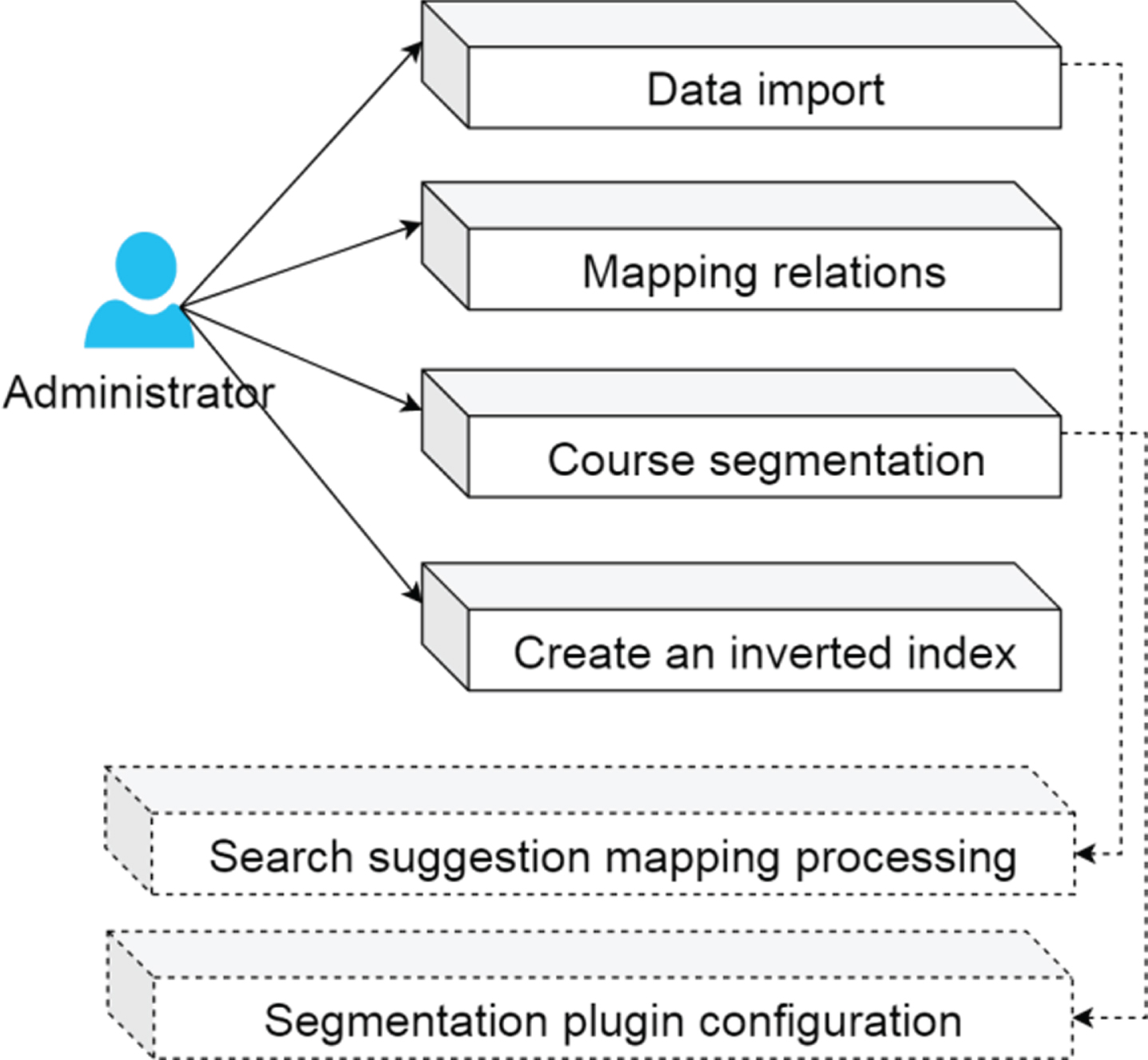
Use case diagram of System administrator.
The information index module is to perform Chinese word segmentation on the processed data, define mapping, and establish an inverted index. ElasticsSearch supports a variety of word segmentation plugins, but it is not ideal for Chinese support, and it is impossible to accurately segment Chinese vocabulary. Therefore, the system uses the IK word segmentation plugin of the Chinese Academy of Sciences to meet the retrieval requirements. The course name, course introduction and other information in the course information are segmented, so that when the user searches for the corresponding vocabulary, accurate index content can be provided. The mapping is the type of data storage in the index database, which can be specified manually. Using the appropriate type to store data can improve retrieval efficiency. Inverted index is an index method used to store the mapping of a word or document in storage and is the most commonly used data structure in retrieval systems. It can provide the basis for searching data for subsequent user searching modules. The user retrieval module is a web page that provides users with data retrieval and is a medium for data interaction with users in the system. Its function is mainly to search for suggestions and retrieve data. When users are retrieving courses, they can give users prompts for search suggestions in real time to help users associate keywords, reduce spelling errors, and improve the search experience. After the user clicks on the search, it can interact with the background index server, perform multi-field matching search on the course information, and return the search results to the front-end WEB page for the user to browse. The functional module structure diagram of the system is shown in Fig. 4.
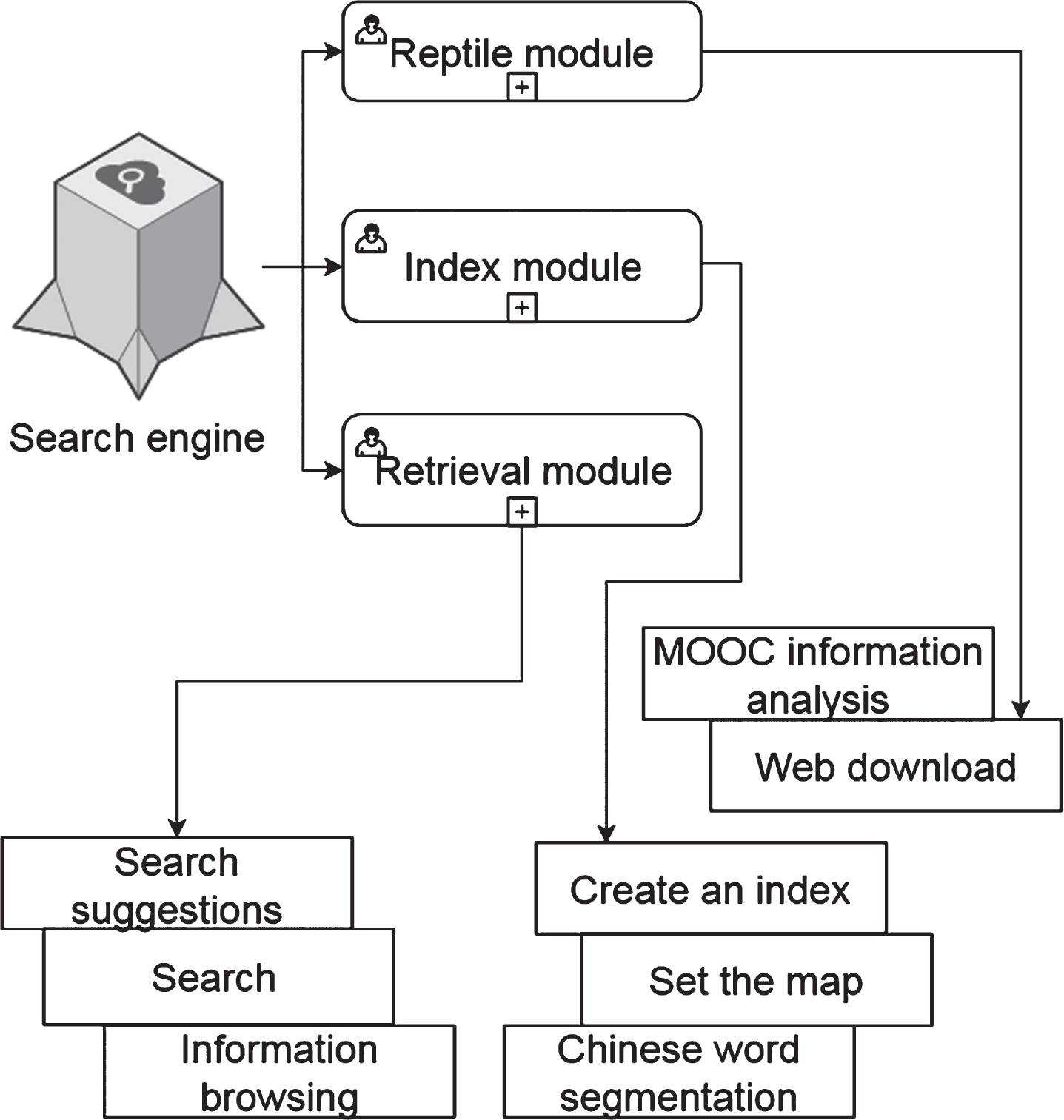
System function module structure.
The data used in this research involves nearly 100,000 topic posts in the College English Intercultural Teaching Curriculum Forum. The total number of reply posts is more than 700,000, and most of the courses require students to complete homework. Courses that need to complete computational tasks are quantitative courses, such as courses that require students to program or complete computational tasks. There are also some courses that are experienced, that is, the grading of the course is not done by completing the calculation task, but the student’s work is graded through the experience of the professor. The number of topic posts in each course ranges from 102 to 9,200, and the total number of students studying the course ranges from 101 to 11,929. The number of forum posts per course is shown in Fig. 5. The abscissa indicates the coding of each course, and the ordinate indicates the number of topic posts in the course forum.
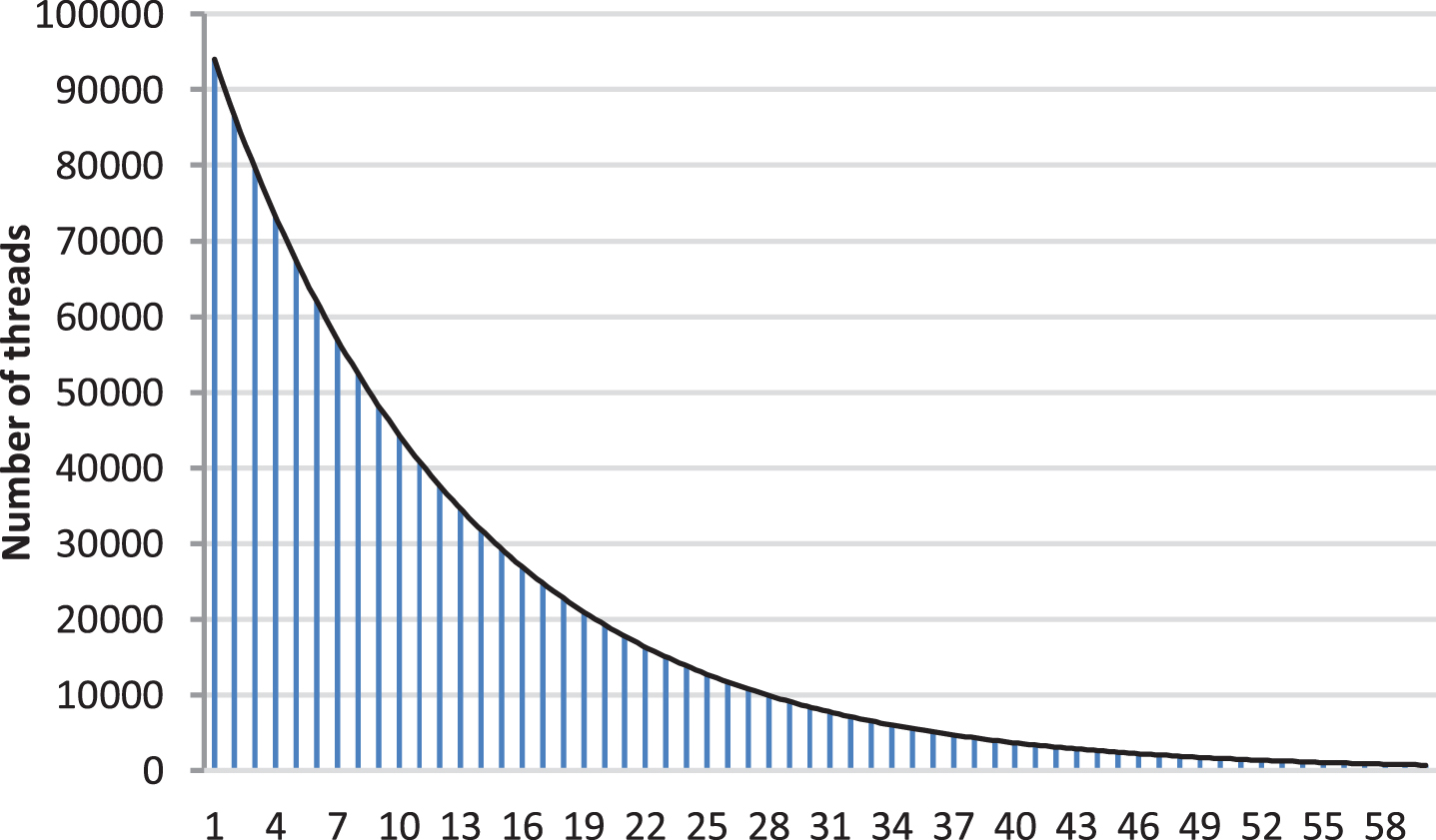
Statistics of the theme posts of the MOOC course forum course.
Since the collected raw data is in JSON (JavaScript Object Notation) format, this study uses java to convert the JSON format into a processable data format, and then extracts the pre-processed data and analyzes and models it. The data description used in this study is shown in Tables 2 and 3. The attributes in Table 2 represent some characteristics of a topic post, and Table 3 describes the characteristics of the reply post in the topic post. The title of a topic post can also be considered as the content of the topic post. The first reply post of each topic post is usually the content posted by the topic post publisher, and its id is the same as the topic post id. Each reply post may have a comment (comment), which is considered to be a type of reply post.
Data feature attributes of topic posts
Data feature attributes of reply posts
At present, most of the research on MOOC focuses on the click behavior and dropout rate of students. In fact, the enthusiasm of students to participate in the course forum is also one of the important factors that affect the learning effect of students in MOOC.Usually, students will often participate in the discussion of the course forum during the course of learning the course. Figure 6 shows the relationship between the number of students posting on the Coursera platform course forum and the course progress. The abscissa is the normalized relative time. It can be clearly seen from the figure that most students post non-anonymously, and the number of discussion posts at the beginning of the course is very large. There are still posts posted until the end of the course. The study points out that the more motivated the students are to participate in the course forum, the better their grades in the course. However, the more topic posts in the course forum and the more complicated the categories, the harder it is for students to effectively choose the content that interests them, and the interest in the course forum will become lower and lower. The traditional text-based recommendation is usually difficult to obtain the required information, and the algorithm cannot identify synonyms, resulting in more noise, lower text similarity, and poor accuracy. Recommendations based solely on collaborative filtering cannot accurately express user interests because they do not involve content information. This article proposes an improved collaborative filtering topic recommendation model for the above-mentioned problems and recommends the topic posts of the course forum to the users, so as to make the recommended content as close to the user’s interest as possible, and increase their participation in the course forum.

Relationship between the total number of student posts and course progress.
Through the above research and analysis, we can see that the network model constructed in this paper has a certain effect. After that, the performance of the model is verified. First of all, this study combines the actual situation to analyze the performance of the model constructed in this paper. The experimental teaching is conducted through the experimental class and the control class for a month, which is English cross-cultural teaching. The results obtained are shown in Table 4 and Fig. 7.
Statistical table of experimental teaching
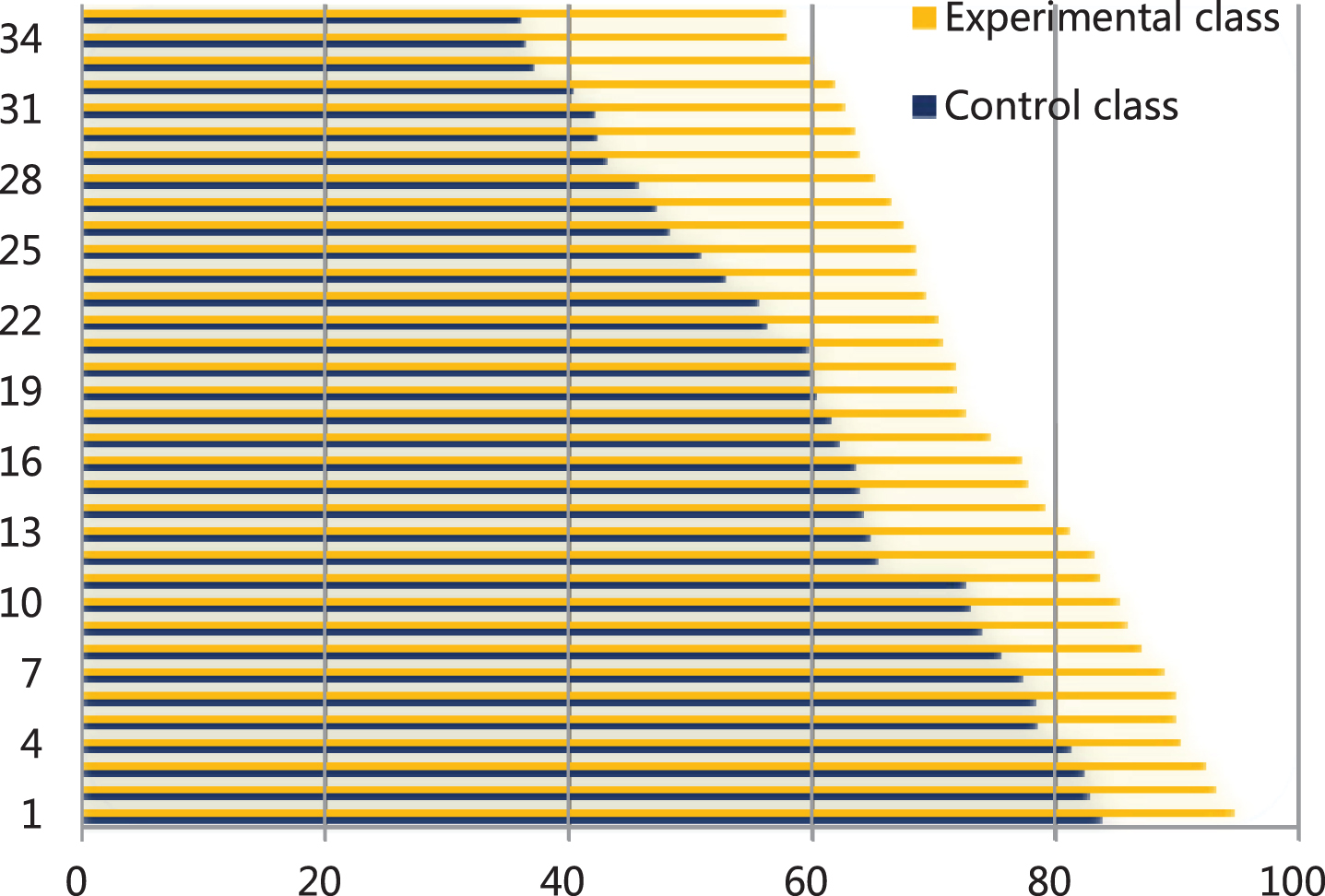
Statistical diagram of the scores of the experimental group and the control group after the experimental teaching.
s
It can be seen from Fig. 7 above that the results of the students in the experimental group are higher than those in the control group. Except for the differences in the teaching systems used, the rest of the teaching factors are the same. It can be seen that the model constructed in this paper has good teaching performance. After that, the attraction of the model constructed in this paper to students is compared with the traditional MOOC model. The results are shown in Table 5 and Fig. 8.
Statistical table of students’ interest promotion in learning caused by the model

Statistical table of students’ interest promotion in learning caused by the model.
As shown in Fig. 8 above, the model constructed in this paper can effectively attract students’ interest in learning English across cultures. This shows that the model constructed in this paper has good performance.
Based on the rapid development of college English cross-cultural online education in the current era of big data and the research background of data mining and machine learning at home and abroad, this article extensively investigates and analyzes the important theoretical value and practical significance of data mining for large online open courses. Moreover, this study expounds and compares the research status of large-scale open courses at home and abroad, proposes a MOOC topic classification method based on cloud computing and artificial intelligence, and studies the scheduling algorithm of task assignment to virtual machines. For the cloud computing scheduling system model, the cloud system first extracts the heterogeneous physical resources into the resource pool through virtualization technology. When different users submit tasks to the cloud system, the tasks are cached in the waiting queue, and then the system scheduler assigns the tasks to the appropriate virtual machine to complete the execution. In addition, this study constructs a corresponding model and analyzes the functional structure of the model. Finally, this study combines with actual needs to design a control test to verify the performance of the model. The research results show that the proposed model has good performance.
Footnotes
Acknowledgments
This research has been financed by the Higher Education Teaching Reform Project in 2019 of the Department of Education of Guangdong Province “Exploration of ‘Flip Classroom’ Teaching Mode of Integrated English from the Perspective of Internet Plus Education” (NO: 20191206).