
Abstract
The three-dimensional intelligent simulation of image art design is an important means of current image art design, which is affected by many factors. The traditional 3D intelligent simulation technology has certain defects, which leads to certain defects in 3D artwork. This paper builds a three-dimensional art design system based on dynamic image detection and genetic algorithm. The system simulates the actual dehazing method, and this paper proposes a dehazing algorithm suitable for this system and proposes to use bilateral filtering instead of median filtering. Because bilateral filtering has good edge retention, it can eliminate the blockiness caused by median filtering. Moreover, this paper uses FMM (Fast Marching Method) algorithm to repair the image. In order to verify the performance of the model, this paper conducts quantitative evaluation through system simulation and user satisfaction survey methods. The research results show that the method proposed in this paper has a certain effect and can be applied to practice.
Introduction
The three-dimensional image art industry belongs to the rising industry of the country’s key development, and traditional cultural art belongs to the scope of traditional art. The development of traditional culture and art is becoming more and more diverse and its forms are also expanding in other fields. Logo design, film and television production, Icon, clothing design, architectural design, industrial design, and mathematical folding, aerospace, mathematics, the problem of plane foldability, and the application in bionics are all important research topics. Moreover, many creative inspirations are derived from traditional culture and art [1].
People’s access to information is becoming more and more widespread, which promotes the improvement of people’s aesthetic appreciation, and changes and refreshes people’s views on art forms and concepts. Art is also looking for breakthroughs in their respective fields and attempts to use different creative techniques and expressions to express their emotions. At the same time, with the continuous development of contemporary art and the cross-border and interactive form between modern disciplines, the concept of art painting in the past cannot cover the new concept of modern art painting. The expression forms of art paintings are also various. They are no longer restricted to the presentation of two-dimensional art paintings but get rid of the expression of the art paintings on the shelf to the three-dimensional art paintings. In the field of fine arts, art painting is the one closest to the progress of modern science and technology. Compared with other paintings, the production process of art painting is more complicated, and the required mechanical equipment is relatively limited. Therefore, art painting can best reflect the development of the scientific and technological level of an era. In today’s network age where visual information is developed, people obtain a rich visual experience through the Internet, mobile terminals, offline exhibitions and other means. At the same time, these visual elements are constantly stimulating the eyes of the public, prompting the improvement of the public’s level of aesthetic appreciation, and changing and refreshing the audience’s views on art forms and concepts. In addition, it also forced art painting artists to break the original traditional thinking mode and get rid of the constraints on media materials and expressions to try to re-create art using the new art painting language. Due to social progress and the improvement of scientific level, the wide application of the Internet, communication technology and electronic equipment has caused a huge impact on the art field. Art paintings have always been dominated by traditional art paintings. Nowadays, scientific and technological information technology has quietly intervened in the process of art painting creation. Artists use new technologies to combine with traditional art paintings. The concept maps output by the computer can help the artists more intuitively and create more room for creation. Science and technology and media materials can also provide more diverse artistic conditions for artistic painting creation. In addition, art painting artists are also looking for new art painting languages and trying to combine new media materials and multi-dimensional expressions to create art paintings [2].
Under the premise of inheriting the traditional art painting language and the spirit of art painting, the rational use of modern and contemporary art and cultural resources to gradually apply and infiltrate them into the field of art painting will have a very significant impact on the future art painting art [3].
Related work
As a key technology in the naked-eye 3D display technology, the virtual viewpoint generation technology has received extensive attention from researchers at home and abroad. At present, virtual viewpoint generation methods are mainly divided into three categories, namely, model-based virtual viewpoint rendering technology (MBR), image-based virtual viewpoint rendering technology (IBR) and depth image-based virtual viewpoint rendering technology (DIBR). Among them, the MBR technology calculates and restores the three-dimensional model of the original view based on multi-view image information and computer modeling technology, and then obtains virtual view images at different positions through three-dimensional space mapping. The main disadvantage of this method is that it is difficult to model, and in complex scenes, the modeling accuracy is not high, which tends to result in poor quality of the generated virtual viewpoint image, and it is impossible to truly restore information such as scene colors and textures [4]. The main feature of the IBR technology is that this method does not require three-dimensional modeling of the scene and can obtain virtual viewpoint images through methods such as matching mapping between pixels, interpolation or image deformation. Due to the relatively fast processing speed of this method, it has received extensive attention. However, this method requires high matching mapping accuracy between pixels [5] and is prone to distortion and unnatural transitions between virtual viewpoints. The DIBR method needs to know the true depth information of objects in the scene in advance. The depth information can be obtained through hardware, such as a near-infrared camera, etc., or the depth image can be calculated through multi-viewpoint information. Then, it generates a virtual view point image by 3D mapping for each pixel point and by judging the occlusion relationship between the pixels. The DIBR method is faster, but the method requires high quality of the depth image obtained by hardware or software, and it is easy to produce artifacts and holes [6].
In comparison, MBR technology is too complicated for modeling complex scenes and difficult to model. Therefore, more research is currently performed on the virtual viewpoint generation method based on IBR technology and DIBR technology. Since DIBR technology needs to obtain accurate depth images of objects in the scene in advance, which is often difficult to obtain, this article will focus on the virtual viewpoint image generation method based on IBR technology. In the naked-eye 3D display technology based on the left and right views, image correction technology and virtual viewpoint rendering technology are two key technologies for virtual viewpoint image generation [7]. In terms of image correction, the literature [8] combines the Seitz method and the Francesco method, and proposes a new method of epipolar correction. This method can effectively avoid the possibility of falling into local optimization when calculating the projection transformation matrix, and through comparative experiments, it is found that this method can improve the quality of the corrected image to a certain extent. The literature [9] proposed a method based on finding matching point pairs of images and calculating a correction transformation matrix according to the vertical disparity of matching point pairs. This method can effectively reduce the vertical disparity of left and right views. The literature [10] uses the principle of the epipolar geometry of the image in three-dimensional space and introduces a shear transformation process that keeps the aspect ratio of the image unchanged, which effectively reduces the geometric deformation of the image. The literature [11] proposed an image correction method based on camera calibration. This method designs the ideal optical center and optical axis and estimates the depth information of the scene through corner matching to further reduce the vertical error. In terms of virtual viewpoint image generation, literature [12] proposed a virtual viewpoint image generation method based on edge feature point matching and Delaunay triangulation. This method first calculates the edge feature point matching information of the left and right views, and then constructs the Delaunay triangle network from the feature point coordinates, and finally uses the triangle network mapping method to deform the intermediate viewpoint to obtain the virtual viewpoint image. This method can get good quality virtual viewpoint images, but it does not have good 3D visual effects, and it relies too much on the matching accuracy and number of feature point pairs. The literature [13] proposed a virtual viewpoint rendering method based on image pyramid repair. This method mainly fixes the problem of holes in the virtual viewpoint, uses the depth information as the weighting condition in sampling, performs Gaussian plus zero elimination filtering and downsampling, and then upsamples through the low-resolution image to perform hole repair. Experimental results show that this method can effectively suppress the generation of artifacts while performing hole repair, but this method is also very dependent on the accuracy of the input depth image or the calculation of the depth image. The literature [14] proposed a new method of virtual viewpoint synthesis based on DIBR. This method mainly processes the depth image in the spatial and temporal domains to increase the accuracy of the depth image. At the same time, it uses two mappings to fill in the cracks to obtain a virtual viewpoint image with better quality. The literature [15] proposed a method for calculating the dense parallax matrix based on the TV-L1 optical flow method and calculating the virtual viewpoint image based on the dense parallax offset. The literature [16] proposed a virtual viewpoint rendering method based on depth-guided hole filling. This method makes full use of depth information and spatial position information to achieve hole filling.
The literature [17] proposed the View Morph-ing algorithm in image correction. Based on the principle of epipolar geometry, the algorithm calculates the basic matrix based on the matching point pair information and proposes a method for calculating the homography matrix for image correction. The literature [18] proposed a new projection correction method. This method does not need to calculate the basic matrix and polar geometric relationship, but only needs to calculate the projection transformation matrix based on the inherent basic matrix information of the corrected stereo image pair while ensuring the optimal result. Experimental results show that the method still has better robustness in the presence of noisy and inexact matching point pairs. The literature [19] proposed an uncalibrated image correction method based on epipolar geometry. This method mainly aims at image correction for left and right views with small parallax. The literature [20] proposed a multi-viewpoint image correction method based on internal parallax consistency constraints. The author performed image correction by setting an objective function that guarantees internal parallax consistency between multi-viewpoint stereo image pairs. The literature [23] addresses the various problems in the field of vehicle communication with the suggestion of a mutual unified and dispersed spectrum sensing model. The application of the mutual cognitive paradigm minimizes conflict and multiple unknown problems. The literature [24] discusses the problem of vast volumes of big data and introduces the SmartBuddy idea of an adaptive and smart world incorporating human activity and human dynamics. The literature [25] talks about the development in parallel reconfigurable computing systems of a directed acyclic graph for video coding algorithms for motion estimation. Partitioning algorithm also plays a major role in speeding up the production of images. The article [26] deals with leveraging IoT and BigData Analytics in real-time applications using the Hadoop platform. The above-mentioned processes enable the deployment of an IoT-based Smart City. The article [27] centers on IoT and its major part in sophisticating the human practices and endeavors. This paper moreover managed with the collection of different information from different assets that are associated to the web [28, 29].
Image defogging algorithm based on statistical information
(1) Algorithm principle
The algorithm of this study mainly imitates the improvement of the clarity in the foggy environment. In the foggy environment, the atmospheric scattering model can also be expressed as:
Among them, L∞ represents the global atmospheric light, ρ (x) represents the reflectance of the target object, and e-βd(x) is the medium transmission rate. Meanwhile, I (x) is the foggy image. If it is assumed that depth of field isd =∞, then the medium transmission rate is e-βd(x) = 0, the resulting image is only the result of atmospheric light. Then, according to formula (1), a parameter is defined:
In formula (2), c represents the r, g, and b color channels. It is assumed that no suspended particles affect the reflected light of the target scene, that is, e-βd(x) = 1, the image imaging only depends on the attenuation model, and the second parameter is defined according to formula (1) [21]:
Therefore, according to formula (2) and formula (3), formula (1) can be equivalent to:
Among them, γ and α are normalized color vectors, and scalars D (x) and A (x) are:
Next, the foggy image is white-balanced, so formula (4) becomes:
Among them, I′ (x) represents the input image after white balance, D (x) γ′ (x) is the target image of the scene to be restored after white balance, then only A (x) is required to get D (x) γ′ (x) (β and L∞ are assumed to be global invariants).
Tan believes that the contrast of outdoor images in foggy weather is lower than that in clear weather, then: The contrast of the output image D (x) γ′ (x) is higher than that of the input image I′ (x); Under the condition that the reflectance ρ is unchanged, A (x) and the depth of field d are related. Therefore, under the condition of the same depth of field, the A (x) value of adjacent pixels in the local area changes gradually;
Then the number of gradient edges can be used to characterize the contrast of the image [22]:
Among them, ∇I
c
(x) represents the gradient of three channels, then the higher the contrast of an image, the greater the C
edges
(I) value. It has been found through experiments that the C
edges
(Dγ′) value of the image after defogging will gradually increase with the increase of A. When it reaches a peak, it begins to decrease. Therefore, in order to obtain the maximum value of A, C
edges
(Dγ′) is required. Since the change of A in the local area is gentle, a Markov random field is used to model A. The model is as follows:
Among them, E is called Markov random field, which is a group of random variables, which means that the distribution of A value is defined in the local area block centered on x. p
x
is the local area centered on x, A
x
is the A value in the block area, and η is the smooth intensity parameter. Meanwhile, N
x
represents the neighborhood of pixel x. The first item on the right side of the Equation (9) is defined as a data item:
The second term on the right side of Equation (9) represents that the smooth term of neighborhood A
x
is defined, and the expression is:
Then, by maximizing the probability distribution p ({ A x }) of Gibbs points, the maximum A x can be obtained, and finally the defogging image can be obtained.
In summary, the specific steps of the algorithm are as follows: The highest pixel value in the world is used to estimate atmospheric light L ∞; The value of α is estimated by L ∞ using formula (2); White balance the input image I to get I′; Formula (10) is used to calculate data items; Formula (11) is used to calculate the smoothing term; A
x
derived from steps 4, 5 The media transmission rate is restored by A
x
, and finally the defogging image is obtained;
(2) Algorithm implementation
In order to verify the feasibility and defogging performance of the algorithm in this section, this paper carried out several sets of simulation experiments on defogging outdoor foggy images. The experimental results are shown in Fig. 1. Among them, the first column represents three images with fog, and the second column is the image after defogging. Although the original intention of this method is to restore the foggy image through the atmospheric scattering model, and the fogging image can be defogged, this is not from the perspective of restoring the image imaging factor, it does not restore the image in essence, but only improves the contrast of the foggy image. In addition, from the perspective of depth of field, the possibility of sudden change of depth of field is ignored, and the solution to atmospheric light is only obtained by the brightest pixel on the image, which is easy to cause misjudgment of atmospheric light. For some outdoor images, Halo phenomenon will occur, and the effect of defogging is not complete.

Result of defogging algorithm based on statistical information. a), c), e) foggy image b), d), f) defogging image.
1) Algorithm principle
Among the defogging algorithms based on atmospheric scattering models, there is an important algorithm based on a constant albedo idea. The so-called constant albedo is that the albedo of the image is independent of each pixel. This independence leads to a certain degree of freedom. Therefore, the restored image J (x) in the atmospheric scattering model is regarded as the product of the surface albedo R of the image and the surface chromaticity l of the surface object. It is assumed that R is the same in the local area, so there is J (x) = Rl (x), then the atmospheric scattering model, that is formula (12) becomes:
Then, the albedo R is divided into two parts. one part is perpendicular to A, that is, R′, and other part is parallel to A, that is R
A
. Meanwhile, I is also divided into two parts. Similarly, one part is perpendicular to A, that is, IR′, and other part is parallel to A, that is I
A
, then the transmission rate t (x) and the surface chromaticity l (x) of the object can be derived:
In Equation (13), we set
Among them,
Among them, I′ = I - AI
A
/ -∥ A ∥, the distance between adjacent pixels is expressed by the shortest arc length:
In formula (17), θ1, θ2 is the chromaticity angle of adjacent pixels.
According to the covariance formula, the sample is Ω
x
and the weighted covariance formula is redefined:
Among them, we defined:
Formula (20) is a weighting function, W x = ∑y∈Ω x w (x, y) is the normalized weight, and the transmission rate t (x) is calculated according to formula (18) and formula (15). Finally, the Markov model is used to standardize the noise in the transmission rate to obtain the accurate transmission rate t (x), and then the final defogging image is obtained by estimating A.
The method steps are as follows: The value of atmospheric light A is estimated; The foggy image I is input, the image is processed in the YUV space according to the redefined sample space covariance, and the media transmission rate t (x) and density l (x) are calculated by using Equations (13) and (14); In Markov random field, the medium transmission rate t (x) is optimized; The atmospheric scattering model is used to obtain the image after defogging;
(2) Algorithm implementation
Based on the theoretical analysis of the above algorithm, this article verifies the algorithm through experiments. Figure 2 shows the experimental results based on the single image defogging algorithm. By using foggy images for simulation, the contrast effect is more prominently highlighted. The defogging algorithm based on a single image is based on the idea that the constant albedo in the local area is independent of each pixel. It can effectively restore the state of the image when there is no fog and its restoration effect is good, and it can suppress the phenomenon of halation due to the sudden change of depth of field. However, this method is based on statistical characteristics and not all images have the same surface albedo, so this characteristic is not reliable in areas where the fog density of the image is inconsistent. Moreover, it is not applicable in a single-tone grayscale image, and the original image cannot be effectively recovered.

Defog effect based on a single image. a), c), e) foggy image b), d), f) defogging image.
(1) Algorithm principle
Among the obstacles to outdoor image defogging, one thing is the speed of image processing, that is, the real-time performance of defogging. The above methods are all processed based on pixels in local areas, which has a high time complexity. The advantage of the fast image defogging algorithm is that it can be effectively guaranteed in time. While achieving a certain defogging effect, it guarantees real-time performance and is widely used in the detection of obstacles such as on-board cameras.
Atmospheric scattering model is mainly divided into atmospheric attenuation model and atmospheric light model. The fast image defogging algorithm restores the image by directly finding the atmospheric light model. From the foregoing, it can be seen that the atmospheric light model is shown in equation (10), then this section makes the atmospheric light model as
The atmospheric scattering model becomes:
We set I (x) = E (d, λ) as the input image, R (x) = E0 (λ) as the requested image, and I S = E∞ (λ) as the atmospheric light. It is assumed that the atmospheric light is known, the atmospheric light model V (x) can be obtained to obtain R (x).
First, the original color is reduced to fog by white balance, and I
S
is set to (1, 1, 1). Second, it is assumed that the value of atmospheric light is known, the size of the atmospheric light model is related to the size of the depth of field. Tarel believes that when the fog is under pure white conditions, there are two constraints: 1. Every pixel will have atmospheric light participating in the imaging. 2. The atmospheric light model is always smaller than the minimum pixel value of the input image. Therefore, the minimum value of the input image is taken as a rough estimate of the atmospheric light model as W (x) = min(I (x)). Then, because the change of the depth of field of different images is different, it is impossible to ensure that the depth of field has always remained stable, V (x) needs to be filtered to smooth the abrupt depth of field part of the image, then the filtered image is:
It is considered that after filtering, there will still be some textures mixed into the fog of the image. In order to filter out these textures, the following processing is done:
Among them, sv represents the size of the filter window, and finally, the atmospheric dissipation function is obtained as:
p is a parameter set in order to maintain the natural depth of the image, and finally the fog-free image can be restored by the atmospheric scattering model.
The method steps are as follows: The input foggy image is processed for white balance to restore the original color of the fog; W (x) is obtained by filtering the image processed in step 1 with a minimum value and used as a rough estimate of the atmospheric light model; W (x) is subjected to median filtering to smooth the abrupt change of depth of field; Formula (24) is used to remove the filtered image texture; The atmospheric light model V (x) is estimated to restore the fog-free image I (x);
(2) Algorithm implementation
Based on the theoretical analysis of the above algorithm, this paper has been verified through experiments and simulations. The foggy image and the image after defogging are shown in Fig. 3. It can be clearly seen from the algorithm overview that the algorithm in this section is simpler than the first two methods. On this basis, it is proposed to use bilateral filtering instead of median filtering, because bilateral filtering has good edge retention, it can eliminate the blockiness caused by median filtering.

Fast image defogging algorithm.
In order to obtain the corresponding epipolar information of any pixel, the basic matrix F needs to be calculated in advance. This matrix contains information about the internal and external matrix parameters of the camera, and vertical correction can be achieved without the need for strong camera calibration. The most commonly used basic matrix calculation method is the normalized 8-point method based on the RANSAC method. The workflow of this method is shown in Fig. 4.
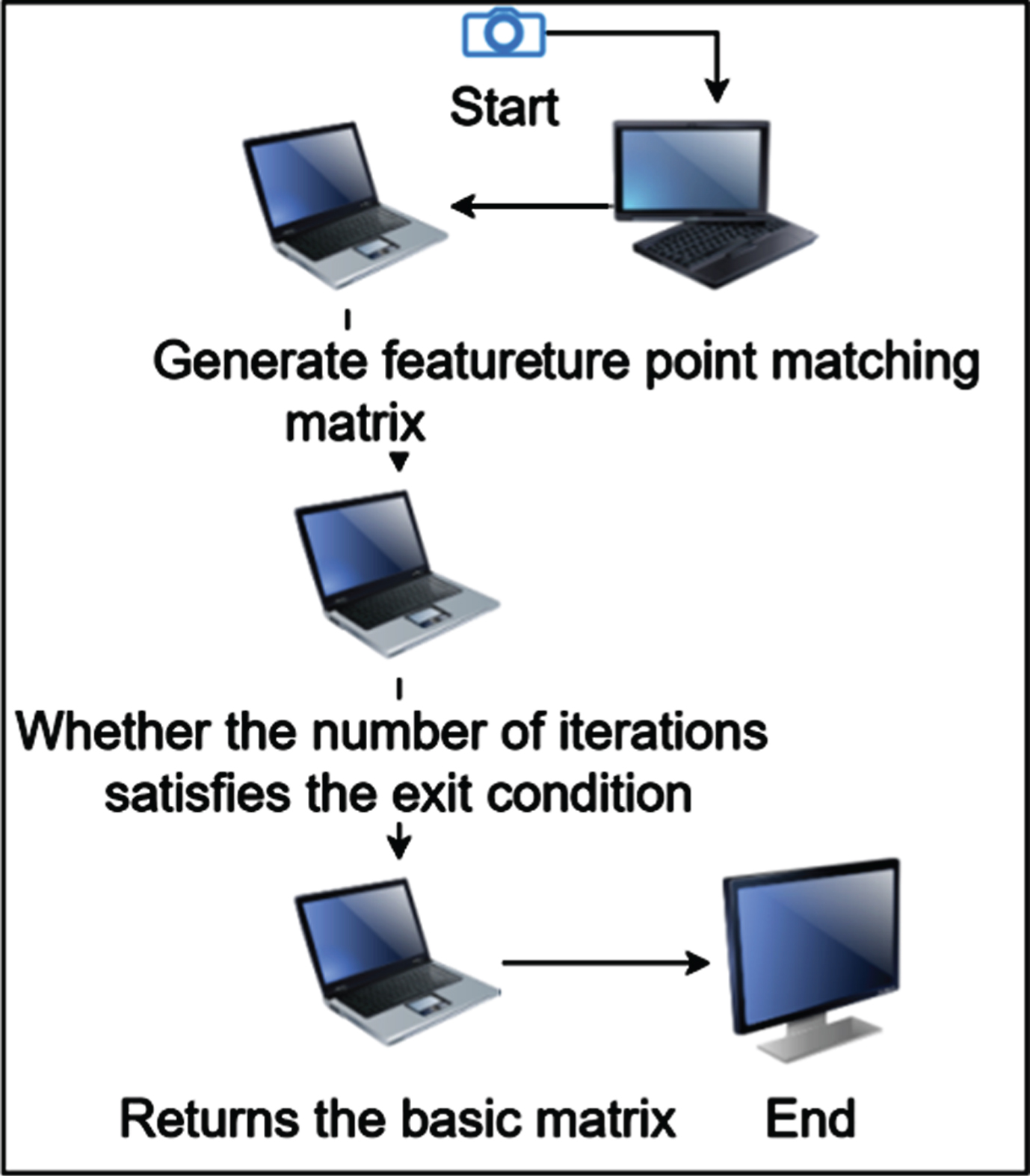
Basic matrix acquisition flow chart.
After that, the image needs to be gradient-processed. By normalizing the gradient matrix to the range of 0–255, the gradient image can be obtained. “Mrs. Xiang” is taken as an example. The schematic diagram of the original image and its gradient image is shown in Fig. 5.

Schematic diagram of comparison between color image and gradient image.
After correcting the dense matching mapping matrix, multiple pixels may be mapped to the same position in the virtual viewpoint. Although the traditional method can solve the problem of remapping, remapping will generate a new “hole” problem, that is, there is a part of content in the virtual viewpoint that is not mapped by pixels. In this case, it is necessary to use image repair algorithms to fill holes in the unmapped areas.
This paper uses the FMM (Fast Marching Method) algorithm to repair the image. The basic mathematical model based on this method is shown in Fig. 6.
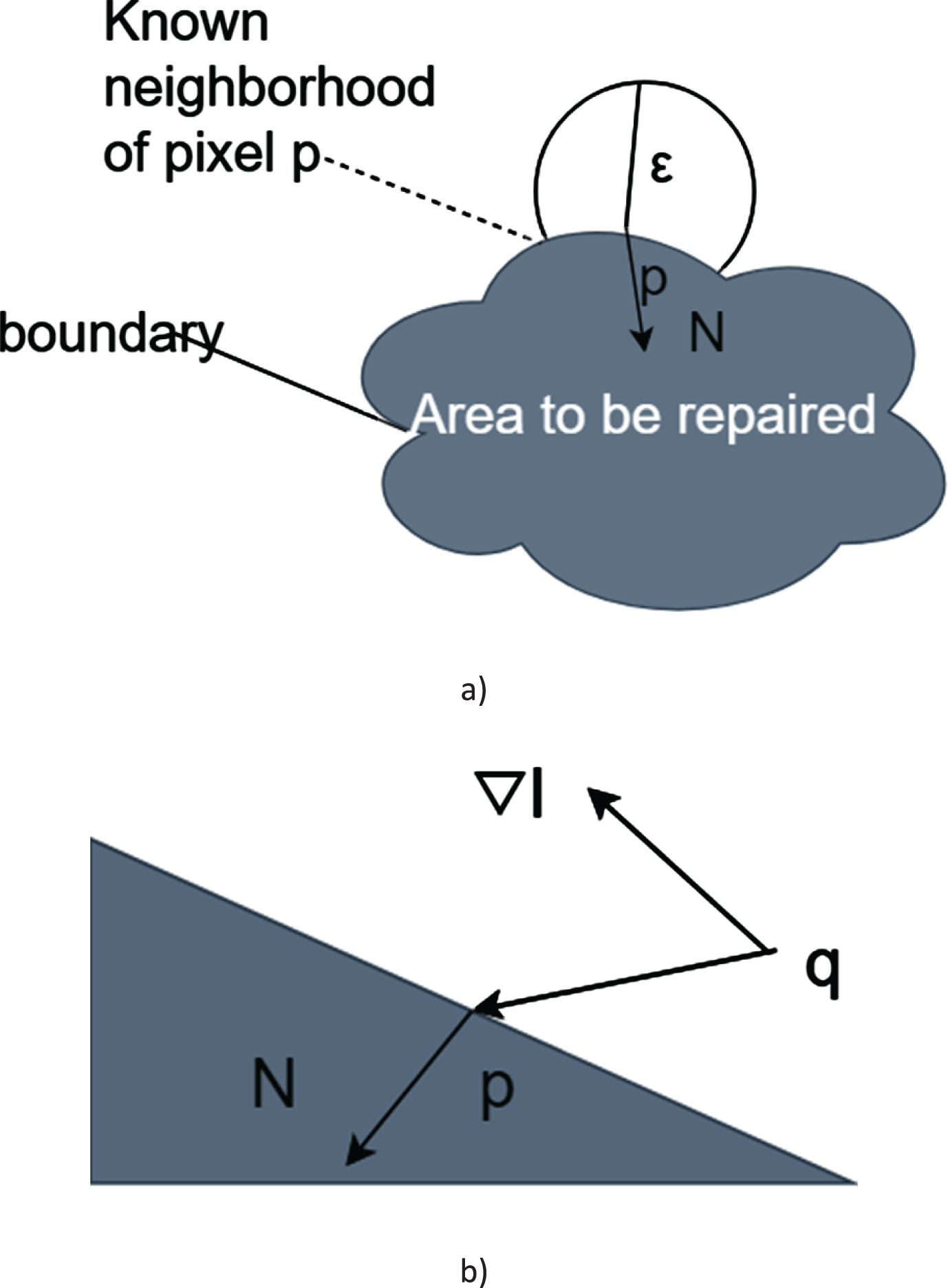
Schematic diagram of FMM mathematical model.
In Fig. 6, as shown in (a), Ω represents the area to be repaired in the image, δΩ represents the boundary of the area to be repaired, and p is any point on the boundary. At the same time, Bɛ(p) represents the center of p with ɛ as the scale Known pixel area. Then, the pixel value at point p can be approximated by the known pixels in the range of Bɛ(p). As shown in (b), when ɛ is small enough, pixel value q and pixel value I(q) and its gradient ∇ I(q) are given, the pixel value of position point p can be calculated by first-order approximation. The calculation method is shown in the following formula.
The main workflow of 3D image art design based on dynamic image detection and genetic algorithm includes feature point matching, construction of triangulation, triangulation mapping, etc. The main flow of this method for generating virtual viewpoint images is shown in Fig. 7.
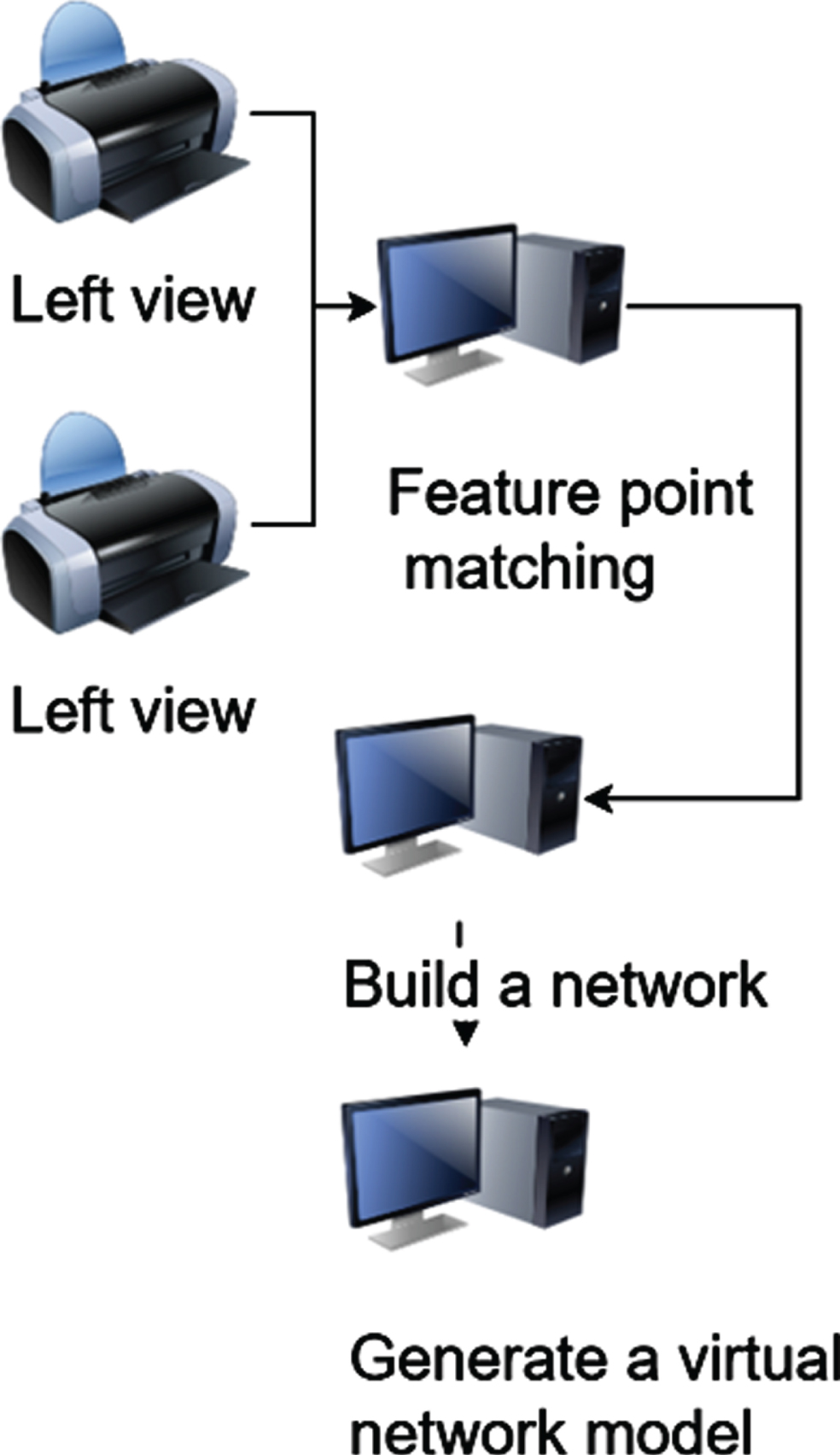
Art design process of Virtual viewpoint image.
A virtual display made using a three-dimensional simulation virtual reality system. Virtual reality itself belongs to the simulation system, so the use of this technology to achieve virtual display is also the future development direction. The high degree of interactivity displayed by virtual reality and the means of displaying in pure three-dimensional space are very similar to the current games. Comprehensively comparing other engines, Unity3D has high technical requirements for development process, good rendering effect and user customization support, which is much higher than other platforms. It has a very broad extension space and can meet all the requirements of interactive access and real embodiment. These features make Unity3D not only popular in game development but also gradually occupy a more important position in the field of virtual reality in recent years.
On the basis of the above analysis, the system constructed in this paper can be obtained, and the performance of the model is analyzed. Since this research is mainly on the research of three-dimensional art design, this research mainly studies the distortion rate of the constructed three-dimensional image and scores the effect of the three-dimensional simulation of the system through survey access.
First of all, the three-dimensional image distortion rate is studied. 100 sets of data are simulated through the model to obtain its corresponding three-dimensional image. The distortion rate is calculated. The statistical tables and statistical charts are shown in Table 1 and Fig. 8.
Statistical table of distortion rate
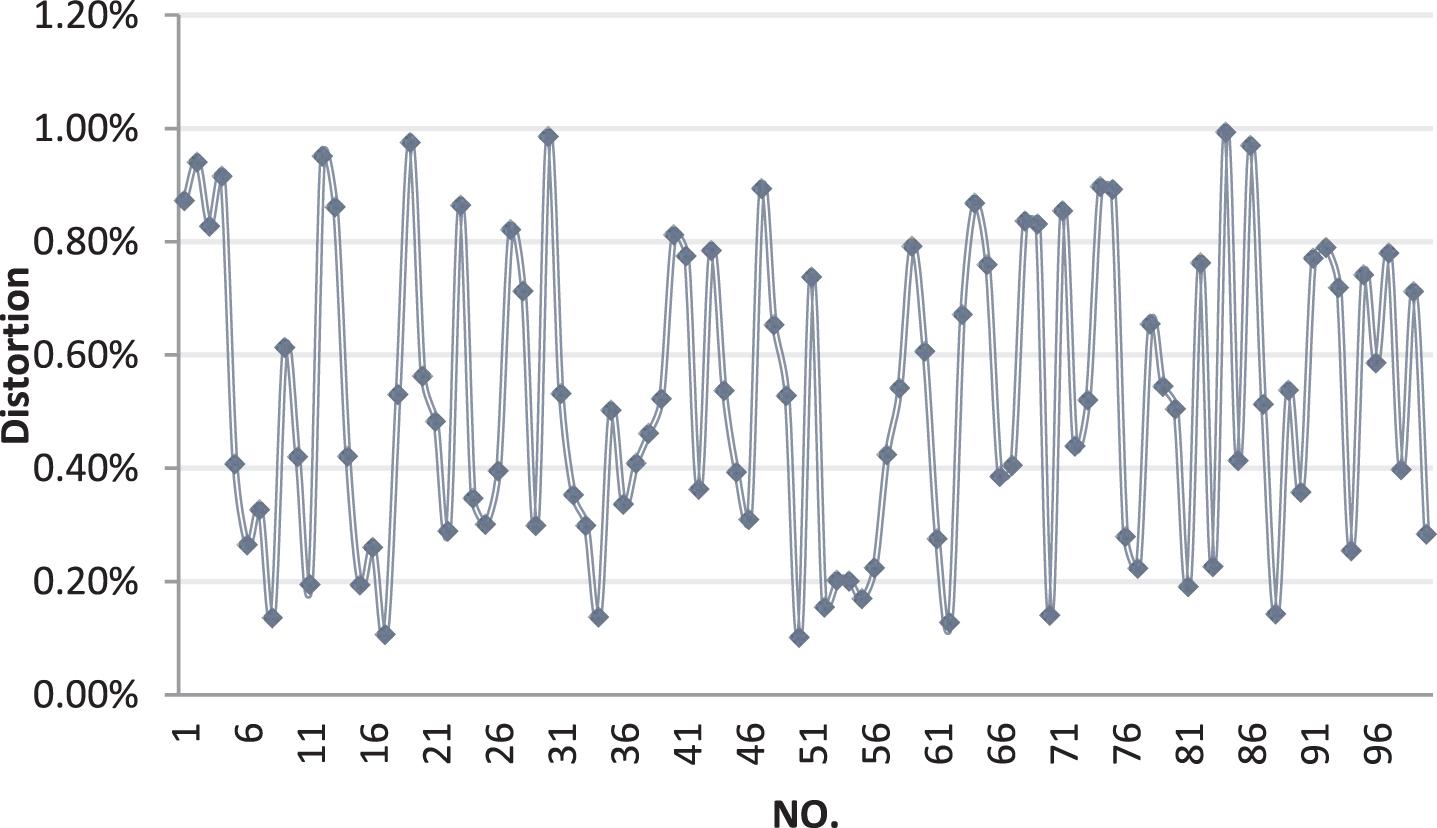
Statistical diagram of distortion rate.
It can be seen from Table 1 and Fig. 8 that the distortion rate is basically below 1%, and this level of distortion cannot be judged by human means, so it can be seen that the method constructed in this paper has a good effect. Next, the satisfaction of users of this system is investigated. A total of 100 groups of people are surveyed and quantified by scoring. The full score is 100. The results are shown in Table 2 and Fig. 9.
System satisfaction score table
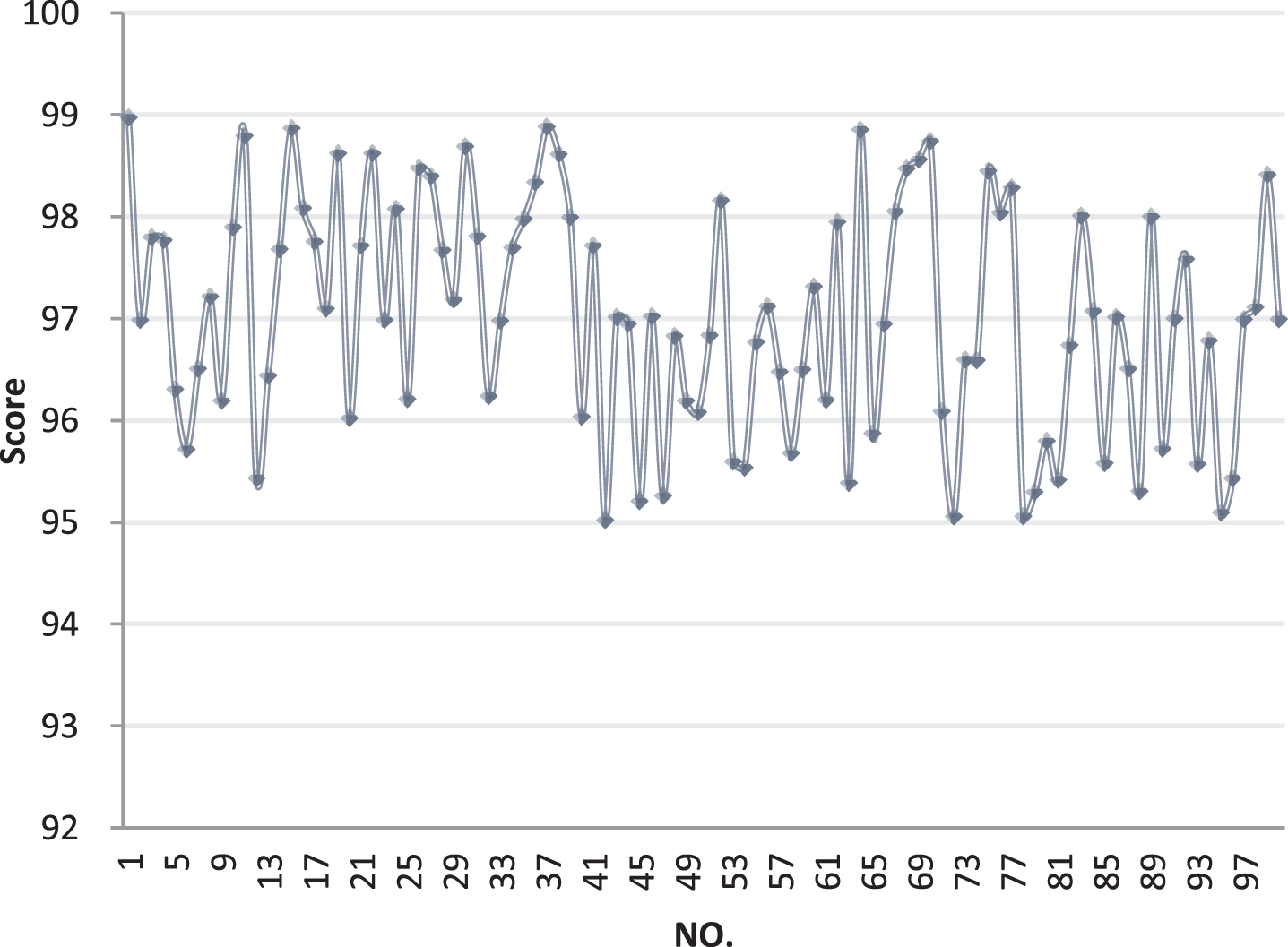
System satisfaction score diagram.
As shown in Fig. 9, the system satisfaction in this paper is above 95 points, and the satisfaction is high, so the method proposed in this paper has a certain effect.
To study the three-dimensional form of image art, it is necessary to break through the thinking mode of traditional images and explore the expression form of image imprints in different perspectives, and finally present it in three-dimensional space. Multi-dimensional works of art can create a new, open, and novel viewing environment for the viewer, and can make the audience jump out of the limitation of watching the works in the picture frame on the wall before. Moreover, it can broaden the public’s field of vision and vision, narrow the distance between art and life, art and the general public, and enable viewers and works to reach a certain resonance. Based on the basis of winter image detection and genetic algorithm, this paper has been verified through experiments and simulations, and the interference elimination in the defogging algorithm is proposed. On this basis, it is proposed to use bilateral filtering instead of median filtering. Because bilateral filtering has good edge retention, it can eliminate the blockiness caused by median filtering, and use FMM (Fast Marching Method) algorithm to repair the image. This research is mainly to study the three-dimensional art design, so it mainly studies the distortion rate of the constructed three-dimensional image and scores the effect of the three-dimensional simulation of the system through the survey access method. The research results meet the expected goals.