
Abstract
With fast developments of artificial intelligence, human behaviors can be further acknowledged by means of the biometric information of hand gesture actions made by the person. Such hand gesture information revealing the specific intention of the person will be undoubtedly a critical clue to cognize human behaviors. Furthermore, identity recognition of the hand gesture-making person is one of the most important technique issues in hand gesture recognition applications. This work explores hand gesture intention-based identity recognition where various deep learning recognition strategies are presented. The well-know image sensor of Leap Motion Controller (LMC) is employed in this work for acquisitions of active hand gesture data. This paper presents four different deep learning strategies for hand gesture intention-based identity recognition, all of which are based on the deep learning model of the visual geometry group (VGG)-type convolution neural network (CNN). The presented deep learning strategies to perform hand gesture intention-based identity recognition are typical VGG-16 CNN deep learning, dynamic time warping (DTW) classifications with VGG-16 CNN extracted deep learning features, DTW classifications by VGG-16 CNN extracted deep learning features with principal component analysis (PCA) data reduction, and PCA centroid classifications using VGG-16 CNN extracted deep learning features with PCA. Compared with traditional hand gesture recognition by classifications of only the geometrical space feature of LMC 3D-(x, y, z) data without any deep learning, most of presented VGG-CNN based deep learning approaches have more outstanding performances on recognition accuracy. In the situation of real-time recognition that considers both of recognition accuracy and computation time, PCA centroid classifications by VGG-16 CNN extracted deep learning features with PCA reduction, FC1-PCA and FC2-PCA features that are estimated from the first and the second fully connected (FC) layer of VGG-CNN respectively (i.e. FC1 and FC2 layers) and then significantly reduced the data dimension by PCA, apparently performs best among all presented deep learning strategies.
Keywords
Introduction
Human behavior understanding will be undoubtedly a critical issue in the field of pattern recognition techniques. It’s well-known that conceptually simple speech recognition [1–4], speaker recognition [5–8] and face recognition approaches [9, 10] have been matured and widely used in various applications nowadays. Compare with these marketing techniques, pattern recognition focused on human behavior cognition has been still an extremely challengeable technique issue in the new generation artificial intelligence category. For human behavior understanding, hand gesture intention-based recognition will perhaps be an effective strategy for realizing such cognition of specific types of human behaviors. Speech recognition and face recognition can be performed according to mainly the acoustic voice data and the visual face data respectively. Likewise, hand gesture intention-based recognition is able to be achieved by the active hand gesture data made by the person. In the aspect of constructing such human behavior cognition by hand gesture intention-based recognition in the real-life application scenario, prior to hand gesture recognition, recognition of the hand gesture-making person identity, i.e. identity recognition of the hand gesture maker, will be the primary task to be taken consideration; the service robot or the virtual agent in the smart home applications will recognize the identity of the monitoring home member first before providing the corresponding feedback service of the recognized hand gesture action. In this work, hand gesture intention-based identity recognition by deep learning of visual geometry group (VGG)-convolution neural network (CNN) [11] is presented for human behavior cognition where different deep learning strategies are proposed and compared on performances.
Recently, studies on human gesture recognition have been frequently seen. Human gesture recognition-based works [12–28] can be primarily divided into two categorizations, body gesture recognition [23–28] and hand gesture recognition [12–22]. Identity recognition of the gesture-making person has been an important issue on both of gesture recognition categorizations. In body gesture recognition studies, the main effort is to analyze an active body gesture with 3D-skeleton sensor data represented by 3D-space location variations of numerous body joints to perform body gesture command recognition [25–28] or body gesture-based identity recognition [23, 24]. Related applications by body gesture recognition include rehabilitation of the aged [25], robot imitations [26], and gesture command-based control with user adaptation [23, 27]. On the other hand, relating to studies on hand gesture recognition, two technique issues are involved, sign language recognition [16, 22] and hand gesture action recognition [12, 18–20]. Most of those hand gesture-based recognition works mainly employ two popular devices for developing the system, the Myo-armband wearable device [29] and the Leap Motion Control (LMC) image sensor [30]. However, system development schemes of Myo-based and LMC-based hand gesture recognition system in these seen works almost entirely belong to non-deep learning types, i.e. the raw data of surface electromyography (sEMG) and 3D space information of the active hand gesture derived from Myo and LMC respectively used directly to be recognized by a typical classifier. Few works aim at the use of specific deep learning models for developing hand gesture recognition applications. Furthermore, it is extremely rarely seen to consider different design types of deep learning features for recognition evaluations of the specific classification approach.
Different to those hand gesture recognition studies, this work explores four different strategies on utilizations of VGG-CNN deep learning for performing hand gesture intention-based identity recognition. Figure 1 depicts the author’s previous study on hand gesture recognition [13] where a typical pattern classification approach, K-nearest neighborhood (i.e. the so-called KNN approach), is adopted. The main work of [13] is to use the LMC image sensor to design the geometrical feature according to the extracted LMC 3D-(x, y, z) hand gesture data, and the KNN method without any deep learning is used to perform classifications of the estimated geometrical features in the LMC-3D space. Different from the previously presented approach in [13], for further evaluating effectiveness and efficiency of the deep leaning approach on hand gesture recognition, this work constructs the hand gesture intention-based identity recognition system based on deep learning calculations of VGG-CNN. The presented four different strategies of VGG CNN-16 deep learning on hand gesture intention-based identity recognition, typical VGG-16 CNN, dynamic time warping (DTW) classifications with VGG-16 CNN extracted deep learning features, DTW classifications by VGG-16 CNN deep learning features with principal component analysis (PCA) data reduction, and PCA centroid classifications using VGG-16 CNN deep learning features with PCA, will be detailed in the following sections.

Typical pattern recognition techniques presented in the previous study using a non-deep learning approach of K-nearest neighborhood (KNN) recognition with the geometrical feature of LMC 3D-(x, y, z) data for hand gesture-based emotion recognition applications [13].
The main contribution of this study is primarily summarized as follows: Appropriate incorporations of VGG-CNN deep learning computations on continuous-time hand gesture intention-based identity recognition applications. Evaluations of various designed features using VGG-CNN extracted deep learning information on recognition performance. Evaluations of effectiveness and efficiency of different deep learning strategies that employ typical pattern classifiers of DTW and PCA with various designs of deep learning features. Performance comparisons among conventional recognition without any deep learning, typical VGG-CNN deep learning recognition, and various presented recognition approaches incorporated with VGG-CNN extracted deep learning features.
This work explores four different strategies of deep learning approaches, typical VGG-16 CNN, DTW with 4096D-FC1 (or 4096D-FC2), DTW with FC1-PCA (or FC2-PCA) and PCA centroid with FC1-PCA (or FC2-PCA), for hand gesture intention-based identity recognition, and all of these presented methods are based on the deep learning framework of the VGG-16 model. Figure 2 illustrates that the continuous-time data of the specified hand gesture intention action performed by the user is acquired by the LMC image sensor. In this study, unlike geometrical 3D-(x, y, z) raw data used as hand gesture features for recognition in the previous developed work [13], RGB image data of continuous-time hand gesture intention actions will be necessary information for VGG-16 deep learning calculations. The reason to use the LMC sensor for acquiring hand gesture intention action data is that the LMC is well-known for its effectiveness on 3D-hand gesture model establishments. In addition, an alternative reason to employ the LMC in this work is to provide a performance comparison between the previous developed scheme in [13] and the presented deep learning-based recognition system in this study. As shown in Fig. 2, the continuous-time hand gesture intention data obtained by the LMC sensor is first recorded in mpeg-4 video files. The video file contains a series of continuous-time RGB images with LMC-3D image rendering. To facilitate VGG-16 processing, images with LMC-3D image rendering information are properly captured (sampled) from the video file using the popular video-to-image conversion application program.

Sensor data of continuous LMC-3D hand gesture images recorded in the mpeg-4 video file (each of 10 different hand gesture actions made by one of 4 subjects, which achieves about 3-sec.).
As mentioned above, the input data of the VGG-16 CNN deep learning model is the set of images, and a series of image frames are captured from the video file, each of which has the size of 1920*1080. Before starting to perform calculations of convolution and max pooling of the CNN model, an image resize pre-processing procedure that transforms the original size of 1920*1080 to the CNN- appropriate size of 224*224 is done first, which can be seen in Fig. 3. Figure 4 depicts the overall framework of the typical VGG-16 CNN model with the LMC-acquired hand gesture data for hand gesture intention-based user identity recognition. As shown in Fig. 4, a series of proper images with the size of 224*224 are used as the model input and then fed to the model for further feature estimates of color variations of pixels. Such the CNN feature estimate is done using a stack of 13 convolution layers with 3 max-pooling layers bundled. When the fed image data completes the calculation of a series of convolution and max-pooling, the estimated new feature set for the original input image of 224*224 then has 4096 parameters (i.e. the CNN-extracted feature with the dimension of 4096).

Data sampling of continuous hand gesture images (1920 by 1080) in the recorded mpeg-4 video file and resizing of a proper image size 224 by 224 for inputs of the VGG-16 CNN model.

The use of the typical VGG-16 CNN deep learning model for hand gesture intention-based identity recognition with input data of LMC-3D hand gesture images.
It is noted after the stack of 13 convolution layers and 3 max-pooling layers of the CNN, the extracted feature set with 4096 dimensions, named as 4096D-FC1 in this work (also see Fig. 4), is then transmitted to the neural network (NN) with the configuration of 3 connection layers for recognition outcome determinations. As illustrated in Fig. 4, there are totally three fully connected (FC) layers, the FC-1 layer (i.e. the input layer of NN), the FC-2 layer (i.e. the hidden layer of NN), and the classification layer (i.e. the output layer of NN) in such neural network for result classifications. It’s also noted that in Fig. 4, the output parameter set of the FC-1 layer used as the input data of the FC-2 layer is named as 4096D-FC2 in this study. Both of 4096D-FC1 and 4096D-FC2 that are extracted from fully-connected layer calculations of VGG-16 CNN are viewed as the deep learning feature parameters in this paper.
Such two different types of deep learning feature parameters obtained from VGG-16 CNN, 4096D-FC1 and 4096D-FC2, will be effectively employed as the feature set for DTW template matching, further data reduction by the PCA approach, and classifications of PCA-based deep learning features by DTW or PCA centriod approaches, which will be detailed in the following sections.
This section will detail the use of VGG-16 CNN extracted deep learning features for the DTW approach on hand gesture intention-based identity recognition. As mentioned in the previous section, 4096D-FC1 and 4096D-FC2 are two main deep learning features used in this study. The primary recognition calculation on pattern categorizations in the DTW method is template matching [31]. DTW with the feature of 4096D-FC1 (or 4096D-FC2) is to make a comparison of similarity between the test deep learning feature and the referenced deep learning feature. In this work, a specified kind of hand gesture actions is completed by the collected gesture-making user at an indicated fixed time period of about 3 seconds. With a setting of 150–200 images captured from the LMC sensor, hundreds of LMC-3D hand gesture images for the performed hand gesture action will be acquired at the time period. Before performing DTW recognition, a feature extraction task to acquire CNN deep learning features is done first. Each of LMC-3D images denoting the making hand gesture action is to estimate both of 4096D-FC1 and 4096D-FC2 feature parameters. It’s noted that for simplicity, the “LMC-3D deep learning frame” is used hereafter to represent the VGG-16 CNN deep learning feature parameter of 4096D-FC1 or 4096D-FC2.
On DTW recognition, the test hand gesture action composed of n LMC-3D deep learning frames (an arbitrary frame represented by test) is performed template matching calculations with the referenced hand gesture action containing m LMC-3D deep learning frames (an arbitrary frame denoted by referenced). The item, d [n (test) , m (referenced)], means the distortion value between these n and m LMC-3D deep learning frames. Equation (1) shows the optimal template comparison path as follows,
Note that in Equation (1), the index D denotes the minimal accumulated distance difference value that is derived from the optimal template comparison path with a comparison end-point at (n (K) , m (K)). Equation (2) denotes the accumulated distances to choose the optimal comparison path as follows,
It’s also noted that the recognition result of the input test template, i.e. the classification label, is the classification label of the referenced template which has the smallest distortion value of minD (test, referenced). The strategy of presented DTW with 4096D-FC1 or 4096D-FC2 for hand gesture intention-based identity recognition by the LMC sensor is illustrated in Fig. 5.
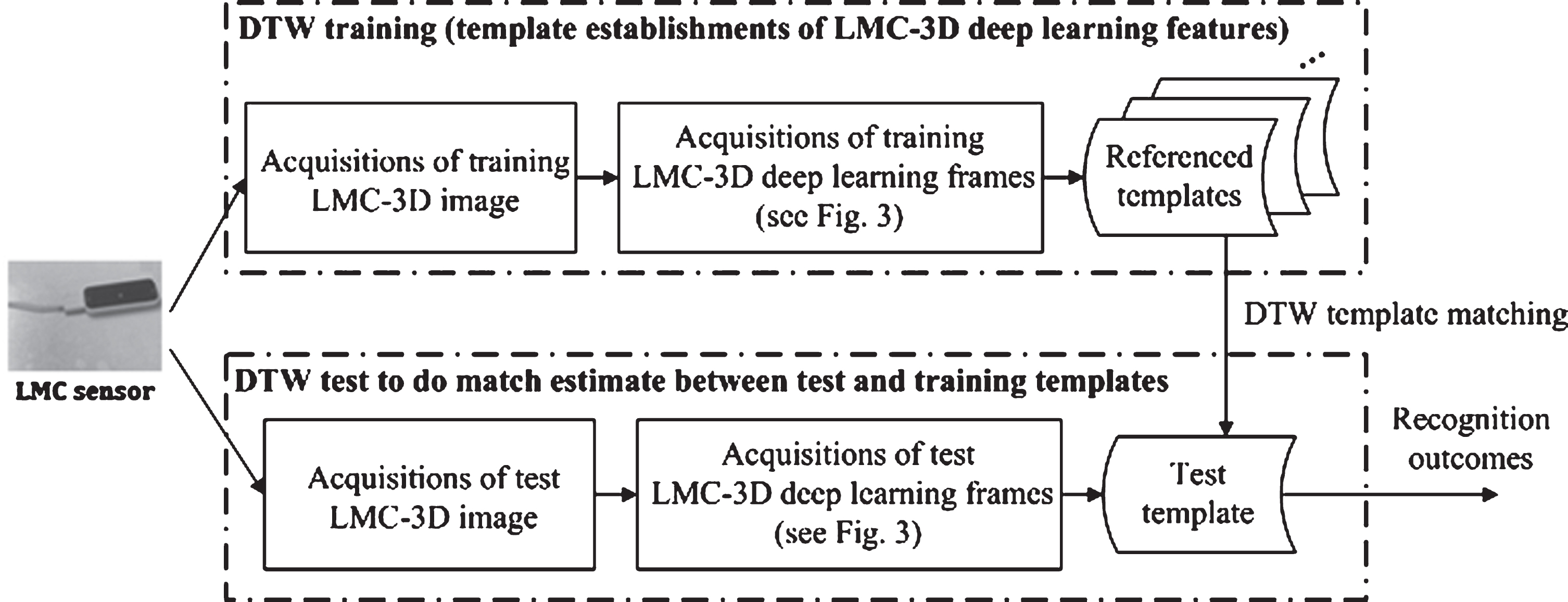
The strategy of presented DTW with LMC-3D deep learning features, 4096D-FC1 or 4096D-FC2, for hand gesture intention-based identity recognition by the LMC sensor.
Feature parameters with high dimensions such as the above-mentioned LMC-3D deep learning features, 4096D-FC1 and 4096D-FC2, each of which contains 4096 parameters, can still be performed classifications using the specific classifier if one can discard the expansive cost of time-consuming computation efforts. In this section, a dimension reduction method of PCA [32] will be efficiently used to significantly decrease the LMC-3D deep learning feature parameters.
As mentioned, two LMC-3D deep learning feature vectors, 4096D-FC1 and 4096D-FC2, each of which has 4096 deep learning parameters (i.e. the 4096-dimension vector), are utilized in this work for constructing hand gesture intention-based identity recognition. The goal of PCA reduction herein is to decrease the original 4096 deep learning parameters as greatly as possible in the situation that the reconstruction error can be achieved the minimum value. In this study, to construct the new feature vector for each of 4096D-FC1 and 4096D-FC2 parameters by PCA is essentially to employ an eigenspace-based method involving principal component analysis of these VGG-16 CNN deep learning features. Such eigenspace constructed for each of 4096D-FC1 and 4096D-FC2 of VGG-16 CNN deep learning features is called as EigenLMC3D-VGGCNN in this paper.
To build up the eigenspace of EigenLMC3D-VGGCNN, an eigen-decomposition procedure shown in the following is carried out first,
It’s noted that in Equation (3), ν is the eigenvector, and λ is the corresponding eigenvalue. In Equation (3), to satisfy the condition of the mentioned minimum reconstruction error, only k eigenvectors in ν chosen for constructing the space of EigenLMC3D-VGGCNN. In this work, in order to keep a little more information of VGG-16 CNN deep learning features, the reconstruction error will not be the standard minimum value. The alternative is to set the threshold of an acceptable reconstruction error to estimate the number of the eigenvectors. Totally 90 eigenvectors, i.e. k = 90, employed in this work to perform hand gesture intention-based identity recognition. Equation (4) denotes deep learning feature projection of the original feature space to the new eigenspace with k eigenvectors.
Note that in Equation (4), μ is the mean vector of the original deep learning feature parameters, X4096N, in which N denotes the amount of the total training deep learning feature vectors associated with a specific gesture-making user; X i denotes the i-th eigenvector; T is the projection matrix to perform space transform of deep learning features. By Equation (4), the new space of large-sized deep learning features of 4096D-FC1 (or 4096D-FC2), i.e. Eigen space of CNN deep learning features, can then be obtained where each data-reduced deep learning feature vector has exactly k dimensions.
By using the PCA approach mentioned above, two LMC-3D deep learning feature parameters, 4096D-FC1 and 4096D-FC2, will be significantly decreased the data dimension and transformed to two new types of deep learning feature parameters, namely FC1-PCA and FC2-PCA, respectively. Figure 6 depicts the strategy of presented DTW with FC1-PCA for hand gesture intention-based identity recognition by LMC. The approach of DTW with FC2-PCA can also be carried out in the same way as depicted in Fig. 6.
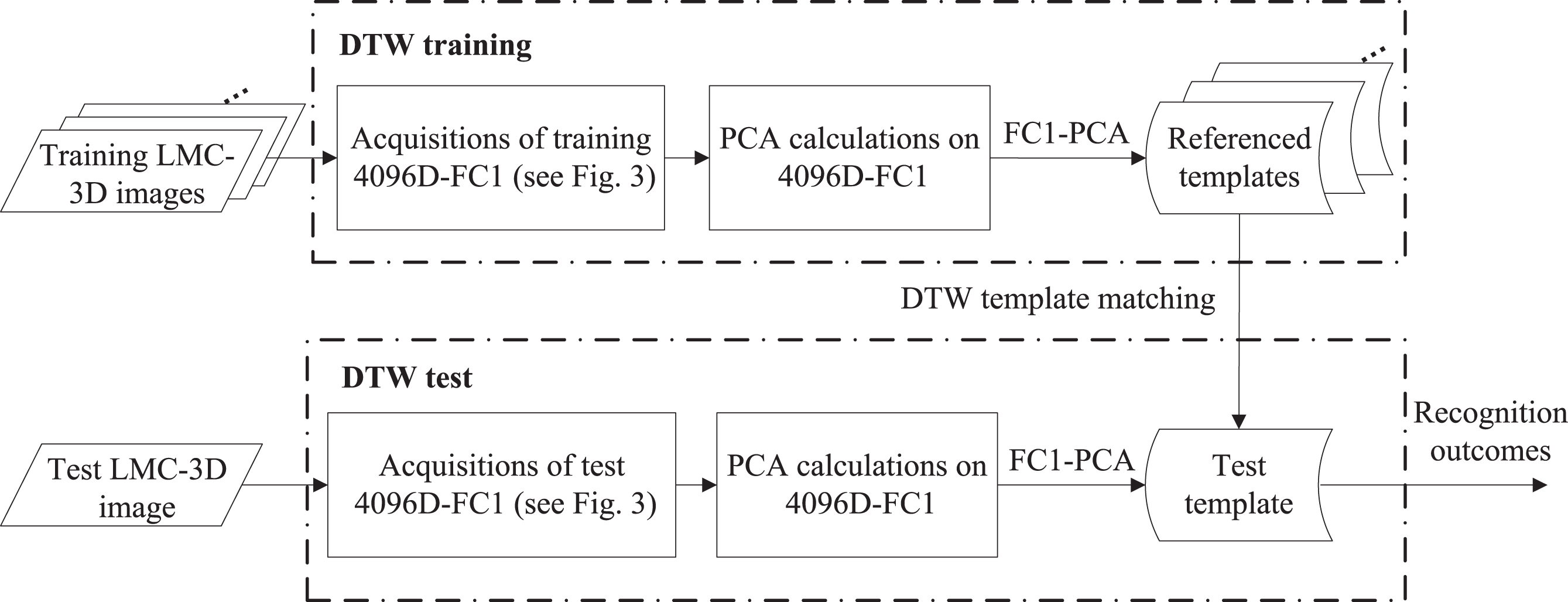
The strategy of presented DTW with PCA-based deep learning features for hand gesture intention-based identity recognition by LMC (an example of the use of FC1-PCA for recognition).
When performing classification calculations on hand gesture intention-based identity recognition using the PCA data-reduced features of FC1-PCA or FC2-PCA, the DTW classifier is an option for carrying out feature categorizations. Compared with the DTW approach, an alternative of classifications on FC1-PCA or FC2-PCA features is to directly use the categorization centroid of the PCA-constructed EigenLMC3D-VGGCNN space. Before performing recognition, the above-mentioned EigenLMC3D-VGGCNN method will be able to firstly estimate P representative points, each of which is used to represent for the specific categorization of user data. The P representative points are the corresponding P centroids of the hand gesture intention-based identity recognition system with P gesture-making users, each of which is separately distributed in the space of EigenLMC3D-VGGCNN to represent for the cluster of the specific user. The strategy of PCA centroid with FC1-PCA or FC2-PCA is to use the pre-established P centroids, each of which has k dimensions, i.e. Centroid pj , p = 1,2, ... , P, and j = 1,2, ... , k, to perform identity recognition on P gesture-making users. On identity recognition, the test data for gesture-making user identity classification is then calculated the Euclidean distance (Distance) among all of these P centroids in the space of constructed EigenLMC3D-VGGCNN, and a recognition decision can then be made according to the estimated P Euclidean distances. Equation (5) shows the final recognition decision of all P hand gesture-making users in the recognition system using the presented strategy of the PCA centroid approach with FC1-PCA or FC2-PCA features as follows,
Hand gesture intention-based user identity recognition is performed in a laboratory office environment. As mentioned in the beginning of Sec. 2, the LMC-3D hand gesture images are captured by the image sensor of the Leap Motion Control. Figure 7 illustrates ten indicated different categorizations of hand gesture intention actions used in this work for classifying the identity of the users in the laboratory office. Each of these ten hand gesture intention actions belongs to the continuous-time dynamic action, i.e. numerous LMC-3D hand gesture frames that can be captured and contained in one specific complete action. As shown in Fig. 7, ten hand gesture actions, “Hand gesture action-1,” “Hand gesture action-2,” ... , and “Hand gesture-action-10,” are different with each other at all aspects of speed, repeat, attack and direction. Note that for justly making a standard performance comparison among the non-deep learning approach used in [13] (see Fig. 1) and all deep learning strategies presented in this study, all ten hand gesture actions in this study are designed entirely as those of the work of hand gesture-based restlessness level recognition in [13]. In addition, the hand gesture database of LMC sensor data used for evaluating effectiveness and efficiency of recognition approaches is also same in [13] and this work. The main difference is that in the work of [13], the feature containing the geometrical information of LMC 3D-(x, y, z) is extracted from the collected hand gesture database and classified using the non-deep learning approach; the VGG 16-CNN based deep learning feature including mainly 4096D-FC1, 4096D-FC2, FC1-PCA and FC2-PCA is computed according to the LMC 3D-image characteristics of the collected hand gesture database.
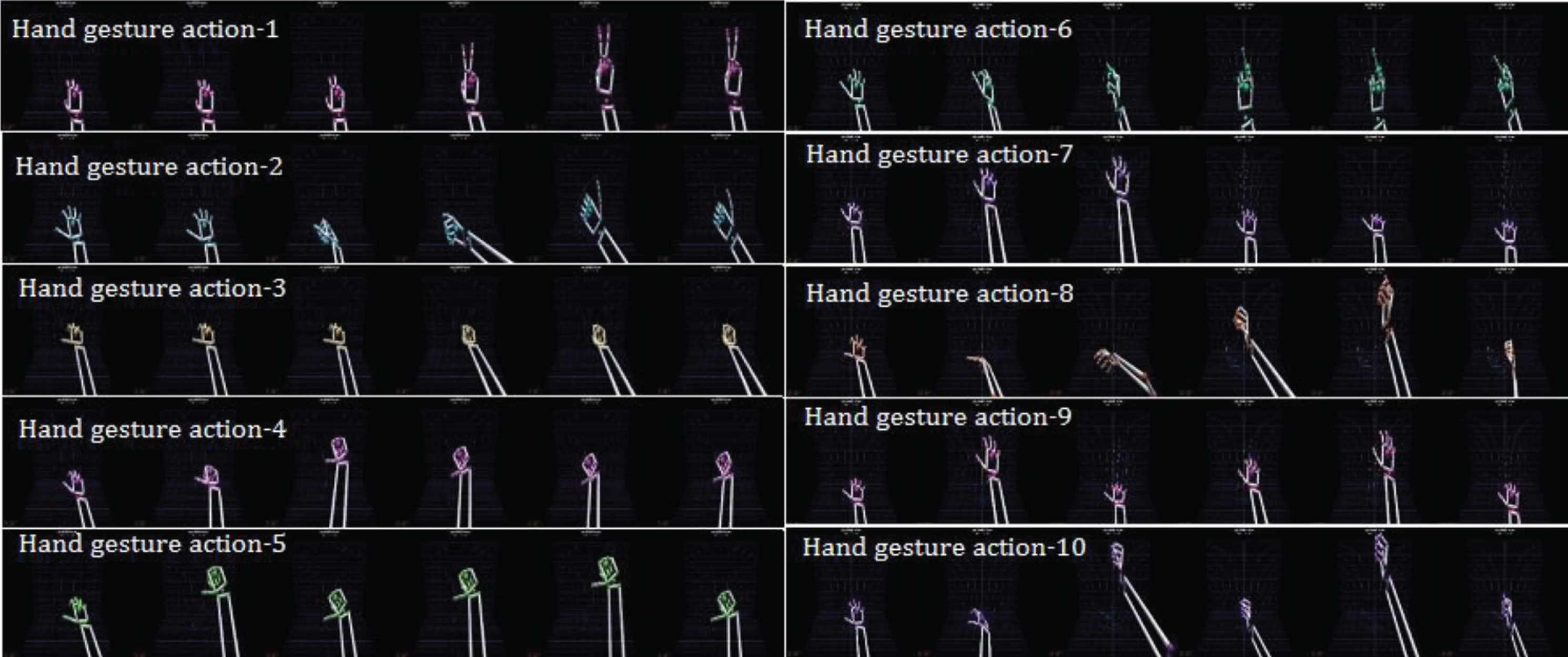
LMC-3D sensor image data of 10 continuous hand gesture action categorizations.
The hand gesture database including ten specified intention actions contains the LMC sensor data of four hand gesture-making users. Each of the collected four subjects is requested to make 50 actions for each of these ten specified hand gesture actions, in which the half is used for training of the recognition model on gesture-making subject identification, and the other half is employed in the test phase for subject identification performance evaluations of the established recognition model. Table 1 is the experimental result of utilizations of the typical VGG-16 CNN approach on four gesture-making subject classifications with 10 specified hand gesture actions. Recognition performances of DTW classifications with 4096D-FC1 features derived from VGG-16 CNN is listed in Table 2, and Table 3 is the recognition result of DTW with the deep learning feature of 4096D-FC2. Observed from Tables 1 3, typical VGG-16 CNN performs better than the DTW approach with 4096D-FC1 or 4096D-FC2 features on averaged recognition accuracy. typical VGG-16 CNN can achieve a satisfactory averaged recognition rate of 89.19% on identity recognition. Tables 4 and 5 are the impact results of the use of the PCA data-reduction scheme to 4096D-FC1 and 4096D-FC2 features. As can be seen in Tables 4 and 5, PCA dimension decrease to each of 4096D-FC1 and 4096D-FC2 will slightly reduce the recognition accuracy of the subject identification system. DTW with FC1-PCA has an averaged recognition accuracy of 67.50%, which is slightly lower than 68.10% of DTW with 4096D-FC1. In addition, DTW with 4096D-FC2 has the averaged recognition rate of 66.90%, which is a little better than that of DTW with FC2-PCA by 1.90%. The averaged recognition performance of PCA centroid classifications with FC1-PCA is reported in Table 6. Table 7 is the performance result of subject identification by PCA centroid with FC2-PCA. It is seen in Tables 6 and 7, for these two presented deep learning features in this work, FC1-PCA and FC2-PCA, the PCA centroid approach is apparently superior to the DTW classifier method on recognition performance. The recognition accuracy of 80.00% of PCA centroid with FC1-PCA is obviously better than that of DTW with FC1-PCA, a significant increase of 12.50% on the averaged recognition rate. For PCA centroid with FC2-PCA, the obviously great grow on the averaged recognition accuracy can also be observed in Table 7. Observed from Table 7, the averaged recognition rate of PCA centroid with FC2-PCA achieves acceptable 79.80%, which is much better than 65.00% of DTW with FC2-PCA.
Performances of VGG-16 CNN on 4 subject user classifications where each of all subjects makes 10 different hand gesture actions
Performances of 4096D-FC1 features derived from VGG-16 CNN, which is classified by DTW on 4 subject classifications with 10 different actions
Performances of 4096D-FC2 features derived from VGG-16 CNN, which is classified by DTW on 4 subject classifications with 10 different actions
Performances of VGG16-FC1 with PCA dimension reduction (FC1-PCA, 90-D), which is classified by DTW on 4 subject classifications with 10 different actions
Performances of VGG16-FC2 with PCA dimension reduction (FC2-PCA, 90-D), which is classified by DTW on 4 subject classifications with 10 different actions
Performances of VGG16-FC1 with PCA dimension reduction (FC1-PCA, 90-D), which is classified by PCA centroid on 4 subject classifications with 10 different actions
Performances of VGG16-FC2 with PCA dimension reduction (FC2-PCA, 90-D), which is classified by PCA centroid on 4 subject classifications with 10 different actions
Table 8 summarizes the averaged recognition performance of the traditional KNN approach by geometrical features of LMC 3D-(x, y, z) without the use of deep learning calculations [13] and various presented deep learning strategies including typical VGG-16 CNN, DTW with 4096D-FC1, DTW with 4096D-FC2, DTW with FC1-PCA, DTW with FC2-PCA, PCA centroid with FC1-PCA, and PCA centroid with FC2-PCA on hand gesture intention-based identity recognition. The calculation time of all these seven different deep learning approaches for hand gesture intention-based identity recognition is also investigated in this work, which is reported in Table 9. Note that in Table 9, all deep learning approaches are run in the same operation system of Windows 10 with the same hardware devices of 3.20Hz-CPU, 32.0G-main memory and Geforce GTX 1080Ti-GPU. Observed from Tables 8, in the task of hand gesture intention-based identity recognition, all VGG16-CNN based deep learning methods in this study excluding DTW with FC2-PCA perform more outstanding than the non-deep learning method in [13]. Furthermore, the deep learning feature extracted from the first fully connected layer (i.e. the FC1 layer) of the VGG-16 CNN model is apparently more accurate than that estimated from the second fully connected layer (the FC2 layer), which can be explained from all conditions of DTW with 4096D-FC1 outperforming DTW with 4096D-FC2, DTW with FC1-PCA outperforming DTW with FC2-PCA, PCA centroid with FC1-PCA outperforming PCA centroid with FC2-PCA. On the other hand, it can also be seen in Tables 8 and 9, although the typical VGG-16 CNN method has the best recognition performance, the calculation cost is the highest among all these 7 deep learning approaches. When taking into considerations both of the recognition accuracy and the computation complexity simultaneously, these two presented deep learning methods, PCA centroid with FC1-PCA and PCA centroid with FC2-PCA, will undoubtedly be fine approaches for constructing a hand gesture intention-based identity recognition with effectiveness and efficiency.
Performance comparisons on 4 subject classifications with 10 different actions using traditional KNN [13], typical VGG-16 CNN, DTW with 4096D-FC1, DTW with 4096D-FC2, DTW with FC1-PCA, DTW with FC2-PCA, PCA centroid with FC1-PCA, PCA centroid with FC2-PCA
Calculation time comparisons of various different deep learning of typical VGG-16 CNN, DTW with 4096D-FC1, DTW with 4096D-FC2, DTW with FC1-PCA, DTW with FC2-PCA, PCA centroid with FC1-PCA, and PCA centroid with FC2-PCA by the same platform (Windows 10 with hardware devices of 3.20Hz-CPU, 32.0G-main memory and Geforce GTX 1080Ti-GPU)
The recognition performance improvement of the presented deep learning approaches by the classifier of DTW, DTW with 4096D-FC1, DTW with 4096D-FC2, DTW with FC1-PCA and DTW with FC2-PCA, to the traditional KNN without deep learning seems to be less significant (see the summary report of recognition performances in Table 8). However, the issue of recognition accuracy increase on these DTW-based deep learning approaches can be further tackled by the specific machine learning techniques to the traditional DTW classification scheme. As can be seen in the previous study [33], supervised learning-based approaches of incremental learning and priority-rejection learning and unsupervised learning-based approaches of most-matching learning are proposed for greatly increase the recognition performance of the DTW speech recognition system. Each of these supervised learning-based and unsupervised learning-based approaches to the DTW classifier in [33] will be able to properly be employed in this work to significantly enhance DTW with 4096D-FC1, DTW with 4096D-FC2, DTW with FC1-PCA and DTW with FC2-PCA on hand gesture intention-based identity recognition.
For the use of the typical VGG-16 CNN approach on hand gesture intention-based identity recognition, the calculation is extremely expensive. Such time-consuming computation cost of VGG-16 CNN will also inevitably be a problem to a hand gesture intention recognition system with the requirement of real-time recognition and responses. Therefore, from the viewpoint of the property of real-time calculation of the recognition system, the deep learning strategy that VGG-CNN extracted deep learning features, 4096D-FC1, 4096D-FC2, FC1-PCA, or FC2-PCA, classified by one of DTW and PCA centorid schemes will be perhaps more appropriate. In this work, performances of VGG-16 CNN hand gesture intention-based identity recognition by different sizes of hand gesture datasets have also been evaluated to further find out the effectiveness of the amount of the training data set on recognition accuracy of typical VGG-16 CNN deep learning. As shown in Table 10, the specified hand gesture intention action, “Hand gesture action-1,” recorded in six different sizes of datasets in which Dataset-1 is the originally collected database relating to the specific hand gesture action, and Dataset-2, Dataset-3, Dataset-4, Dataset-5 and Dataset-6 are two, three, four, five and six times of the size of Dataset-1, respectively. Figure 8 depicts the recognition rate curve of typical VGG16-CNN hand gesture intention-based identity recognition using different amounts of hand gesture datasets. Observed from Fig. 8, a tendency can be seen is that the recognition accuracy on identity recognition will increase as the amount of the hand gesture data becomes large. Without considerations of computation time, such typical VGG-16 CNN approach with extremely rich training data will eventually achieve perfect recognition.
Performance comparisons of VGG-16 CNN on 4 subject classifications with the specified hand gesture intention action, Action-1, by six different sizes of datasets in which Dataset-0 is the originally collected database relating to Action-1, and Dataset-1, Dataset-2, Dataset-3, Dataset-4 and Dataset-5 are two, three, four, five and six times of the size of Dataset-1, respectively
Performance comparisons of VGG-16 CNN on 4 subject classifications with the specified hand gesture intention action, Action-1, by six different sizes of datasets in which Dataset-0 is the originally collected database relating to Action-1, and Dataset-1, Dataset-2, Dataset-3, Dataset-4 and Dataset-5 are two, three, four, five and six times of the size of Dataset-1, respectively
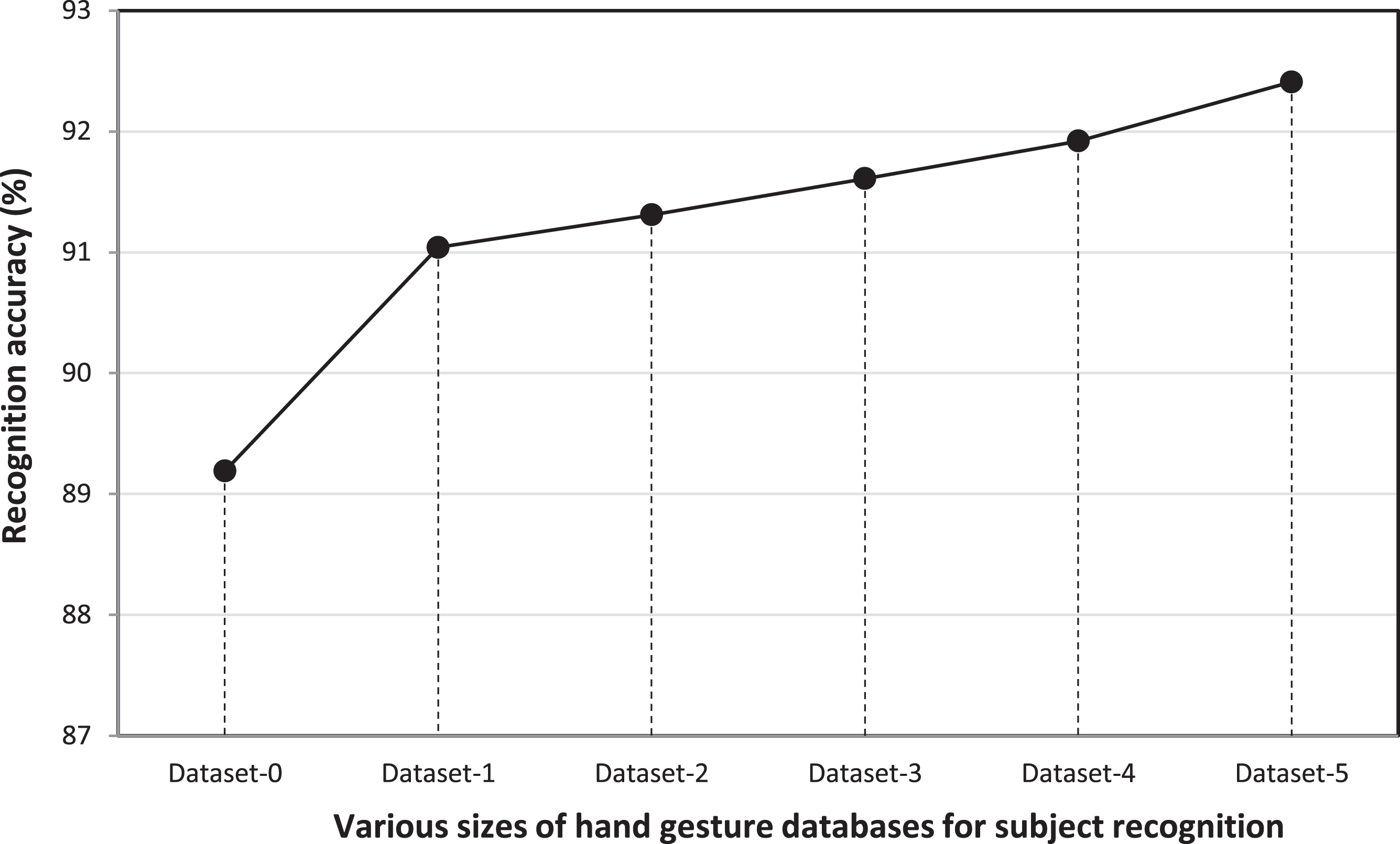
The recognition rate curve of typical VGG16-CNN on hand gesture intention-based subject identification using six different sizes of hand gesture datasets (evaluated from small to big sizes).
On the other hand, the presented different deep learning strategies in this study are to mainly build up the identity recognition system by classifying the human intention that is represented by the active hand gesture. The presented hand gesture intention-based system with deep learning will be taken in to consideration to further be properly combined with command-based hand gesture recognition and context aware-based hand gesture intention recognition to construct the human machine interaction application that is close to the real life in the future work.
In this study, various deep learning strategies that are based on the VGG16-CNN model are presented for hand gesture intention-based identity recognition by the LMC sensor. Performance comparisons are made among traditional recognition without deep learning, typical VGG-16 CNN deep learning, DTW with deep learning features of 4096D-FC1 or 4096D-FC2, DTW with deep learning features of FC1-PCA or FC2-PCA, and PCA centroid with deep learning features of FC1-PCA or FC2-PCA. Experimental results show that considering both of recognition accuracy and computation time on hand gesture intention-based identity recognition, proposed PCA centroid with estimated FC1-PCA or FC2-PCA features has the most competitive performance.
Footnotes
Acknowledgments
This research is partially supported by the Ministry of Science and Technology (MOST) in Taiwan under Grant MOST 109-2221-E-150-034-MY2.