
Abstract
This Ensuing generation of FPGA circuit tolerates the combination of lot of hard and soft cores as well as devoted accelerators on a chip. The Heterogene Multi-Processor System-on-Chip (Ht-MPSoC) architecture accomplishes the requirement of modern applications. A compound System on Chip (SoC) system designed for single FPGA chip, and that considered for the performance/power consumption ratio. In the existing method, a FPGA based Mixed Integer Programming (MIP) model used to define the Ht-MPSoC configuration by taking into consideration the sharing hardware accelerator between the cores. However, here, the sharing method differs from one processor to another based on FPGA architecture. Hence, high number of hardware resources on a single FPGA chip with low latency and power targeted. For this reason, a fuzzy based MIP and Graph theory based Traffic Estimator (GTE) are proposed system used to define New asymmetric multiprocessor heterogene framework on microprocessor (AHt-MPSoC) architecture. The bandwidths, energy consumption, wait and transmission range are better accomplished in this suggested technique than the standard technique and it is also implemented with a multi-task framework. The new Fuzzy control-based AHt-MPSoC analysis proves significant improvement of 14.7 percent in available bandwidth and 89.8 percent of energy minimized to various traffic scenarios as compared to conventional method.
Introduction
Controller based on Field Programmable Gate Array offers points of interest, for example, fast complex usefulness and low power utilization. As indicated by the controller’s multifaceted nature, A Multi Processor Chip System (MPSoC) architecture with blended programming/equipment arrangements used to complete the FPGA outline. Using the maximum number of HW assets, the future generation FPGA provides the feasible way to produce very complex multiprocessor heterogene framework on microprocessor (Ht-MPSoC) architectures [1]. Such systems include incorporated computer and/or hardware facilities, real-time HW accelerators, and units of communication.
With the name of Zynq-7000 Extensible Processing Platform (EPP), the Xilinx published technical note. These designs are a good illustration of the ARM Cortex A9 dual cpu and deal with more reconfigurable hardware devices [2]. Altera [3] and Micro-Semi [4] dealt with Ht-MPSoC architectures in a similar way to that of Xilinx. Modern Ultra Scale Virtex devices based on 20 nm SoC process technology from TSMC [5–6]. D. Bouthaina et al. have introduced Shared hardware accelerator architectures for Heterogeneous MPSoC. This works deals with a promising different option for homogeneous MPSoC architectures, as they permit a higher execution vitality exchange off [8–11]. By implementing, the specific guidance in FPGA-form on MPSoC extends an execution capture through fusing equipment segments to manage computational tasks [12–15]. Most of the conventional works have two operational modes namely closely coupled mode and loosely coupled mode [16–18]. In Closely coupled mode, the equipment quickening agent is a piece of the processor information way and has direct access to the memory processor. At the loosely coupled mode, in committed bus the accelerator is located outside the processor. This symmetric architectures and Asymmetric architectures commonly used for multimedia applications. The runtime reconfiguration based MPSoC gives performance improvement. The biggest disadvantage though is the slight delay in implanting the circuitry systems [19–23].
Therefore, Dammak et al. acknowledged that the lag in runtime reconfiguration and sharing would influence the total runtime, in various applications where there is a slight difference between two concurrent hardware accelerators [8]. Dammak et al. implemented optimization of the consumption of hardware resources in heterogeneous FPGA-based MPSoC architecture to avoid this problem. While there were some issues with Dammak et al. [8]. These issues listed below: The above model remains suitable for the input of a single dataset and does not require a variety of metrics. Either the device specification differs if the model varies. The computer complexity of the MILP scheme is involved. Specific output parameters in FPGA discussed in traditional research. There is no explanation of the other output parameters.
In the current study, to solve the above problems, a new framework built depending on the Fuzzy design. Different benchmarks and real-time input information used to test the proposed work. The input information estimated using GTE [17]. For performance measure, real time input traffic is used.
The remainder of this paper structured as follows. Section 2 deals with traditional work. Section 3 contains the intended system and the elements. Section 4 includes the current MPSoC structure and its principles. The deployment and research outcomes are described in section 5. Finally, Section 6 presents our observations.
Conventional work
The FPGA circuits bear in the same chip the combination of many firm and facile gists along with persistent Speed-ups. The multiprocessor heterogene framework on microprocessor (AHt-MPSoC) design can achieve this recent performance and energy consumption implementation to the same FPGA microprocessor by embracing this very complex system-on-chip (SoC) scheme. The current method uses the FPGA-based Ht-MPSoC design. The design of AHt-MPSoC adapts the efficient use of HW resources on a chip that consumes less energy but produces high performance. When usage increases, design space format size should explored. Therefore, to define sufficient architectural configuration, a Design Space Exploration (DSE) method is used. This design demands much fewer energy from HW and provides less time for execution in the design flow of architectures from Ht-MPSoC, DSE tool play a major role.
The FPGA cores used in future generation in FPGA schematic-based systems, which include the dedicated hardware accelerators that meet the requirements of modern applications. Therefore, heterogenic multi-processor designs made possible by the implementation of system-on-chip (Ht-MPSoC).
Symmetric Ht-MPSoC configured in this architecture configuration. In SHt-MPSoC’s case, the number of equally shared private processors and hardware accelerators. Whereas in the case of AHt-MPSoC, the hardware accelerators are integrated with the separate processors.
When using SHt-MPSoC, the processor is unable to work with more demanding and complex configurable systems. This strategy limits the use of Ht-MPSoC and it cannot work efficiently for highly complex reconfigurable schemes.
Both approaches aimed at the next generation processor with a higher number of reconfigurable logic elements and uses of AHt-MPSoC architectures. In this paper, the concept of the AHt-MPSoC configuration proposed as a Mixed Integer Programming (MIP) template. There are more FPGA HW accelerators in the proposed architecture and the use of various types of accelerators differs from memory to memory.
In the proposing architecture, Ht-MPSoC associates the hardware accelerators among controllers. MIP formulation, which used in a reasonable time to test the wide range of possible configurations and the tests are depending on MIP formulation.
AHt-MPSoC architecture is accustomed to improve processor performance and effective use of application-specific instructions. Uses of newly added guidelines implemented on HW accelerators in these processors and their effects on critical computation runtime. The use of each processor’s HW accelerator connected to the instruction pipeline either by device bus or by controller for memory.
The space explorations of the MIP model deteriorate the overall area use As far as application efficiency is concerned constraints and to link the computational patterns defined on the various applications by established process. The correct limit taken to produce every processor execution time preserved by producing the appropriate limit of the execution time. The MIP model can thus evaluate an optimal configuration of AHt-MPSOC that achieves the desired output and efficiency. The proposed model reduces the in terms of application performance.
Hardware sharing achieved by access to the HW processor, which decreases service costs and improves efficiency. HW accelerators connected to the multiple modules, which differ from one processor to another in the context of AHt-MPSoC. Such accelerators operate as an external hardware gateway that is present outside of the hardware. The Design Space Exploration (DSE) is the design tool used to boost Ht-MPSoC quality of design. This approach further decreases the use and execution time of FPGA resources.
The architecture designed in a scalable type. On this model, Ht-MPSoC’s linear type has a personal number of equally shared hardware (HW) processors and transistors. In comparison, Ht-MPSoC’s nonlinear form consists of processor and hardware accelerators connected to the same processor and varying from each other. In a short span of time, it is feasible to examine the core design of structure by simulator or by specific analytical techniques for the new and former FPGA circuit generation, which interacts with very little assets.
In new designs, HW modules used to define a lot of design guidance. The new conventional work is proposed to classify and connect Newly designed instructions described and communicated HW accelerators in order to avoid Superfluous region use of HW elements, The sharing of HW use by the polynomial time process reduces the field and the collection of personalized Instruction Extensions (ISEs) is sequenced. Nonetheless, with this sharing approach, the extended MIP model minimizes the ISEs. This sharing method turns the knowledge into a single data path as a series of ISEs. The traditional work based only on the reduction of the region without considering performance improvement. While the study suggested explores all feasible sharing architectures that decrease the desired area use and time of execution based on performance constraints. The use of the region decreases in all possible ways of exchanging configuration and the output fulfilled with regard to its time of execution.
To reduce the reconfigurable FPGA structure area, HW distribution used among various functional structures. Based on the functional units applied to a particular design, the degree of sharing system (Processors and HW accelerators) implemented. In the order of area use and clock speed, this method gives low efficient architecture. Here, HW DSE is not scheduled. Therefore, the suggested distribution approach refers only to uni-processor architecture design and never be accepted for workload use or clock frequency reduction.
Proposed system
The existing systems deal with the latest types of processors involved in hardware accelerators in the FPGA configuration. These hardware accelerators are accessible in the outside area and the logic elements become a reconfigurable type in the processors. The selection of reconfigurable logic elements leads to architecture design. The two forms of MP-Soc architectures are Ht-MPSoC architecture in a symmetrical and asymmetrical shape. In the case of Ht-MPSoC architecture symmetric sort, the numbers are identical in both hardware accelerators and processors. However, each processor shares the hardware accelerators. However, the number of cores and modules in the hardware are different in the asymmetric type of architectures. Furthermore, different processors attached to data and HW accelerators. However, this processor architecture achieves minimized use of the field.
This architecture constructed using the MIP method, which for a given span of time seeks the wide space of possible configurations. A CPLEX linear program solver used to solve after a method of linearization of constraints. The output of the input data improved in the proposed system, as further improvements will occur in the traditional model.
Using additional block usage, architecture improves system performance. However, the adjustments were introduced in combination with the combined progress of the fuzzy-based regulator and a chart congestion operator. The device as a whole updated to a certain amount for this upgraded system amount. From this measurement of rate of performance, the HW accelerators are associated with each processor using the specific level. In this work, the router level of the input nodes is random. Consequently, destination-based nodes are necessary and rendered to be a unidirectional state by using that node.
To achieve this, a traffic estimator based on graph theory is required. The coming out nodes are ready can be placed in the specific node at this point. However, these nodes are not ready for the HW accelerator to perform the operation. The node needs to control behavior.
For each node that comes out of the controller, fuzzy-based controller logic provided. In addition, is capable of solving sharing problems and providing the desired solution at each processor level. The processor output is not affected by these controller (i.e.) GTE and fuzzy-based logic controller. This architecture has been able to boost efficiency. It increases the speed of processing to the next level. Figure 1 shows that graphical representation of proposed approach.
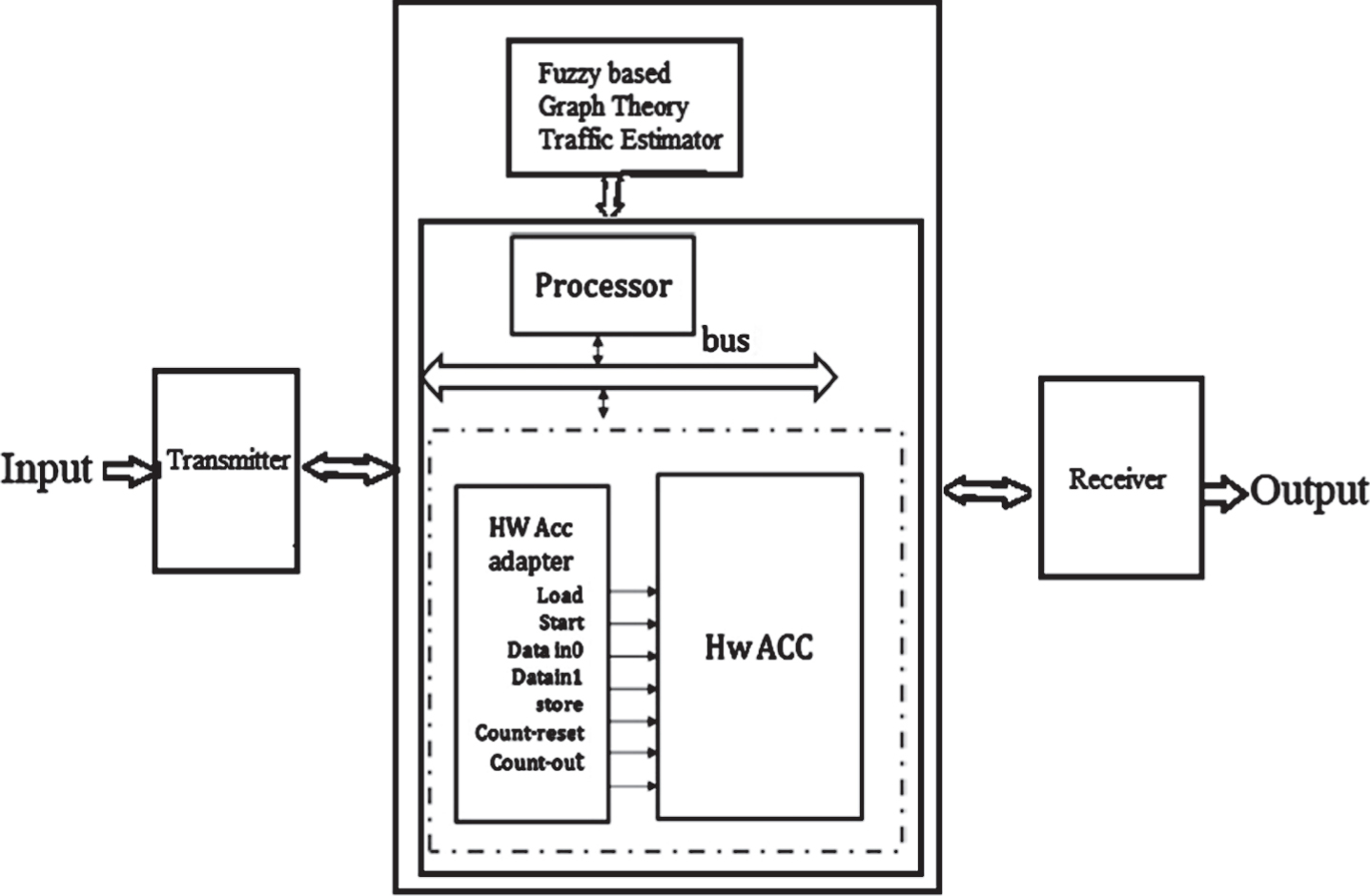
Graphical representation for proposed methodology.
In the design architecture of MPSOC processors, two major designs defined, symmetrical and asymmetrical shape of Heterogenic Multi-Processor SoC socket (Ht-MPSoC) architecture. The main drawbacks of the symmetrical Ht-MPSoC processor model are the use of runtime rearrangement, resulting in a slight delay in hardware sequencing. The overall execution time regulated by the lag in sharing and lags in reconfiguring runtime. As a result, this computation reduced in both the next two hardware accelerators. It is tricky to compare the different approaches by examining all of these reasons.
As an outcome, the Asymmetrical Ht-MPSoC architecture is classified and clear directions for operation added to boost processor efficiency in this architecture. This processor reduces the complex runtime of computation depending upon the use of physical accelerators. Nonetheless, given Enhanced use in the sector, the best architectural configuration needs to be determined.
Use the method of Designer Space Exploration (DSE) construction this area’s design space layout, and the designs are the best architectural setup. When functioning with AHt-MPSoC’s work, each hardware accelerator annexed to the various processors is different from one processor to another. Cores performed by sharing system with a major numbers for privately owned accelerators case of complex applications considered. Therefore, the subsequent generations of FPGA circuits suggested in past efforts by the use of the AHt-MPSoC method. For each application, these architectures executed and the processors are different from one processor to another. The MIP design, defining the solution in a short span of time, made the work of finding in the architecture layer the wide area of potential model.
Prediction method of graph theory
A channel in a map that contains of the point, link, and strength of the link. So far, using the graph method, it is simple to evaluate the defects and errors existing in a network. A chart dependent congestion evaluator was therefore built on the basis of the estimation of the signal input date scale. The purpose of this is to identify the incoming traffic conditions depending on the cost of the input threshold. This visualization idea is commonly had to render a recommended quantity and efficient. To reduce the traffic constraints imposed by internal and external transmission disruptions, this policy was established here. Transmissions that are disrupted here are generated in unpredictable sets. Then the formed signals communicate with the fuzzy controller to reach desired response.
Proposed fuzzy based controller
The set of processes required to achieve the solution to align it with the all-possible sorts of incidents for the fuzzy based regulators. For a fuzzy based system, it mainly deals with the several combinations of logic based scheduling. This logic deals with both numerical and linguistic variables that make a valuable advantage. In the fuzzy logic scenario, the process starts with the scheduling of inputs.
A schedule, which includes the coordination of the process, the selection and the scheduling of the use of the resource to do all the activities necessary to achieve the required results. In fuzzy, the definitions of linguistic variables mentioned with the specified inputs. The variables that fall under the category used for the specification purposes. Then, the membership development and its functions made developed in this section.
In this section, the variables chosen with the definite intervals. This value makes a possible scale of values. That makes the input disturbance to assign in a defined range. This section further extended to obtain the set of conditions. After that, this used to make the section of develop rule. In this layer, the possible solution that obtained from the previous set arranged in a particular set of matrices.
This matrix arrangement makes the solution to fall in a particular set of elements. The identification of values easily determined by this approach. When the solution reaches its terminal value, the value is stored for the next stage of process. In this stage, the possibility of finding a solution is determined.
This stage named as fuzzification process. However, in some cases, the result loses its accuracy and by further examining, the results could be flattered. So, a better improvement needed. At last, the defuzzification done. In this stage, accurate result values obtained. This stage named as action stage in which the possible outcomes further analyzed. The results, which are very close to the identical solution, taken as the solution and that matched with the given problem. This derived solution taken as the fuzzy based analysis and that related with the environment.
Table 2 shows an example of an Xj =Xkji matrix for the Sk pattern performed on an 8-CPU design. In the MPSoC, processor j (respectively processor i corresponds to each row j (respectively column I in the matrix. The parameter in jth row and ith column refers Xkji variable and specifies whether the Rj and Ri processors access the same Sk accelerator. In Table 2, for example, it is presumed that the related HW accelerator Sk is distributed between P1, P2 and P3 from the first three columns. The region covered was decreased by a factor of 3 in this region for each line and is equal to bk/Shij=bk/3.Similarly, a 4- distributed among HW accelerator is distributed among P5, P6, P7 and P8 for the last four columns. Every row k requires bk/4 area units in this field.
Real congestion classification [17]
Real congestion classification [17]
xjik variables for a Sk pattern
Let Yk, k∈N, be a vector in binary it shows either or not the Processor Sk template has been implemented for Processor Rj on Hardware (HW)
Let Xkji, K∈N, j∈M, i∈M, is a Boolean variable used to represent task Sk of HW accelerator can shared between processors Rj and Ri. The value1 denotes it can be shared and 0 restricts the sharing.
It is assumed that Xkjj = 1, and this leads to the following equation:
Total volume needed for implementing m patters will be minimized using the objective function.
The solution is obtained from two linear term ratios. To linearize the function a continuous variables Wjk, Zjk, and hjki are included.
In addition the following are constrain that restricts or minimizes the search space for efficient exploration.
The main activity is re-written in (Equation (3.4)):
The additional performance limitation is given in (3.11)
here varies from maximum of (0 to j-1)
And
Where
And U
kji
, k belongs to N, (j,i) belongs to M2 are boolean value defined as follow:
Combining the equations, the performance constraint can be re-written as:
The proposed objective function to minimize the total area:
The required speedupj for each processor j defined as follows:
The 2D-DCT and 2D-IDCT computations are detailed in Equations (3.20) and (3.21)
Where
The separated transformations is expressed in matrix operations Equations (3.22) and (3.23).
Where
In development of this future proposal, the project made beneath structure of packages. The techniques used to enforce them are Model Sim 5.5f which used to model the PWM signals and for extra emulation, it executed under Xilinx 12.1 that allows a one-step project in the software package ahead. Compared to previous conventional methods, the results of the experiments enhance the performance of the AHt-MPSoC architecture.
The additional hardware accelerators usage with diverse real time speedup factors shown in Table 3 and the proposed model’s estimation space usage with different speedup of model estimation presented in Table 4. The comparison made with the increased use of the area used by the hardware accelerators of various speed-up configurations. In this context, 8 processors are observed and compared with the readings on the FPGA platform.
Enhanced use of the HW accelerators in different speed Configurations
Enhanced use of the HW accelerators in different speed Configurations
Region use of the Fuzzy-based MIP model and GTE for the configurations generated for different speedups
They developed in the MIP model in the existing system. Whereas, in this proposed system uses the fuzzy controller. This resembles that the area usage minimized. For instance, in the table, the speedup measurement rate is 1.26, whereas the area usage in [8] presents 52, 54 in the conventional work. The proposed work decreases the rate of value to 30, 31. This denotes that the utilization of space minimized at the level of 40 %. This shows that the proposed work consumes a minimized area, which is better improvement than the conventional system with a satisfied performance.
In Table 5 Bouthaina Dammaka et al. [8] describes the important computing processing period for various processors focusing on the period of execution HDCT and VDCT Syntaxes of structure for specific processors (P = 1, 2, 4). Throughout this scenario, the table displays the overall energy usage per encoded image. In this proposed study, which is a better improvement than the traditional method and which gives an improvement to the overall system design, the calculation of the execution time is decreased.
Operation duration analogy for Various CPUs
The comparison of the proposed architecture with different speedup for the use of the logic area presented in Table 6. Bouthaina Dammaka et al. [8], discuss the area occupation in terms of percentage (%) for different processors which consume 28% of FPGA slices and 22% of LUT. They are available within the FPGA. The outcome obtained from the suggested approach indicates that it has used minimum area. It is better than conventional work.
Area Comparison of Proposed AHt-MPSoC Architecture
The effects of the energy utilization of the suggested technique are shown in Table 7. This interacts with the relation and definition of consumption of energy in joules. The standard approach represents the price per encrypted picture of power generated. For an image representation sample group, the single cpu design includes acceptable resources, although less when compared to other designs. This informs that the different multicore models with the same set of generators have roughly the same resource utilization.
Comparison of the Emerging AHt-MPSOC design’s Power Consumption
Additionally, the scenario utilizes the finest activity level in the case of the proposed work, as it is supposed to absorb depending on the type of architecture (P = 1, 2, 4). In the context of saving energy, this raises the best policies and this conform to the expectations stands ahead of the traditional one.
Figure 7 shows the comparison results of delay consumption in Pico seconds (Ps). The proposed delay results of the fuzzy-based control architecture calculated under different traffic conditions providing a minimum rate of delay. The delay that occurs in the Symmetric HT-MPSoC (SHT) for picture operation, for example, takes 180 Ps. In the proposed development, however, it only needs 80 Ps. It demonstrates that comparable output to traditional work is defined by the suggested model.

Existing Method of SHt-MPSoC model with 4 Processors. Each processor has one-seperate HW accelerator (Pri) and share m accelerators (Shi) by another processor [8].
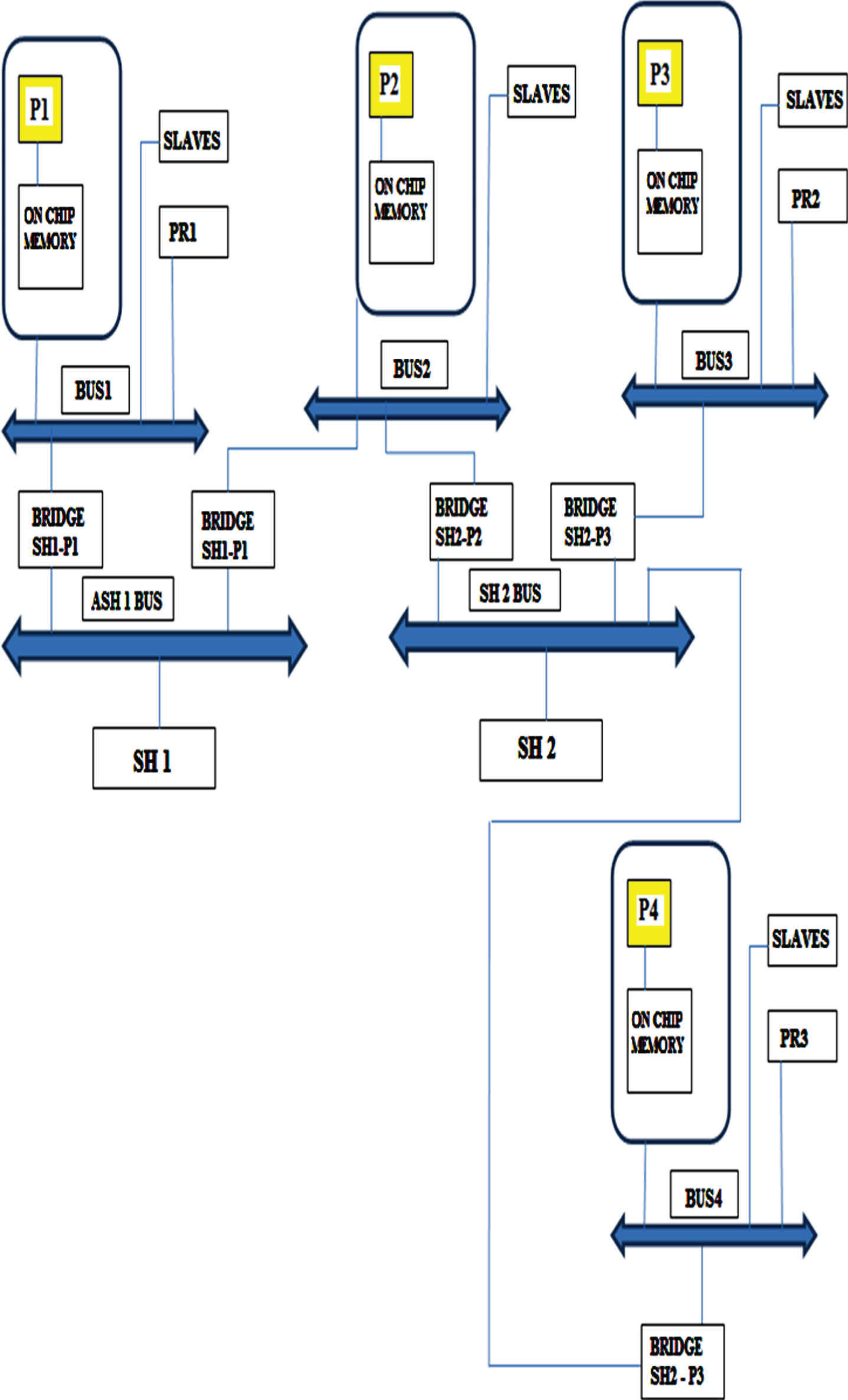
Existing Method of AHt-MPSoC model with 4 processors. P1 and P2 divides one accelerator (Sh 1) and P2, P3 and P4 divides another accelerator (Sh 2). P2 has no private accelerator [8].
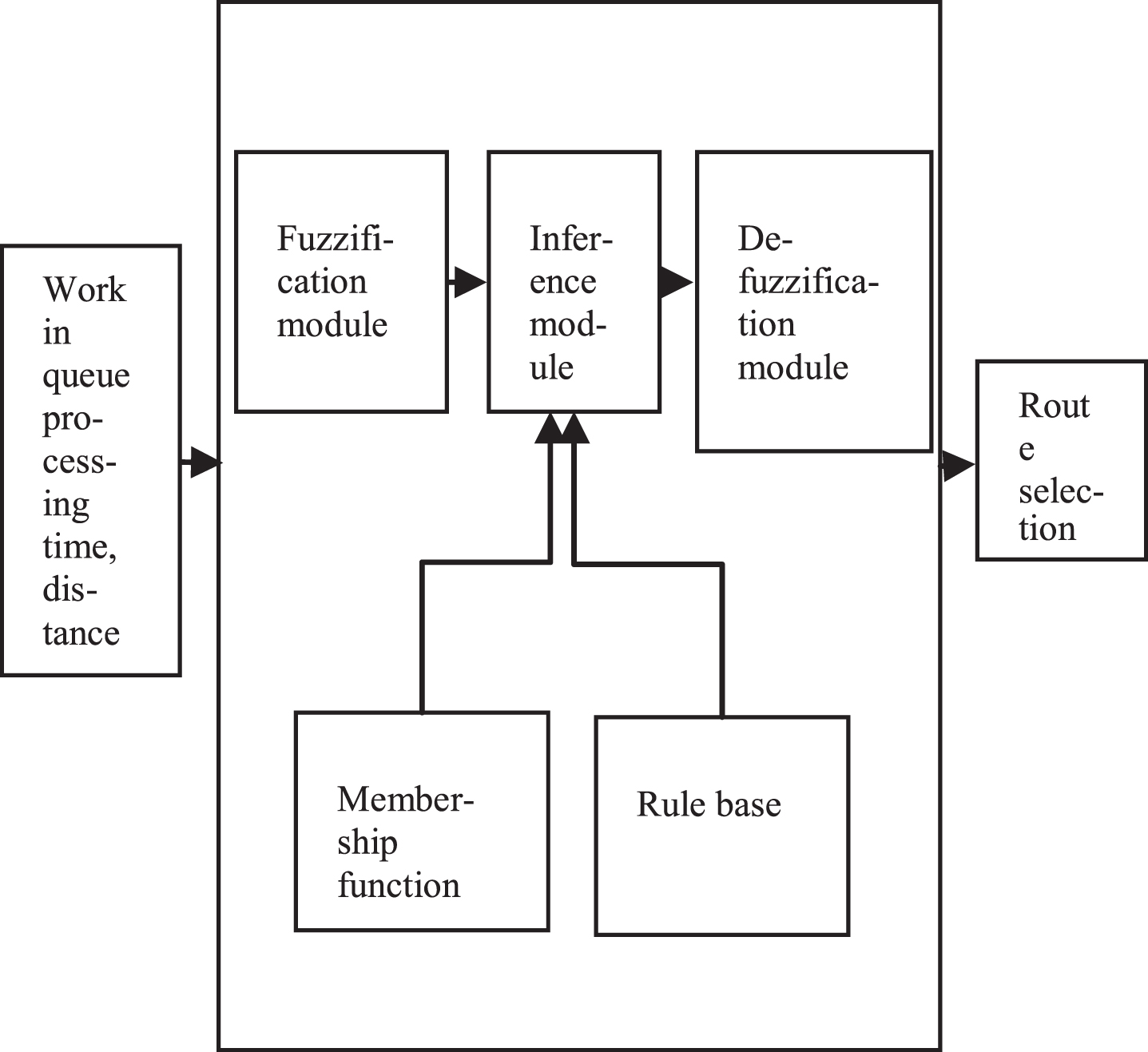
Fuzzy Models for Route Selection.
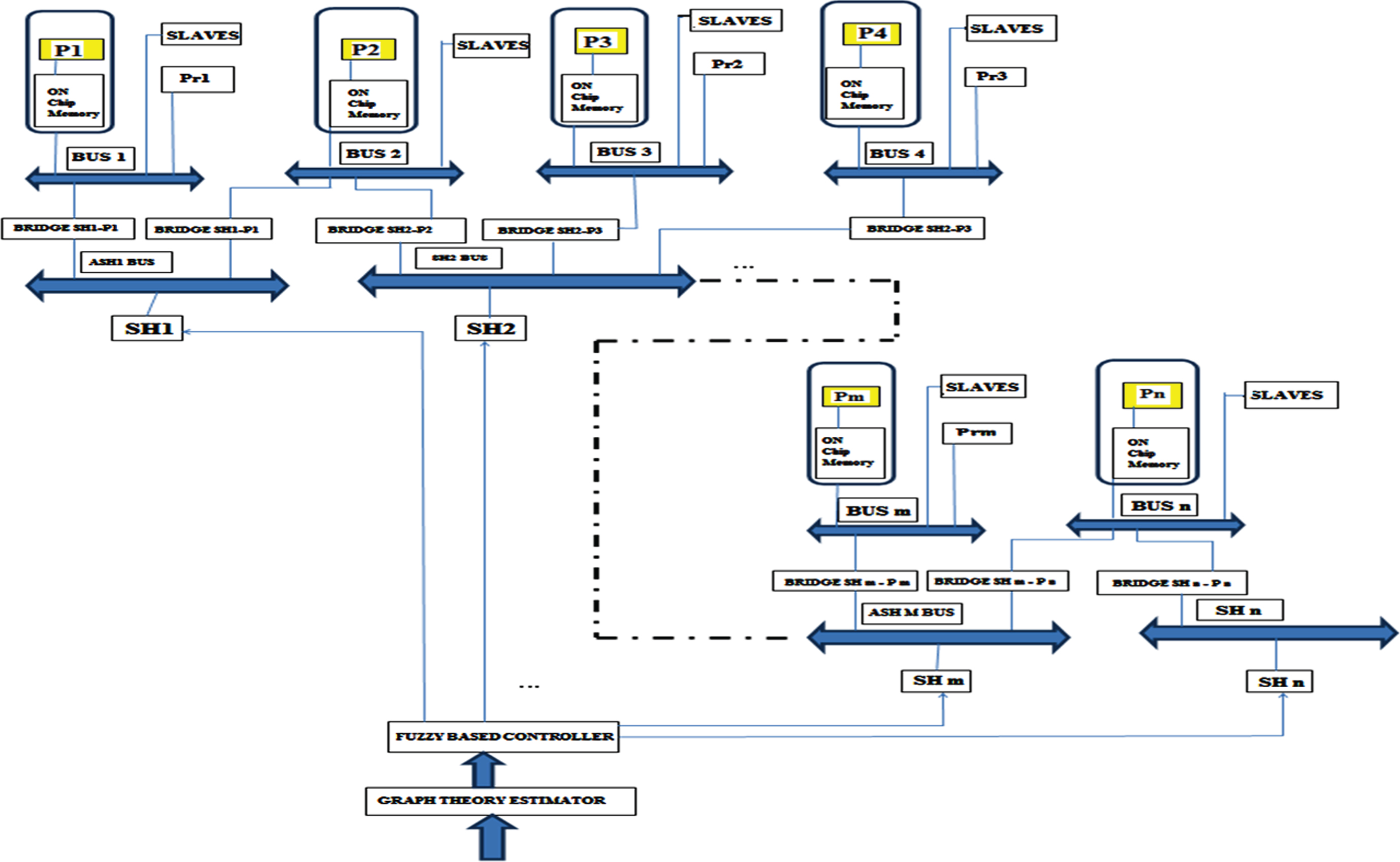
Proposed Fuzzy based MIP and GTE of AHt-MPSoC model with 4 processors.
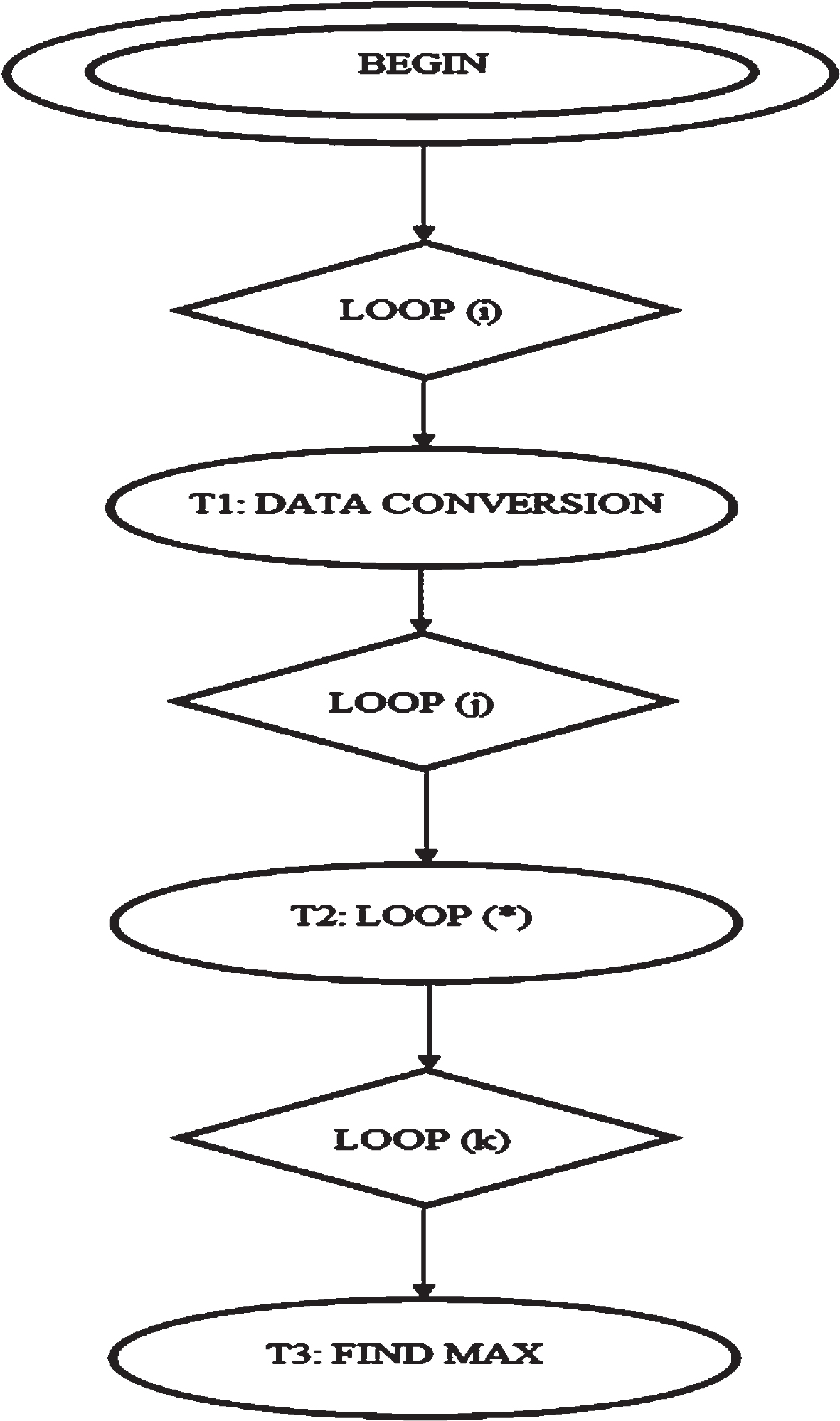
Era of Various Synthesized Applications.
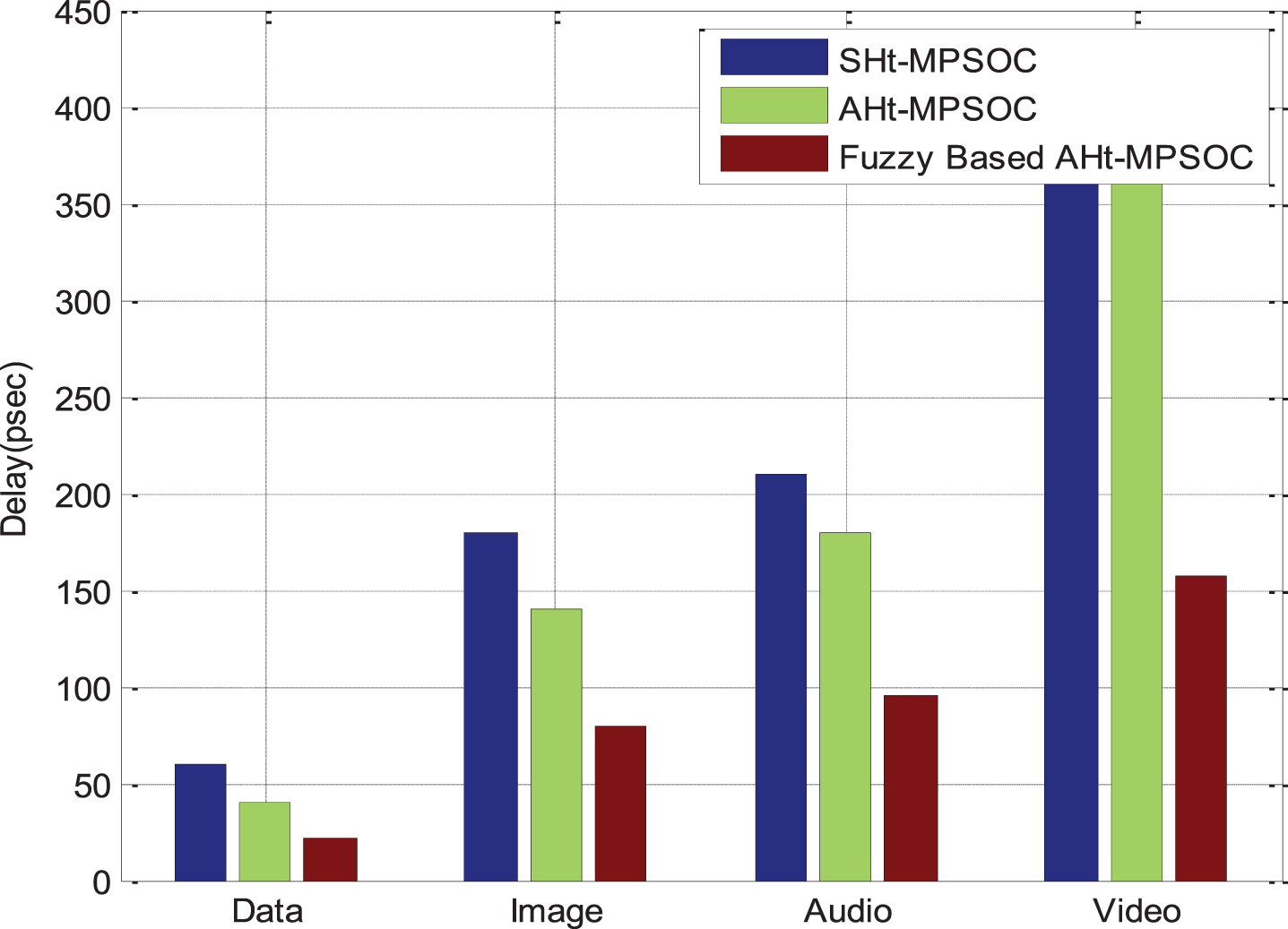
Delay analysis of the proposed architecture of AHt-MPSoC.
The implementation of the data values of various approaches is shown in Figure 8. Data rate is taken in the Gigabytes-per-second (Gb/s) order. The suggested study predicted that, in various traffic situations, the data rate is determined. The standard work consumes less data compared to the proposed work, due to traffic conditions. However, the quality of the output is very low. In this case, the outcome of overall data rate of proposed work superior to the conventional design.
The consistent energy utilization results shown in Fig. 9. The design of the network suggested in the conventional scheme addresses the minimised amount of magnetic fields. Nevertheless, the designed methodology indicates that energy usage has decreased thrice in each market, which may raise the value of output a bit more.
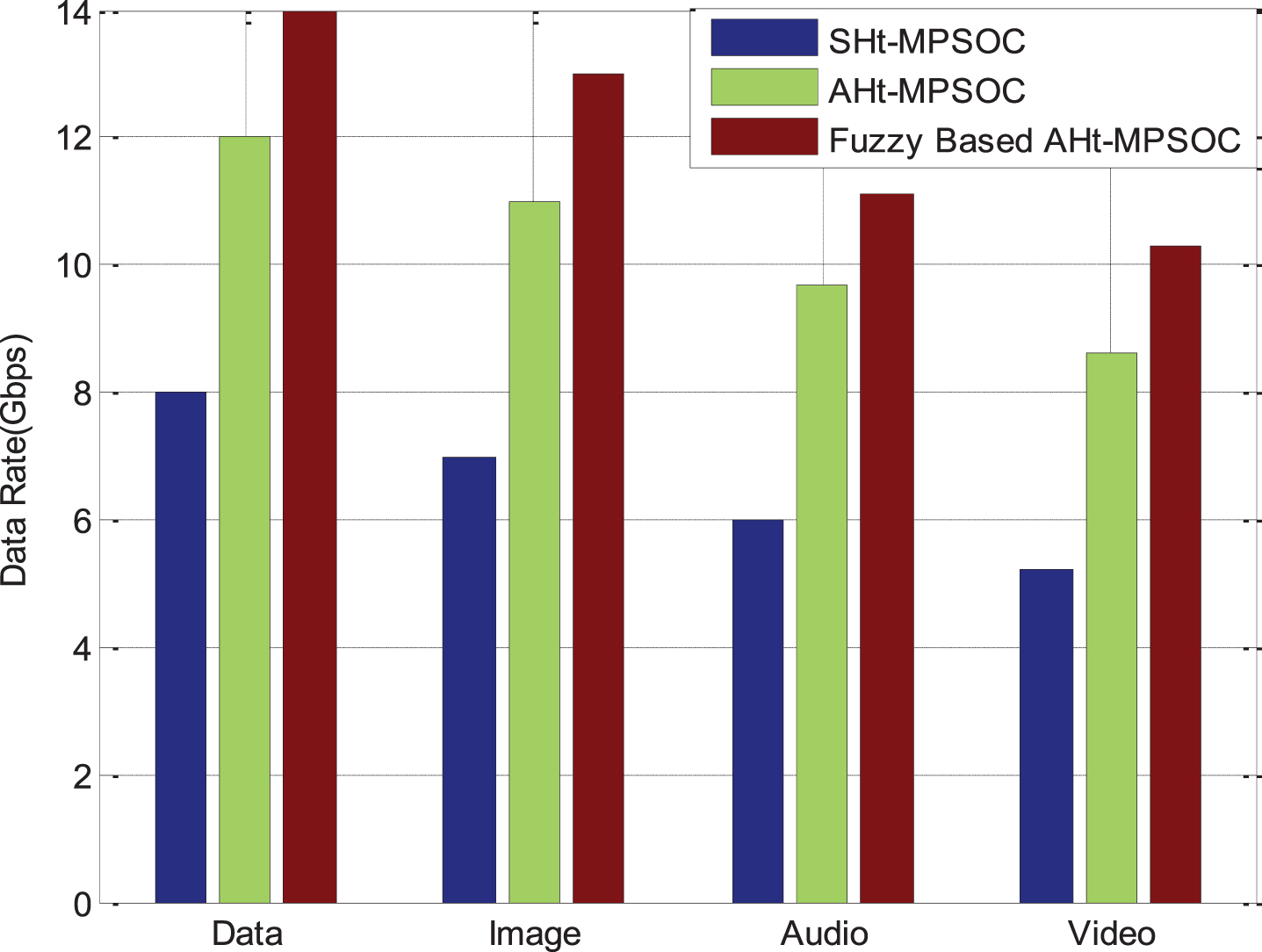
Data rate analysis of the proposed architecture of AHt-MPSoC.
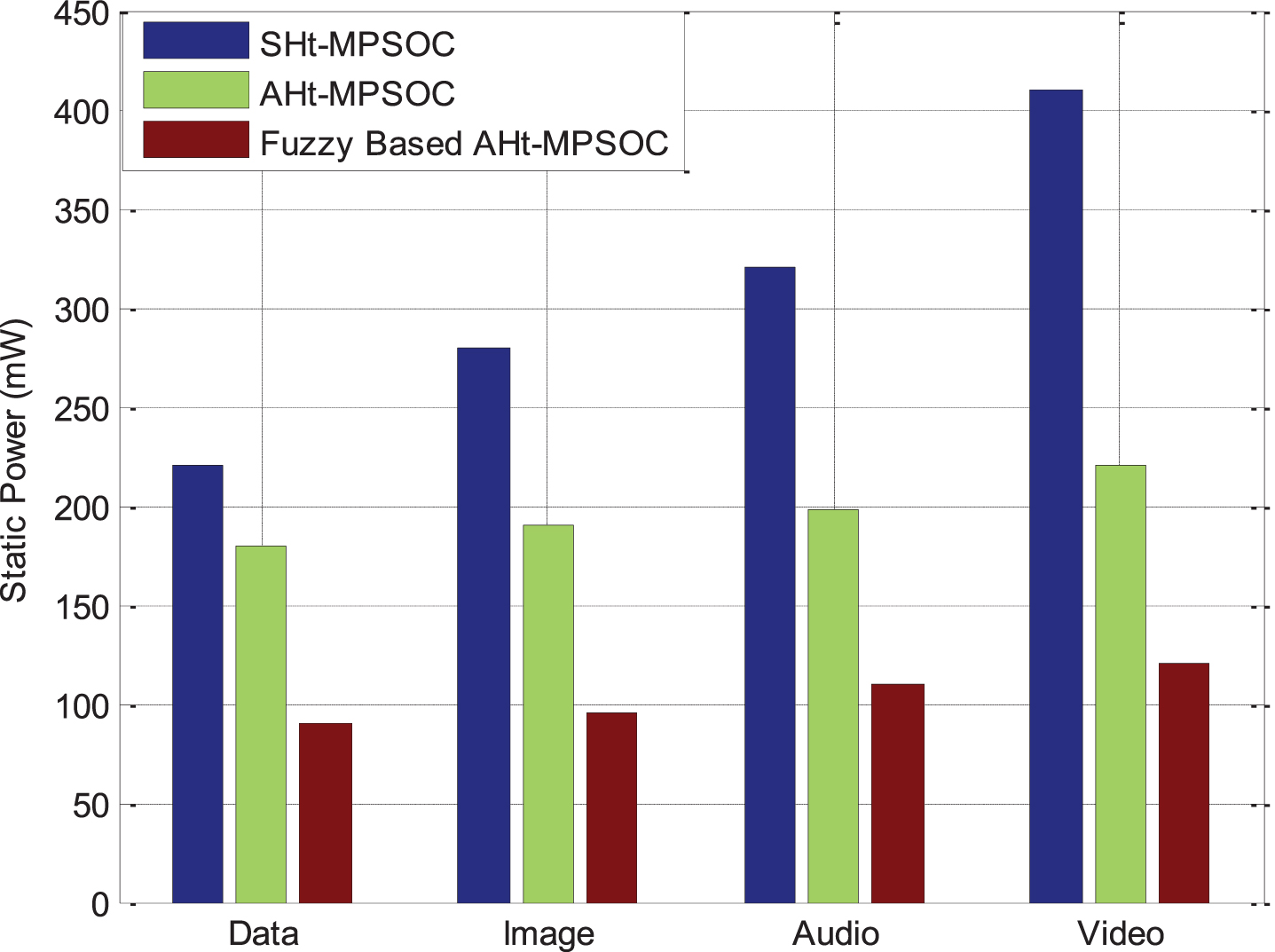
AHt-MPSoC Architecture Static Power Contrast.
In this paper, a new division of Heteroge Multiprocessor System-on-Chip (Ht-MPSoC) introduced. The asymmetric multiprocessor heterogene framework on microprocessor (AHt-MPSoC) designed with multiple CPUs equally get various HW accelerators. In such a way, to increase the performance, the total price is minimized. The performance evaluation indicates that AHt-MPSOC architecture has reached same outcome with low reduction in of logic blocks than SHt-MPSoC design. The proposed MIP model based on fuzzy control and GTE will find the best solution for the AHt-MPSoC design that very quickly reaches the targeted area / performance. This proposed architecture achieved in terms of latency, power, data rate, delay and it is better than the conventional method. The GTE is the proposed method estimates various traffic rates. By the using GTE, the average power and delay between the conventional work and the proposed work estimated and they are 103.75 mW and 50.8ps. The latest AHt-MPSoC outcome indicates better performance of 14.7 percent in data rate and 89.8 percent of the total energy level in different traffic situations relative to conventional design. Even though latency of new AHt-MPSoC design is high, the addition of fuzzy control based MIP model and GTE is acceptable, and they not presented in conventional architecture. It proved that fuzzy based AHt MPSoC achieves 12.2% and 50% reduction in the execution time and relative energy compared to the conventional architecture.
In the future works, plan to evaluate the proposed hybrid Asynchronous Low Power Innovative NOC (ALPIN) AHt-MPSoC model on multithreaded parallel benchmarks. In most of these benchmarks, several concurrent threads execute the same tasks with the same patterns. A novel hybrid ALPIN AHt-MPSoC model proposed in which hardware accelerators shared between processors in such a way to reduce system cost and increase performance. Hybrid asymmetric heterogeneous MPSoC architecture consists of a Static Random Access Memory (SRAM) and an embedded Dynamic Random Access Memory (eDRAM) cell in associated with Hardware Accelerator (HWA) shared methodology to determine the common computational tasks in between the concurrent tasks of application.