
Abstract
This paper presents a Hybrid Feature Selection Technique for Sentiment Classification. We have used a Genetic Algorithm and a combination of existing Feature Selection methods, namely: Information Gain (IG), CHI Square (CHI), and GINI Index (GINI). First, we have obtained features from three different selection approaches as mentioned above and then performed the UNION SET Operation to extract the reduced feature set. Then, Genetic Algorithm is applied to optimize the feature set further. This paper also presents an Ensemble Approach based on the error rate obtained different domain datasets. To test our proposed Hybrid Feature Selection and Ensemble Classification approach, we have considered four Support Vector Machine (SVM) classifier variants. We have used UCI ML Datasets of three domains namely: IMDB Movie Review, Amazon Product Review and Yelp Restaurant Reviews. The experimental results show that our proposed approach performed best in all three domain datasets. Further, we also presented T-Test for Statistical Significance between classifiers and comparison is also done based on Precision, Recall, F1-Score, AUC and model execution time.
Introduction
Sentiment Classification is the method of extracting information from textual data and classifying it into its respective polarity (positive or negative). Sentiment Analysis (SA) plays a vital role in different aspects of our lives. Even in the US Presidential Elections of the year 2016, SA played a crucial role in developing the election campaign strategy [1]. SA is also a common technique to analyze the customer’s reaction to a product, and in the business sector, companies tend to change their strategy based on customer feedback, which eventually increases their sales. The two most popular ways to carry out the Sentiment Classification task are Dictionary-based (DB) and Corpus-based (CB) methods [2]. The DB approach employs prebuilt dictionaries of words such as WordNet [3], and CB methods use the semantic relation between the words that appear in the corpus dataset.
Apart from these methods, Machine Learning (ML) classification algorithms have also been used to classify the text into different polarities. Recent research shows the use of the Hybrid approach [4] in Sentiment Classification.
In this paper, we have proposed a Hybrid Feature Selection Method using UNION Set Operation [5] and Genetic Algorithm [6]. We have considered UCI ML Dataset [7] of three domains: Movies, Products, and Restaurants. There are 1000 reviews present in each dataset with equal distribution of positive and negative reviews. Each of these are well labeled datasets, and hence we are classifying them using Supervised ML Classifiers. Below are the key contributions of the work carried out in this paper: We propose a Hybrid Feature Selection Method (FSM) using pre-existing techniques and Optimization by Genetic Algorithm. We analyzed the proposed FSM using four variants of Support Vector Machine (SVM), namely: Linear SVM (LSVM), Quadratic SVM (QSVM), Fine Gaussian SVM (FGSVM), and Medium Gaussian SVM (MGSVM). We also proposed an Ensemble Classification Approach considering all three domain datasets. In this, only two SVM variants are used, which showed a minimum error rate for individual polarity class.
The rest of the paper is structured as follows: Section 2 shows related work in Sentiment Analysis domain. Section 3 gives a comprehensive summary of the proposed Hybrid Feature Selection methodology. Experimental setup information is provided in Section 4 and Section 5 describes results and discussion. Finally, Section 6 concludes the paper with future work.
Related work
This section gives a brief overview of recent research works built on Supervised Machine Learning, Sentiment Classification Algorithms, and Feature Selection techniques used in Sentiment Analysis [8]. Pang et al. [9] were one of the pioneers in using ML for Sentiment Classification and introduced techniques such as N-Gram and Bag of Words (BOW). In [10], the authors used Term Frequency Inverse Document Frequency (TF-IDF) to convert a text file into numerical vector space, and classifiers were executed using the N-Gram approach. The authors in [11] conducted a comprehensive survey on Sentiment Analysis using various classifiers. The survey highlighted recent applications, improvements in Sentiment Analysis using Transfer Learning, Resource Building, and Emotion Detection.
The authors in [12] considered word features and POS Tagging to classify the review into respective polarity using Naïve Bayes Classifier. Geetika et al. in [13] used the unigram approach to extract adjectives of the word and used both (POS Tagging and Word Feature) as the final feature set. In [14], Naïve Bayes Multinomial (NBM), SVM, & Maximum-Entropy (ME) classifiers have been used for sentiment classification using Unigram, Bigram, and Hybrid N-Gram feature set. In [15], Dave et al. used Bigram and Trigram feature set and trained the model using SVM and NB classifiers on CNET and Amazon Reviews dataset.
In [16], the authors used a novel sentiment classification of sentences using a Rule-Based Approach. Sentiment classification can also apply in various other fields such as Sarcasm Detection, and authors in [17] worked on this application area. They considered slang and emojis present in sentences to classify offensive content. The results they produced show that the use of slangs and emojis in the feature set increases sarcasm detection accuracy. In [18], Taboda et al. proposed the Semantic Orientation Calculator (SO-CAL) that used dictionaries and other factors such as POS, Negations, etc. to find the orientation of the sentiment.
Melville et al. in [19] extracted features using Lexicon methods and used Pooling Multinomial classifier to classify text into respective classes. Nowadays, Twitter is one of the leading data sources for Sentiment Analysis, and authors in [20] used the Lexicon and ML approach to perform Twitter Sentiment Analysis. The results show that using a combination of features such as N-Gram, Lexicon, Punctuations, etc. improves efficiency. Aggarwal et al. in [21] also worked on Twitter Sentiment Analysis. They used POS features and tree kernel approach to classify the tweets and showed that their approach was better than existing baseline classification approaches. Table 1 summarizes past research works done on different domain datasets for sentiment classification.
Summary of recent work on sentiment classification
Summary of recent work on sentiment classification
This paper proposes a novel Feature Selection approach using Feature Union from IG, CHI and GINI Index and Genetic Algorithm. Our Feature Selection approach runs in two parts. In the first phase, features are selected from Review Dataset using existing feature selection techniques namely: Information Gain (IG), Chi Square (CHI) and Gini Index (GI). Then the selected features are combined with Union Set Operation. Then we applied Genetic Algorithm (GA) to choose best possible features for Sentiment Classification task. In this paper, four variants of SVM namely, Linear SVM (LSVM), Quadratic SVM (QSVM), Fine Gaussian SVM (FGSVM) and Medium Gaussian SVM (MGSVM) are used to train and test dataset from UCI ML repository. To check the effectiveness of our Hybrid Feature Selection approach, IMDB Movie Review, Amazon Product Review and Yelp Restaurant Review datasets are used. The process flow of proposed feature selection approach is shown in Fig. 1 and algorithm 1. Our methodology has five steps: Data Collection, Data Preprocessing, Feature selection using proposed Hybrid approach, Optimizing Feature Selection using Genetic Algorithm, and Classification using SVM variants.

Process Flow Diagram.
Collection of Data
In this paper, UCI ML Labelled datasets are used to test the proposed FSM using four different SVM classifiers. Before proposed FSM is applied on the dataset, we have applied various preprocessing techniques as discussed in the next subsection.
Data Preprocessing
Following data preprocessing techniques are applied on the dataset to remove irrelevant and noisy entities. Stop Words Removal Lovins Stemmer Stemming is done Tokenizing Sentence (TF-IDF Calculation) Sentiment Score Calculation using Vader API
Combining features using union set operation
Sentiment Classification requires a precise FSM to increase the accuracy of the process. The authors in [5] proposed the use of feature combination technique. In our proposed approach, we are using IG, CHI and GI FSM to extract features subsets. We are using UNION Set operation to merge the extracted feature subsets into combined feature set. Let f (f1, f2, ... fn) be the original feature sets extracted after data preprocessing from Review Dataset D. Then IG, CHI and GI FSM are applied on F to extract feature subset namely, fs1 (f11, f12, ... fn), fs2 (f11, f12, ... ... fn), fs3 (f11, f12, ... ... fn) respectively as shown in Equation 1.
Then the combined Feature Set FSET is passed to Genetic Algorithm to select the optimized features for Sentiment Classification task.
We have selected the GA technique to optimize FSM due to its evolutionary nature, which is appropriate for non-polynomial time problems. The reduced feature set obtained in the above step is then considered input for the Genetic Algorithm step. The above step reduces features to a considerable amount but still scalability remains a problem in large datasets. The use of Genetic Algorithm solves this scalability issue to a large extent. From equation (1), FSET signifies the number of words present in the corpus and we need to optimize that using GA. Major steps followed to optimize the feature set are as follows:
Population Initialization
The Collection of randomly generated n strings is known as population in GA. In this paper, we have selected population size as 50 and Pi value is set to 0.1.
Selection
In this step, classification accuracy is used as a fitness function to evaluate each generated solution’s quality. In this paper, we have used Tournament method as the selection scheme and size of the Tournament is used as 0.05.
Crossover
This step helps in the production of new off-springs with information exchange process. Crossover is performed between two chosen individuals based on Crossover Probability Pc which is set as 0.6 in this study. After Crossover, the Mutation process is carried out with Mutation Probability Pm, which is set as 0.01 in this work.
Experimental work
To perform the experimental work, entire process is converted into three phases namely, Optimized Feature Selection, Training of SVM Classifiers and Testing. The first phase includes Data Collection from UCI ML Repository, preprocessing of data, and reducing features using proposed FSM. We are using datasets from variety of domains (IMDB, AMAZON, YELP) to check the effectiveness of our proposed approach. Before applying FSM, data is preprocessed by Tokenizing, Removal of Stop Words, Stemming by Lovins Stemmer and Generation of SentiScore from Vader API, TF-IDF creation. Once the data is converted into appropriate TF-IDF form, Hybrid Feature Selection approach is applied to obtain reduced feature set. The experiments are carried out on three different UCI ML repository using tenfold (k = 10) cross validation. In 10-fold cross validation, dataset is partitioned into two sets, where 9 folds (k-1) for training the model and 1-fold for testing the model.
Evaluation parameters used
In this paper, evaluation of 4 different SVM Classifier is carried out using Confusion Matrix from which we computed the Accuracy, Precision, Recall and F1 Score metrics. Four entities that are used to calculate the evaluation metrics are: True-Positive (TP), False-Positive (FP), True-Negative (TN), False-Negative (FN).
Accuracy (A)
It is described as the portion of testing dataset that is accurately classified by the classifier.
It is defined as the proportion of correctly predicted positive to total predictive positive.
It is defined as percentage of correctly predicted positive observations to all the observations in that class.
It is defined as the weighted average of Precision and Recall.
It is a plot that presents the classification model performance on all thresholds. X axis of the ROC curve contains False Positive Rate and Y axis contains True Positive Rate. Our classification problem is an example of Binary classification, where higher Area Under the Curve (AUC) value means better classification.
Results and discussions
This section gives an in-depth analysis of the proposed Hybrid FSM using SVM Classifier variants: LSVM, QSVM, FGSVM, and MGSVM. The experiment was conducted on three different domain datasets and evaluation results are shown in Table 2. The following subsection discusses the results obtained for each dataset in detail.
Evaluation metrics comparison
Evaluation metrics comparison
For Amazon Product Review Dataset, confusion matrix is shown in Fig. 2 and ROC Plot in Fig. 3. It has been observed from Table 2 and Fig. 3 that LSVM achieves the maximum Accuracy, Recall and F1 Score of 81.2%, 0.8377 and 0.8046 respectively. However, in case of Precision, best results are obtained by FGSVM with score of 0.8220. Figure 4 depicts the Accuracy Per Class. It has been observed that FGSVM resulted in lowest error of 17.8% for Positive class and LSVM with 15% for Negative class.

Confusion Matrix for Amazon Dataset.

ROC Curve for Amazon Dataset.

Error per Class for Amazon Dataset.
For IMDB Movie Review Dataset, it has been observed from Table 2 that LSVM obtained maximum Accuracy, Precision, Recall and F1 Score of 78.6%, 0.76, 0.8017 and 0.7803 respectively. However, in case of Precision, best results are obtained by FGSVM with score of 0.8220. Confusion matrix is shown in Fig. 5 which helps in identifying the Accuracy of each SVM classifier for both classes i.e. Positive and Negative. ROC Curves and Error Rates for each class is shown in Figs. 6 and 7 respectively. Figure 7 clearly shows that Minimum Error Rate for Positive Class is shown by LSVM with 24% Error while QSVM achieves the lowest error rate of 16% for Negative Class.

Confusion Matrix for IMDB Dataset.

ROC Curve for IMDB Dataset.

Error Per Class for IMDB Dataset.
For Yelp Restaurant Review dataset, it has been observed from Table 2 that LSVM achieved maximum Accuracy and F1 Score of 77.5%, and 0.7702 respectively. However, in case of Precision, best results are obtained by FGSVM with score of 0.8020. MGSVM Classifier obtains the best score of 0.7890 for Recall evaluation metric. Confusion matrix is shown in Fig. 8 which helps in identifying the Accuracy of each SVM classifier for both classes i.e. Positive and Negative. Figure 9 shows ROC Curve and Error Rate for each class is shown in Fig. 10, which clearly shows that Minimum Error Rate for Positive Class is shown by FGSVM with 19.8% Error and QSVM with lowest error rate of 12.2% for Negative Class.

Confusion Matrix for Yelp Dataset.

ROC Curve for Yelp Dataset.

Error per Class for Yelp Dataset.
We also compare the execution time of each ML Classifier and found out that Gaussian Kernel based SVM Classifiers are faster than LSVM and QSVM. The execution time of FGSVM Classifier is best for Amazon Dataset with 2.84 s. MGSVM executes only in 3.21 s and 3.12 s for IMDB and Yelp Dataset respectively. The results are presented in Figs. 11 and Table 2.

Execution Time Comparison.
Further, we also carry out statistical significance test using T-Test between various classifiers. The null and alternate hypothesis are: Both classifiers perform similarly. One of the classifiers performs differently.
Let a1 and a2 be the Accuracies obtained from two classifiers c1 and c2 respectively and n be the number of samples present in dataset. To perform T-Test, we need total number of correctly identified instances. Let y1 and y2 be the number of correctly identified instances of c1 and c2.
T –Test Statistic is given by following formula:
To compare the two classifiers rejection region is selected as Z< -Zα′ where Zα′ is found out from Standard Normal Distribution with significance level of α′= 0.5. The chosen value of α′ helps in identifying the statistical significance of one classifier over other. For α′= 0.5 if value of Z< –1.645 than it can be said with 95% confidence that second classifier is more efficient than first classifier.
Table 3 shows the t-test results for each classifier for the various dataset. T-Test hypothesis shows that LSVM works better than other SVM classifiers for all datasets. For Amazon dataset, we observed that MGSVM is working better than FGSVM with confidence of 95% as per standard normal distribution considered for the study. The table shows that MGSVM and FGSVM are better than QSVM for both IMDB and Yelp datasets.
T-Test hypothesis comparison
This section presents results obtained from the proposed Voting Ensemble Classifier approach to classify the text into sentiment polarity, as shown in Fig. 12. FGSVM and QSVM are used in the proposed approach as they obtained a minimum average error rate of 20.73% and 15.33% as shown in Table 4 for Positive and Negative class respectively. LSVM has shown best results using our proposed hybrid FSM and is chosen as the base classifier to test Voting Ensemble Approach using FGSVM and QSVM. Table 6 summarizes the results obtained using Proposed Ensemble classifier. Figure 13 shows the Accuracy values of our proposed ensemble approach with base classifier LSVM. The results show that our approach gives better results than LSVM. Figures 14, 15 and 16 show the ROC comparison. We have also compared our proposed approach with LSVM using statistical significance T-Test which is shown in Table 5. Statistical Test Hypothesis shows that the proposed Ensemble Approach works better than baseline classifier LSVM and for IMDB and Yelp dataset. Comparing our proposed Hybrid FSM using Voting Ensemble Classification (QSVM, FGSVM) with some of the earlier work (Table 1) carried out in Sentiment Classification shows significant improvement in accuracy.
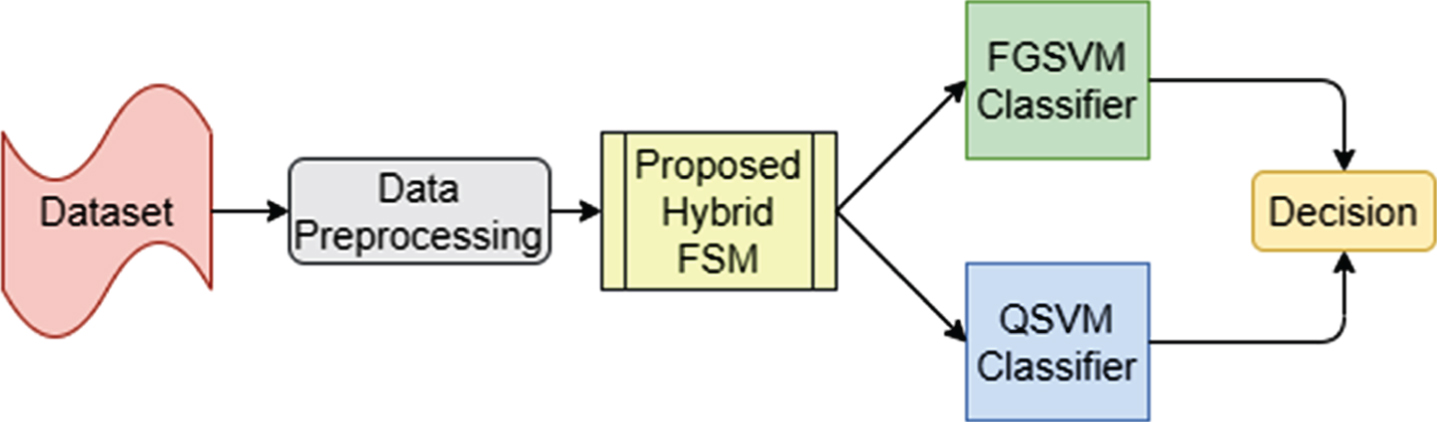
Proposed Ensemble Classifier.

Accuracy Comparison between LSVM and Ensemble Approach.

Amazon - ROC Comparison of LSVM and Ensemble Approach.
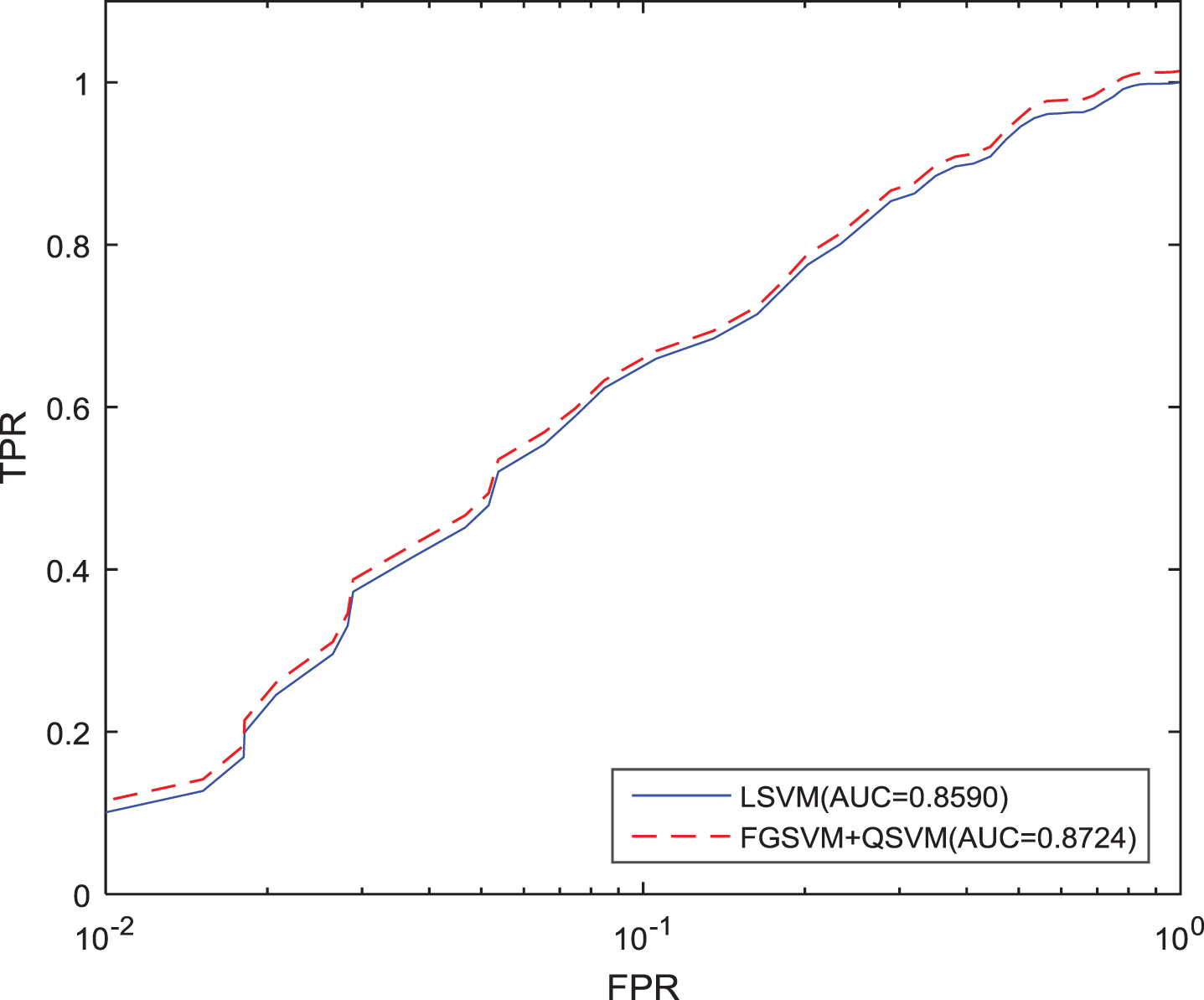
IMDB - ROC Comparison of LSVM and Ensemble Approach.

Yelp - ROC Comparison of LSVM and Ensemble Approach.
Average Error Rate
T-Test Hypothesis Comparison with Proposed Ensemble Approach
Results obtained using Proposed Ensemble Classifier (FGSBM, QSVM)
This paper aims to improve Sentiment Classification’s efficiency by proposing the Optimized Sentiment Classification Model using Novel Hybrid Feature Selection Method and Ensemble Classifier. This study explores the combination of three FSM namely, IG, CHI, and GINI. Features selected from each FSM are combined using UNION Set Operation. We further optimized the features chosen by using Genetic Algorithm. To test the efficiency of sentiment classification, four SVM variants: LSVM, QSVM, FGSVM, and MGSVM, are used in this paper. The results show that LSVM outperforms all other classifiers with an accuracy of 81.2%, 78.6%, and 77.5% for Amazon, IMDB and Yelp dataset respectively. Execution Time comparison shows that Gaussian Kernel SVM is faster than LSVM and QSVM. The execution time of FGSVM Classifier is best for Amazon dataset with 2.84 s. MGSVM executes only in 3.21 s and 3.12 s for IMDB and Yelp dataset respectively.
We further improved the accuracy of the sentiment classification task by proposing an Ensemble Classification approach. Our classification approach using FGSVM and QSVM outperforms LSVM which is selected as base classifier with increase of 2.33%, 1.14%, and 11.09% for Amazon, IMDB and Yelp dataset respectively.