
Abstract
The decisions and approaches of renowned personality used to impress the real world are to a great extent adapted to how others have seen or assessed the world with opinion and sentiment. Examples could be any opinion and sentiment of people view about Movie audits, Movie surveys, web journals, smaller scale websites, and informal organizations. In this research classifies the movie review into its correct category, classifier model is proposed that has been trained by applying feature extraction and feature ranking. The focus is on how to examine the sentiment expression and classification of a given movie review on a scale of (–) negative and (+) positive sentiments analysis for the IMDB movie review database. Due to the lack of grammatical structures to comments on movies, natural language processing (NLP) has been used to implement proposed model and experimentation is performed to compare the present study with existing learning models. At the outset, our approach to sentiment classification supplements the existing movie rating systems used across the web to an accuracy of 97.68%.
Introduction
Sentiment review or opinion prospecting is one of the most indelible mounting areas with its interest and possible assistance is increasing each day. With the opening of the internet and present technology, there has been a progressive growth in the availability of voluminous data. Each person may post their opinions freely and rapidly on social media. Such social data can be analyzed and used in education to draw support and quality learning. One such opinion is sentiment review, here, the opinion of the problem is recognized and required information is strained out whether it is a human opinion on anything materialistic or outcome analysis. In [6, 7], applications of opinion review and the method in which they are applied are studied.
However, finding and tracking opinion on the web sites and distilling the facts contained in them, still remains an impressive mission due to the proliferation of diverse websites. Each website commonly incorporates a large extent of opinion textual content that is not always without difficulty deciphered in lengthy blogs and discussion board postings [8–10]. The normal human being who reads will have a problem figuring out important sites and secure and shortening the evaluations in them. Automatic sentiment analysis systems are thus required. Due to this, numerous start-ups are focusing on providing sentiment evaluation services. Many massive groups have additionally constructed their in-house capabilities. Those practical programs and commercial interests have supplied strong motivations for studies in sentiment evaluation.
Existing studies have produced several techniques for diverse responsibilities of sentiment analysis, which encompass each supervised and unsupervised methods. In a supervised learning-based setting, early studies used all types of supervised models to gain knowledge (including support vector machines, Naïve Byes, and many others.) and feature combinations. Unsupervised techniques consist of numerous strategies that take advantage of sentiment lexicons, grammatical evaluation, and syntactic patterns. Numerous survey books and papers were published, which cover those early techniques and packages considerably [11–13].
Sentiment analysis of movie overview facts is one of the complex problems that is related to natural language processing and machine learning areas, however in practice most research contributions are limited to applying classifiers such as Naive Bayes, Logistic Regression or a MNB classifier [1]. In Naïve Bayes, a finite set of rules obtained are used for the sentiment evaluation through the supervised classification model. Naïve Bayes is a completely simple probabilistic version that has a tendency to work well on textual content, statistics classifications and consumes minimal computation time to perform supervised learning as against to other classifier models and systems.
Usually, through application of naïve bayes classifier, one can attain high degree of accuracy in learning sentiment type. To compare and evaluate the performance, other classifier models such as Logistic Regression based classifier, MNB classifier are applied and results are studied [1–3].
With the availability of large volumes of online film, assessment records IMDB, and different internet sites sentiment analysis is gaining increasingly significant in the present-day context. Given a textual content, a sentiment classifier can classify the input textual content into either of the two classes such as positive (+) or negative (-) [3].
With the advent of many internet platforms like Twitter, Instagram, LinkedIn, Face-book, Blog, IMDB lets stakeholders share their comments, feelings, evaluations, opinion, and judgments on myriad of topics. These platforms contain voluminous amount of data in the form of tweets, comments, blogs, repute, review, and updates on the posts [4]. Sentiment evaluation aims to discover the polarity of feelings like happiness, sorrow, tremendous, terrible, hatred, anger, affection and reviews from the textual content records, opinions, comments, posts that might be available online on those platforms. Opinion mining and sentiment analysis find the sentiment of the textual content records with recognition to a given supply of content material. Sentiment evaluation is complex because of the slang phrases, misspellings, quick bureaucracy, repeated characters, use of local language and new upcoming feelings. So, it is far a massive mission to identify the suitable sentiment of each word. Sentiment analysis is one of the maximum energetic research areas and is likewise extensively studied in fact mining. Sentiment analysis is carried out in almost every enterprise and social domain as the fact opinions are in fact valuable to most human interest & behaviour [5].
Work preparation
In this research, sentiment analysis of movie review data is carried using Naïve Bayes, Multinomial Naïve Bayes, and Logistic regression, using Natural Language toolkit (NLTk) to prepare a data set of a movie review and then apply a suitable classifier algorithm to generate positive and negative accuracies [14].
NLTk
Natural Language Toolbox kit (NLTk) is used for creating python base projects requiring human language information. It has easy to use interfaces. It gives larger no of lexical and corporal assets. For example, a WordNet. It also consists various plug-in for creating libraries to carry stemming, tokenization, grouping, indexing, and semantic thinking. Theses plugins are useful for creating wrappers for good quality NLP libraries. NLTk is a good toolbox for building machine learning algorithms by employing Python and it also has an exceptional library to operate with regular expression.
Machine learning classifier
In AI and insights, the order is a regulated learning approach in which the PC program gains from the information input given to it and afterward utilizes this figuring out how to group new perceptions. This informational index may essentially be bi-class (like recognizing whether the temperature is high or low or that the person is man or woman) or it might be multi-class as well. A few instances of grouping issues are discourse acknowledgment, penmanship acknowledgment, biometric distinguishing proof, archive arrangement and so on [12–14] utilizing Naïve Bayes classifier to fine slant investigation of film audit information.
Supervised learning
The supervised learning approach makes expectations dependent on a lot of models for film reviews. The model utilized for preparing and testing is marked with the estimation of enthusiasm right now films positive or negative survey. Supervised learning like Naive Bayes, strategic and MNB approach searches for designs in those worth names. It can utilize any data that may be significant to the film review information, the season, the sort of industry, the nearness of troublesome occasions and every computation search for various kinds of examples for information. After the computation has discovered the best kind, it utilizes that example to make forecasts for unlabeled testing information that resembles new film reviews information [15].
Naive bayes classifier
It is an organization policy reliant on Bayes’ Theorem with a feeling of spontaneity between symbols. In fundamental phrases, a Naive Bayes classifier affirms that the rate of the special element in a class is disengaged from the proximity of any additional component. [16, 17].
Naive Bayes the theorem presents a method of computation probability-based the posterior probability P(c|x), prior probability P(c), prior probability P(x) and prior probability P(x|c). Consider Equation (1) shown below
The posterior probability P(c|x) is determined by the class (c, target) and the supplied predictor (x, attributes). The prior probability P(c) is presented in a class. The likelihood P(x|c) is the probability of the predictor class. The prior probability P(x) is used for a predictor.
A minor model utilizing Naive Bayes is expected beneath:
Logistic regression is a statistical approach of systematic investigation from a dataset over the independent and dependent variables of consequences of deterministic work. The approach is slow for dichotomous mutable (there are only two outcomes positive or negative, i.e either true or false based on binary outcome 1 or 0) for the significant categorization of the data. Logistic regression is the remarkable approach of linear regression technique that is based on variable positive and negative [18].
MNB classifier
The simple probabilistic classifiers for data classification using a naïve bayes machine learning algorithm are used. This classifier was introduced with different names in the early 1960 and remains a baseline technique for text classification and categorization for the arbitrary problem [19]. The problem extracted from the documents which are arbitrary of nature, belongs to the different additional categories like legitimate technique for sports, different politics over nature etc, which includes various incidents of a word as a feature. Different pre-processing techniques are used in this domain which is very competitive such as naive Bayes is used in our proposed algorithm.
In the involuntary prediction system, there is much application of it. The multinomial including feature vectors extracted from samples and represented in the form of frequencies which is used in the multinomial event-based model.
Here, the probability represents in the form of a different class from (p1 to pn) where Pi is the number of events occurs in the method represented by variable i.
(K is multiclass in the multinomial). Here, x=(x1. ... xn) is the feature vector for the histogram data representation in a particular instance which could be analyzed by different-different events. Majorly, the occasion model is used for text document analysis for classification purpose through which the number of words occurred is analyzed by the events which are available in the sample documents. The process of observing data is expressed in the form of a histogram x is given by the Equation (2)
When the log-space is used for the multinomial naïve Bayes it behaves like a linear naïve Bayes classification technique.
Where b = log p (C k ) and w ki = log p ki .
Differential sentiment analysis is used with different mixtures along with different machine learning classifiers that considers different features for reviewing a movie review from the experiment with various preprocessing steps. Different features like positive and negative discovery are used. Lastly, different machine learning algorithm are applied for treating the data with different classifiers in various works of previous researchers.
The central and key step for any building any learning model is the data collection. The majority of work contains filling and getting that complex data and cleaning the data, which is an important task and hence such as task has to be handled very carefully. It also involves various steps required for where to start the work and move forward towards finishing it through modelling and using various raw data. It is required to prepare a review of the movie using the text data and doing sentiment analysis for step-by-step procedure. There are various procedures required for loading the data and then cleaning it and removing all the errors like the words which are not expected. It may be required to create a vocabulary and then make it available to customers in such a way that they can save it in a file.
The movie reviews need to formulate a properly thorough cleaning process and vocabulary. The review of a movie audited define before and then save them into the trial any new files which are going to be displayed publicly [17, 18]. Movie review dataset new Loading the raw text data Cleaning of raw data Vocabulary design Collect the earliest used data
The preposition has been used for taking the movie data for using different movies bytes and also using the content from the website known as pythonprogramming.net. The various positive and negative movie reviews are used from the dataset for checking the accuracy of the algorithm.
The latest which is used in our proposed model is the content of different file sets and data file, data taken from different movie reviews. The dataset is divided into different parts like training and test set for benchmarking of resolution like but the sentences which are there are coupled from the original order so that it can create a much more efficient training dataset. Rolling in the dataset are analyzed and passed using different persons (like popular persons, like the Stanford purchase) which serves as an expression ID and it also acts as a judgment ID. Some words which can be repeated in the places are involved once only neglecting on for purifying the missing dataset. For data cleaning, algorithm processing is done and purification is used to delete the missing values.
An online value that is used in several datasets, contains different necessary words called as tags, HTML scripts, for their advertisement. Actually, in those kinds of the word, there are various issues. So, thinking of this, its classification becomes much more problematic. So, the majority of work lies on the processing and reducing the noise values so that the text is preprocessed to improve the performance of the algorithm and speed of the classification methods [19–21]. Around 25000 reviews are taken from the different websites which contain both positive and not good reviews these reviews are put it on a different text file in the name given as pure asp.net and any g.st for positive for the negative reviews. 80% of sentences are used for training for the past and 20% of the sentences are used for testing purposes. Underscore of each of the datasets is calculated and from the training dataset. The list is modified and generated using the dictionary from where the train gets upset and store and followed by each of the scores calculated.
Implementation
This section covers the implementation part of the approach based on the different classifiers used in this work with supervised machine learning, for movie reviews dataset, positive and negative text separation is used and required. The dataset is further classified in 3 different categories having separated ratio used for training and test purpose.
training_dataset = feature_dataset[:18000]
testing_dataset = feature_dataset[7000:]
In the second step classify the data using well-known classifiers, and train our classifier like:
classifier = NLTk.
NaiveBayes_Classifier.train(training_dataset)
After the training portion of the classifier, there is a test step in the next section.
print (“Percentage of classification
accuracy:”,(NLTKk.classify.percentage_
accuracy(classifier, testing_dataset))*100)
This classifier is based on the NLTk classifier using all of the methods using Python, and the NLTk classifier in the study.
from nltk.classifyer import Classifier_I
from statistics import mode
Now, allows developing a classifier class:
class Division_Classifier(Classifier_I):
def_init_(self, *classifier):
self._classifier=classifiers
By inheriting from NLTK’s Classifier calling of class Division_Classifier is to be done followed by assignment of classifiers list that is passed to the class for self-classification. And to further invoke, calling is required for classification.
def classify(self, feature):
division = []
for sc in self._classifier:
data = sc.classify(feature)
division.append_data(value)
return mode(division)
And then based on features, classification is done, which are treated as division while iterating is completed, the model is returned to its prevalent division. Use stricture as confidence for the algorithm. Here the confidence method used for calculate the confidence over the features:
def confidence(self, feature):
division = []
for sc in self._classifier:
doc = sc.classify(feature)
division.append(doc)
choice_division = division.count(mode(division))
confidence = choice_division/length(division)
return confidence
The data set has a positive and negative statement and with the help of them, we can train our model. The division of the dataset is done in two parts of 25000 (positive and negative) movie reviews.
The new dataset in a very compatible form is represented here as done before.
short_ positive = fileopen(“short_ analyses/
positive_record.txt”, “record”).read()
short_ negative = fileopen(“short_ analyses/
negative_record.txt”, “record”).read()
document = []
for record in short_positive.split(’∖n’):
document.append((record, “positive”))
for record in short_negative.split(’∖n’):
document.append((record, “negative”))
full_words = []
short_positive_review_words =
wordtokenize_(short_pos)
short_negative_review_words =
wordtokenize_(short_neg)
for word in short_positive_review_words:
full_words.append(w.lower())
for word in short_negative_review_words:
full_words.append(w.lower())
full_words = nltk.Frequency_Distribution (full_words)
With the application of feature finding function, the tokenizing of words is created, for new sample data of document words(). and thereby increasing the common word record.
word_feature = list(fll_word.keys())[:5000]
def find_feature(document):
w = wordtokenize(document)
features={}
for word in word_feature:
feature[w]=(w in words)
return feature
feature_set = [(find_feature(review), category) for (review, category) in document]
random.sort(featureset)
Results analysis
Movie review dataset has 25000 records separated and characterized in three classifiers with an alternate proportion like 90 percent of preparing information and 10 percent of testing information, 80 percent of preparing information and 20 percent of testing information and 70 percent of preparing information and 30 percent of testing information. Naïve Bayes, Multinomial Naïve Bayes and strategic relapse are the three classifiers used to discover the exactness of a negative and positive Movie reviews. The accuracy is the number of true results (both true positives and true negatives) among the total number of cases examined, i.e., true positives, true negatives, false positives, false negatives the accuracy rate is mentioned in the Table 2 below.
Sentence classification
Sentence classification
Comparative results of three classifiers with their accuracy
The word feature is analyzed from the word frequency appeared in the dataset in Fig. 4.
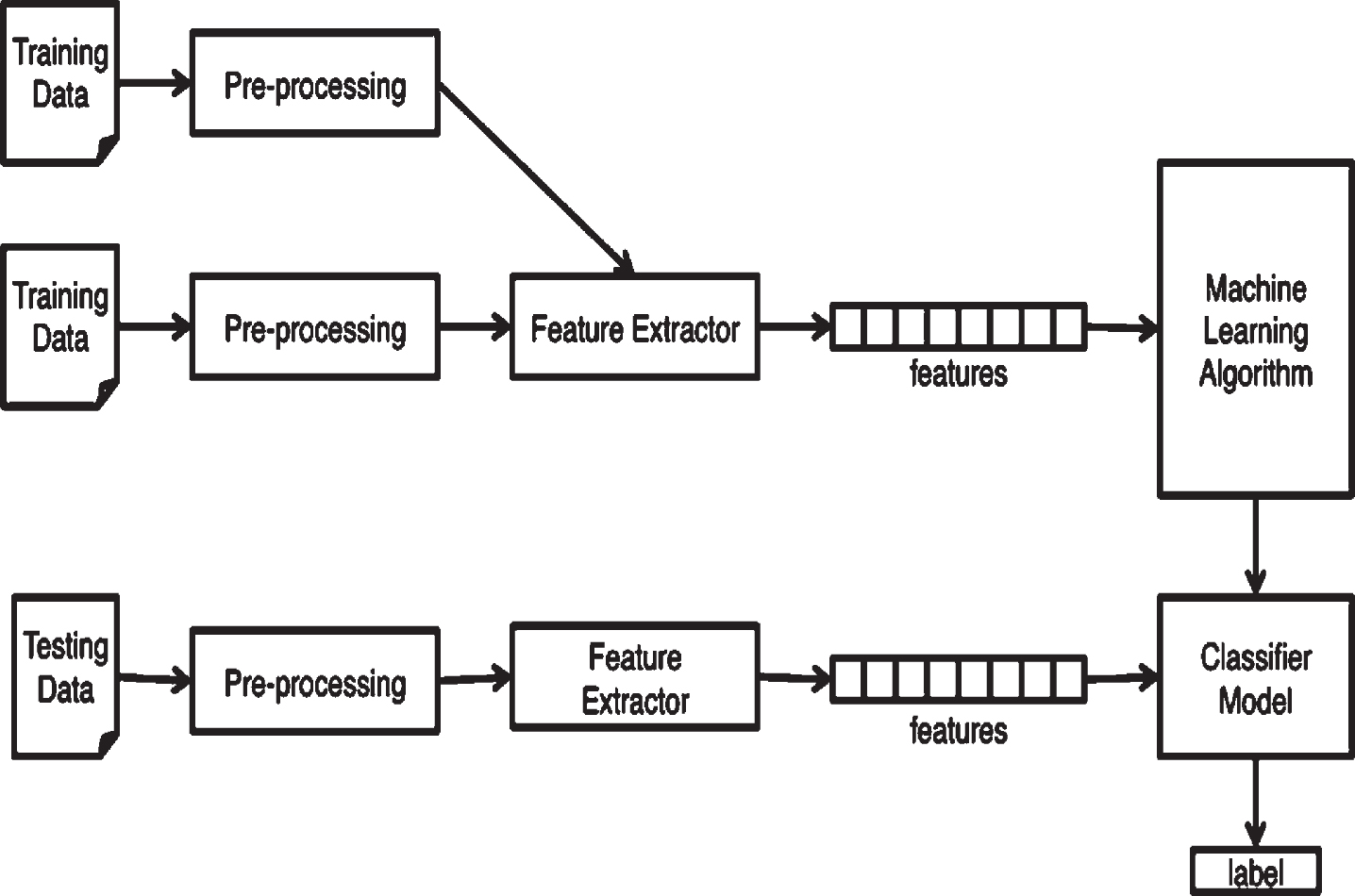
Sentiment analysis methodology for data processing and classification.

Three-step process model.
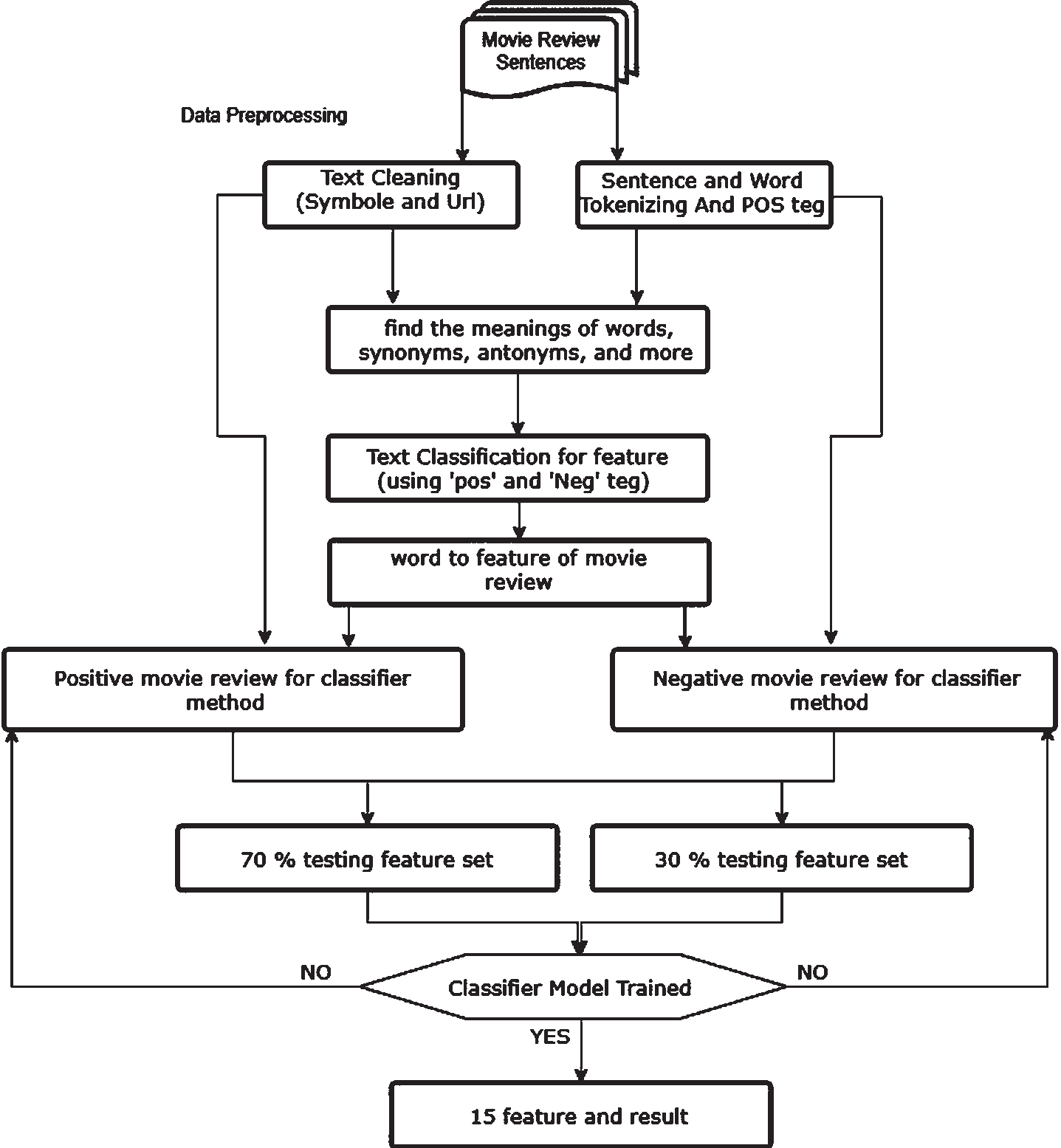
The flow chart of proposed model.

The distributions of negative and positive text.
For each test and each word, on the off chance that it exists in the word score list, add its score to audit score v. Else discover the word in word score list with least inventory to the unidentified word and add its score to the audit score. Check the classifier’s accuracy and show the outcome.
The four plots are distributions of negative and positive text before and after processing. During the processing, the removing of punctuations and stop words in English is done. Also, we removed word with length less than 3 letters.
The assessment of the movie reviews is performed by utilizing various classifiers. Datasets used for experimentation includes data from corpora and online social data collection sites like Twitter, IMDB, Instagram and Facebook, audit on the movie reviews.
The evaluation of wellness using several highlight collections and different learning techniques like Naive-Bayes Multinomial, Logistic Regression, Naive-Bayes, is based on grouping of movie analysis and review audit informational indexing as shown in their extremity (positive/negative).
The outcome shows that a straightforward examination of the classifier model can perform moderately great, and very well it may be additionally refined by the selection of highlights dependent on syntactic and semantic data from the movie reviews content. This study investigated the impact of the highlight vector on the characterization precision. Here, we have analyzed about the corpus that contains sentences from movie comments and reviews. Results revealed a corpus, instead of the fact that it shows the comparative extremity of the words.
The proposed model is only an opening advance towards the improvement in the procedures for opinion investigation. It merits investigating the capacities of the model for the dynamic information and broadening the examination utilizing half breed procedures for notion examination. There is a significant degree for development in the corpus creation and viable pre-handling and highlight determination. Also, improvement in accuracies is observed.