
Abstract
In this paper, we propose a frequency domain data hiding method for the JPEG compressed images. The proposed method embeds data in the DCT coefficients of the selected 8 × 8 blocks. According to the theories of Human Visual Systems (HVS), human vision is less sensitive to perturbation of pixel values in the uneven areas of the image. In this paper we propose a Singular Value Decomposition based image roughness measure (SVD-IRM) using which we select the coarse 8 × 8 blocks as data embedding destinations. Moreover, to make the embedded data more robust against re-compression attack and error due to transmission over noisy channels, we employ Turbo error correcting codes. The actual data embedding is done using a proposed variant of matrix encoding that is capable of embedding three bits by modifying only one bit in block of seven carrier features. We have carried out experiments to validate the performance and it is found that the proposed method achieves better payload capacity and visual quality and is more robust than some of the recent state-of-the-art methods proposed in the literature.
Introduction
Steganography is the science of hiding secret message inside a public cover medium such that the presence of the secret message remains undetectable and not suspected.Digital image steganography is largely divided in two major domains: A) Spatial Domain and B) Transform Domain. In spatial domain approach, the values of cover image pixels are directly manipulated to carry the message bits. The embedding techniques include simple LSB substitution [1] and many of its later variants such as LSB substitution with Local Pixel Adjustment Procedure (LPAP) [2], Optimal Pixel Adjustment Procedure (OPAP) [3], Pixel Indicator Technique (PIT) [4], Pixel Value Difference (PVD) [5] and SLSB [6] etc. Below is the general operation that describes the LSB embedding process:
In Transform Domain techniques, the cover image is first transformed into frequency domain representation using mathematical functions such as Discrete Cosine Transform (DCT), Discrete Wavelet Transform (DWT), Integer Wavelet Transform (IWT) etc. Secret message bits are then embedded by perturbing the frequency coefficients obtained from the transform operation. Next, inverse transform is applied on the modified frequency coefficients to obtain the stego-image. Since any change of the transform coefficients due to data embedding, results in subtle wide-spread (i.e., multiple pixels) changes when the coefficients are inverse transformed to spatial domain, transform domain techniques are generally more resistant to statistical steganalysis attacks.
JPEG (i.e., ISO/IEC 10918) is one of the most successful and popular image compression standards that is used in almost every application ranging from entertainment to medical imaging. Since JPEG is arguably the most popular and ubiquitous on the internet and widely used in almost all applications, a data hiding algorithm for JPEG compressed images with improved payload capacity, better distortion performance and better robustness would be most useful. Therefore, in this paper, we present a robust, transform domain, high capacity data hiding method specially suitable for JPEG cover medium.
The rest of the paper is organised as follows. In Section 2, we discuss the related works and their weaknesses that motivate this research work. In Section 3, we present the proposed data hiding framework in detail. Next, in Section 4, the experimental results are presented and discussed. Finally, in Section 5, the paper is concluded with remarks on further research in this area.
There are many data hiding frameworks and methods in literature that have been specially designed keeping JPEG image cover medium in mind. JSteg [10] was probably first most prominent transform domain data hiding algorithm for JPEG images. JSteg embeds data in the non-zero and non-one quantized DCT (Discrete Cosine Transform) co-efficients. The embedding algorithm used is the simple LSB substitution. The JSteg algorithm provides good payload capacity compared to many contemporary algorithms. However, since it uses the simple LSB substitution technique for actual data embedding, it suffers from vulnerability to statistical steganalysis attacks such as histogram analysis and χ-square attack [11]. These attacks are able to predict the presence of concealed data with high degree of confidence. Moreover, since no effort is made to correct errors induced by re-compression or error prone network transmission, the JSteg algorithm offers no robustness or survivability of embedded data againt these attacks. Later variants of JSteg algorithm such as F5 improved the payload, distortion and robustness performances [11], but still leaves much to be desired. Sachnev et. al. [12] proposed a less detectable and robust JPEG steganography method. It uses Bose–Chaudhury–Hocquenghem (BCH) code to achieve robustness of embedded data. Recently, the authors in [13] proposed a data hiding technique that uses BCH codes for robustness and survivability of the embedded data in noisy transmission, image recompression and other attacks such as median filter and image rotation. The authors in [14] have proposed a steganography method that aims to achieve good robustness of embedded data with the help of Reed–Solomon (RS) code. Jana et al. [15] proposed a robust and reversible dual-image based data hiding scheme that achieved some degree of robustness using (7, 4) Hamming codes using a shared screet key. In [16] the author presented a LWT and DCT based transform domain robust data hiding scheme that is suitable for medical image cover mediums. In this paper, the author proposed to achieve robustness of the embedded data by using Bose–Chaudhuri–Hocquenghem (BCH) codes. Konyar et al. [17] proposed a data hiding method for medical image cover medium that achieved good robustness against salt and pepper noise using Reed-Solomon codes. Over time, one after another, these methods in the literature improved upon the existing performance standards. However, it is imperative to carry on research for even better performance in all three criterion: payload capacity, distortion and robustness. In our work, we have used Turbo Codes for robustness of embedded data and proposed a block selection criteria called SVD-IRM that is able to select destination blocks with high roughness. Moreover, we use a variant of matrix encoding for data embedding that is able to embed three bits of data by modifying only one carrier coefficient. These techniques combined, our method is able to achieve better performance in all three respects. The proposed method is described in detail in the next section and the simulation and performance analysis is presented in Section 4.
Proposed method
The proposed method aims to improve three main issues of data hiding in JPEG compressed cover images —first, distortion performance; second, robustness of embedded data in transmission over noisy channels and re-compression attacks and third, payload capacity. For good distortion performance, it is imperative to embed data only in those 8 × 8 JPEG blocks that results in minimal perceptual distortion upon changes of values of its co-efficients. According to the theory oh HVS, the human eye is highly sensitive to changes in smooth areas in image, but much less sensitive to changes in busy or rough areas. Therefore, to minimize perceptual distortion, it is important to embed data in the relatively coarse blocks, i.e. the blocks that have high spatial roughness. To select the relatively more coarse image blocks, in this paper, we propose a singular value decomposition based image roughness measure (SVD-IRM). Section 3.1 discusses SVD-IRM in detail.
SVD-IRM: SVD based image roughness measure
The singular value decomposition of a matrix A is the unique factorization of A into three matrices
Let
Where
Now, let us assume that the matrix
If an 8 × 8 block has high coarseness (i.e., high roughness), the reconstructed image
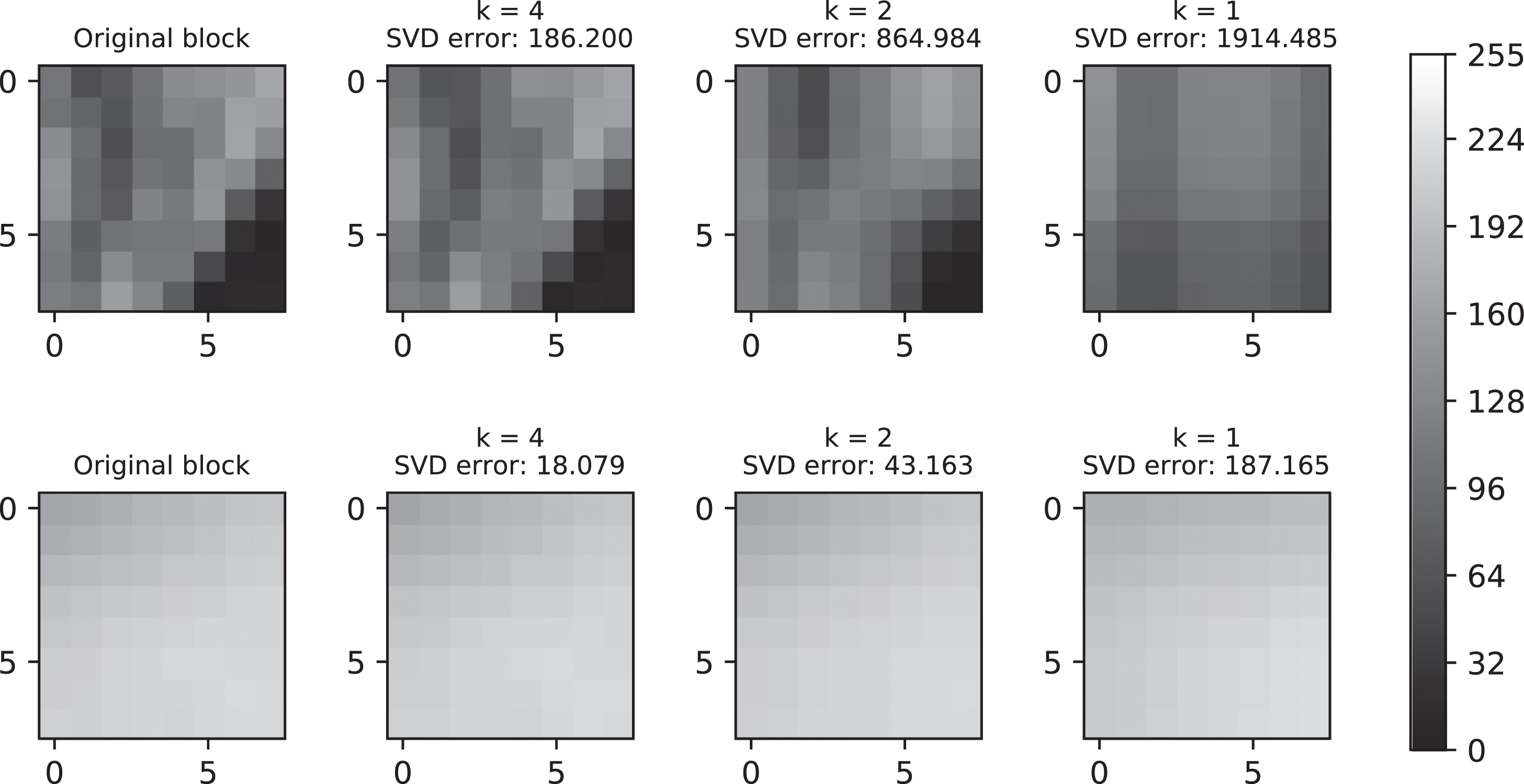
The leftmost blocks are the original 8 × 8 blocks
The proposed SVD-IRM algorithm is based on the above observations. We describe the SVD-IRM process in Algorithm 3.1.

Cover medium with data hidden in it, may be transmitted over unreliable network channel. This may introduce errors in the cover medium. Errors may render the embedded data unreadable, invalid or meaningless. Moreover, an attacker may deliberately apply destructive operations on the cover medium it in order to damage the embedded data. To prevent these and to increase the survivability of the embedded data, we employ error correcting coding that introduces redundancies in the data. The data with the added redundant bits is transmitted over the network. The noisy channel may cause errors (i.e., one or more bits may have changed) at the receiver end. The decoding algorithm then corrects the errors based in the redundant bits.
In order to achieve higher efficiency of the traditional codes so that it approaches the Shannon limit [19], the code-word length of the linear block codes (or constraint length, for convolutional codes) must be increased. However, complexity of the decoder is exponential to code-word lenght and therefore the decoder takes exponentially longer time. Turbo codes address these issues. Turbo codes [19, 20] simulate larger coding blocks by methods of splitting and interleaving, such that the decoder can decode in a number of smaller blocks. An interleaver is used that temporally permutes a sequence of symbols completely deterministically. An additional benefit of interleaving is that, statistically correlated burst errors in data are converted to statistically independent short errors while the data being de-interleaved at the decoder. This makes it possible that code designed for correcting statistically independent errors to be used as the constituent codes (for encoder 1 and 2). Figure 3 illustrates the basic building blocks of a Turbo encoder ans decoder system. The interleaver permutes the input bits (in periodic or pseudo-random manner) such that the two encoders operate on the same set of input bits at any given time, but in different order.
In the proposed work, we utilize parallel concatenated convolution encoders (PCCE) as the constituent encoders and a pseudo-random interleaver. The proposed structure of the constituent encoder is shown in Figure 2. For decoding at the receiver end we use the Soft-Output Viterbi algorithm (SOVA) [21] that decodes received codes by estimating logarithm of likelihood ratio (LLR) as given in Eq. 8.
The two schemes of Turbo codes of parameters n, k and t and constraint length used in our work
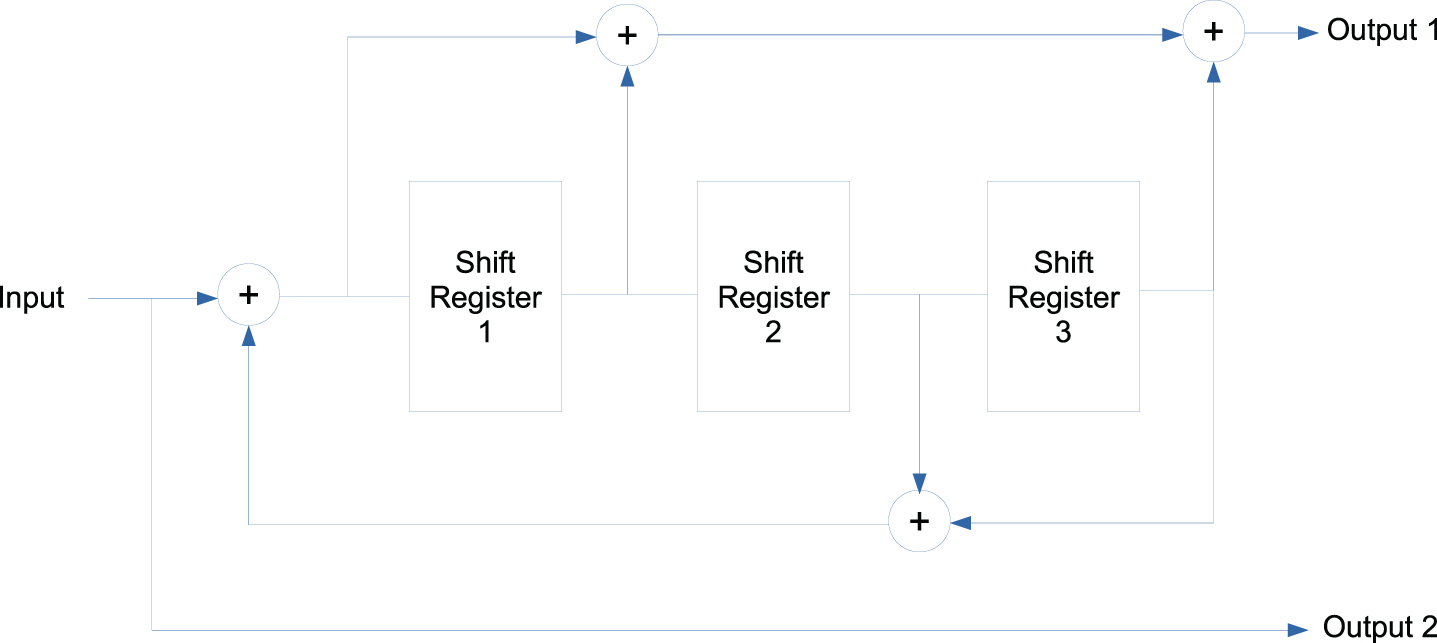
Structure of the constituent recursive convolution encoder used in this work. This is a half-rate, 8-state encoder. Both CE1 and CE2 have the same structure.

The proposed structure of the Turbo coding/decoding system.
The actual data embedding and extraction is done using a Matrix Embedding scheme. The family of Matrix Embedding was discussed in [22]. In our work we use a (7, 3, 1) scheme of matrix embedding. This scheme is able to embed 3 data bits in a block of 7 DCT coefficients, by modifying only 1 of the coefficients. This scheme works as follows. Let D = (d1d2d3) be a sequence of three bit data to be embedded and the destination block of seven coefficients is C = (C1, C2, C3, C3, C4, C5, C6, C7). Define three parity values P1, P2 and P3 as follows.
To encode data bits (d1d2d3), perturb the coefficients as follows: Case 1. If (d1 = P1) ∧ (d2 = P2) ∧ (d3 = P3), modify no coefficient Case 2. If (d1 ≠ P1) ∧ (d2 = P2) ∧ (d3 = P3), modify C1 as follows. If |C1| = C
max
, |C1| = |C1 - 1|. Else, C1 = C1 + 1 Case 3. If (d1 = P1) ∧ (d2 ≠ P2) ∧ (d3 = P3), modify C2 as follows. If |C2| = C
max
, |C2| = |C2 - 1|. Else, C2 = C2 + 1 Case 4. If (d1 ≠ P1) ∧ (d2 ≠ P2) ∧ (d3 = P3), modify C3 as follows. If |C3| = C
max
, |C3| = |C3 - 1|. Else, C3 = C3 + 1 Case 5. If (d1 = P1) ∧ (d2 = P2) ∧ (d3 ≠ P3), modify C4 as follows. If |C4| = C
max
, |C4| = |C4 - 1|. Else, C4 = C4 + 1 Case 6. If (d1 ≠ P1) ∧ (d2 = P2) ∧ (d3 ≠ P3), modify C5 as follows. If |C5| = C
max
, |C5| = |C5 - 1|. Else, C5 = C5 + 1 Case 7. If (d1 = P1) ∧ (d2 ≠ P2) ∧ (d3 ≠ P3), modify C6 as follows. If |C6| = C
max
, |C6| = |C6 - 1|. Else, C6 = Q
C
+ 1 Case 8. If (d1 ≠ P1) ∧ (d2 ≠ P2) ∧ (d3 ≠ P3), modify C7 as follows. If |C7| = C
max
, |C7| = |C7 - 1|. Else, C7 = C7 + 1
Data is extracted from the modified coefficients at the receiver end as follows. Let a modified block of coefficients be Find the parity conditions of the modified coefficients at the receiver end. using Eq. (11)–(13)
Three data bits
Figure 4 illustrates two cases of embedding in an example 4 × 4 block of destination coefficients. In JPEG algorithm the block size is 8 × 8 but in this example we have used 4 × 4 blocks for brevity.

Illustration of the embedding process by taking an example 4 × 4 block of coefficients and two 3-bit messages. The two messages consisting of six bits in total, are embedded by perturbing only two coefficients.
In the proposed method, payload data is embedded in the quantized DCT coefficients of the image while JPEG encoding is being performed. Therefore, the embedding process is closely integrated to the JPEG encoding algorithm. First, the payload message is converted to binary. Then the data is encoded in one of the Turbo error correcting codes (ECC) given in the Table 1. Then, JEPG encoding is started on the input carrier image. The JPEG algorithm divides the image in a collection of 8 × 8 blocks. DCT is applied on each block. Next, spatial domain counterpart of each of the block is analyzed using the proposed SVD-IRM algorithm 3.1 described in Section 3.1. SVD-IRM measures roughness of each of the 8 × 8 blocks in spatial domain. The blocks are then sorted based on their CSVD-IRM values. Next, α% of these blocks are selected which have the highest CSVD-IRM values. Only the corresponding transform domain blocks are selected as data embedding venues and the rest are skipped. Next, the ECC encoded is embedded in the quantized DCT coefficients of the selected blocks. Afterwards, the usual steps (e.g., entropy coding) of the JPEG algorithm are performed and the compressed image is output, in which the payload data is embedded. The quantity α works as a parameter to control the amount of payload data and embedding distortion. If α is 50%, half of the 8 × 8 blocks of the image are selected as embedding venue and if α is 25%, one-fourth of the blocks are selected. Thus, depending on the value of α, number of embedding blocks are adjusted. The more blocks are selected, the more coefficients are modified and more data is embedded, which results in better payload capacity but higher distortion. Hence, the proposed method is flexible and allows for choosing a good trade-off between payload capacity and distortion depending on the application. The extraction process is closely tied to the JPEG decoding algorithm. The data extraction after entropy decoding but before de-quantization. The data is extracted form the quantized DCT coefficients from the block in which data was originally embedded. The overall embedding and the extraction processes are described in Algorithm 3.4 and Algorithm 3.4. The processes are illustrated in Figure 5 and Figure 6.

Block diagram of the overall embedding process

Block diagram of the overall data extraction process


We have conducted extensive experiments to validate and compare the performance of the proposed method. We implemented the method in Python (v.3.6.9) programming language in Linux (Ubuntu 18.04) OS environment running on a computer with Intel i3-3110M CPU and 4GB memory. In the experiments, as cover images, we use six 512 × 512 images that are well known and widely used in the image processing research community. These images are: Peppers, Baboon, Tiffany, Lena, Jet and Splash. These images are shown in Figure 7. We have simulated and compared payload capacity, distortion performance and robustness against multiple types of noise and attacks with respect to performance of two recent state of the arts in the literature which are Kumar et al. [13] and Banerjee et. al. [14]. One challenge that we faced in performance comparison, is that, most proposed methods in the literature use cover image datasets that are not available in the internet. For example, in [13] six images are used, among which only two (Pepper and Baboon) are well known and available. The capacity, distortion and robustness performances are presented in the next sections.
Payload capacity and distortion performance
We evaluate the distortion performance of the proposed method in terms of two metrics: Peak Signal to Noise Ratio (PSNR) and Structural Similarity (SSIM) [23]. The results are summarized in Table 2 and Table 3. From the tables, it can be seen that the proposed method has much better distortion performance than [14] and performs almost at per with Kumar et al. [13]. The cover and stego-images with embedded data are show in Figure 7 and it can be seen that there is no noticeable visual distortion. For [13] only two images could be compared as the other images used in that paper are different and could not be found on the internet.
PSNR values achieved by the proposed method on six test images, compared to the two recent sate of the art methods in the literature. Some cells are empty because Kumar et al. [14] did not provide performance results on those images
PSNR values achieved by the proposed method on six test images, compared to the two recent sate of the art methods in the literature. Some cells are empty because Kumar et al. [14] did not provide performance results on those images
SSIM values achieved by the proposed method on six test images,compared to the two recent sate of the art methods in the literature. Some cells are empty because Kumar et. al. [14] did not provide performace results on those images

The images in the top row are the original 512 × 512 grayscale test images. The images in the bottom row are the stego-images with data embedded in them. Evidently, there is hardly any noticeable distortion
The embedding capacity performance is evaluated in terms of bits-per-pixel (bpp) and are summarized in Table 4. Banerjee et al. [14] did not provide capacity performance results whereas only two images of Kumar et al. [13] were publicly available. From the results, it is seen that the proposed method has better payload capacity than the method in [13].
The data embedding capacity of the proposed method in bits per pixel (bpp) compared to the two recent sate of the art methods in the literature. Banerjee et. al. [14] did not provide capacity performance results at all
The robustness performance is evaluated in terms of recovery percentage of embedded data when the stego-image is subjected to attacks such as additive Gaussian noise, JPEG compression and median filtering. The results are summarized in Table 5. In Table 6 we compare robustness of the proposed method with the work of Banerjee et. al. [14]. The results show that the proposed method is much more robust than both the recent state of the art methods in the literature. This can be attributed to the superior error correcting capabilities of the Turbo code.
Recovery rate of the embedded payload data when the stego-image is subjected to additive Gaussian noise with σ = 0.5, JPEG compression of ration 5 : 1 and median filtering. These results are compared to that of Kumar et. al. [13]
Recovery rate of the embedded payload data when the stego-image is subjected to additive Gaussian noise with σ = 0.5, JPEG compression of ration 5 : 1 and median filtering. These results are compared to that of Kumar et. al. [13]
Bit error rate (BER) rate of the recovered payload data when the stego image is subjected to JPEG compression with quality factor QF = 90%, salt pepper noise and image sharpening. These results are compared to that of Banerjee et al. [14]
In this paper we have proposed a frequency domain data hiding method for JPEG compressed cover images. The proposed method aims to address all three aspects of data hiding: payload capacity, visual distortion and robustness of the payload data against noise, re-compression and other image processing attacks. Taking cue from the theory of HVS, we have proposed a novel SVD based block selection algorithm that selects relatively coarse blocks in the JPEG image for data hiding destinations. Moreover, for robustness, we used a powerful error correcting code called Turbo code. The benefits and superiority of Turbo codes in correcting random errors in the embedded data have been demonstrated in the experimental results. Turbo code gave superior BER and recovery rate of the embedded data compared to other recent state of the art methods in presence of simulated noise, image compression and other attacks. Moreover,in the proposed work, the actual data embedding is done using a variant of matrix embedding that embeds three bits data in a block of seven DCT coefficients by perturbing only one coefficient. This results in improved stego-image distortion. The efficacy of the proposed method has been demonstrated by extensive experiments.