
Abstract
With the development of urbanization, urban traffic has exposed many problems. To study the subway’s influence on urban traffic, this paper collects data on traffic indicators in Nanchang from 2008 to 2018. The research is carried out from three aspects: traffic accessibility, green traffic, and traffic security. First, Grey Relational Analysis is used to select 18 traffic indicators correlated with the subway from 22 traffic indicators. Second, the data is discretized and learned based on Bayesian Networks to construct the structural network of the subway’s influence. Third, to verify the reliability of using GRA and the effectiveness of Bayesian Networks (GRA-BNs), Bayesian Networks with full indicators analysis and other four algorithms (Naive Bayes, Random Decision Forest, Logistic and regression) are employed for comparison. Moreover, the receiver operating characteristic (ROC) area, true positive (TP) rate, false positive (FP) rate, precision, recall, F-measure, and accuracy are utilized for comparing each situation. The result shows that GRA-BNs is the most effective model to study the impact of the subway’s operation on urban traffic. Then, the dependence relations between the subway and each index are analyzed by the conditional probability tables (CPTs). Finally, according to the analysis, some suggestions are put forward.
Introduction
Background
The acceleration of China’s urbanization has led to rapid social and economic development. However, a series of urban problems, such as explosive population growth, population mobility, and the imbalance between supporting facilities and urban expansion, have emerged one after another, which has led to many traffic problems, resulting in limiting the healthy development of cities. The smooth flow of urban traffic not only reflects the level of urban management planning but also demonstrates the potential of the city’s future development. Table 1 reflects the top ten cities in the peak commuter congestion index in 2019. Unreasonable ground transportation planning and high car ownership are all causes of traffic congestion. This phenomenon has brought many urban development problems, such as transportation network safety, environmental noise pollution, electromagnetic interference, and other issues.
National Traffic Congestion Ranking of 100 Cities in 2019
National Traffic Congestion Ranking of 100 Cities in 2019
To solve traffic problems in medium and large cities, urban road traffic in many cities has been optimized, and methods such as vehicle number travel, building BRT, widening roads, improving road traffic networks, and rush hours are used to relieve road traffic pressure. During the development of China’s rail transit, the growth rate of operating mileage is relatively high. From 2012 to 2019, the annual growth of rail transit operating mileage has exceeded 10%. The changes in operating mileage of China’s rail transit are shown in Fig. 1.

Total length and growth rate of urban rail transit lines in China from 2012 to 2019.
As an urban infrastructure, the development of the subway is still developing rapidly throughout the country. The urban subway in mainland China completed 23.71 billion passenger trips throughout the year, increasing 2.64 billion people over the last year. The high efficiency, punctuality, environmental protection, and increased accessibility have been favored by all sectors of society and have gradually become the mainstay of public transportation in medium and large cities.
In recent years, many scholars have studied extensively when analyzing the impact of subway opening on cities. To study the accessibility of subway opening to urban traffic, Paloma Cáceres et al. [15] improved the accessibility in the public transport system by using available information (open data, semantic-aware knowledge) provided by transport organization; Wang [24] analyzed the relationship between community attributes and the subway home-price capitalization effect, asking whether the magnitude of the subway proximity premium is affected by neighborhood economic status and location; Trojanek and Gluszak [17] analyzed both spatial and time effects of subway availability on apartment prices in Warsaw; Seo and Nam [22] used the conventional hedonic price model and the spatial autoregressive combined model to examine the effect of subway accessibility on apartment prices for the three types of apartments. Furthermore, to illustrate the influence of subway construction on the evolution of urban spatial morphology, Miao et al. [27] used the concept of response displacement method to investigate the seismic characteristics of subway tunnel under spatially varying earthquake ground motions (SVEGMs). The research concluded that the development of rail transit strengthened Zhengzhou’s spatial development axis and affected the urban land use Structure optimization and gradually formed a multi-center urban spatial development structure; Li et al. [18] used a variety of remote sensing images, landscape metrics and gradient analysis to study the spatiotemporal dynamics of urban expansion and regional structure changes along the Guangzhou-Foshan intercity metropolis in the Pearl River Delta.
Moreover, the traffic evaluation system has always been a hot research topic for scholars in traffic evaluation, and there has not found a widely recognized traffic evaluation model. The reason is that traffic is often closely related to research on economy, environmental protection, and technology. Therefore, when a traffic evaluation model is being constructed, it tends to have a specific directionality. Ziedan [1] used multilevel negative binomial regression models to analyze light rail and streetcar collisions and injuries; Lin et al. [5] established a road network model in VISSIM to compare four different traffic organization plans. According to the different means of transportation, the existing research fields can be divided into public transportation, road transportation, rail transportation, etc. When studying the urban traffic evaluation system, scholars pay more attention to private cars’ impact on traffic. During the research process, indicators such as road traffic and car ownership often become essential aspects, while public transportation accounts for fewer influencing factors; research is more focused on traffic prediction. Gabriel Gomes [6] developed the Traffic Prediction System (TPS) model to generate the system’s real-time daily status prediction and large-scale distribution activities. Barros [4] studied the traffic conditions in residential areas and constructed an evaluation model using noise, pollution, and congestion as comprehensive evaluation indicators. Mark Wardman et al. [21] analyzed the urban traffic evaluation system and took noise and air quality as critical factors.
After detailed exploring the research on the application of the Bayesian networks and the urban traffic evaluation system, it is found that the Bayesian networks is widely used in traffic accidents, and it is mostly causal reasoning in traditional research. The research involves selecting the result as a class variable and the reason as an attribute variable. Scholars are confined to a particular aspect in studying the impact of subway opening on urban traffic but have not established a comprehensive evaluation system. Thus, this paper comprehensively analyzes the various traffic data of Nanchang subway since its official opening in December 2015 and the data before the opening of the subway from 2008 to 2015. It is constructed a comprehensive evaluation system from three aspects of traffic accessibility, green transportation, and safety for study to analyze the impact of subway opening on urban traffic. In addition, the paper also proposes a research method based on grey relational analysis and Bayesian networks method (GRA-BNs) learning to identify and screen the indicators with a high degree of relevance to subway opening and analyze the dependence between various indicators. The framework and technical route for this paper is shown in Fig. 2.

Framework and technical route of this paper.
Grey relational analysis
Grey Relational Analysis (GRA) refers to a quantitative expression of changes in the causal state in the development and evolution of various factors and results of a system. It is a method of comparing the intimacy between multiple factors and results. The fundamental core is to adopt and determine the degree of similarity between the reference data column’s geometric state and several data columns to determine the distance relationship, which expresses the degree of correlation of the curve [11].
The first step of utilizing the GRA is to determine a series of data as an evaluation index, i.e., the reference series determines the statistical data series of the fixed characteristics in the system, and the comparison series represents the data series that affect the behavior of the system. The reference series is as follows:
The comparison series is as follows:
Due to the differences in definitions, meanings, units, and value ranges of the indicators, the dimensions of the indicators are inconsistent, making it inconvenient for direct comparison. Therefore, when GRA is adopted for data, it is usually necessary to pre-process the data without dimension, and finally compare and analyze each index.
The grey relativity generally refers to the difference trend of geometric states between the curves, and the difference is the size of the correlation level. The calculation formula of each correlation coefficient is as follows:
Where
Since the correlation coefficient is to compare the correlation level of the sequence with the reference sequence at different times, its value is not unique and is not suitable for the overall comparison. Therefore, the correlation coefficient of each indicator is averaged to compare and analyze the evaluation objects. The calculated average value is the quantitative expression of the correlation analysis between the comparison series and the reference series. The value range of the correlation degree is between [0, 1]. The closer to 1, the greater the correlation degree, and vice versa. Calculated as follows:
After obtaining the relevance of each indicator, each factor is sorted according to its numerical value. The higher the evaluation indicator’s ranking, the higher the correlation level between the indicator and the reference quantity. On the contrary, the lower the correlation level.
The Bayesian networks (BNs) is also regarded as a reliability network, which is a continuation of the Bayesian method and an effective theoretical model, especially widely used in the field of uncertain expression and reasoning. The BN method is a mainstream method to solve uncertain and incomplete problems, including the knowledge of probability theory and graph theory [2]. BN is expressed by a directed acyclic graph (DAG), i.e., B (G, P), where G represents a directed acyclic graph, and P represents conditional probability tables (CPTs). DAG is composed of nodes and directed arcs. Nodes represent random variables, directed arcs represent the connections between nodes (from the parent nodes to the child nodes).
On the one hand, the BN simplifies the complexity of the problems; on the other hand, the uncertain problems are modeled and refined. Because the CPTs are based on rigorous probability derivation, the dependence between nodes is expressed by prior probability or posterior probability, and the qualitative causal relationship is transformed into a quantitative derivation model based on probability calculation. In view of the above characteristics of BN, it has obvious advantages over other machine learning algorithms such as decision tree, support vector machine and neural network.
Conditional independence diagnoses whether there is a correlation between nodes from the perspective of probability. The first step is to determine the probability distribution and value range of data. Second, by observing the BN and analyzing the directed line segments in the graph, the independence and correlation between network nodes are recognized. Third, in BN, conditional independence is reflected in the graph, i.e., directed separation, and the result of conditional independence between nodes can be obtained from graph observation. For the point set X, Y, and Z without intersecting connection, the necessary condition for the conditional independence of X and Y concerning Z can separate X and Y in Z. Before studying directed separation, three particular types of node connections should be taken into consideration (Fig. 3): Sequential connection: the directed acyclic connection mode is X
i
→ X
k
→ X
j
, in which the intermediate node X
k
has a special name and is recorded as a head-to-tail node; Divergent connection: the directed acyclic connection mode is X
i
← X
k
→ X
j
, in which the intermediate node X
k
has a special name and is recorded as a tail-to-tail node; Convergence connection: the directed acyclic connection mode is X
i
→ X
k
← X
j
, in which the intermediate node X
k
has a special name and is recorded as a head-to-head node.

Three special node connection situations.
The purpose of structure learning is to find out the dependencies between nodes and then construct a network structure model corresponding to the training data set’s simulation state, which is learned by the entire BN method necessary steps. All subsequent analyses are based on the completion of the work.
For a set of random variables V = {V1, V2, . . . , V
n
} and the training data set D = {D(1), D(2), . . . , D(m)} about these variables, where m is the number of training sets. The goal of learning is to obtain the most adaptable DAG structure G. When there are few variables and fewer iterations, it is easy to get the structure. However, when the number of nodes is large, the corresponding graph structure’s complexity will increase accordingly. The number of DAG g(n) and the number of nodes n satisfy the function (4):
According to the algorithm difference of structure learning, different types can be extended. In essence, these methods are mainly divided into two categories: constraint-based methods and search score-based algorithms. The following specific search scored-based methods are utilized in this study.
(i) Algorithm based on search score
The search-and-score-based BN structure learning algorithm mainly proposes optimization and improvement schemes through BN and uses existing scoring algorithms to calculate the highest-scoring network structure [12]. The structure learning model of search scoring can be uniformly expressed as the function model:
Where f is the core formula, i.e., the search scoring function, θ is the structure learning space, and G| = C means that the directed acyclic graph G satisfies the constraint C. In the search scoring system, the restriction C is to ensure that the searched model structure is all DAG. The optimal structure can be expressed as the function:
In machine learning, we must first determine the training set D and the potential structure G, and penalize the data that does not meet the requirements and the results that have the properties of the DAG graph structure. In addition, when the structure meets the data distribution requirements, give the graph structure a simple Higher evaluation of the model. If the scoring algorithm’s calculation results have better homogeneity, it means that the results also have higher sufficient accuracy. Based on this situation’s consideration, the scoring function is further classified into Bayes-based and information-based scoring functions. The research process of this paper uses Bayes-based scoring functions. The Bayesian scoring function regards the formula G* as a MAP type problem:
Where P (G|D) is the posterior probability of structure G given D. Assuming that the prior probability of g is P (G), according to Bayesian formula:
P (D) has nothing to do with g, so P (G|D) is proportional to P (D|G) P (G), and the logarithm of both sides are:
If the parameter of the directed acyclic structure G is ΘG, we can get:
Where the likelihood function L (G, ΘG|D) P (D|G, ΘG) represents the relevant number set of the structural model. In the process of analyzing the discretized training set, it is generally assumed that the prior probability distribution P (ΘG|G) of the model parameters obeys the Dirichlet distribution probability with the parameter α
ijk
:
Where Γ represents the gamma function, r i is the number set of training objects whose state of the node V i is k and the parent node combination is j, m ij = ∑ k m ijk and α ij = ∑ k α ijk . Combining formula (6) with (10) can get:
This formula is also called the BD score. When the structure is equal frequency distribution, log P (G) =0, the latter term of the BD score can be ignored, which is called the GH score [13].
Regarding the Dirichlet parameter α ijk , it exists in the BD score. If the Dirichlet parameter α ijk obeys 1, the K2 score is derived. This article mainly employs the K2 scoring model:
(ii) K2 algorithm
The K2 algorithm is a scoring function, as described above, is a structure learning algorithm. It was first proposed by Cooper and Herskovits [16]. In the algorithm, the quality of the structure is measured by the CH score. To limit the search space, the node order ρ and a positive integer u are used. The starting point of the K2 algorithm is a graph with unstructured and undirected lines. It traverses each node in turn according to the order of each node specified in the node sequence array and calculates its CH score by comparing the specific changes after a certain node is added. If it increases the representative, it is necessary to increase the parent node. To avoid the parent node’s redundancy, limiting the number of parent nodes is mainly by using a positive integer u. However, identifying the proper node sequence is the most basic part of the algorithm, and the final output network structure diagram is closely related to the difference in node sequence. Therefore, the K2 algorithm is so widely used. Experts and scholars have proposed various solutions to the problem of node order improvement, such as the method of learning node order, which is completed by the CI test.
In analyzing the research influence relationship, Chen Yanyan et al. [26] used logistic regression analysis to distinguish and analyze the road traffic influence factors; Yu et al. [7] used spatiotemporal recurrent convolutional networks to predict large-scale transportation network traffic. To verify the BN’s effectiveness, Zhang et al. [3] utilized the ROC area, accuracy, and other indicators in the comparative analysis of the BN, decision tree, support vector machine, and other algorithms to construct the traffic accident black spot recognition model. This section also uses the following indicators for model reliability evaluation.
ROC area is enclosed by the coordinate axis under the ROC curve, the decimal of the range of [0, 1]. The ROC curve is generally compared with y = x. The area above the linear function graph is usually above 0.5. The closer this value is to 1, the better the effect of the model. The value in [0.5, 0.7] is lower accuracy, [0.7, 0.9] represents a certain degree of accuracy, [0.9, 1] represents better accuracy, and [0, 0.5] represents completely invalid. The true positive rate (TP) rate measurement sensitivity is defined as the ratio of actual positive and predicted positive samples. The false positive rate (FP) rate represents the proportion of actual negative and predicted positive samples. The ratio of the TP rate to the FP rate is directly proportional to the classification effect. The larger the ratio, the better the effect.
Precision is the proportion of samples that are predicted to be positive if they are positive.
Recall is a measure of coverage, which is equal to sensitivity.
F-measure is used to comprehensively evaluate precision and recall indicators. When the F metric is larger, the effect of the classifier is better.
Accuracy is often used when testing the classification effect—the greater the accuracy, the better the classifier’s performance.
The calculation formula for each index is as follows.
Where TP is actually positive and predicted positive data, FP is actually negative but predicted positive data, TN is actually negative and predicted negative data, FN is actually positive but predicted negative data.
Collection of influence indicators based on GRA
The evaluation system to explore the impact of subway opening on urban transportation development is divided into three layers: cause layer, first-level indicators layer, and second-level indicators layer. The first layer is the cause layer, whether to build a subway is the criteria; the second layer is the main content of the evaluation system, setting sub-goals from three aspects: accessibility, green transportation, and safety; the third layer is the second-level indicators layer and indicators at this level are all numerical indicators. There are 22 indicators in the second-level indicators layer, shown as Table 3. The statistical data of each reference sequence from 2008 to 2018 is shown in Table 4.
K2 algorithm
K2 algorithm
Primary selection index system table
Statistical Table of Reference Sequences from 2008 to 2018
The calculated correlation degree is shown in Table 5. The second-level indicators under the first-level accessibility index have a large correlation with subway opening. The maximum is the growth rate of road area rate X3 reaching 0.975678726, and the minimum is taxi operation. The increase in the number of vehicles X6 is 0.648601097, while the correlations of the secondary indicators under the green transportation primary indicators are relatively small. The maximum is the road cleaning area X15, and the minimum is the energy consumption elasticity coefficient of only X16, which is 0.433484404, and the accessibility is level 1. For each secondary index under the index, the maximum X20 reaches 0.934185223, and the minimum X18 reaches 0.682965801. When Ma Xiaotong [25] analyzes the influencing factors related to single-vehicle accidents using improved grey correlation analysis, the factors with the average correlation degree exceeding 0.6 are selected as the key factors affecting the occurrence of the accident. Therefore, in this section, indicators with a correlation degree greater than 0.6 are selected as the evaluation indicators for the impact of subway opening on urban traffic, so X1, X2, X3, X4, X5, X6, X7, X8, X9, X12, X14, X15, X17, X18, X19, X20, X21, X22 are used as traffic indicators for follow-up analysis.
Grey correlation degree of each comparison sequence
From the BN structure (Fig. 4), it can be seen that the per capita traffic network area growth X1 and the bus operation mileage growth X2 are only dependent on the opening of the subway. However, the four indicators of road area rate growth rate X3, infrastructure investment X12, taxi operating vehicle number growth X8, and total bus passenger transport X6 are not only directly affected by the opening of subways, but also by per capita traffic network area growth X1 and bus operations mileage increase X2. In addition, the proportion of urban transportation land consumption X7, road cleaning area X15, 100-kilometer road death rate X20 related to not only the opening of the subway, but also one of the increases in the traffic network area per capita X1, the increase in bus operating mileage X2, the road area rate growth rate X3, infrastructure investment X12, and taxi operating vehicle number growth X8 and total bus passenger transport X6. Moreover, the number of standard buses for 10,000 people X4, the travel coefficient of citizens X5, the proportion of one-time electric energy X14, the accident rate of 10,000 vehicles X18, and the total number of taxi passengers X9 not only related to the opening of the subway, but also two of the increase in traffic network area per capita X1, the increase in bus operating mileage X2, the increase in road area rate X3, the infrastructure investment X12, the increase in the number of taxi operations X8, and the total number of bus passenger transport X6. Furthermore, the proportion of drivers under three years of driving experience X17, the death rate per 10,000 vehicles X19, the average economic loss of traffic accidents X21, and the number of road traffic accidents X22 are not only directly related to the opening of the subway, but also other 14 attribute variables.
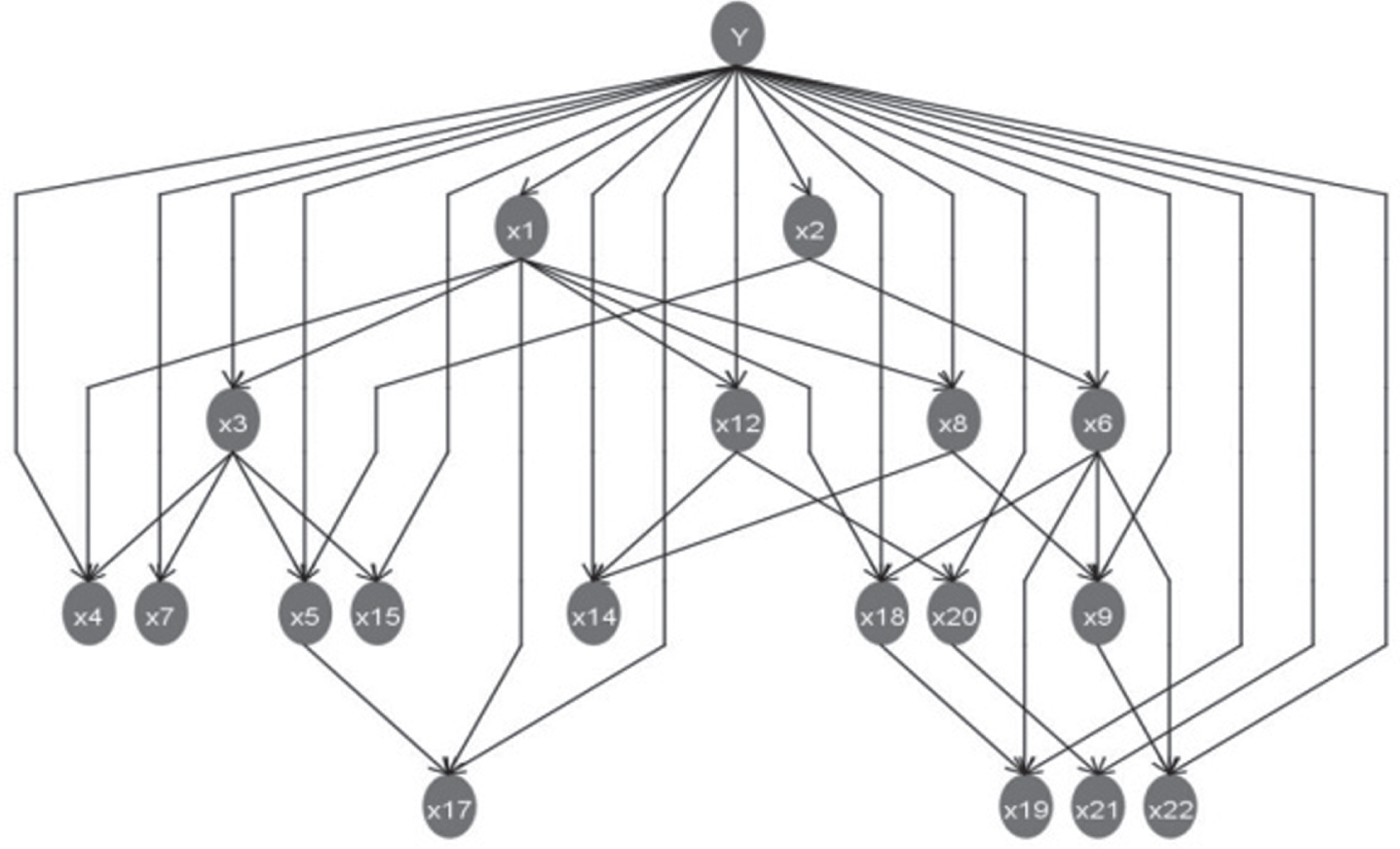
The influence of subway opening on urban traffic Bayesian networks structure.
To judge the reliability of selecting GRA for index screening, under the condition of adopting the BN method, the result of analyzing 22 indexes without index screening with GRA is compared with the outcome of index screening using GRA. Moreover, in this paper, the ROC curve area is selected as the reference index for comparison. The ROC curve is shown in Fig. 5, where the abscissa represents the false positive rate, and the ordinate represents the true positive rate. Among them, the ROC curve area of GRA-BNs is 0.986, and the ROC curve area of All-BNs is 0.886. Therefore, it is better to use GRA to screen than to analyze 22 indicators without GRA.
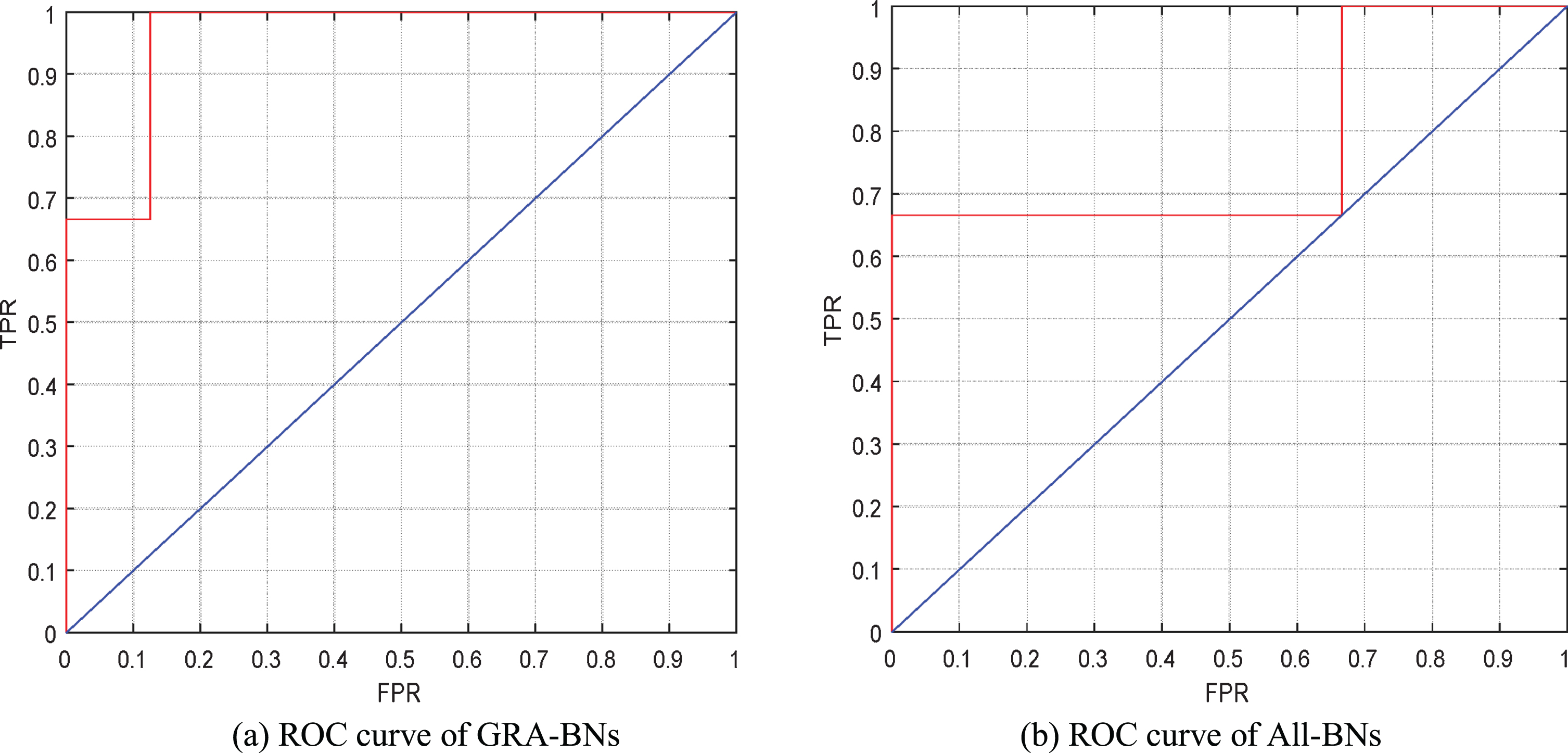
ROC curve graph of the full index and grey relational analysis.
To further explore the reliability of proposed GRA-BNs, the results are compared with the Naive Bayes Model (NBM) [14], Random Decision Forests (RDF) [20], and Logistic regression analysis (GLM) [19]. The ROC curve is shown in Fig. 6, where the abscissa represents the false positive rate, and the ordinate represents the true positive rate. In the three times of learning, the ROC area exceeded 0.5, so it shows that the learning results for the four models are all effective. Among them, the ROC curve area of GRA-NBM is 0.694, the ROC curve area of GRA-RDF is 0.771, and the ROC curve area of GRA-LGM is 0.664, which are all inferior compared with GRA-BNs (0.986).

ROC curve.
Table 6 lists the other six indicators to evaluate GRA-BNs, All-BNs, NBM, RDF, and GLM. Among them, GRA-BNs has a precision of 1.000 and an accuracy of 0.958 as the optimal values, and All-BNs are the best values when the true positive rate reaches 1.000, the false positive rate reaches 0.667, and the recall rate reaches 1.000. In addition, the false positive rate of NBM reaches 0.667, which is also the optimal value for the false positive rate as All-BNs.
Calculation table of each evaluation index
As shown in Fig. 7, color blocks are used to visually show the pros and cons of the five learning sessions. Ideally, the higher the true positive rate to the false positive rate and the other four indicators, the better the learning result. In comparing the six indicators in this study, there is no low-level indicator in the learning results of GRA-BNs, while there is one low-level indicator in All-BNs, five low-level indicators for NBM, two low-level indicators for RDF, and two low-level indicators for GLM. Thus, in terms of low-level indicators, GRA-BNs is better.

Comparison chart of 6 indicators.
After the model is built, each node’s conditional probability is learned, and the dependence between the variables is quantitatively described. This paper takes the influence of subway opening on urban traffic indicators as the research objective, so the probability distribution between each of the 18 attributes and the subway opening and other attribute variables is studied.
It can be seen from Table 7 that before the opening of the subway, the value of per capita traffic network area growth is evenly distributed in the four sections without obvious trend characteristics. Still, after the subway is opened, the probability that the per capita traffic network area increases above 16.5875 m2 will reach 70%; it can be judged that the annual increase in the traffic network area per capita has increased significantly after the opening of the subway.
Conditional probability analysis results of per capita traffic network density increase number
Table 8 illustrates that before the subway opening, the annual increase in bus operating mileage was mainly distributed above 16.5875 m2. After the subway opening, the annual increase in bus operating mileage was mostly less than 10.7425 km. There is a clear downward trend in the growth of operating mileage.
Conditional probability analysis results of the increase of bus operating mileage
Seen as Table 9, the per capita traffic network density growth is constant and higher than 16.5875 m2 when the subway is not opened, and the road area growth rate is concentrated in [6.77%, 8.24%], while the growth rate mostly exceeds 8.24% after the subway is opened. Therefore, the opening of the subway stimulated the increase in the growth rate of the road area.
Conditional probability analysis results of road area rate growth rate
It can be seen from Table 10 that when the per capita traffic network density increase is constant and is lower than 13.665 km. When the subway is not opened, the infrastructure investment is concentrated at less than 2,372.245 million yuan. After the subway is opened, the infrastructure investment is more flexible, with a balanced distribution in each interval.
Conditions probability analysis results of infrastructure investment
Table 11 shows that when the per capita traffic network density increase is constant and is higher than 16.5875 km. When the subway is not opened, the increase in the number of taxis operating is concentrated between 133 and 266. After the subway is opened, the increase in the number of taxi operating vehicles is concentrated below 133. Therefore, the subway opening has a significant negative impact on the growth of the number of taxis in Nanchang.
Conditional probability analysis results of the increase in the number of taxi operating vehicles
It can be seen from Table 12 that under the condition that the increase in bus operating mileage remains the same and is higher than 26388.775 km. When the subway is not opened, the total number of bus passengers is mainly distributed over 47814. After the subway is opened, the total number of bus passengers is mainly distributed between 33055 and 47814 people. Therefore, after the opening of the subway, the passenger traffic volume of Nanchang has decreased.
Conditional Probability Analysis Results of Total Bus Passenger Transport
Table 13 demonstrates that when the road area rate growth rate remains unchanged and is higher than 8.24%. When the subway is not opened, the proportion of urban traffic land consumption is evenly distributed in each section, and there is no obvious law. After the subway is opened, the proportion of urban traffic land consumption is mainly distributed above 13.9%. Therefore, after the subway opening, the proportion of urban transportation land consumption has increased significantly.
Conditional probability analysis results of the proportion of urban traffic land consumption
Table 14 indicates that under the condition that the road area’s growth rate remains unchanged and is higher than 8.24%. When the subway is not opened, the road cleaning area is uniformly distributed in each section, and there is no obvious law. After the subway is opened, the road cleaning area is mainly distributed above 4235.75 m2. Therefore, after the opening of the subway, the road cleaning area has increased significantly.
Conditional probability analysis results of road cleaning area
It can be seen from Table 15 that under the condition that the infrastructure investment remains unchanged and is less than RMB 237,224.5 million, the average economic loss from traffic accidents before the opening of the subway is mainly distributed under RMB 63.695 million. After the opening of the subway, there is no obvious law in the distribution of average economic losses from traffic accidents.
Conditional probability analysis results of average economic loss from traffic accidents
Table 16 shows that the per capita traffic road network area growth rate is unchanged and higher than 16.5875 km2, and the road area growth rate is unchanged and higher than 8.24%. Before the subway is opened, there is no obvious law in the distribution of the number of buses per 10,000 people, and they are evenly distributed in each interval. After the subway is opened, the number of buses for 10,000 people is mainly distributed in 14.925/10,000 people. Therefore, after the opening of the subway, the number of buses per 10,000 people showed a downward trend.
Conditional probability analysis results of the number of bus standards with 10,000 people
It can be seen from Table 17 that under the condition that the road area growth rate is unchanged and higher than 8.24%, and the increase of bus operating mileage is unchanged and higher than 10594.325 km. Before the opening of the subway, there is no obvious law in the distribution of the citizen travel coefficient, and they are evenly distributed in each interval. After the subway is opened, the citizen travel coefficient is mainly distributed above 2.6325. Therefore, after the subway was opened, the travel coefficient of citizens increased.
Conditional probability analysis results of citizen travel coefficient
Table 18 indicates that when the increase in the number of taxi operating vehicles remains unchanged and is less than 133, and the infrastructure investment remains unchanged and remains between 411.49 million yuan and 5.86473 million yuan. Before the opening of the subway, there is no obvious law in the distribution of the primary electric energy, and they are evenly distributed in each interval. After the subway is opened, the proportion of primary energy is generally distributed above 7.1%. Therefore, after the opening of the subway, the proportion of primary electric energy has increased.
Conditional probability analysis results of primary electric energy condition
Table 19 demonstrates that when the per capita traffic road network area growth is constant and higher than 16.5875 km2 and the total number of bus passenger traffic is unchanged and distributed between 33,055 and 47,814; there will be 10,000 car accidents before the subway is opened. The rate distribution has no obvious regularity, and it is evenly distributed in each section. After the subway is opened and operated, the accident rate of 10,000 vehicles is mainly distributed below 4.60%. Therefore, the subway opening will help reduce the accident rate of 10,000 vehicles and improve urban traffic safety.
Conditional probability analysis results of an accident rate of 10,000 vehicles
It can be seen from Table 20 that when the growth of the number of taxis operating is constant and less than 133, and the total number of bus passengers is unchanged and distributed between 33,055 and 47,814, the total number of taxi passengers before the opening of the subway. There is no obvious regularity in traffic distribution, and it is evenly distributed in each section. After the subway is opened and operated, the total number of taxi passengers is mainly distributed over 18,058.83.
Conditional probability analysis results of total taxi passenger traffic
Table 21 shows that when the accident rate of 10,000 vehicles remains unchanged and less than 4.595%, and the total number of bus passengers remains unchanged and is distributed between 33,055 and 47,814, there is no obvious distribution of mortality among 10,000 vehicles before the subway is opened, and it is evenly distributed in each interval. After the subway is opened, the death rate of 10,000 vehicles is mainly distributed below 6.9475%. Therefore, the death rate of 10,000 vehicles after the opening of the subway has shown a downward trend, which is beneficial to the development of urban traffic safety.
Conditional probability analysis results of death rate of ten thousand vehicles
It can be seen from Table 22 that when the average economic loss of traffic accidents remains unchanged and is distributed between 7987 and 9604.5, before the opening of the subway, the death rate per 100 kilometers is mainly distributed above 0.445%, and after the opening of the subway, it is mainly distributed between 0.35% and 0.445%. Therefore, the opening of the subway is conducive to reducing the mortality rate of 100 kilometers of roads and is conducive to urban safety development.
Conditional probability analysis results of the death rate of 100 kilometers of road
Table 23 indicates that when the total number of taxi passengers is unchanged and higher than 18,058.825 and the total number of bus passengers is unchanged and distributed between 33,055 and 47,814, the distribution of the number of road traffic accidents before the opening of the subway. There is no obvious rule, and it is evenly distributed in each section. After the subway is opened, the number of road traffic accidents is mainly distributed below 2846.5. Therefore, the number of road traffic accidents after the subway opening shows a downward trend, which is beneficial to the development of urban traffic safety.
Conditional probability analysis results of road traffic accidents
This paper proposed a novel GRA-BNs method to analyze the impact of the subway operation on urban traffic. A three-layer framework is established, and 18 traffic indicators were comprehensively selected from 22 traffic indicators by considering three aspects: traffic accessibility, green traffic, and traffic security. To verify the proposed model, Bayesian Networks with full indicators analysis (All-BNs) and other three algorithms of the Naive Bayes Model (NBM), Random Decision Forests (RDF), and Logistic regression analysis (GLM) are employed to conduct the comparative analysis. The result shows that GRA-BNs is the most effective model to study the impact of the subway’s operation on urban traffic. In addition, the dependence relations between the subway and each index are analyzed by the conditional probability tables (CPTs), and some suggestions are given for the stakeholders. However, due to the objective circumstances with limited reference materials, there are still some limitations for this paper:
As the data collection in this article is mainly from the Jiangxi Statistical Yearbook and related traffic news reports on the Internet, the data’s completeness and comprehensiveness are lacking.
The preliminary consideration of urban traffic impact indicators is relatively one-sided. In terms of indicator selection, only accessibility, safety, and green transportation are considered. Still, many other factors have not been considered.
Since the Nanchang Metro opened in December 2015, the traffic data after the metro’s opening is relatively scarce, the analysis of the dependence between various indicators is relatively shallow, and many possible laws have not been unearthed.
Data availability
The data will be accessible upon request.
Conflicts of interest
The authors declare that they have no conflicts of interest.
Footnotes
Acknowledgments
This work was financially supported by the National Natural Science Foundation of China (51805169, 51708218, 52062014). This study is also supported by the Natural Science Foundation of Jiangxi Province 20202BABL212009.