
Abstract
Entropy has been used in many fields of computer vision, like image restoration, edge detection, pattern recognition, and as an evaluation method for image segmentation. The mean shift iterative algorithm (MSHi) was proposed in 2006, where the Shannon entropy was used as a stopping criterion. Later, it was introduced a theorem where this ensures, with a new stopping criterion, the convergence of the MSHi and determines what happens with the entropy at the limit of the segmentation process. The goal of this paper is carry out an analysis of the implications of this theorem and highlight the relation that were found from a physical point of view with image segmentation and the information theory. This last aspect being the novel part of this work.
Introduction
The concept of entropy is essential in the foundation of statistical physics. It first appeared in thermodynamics through the second law of thermodynamics [3]. The notion of entropy has been broadened by the advent of statistical mechanics and has been still further broadened by the later advent of information theory. In fact, in 1865 Rudolph Clausius presented the thermodynamic argument for the existence of entropy, and introduced the unit for entropy, but it did not become fashionable [4].
Later, Boltzmann (who was one of the most important physicists of the nineteenth century) proposed a statistical explanation of the second law of thermodynamics through the formula E = k log(W), which express the relationship between entropy E and the probability W. Boltzmann’s point of view had a great relevance to describe the precise relationship between the thermodynamical properties of macroscopic bodies with their microscopic constitution, and the role of probability in this relationship. However, Boltzmann equated the negative of his E-function with Claudius’s thermodynamic entropy and thus claimed to have proved the second law of thermodynamics via statistical mechanics; although this statement caused almost immediately after publication severe criticism of his contemporaries [5].
Nevertheless, nowadays in many texts is frequently spoken about Boltzmann entropy, and over a more general definition of Gibbs entropy, called “Generalized Boltzmann-Gibbs Entropy”, where Boltzmann entropy E is defined for a macroscopic state, whereas Gibbs entropy is defined over a statistical ensemble. This last generalized definition can be reduced to the form of Shannon entropy [6].
Indeed, in 1949 Claude Shannon introduced a formalism designed to solve certain specific technological problems in communication engineering [7], and redefined the entropy concept of Boltzmann-Gibbs as a measure of uncertainty regarding the information content of a system. He proposed a new revolutionary probabilistic way of thinking about communication and defined an expression for measuring quantitatively the amount of information produced by a process [8].
The Shannon entropy was a new concept in the field of information theory, and in computer vision has been used mainly in edge detection, in image restoration, and as an evaluation method for some image segmentation algorithms [9, 10].
From the point of view of digital image processing, the entropy of an image is defined as:
Within a uniform region, entropy reaches the minimum value. Theoretically speaking, the probability of occurrence of the gray-level value into a uniform region is always one. In practice, when one works with real images the entropy value does not reach, in general, the zero value. This is due to the images existent noise. Therefore, if we consider entropy as a measure of the disorder within a system (image), it could be used as a good stopping criterion in image segmentation.
The mean shift iterative algorithm (MSHi) was proposed by Rodríguez and Suarez in 2006 [1], and it has been used in many segmentation works, where we took as stopping criterion the Shannon entropy [11–14]. This first version of the MSHi algorithm stopped when the relative rate of change of entropy from one iteration to the next falls below a given threshold. In 2013, Garcés et al. defined a new stopping criterion based on the entropy of the difference between two images [15], and later they formalized this ideas as a new metrics of similarity between images (called, Natural Entropy Distance (NED)) [16].
In 2017, Rodríguez et al. introduced a theorem that ensures the convergence of the MSHi with NED as stopping criterion [2], and determined the behavior of the entropy at the limit of the segmentation process. So, the goal of this paper is carry out an analysis of the implications of this theorem and highlight the concatenation that were found from a physical point of view with image segmentation and information theory. This last aspect being the novel part of this work.
The remainder of the paper is as follows. In Section 2, a retrospective review about entropy and some theoretical aspects are given. In section 3, we carry out a review of the use of entropy in computer vision. Section 4 presents the mean shift iterative algorithm and the concatenation that were found from a physical point of view with image segmentation and information theory. In Section 5 provides some further topics for future works. Finally, in Section 6 the conclusions are given.
Although in many textbooks there has been a big dispute on that Boltzmann never presented explicitly the formula E = k log(W), the truth is that many works of him exemplifies several of Boltzmann’s most important contributions to modern physics. In effect, the Boltzmann distribution also has passed almost unchanged into the quantum world, and in [17] was expressed that: even without its connection to entropy, the Boltzmann distribution is of remarkably wide ranging importance. His works being a key step in developing the fully probabilistic basis of entropy and the second law of thermodynamics.
In order to avoid all the philosophical discussion around the Boltzmann entropy, and to enter into the analysis of the Shannon entropy, the main goal of this work, we will briefly refer to the generalized Boltzmann-Gibbs entropy, which can be reduced to the form of Shannon entropy [6]. Indeed, the Boltzmann-Gibbs entropy is given by the following definition.
where,
The expression (4) is analogous to the coarse density of microstates defined over the phase space of the usual definition of Gibbs entropy [6]. Then, the Boltzmann-Gibbs entropy is defined as,
The expression (5) measures the total uncertainty or disorder associated with the microscopic and macroscopic states of the system, and it is, therefore, an example of total entropy introduced in information theory [6]. This definition is very useful for the case of image analysis since a simplest image (segmented) has minor disorder grade, which mean that the existent pixels have minor uncertainty.
In the case of a classical system, the Boltzmann-Gibbs entropy is given by the following definition.
The expression (6) represents the total number of macrostates or complexions compatible with the constraints the system is subjected. In the case of images, we might consider the macrostate like the image, while that microscopic states being the classes, which have a certain correlation between the pixels (constraints).
For large N
i
, we can reduce the Boltzmann-Gibbs entropy, given by expression (6), to the form of Shannon entropy [6],
Nowadays, it is well-known that Shannon entropy is the key concept of information theory [7], which has found wide applications in different fields of science and technology [18], and provides a measure of uncertainty associated with the probability distribution. From a computer vision point of view the Shannon entropy has been one of the most used, due to the strong relationship that exists between information theory and digital image processing. From the physical point of view, we also established a good link, especially with images segmentation.
Returning to information theory, motivated with the possibility to obtain an efficient transmission of information over a noisy communication channel, Shannon redefined the entropy concept of Boltzmann-Gibbs as a measure of uncertainty regarding the information content of a system. He introduced a new probabilistic way of seeing communication and defined an expression for measuring quantitatively the amount of information produced by a process, which is given by expression (6). Note that with the Shannon entropy function is possible to proof that: E (P) is maximal for p1 = p2 = •• • = p
n
= 1N, where N is the total number of events. E (P) = 0 just when one p
i
is “1” and the rest are “0” Logarithm is to base 2: ln 2 (x) = y ⇒ x = 2
y
(for example, 8 bit/pixel ⇒28 gray levels).
In information theory what we exposed has a great importance; since this means, at the message level, it’s possible to encode them using only K • E (P) bits; that is, there are only 2K•E(P) typical messages with K letters. Therefore, E (P) represents the maximum amount of letters that can be compressed as normal messages drawn from a given set [7]. According to Shannon this have a good implication since, “if one is trying to use a noise channel to send a message, then the conditional entropy specifies the number of bits per letter that would need to be sent by an auxiliary noiseless channel in order to correct all the errors due to noise”.
The expressed in previous paragraphs have a strong relationship with image segmentation, and with the theorem presented in [2]. For example, if we carry out an analogy between image segmentation and information theory, we can consider the original image as the transmitter and the result of segmentation as the receiver. It is known that the receiver decreases in entropy (but less than the increase at the transmitter) [21], and the same happen with the entropy in the segmented image and which it will be a corollary of the theorem presented in [2].
Many authors agree that the visualization process can be treated as an information channel; that is, a visual communication channel that attempts to communicate the information in the source data to the destination, the viewer [22–24]. For example, many time the scenes, for a better interpretation, need to be transformed by a sequence of steps (algorithms) such as filtering, elimination of noise and segmentation (among other) until its projection. These steps, we can analyze from two point of view, from a physical point of view as a problem of energy conservation (trying that algorithm causes in each step the lowest possible loss of energy), or from the point of view of information theory (preserving the maximum amount of information from the input and generate the output for the next stage of flow [22]). When information loss is inevitable, such as happen in image restoration or in the projecting 3D data to 2D images, it is necessary to have a special care in the selection of the appropriate parameters to preserve as much information (energy) as possible, otherwise the processing result will be disastrous.
The function that connects the relation between the energy and the information is the entropy. Indeed, without the intention of studying in depth very much this matter, let’s take a look at the fundamental equation of thermodynamics [25],
On the other hand, Fig. 1 shows an analogy between message transmission and data visualization [22].

Schema that represents a transmitter-receiver device. (a) Message transmission, (b) data visualization.
To date, in computer vision (CV) entropy has been widely used. Only some examples, in [8] was carried out a deep review of the use of entropy for different applications, and was seen that in CV had been used majorly in image thresholding, which often represents a first step in image analysis. In the mentioned reference was also evidenced that maximum entropy has been utilized in tackling of various real life problems; for example, in radio astronomical interferometry; in spectroscopy; in detecting occurrence of abnormal activities in a video stream in accidents in an escalator, where the frames resulting in a higher error function will have higher entropy; in image reconstruction for positron image tomography, among other many examples.
In [22], the Shannon entropy was used for modeling a scientific data set as a discrete random variable where each data point in the domain carries a value as the outcome. Here, the entropy function E (P) indicated how much information the data set contains. If the distribution in the histogram was uniform across all bins, it was difficult to predict the value of a voxel, due to that the entropy of the data set was high. On the contrary, when the histogram distribution was highly skewed into a few bins, it was easy to guess the value of a voxel, entropy of the data set being low.
In [26] was proposed a new entropy-based evaluation method, taking into consideration that a good segmentation algorithm should maximize the uniformity of pixels within each segmented region, and minimize the uniformity across the regions. In the proposed method, the entropy for region j was defined as,
From an information theory point of view,
The mean shift is a non-parametric procedure that has demonstrated to be an extremely versatile tool for feature analysis. It can provide reliable solutions for many computer vision tasks [28]. The mean shift filtering (MSh) was proposed in 1975 by Fukunaga and Hostetler [29]. It was largely forgotten until Cheng's paper rekindled interest in it [30]. Unsupervised segmentation by means of the MSh carries out two steps; a first step is a smoothing filter, and a second is to carry out the segmentation [28].
On the other hand, Rodríguez and Suarez [32] proposed the mean shift iterative algorithm (MSHi) in 2006, and the same was employed to carry out image segmentation. The novelty of the proposed algorithm was to use the Shannon entropy as a stopping criterion. The choice of the Shannon entropy as a measure of goodness deserved several observations, which were detailed in [2, 11– 14].
However, it is very important to point out that the MSh by itself is a filtering process. For this reason, in [28] for the segmentation process two steps were proposed; a first step was to apply the MSh and the other, to carry out segmentation. On the other hand, in [28] it was also expressed that the segmentation step does not add a significant overhead to the filtering process. This issue was our principal motivation, i.e., to arrive to the segmented image from the filtering process without an additional step. Which was the problem then? How to stop? The answer to that question was to use the entropy as a stopping criterion [1]. That was the origin of the MSHi. Therefore, the MSh is a filtering process, while the MSHi is a segmentation algorithm that uses, by default, the MSh in the iteration process.
As we expressed in the introduction, in the first version of the MSHi we used as stopping criterion the difference of entropy (called old criterion) between the first and the next iteration [1]; and later, Garc
So alone an example, Fig. 2 shows two different images; when using the old criterion, we obtain that the difference of entropy is similar to zero, which is not correct. With the new criterion(E (/Ik+1 - I k /)), the spatial information was taken in consideration (and implicitly the correlation among the pixels), and a major stability was obtained. Therefore, in real conditions is not correct to consider that the pixels are not correlated; that is, as independent random variables. This is one of the problems that have the classical threshold operators, to assume that the pixels are statistically independent [31].

Dissimilar images with entropy = 1.
All this physical analysis was mathematically corroborated in [16] by using ring theory. In Garc
The implication of Theorem 1 is important since in Fig. 2 images are weakly equivalents, but they are not strongly equivalents, which means that A ≍ B ≱ A ≅ B. Therefore, one should understand that two images strongly equivalents have the same histogram of frequency, except for a uniform shift of all gray levels.
Note, that the mathematically expressed has a close relation with the physics of digital image, since the strong equivalence takes into consideration the spatial relationship among pixels (correlation), and therefore this assumes that exists statistical dependency among them. In addition, we want to point out that this dependency among pixels is not necessarily the same in all image. So, Garc
The Theorem 1 establishes that the old and new criterions are very different, having the new criterion better properties and being more suitable for computer vision tasks. Moreover, Rodriguez et al. proved the following theorem that has interesting implications [2]. These implications (corollaries) being the most outstanding results in this paper.
A first implication of Theorem 2 is the following corollary.
From an information theory point of view, when considering the Shannon entropy a measure of the disorder of a macrostate (for example, an image), will help that when the MSHi algorithm is used, within each region the entropy diminishes in measure that is more homogenous. On the other hand, from the physical or of the second law of thermodynamics point of view, it is known that the entropy is a state function, E (B) - E (A) is independent of the path, regardless whether it is reversible or irreversible. For an irreversible path, the entropy of the environment changes, whereas for a reversible one it does not. And, in the case of image segmentation, it can be considered as an irreversible process.
Returning to information theory, it is known that in a transmission channel the receiver decreases in entropy with regard to the transmitter [21], what happens with the segmentation process (Corollary 1). In short, by using the MSHi algorithm for image segmentation, Theorem 2 guarantees that Shannon’s theorem it is fulfilled and the second law of thermodynamics too. On the other hand, image segmentation can be considered as an optimization process with not exact solution. Therefore, many times the important, given a segmentation problem, it is not finding the exact solution, but the closest to the optimal, which when using the MSHi algorithm can be guaranteed.
Note that Theorem 2 ensures convergence whatever the chosen threshold; therefore, we will have a finer or coarser segmentation depending on the selected value of the stopping threshold. In addition, from Theorem 2 is possible to establish the following corollary.
Observe that Theorem 2 ensures that at the limit the entropy will be zero, then p i = 1 what it implies only a gray level.
In short, from an information theory point of view -p
i
ln(p
i
) means the amount of information associated to pixel x
i
(where,
What just expressed in the above paragraph is of much importance and it is in line with the state of the art for the quantitative analysis of a segmentation process. It is known the quantity of existing methods for carrying out the quantitative validation of a segmentation method, and in many of them the procedures are very similar [33]. Our proposal could be a different way to validate and compare segmentation strategies. This will be experienced in future works.
The experimental results and simulations that will be presented were carried out with the standard images shown in Fig. 3.

Standard images [34]. (a) Cosmonaut, (b) Bird, (c) Barbara, (d).
Figure 4 shows three examples of the performance of the MSHi algorithm. In the “

The “
The graphics in Fig. 4 show that entropy decreases in each one of the iterations. It is interesting to observe that in some iterations an increase of the entropy is noticed, but starting from this iteration the entropy falls quickly, and at the limit the entropy will be zero. Figure 4 is a graphic way of seeing the Corollary 1. To note that in the first iteration entropy in much greater than in subsequent iterations; that is, segmentation can be seen as a process of simplifying the original image, since the number of gray levels decreases in the process of homogenization.
Figure 5 presents a simulation of a segmentation process as the image becomes simpler (more homogeneous areas).
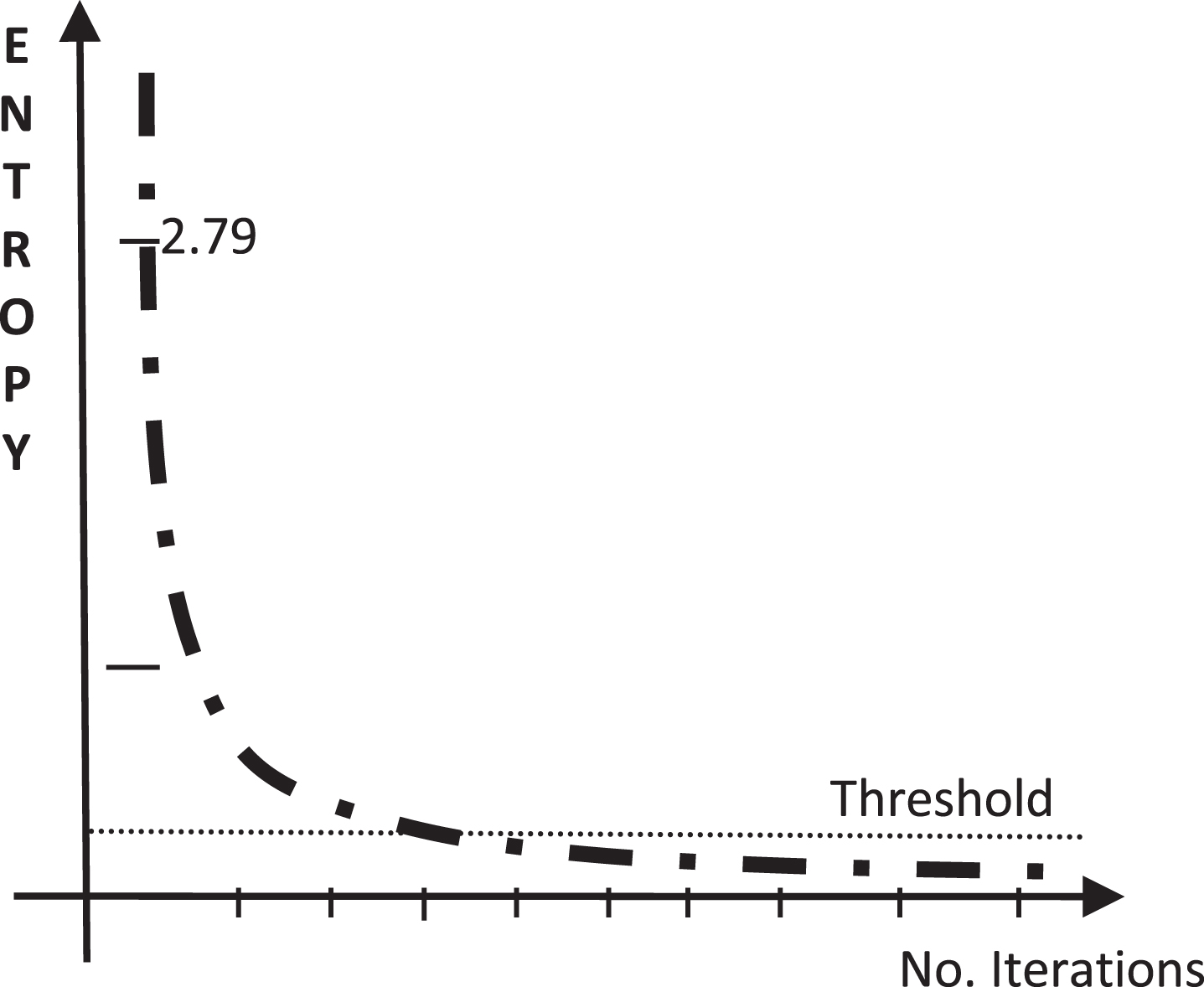
Simulation of decrease of entropy as the image becomes simpler.
The segmentation of the Astro’s image for different values of the stopping threshold is shown in Fig. 6 (simulation of Corollary 2). One can appreciate that the number of iterations increased in an abrupt way when the stopping threshold diminished from 0.001 to 0.0001, and one can also see that the segmentation is going to be refined (the homogenization degree increased in the segmented image).

(a) Segmentation for stopping threshold (st)=0.1, 2 iterations, (b) Segmentation for st = 0.05, 2 iterations, (c) Segmentation for st = 0.01, 4 iterations, (d) Segmentation for st = 0.005, 5 iterations, (e) Segmentation for st = 0.001, 7 iterations, (f) Segmentation for st = 0.0001, 60 iterations.
A simulation for the case of Corollary 3 appear in Fig. 7. Observe that Theorem 2 ensures that at the limit the entropy will be zero, then p i = 1, what it implies only a gray level; that is, a completely homogeneous image. Therefore, el hitogram will have an only bin shifted to the gray level x i
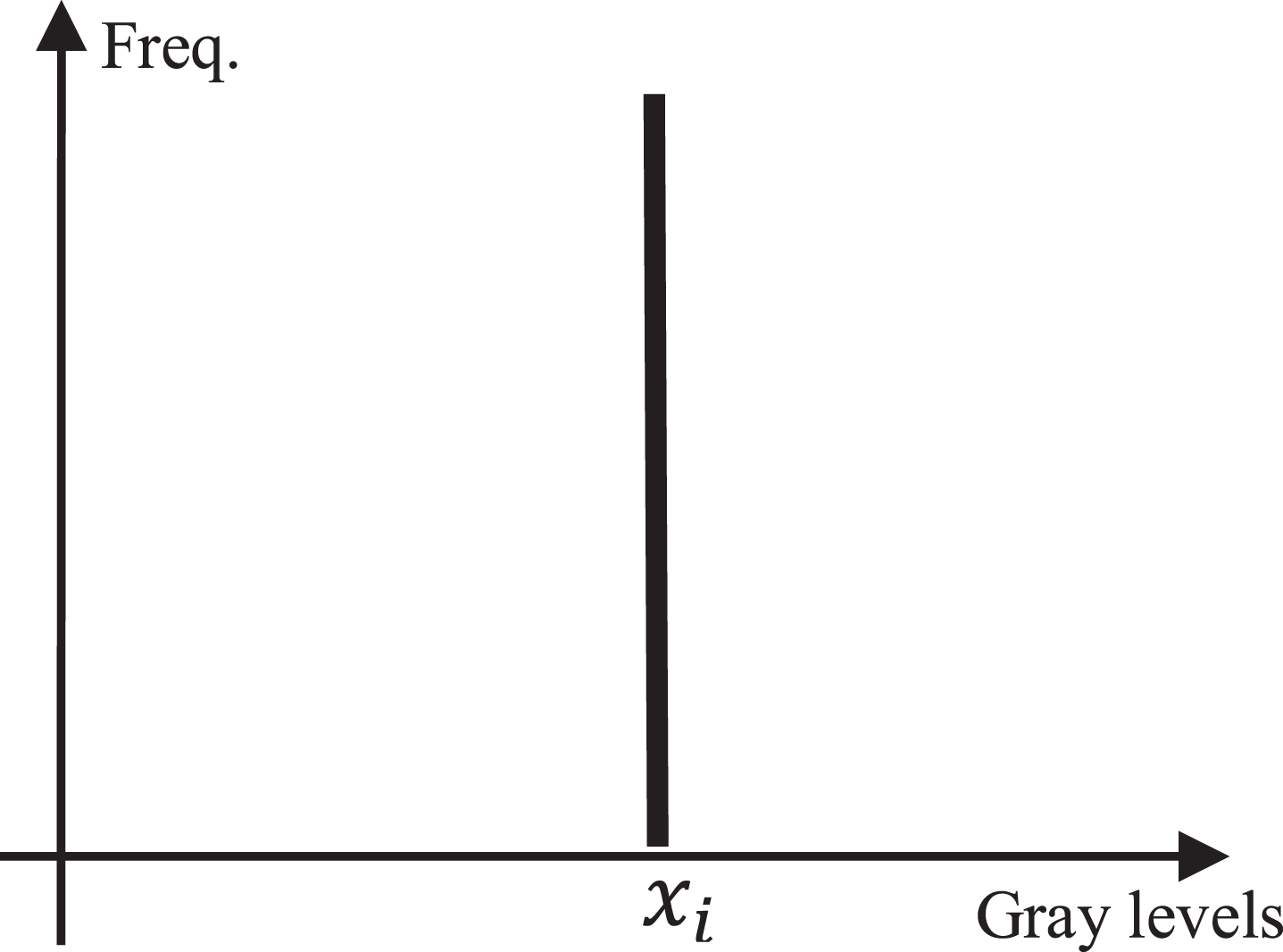
Simulation of a completely homogeneous image (only a gray level).
In this paper, we carried out a retrospective review of entropy functions since its emergence, and we did a broad theoretical analysis from point of view of the information theory and the physics, deepening in the Shannon entropy. We evidenced that majorly, entropy has been used for the purpose of image thresholding. We introduced and discussed about the MSHi algorithm, where the Shannon entropy was used as a stopping criterion, and where we proposed a theorem that ensures the convergence. Finally, we carried out a wide analysis of that theorem and its implications from a physical point of view and its relationship with image segmentation. We propose some further topics for future works.
Some further topics for future works
What written in the final paragraph of section IV can serve as base for the creation of another way of evaluating quantitatively the quality of a segmentation process or of several. This issue will be matter of next researches. In physics, the notion of entropy is typically regarded as a measure of the degree of disorder and the tendency of physical systems to become less organized. Then, image segmentation violates this principle? The answer to this question also could give step to another criterion of quantitative evaluation for image segmentation, which we will analyze in next works. We will propose an experimental work with several of the theoretical aspects considered in this paper.
Footnotes
Acknowledgments
The authors would like to thank the Instituto Politécnico Nacional for the support to carry out this research. H. Sossa appreciates the economic support received from the SIP-IPN and CONACYT under grants 20170693, 20180730, 20190007 and 65 (Frontiers of Science), respectively, to conduct this investigation.
Yasel Garcés received a postdoctoral scholarship from the “Dirección General de Asuntos del Personal Académico de la UNAM” (DGAPA) in the “Instituto de Biotecnología” (IBt-UNAM). Esley Torres received scholarships from CONACYT with grant 596179.
Appendix A
Let the following expression,
But,
For large N
i
the Stirling’s approximation establishes that,
but the last term in expression (A.4) is usually neglected so that a working approximation is:
Therefore, when substituting expression (A.5) in (A.3), we obtain,
where