
Abstract
For the uncertain problem that between-cluster distance influences clustering in the soft subspace clustering (SSC) process, a novel clustering technique called adaptive soft subspace clustering (ASSC) is proposed by employing both within-cluster and between-cluster information. First, a new objective function is constructed by minimizing the within-cluster compactness and maximizing the between-cluster distance based on the framework of SSC algorithm. Based on this objective function, a new way of computing clusters’ feature weights, centers and membership is then derived by using Lagrange multiplier method. The uniqueness of ASSC is that the objective function does not increase any control parameters, which can avoid the sensitivity of clustering results to the initial points of the control parameters. The properties of this algorithm are investigated and the performance is evaluated experimentally using UCI datasets. The contrastive experiment results demonstrate that the accuracy and the stability of the proposed algorithm outperform the four existing clustering algorithms, i.e., ESSC, EWKM, FWKM and CIM_QPSO_SSC.
Keywords
Introduction
Clustering is an algorithm which divides the dataset without labels into several meaningful categories according to the different similarity degree. A cluster is a homogeneous group of entities. While entities in the same cluster are supposed to be homogeneous, according to some notion of similarity, entities in different clusters are expected to be heterogeneous [1, 31], i.e., by minimizing the between-cluster similarity while maximizing the within-cluster similarity [2, 28]. Driver et al. first applied the idea of cluster analysis to the field of anthropology, Robert Tryon introduced it to the psychology [4], Ayub, et al. Modeling user rating preference behavior to improve the performance of the collaborative filtering based recommender systems [32] and Qazi et al. A hybrid technique for speech segregation and classification using a sophisticated deep neural network [33]. In order to solve practical problems, clustering has been developed simultaneously with many classic algorithms [5]. Those algorithms have been applied to various fields such as electronic commerce, internet, bioinformatics as well as financial transactions [6, 7]. Among the studies algorithms, for datasets with different clusters correlating to different subsets of features, the soft subspace clustering (SSC, for short) is a more suitable approach since different vectors of feature weights are assigned to each cluster.
According to the ways of soft subspace weighting, the SSC algorithm which has been widely used in scientific research and industrial applications can be divided into two categories, namely, fuzzy weight [8] and entropy weight [9, 30] for SSC. For the former, the algorithm assign a fuzzy weight w jk β to the jth feature of the kth cluster and adjust the feature weights for each cluster automatically during the clustering process, while for the latter, the algorithms utilize entropy to control the feature weights in each cluster. Entropy is a measure based on local similarity and has certain advantages for measuring the similarity between sample points in the same subspace. The membership degree in entropy weight is a hard partition matrix. Although many SSC algorithms have been developed for different application areas, there are still rooms to further improve the performance and many researchers have proposed different remarkable methods. Wang et al. proposed a soft subspace algorithm based on fuzzy partition index and applied the concept of partition index to the existing SSC algorithm [10]. Zhu et al. proposed the online SSC algorithm combined online learning strategy with SSC to solve large-scale high-dimensional data and data streams problems [3]. Wang et al. proposed an enhanced SSC algorithm through hybrid dissimilarity. The optimization function in the algorithm was designed based on the goal of minimizing the hybrid dissimilarity and maximizing the weighted entropy, eventually improve the performance of SSC [11].
However, one of the main weaknesses of SSC is that the clustering results can be satisfactory for some datasets while others are not so desirable. This may be because the study of distance between classes is not deep enough, so it is necessary to adaptively evaluate the relationship between cluster and cluster distance measure. Recent studies have shown that the introduction of between-cluster separation can effectively improve the clustering performance. Representative approaches include alternating optimization approach [12], adaptive metric learning for self-organizing incremental neural network [13] and entropy weighting fuzzy clustering in a composite kernel space (CKS, for short) for kernel space and feature space [14]. However, all these clustering algorithms frequently falls into local optimum during searching clustering center point due to the improper selection of initial points, which leads to a number of clustering mergers and thus results in the degradation of the clustering performance.
In this work, the above problems will be investigated by integrating within-cluster compactness and between-cluster separation into the framework of SSC and a novel adaptive soft subspace clustering algorithm named ASSC will be proposed accordingly. The first characteristic of ASSC is that the new objective function does not increase any control parameters, which can avoid the sensitivity of clustering results to the initial points of the control parameters and thus the computational efficiency could be improved. The second is that the proposed algorithm employs a new way of computing clusters’ feature weights, centers and membership degree by Lagrange multiplier method. For easy reference and to enhance the readability of the paper, the major notations used in this paper are summarized in Table 1.
Notations used in this paper
Notations used in this paper
The remainder of this paper is organized as follows: Section 2 presents related work and background. Section 3 introduces the ASSC algorithm. In Section 4, comparative experimental results on real dataset show the superiority of ASSC. Finally, in Section 5, we draw conclusions and describe possible extensions of this work.
Let X ={ x
ij
, i = 1, 2, …, N ; j = 1, 2, …, M } be a dataset with N entities (i.e., objects) in M variables (i.e., features). The expression of
The soft subspace clustering algorithm
The SSC algorithm is a clustering algorithm for local search on a related dimension. The SSC seeks the important features by setting the feature weights, thereby reducing the effect of irrelevant features. The SSC algorithm can identify the feature subset of each cluster and find the corresponding clusters of different characteristic subsets. Its basic thought could be described as a problem of minimum value of the objective function [10], as follows:
The first term in Equation (1) is interpreted as the total weight distance between each sample point x
i
, i = 1, 2, …, N, and the cluster center point v
k
, k = 1, 2, . . , C and the second item
The cluster results are affected by within-cluster compactness and between-cluster separation. Some scholars had studied the subspace clustering algorithms which integrate within-cluster and between-cluster information. The enhanced soft subspace clustering (ESSC, for short) [2, 26] algorithm minimizes the within-cluster distance feature weight entropy and meanwhile maximizes the between-cluster distance. It belongs to soft membership degree matrix, divided into numerical values between 0 and 1. It modifies the division of membership to better fit each sample point and effectively reduces the influence of close cluster centers on global central feature. Xia et al. proposed a multi-objective evolutionary SSC algorithm in 2013 [15], while optimizing two objective functions, the optimal solution and the optimal number of clustering were obtained by using the projection similarity criterion. Qiu et al. proposed a SSC algorithm based on adaption of between-cluster distance in 2016 [16], a new way of computing clusters’ center and feature weight was derived, which overcomes the sensitive defect of input parameters and obtains better clustering results. Xu et al. proposed a SSC algorithm based on quantum-behaved particle swarm optimization (SSC_QPSO, for short) [17, 34]. The algorithm solved global optimal clustering centers in the subspace by the advantages of global optimal algorithm of QPSO, the corresponding objective function of which can be formulated as
However, the influence of the between-cluster separation of SSC_QPSO algorithm on clustering results is not specified. In the process of the iteration in Equation (2), the within-cluster compactness and between-cluster separation are calculated in the same way - the objective function is based on Euclidean distance and still has a problem of dimensionality curse in higher dimensions and thus results in the failure of Euclidean distance metric function.
Xu et al. proposed CIM_QPSO_SSC (Correntropy Induced Metric is abbreviated to CIM) by modifying the metric in SSC_QPSO [18, 29]. The corresponding objective function can be written as
CIM_QPSO_SSC has demonstrated better performance than classical clustering algorithms on some popular datasets [10]. But given a specific learning task, it is difficult to select appropriate initial values for the control parameters (m, σ, γ, η). Incorrect choices can seriously affect the performance of CIM_QPSO_SSC. At the same time, CIM_QPSO_SSC has some shortcoming of QPSO because of the introduction of QPSO algorithm, i.e., the time efficiency is sacrificed due to the process of particle renewal.
As described in [2], in the weighting subspace, the fuzzy weighting within-cluster compactness and the fuzzy weighting between-cluster separation of a dataset containing C clusters can be expressed as follows:
Where η ⩾ 0. Note that, when η = 0, Equation (4) was only considered to develop the corresponding algorithm.
The form of different objective functions and the value of control parameters have significant influence on the performance of the algorithm. Therefore, a novel algorithm based on SSC is developed by integrating within-cluster compactness and between-cluster separation. Compared with the classic algorithm, the uniqueness of our work is that a new objective function is designed does not increase any control parameters. We decided to extend ASSC by addressing the three major theorems – updating the membership degree matrix, updating the cluster center matrix and updating the feature weight matrix.
Design of objective function
ASSC is proposed based on the framework of SSC. The objective function J is given by
The main idea of ASSC is to minimize the sum of the within-cluster compactness and the between-cluster distance in Equation (5). It contains two terms - the within-cluster compactness and the between-cluster separation. The ASSC algorithm is extended to the corresponding non-Euclidean distance for measuring distances, i.e.,k
γ
= - □ γ
j
× (x
ij
- v
kj
) 2). The function maps to the Gaussian kernel space based on the original Euclidean distance metric’s optimization function. The parameter σ
j
can be estimated by using the inverse of the variance of all samples X
i
= (x1j, x2j, …, x
Nj
) in the j-th dimension, i.e.,
Essentially, the minimization of the objective function in Equation (5) with the constraints is a class of constrained non-Euclidean distance problems. ASSC can minimize Equation (5) by iteratively solving the three groups of variables, namely,
where D ik = (1 - exp (- γ j (x ij - v kj ) 2)) -1/g j (v kj - v oj ) 2, D il = (1 - exp (- γ j (x ij - v lj ) 2)) -1/γ j (v lj - v oj ) 2. In Equation (6), u ik = 1 means that the ith data x i is assigned to the kth cluster v k and otherwise vice versa.
minimizing Equation (5) is equivalent to maximizing
Denote the number of data points in the k-cluster as n
k
, Equation (8) turns into
We differentiate Equation (9) with respect to all x ij and set the derivative to zero, then we can obtain the following equation
which is exactly Equation (7). Equation (10) is a nonlinear equation with respect to v kj , it can be solved using the fixed point iteration method [10]. Denote
then by the fixed point iteration method, we can obtain the sequence
The minimisation of Equation (5) is subject to ∑j=1
M
w
kj
= 1fork = 1, 2, . . . , C and a crisp clustering where any given
It one can be easily derived that w kj = λ/2D kj . By summing these expressions over all M, one arrives at equation ∑j=1 M λ/2D kj = 1 and thus λ = ∑j=1 M 2D kj . This leads to Equation (13) we want.
The ASSC algorithm is summarized in Table 2. Before running an algorithm, the dataset is pre-processed so that every feature is standardized by subtracting its average from the data entries and dividing the result by half the feature’s range, the difference between the maximum and minimum divided by 2 [20].
The pseudo-code of the ASSC algorithm
The pseudo-code of the ASSC algorithm
Observing Equation (7), we can know that x ij , which is the j-th feature of data point x i , is assigned a weigh exp (σ j (x ij - v kj ) 2). Since exp (- γ j (x ij - v kj ) 2) →0 as γ j → 0, 1/γ j → ∞. When two of the same order of infinity are divided, the limit is constant.
The objective function Equation (5) is minimized interactively according to three theorems. Suppose in the t iteration where partial minimization is achieved, the following relationship holds
It implies that J(
The computational complexity of ASSC algorithm per iteration is
Experiments and analysis
The proposed ASSC algorithm is evaluated with a large number of experiments on real datasets for different complexities. The clustering results were compared with those obtained by ESSC [2], EWKM [9] (entropy weighting k-Means is abbreviated to EWKM), FWKM [25, 31] (feature weighting k-Means is abbreviated to FWKM) and CIM_QPSO_SSC [18] algorithms. Different parameters are used in these five algorithms and their settings are tabulated in Table 4. All the experiments were implemented on a computer with an Intel(R) Core(TM) i3-4170 CPU, Windows7 and Matlab 13.0.
Datasets selection
The proposed method was evaluated with experiments conducted using datasets obtained from the UCI repository [21]. The datasets are described with a data matrix of “objects × features ”. The details are shown in Table 3.
Details of the UCI datasets
Details of the UCI datasets
Before the experiments, all the datasets were normalized - the three datasets of Wine, Wall and Sonar were dimensional normalized and the datasets of Glass and Ionosphere were normalized by sample points. Dimension normalization is the sample point x
ij
divided by the square sum of all the sample points in the dimension, i.e.,
Two metrics, the rand index (RI) [22] and the normalized mutual information (NMI) [23], are used for evaluating the performance of the proposed ASSC algorithm. RI is defined as
where C is number of clusters, N is number of samples, d ik is the number of data objects occurring in both class ith and cluster kth, d i is the number of samples that have the ith label, d k is the number of samples that belong to the kth cluster. Apparently NMI is equal to 1 when the clustering results perfectly match the external category labels, and close to 0 for random partitioning.
In the experiments, the maximum iteration number of the five clustering algorithms is set to 500 and the threshold value of iterative stop is set to 10-5. The parameters of these algorithms and their settings are tabulated in Table 4.
Algorithms and the setting of the parameters in the experiments
Algorithms and the setting of the parameters in the experiments
In the experiments, for each UCI datasets, the clustering of each algorithm was executed repeatedly 10 times with different initial partitions under a fixed parameter setting. The best clustering results expressed in terms of the means and standard deviations of the RI and NMI values are tabulated in Tables 5 and 6 respectively. The results of the four comparison algorithms refer to the results in Ref. [24].
Some interesting results can be observed in Table 5 when considering the results of RI metric. ASSC produced higher values of mean than ESSC for 3 of the 5 datasets we considered. CIM_QPSO_SSC algorithm did even better, providing higher values of mean than ESSC for 5 of the 5 datasets. The performance of ASSC is slightly lower than CIM_QPSO_SSC in the Wall and Sonar datasets, with the difference of 0.0125 and 0.0257 in the corresponding datasets respectively. This indicates that the ASSC algorithm has strong robustness. In terms of standard deviations, the ASSC algorithm in 5 datasets is better than the other four algorithms. We believe that the introduction of between-cluster distance metric was the key factor to ensure the stability of the cluster results.
Best results obtained on UCI dataset with RI as metric
Best results obtained on UCI dataset with RI as metric
Best results obtained on UCI dataset with NMI as metric
When considering the results of NMI metric, it can be observed from Table 6 that ASSC produced higher values of mean than the other four algorithms for 4 of the 5 datasets. In terms of standard deviations the algorithms took to complete, the ASSC algorithm in 5 datasets is better than the other four algorithms.
Further comprehensive comparison of the two categories of evaluation indicators in Tables 5 and 6 can find that the ASSC algorithm is better than the other four algorithms in the accuracy and the stability of clustering results. The ASSC algorithm has not obtained the optimal RI and NMI evaluation indexes in all the datasets. This indicates that there is no single algorithm that is always superior to the others for all datasets. By comparing Tables 5 and 6, it is further noticed that the best clustering performance as indicated by RI is not always consistent with that indicated by NMI, i.e., an algorithm showing good clustering performance with a high RI value may not have a high NMI value. Therefore, it is necessary to evaluate the performance of a clustering algorithm with different metrics. The averages of the best clustering results obtained from these five algorithms are plotted in Fig. 1.
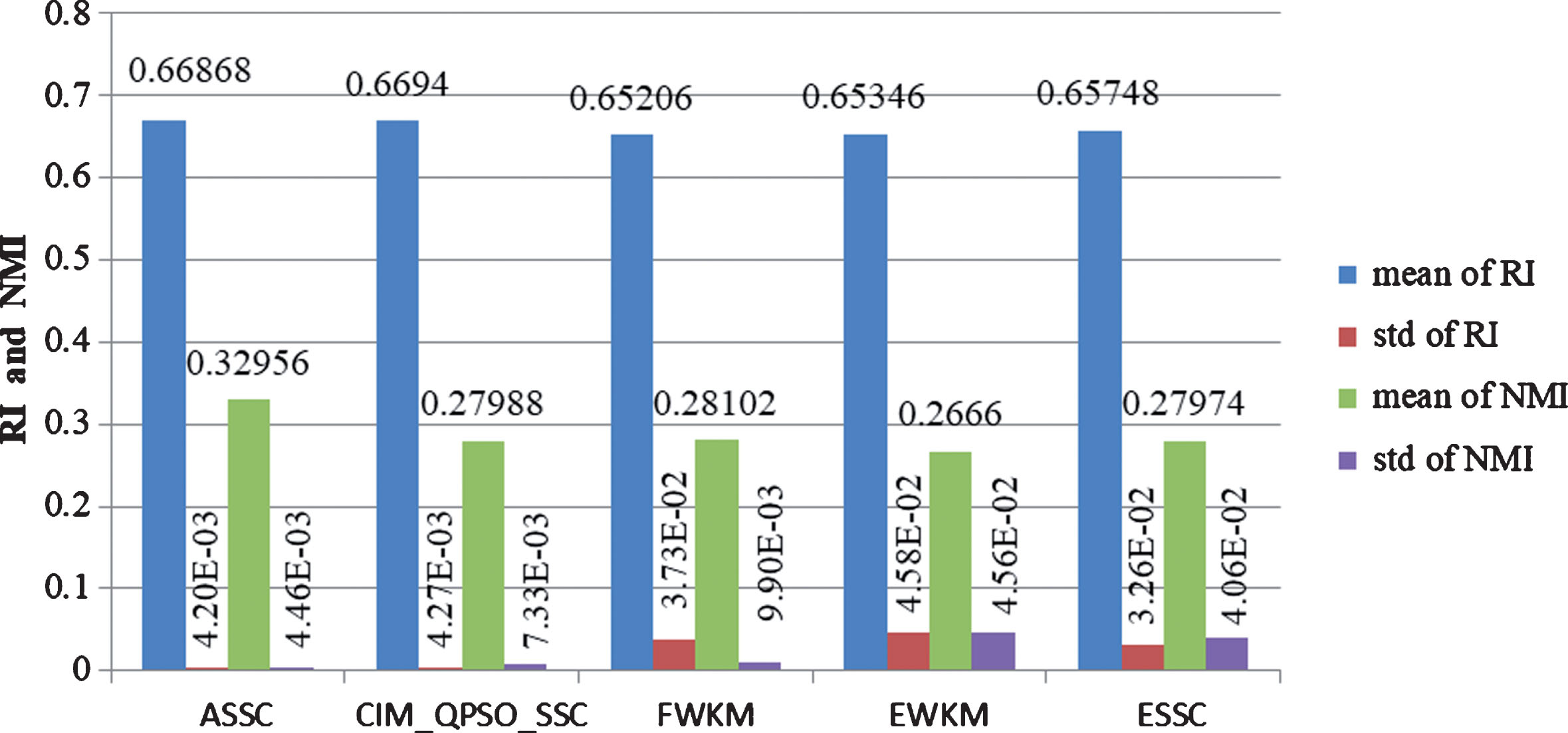
The averages of clustering results obtained for the UCI datasets.
Figure 1 shows the average results of the five algorithms evaluated in these five UCI datasets. It can be seen from the histogram that the RI metric of the CIM_QPSO_SSC algorithm is optimal, and the RI value are 0.6694 and 0.66868 respectively with CIM_QPSO_SSC and ASSC algorithms, the difference between them is very small. The comparison of the NMI metric shows that the ASSC algorithm has the best performance in these five algorithms. It demonstrates that once again the proposed algorithm has better clustering accuracy and stability, as well as adaptive learning capabilities.
The reason for the better clustering results of ASSC algorithm in most datasets is: (i) a novel objective function integrating the within-cluster compactness and the between-cluster separation is proposed based on SSC objective function; (ii) the variance of the sample is chosen as the influencing factor of the between-cluster distance on the clustering effect, which can prevent the local optimum to a greatest extent; and (iii) The contrastive experiment results demonstrate that the accuracy and the stability of the ASSC algorithm outperform the four existing clustering algorithms. The above three points guarantee the superiority of the proposed algorithm. In the next section, the clustering results of ASSC in five datasets are described in detail.
Figure 2 (a) (e) shows the convergence curves of the ASSC algorithm in five datasets. The horizontal axis represents the number of iterations and the vertical axis represents the value of the objective function that the values are the best results among 10 trials. We can see that the objective function of ASSC has a significant drop after dozens of iterations and that shows ASSC has good convergence. i.e., the Glass dataset for iteration 10 times tends to be smooth, the Wine dataset iterates 5 times, the Wall dataset iterates 26 times, the Ionosphere dataset iterates 5 times and the Sonar dataset iterated 7 times.
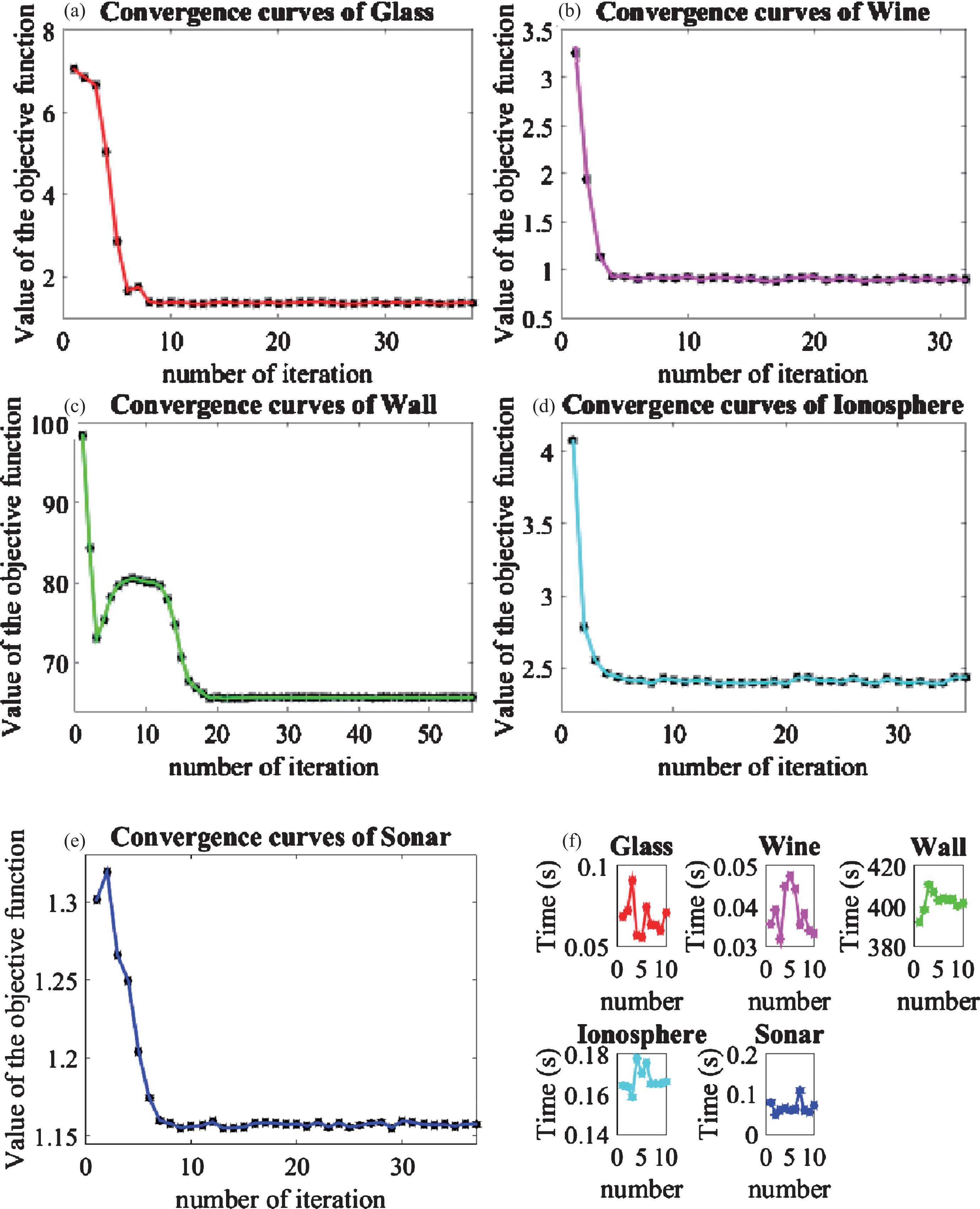
Convergence curves of (a) Glass, (b) Wine, (c) Wall, (d) Ionosphere, (e) Sonar, (f) Time.
The running time of the ASSC algorithm performed on the UCI datasets is measured in Fig. 2 (f). The horizontal axis represents the number of trials and the vertical axis represents time. We can see that the CPU running time of the ASSC algorithm in the Glass dataset, the Wine dataset, the Ionosphere dataset and the Sonar dataset are the fastest, the average of running 10 trials were 0.0676s, 0.0383s, 0.1672s and 0.0669s, respectively; and the Wall dataset is a large-scale data, its running time is longer than the other four datasets and the average time of 10 run was 402.2320s. Once again embodies the proposed algorithm was very strong adaptability and fast convergence rate. This is due to the fact that it is based on the framework of SSC and integrates within-cluster and between-cluster information required in the clustering process. Therefore, it is necessary to evaluate the distribution of a clustering algorithm with the feature weight, the distribution of the best clustering results obtained from ASSC algorithm is plotted in Fig. 3, X j {j = 1, 2, …, M} represents the value of all entities in the j dimension.
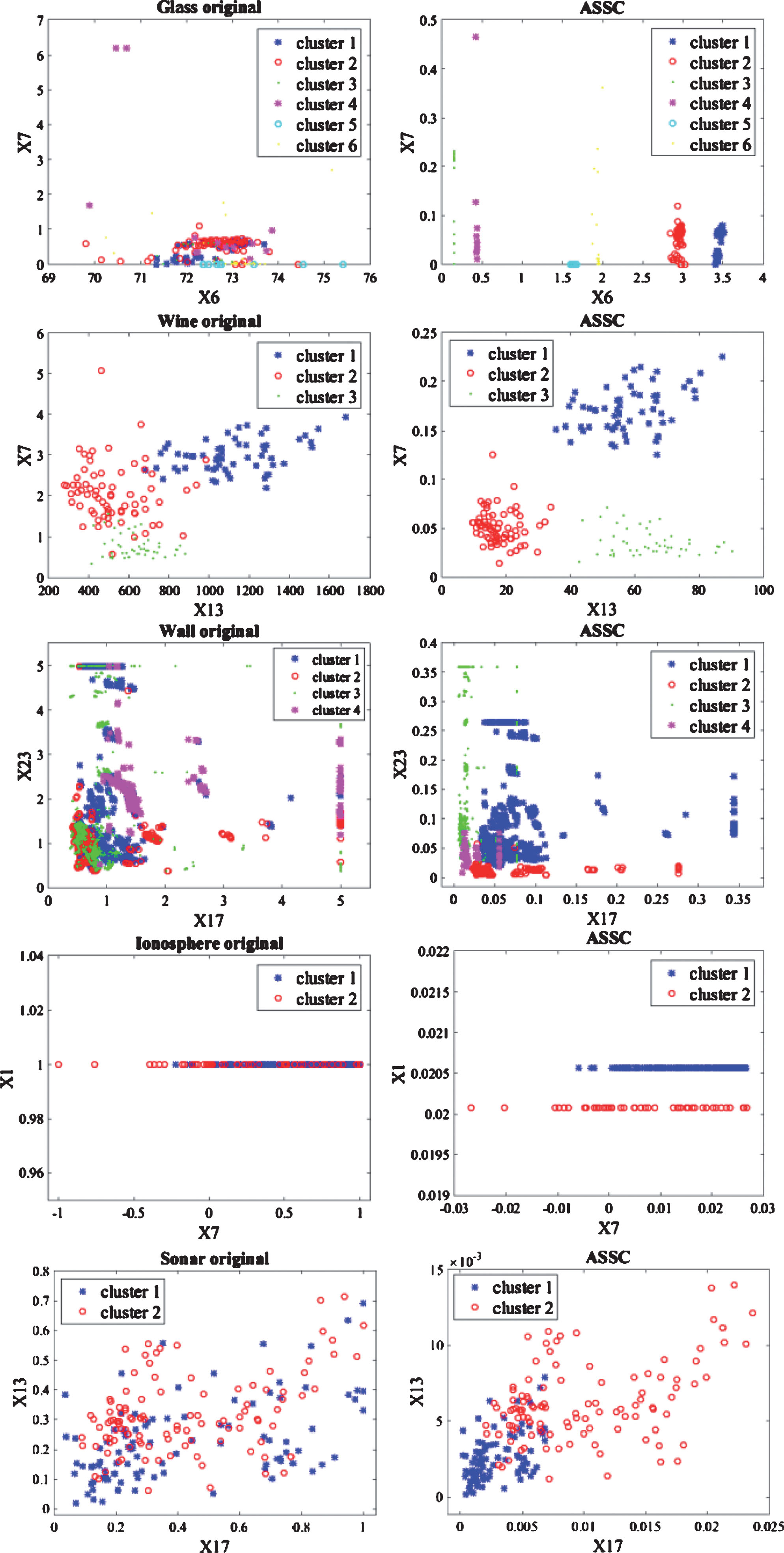
The left is the original data distribution; the right is the transformed data distribution according to feature weight.
The data distribution according to the feature weight was shown in Fig. 3. The left is the original data distribution for each dataset, the right is the implementation of ASSC algorithm after the data distribution, and the corresponding feature weight values are shown in Table 7. We can see that the introduction of between-cluster distance is very important for clustering results. There is a serious overlap between these five raw data, but the implementation of the ASSC algorithm can well distinguish these overlapping data. For example, the Glass dataset, the Wine dataset and the Ionosphere dataset can be completely separated and the distance between each type of data is maximized and between-cluster distance reaches a maximum. While the four classes in the Wall dataset have a small amount of data overlap. The two classes in the Sonar dataset have only a small amount of data overlap. Furthermore, the adaptive strength of ASSC algorithm can improve the clustering performance, thus indicating that the introduction of between-cluster distance can improve the clustering accuracy and the stability of clustering results.
The transformed data distribution according to feature weight
In this study, the ASSC algorithm is proposed and developed by considering both within-cluster and between-cluster information. The work involves the following aspects: (i) The algorithm combines non-Euclidean distance and between-cluster separation, a new objective function is constructed by modifies the original SSC algorithm; (ii) the adaptive soft subspace clustering ASSC is developed and the properties are investigated; and (iii) comprehensive experiments are carried out to evaluate the performance of the ASSC algorithm. The findings in this study demonstrate that the proposed ASSC algorithm is in general more effective in subspace clustering than ESSC, EWKM, FWKM and CIM_QPSO_SSC algorithms.
This study will be further extended to improve the performance of other SSC algorithms. For example, entropy weighting subspace clustering algorithms. In this paper, the test results on high-dimensional dataset do not fully reflect the superiority of ASSC algorithm, but next we will try larger and more practical dataset to valid the effectiveness of the algorithm.
Footnotes
Acknowledgments
We would like to thank the anonymous reviewers whose thoughtful comments improved the quality of this paper. This work was jointly supported by the Fundamental Research Funds for the National Natural Science Foundation of China for General Program (Grant No. 51675414), National Key Research and Development Program of China (Grant No. 2017YFD0700200), China Postdoctoral Science Foundation (Grant No. 2018M643627) and National Natural Science Foundation of PR China (Approval No. 51575532).