
Abstract
Scientific workflow applications include a set of tasks, which have complex inter dependencies with each other, along with a large number of parallel tasks. The problem of scheduling such application tasks involves careful decisions on determining the sequence in which it can be processed, causing high impact on the cost of execution and makespan (execution time), when executed on a cloud computing system. Achieving optimal schedule, which can optimize both of these objectives while keeping the dependencies between tasks intact is a real challenge. In this work, a non-dominated sorting based particle swarm optimization approach to find an optimal schedule for workflow applications in cloud computing systems is proposed. A graph is used to represent tasks in the workflow and the dependencies among tasks. The optimization problem is modelled using integer programming formulation, subject to capacity and dependency constraints among tasks and Virtual Machines (VM). Simulation studies and result comparison with other representative algorithms in the literature shows that the proposed algorithm is promising.
Keywords
Introduction
Cloud computing allows leasing of computing resources over the Internet for meeting the computing/storage requirements of an individual, small scale companies and research organizations. The characteristics of cloud computing systems include on demand self-service, broad network access, resource pooling, rapid elasticity and measured service. The benefits of using public cloud systems include reduced infrastructure cost, reduced overhead for the end user and pay only for the components he has used for the given amount of time [3]. Resource management in the cloud computing system is an activity consisting of two stages, namely resource provisioning and resource scheduling. The resource provisioning is to identify adequate resources for a workload submitted by the end user and resource scheduling is the process of mapping the workload to provisioned resources [28].
Optimal scheduling algorithms are important for the cloud since they determine the efficient utilization of cloud computing resources, thereby achieving desirable throughput for the end user and reduced infrastructure and management cost at the cloud service provider’s (CSP’s) end [5]. Task scheduling algorithms can be designed to meet different application requirements such as minimizing makespan, minimizing cost, fairness among users or applications, reducing energy consumption, minimizing response time and making the system deadline aware. Based on the application requirement, algorithms can be designed to optimize any one or more of these requirements. Scientific workflows are even complex in that not only we need to consider makespan or cost, but also the inter-dependencies between tasks in the workflow. The process of scheduling a workflow in a distributed system, like cloud computing systems, consist of assigning tasks to resources and orchestrating their execution so that the dependencies between them are preserved [26]. Scheduling of workflow task requires massive computation and communication cost [33]. For scheduling such applications, there is a limit on the number of tasks that can be executed in parallel in different Virtual Machines (VM).
In this work, the scheduling of workflow of different sizes in the cloud are considered. The objective functions considered for performance optimization are the overall execution time of all the tasks in the workflow and its cost of execution. The cost may include total computation cost, communication cost, over all maintenance cost and power consumption cost for the set of tasks in the workflow. These two objectives are conflicting with each other, as well as they, in turn, affect other performance metrics such as response time, energy consumption, etc. Each task can be assigned to a VM that cost less but may take more time for its execution, reducing throughput. For an end user, this may not be acceptable. Having a powerful VM will be costlier for the end user and may consume more energy. Hence, a balance between cost and execution time is of prime importance as far as cloud computing systems are considered. This paper addresses workflow task scheduling in cloud computing systems, by employing non-dominated sorting procedure along with crowding distance comparison under the framework of particle swarm optimization (PSO) algorithm. To the best of our knowledge and belief, such a proposal under the PSO algorithm framework is not available for workflow task scheduling in the cloud computing domain so far. Since bi-objective optimization scenario is only considered, the performance of the proposed algorithm is compared with NSGA-II [9]. NSGA-III [8, 14] is also further addressed in the text.
Contributions of the paper include: Developed a fast non-dominated sorting based multi-objective optimization algorithm along with the crowding distance comparison operator under the framework of PSO algorithm for scheduling workflow tasks in the cloud computing environment. Performance comparison against genetic algorithm based non-dominated sorting technique, NSGA-II [9].
Related work
Classical approaches to solving a multi-objective optimization problem include combining multiple objectives into a single objective function by assigning weights to different objective functions [20, 30]. Our previous work [3, 5] and L Guo et al.[13] uses PSO technique for independent task scheduling using weighted-sum approach where as in [4] the genetic algorithm is used. R Duan et al. [10] use game theoretic approach for independent Bag-of-Tasks (BoTs) scheduling using weighted-sum approach. For domains with highly unpredictable and dynamic workload characteristics, such a formulation is practically infeasible as the relative weights among objective functions need to be known in advance, hence other methods are to be explored. V A Leena et al. [17] attempts to schedule independent tasks in the hybrid cloud platform using the algorithmic framework of NSGA-II for optimizing makespan and cost. MOEA/D technique is used by X Wang et al. [34] for bi-level multi-objective task scheduling which uses map reduce framework. In these proposals, scheduling of independent tasks in the cloud domain is only considered, which is not suited for workflow task scheduling.
Algorithms for solving the task allocation/scheduling problems in workflows in the cloud computing domain is proposed by B P Rimal et al. [24], Chen et al. [6], M.A. Rodriguez et al. [25], S Abrishami et al. [1] and A M Manasrah et al. [19], but optimizes single objective function only. Wu et al. [35] has tried to optimize total execution cost and transmission cost and modelled the problem as the summation of both, leading to single objective optimization. H M Fard [12] finds execution time and cost optimal schedule for scientific workflows using a reverse auction mechanism of game theory. Juan et al. [11] proposes a workflow scheduling algorithm named MOHEFT, a list based heuristic algorithm considering energy efficiency and makespan trade-off. They have used B-rank procedures and non-domination principle to find Pareto optimal solutions. A Verma et al. [33] uses another list based heuristics, namely BDHEFT, to execute workflows in the cloud optimizing execution time and cost for budget and deadline constraint applications. Szabo et al. [31] and Z Zhu et al. [36] uses genetic operators for scheduling workflows considering multiple objective functions. An adaptive meta-heuristic technique for workflow scheduling in grid and cloud computing environment is proposed by M Rahman et al. [23] for optimizing cost and time. The major problem with all these multi-objective heuristic techniques is that they do not scale well for larger problem instances, but scientific workflow applications consist of hundreds of nodes.
A Verma et al. have tried to incorporate their BDHEFT heuristics [33] within the framework of PSO algorithm for workflow task scheduling in [15]. They have defined the fitness function for the PSO algorithm as a weighted-sum of objective functions, time and cost for the bi-objective case, and time, cost and energy for the tri-objective case, thus requiring preference parameters to be set apriori. An external archive is then used to store non-dominated global best particles and the rest of the procedure is similar to the proposal by C A C Coello et al. [7]. The paper is not giving any clue on the preference parameter settings and their impact on the results presented in their work.
Scientific workflow scheduling using NSGA-II is proposed by P T Thant et al. [32] to optimize three objective functions. NSGA-II uses a fast non-dominated sorting procedure and crowding distance measure for multi-objective optimization. The proposal by P T Thant et al. has motivated us to attempt the steps in the NSGA-II algorithm for workflow task scheduling using PSO framework, as the PSO framework is well known for its fast convergence with larger problem instances.
Here, we propose a novel method for efficient workflow task scheduling in the cloud computing domain by applying particle swarm optimization algorithm. This is a PSO based multi-objective optimization algorithm that uses fast non-domination sort procedure and crowded comparison operator for scheduling workflow tasks in the cloud platform, adopting the NSGA-II procedure proposed by K Deb et.al. [9] and its PSO version by X Li [18]. The advantage of our approach is that there is no need for an external archive for the proposed PSO based algorithm. The selection of personal best particle and global best particle in each iteration of the PSO algorithm as well as maintaining the global best particles of each iteration are critical concerns while using the PSO algorithm with non-domination principle. The concept of an external archive proposed by C A C Coello et al. [7] for storing globally best non-dominated particles and is used to find the leaders of each iteration. As the size of the archive increases over iterations, there should be some mechanism to limit the length of the archive. The method used in the literature for the same include clustering method of G T Pulido et al. [22], the application of crowding distance by M R Sierra et al. [27] and the formation of the adaptive grid by C A C Coello et al. [7]. Such overheads are eliminated in our proposed method. Another advantage of the proposed method is that there is no need of setting preference parameters apriori, a static decision to be made with the weighted-sum based approaches. Though the weighted-sum based method is simple and easy to implement, determining the weight value (preference parameter) apriori is a major limitation of this approach as the same depends upon the type of application and the requirements of user and the cloud service provider. With non-domination based approach, the concept of objective weighing is not used.
System model
In cloud computing systems, the resource can be treated as Virtual Machines (VMs) of a different configuration in terms of the processing power, storage, bandwidth, etc. upon which application programs run. An application may consist of thousands of jobs, which may be further divided into tasks, to be executed. There are some applications where the set of tasks are purely independent. Hence they can be executed without considering any particular order of task execution and may be executed in parallel, using different VMs. But for workflow applications, there exists a set of series and parallel paths having multiple tasks, each of which can be scheduled to execute only after completing all previous tasks in the path.
Formalism
Formally, a workflow application is represented using a Directed Acyclic Graph(DAG) W = (T, D) where T represents the set of tasks and D, the dependencies between tasks in the workflow application, defined as:
D ={(T p , T q , Fp,q)} such that (T p , T q ) ε TX T where p ≠ q and Fp,q is the data that need to be transmitted from task T p to task T q .
Assume an application consists of w tasks having a set of parallel tasks and sequential tasks. Each task T i receives a set of data from all its immediate predecessors and after processing the task, it sends out an amount of data to all its immediate successors. Assume there are p i immediate predecessors and s i immediate successors for T i . Thus, T i receives data from p i tasks where the data received may be of different size. The sum of all received data units forms the data for the processing of T i . The data that is sent out from T i after its processing to all s i successors will be of the same size. The time taken for sending the data to all s i tasks depends on the size of the data as well as the bandwidth of the communication link between T i and these successors. The sequential tasks in the workflow may be assigned to a VM of low cost or to a VM that runs faster from the available VMs, depending on the requirement. For parallel segments, to effect the parallel computation, n a VMs are needed, which depends on the number of tasks that can be executed concurrently.
For each type of VM instance I, the associated cost of usage and the computing power are different. Let P
j
represent the processing power of j
th
VM instance type where j = {1 … |I|} and C
j
represent its cost for unit time. For i = {1 … w}, we define the task length Tl
i
, the time taken for execution of T
i
, as the sum of the time taken for the execution of its own code on the data received at T
i
by VM
j
(denoted as Tn
ij
) and the time taken by T
i
to send the output data to all s
i
successors (denoted as Tt
i
). i.e.,
The cost of execution, Tc
ij
, of a particular task T
i
depends on its task length and the cost of usage of the assigned VM. i.e., if the i
th
task is assigned to j
th
VM, then
Similarly, the cost of computation of the workflow application is defined recursively as:
Our objective is to minimize TL
w
and TC
w
simultaneously. i.e.,

Workflow applications.
Following assumptions regarding VM placement, scheduling and usage are also assumed in this work: VMs are time shared among tasks, and the minimum number of VMs needed for concurrent execution of the parallel segments of a given task graph, n
a
are available. VMs cost is based on real usage time, not some time units like hours in EC2. VMs are already created, deployed and ready to receive tasks when the algorithm runs. Decisions on VM placement and its geographical locations are already been made. Number of VMs can be changed, but made constant for each simulation run.
Multi-objective optimization
Formally, a multi-objective optimization problem consists of optimising a vector of n obj where the objective function is F (x) = (f1 (x) , f2 (x) , …, f n obj (x)). Each of these f i (x) need to be either minimized or maximized and most of them will be conflicting each other. Here we have two objective functions, TL w and TC w , and both are to be minimized. In a multi-criterion optimization problem, the solution consists of a set of optimal solutions known as Pareto-optimal solutions. Different classical techniques exist in literature to solve a multi-objective optimization problem. The weighted-sum approach, Min-Max formulation and the method of distance functions are some of the common techniques among them. In these methods, multiple objectives are combined into a single objective function, resulting in a unique solution. Here, prior information about the optimum is needed for performing the optimization. Other methods generate a set of optimal solutions and leave the selection of a particular one from the set of alternatives to the decision maker at a later stage. Heuristic search techniques that use domination principle is one such technique, which is attempted in this work.
Non-dominated sorting technique
A solution x1 is said to dominate another solution x2 if the solution x1 is no worse than x2 in all objectives and the solution x1 is strictly better than x2 in at least one objectives [29]. The non-dominated sorting approach classifies the entire solution set into different non-domination levels. Solutions in the first non-dominated level are at Frontlist 1, and they will be assigned rank 1. In the next iteration of the algorithm, the domination principle is applied to all other solutions, leaving the solutions in the Frontlist 1. Current non-dominated set in the first level forms the Frontlist 2, and they will be assigned rank 2 and the process repeats. On completion of all the iterations of the algorithm that use non-dominated sorting technique, the solutions in first front are nearer to the true Pareto-optimal front.
K.Deb has proposed NSGA-II algorithm that use the non-dominated sorting technique with the crowded comparison operation to generate Pareto-optimal solutions [9] within the framework of Genetic Algorithm (GA). The crowding distance is calculated by adding the distance of a particular solution from its neighbouring solutions in that front on each of its objective function values. The idea of non-dominated sorting along with the crowding distance measure is used in the selection of parent chromosomes. X. Li [18] used this idea and integrated the same into the framework of particle swarm optimization technique. He has used both crowding distance assignment procedure as well as the Euclidean distance method (σ share ) for population diversity. Both of these researchers have experimented with functions in the continuous domain.
NSGA-III is an alternative of NSGA-II for many-objective optimization problems, where the number of objective functions to be optimized are four or more [8, 14]. Since the number of objective functions considered here are two, NSGA-III approach is not considered in this study. C Bao et al. [2] proposed a modification of the non-dominated sorting procedure, namely hierarchical non-dominated sorting, recently. They suggest an alternative procedure for reducing the number of redundant comparisons of objective function value on non-domination sort procedure. But the worst case time complexity of this algorithm is O(MN2) which is same as NSGA-II, though the best case time complexity is good. Since the fast non-dominated sorting procedure along with the crowding distance comparison operation is an established and widely accepted method in the literature, in this work the same procedures are adopted under the framework of PSO to schedule workflow tasks in the cloud, a problem in the discrete domain.
Particle swarm optimization technique
Particle Swarm Optimization is one among the nature inspired optimization techniques introduced by Kennedy and Eberhart based on swarm intelligence [16] for solving problems in the continuous domain for single objective optimization problems. In the beginning, the PSO algorithm generates randomly a set of N solutions called particles in the d-dimensional search space. Each particle is represented by a d-dimensional vector X i which stands for its position (xi1, xi2, . . . , x id ) in space. Each particle maintains its position (x), its velocity (v) and the best position (pbest) it has achieved so far during the search. The PSO algorithm also maintains the best position (gbest) achieved among all the particles in the swarm.
Since the task scheduling problem is in the discrete domain, Integer-PSO technique [3, 5] is used in this work to generate discrete position values. The velocity update mechanism, constrained by v
min
and v
max
, and the position update mechanism of each particle in the proposed algorithm are given in equations (13) to (16) where i = 1, 2, …, S (the swarm size), t = 1, 2, …, G (the maximum number of iterations), w the inertia weight, c1 and c2 are acceleration coefficients, and r1 and r2 are two uniformly distributed random numbers in the interval [0, 1]. Y is a parameter that takes integer values and is to be tuned for better accuracy. New position
The proposed algorithm using non-dominated sorting procedure and the crowded comparison operator integrated into Particle Swarm optimization framework is given in Algorithm 1. For each particle in the random initial population P1 of size S, pbest is assigned with the same particle position and gbest is assigned randomly among pbests. The velocity and position of P1 are updated to create new particle positions Q1. Both of these populations are evaluated on each of their objective functions, based on the mathematical model presented in Section 3.1.
In the t th iteration of the algorithm, both P t and Q t are combined to get R t . The Nondomination-Sort() procedure (Algorithm 2) is invoked to generate Frontlist where R t is sorted into different Frontlists based on domination principle. A rank is assigned to each member based on the front list. The best particle set Pt+1 of S particles is created by adding individuals from each Frontlist. For situations where all the elements of a Frontlist cannot be added to Pt+1, the individuals in that Frontlist are sorted in descending order based on their crowding distance value. The crowding distance of each solution is found using equation (17). The individuals with higher crowding distance value from this list are added to Pt+1, to maintain diversity among particles. The particles in the set Pt+1 are evaluated and the pbest of each particle is updated based on non-domination level. The gbest is also updated with a random member in the Frontlist 1. The new population Qt+1 is created from Pt+1 by velocity and position update mechanism and are evaluated to find fitness. These steps are continued for G iterations and on completion, the particles in the Frontlist1 is output as the Pareto-solutions.

With PSO approach, on each iteration of the algorithm, each particle’s personal best (pbest) and the global best (gbest) need to be updated, as they are needed for finding the new velocity and position of each particle. This makes the algorithm to decide a criterion for selecting the best solution among particles at each iteration of the algorithm. The algorithm NSPSO [18] uses the sorted non-domination list to find the global best particle (random among top 5%), but they are silent on the criteria of selecting the personal best particle. In our proposal, the gbest is selected as a random particle position in the Frontlist 1 having members with rank 1. The pbests are decided based on the domination principle between two particles on each of its objective function values. If both of them are dominating each other, then any one of these particles is randomly assigned as pbest.

In the Nondomination-Sort() algorithm (Algorithm 2), Frontlist 1 is found by comparing each individual with every other individual in the population. Corresponding state variables S p and n p are updated. If n p = 0 after all comparisons, it means that none of the individuals dominates p. All individuals with a domination count equal to zero constitute the Frontlist 1. To find the next front, for each p in the current Frontlist, the domination count is reduced by one for all elements in its S p set, and the process is repeated to find the Frontlist 2. The same process is repeated to find all the Frontlists.
The crowding distance of i
th
individual, denoted by I [i]
dt
indicates how near a solution is to its neighbours in its frontlist. Individuals with a large crowding distance value give a diverse population. To find the crowding distance value, for each objective function to be optimized, the elements in the Frontlists are sorted based on objective function values. Boundary points are assigned an infinite distance value and intermediate points are assigned values according to equation(17), where I [i] . m refers to the m
th
objective function value,
In a population of size S with m objective functions to be optimized, the time complexity of the non-dominated sorting procedure is O (mS2) and storage requirement is O (S2) [9]. Since the procedure is invoked G times in the proposed algorithm, the total time complexity of the algorithm is O (GmS2). As the crowding distance comparison operator is used in the selection of particles for successive generations, more regions in the search space will be explored, ensuring diversity among non-dominated solutions. Thus the proposed non-dominated sorting based algorithm efficiently handle the local optima problem.
Implementation
The permutation encoding technique is used here for representing Task-VM assignment. Every VM is assigned a number from 1 to n a and solutions are represented by a sequence of assigned VMs in task order. For example, if the solution sequence is (4, 2, 1, 3, 4), then it means that the solution is to assign Task 1 to VM 4, Task 2 to VM 2, and so on and the corresponding makespan and cost are estimated for the given schedule, considering all dependencies and the data transfer cost between tasks, as per mathematical model presented in Section 3.1. It is assumed that the cost of using each of the VMs are different and their execution speeds are also different. Also, for tasks running in different VMs, data may be sent between VMs incurring data transfer cost. For successive tasks running on the same VM, data transfer cost is zero.
For experimentation, the VMs are configured as shown in Table 1. The VMs are set in such a way that the performance of the algorithm on heterogeneous environments can be analyzed. Here, if a task when assigned to VM1 or VM4, it may take 1 unit of time with 10 units of cost. If the same task is assigned to VM2, the task will be executed in 3/4 time units incurring a cost of 20 units whereas VM3 will execute the same task in 1/2 time units incurring a cost of 30 units. For experiments with workflow I, VM1 to VM3 are used and with workflow II, VM1 to VM4 are used. For both the the workflows, atmost 3 tasks can be run in parallel.
VM Configuration
VM Configuration
We assume the availability of an expected time to compute matrix which gives the expected execution time of tasks in a standard type VM. The capacity of each VM in terms of speed and cost of usage per unit time, input/output data size of each task and the average communication cost per unit data between VMs are also assumed, where each of these VMs is located in different geographic locations. A convergence study on the proposed algorithm is done along with parameter tuning trials to find the best settings using the workflow example having 5 tasks (Fig. 1(a)). We have tested the algorithm on the example workflows of Fig. 1(a) with n a = 3. The best results are obtained when the inertia weight w is set as 0.6, c1 and c2 as 0.2, Y as 2, v min as -4.0 and v max as +4.0 with G = 200 and S = 5. For workflow example with 9 tasks (Fig. 1(b)) n a is set as 4 and G as 500. Fp,q is the data that is transmitted from task T p to task T q . For both the workflows, the sum of all such data transfers between tasks in the workflow is varied between 43MB and 512MB to assess the performance of the proposed algorithm.
For comparing the performance of the proposed algorithm, NSGA-II algorithm is also simulated. NSGA-II uses genetic algorithm framework with the non-dominated sorting approach along with crowded comparison operator. The parameters of the GA are set as crossover rate = 0.9 with 1-point crossover, mutation rate = 0.01 with bit flip method, generation count = 500 and number of chromosomes = 10.
During the evaluation of a given population set, both the algorithms check to see that all the constraints specified in the mathematical model are satisfied. If there is any violation of the constraints, then that solution is ignored. The whole process is repeated for G iterations, and individuals in the Frontlist 1 on completion are the Pareto solutions. These algorithms are simulated 10 times on the same parameter setting on the same workflow, and the average value is taken for each algorithm. The selection of a particular schedule from the Pareto-solutions can be based on application-specific priorities such as the most cost effective one, the schedule that gives the least makespan, the schedule closest to a reference point, etc.
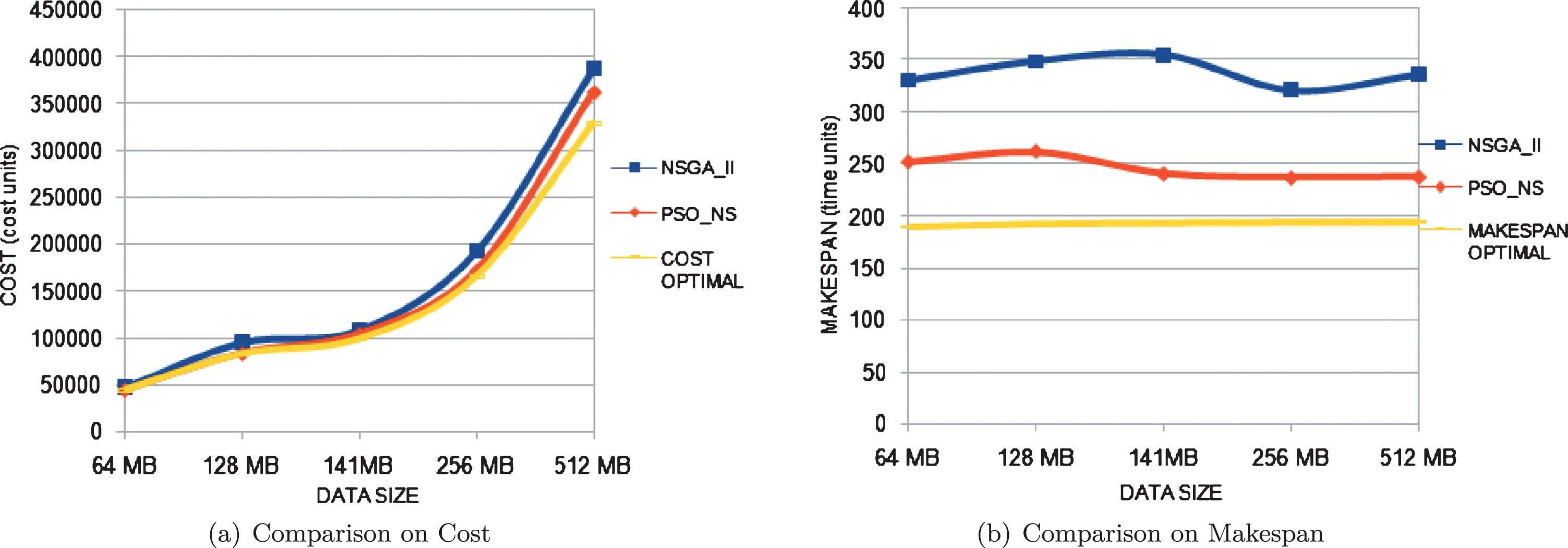
The solutions generated using the proposed PSO-based method and GA-based method for the workflow application examples of Fig. 1(a) and 1(b) are shown in Fig. 2 and in Fig. 3 respectively. Fp,q is the data that is transmitted from task T p to task T q and the variable DATASIZE in the X-axis in the figure is the sum of all such data transfers between tasks in the workflow. In the Y-axis, makespan may be expressed in terms of milli seconds or seconds and cost in terms of US Dollars, Indian Rupee, etc. Since the study uses assumption and simulations, the actual unit of these variables are considered to be immaterial and are not mentioned in the text and in the figures as well. The solutions in the Frontlist 1 on completion of G iterations of the proposed method and NSGA-II give best schedules that can be achieved by these algorithms. There will be more than one solution, which may not be the best in all the objectives. If we fit the solution set on a curve, we have infinite solutions. Selection of a particular solution from this set is to be made at the higher level.

Performance Analysis of Workflow-I.
Performance Analysis of Workflow-II.
For comparison of the results, solutions that give the best cost and the best makespan for different data sizes are taken from the set of solutions generated by each of the algorithms for the bi-objective optimization of cost and makespan. These points are the extreme points in the considered bi-objective optimization problem. Fig. 2(a) to 2(b) represents the simulation results for the example workflow in Figs. 1(a) and 3(a) to 3(b) shows the simulation results for the example workflow in Fig. 1(b). In Figs. 2 and 3, PSO_NS represent the solutions generated by the proposed PSO based non-dominated sorting algorithm whereas NSGA_II represent the solutions generated by the NSGA-II algorithm for bi-objective optimization.
To find the benchmark solutions for the workflows, best resource selection (BRS) algorithm is simulated considering single objective function. In Figs. 2 and 3, COSTOPTIMAL represent the solution obtained when BRS algorithm is run considering cost function alone. Similarly MAKESPANOPTIMAL represent the solution when makespan function alone is considered by the BRS algorithm. BRS algorithm achieves best cost on different data sizes, but the corresponding makespan in that situation is the worse which is not plotted. This is because when the BRS algorithm tries to optimize cost function, it assigns all tasks to VMs with less cost without considering the execution time needed for completion of the task. Similar effect is there for makespan optimal case also. In the presented results, the BRS results are plotted to show that the proposed algorithm tries to be nearer to its optimal case on cost value and makespan value on different data sizes when bi-objective optimization is done. It can be seen in Figs. 2 and 3 that the proposed algorithm achieves good results than NSGA-II algorithm and is much nearer to the benchmark results for cost and makespan for different data sizes considered for both the workflow examples. For workflow I, the average percentage benefit for the proposed algorithm with respect to the NSGA-II algorithm on best cost case is 20.2% and that of best makespan case is 18.1%. For workflow II, the average percentage benefit on best cost case is 7.7% and that of best makespan case is 27.3% on an average. The main loop of all the three algorithms is iterated 200 (G) times for Workflow I and 500 (G) times for Workflow II. 10 independent trials of each of these algorithms are done on each of these workflows and the average results over these 10 trials are presented in this section. The time of execution of each trial are close to the average value with a standard deviation of 0.02.
Figure 4(a) to 4(b) represent the average percentage of utilisation of different virtual machines by the NSGA-II algorithm on various data sizes for best cost and best makespan solutions for the example workflow with 5 tasks (workflow I) when bi-objective optimization is done. Fig. 5(a) to 5(b) represent the corresponding VM utilization of the best cost and best makespan solutions of the proposed PSO_NS algorithm. Similarly Figs. 6(a) to 7(b) represent the VM usage for the example workflow with 9 tasks for both the algorithms when bi-objective optimization is performed. For best cost case, the low cost VM (VM1) usage by the proposed algorithm for workflow I is 70% to 90% as shown in Fig. 5(a) where as the usage of VM1 is 30% to 60% with NSGA-II algorithm as shown in Fig. 4(b) for different data sizes. Similarly, the usage of low cost VMs (VM1 and VM4) by the proposed algorithm is up to 80% with workflow II as shown in Fig. 7(a) where as the usage of VM1 and VM4 are 40% with NSGA-II (Fig. 6(a)). This causes the proposed algorithm to achieve low cost than the NSGA-II algorithm.
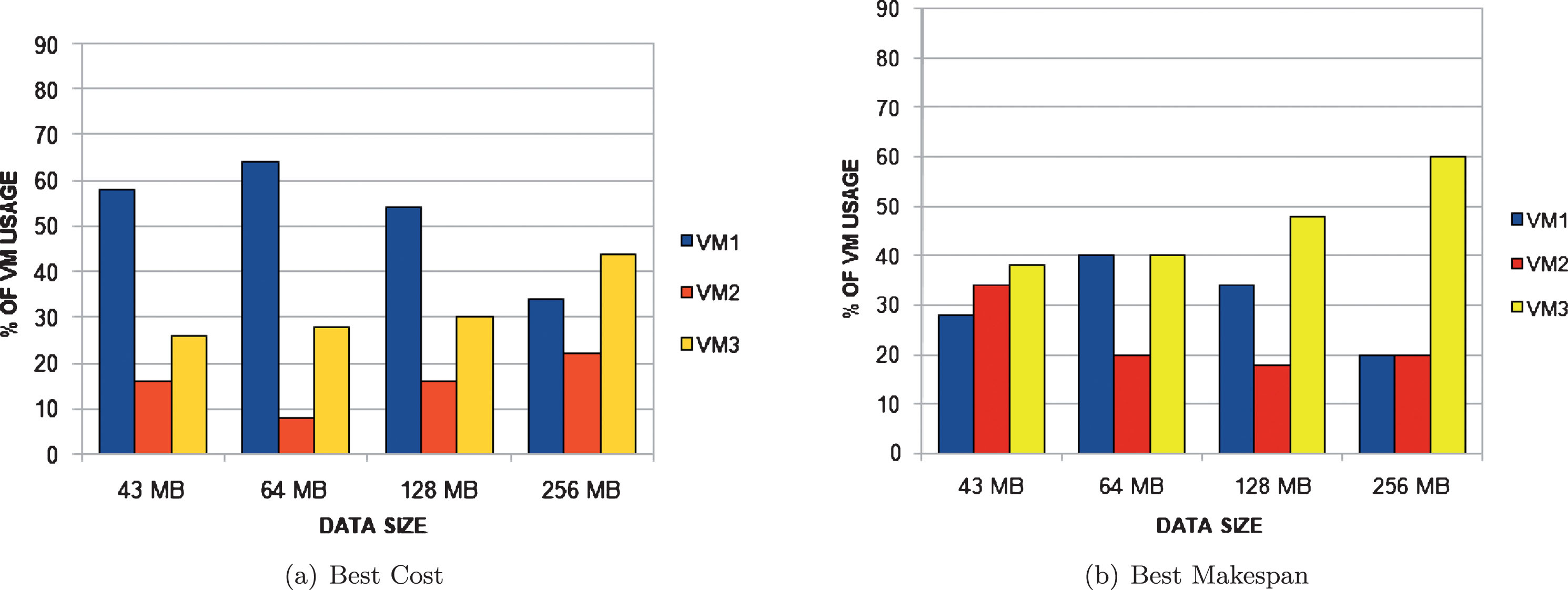
VM usage by NSGA-II algorithm for Workflow-I.

VM usage by PSO_NS algorithm for Workflow-I.

VM usage by NSGA-II algorithm for Workflow-II.

VM usage by PSO_NS algorithm for Workflow-II.
For best makespan case, the PSO_NS algorithm is able to assign most of its tasks to VMs with high processing power such as VM2 and VM3 as shown in Figs. 5(b) and 7(b). In the case of NSGA-II algorithm, the less powerful VMs (VM1 and VM4) are mainly used in most of the test cases as shown in Fig. 6(b). These results shows why the NSGA-II algorithm fails to achieve optimal solutions for best cost case and best makespan case. These analysis shows that the proposed algorithm is better than the NSGA-II based task scheduling algorithm and is able to converge faster to optimal solutions for the test cases considered. However, as a future work, experiments with more number of workflow samples and real scientific workflow examples are to be done and more statistical analysis based on quality parameter measures such as generational distance, spacing, etc. are to be derived to assess the performance of the proposed algorithm.
Scheduling tasks of a workflow application is challenging in the cloud computing environment as it involves many factors such as cost and profit considerations, execution time, service level agreements (SLA), quality of service parameters requested by the end user and committed by the CSP and power considerations. Also, the task arrival rate is highly unpredictable and dynamic in nature. Here, the workflow scheduling problem is modelled as a constraint bi-objective optimization problem, where the objective functions to be optimized are makespan and cost. The non-dominated sorting based technique and crowded comparison operator are used here under particle swarm optimization framework for solving the multi-objective optimization problem. For the tested workflows, with the simulation done so far, the proposed algorithm performs better than the NSGA-II algorithm and the results produced are close to the benchmark results for the test instances.