
Abstract
A well-managed time-constrained workflow scheduling is needed for improving system performance and end user satisfaction. Meanwhile, the intrinsic uncertainty in dynamic systems increases the difficulties of scheduling problem. Therefore, it is a great challenge to improve performance and optimize several objectives simultaneously. To address these issues, a novel workflow scheduling method for distributed systems based on TOPSIS method with fuzzy set is proposed in this paper. The new method can minimize the makespan of the workflow application under uncertain environment. Finally, a numerical example is provided to demonstrate the efficiency of the proposed method.
Introduction
Many complex applications such as bioinformatics and disaster modeling can be naturally expressed in the form of workflow of tasks [1, 2]. One of the advantages for workflow representation is that the workflow is reproducible, traceable and reusable even by other workflows [3, 4]. Meanwhile, computing systems where catastrophe may occur will become useless, if tasks completion takes more than some specified time. Such applications based on the workflow management systems are increasing demands for processing large amounts of data in real-time tasks with desired cost reduction of computational resources [5].
Workflow scheduling is a process of mapping the workflow tasks to the appropriate networked resources. Because of the complex operations, the relationships of processing tasks are multiple interdependent. Hence, the tasks and dependencies of parent/child inter-relationship can be represented by the directed acyclic graph (DAG). Each task has various execution times, priorities and deadline constraints that are associated to other workflow [6, 7]. For achieving user quality of service (QoS) expectations, e.g., execution time minimization, while at the same time optimizing system performance, e.g., resource usage, an efficient workflow scheduling is imperative.
However, in order to attain good performance, different workflow applications need different scheduling approaches in distributed systems. Most literatures investigated the homogeneous computing system, while some works focused on heterogeneous system, each with different related constraints. The existing approaches tend to be process-oriented or data-oriented rather than resource-oriented, so that they lack efficient task-to-resource mapping capabilities [8]. Furthermore, in the conventional scheduling problem, the parameters such as task communication time and computation time have been assumed to be deterministic [9–12]. In fact, in the real-world situations, various factors involved in the scheduling problems are often imprecise or uncertain in nature [13–16]. Especially, human-made factors are involved into the problems. Up to now, the problems of modeling and handling uncertain information have attracted great attentions from researchers [17–22].
In this paper, we consider fuzzy completion times in the workflow management systems. Nevertheless to say, fuzzy sets theory [23] introduced by Zadeh is a good approach to settle with such an uncertain problem [24, 25]. The Technique for Order Preferences by Similarity to an Ideal Solution (TOPSIS) method was proposed by Hwang and Yoon [26] in 1981 to determine the best alternative based on the concepts of the compromise solution [27, 28]. TOPSIS is widely used in decision-making [29–31]. Because of incomplete or non-obtainable information, the data (attributes) are often not so deterministic [32]. Therefore, extension of the TOPSIS method for decision-making problems with fuzzy number was considered [33, 34]. Furthermore, TOPSIS has been extended with many math models. For example, D numbers [35–37] is combined with TOPSIS to deal with linguistic decision making [38]. To address these issues, we propose an efficient workflow scheduling method for distributed systems based on triangular fuzzy numbers approach (WfSTFN). The proposed scheduling method enables efficient distribution of workflow tasks with different fuzzy computation and communication demands on networked resources. Effectiveness of the proposed scheduling method is demonstrated through a numerical experiment.
The rest of this paper is organized as follows. Section 2 briefly introduces the preliminaries of this paper. After that, a novel workflow scheduling approach on distributed systems under fuzzy environment is proposed in Section 3. Section 4 gives a numerical example to show the efficiency of the proposed method. Finally, conclusions are given in Section 5.
Preliminaries
Fuzzy number
Fuzzy set theory [23] provide an alternative and convenient framework for modeling of real-world fuzzy decision systems mathematically [39–42], which has been widely applied in various fields, like information integration [43], sensor data fusion [44], strategy selection [45], tracking control [46], supplier selection [47], medical diagnosis [48, 49], and multi-criteria decision making [50–54]. A fuzzy set is any set that allows its members to have different grades of membership in the interval [0,1]. It consists of two components: a set and a membership function associated with it.
Let X be a collection of objects denoted generally by x, a fuzzy subset of X,
A fuzzy number is a fuzzy subset of X. And a triangular fuzzy number
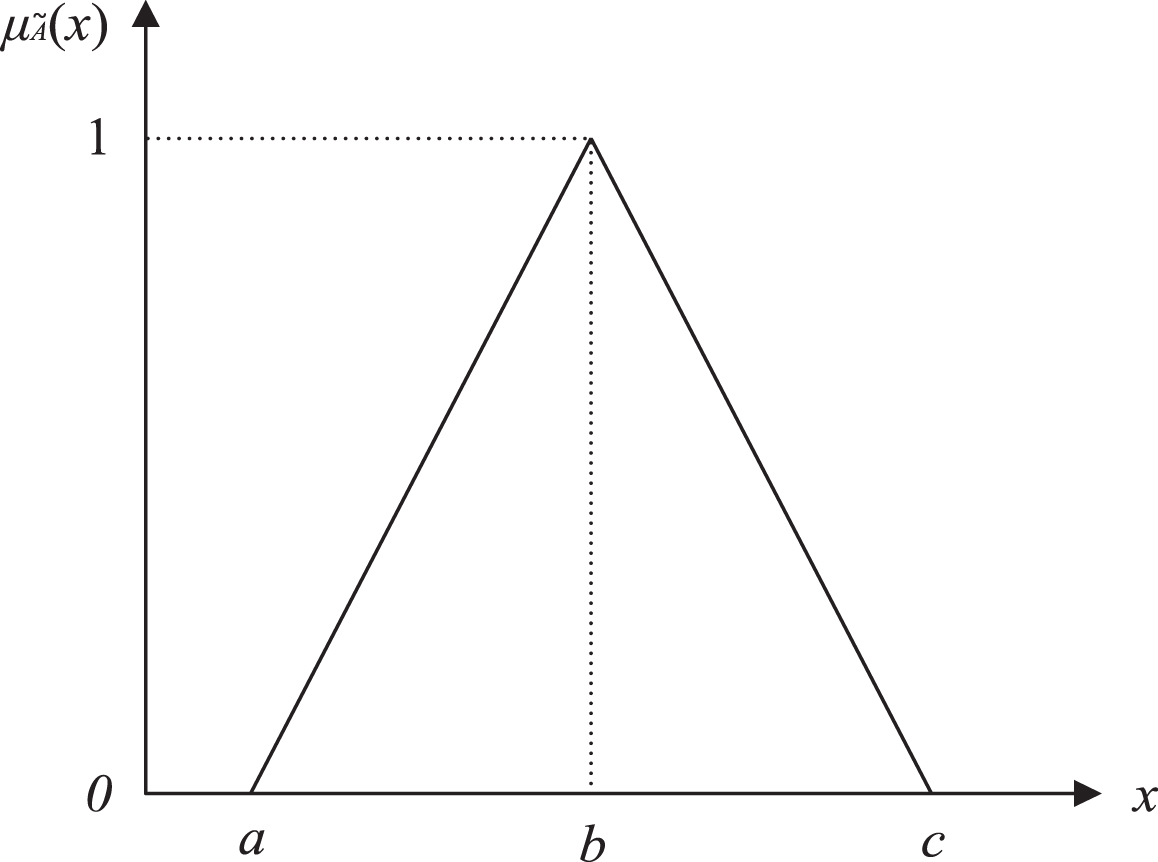
A triangular fuzzy number.
Let
The main idea of TOPSIS is that the best compromise solution should have the shortest Euclidean distance from the positive ideal solution and the farthest Euclidean distance from the negative ideal solution.
The procedures of TOPSIS method with fuzzy set can be described as follows. Let A= {A
k
|k = 1, 2, … , m } be the set of alternatives; C= {C
s
| s = 1, 2, …, n} be the set of criteria;
Let B and C be the set of benefit criteria and cost criteria, respectively. The normalized value
In the weighted normalized decision matrix, the modified ratings are calculated by
The elements
The distance of each alternative from A+ and A- can be currently calculated as
The relative closeness coefficient for the alternative A
k
with respect to A+ is
Obviously, an alternative A k is closer to the FPIS (A+) and farther from FNIS(A-) as C k approaches to 1. Therefore according to relative closeness coefficient to the ideal alternative, larger value of C k indicates the better alternative A k .
Assumptions and notations
Assumptions and notations for this paper are described as follows.
(i) Each task can be processed on any machine.
(ii) The machines are fault-free.
(iii) Each machine/resource can process at most one task at a time
(iv) The computation time and communication time are assumed to be fuzzy variables.
(v) The workflow structures are single entry with single exit.
t i , i = 1, 2, …, n: the tasks to be scheduled;
t entry : an entry task with no parent;
t exit : an exit task with no child;
parent (t i ): the parent task(s) of task t i ;
h j , j = 1, 2, …, m: the machines/resources;
T i : the fuzzy completion time of task t i ;
T make : the workflow makespan is the maximum completion time of all its n tasks;
ET ij : the execution time of task t i on r j ;
dp,i: the number of bytes transferred from t p to t i ;
bp,i: the available bandwidth;
d i : the deadline associated with task t i ;
System model
Figure 2 shows an example of a workflow management system (WfMS). The system is composed of networked homogenous resources. Once users submit requests to the workflow management system, along the workflow application, the system adopts a workflow scheduling to dispatch the tasks to avaiable workflow engines/processors that are hosted on the machines/resources. The workflow management system can provision dynamically to the workflow applications taking into account user QoS requirements (e.g., deadline) as well as the performance of the system (e.g., resource usage). In this paper, we focus on the workflow scheduling component of a workflow management system [55].
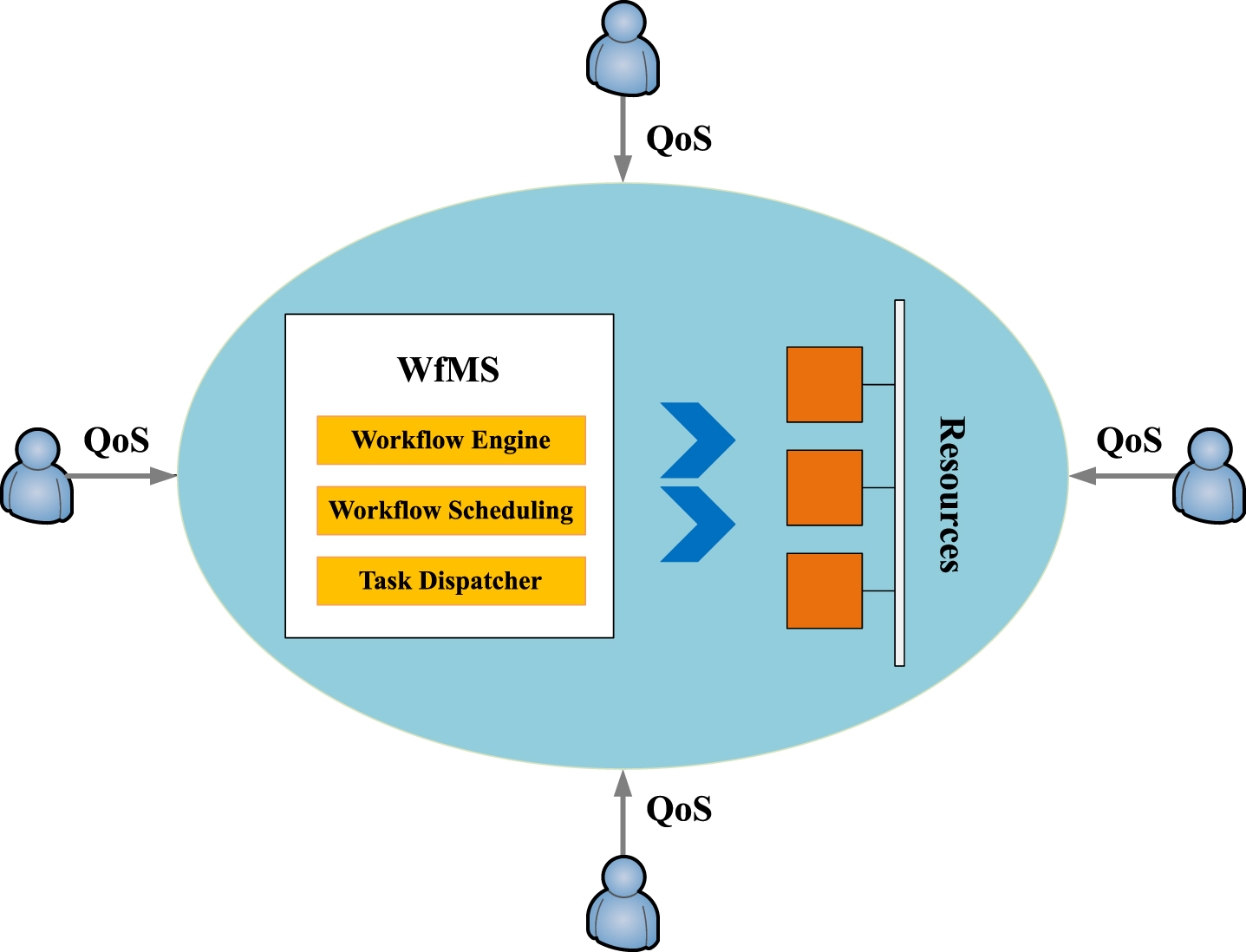
An example of a workflow management system.
The key challenge in workflow scheduling is to decide the execution time and resource allocation of each of the atomic tasks. We consider a scheduling method that minimizes the total execution time of a workflow on set of resources, while satisfying a user-defined deadline. The workflow task scheduling problem is an optimization problem and can be formally expressed as follows [56]:
Eq. (12) presents the workflow scheduling challenge which tends to find an assignment of the task t i to the resource r j such that the makespan is minimized. The workflow makespan is the maximum completion time of all its n tasks shown in Eq. (13). In Eq. (14), T i denotes the fuzzy completion time of task t i , where the first term ET ij represents the execution time of task t i on r j , and the second term is the competition time of the parent tasks. If t i has more than one parent task, we consider the parent task with the largest completion time will be selected. In Eq. (15), each task must be allocated to one available resource capable of executing the task. Eq. (16) ensures that each resource executes the tasks within the given deadline. In Eq. (17), x ij is a variable indicating whether task t i is assigned to resource r j .
In this section, a novel workflow scheduling method for distributed systems based on triangular fuzzy numbers approach (WfSTFN) is proposed. Our proposal is inspired by [23] and [56]. The WfSTFN minimizes the makespan of the workflow application for distributed systems, while improving system performance and end user satisfaction.
Figure 3 illustrates the flow graph of the WfSTFN approach. Essentially, the proposed method consists of five steps. We will now explain each of the steps in detail.

A flow graph of the WfSTFN.
As we discussed in Section 1, workflow applications can be divided into two sets of tasks. The first set of tasks are interdependent, in which the execution order must be coordinated such that a task will execute only after its immediate parent tasks have completed execution and the input data is readily available. The second set of tasks are independent, in which their execution order can be interleaved. Hence, these independent tasks compete for resources. Therefore, the layers of a workflow depend on the complexity of the interdependent task is taken into consideration within the workflow execution.
Fig. 4 shows an example of the layers of a workflow that is a four-layer workflow. There are 10 tasks with different fuzzy computation time and communication time shown in Table 1. As shown in Fig. 4, the workflow has layers and arc. The dotted lines indicates the layers for the workflow (layers 1-4). Each arc represents a precedence constraint which indicates that task t p should complete execution before task t i can start. In layer 2, there are four tasks (e.g., t2, t3, t4, and t5) with one parent (e.g., t1). In layer 3, there are four tasks (e.g., t6, t7, t8, and t9) that have more than one parent (e.g., t3, t4, and t5). We use parent (t i ) to denote the set of parents of task t i , in which the set of parents are need to be completed before starting t i . Similarly, a task can have no child (e.g. t10), one child (e.g., t9) or more than one child (e.g., t3).

An example of the layers of a workflow.
Workflow task with fuzzy computation and communication time
In this step, the tasks prioritization is based on the task layers. For each layer, the tasks will be prioritized in terms of the total number of dependency tasks denoted as Num depend (t i ) that consists of the number of children and the number of parents. And, this task prioritizing process will be done recursively until to the last task. Note that, the task on the first, namely, entry task is always assigned priority level 1.
We first compute the number of children and the number of parents for tasks in the workflow. Secondly, we add the above two numbers to create the total number of dependency tasks. Thirdly, we retrieve tasks for each layer and assigns the priority to tasks based on the location within the layer and the total number of dependency tasks.
The purpose of Step 3 is to prioritize the tasks with the same number of dependency tasks. In this step, the tasks prioritization is also based on the task layers. For each layer, the tasks will be prioritized in terms of the fuzzy computation time. As we described in Section 2, C
k
is defined as the relative closeness coefficient for the alternative A
k
with respect to A+. The bigger the value of C
k
is, the better alternative A
k
is. We denote
The purpose of Step 4 is to prioritize the tasks with the same number of dependency tasks and the same fuzzy communication time. In this step, the tasks prioritization is also based on the task layers. In each layer, the tasks will be prioritized in terms of the fuzzy communication time. We denote
On the basis of previous four steps, the new prioritized task scheduling list ready to be executed to the available resources, based on the computation of the time slots they are assigned to. The resources are selected based on the readiness of the resources. It means that the task will be scheduled to the resources which finishes the earliest task execution denoted as R t i .
In this section, a numerical example is provided to demonstrate the effectiveness and advantages of our proposed method. This numerical example is based on the workflow of Fig. 4 where there are 10 tasks with different fuzzy computation time and communication time as shown in Table 1. Here, we assume that the workflow of Fig. 4 satisfies the user-defined deadline.
By taking the complexity of the interdependent task into consideration within the workflow execution, the layers of tasks are decided. As shown in Table 2, entry task t1 belongs to layer 1. Tasks t2, t3, t4, and t5 belong to layer 2, while tasks t6, t7, t8, and t9 belong to layer 3. Exit task t10 belongs to layer 4.
We calculate the total number of dependency tasks for each task in terms of the number of children and the number of parents. Then, we retrieve tasks for each layer and assigns the priority to tasks based on the location within the layer and the total number of dependency tasks as shown in Table 3. Note that, the entry task t1 is assigned priority level 1. Task t3 has the same number of dependency tasks as t4, while task t8 has the same number of dependency tasks with t9.
The layers of a workflow
The layers of a workflow
Workflow task dependency table
We calculate the relative closeness coefficient for the alternative fuzzy computation time
Step 3.1: Construct the normalized fuzzy decision matrix as Table 4.
The normalized fuzzy decision matrix
Step 3.2: Determine FPIS (A+) and FNIS (A-) as
Step 3.3: Calculate the distance of each alternative from FPIS and FNIS, respectively, as Table 5.
The distance measurement
Step 3.4: Calculate the closeness coefficient of each alternative as Table 6.
The closeness coefficient of each alternative
Step 3.5: According to the closeness coefficient, the ranking order of the alternatives with the same number of dependency tasks can be determine as Table 8. From the results, we can notice that tasks t8 and t9 can be prioritized by the value of
Nearness degree table in terms of fuzzy computation time
The closeness coefficient of each alternative
Similarly, we calculate the relative closeness coefficient for the alternative fuzzy communication time
Nearness degree table in terms of fuzzy communication time
Based on the the Rank comm in Table 9, the task scheduling list is generated. Then, we schedule the new task scheduling list to the available resources. We assume there are three resources (R1, R2 and R3). Considering user quality of service (QoS) expectations, we use the largest computation time and communication time when allocating the tasks. The resources are selected based on the readiness of the resources. The earliest start time for each task in all three resources will be computed. The scheduling trace of the new list is shown in Table 10. In the table, the execution start times of each node on all resources at each step are given. Meanwhile, the nodes on the list are scheduled one by one, to the available resources that have the earliest start time.
Resource mapping table
In order to demonstrate the effectiveness of the WfSTFN scheduling approach, we compare it with the earliest time first (ETF) scheduling approach by considering the resources that the tasks are most likely needed. The ETF scheduling approach searches for the earliest time for all tasks where it chooses the tasks with the minimum value. Specifically, the ETF first computes the computation cost and communication cost for each task. Based on the sum value of computation cost and communication cost, the tasks will be sorted and ranked. After implementing the WfSTFN and ETF scheduling approaches, the makespan for the two methods are shown in Fig. 5 and Fig. 6, respectively. It is easy noticed that the makespan for the WfSTFN scheduling approach is 84 ms, while the makespan for the ETF scheduling approach is 88 ms. Consequently, it can be concluded that the makespan is minimized by utilizing the proposed WfSTFN method.
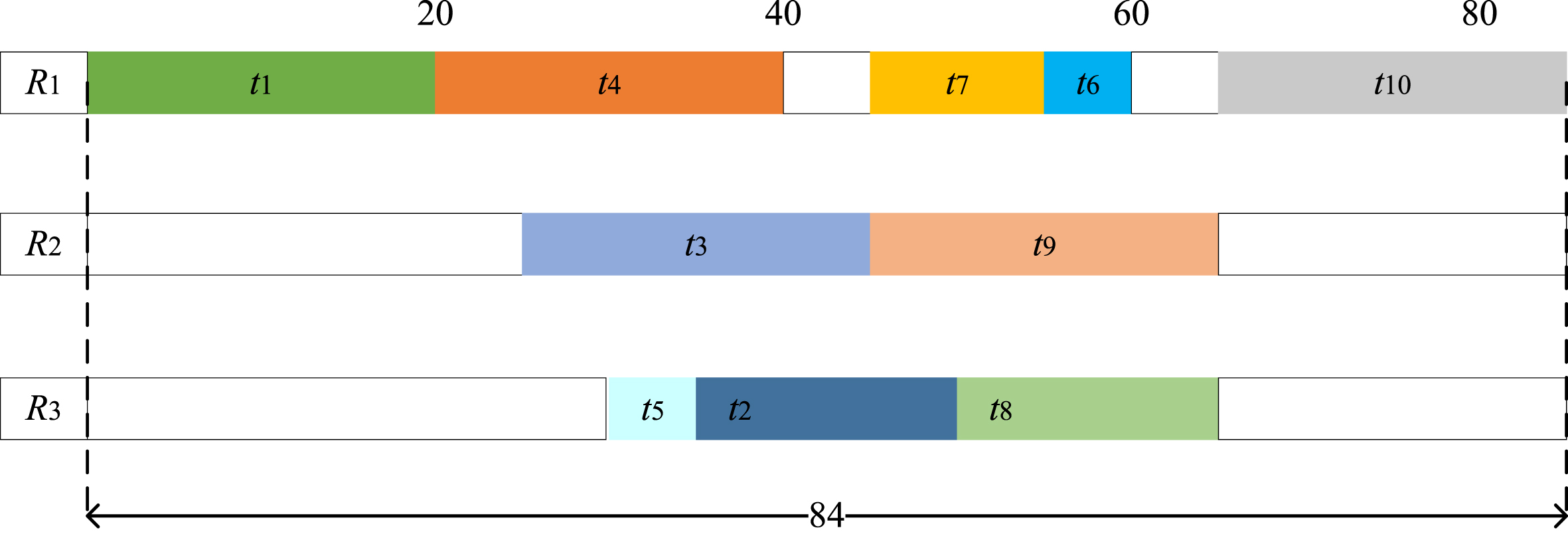
The makespan for the WfSTFN scheduling approach.
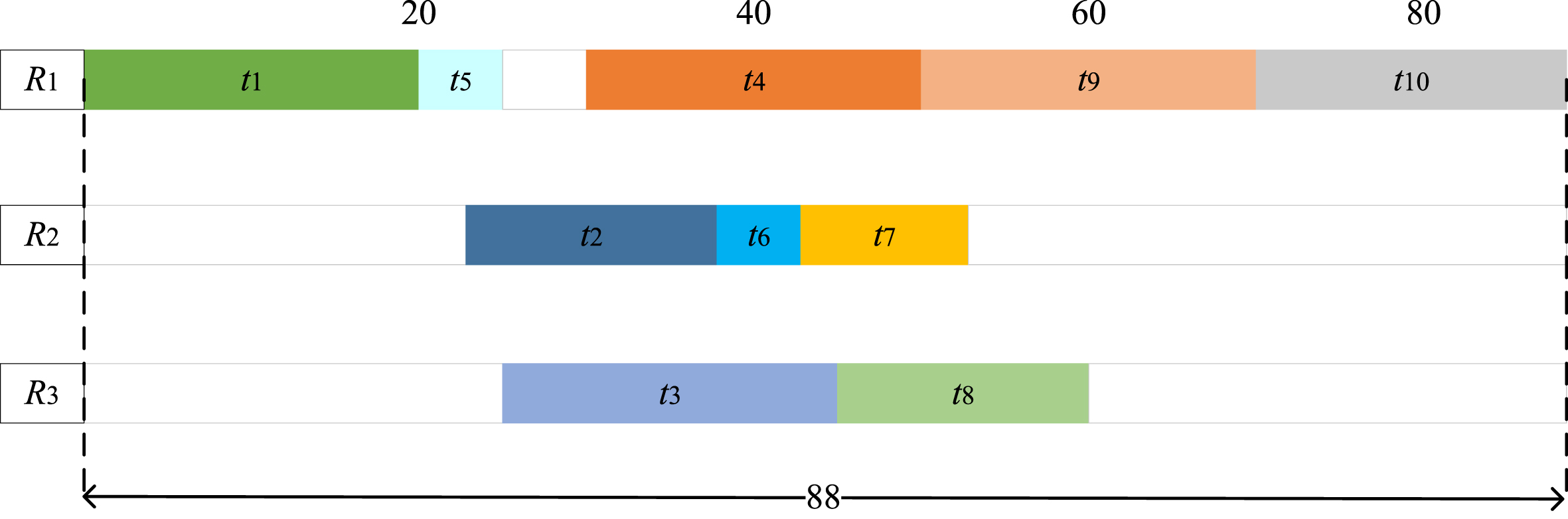
The makespan for the ETF scheduling approach.
In this paper, we started off with identifying the general problems of scheduling tasks with fuzzy completion time in a distributed computing environment. We proposed a novel workflow scheduling method for distributed systems based on triangular fuzzy numbers approach (WfSTFN), which could minimize the makespan of the workflow application. The main idea of WfSTFN approach is to achieving user QoS requirements as well as the performance of the system. A numerical example was illustrated to demonstrate the effectiveness of our proposed method. In this study, we only consider the single-entry-single-exit workflow structure problem. In the future work, we would like to consider more complexity structure with multiple-entries-multiple-exits workflow.
Compliance with Ethical Standards
Funding: This research is supported by the Fundamental Research Funds for the Central Universities (No. XDJK2019C085) and Chongqing Overseas Scholars Innovation Program (No. cx2018077).
Disclosure of potential conflicts of interest: Author F.X. declares that she has no conflict of interest. Author Z.Z. declares that he has no conflict of interest. Author A.J. declares that he has no conflict of interest.
Research involving human participants and/or animals: This article does not contain any studies with human participants or animals performed by any of the authors.
Informed consent: Informed consent was obtained from all individual participants included in the study.
Footnotes
Acknowledgment
The author greatly appreciates the reviews’ suggestions and the editor’s encouragement.