
Abstract
In the multi-attribute decision-making problems, uncertain information can be well-represented by single-valued neutrosophic linguistic sets (SVNLSs); Decision makers’ risk attitudes toward gains and losses can be solved by prospect theory (PT). Based on both, a novel integrated fuzzy decision method is proposed which combines SVNLS and PT (SVNLS-PT). In this method, we extend linguistic scale function to adapt the single-valued neutrosophic linguistic environment. Following that, we introduce the operational laws, some aggregation operators and the distance calculating method of SVNLS. Besides, PT is employed to rank the alternatives. In order to reflect both subjective considerations of decision makers and objective information, weights of attributes are combined by objective weights and subjective weights which objective weights are obtained by mean-squared deviation method and subjective weights by establishing the liner programing model. Finally, a case study concerning investment project of Internet of Vehicles is provided to illustrate the applicability of the proposed method.
Keywords
Introduction
In the multi-attribute decision-making (MADM) problems, due to limited ability of human beings and complexity of decision-making environment, the evaluation values of attributes cannot always be expressed by scrip numbers. Usually through fuzzy information, such as fuzzy numbers [13], linguistic variables [12, 26], preference presentation structures [3, 37] and so on. Thus, many different theories and methodologies have been developed in the literature to represent and manage different types of uncertainty under these circumstances [2, 36].
Many researchers paid attention on how to express uncertain information, which some introduced fuzzy set and extended fuzzy set to do it. Zadeh [19] proposed the concept of fuzzy set (FS), which depicted uncertain information by the membership function. However, in some cases, FS cannot fully reflect uncertainty. For this reason, Atanassov [18] proposed the concept of intuitionistic fuzzy set (IFS), which considered both membership degree and non-membership degree. The sum of membership degree and non-membership degree of a vague parameter is less than unity. Therefore, a certain amount of incomplete information or indeterminacy (hesitancy degree) arises in an intuitionistic fuzzy set. IFS has applied successfully in various fields [7, 26], such as Xian et al. [26] combined interval intuitionistic fuzzy language with TOPSIS method to establish multi-attribute group decision-making model; Taking the advantages of linguistic intuitionistic fuzzy sets and preference, Meng et al. [7] proposed the linguistic intuitionistic fuzzy preference and studied their application to decision making.
However, FS and IFS cannot handle all types of uncertainty successfully in different real physical problems such as problems involving indeterminate and inconsistent information. From this perspective, Smarandache [8] firstly put forward the concept of neutrosophic set (NS) by adding an indeterminacy membership on the basis of IFS, which means decision makers (DMs) can use truth membership, indeterminacy membership and falsity membership simultaneously and independently. Thus, NS which is an extension of FS and IFS, gives the better way out to deal with indeterminate and inconsistent information and further tackle the decision-making problems. In follow studies, some researchers proposed some subclasses of NS for applications in real scientific and engineering areas, such as single-valued neutrosophic sets (SVNSs) [10] and interval-valued neutrosophic sets (IVNSs) [9]. Also many scholars made deep studies on the properties, aggregation operators and distance measures of NS. Wu [30] defined the distance of NS through cross-entropy; From fuzzy cross-entropy and singled valued neutrospohic cross-entropy, Şahin [25] defined the interval neotrosophic cross-entropy and applied it to MADM problems; Ye [16] proposed an aggregation operator of simple NS, but this operator was not applicable in some cases; Peng et al. [14] revised it and proposed a new aggregation operator. Recently, some scholars combined SVNSs with other ranking methods, such as ELECTRE, MABAC [24] and TPOSIS [17], and established MADM models in neutrosophic environment.
Other researchers think uncertain information is easier represented by linguistic variables, especially for qualitative attributes in the MADM problems. Computing with words [6] and consensus reaching process [11] play important roles in the linguistic decision making. Dong et al. [31] defined the concept of numerical scale for computing with words, and developed an optimization model to compute the numerical scale of the linguistic term set through defining the concept of the transitive calibration matrix and its consistent index; Based on the extended linguistic hierarchies, zhang et al. [36] proposed a novel computational model which can operate with multi-granular linguistic distribution evaluations and provide interpretable linguistic results to DMs; Considering words may mean different things for different people, Li et al. [4] proposed personalized individual semantics model which is carried out by the fuzzy envelopes of hesitant fuzzy linguistic terms sets based on the personalized numerical scales of linguistic term set. Wu et al. [32] developed a linguistic group decision making model with flexible linguistic expressions and the consensus rules with minimum preference-loss were designed to support the consensus reaching process; About consensus reaching process, Li et al. [5] proposed a consensus model based on personalized individual semantics to improve the willingness and achieve a consensus; Zhang et al. [13] developed a 2-rank consensus reaching with the minimum adjustments to achieve a consensus under the multigranular linguistic context; Zhang et al. established minimum information loss consensus model with heterogeneous preference structures [3] and hesitant fuzzy linguistic term sets [2] respectively in the group decision making problems.
Numerous researchers have determined the advantages of linguistic variables in the neutrosophic linguistic environment. Ye [17] put forward the concept of single-valued neutrosophic language set based on SVNS; Wang et al. [15] applied Maclaurin symmetric mean operators to single-valued neutrosophic linguistic number; Liu et al. [23] defined the bidirectional projection measure of linguistic neutrosophic numbers and applied it to solve multi-criteria group decision making problems. Thus, linguistic variables [20] are really efficient and powerful to denote the qualitative evaluations of the DMs.
The above decision-making models have important contributions to MADM problems with the uncertain information. However, these are mostly based on the assumption that DMs are totally rational. In realistic decision-making process, DMs do not behave in a completely rational manner, almost bounded rationally. This practical situation is a significant issue in constructing these MADM models. Many researchers considered that prospect theory (PT) proposed by Kahneman and Tversky is one of the most influential psychological behavior theories [1]. Following that, several scholars extended PT into MADM context [27, 28] and these studies have shown that decision making based on PT is more consistent with DMs’ behavior, such as Yu et al. [27] developed an extended TODIM method with unbalanced hesitant fuzzy linguistic term sets.
Single-valued neutrosophic linguistic sets (SVNLSs) can partly make up for some limitations that other fuzzy sets cannot represent indeterminacy directly. Consequently, SVNLSs are needed to express evaluations in the MADM problems. On other side, the bounded rationality of DMs is essential to consider dealing with MADM problems in practice. However, as demonstrated above, most existing methods under single-valued neutrosophic environment disregarded the psychological behavior of DMs. Obviously, PT is good tool to deal with this issue. Considering the advantages of NS and PT, a new approach called SVNLS-PT is proposed for solving MADM problems which expresses evaluation values through SVNLSs and ranks alternatives through prospect matrix. Plus, this paper presents an extended linguistic scale function for defining basic operational relations and distance measures between single-valued neutrosophic linguistic numbers (SVNLNs).
The contributions of this paper are threefold: (1) The novel expressing form for evaluation values: the single-values neutrosopohic linguistic variables combined linguistic variables and single-valued neutrosophic numbers which can depict information regarding the confidence degree of the linguistic part perfectly, especially can determine the indeterminacy degree directly; (2) Taking into full consideration the DMs’ bounded rational behavior in face of risk: the proposed method is based on prospect theory, which depicts decision-making behavior under bounded rationality. (3) Weight method: our method combines objective weights and subjective weights which objective weights are determined by mean-squared deviations and subjective weight by establishing a liner programing model of maximizing the prospect value. Finally, an illustrative example including sensitivity analysis and comparison analysis is taken to verify the applicability and effectiveness of the proposed method.
The structure of this paper is organized as follows. Section 2 introduces definitions that will be used in the MADM problems. Furthermore, we extend the linguistic scale function. In Section 3, we construct SVNLS-PT method and a generalized distance between SVNLNs and aggregation operators based on the extended linguistic scale function are proposed. Section 4 provides an illustrative example of investment project of Internet of Vehicles. The effectiveness and performance of the proposed method are verified by sensitivity analysis and compared with SVNLTS-TOPSIS. Finally, section 5 concludes the paper and points out the future researches.
Preliminary definitions
Thus, the SNS satisfies the condition: 0 ≤ TA(x) +IA(x) + FA(x) ≤ 3.
Example 1: Given the following LTS:
The discrete linguistic terms may lead to the loss of information in the computational process. Thus, Xu [34] extended the LTS to a continuous form
Then, for any two linguistic variables s
i
and s
j
, they must satisfy the following characteristics: The set is ordered: s
i
> s
j
, if i > j; Negation operator: neg (S
i
) = S
j
if j = 2t - i; Maximum operator: max (S
i
, S
j
) = S
i
, if s
i
≥ s
j
; Minimum operator: min (S
i
, S
j
) = S
j
, if s
i
≥ s
j
.
The linguistic scale function based on the subscript function (sub (s
x
) = x) of linguistic terms is defined as
The function is strictly monotonically increasing and continuous. Obviously, f(sθ(xi)) ∈ [1/2t + 2, t+1/2t+2].
Example 2: Suppose S = {s0, s1, s2, s3, s4, s5, s6}. Then f (s0) =0.125, f (s1) =0.25, f (s3) =0.5, and f (s6) =0.875.
a × b = 〈f-1 (f (sθ(a)) × f (sθ(b))) , (T
a
T
b
, I
a
+I
b
- I
a
I
b
, F
a
+ F
b
- F
a
F
b
) 〉 ; λa =〈 f-1 (λf (sθ(a))) , (T
a
, I
a
, F
a
) 〉 ; a
λ
= 〈f-1 ((f (sθ(a)))
λ
, ((T
a
)
λ
, 1 - (1 - I
a
)
λ
, 1-(1 - F
a
)
λ
)〉 ; neg (a) = 〈f-1 (f (sθ(2t)) - f (sθ(a))) , (F
a
, 1 - I
a
T
a
) 〉.
The accuracy function of can be defined as follows:
The certainty function of can be defined as follows:
If S (a) > S (b), then a ≻ b; If S (a) = s (b) , A (a) > A (b), then a ≻ b; If S (a) = s (b) , A (a) = A (b) , C (a) > C (b), then a ≻ b; If S (a) = s (b) , A (a) = A (b) , C (a) = C (b), then a = b.
In the risky MADM problems, suppose that A = {A1, A2, …, A
m
} and C = {c1, c2, …, c
n
} are the sets of alternatives and attributes respectively. Let ω = (ω1, ω2, …, ω
n
)
T
be the weight vector of attributes, such that
Where
The distance measure and aggregation operators for SVNLNs
Based on the extended linguistic scale function (definition 3 in the section 2), this paper proposes a generalized distance measure of SVNLNs.
When p = 1, Equation (7) reduces the Hamming distance; and when p = 2, Equation (7) reduces to the Euclidean distance. Based on Equation (7), it can be easily shown that the provided distance measure satisfies the properties of the metric space described in Theorem 1.
Theorem 1. Let a, b, c be SVNLNs. The distance d (a, b) satisfies the following three axioms: d (a, b) ≥0, if a = b, d (a, b) =0; (Positivity) d (a, b) = d (b, a); (Symmetry) d (a, b) + d (b, c) ≥ d (a, c). (Triangle inequal ity)
If the weight vector
PT established by Kahneman and Tversky in 1979, is a descriptive theory based on a series of psychological experiments and describes the DMs’ decision behavior under risk and uncertainty [1]. Prospect values are determined by both value function and weight function.
w (p
i
) is the weight function. V (Δx
i
) is the value function which reflects the DMs’ subjective attributes. Δx
i
= x
i
- x0 represents the deviation degree between the existing prospect value and reference point x0, gains if positive, losses otherwise. With the knowledge of the PT, the reference point can be specified by the following methods: (1) the zero point, (2) the mean value, (3) the medium value, (4) the worst value and (5) the best value. We formally consider rational expectations as a reference point. So we use the medium point 〈s
t
, (0.5, 0.5, 0.5) 〉 to derive the prospect values. In the neutrosophic linguistic environment, the value function is calculated based on the distance between alternatives and reference point. Prospect values under neutrosophic linguistic environment are as follows:
where
Figure 1 gives a sketch of value function. The larger α and β, more risk-taking the DMs are inclined to take. θ is the loss avoidance coefficient. θ > 1 means that the loss area is steeper than the gain region, and θ is larger, indicating that the DM is more averse to loss. w (p i ) is the weight function. p k represents the probability of the status ɛ k being occurrence in decision-making process. When p is small, w (p) < p, it means that DMs overestimate small probability events; when p is large, w (p) < p, it means that DMs will ignore large probability events. The probability weight function w (p) is shown in Fig. 2.
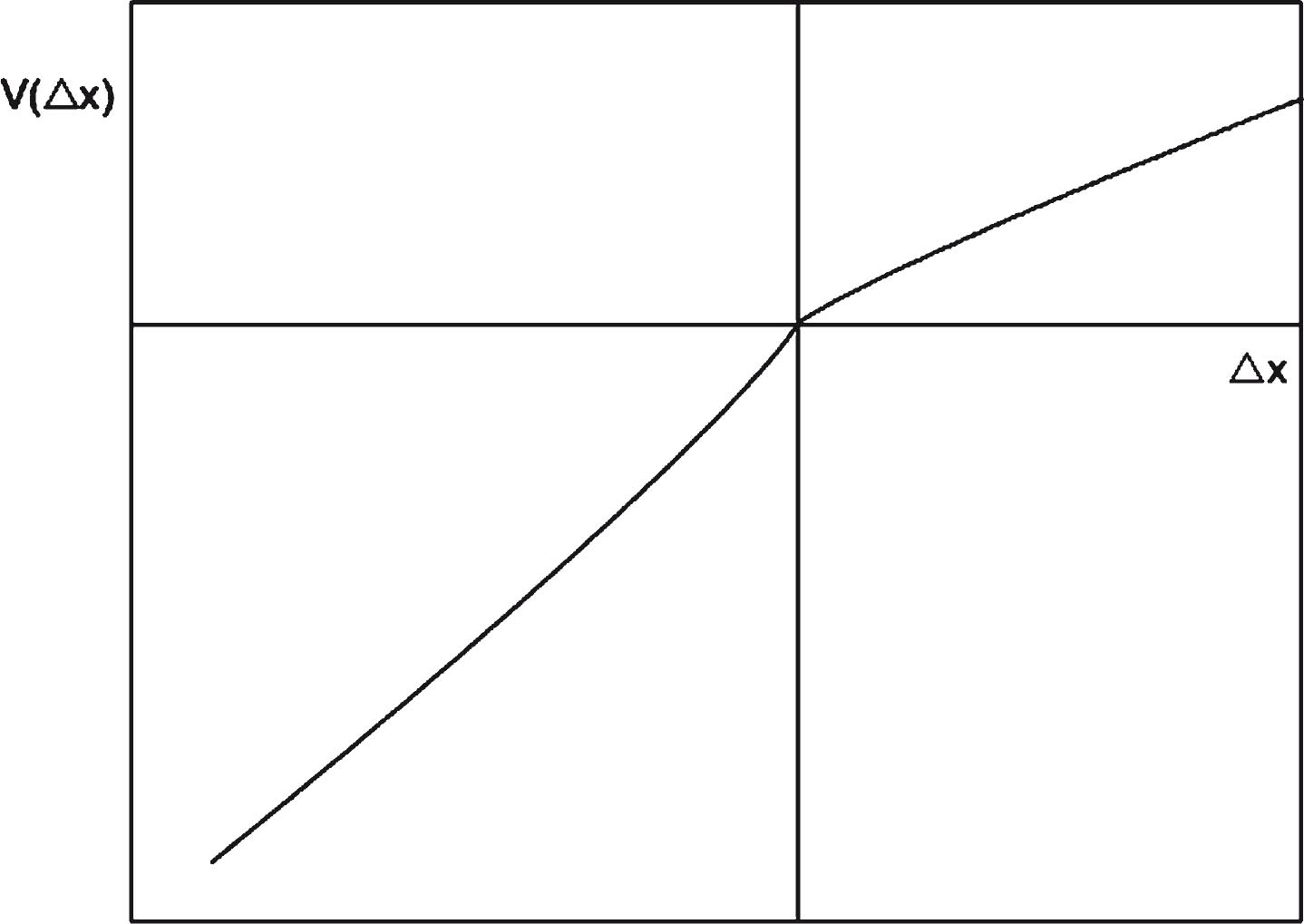
Tthe value function V (Δx i ).
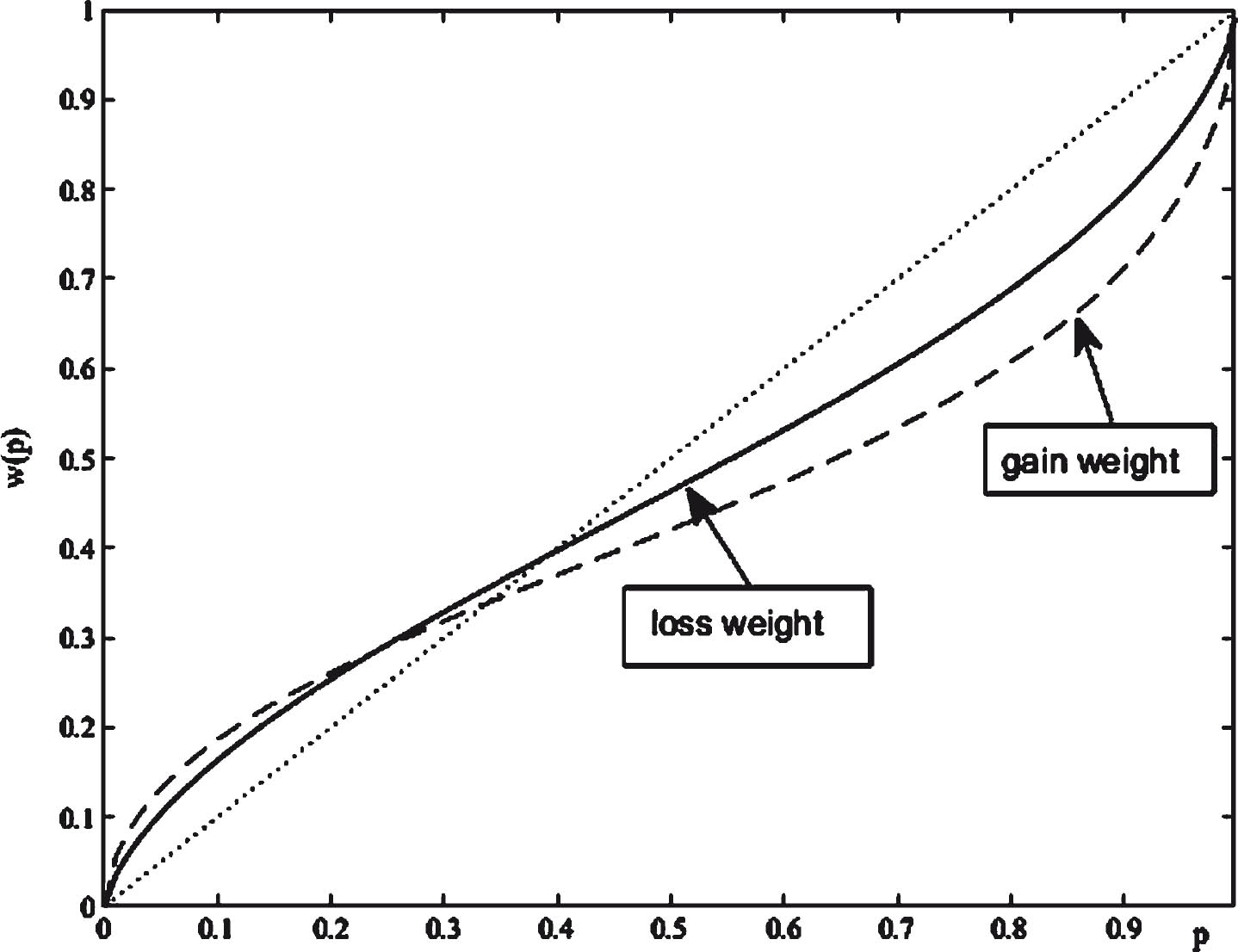
Tthe probability weight function w (p).
In this paper, weights of attributes are determined by combining objective weights with subjective weights through geometric average. Objective weights are determined by mean-squared deviation, and subjective weights by establishing the liner programing model of maximizing prospect values.
Determining objective weights of attributes by mean-squared deviation method
The main idea of mean-squared deviation is that if one attribute makes the evaluation values of each alternatives similar, it should be assigned a small weight; otherwise, the attribute is weighted by the degree of its own importance, and the importance of the attribute is measured by the deviations. An attribute which makes larger deviations should be assigned a bigger weight.
The mean values of the attributes are calculated according the Equations (12–14).
The mean-squared deviation value σ (A
j
) against C
j
can be using Equation (14):
The objective weights φ
j
can be obtained by using Equation (15):
For each alternative A
j
, DMs always hope that the bigger prospect values are, the better the alternative is. ψ is the set of DMs’ subjective preference relationship which can be expressed by ψ
i
≥ ψ
j
; ψ
i
- ψ
j
≥ α ; ψ
i
≥ β ψ
j
; ψ
i
- ψ
j
≥ ψ
k
- ψ
l
(i ≠ j ≠ k ≠ l). In this paper, partial preference of attributes is given by DMs directly. Then, subjective weights of attributes are obtained by establishing the liner programing model.
We can get subjective weight vector ψ = (ψ1, ψ2, …, ψ n ) T .
We combine objective weights and subjective weights through geometric average operator. Consequently, we can get attribute weight ω = (ω1, ω2, …, ω
n
)
T
as follows:
In summary, the process of decision making based on the PT for selecting the optimal under the neutrosophic linguistic environment can be described in following steps:
Step 1. Normalize decision matrices.
Based on the principle of attributes category, decision attributes can be divided into two types: cost attributes and benefit attributes. Thus, decision matrices of each status
Step 2. Obtain prospect matrices.
The prospect values V = (v ij ) m×n are calculated by Equation (11) and prospect matrices are obtained. In the Equation (11), the gains and losses of evaluation values are obtained by comparing the SVNLNs based on Equations (4–6), and the distance d (x ij , x0) is computed by Equation (7) which we set 〈s t (0.5, 0.5, 0.5) 〉 as the reference point x0 as demonstrated in the section 3.2. The values of α, β, γ and δ are determined through experiments which Kahneman et al. [1] concluded that α = β = 0.88, θ = 2.25, γ = 0.61, δ = 0.72.
Step 3. Calculate attribute weights.
The objective weight φ j is obtained based on the mean-squared deviation of attributes through Equations (12–15). The liner programing model based on the prospect matrices is established by Equation (16) to obtain the subjective weight vector ψ. The weight vector ω is calculated by Equation (17).
Step 4. Calculate the integrated prospect values.
The integrated prospect vectors
Step 5. Rank alternatives.
According to the integrated prospect values, we can get the rank of all alternatives. The bigger
Internet of Vehicle (IoV) is emerging as an important part of smart or intelligent cities and developed around the world. There is a venture capital company which aims to provide funds into IoV projects to earn money. Many projects are put forward to be selected. After preliminary screening, four feasible projects A1, A2, A3, A4 are determined by the manager. The manager may lack necessary knowledge about the projects so that performances of the projects cannot be evaluated precisely. In this case, three experts are invited to help the manager assess the projects. The three experts forecast the future market will be under high risk (ɛ1), medium risk (ɛ2) and low risk status (ɛ3) respectively. The weight of the experts ω ɛ = (0.2, 0.6, 0.2) is determined which reflects the probability of the statuses. Four attributes to be considered in the evaluation process are c1: technical level; c2: market scale; c3: operation management; c4: exit risk. In fact, these four attributes can be considered as the consensus for the problem of portfolio selection.
The linguistic values with S = {s0, s1, s2, s3, s4} are used, namely, very bad, bad, general, good, very good. For example, the expert evaluates x1 against c1 using the linguistic value s3. Moreover, the experts provide the following information: (1) The degree of which he thinks the evaluation is true; (2) The degree of which he thinks the evaluation is indeterminate;(3) The degree of which he thinks the evaluation is false, which are 0.4, 0,6, 0.2 respectively. All the aforementioned information on x1 against c1 can be denoted by a SVNLN:
The single-valued neutrosophic linguistic evaluating matrix D1
The single-valued neutrosophic linguistic evaluating matrix D1
The single-valued neutrosophic linguistic evaluating matrix D2
The single-valued neutrosophic linguistic evaluating matrix D3
Step 1. Normalize decision matrices.
Since c4 is a cost attribute and the others are benefit attributes, so decision matrices can be normalized by using neg operators in the section 2. The normalized decision matrices are listed in Tables 4–6.
The normalized evaluating matrix R1
The normalized evaluating matrix R1
The normalized evaluating matrix R2
The normalized evaluating matrix R3
Step 2. Obtain prospect matrices.
In this evaluation process, the reference point is 〈s2, (0.5, 0.5, 0.5) 〉. The distance measure is computed by Equation (7) where p = 1. According to the Equation (11), the prospect values under each attribute of each alternative under each status are calculated. The prospect matrix V = (v ij ) m×n is obtained, as shown in Table 7.
Prospect decision matrix V
Step 3. Calcualte attribute weights.
Firstly, we can obtain the mean values of four projects against each attribute by using Equations (12-13). The results are presented as follows:
The mean squared deviation values of projects under attribute c j can be obtained by using Equation (14). Results are shown in the second column of Table 8. The objective weights are presented in the third column of Table 8.
The mean squared deviation value
Secondly, the manager put forward the following weight constraints: c1 is more important than c2, c2 is more important than c3, c3 is more important than c4; the weight of c1 is no less than 40% and the weight of c4 no less than 20%. Namely, ψ1 ≥ ψ2 ≥ ψ3 ≥ 4, ψ1 ≥ 0.4 . ψ4 ≥ 0.2. The liner programing model is established as follows.
We can get ψ
j
= (0.40, 0.20, 0.20, 0.20)
T
through MATLAB. According to Equation (15), calculate the combined weight vector:
Step 4. Calculate the integrated prospect values.
The integrated prospect values can be calculated through combining values weights in step 3 and the prospect matrices in step 2, namely,
Step 5. Rank alternatives.
Since
To analyze the influence of the attenuation factor of the loss θ, the proposed method is then implemented by setting different values of θ from 1 to 4 and the rankings of alternatives with different values of θ are demonstrated in Fig. 3. It can be observed that the best alternative is always A1 and the worst alternative is always A2, while the ranking of A3 and A4 is different with different values of θ. When θ ⩽ 2.25, a ranking result is obtained, i.e., A1 ≻ A3 ≻ A4 ≻ A2, and the ranking result is changed when θ > 3, i.e. A1 ≻ V4 ≻ A3 ≻ A2. In this case, there is obvious effect on ranking results with changing θ, which demonstrates that the psychological behavior of decision makers will have effect on the decision results.

Sensitivity analysis of the prospect results about θ.
In addition, it is worthy pointing out that the above sensitivity analysis is based on the weight of experts ω ɛ = (0.2, 0.6, 0.2). In what follows, we carry out the sensitivity analysis of experts’ weight which reflects changes of assessment for the future market risk. We assume θ = 2.25, and the sensitivity analysis is performed by modifying the weight vector of experts. Ranking orders are recalculated that are shown in Table 9.
The ranking orders of alternatives with different weight of experts
From Table 9, it is apparent that the ranking orders of alternatives are different, and the results may lead to different decisions. So, when unknown experts’ weight, it is important to choose an appropriate method for determining it.
A comparative analysis is conducted to demonstrate the effectiveness of our proposed SVNLTS-PT approach. The method SVNLTS-TOPSIS which was proposed by Ye [17], is applied for the above case study. Due to the method limitation, the ranking results are calculated respectively under three risk statues, which the results are listed inTable 10.
Ranking results by [18]
Ranking results by [18]
The decision-making results under the three risk statuses are different. In other words, we can only draw corresponding conclusions for different risk states, and it is difficult to draw a definite conclusion. Furthermore, we can get a comprehensive ranking result through expected utility theory: A4 ≻ A3 ≻ A1 ≻ A2 The best alternative conducted by SVNLTS-PT and SVNLTS-TOPSIS are respectively A1 and A4. The main reason behind difference is that SVNLTS-PT considers the DMs’ bounded rationality behavior in the decision-making process, while the SVNLTS-TOPSIS assumes a complete rationality of the DMs. So SVNLTS-PT produces more suitable decision results according to the DMs’ actual preference.
According to the results of sensitivity analysis and comparative analysis, the characteristics of the proposed approach can be summarized as follows: An extended linguistic scale function is proposed to conduct the transformation between qualitative and quantitative data in this paper. And it can preserve decision information as much as possible. Following this, an extended distance measure and aggregation operator are developed. In the proposed approach, SVNLS is combined by linguistic term and SVNS which make it own advantages of the both. So SVNLS can better represent qualitative data involving uncertain and inconsistent information given by DMs. Based on combined weight method, both subjective and objective weights of evaluation attributes can be considered which can reflect both the deviations of alternatives and DMs’ subjective information. What’s more, it makes the proposed approach more practical and flexible. With the PT, the proposed method can deal with MADM problems and consider the psychological behavior of DMs during the process. As a result, a more accurate ranking of alternatives can be derived.
Conclusion
To handle the MADM problem with much uncertain information, an extended method based on SVNLS and PT, called SVNLS-PT is put forward in this paper. SVNLS can describe decision-making information, which further quantifies the uncertainty to a certain extent and avoids the loss and distortion of information as much as possible. The PT based on bounded rationality hypothesis reflects the different risky attitudes of DMs to gains and losses, which makes the decision-making results more reasonable. Thus, SVNLS-PT method is proposed based on the PT under the neutrosophic linguistic environment. Furthermore, we extend the distance measure and aggregation operators of SVNLNs through the extended linguistic scale function. Besides, we take into account subjective and objective weights together which reflects both the deviations of alternatives and DMs’ objective attitudes. Finally, an illustrative example is given. Sensitivity and comparison analysis shows the method’s effectiveness and practicability in solving risky MADM problems.
Several interesting directions may be investigated in our future research. Firstly, some parameter settings depend on every realistic decision circumstance in the PT, such as that the selection of the reference point in PT is largely based on the DMs’ preferences and it is featured with great subjective randomness. Therefore, in the future research, we can further study how to better set the reference points in the PT. Secondly, with increasing social demand, decisions need to be made by a large number of DMs and consensus should be considered. Thus, future research can extend the proposed approach by introducing a reasonable consensus mechanism to deal with large numbers group decision making problems.
Footnotes
Acknowledgments
This work was supported in part by a grant from National Social Science Foundation of China (No. 11BGL089), Hebei Provincial Social Science Foundation of China (No. HB18GL008) and Post-graduate’s Innovation Fund Project of Hebei University (No. hbu2019ss044).