
Abstract
The traditional fixed sampling interval (FSI) synthetic
Introduction
Faced with fierce competition in today’s global marketplace, for a manufacturing enterprise, quality of production is one of the key factors for the success. Statistical process control (SPC) is a significant method of quality control in which statistical methods are employed to monitor processes and ensure quality. In SPC, control chart is nowadays well established graphical and statistical tool which adopts random sampling to test, record, monitor and assess the quality characteristics of interest gathered from intelligent manufacturing process to detect if the process is under control (Yen et al. [29]). In intelligent manufacturing monitoring, combining the control-chart scheme with other intelligent methods to make the original monitoring methods more efficient has attracted much attention. Such works can be seen in Han et al. [10], He et al. [12], Zhou et al. [34], and many more. Undoubtedly, a more sensitive control chart for the diagnosis of process shift can improve the detection capacity of the integration scheme. For this reason, the improvement of control chart remains a heated topic due to the search for precise methods of quality control.
Since the first control chart, that is,
However, the above-mentioned control charts all dealt with the fixed sampling interval (FSI) strategy. The approach to sampling for these control charts is to take samples from the process by using a fixed time interval between samples, and the control charts using this approach are usually called FSI control charts. As we know, to obtain a fast detection of process shifts is one of the main objectives of using control charts, so that the nonconformities can be produced as few as possible before the process shifts are eliminated. In order to utilize the inspection capacity more effectively for better process control, researchers put forward the concept of adaptive control charts in which at least one of design parameters (sampling interval h, sample size n and control limits coefficient k) is allowed to be changed based on the current state of the process. Generally, these adaptive control charts can be categorized into four types: variable sampling interval (VSI) control charts, variable sample size (VSS) control charts, variable control limits (VCL) control charts, and joint-adaptive control charts in which at least two of the design parameters can be changed simultaneously [33]. In general, the VSI scheme is used most often and also the most useful one due to its simplicity and good usability.
The basic idea of using the VSI scheme is: if the current sample indicates a potential shift in the process, the sampling interval before the next sample should be relatively short; but the sampling interval before the next sample should be relatively long if the current sample does not show a process change. When concerning the detection of process shifts, due to using a higher sampling frequency when some indication of a process shift is showed by a sample statistic, VSI control charts are always superior to the corresponding FSI control charts. Nguyen et al.[20] and Safe et al. [22] pointed out that, in long-run context, VSI control charts outperformed VSS and fixed ratio interval control charts for moderate to large process shifts. An extensive amount of works on VSI control charts has been done to improve the charts’ sensitivity for fast detection of process shifts. The most recent research on VSI control charts can be seen in Aslam and Khan [1], [11], Shirke and Barale [23], and so forth. However, we found that although there are some research indicating the benefit of using VSI strategy for
On the other hand, the development of control charts usually assumes the process parameters are known. However, the process parameters are generally unknown in practice. Often the process parameters are estimated by using an in-control historical data set which is collected from Phase I. Undoubtedly, due to the randomness and variability of the estimators adopted during Phase I, the performance of control charts with estimated parameters must be different from the known parameters case. Yeong et al. [30] concluded that regardless of parameter estimates in the design of control charts results in an increase in false alarm rate and an decrease in the ability of control charts to detect the process shifts. Therefore, it is important to discuss the optimal design of control charts in the case where the process parameters are estimated. Many scholars have concerned about this topic, and an early literature review on this topic is given by Jensen et al. [13]. More recently, Cheng and Wang [7], Khoo et al. [14], Mehmood et al. [19] and Zhang et al. [32] studied the optimal design of
Summarized literature review
Summarized literature review
In this paper, consider a process containing a single quality characteristic of interest (denoted by X) following a normal distribution with known mean μ and variance σ2, i.e. X ∼ N (μ, σ2). When the process is in control, μ = μ0 and σ = σ0. When the process is in an out-of-control state, the process mean changes from μ = μ0 to μ = μ0 + δσ0 (δ is the shift size coefficient) but the value of σ remains unchanged. Assuming that only the occurrence of assignable cause can result in the process mean shift. Additionally, the main objective of this paper is to detect the unilateral process mean shifts, therefore, all expressions are developed hereafter for the case δ ≥ 0.
This article is organized as follows. Section 2 gives an introduction of the FSI synthetic
The FSI synthetic

The FSI synthetic
The steps for developing and implementing the FSI synthetic Decide the LCL and UCL of the At every time interval of h hours, take a random sample of size n and calculate the mean If If The number of If CRL ≥ L, the process is still considered as in-control and the control flow returns to Step (2). If CRL < L, the synthetic chart produces an out-of-control signal and the control flow goes to Step (4). An investigation is executed to find and eliminate the assignable cause. Then go back to Step (2).
In Wu and Spedding [27]’s work, the optimal values of the design parameters, such as h, n, L and k, are chosen so as to minimize the out-of-control average run length (denoted as ARL1), with the requirement that must attain an in-control average run length (denoted as ARL0) equals to a pre-specified value.
The average run length (ARL) of the synthetic

A graphical illustration of the FSI synthetic
The VSI control charts are the sort of control charts in which the sampling intervals vary as a function of what is obtained from the target process. The idea of the VSI scheme is that the length of the next sampling interval should be short; if the position of the last plotted control-chart statistic shows a possible out-of-control situation; and long, if no indication of a change is found. Remarkably, if the indication of a process change is strong enough then a signal will be given as with a FSI scheme. In this section, the above concept is applied to implement the VSI feature on the synthetic
As Runger et al. [21] demonstrated, most of the gain in detection effectiveness that is attainable for a VSI chart can be achieved by using two sampling intervals and it keeps the complexity of VSI schemes to a reasonable level. Therefore, in the monitoring period, the proposed VSI chart provides two levels of sampling inspection: the normal inspection level h0 and the tightened inspection level h1 with h0 > h1 > 0. Without loss of generality, it is assumed that the process is in control at the beginning of the process monitoring so the normal inspection h0 is used as the start of monitoring.
The proposed VSI synthetic chart consists of an improved
In the literature, the most common assumption for implementing a control chart is that the process should be concluded to be out-of-control when a sample point beyond the control limits of the chart. The same assumption is used in this paper. In particular, unlike in the FSI synthetic chart, in our paper, a sample is classified as a nonconforming sample only if the sample mean falls in the warning region (i.e.
The VSI synthetic Decide on the sampling intervals, h0 and h1, and the sample size n. Determine the control limits (including LCL, LWL, UWL and UCL) of the Every h0 hours, a sample is taken and the sample statistic, If the sample statistic falls in the central region, i.e. If the sample statistic, If the sample produces a value in the warning region, i.e. Compute the CRL value and plot the value on the CRL sub-chart. If CRL ≥ L, the process is still in control, but the next sample will apply to the tightened inspection h1. If CRL < L, then the process will be deemed out of control and the control flow goes to Step (4). The process will be stopped, and an investigation action will be executed to eliminant the assignable cause. After that the out-of-control process will be brought back into an in-control condition. Then the process goes back to Step (2) and continues with process monitoring.

The
Figure 4 illustrates the decision procedure of the VSI synthetic

The control procedure of the VSI synthetic
It is noteworthy that Lee et al. [16] recently also proposed a VSI synthetic chart scheme. In their paper, the VSI chart model consists of a VSI
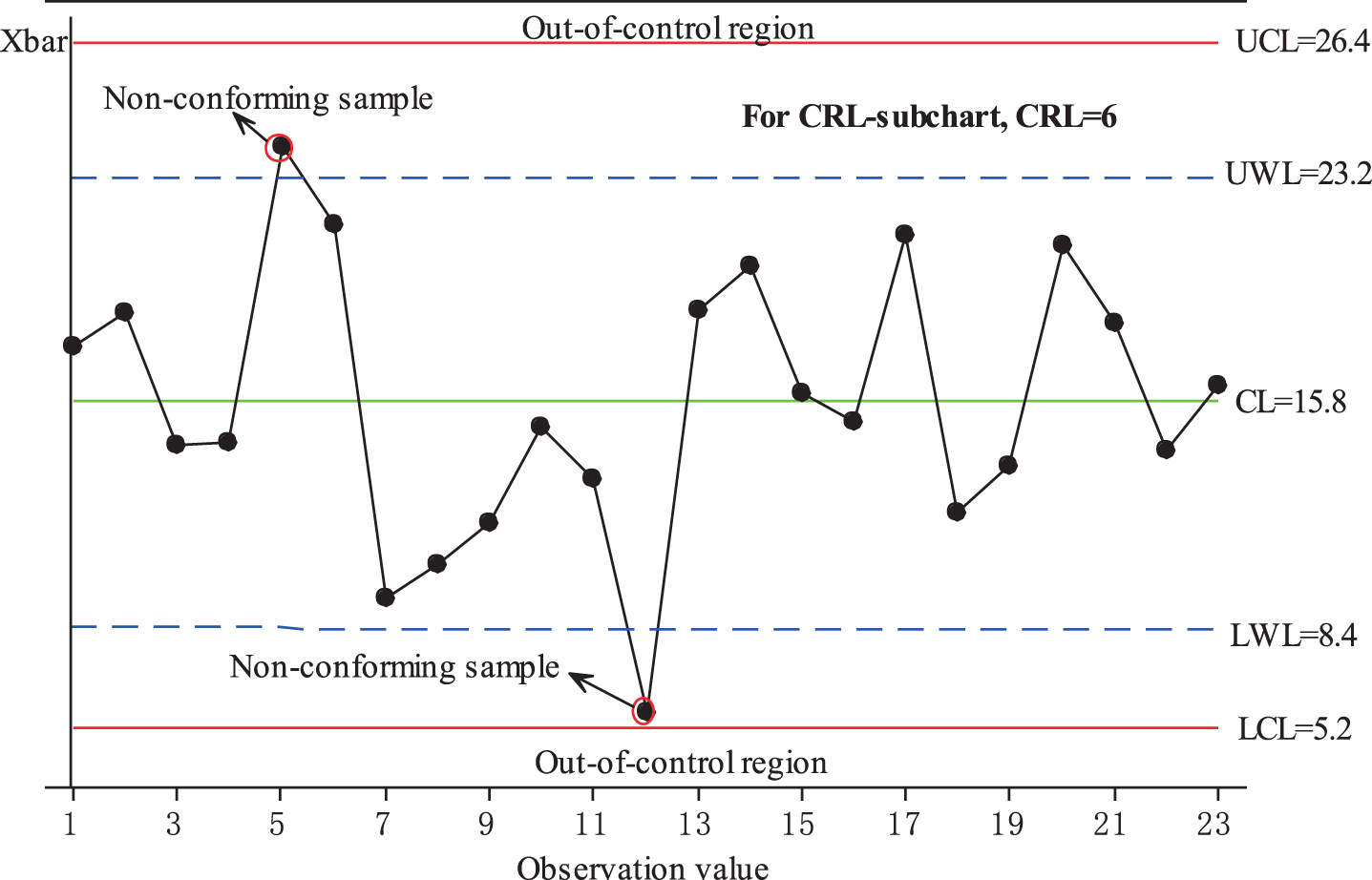
A graphical illustration of the FSI synthetic
Besides ARL, another two statistical indices, namely average time to signal (ATS) and adjusted average time to signal (AATS), are also widely used to evaluate the statistical performance of the considered control chart. Average Time to Signal (ATS), which refers to the average time from the start of the process to the time when an out-of-control signal is generated by the control chart. The in-control ATS, denoted as ATS0, is designed by quality assurance (QA) engineers to satisfy the requirement on false alarm rate. The out-of-control ATS, denoted as ATS1, is the expected value of the time to signal that the process is out of control when a process shift has occurred. Adjusted Average Time to Signal (AATS), which is defined as the expected time from the process mean shift to the time when the shift is truly signaled.
In this section, the Markov chain approach proposed by Davis and Woodall [9] is employed to compute the ARL, ATS and AATS of the VSI synthetic chart.
Let p1 denote the probability that a non-conforming
Let p2 and p3 denote the probability that a sample falls in the warning region and the central region of the
Then a Markov chain {N (i) , i ≥ 1} can be constructed to describe the VSI synthetic
For calculating the ATS and AATS of the chart, the steady-state probability of the process is required due to the uncertainty of the instantaneous probability of the process in each state.
Let π = {π0, π1, . . . , π
L
} be the homologous steady-state probability of the state space. Based on Markov theory, the following results can be obtained:
Then when the size of the mean shift is δ (≥0), the expected value of the average sampling interval Eh (δ) can be given by
The ATS of VSI synthetic
Carot et al. [4] assumed that the sojourn interval of the in-control state of process follows a uniform distribution for the calculation of AATS. The same assumption is adopted here. Then the AATS of VSI synthetic
Most of control charts are designed under the assumption that the process parameters are known. However, these parameters are almost impossible to be known and they have to be estimated from an in-control reference sample. In this section, we reconstruct the VSI synthetic
When the values of μ0 and σ0 are unknown, their estimators
These two estimators
When process parameters are known, the control limits of VSI synthetic
In the case where process parameters are estimated, the approach proposed by Zhang et al. [31] is adopted to compute the ARL of VSI synthetic
The estimators
Because
Because
The unconditional ARL and ATS under the case of process parameters estimation then can be calculated as
In order to obtain the optimal design parameters of VSI synthetic
As we can see, it is computationally complex to optimize the proposed statistical design model because the model is a non-linear model with mixed continuous-discrete decision variables. Genetic Algorithm (GA) is widely used in solving such optimization problems. Recently, successful applications of GA in the optimal design of control charts can be found in Bezerra et al. [2], Kosztyán and Katona [15], Wan et al. [25, 26], and so on. In this paper, a GA is constructed to solve the proposed model.
In the processing of using a GA, crossover operator and mutation operation are two crucial parameters that need to be set up. The values of these two parameters were determined by trial and error in our GA. Specifically, the population number, crossover rate, and mutation rate are set up to 700, 0.7 and 0.3, respectively. For our experiment, the solution process using the developed GA by MATLAB 8.3.0(R2014a) is concisely described as follows: Initialization: At the start of the GA procedure, 700 candidate solutions which meet the constraint condition of the parameter of individual test are randomly generated. Specifically, the constraint condition stand for individual test parameter is given below:
Evaluation: In this step, the fitness of individual solution is defined by computing the value of fitness function. For this study, the fitness function is shown in Eq.(32). Selection: Based on the fitness expression obtained in Step 2, 100 solutions that are probably going to be better fitness of solutions. Then these solutions are selected to breed the next generation. (In the selection, the chromosome with the lower AATS value is used to replace the higher AATS chromosome.) Crossover: During this phase, a pairs of parent solutions which come from the 100 solutions are chose randomly and employed for crossover operations to produce the new chromosomes of the next generation. In our experiment, the arithmetical crossover method with crossover probability 0.7 is adopted, which has the following form:
Mutation: The mutation rate used in this research is 0.3. The non-uniform method is employed to carry out the mutation operation. As mentioned above, there are 300 candidate solutions. Then, ninety chromosomes (i.e., 300 × 0.3 = 90) can be randomly chose to mutate some genes. Repeat the procedure from Step 2 to Step 5 until a stopping criterion is satisfied.
Performance comparisons
To investigate the performance of the VSI synthetic
The comparisons between VSI and FSI synthetic
charts in the known-parameter case
As a general rule, if a control chart has smaller AATS value when a specific process mean shift δ is given, the control chart is considered better than its competitors, under the assumption that the same ATS0 value is assigned to all considered charts. In this paper, for a fair comparison between the VSI and FSI synthetic
A comparison between the VSI and FSI synthetic
From Table 2, from the aspect of time up to signal, it is obvious to see that the VSI synthetic
The comparisons between other VSI
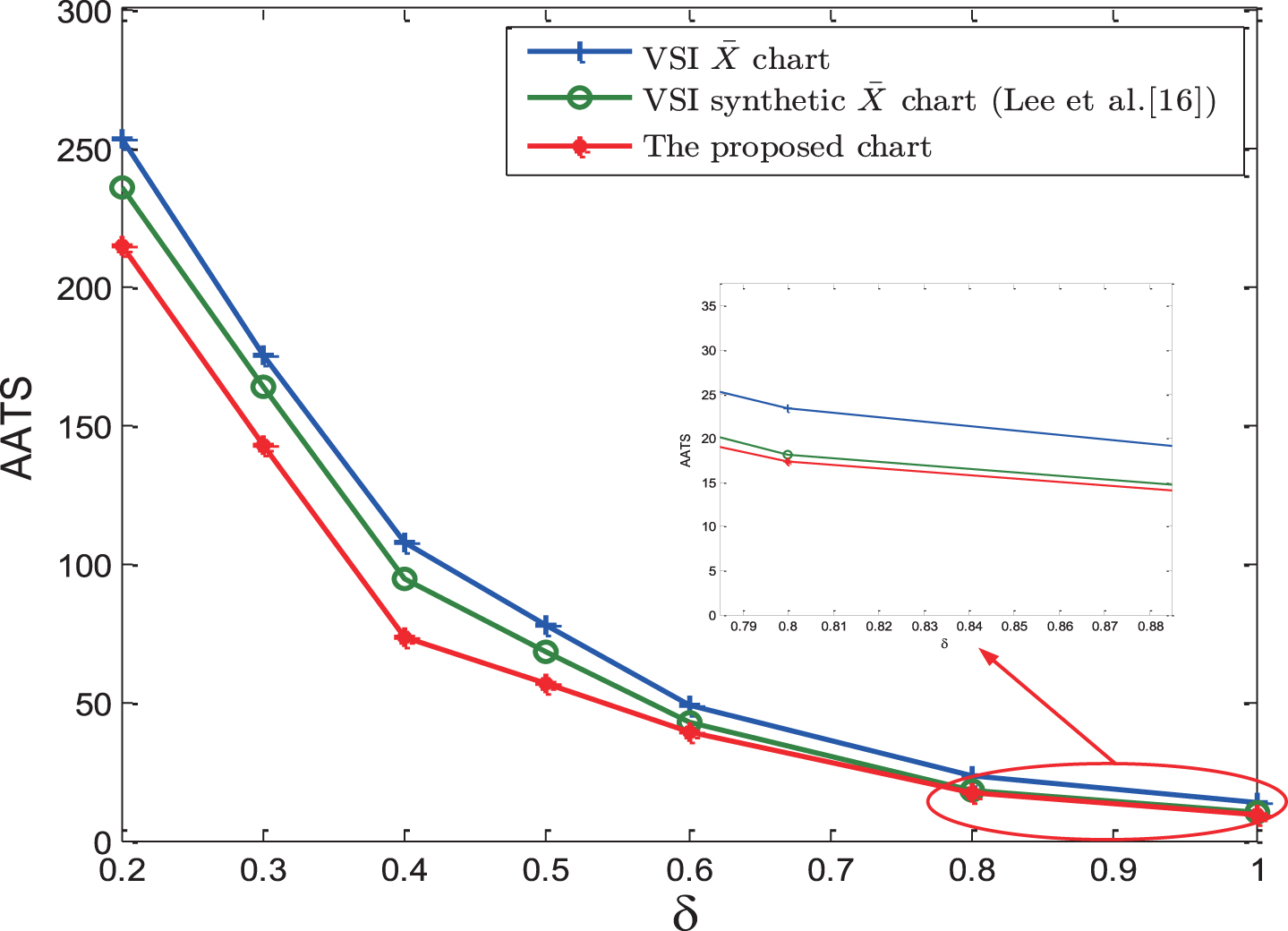
AATS for the VSI
From Figure 6, it is clear that the proposed synthetic
In this subsection, the effects towards AATS when the optimal parameters of VSI synthetic
Table 3 lists the AATS values and the increase in AATS values for the different number of subgroups. The increase in AATS is an increase from the optimal AATS obtained from the known-parameter case.
AATS values and increase in AATS by using the optimal parameters corresponding to the known-parameter case when process parameters are estimated
AATS values and increase in AATS by using the optimal parameters corresponding to the known-parameter case when process parameters are estimated
From Table 3, it is found that when the values of mean shift sizes δ are small, the increase in AATS becomes quit large. When the number of subgroups is small, the result will be more obvious. The reason may be that small process mean shift sizes leads to a poorer run length performance when estimated process parameters are adopted, consequently increasing the value of AATS. It is also found that the increase in AATS is not large when a moderately large number of subgroups is employed (m ≥ 20), except for small process shift. That is to say, in this condition, the optimal control chart parameters obtained from the known-parameter case can still be applied to estimate the AATS when estimated process parameters are used, with only a minute increase in AATS. Whereas the optimal control chart parameters obtained from known process parameters case can not be applied to safely estimate the AATS when estimated process parameters are used, since the time to signal a process shift will be increased. Meanwhile, it is worthy of note that when a large m is used, the increase in AATS becomes smaller for all cases. This indicates that as m increases, the AATS corresponding to the estimated-parameter case comes to that of known process parameters.
As mentioned above, when the parameters obtained from the known-parameters case are applied in the AATS computation when estimated process parameters are used, an increase in AATS will occur. Then the producer may want to know that how many the number of m of preliminary in-control subgroups for process parameter estimation should be used in order to have approximately the same AATS value for both the known-parameter and estimated-parameter cases. Define that
Table 4 lists the minimum value m* of satisfying Δ < 0.01, namely, such that the relative difference between the AATS corresponding to the estimated process parameters case and the AATS corresponding to the known process parameters case is not larger than 1%.
Minimum values m* of satisfying Δ < 0.01
From Table 4, we can found that for small values of δ, the value of m* satisfying Δ < 0.01 is quite large. Therefore, under these cases, the AATS difference between the estimated parameters and known parameters cases is small only when a large numbers of preliminary in-control subgroups is available. Conversely, for large values of δ, only a moderately large m* should be used so that the AATS difference can be less than 1%.
Table 5 lists the AATS values which are calculated by employing the optimal parameters corresponding to the case of estimated process parameters and savings (with regard to the AATS values in Table 3). From Table 5, we find that the smaller the shift size and the smaller the number of subgroups m, the larger will be the savings. When one of the two parameters (i.e. δ and m) is big enough, the savings are small. In short, it can be concluded that in the case of estimated process parameters, the AATS calculated by using the optimal parameters associated with the case of estimated process parameters is always smaller than that of using the optimal parameters associated with the known process parameters case. Therefore, in the estimated process parameters case, due to the fact that the AATS decreases along with the increase of the number of subgroups m, a large amount of preliminary subgroups should be employed whenever possible.
AATS values and savings when chart’s optimal parameters corresponding to the estimated process parameters case are used
The main purpose of this study is to propose an improved VSI synthetic
As an attempt of improving the FSI synthetic
Footnotes
Acknowledgments
We sincerely thank the anonymous reviewers for their valuable suggestions and comments. We also wish to thank the editor for handling this paper. This research is supported by the Soft Science Research Plan Project of Henan Province (202400410105), the Key Scientific Research Project of Colleges and Universities in Henan Province (20A630030) and the Nanhu Scholars Program for Young Scholars of XYNU.