
Abstract
Telecom sector is hugely losing profits in different degrees due to various undesired classes of its customers. Churners, a certain class of customers shifting to the competitors, are the most undesired class of customers who are the predominant reason for the losses. Still, there are other classes of customers in this business who stay with the enterprise, but they are inactive in using the services and leading to uncertainty and an insignificant amount of profits. When data mining techniques are applied to such applications they produce customer models in the form of decision trees, etc. and provide customer’s class label only such as churner/non-churner. Furthermore, they only focus on improving the technical interestingness measures of prediction models. Thus, very limited research has been carried out on turning the prediction results into useful decision making actions. Consequently, some manual work by domain expert has to be done to postprocess the model to obtain the actionable knowledge for changing the customer from undesired class to the desired one. However, some of the existing works are suggesting the actions to convert the class of the customer from one category to another, but they have limitations in that they do not generalize to more than two classes. In this paper, a novel algorithm, which aptly fits the multi-class setting of Telecom sector, is presented that suggest actions to change the customer from an undesired class to a desirable one with maximum net profit. We explain our proposed method with the help of a case study of the Telecom sector. Empirical tests are conducted on the case study problem and also on UCI benchmark data and shown that our method is effective and scalable. With the help of comparison with state-of-the-art methods and substantial experiments, we demonstrate the efficiency of the proposed method.
Keywords
Introduction
Telecom service providing industry is facing more competition in recent years. With enormous industry deregulation, customers of this sector are more transient and have more options and they are easily shifting to other service providers [21]. The trend which denotes the loss of a customer to competitors is known as customer ‘churning’ or ‘attrition’ which is leading to a huge fall in the profits of the service providers. Telecom industry is highly affected due to this nature of the customers. Therefore, stopping attrition, and increasing profits by taking necessary actions receives huge attention in this industry. Low service levels provided to the customer, aggressive competitive strategies, new products, regulations, not up to date with the technology etc., could be other reasons for churning in this sector. Acquiring new customers is really a tough task in any business rather than retaining existing customer. Hence, now the Telecom sector is focussing more on retaining their existing customers. Therefore, it is necessary to take essential steps to retain the customers in the Telecom sector. In general, retaining the existing customers is cheaper than acquiring new customers [13]. To remain profitable in their business, Telecom industry is consistently putting efforts to hold its customers. In this direction, it organizes customer retention campaigns with the objective of detecting which existing customers are intending to shift to the competitor and provide suitable offers and benefits to them to avoid churning. Telecom service providers normally have a huge number of customers, and therefore, detecting probable churners with the help of customer retention campaigns can be really a tough task. Hence, service providers are depending on churn prediction models of machine learning to find potential churners. When existing customers’ data (personal, demographic, behavioral details, and services provided, etc.), is given as input to the churn prediction model, it specifies which customers will be the likely churners. By using the output produced by the churn prediction model, the service providers with the help of domain experts do some manual work and can determine some possible personalized actions to make the likely churners satisfied and stay with them. Due to this reason, churn prediction models are vastly researched. For churn prediction, enterprises use various machine learning techniques [8, 43] to discover the hidden patterns and relationships between instances and their features in huge data.
Many researchers of the machine learning community have proposed different techniques in order to handle the problem of churn prediction in the Telecom and other enterprises. They tried to provide a solution using methods like decision trees, Naive Bayes, Artificial Neural Networks, Support Vector Machines, and Rough Set approach etc. Out of these methods, decision tree based algorithms have often performed the best along with other ensemble methods [22]. In the context of CRM, the present research is aimed at building only the efficient churn prediction models on customers’ profiles and accurately classifying a customer as a churner or non-churner which does not offer direct benefit to the enterprise. The constructed model does not suggest any actions for churn prevention and profit maximization which is the final objective of the enterprises. Hence, it is necessary for the enterprises especially like Telecom service providers to use the services of the domain experts for performing some extra manual work on the model to discover actions for churn prevention and profit maximization. So far, very limited research has been done on automatic extraction of actionable knowledge using machine learning models to achieve the final objective of the enterprises.
If the discovered knowledge can directly suggest the fruitful actions to achieve the objective function without any additional manual efforts, then it is referred to as actionable knowledge [6]. Simply, an ‘action’ is changing the present value of an attribute of a customer to another possible value. However, each action incurs some cost to the enterprise. Attributes can also be described as changeable attributes and unchangeable attributes. Values of changeable attributes are possible to change by applying actions. In the Telecom sector, data plan, roaming plan, calls tariff etc. can be the examples of changeable attributes since the values of these attributes can be changed by the operator. On the other hand, the values of unchangeable attribute (Eg. Gender, age, marital status, etc.) are not possible to change. Intuitively, actionable knowledge discovery entails determining a finite number of actions in order to make changes to the values of the attributes of the input instance, so that its class is changed from undesired to a desired with a maximum net profit. In the Telecommunication industry, by using the machine learning model an existing customer can be predicted that he/she is more likely to switch to another service provider. Then, the actionable knowledge can be the actions to retain that unwilling customer such as reducing the call and SMS charges, providing free roaming services, increasing service level, and offering suitable data plan, etc.
Though some researchers worked on mining actionable knowledge for customer retention in this sector, they have some limitations. All the past researchers had seen the problem as a 2-class problem only and there was no specific focus on dealing the multi-class problems. The existing methods treated the customers of CRM applications belong to two classes (Churner and Non-churner) only and designed solution which fits for 2-class applications and tried to change ‘Churner’ as a ‘Non-churner’ [27, 49]. Generally, Telecom sector also classify its customers according to the degree of profitability. In the Telecom business, there can be customers with more than two classes in a certain order of priority based on the degree of profitability. Hence, it is not necessary to restrict to the applications or domains with two classes of customers only. In Customer Relationship Management, in one scenario, customers are classified as platinum tier, gold tier, iron tier, and lead tier in the decreasing order of profitability [48]. In one another case, customers are classified as High loyal, latent loyal, spurious loyal and low loyal [7] where the ‘High loyal customers’ are of most profitable class and ‘low loyal’ are least profitable. In these cases, a customer who has fallen in a less profitable class has to be changed to any one of the possible higher level profitable classes with a maximum net profit. In such a way, when customers are of multiple classes in a certain order of priority based on the degree of profitability, then for the enterprises it is required to convert them from a lesser profitable class to a higher profitable class to improve the profits. Thus, solutions for the problems with more than two classes of customers are required. To the best our knowledge, the present research has not adequately addressed the customer’s class transformation issue when the number of classes of customers is ‘n’ where n > 2. This paper addresses these limitations and challenges and the main aim is predicting the churning nature and less profit yielding features of the customers and suggesting required actions to avoid churning or to change the customer from a lesser profitable class to a higher profitable class in the multi-class environment of Telecom sector.
We introduce our technique ‘Dest_leaf_finder’ which extracts actionable knowledge by post processing the probability estimation decision tree (PET). With the help of PET if an existing customer is predicted to be as a Churner or a low profitable class customer, then this method tries to convert him/her as non-churner/higher profitable class customer by changing the values of changeable attributes and also taking the cost of actions into account. The proposed PET based method treats the problem as a multi-class problem where n≥2. It provides profit maximization solution when the customers are classified according to the amount of profit earned from them. Eventually, the main objective of this paper is developing a model which assists the Telecom sector to transform churners as non-churners and changes less profit yielding customers as more profit yielding ones. The proposed method is presented as a case study using the real data pertaining to one Telecom operator in India, on customer’s class transformation for profit maximization. Experiments on real-world data and UCI datasets demonstrate that our method achieves finer computational performance while achieving the objective and outperforms the ensemble tree based state-of-the-art methods [32, 49] and also single tree based methods [27, 34].
The rest of the paper is organized as follows: In Section 2 we review the literature and discuss the related work. In Section 3, we present some preliminaries and also discuss extracting knowledge from PET using our algorithm Dest_leaf_finder for 2-class, 3-class scenarios of Telecom and finally, a mathematical model has been formulated to provide the required solution for n-class context. In Section 4, performance evaluation of Dest_leaf_finder and run time comparisons with the state-of-the-art methods has been presented. In Section 5, we have given the conclusions and discussed the possibilities for the future work.
Related work
Churning problem in Telecom industry has been studied and addressed by many researchers earlier [1, 40]. Data mining and machine learning community have widely studied on providing a solution and a model for forecasting attrition nature of customers where most of the focus is on improving the technical interestingness measures of the models [16, 42]. In the past, many researchers have shown their interest on CRM and direct marketing problem and handled the cost-sensitive customer retention problem as a classification problem [32, 34]. B. Zadrozny and C. Elkan [47] described a method for cost-sensitive learning with the assumption that costs vary based on the examples.
The framework presented by Cui et al. [49] post-processes the additive tree model (ATM) classifier like random forest. Their method employs integer linear programming to determine measures for changing the class membership of a sample. They focused on changing the values of attributes without taking profit maximization into consideration. Qiang LU et al. [32] extended the work of Zhicheng Cui et al. [49] and presented a method which post processes ensemble of trees and finds actions with maximum net profit for a given single input instance. They also showed that finding optimal actions to transform an undesired class instance to a desired class from the ensemble of trees is NP-hard. They transferred the problem of finding optimal actionable plans to a state space graph search problem and solved it. Furthermore, for achieving the balance between search time and quality of the solution, they also proposed their second method viz. state space search algorithm which gives a sub-optimal solution. They also proved that the computation time for extracting optimal actions with their framework is more efficient than the framework of Zhicheng Cui et al. [49]. However, computation time to achieve objective function using ensemble based classification models like random forest, etc. are high, especially when the dataset size is very large. Lv Q et al. presented a method [26] for transforming the prediction label of an input instance by considering action costs. They have formulated the suboptimal action plan problem using an ensemble method works in two phases which is also computationally expensive.
Yang et al. [34, 35] presented a decision tree based greedy approximate solution for mining the required actions to change a group of undesirable class input instances whom they call as ‘unloyal customers’ to a desirable class(loyal) with a maximum net profit. They have also considered changing the values of the attributes to obtain maximum net profit, but however as the method is generating a huge number of actions leading to more complications in the computation. Liu et al. [24] introduced a method which first prunes and summarizes the discovered set of rules and then finds a small number of direction setting rules from which actionable knowledge can be discovered with a little manual effort. By incorporating business needs with a fuzzy machine learning model, L. Cao et al. presented a method [5] for actionable knowledge discovery. They have adopted a method based on fuzzy aggregation which has balanced both business needs and technical measures by re-ranking the discovered outputs. Nasrin Kalanat et al. [28] presented another fuzzy based method for discovering cost-effective actions from data. Their method assumes that in all cases continuous-valued attributes in the data are discretized in advance that leads to the disadvantage that using this crisp behavior can result in missing the best actions. To overcome this problem, they presented a method based on fuzzy set theory as they took the output from fuzzy decision trees, and produced actionable knowledge through automatic fuzzy post-processing. Their algorithm takes into account the fuzzy cost of actions, and further, attempts to maximize the fuzzy net profit. Later, they extended their work by assuming only the selected attributes as the flexible attributes and provided the other form of solution [27]. Though research on actionableknowledge discovery from data mining models is limited, some researchers have even shown their interest in surveying the existing methods [25, 50]. Dong X et al. proposed a method for mining actionable knowledge [45] from sequential patterns instead of a classification model. In the course of actionable knowledge mining, Kalanat N et al. presented a method in the other dimension which is suitable for graph data pertaining to social networks where there will be relationships between the objects [20].
In order to describe performance metrics which are integrated with the main intentions of the end users, a cost-benefit analysis methodology has been presented by Verbraken et al. [41]. Ronan et al. proposed a classification rule based framework [38] which address the concept of actionability. Their approach suggests actions to reduce the degree of the unsatisfactory situation by considering the quality and feasibility of actions. Nonetheless, all the existing research has perceived the problem as a 2-class problem only.
Mining profitable knowledge from probability estimation decision trees (PET’s) for Telecom application
In this section, first, some preliminaries regarding decision tree and PET construction are discussed. Then, we present our method ‘Dest_leaf_finder’ as a case study on Telecom business for customer’s class transformation for profit maximization. We start with a 2-class problem and then discuss a 3-class problem and finally present the mathematical model for the multi-class setting.
Decision trees
In the perspective of machine learning, modeling for customer churn prediction can be formulated as a classification problem. Since the decision tree is a powerful, prevalently used and most popular tool for classification, we use it as our classification model. When compared to other classification techniques, decision trees are easy to interpret as they can generate understandable rules. Training and classification phases of decision tree are simple and fast. Normally, decision trees produce good accuracy [14] and effectively handle high dimensional data. In the Telecom sector, customers’ data includes various kinds of features of customers such as socio demographic attributes (e.g., age, income, gender, culture, zip_code, job_status, education and nationality), behavioural information (e.g., service usage time, revenue, customer interaction with company for service), etc. This information is used to predict the customer’s churning or profitability nature. To construct decision tree for customer’s profiles, we have used the C4.5 algorithm [39] and gain ratio as the splitting attribute selection measure. During decision tree construction, for selecting splitting attribute at a node, gain ratio is a better choice than Information gain which is biased towards the attribute with a large number of outcomes. Information gain describes that what amount of information an attribute gives us regarding the class. The calculation of information gain with respect to an attribute ‘A’ is given in Equation (1) where ‘D’ is the dataset, ‘n’ is the number of classes of customers, ‘Pi’ is the probability that a randomly selected instance has class-i, ‘v’ is number of outcomes of attribute A and Dj is the data partition matching the jth value of attribute ‘A’.
Gain ratio measure performs a kind of normalization to information gain using split information as shown in Equation (4) to overcome the drawback with Information gain method. Gain ratio with respect to attribute A is:
The attribute with the maximum gain ratio will be selected as the splitting attribute at a node of the tree. C4.5 is a remarkable decision tree construction algorithm that is most likely the data mining trump card which is widely used till today. This algorithm has become very popular as it has been ranked as #1 in the top 10 Algorithms in Data Mining [46]. When the model has to be built on a very large dataset, other sophisticated decision tree techniques like Random forest [4] can be enormously huge and deep. They also increase the computation time of our objective function. When the other popular single decision tree construction method viz. Decision stump [44] is considered, though it produces a very short tree its technical evaluation measures are not up to the mark. Hence, our profit maximization approach cannot be applied on such models. Even when compared with one of the other prominent single decision tree construction methods i.e. Random Tree, C4.4 is better since it produces shallower trees with better technical evaluation measures than that of Random Tree. Though highly accurate decision trees are essential, the focus of this work is not finding the next best algorithm for Decision Tree or PET construction. Due to this reason, we used the standard algorithm for tree construction which is also perfectly suitable to explain our research and easy tounderstand.
For PET construction, the improved version of C4.5 algorithm viz. C4.4 is used. C4.4 employs maximum likelihood estimate, a completely frequency based method, and applies Laplace correction for smoothing the extreme probabilities [31]. The probability of belonging to class Ci for a customer’s instance X which has fallen into a leafnode is:
If jth instance belongs to class-i, then ∂ (Cj, Ci)=1, otherwise 0 and n is the number of classes, |D| is the number of instances in the dataset. When customers’ profiles are given as input to C4.4 algorithm, a PET is obtained. For example, Fig. 2 and Fig. 3 represent a class labeled decision tree and a PET respectively for the dataset shown in Table 2. After PET is introduced, its performance is evaluated using necessary metrics [15, 19].
To apply our proposed method, we have used a real dataset pertaining to a Telecom operator in India. The dataset contains 15000 instances of their subscribers described by 40 features. Out of these 15000, ‘Churn’ customers are 2500. Attributes are divided into four groups: Socio demographic, behavioral, charges, and customer service levels. The summary of the main features of the dataset is presented in Table 1. The output attribute is a class label which specifies whether the customer has churned or stayed within a period of 3 months. Before using the data for experiments, necessary preprocessing steps (eg. data cleaning, data transformation, etc.) are performed. During the experiments, 10-fold cross-validation is used to evaluate the constructedmodel.
Description of various features of the Telecom dataset
Description of various features of the Telecom dataset
In this section, we introduce our technique ‘Dest_leaf_finder’ which tries to produce retention/profit increasing actions for each customer of Telecom sector who is predicted to be churner/less profitable. Due to the values of its attributes, an instance falls into a particular leaf L of the tree which represents a class. If we want to it to fall into another leaf node, we simply have to change the values of required attributes. If the instance has fallen into a leaf node(‘Source leaf’) which represents an undesired/lesser profitable class, then the task of ‘Dest_leaf_finder’ is finding the best leaf node (‘Destination leaf’) among the other leaf nodes with desired/higher profitability class for this instance. For this purpose, algorithm extensively searches and finds the right destination leaf node with maximum net profit for this customer to shift to. Therefore, to shift/transform a customer’s instance from a lesser profitability class to a higher profitability class, ‘Dest_leaf_finder’ changes the values of the necessary attributes of that instance. For example, ‘Customer Service level’ is one of the important features in the Telecom sector which is a changeable attribute. For instance, if the customer is provided with ‘low’ service level, then we need to change his/her service level to ‘high’ or ‘medium’ to make the customer satisfied and stay with the enterprise. For the enterprise to increase ‘service level’ it incurs some cost. A cost matrix is maintained for every attribute, where each entry in it is the cost that incurs to change the value of the attribute from one state to another. Values of the cost matrix are obtained from the domain expert. If the outcomes of an attribute are n, then the order of cost matrix will be n×n. Each element C(i, j) in the cost matrix represents the cost incurred to change an attribute value from i to j. As the unchangeable attributes’ values are impossible to change, for those attributes, elements in the cost matrix are filled with very huge and unbearable cost values to avoid considering that attribute’s value change. However, unchangeable attributes must be included during the decision tree induction process, as they are important and can influence the class of the customer to a greater degree and cannot be discarded. For example, some of the features described in Table 1 pertaining to Telecom data viz., customer gender, age, and job_status, etc. are required to be included while constructing the model to predict the nature of the customer. Research framework of our method is shown in Fig. 1. The constructed PET, input instance and the output given by the PET are inputs to our proposedalgorithm.

Research Framework of ‘Dest_leaf_finder’.
By using the PET, if a customer is predicted as belonging to a Churn/less profitable class, then while finding optimal destination leaf for him/her, Dest_leaf_finder algorithm considers each potential destination leaf node. At one time, from the PET, Dest_leaf_finder algorithm takes the path of one destination leaf node from root to leaf. Then it examines and finds the nodes’ (attributes’) values which do not match with the values of attributes’ of given input instance and thus identifies the actions. By considering the cost of actions, net profit will be computed for shifting the instance/customer from one leaf to another. This process is performed on all the potential destination leaf nodes and finally, the destination leaf and the corresponding actions which yield maximum net profit will be chosen. According to the procedure discussed above Dest_leaf_finder algorithm is designed and presented in Algorithm 2.
Source leaf for the input instance X is found using the algorithm find_leaf(). This algorithm takes one customer’s sample X i.e. test/training/new instance and according to its attributes’/features’ values, starting from the root the PET is traversed and an appropriate leaf node is reached.

Based on number of classes of the customers, the mathematical model for calculating the profit will be changed and the find_profit() method undergoes to slight changes.
Next, determining net profit in the three contexts of Telecom business is discussed. The first case discusses churn detection and prevention as a 2-class application, the second case discusses a 3-class application and finally finding profit for n-class (multi-class) scenarios is discussed and a mathematical model is formulated.
Telecommunications industry broadly classifies its customers into two. One is ‘Non-churn’ customers who will stay with the same service provider. Another class of customers is ‘Churn’ customers who will cancel their account and shift to another service provider during a period of time. For easy illustration of proposed algorithm Dest_leaf_finder, we have used a small subset of the examples from the real Telecom dataset discussed in Section 3.2 to build the PET. Further, we have taken four significant input features i.e. service level, income of the customer, gender, and call charges belonging to different categories. Moreover, among these 4 attributes, 2 are changeable and 2 are unchangeable. Though call charges, service level have different sub categories we have generalized them for simplicity.
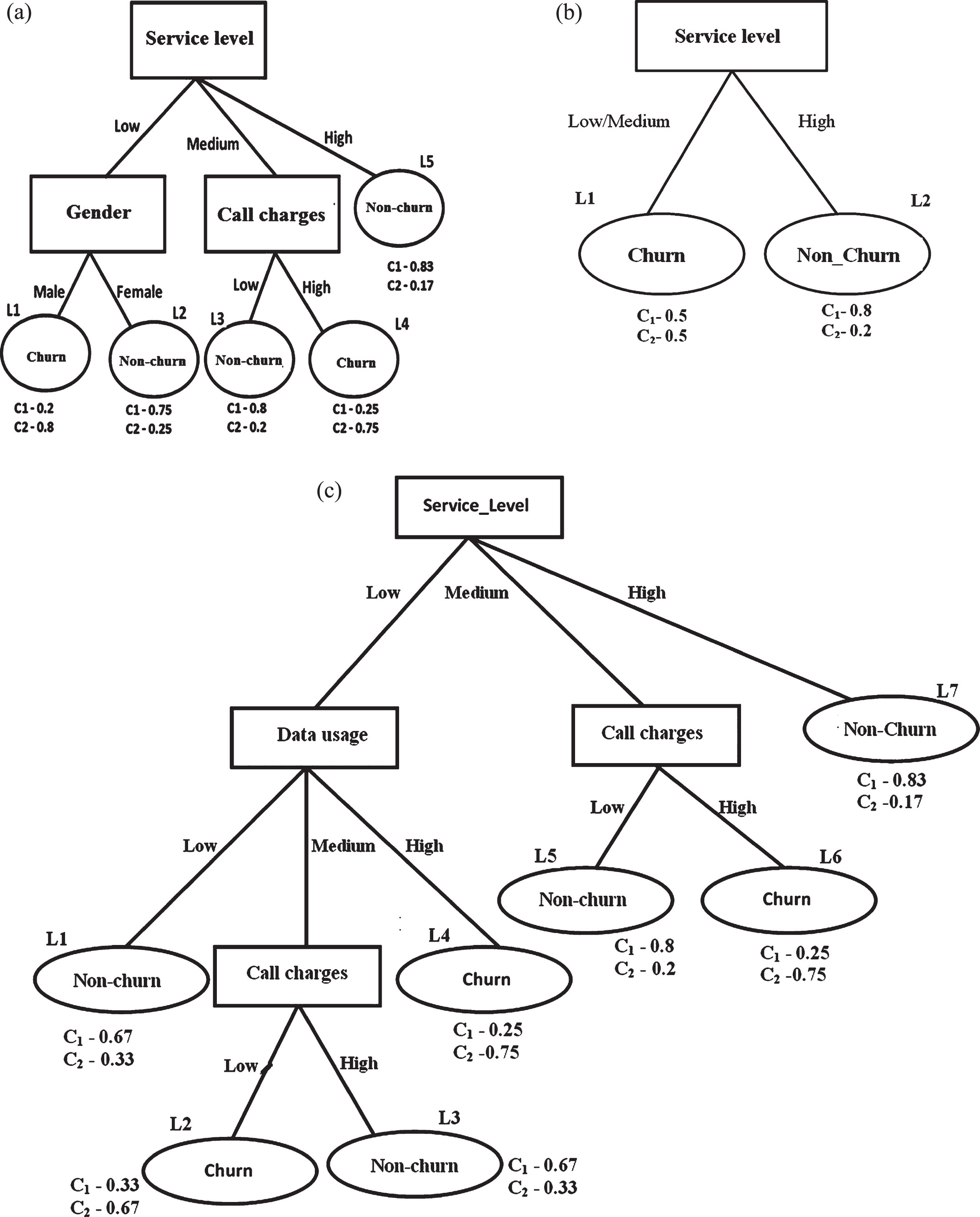
The description of the attributes of the subset of Telecom data is presented in Table 3. This dataset contains 14 instances composed of four significant categorical attributes of the customer and a class label viz., Churn, Non-churn. Among 14 instances of dataset, 9 are Non-churn (64.29%) and 6 are Churn (35.71%). Dataset in Table 2 is given as input to C4.4 algorithm and a class labeled decision tree (Fig. 2) and then a PET (Fig. 3) is obtained as output. The constructed tree describes customers with what kind of features will be of class ‘Churn’ and customers with what sort of features will be of class ‘Non-churn’. In the PET each leaf node also represents the class probabilities belonging to C1 (Non-churn) and C2 (Churn) if an instance has fallen in it. However, the leaf node is labeled with the majority class. Ultimately, for an instance which has fallen into a leaf node, the constructed PET can provide a class label and also the probability of belonging to each class. In our application, C1 is the desirable class and C2 is an undesirable class. In this case, we discuss changing the class of a customer from Churner (C2) to Non-churner (C1) i.e. C2 → C1 with a maximum netprofit.

Class labeled Decision Tree representing dataset inTable 2.
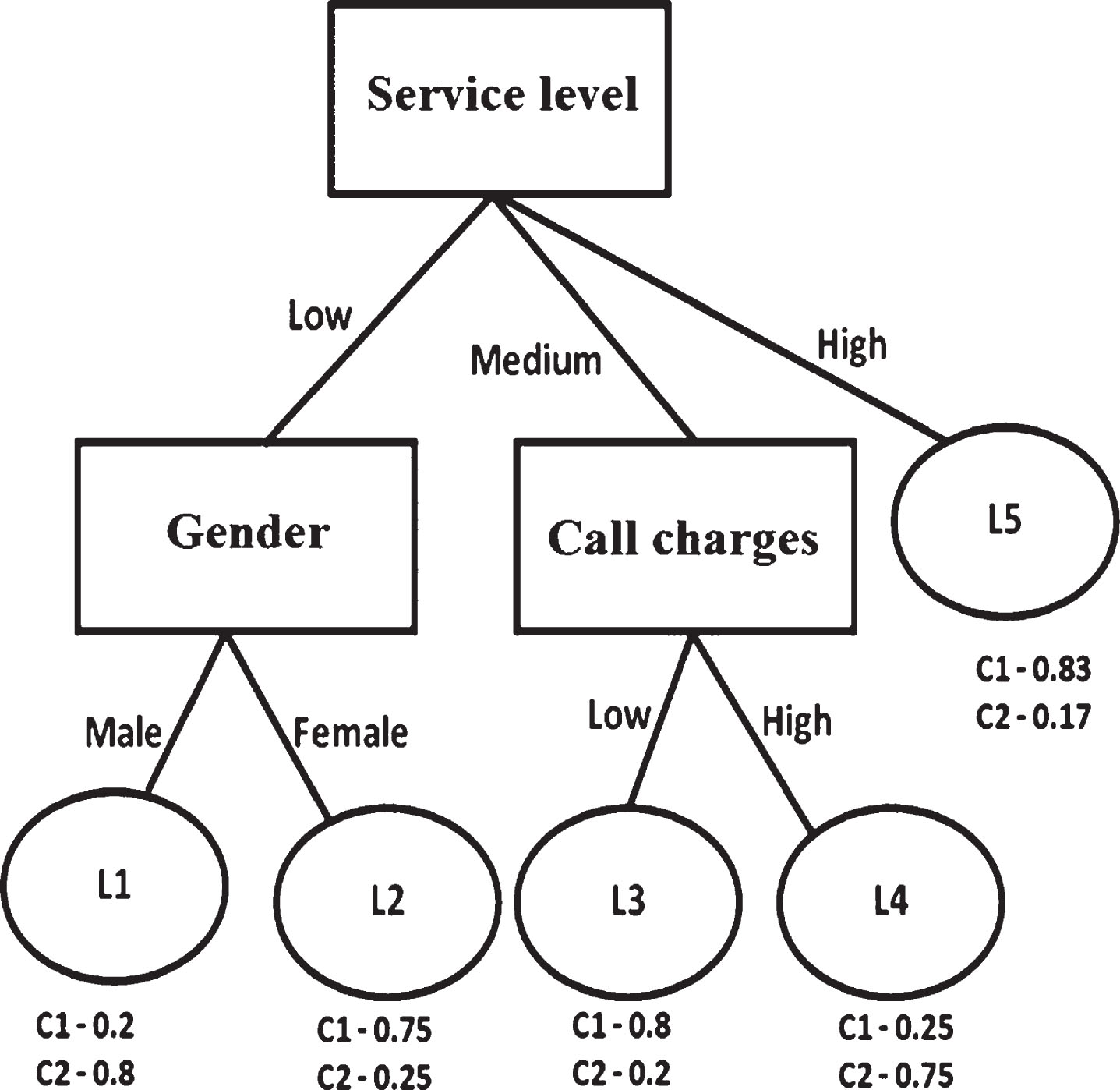
Probability Estimation Decision Tree (PET) representing dataset in Table 2.
Sample 2-class dataset of Telecom
Description of Telecom data in Table 2
In the case of 2-class problems of Telecom enterprise, if an instance/customer has fallen into a leaf node then profit obtained from him/her, if he/she remains in that leaf node, is computed with respect to the desirable class i.e Non-churn (C1). If the probability of class C1 is 1.0(if the customer is 100% Non-churn customer) for a leaf node, then enterprise makes a certain amount of profit ‘PA’ from the customer who has fallen into this leaf. In our case study, we have considered a value $1000 for PA which is obtained from a domain expert. As an example, if a customer falls into Leaf-1 (Fig. 4), then enterprise makes 0.8*1000 = $800.

A Leaf node representing probabilities w.r.t. 2-classes.
The method find_profit() called by Dest_leaf_finder algorithm computes the profit obtained by moving a customer from an undesired leaf node to a desired leaf node as shown in Equation (7).
In Equation (7), P is the profit obtained after shifting the customer from source leaf node S to destination leaf node D, and PC1(D) and PC1(S) are the probabilities of desirable class (Non-churn) if the customer is in destination leaf and source leaf respectively. PC1(D) and PC1(S) are obtained from ith destination leaf Di and source leaf S respectively. PA is the amount of profit from a customer who is 100% in the desired class. However, by subtracting the total cost incurred for this transformation (since some actions have to be taken), the Dest_leaf_finder algorithm computes the net profit. For this case, find_profit() method is shown in Algorithm 3.
Finding profit for two class applications
As an example, a customer’s instance X from our case study is considered, where the attribute values are Gender = Male, Data usage by the customer = High, Service_level = Low, Call charges = High. In the PET (Fig. 3), this instance falls into leaf node L1 which represents undesired class i.e. Churn. The possible destination leaf nodes for instance X can be L2, L3, and L5. We need to try out to which among them X can be moved to on changing its attribute’s values.
Cost matrices for the two changeable attributes in the PET (Fig. 3) i.e. Service_level and Call charges are given in Figs. 5(a) and 5(b) respectively. When we want to avoid changing the attribute’s value, a cost value ∞ has been taken. For example, changing ‘Service_level’ from ‘high’ to ‘low’ does not make any sense. Cost matrices of ‘Gender’ and ‘Data usage by customer’ are not given since they are not changeable attributes.

(a) Cost matrix of ‘Service_level’. (b) Cost matrix of ‘Call charges’.
X cannot be moved to L2 since the ‘gender’ (unchangeable attribute) has to be changed. X can be shifted to L3 by changing ‘Service_level’ from ‘Low’ to ‘Medium’ with the cost of $100 and ‘Call charges’ from ‘High’ to ‘Low’ with the cost of $100. Net profit in this case is (PA * (PC1(L3) - PC1(L1))) – Total Cost=(1000 * (0.8-0.2)) – (100 + 100) = $400. Net profit obtained after transforming the customer X from L1 to L5 with one attribute’s value change i.e. ‘Service_level’ from ‘low’ to ‘high’ with the cost of $200 is (1000 * (0.83 – 0.20)) – 200 = $430. As the shift to L5 is yielding maximum net profit, L5 will be the destination leaf for X. Hence, for the customer X, source leaf node is L1, destination leaf is L5, action taken for transforming X from L1(undesired class) to L5 (desired class) is changing ‘Service_level’ from ‘low’ to ‘high’ and expected net profit after shifting is $430.
Most often, Telecom sector finds a typical class of customers who do not cancel their account and continue with the same service provider but, they will be inactive in using the services. When a customer uses the enterprise services to a lesser degree and performs very less number of transactions every month, obviously profit obtained from him/her can be less. Due to various reasons like increased service charges, reduced coverage, the need for using data is finished, and unsatisfactory service levels, etc. can be reasons for this nature of the customer. However, these classes of customers cannot be ignored since they can be transformed as active customers by applying some cost-sensitive actions. Thus, in the real time scenario of Telecom sector, it is not necessary to restrict the customers to belong only to two classes like Non-churn or Churn.
Further, to study the additional behavior and profit-yielding nature of the customers, we have added a third class label viz., ‘Non-churn but less active’ and then 125 samples are collected from the customers of the same operator through structured questionnaires which are distributed online. This class of customers stays with the operator but inactive in using the services thereby lead to uncertainty and nominal profits. Each customer record is characterized by five decisive input attributes viz. SMS charges, call charges, internet connectivity/speed, service level, and signal strength. The details of the attributes of 3-class Telecom dataset are presented in Table 4. The class label of the customer can be one of the three labels viz. Non-churn and active customer (C1), Non-churn but less active customer (C2), Churn customer (C3). Among 125 instances of dataset, 40 are C1(32%), 42 are C2(33.6%) and 43 are of class C3(34.4%). After applying C4.4 algorithm on the dataset a PET which is shown in Fig. 8 is obtained. In this PET, each leaf node represents a class label (majority class) and also associated with each class probability of C1, C2, and C3 respectively in the dottedbox.
Description of attributes in the 3-class Telecom dataset
Description of attributes in the 3-class Telecom dataset
Here, class C1(Non-churn and active customer) is the most preferred class. Class C2(Non-churn but less active customer) is the next preferable class. Class C3 represents churn customer i.e. Churner. Enterprise no longer can gain from the customer who belongs to class C3. Obviously, there will be no profit for the enterprise if the C3 probability is 1.0 because he/she leaves the enterprise. Accordingly, customers’ classes in the order of profitability in the descending are C1, C2, C3. Our objectives are (1) to convert a customer who actually belongs to class C2 to class C1, and (2) converting a customer who belongs to class C3 to either class C1 or to class C2 whichever is possible and more profitable to the enterprise. In 3-class problems, class transformations will be as shown below:
C2→ C1
C3→ C1/C2
In a 3-class scenario of Telecom, when the customer has fallen into a leaf of the PET, the amount of profit obtained from him/her is computed in terms of probability of belonging to class C1 and also class C2. Though class C1 is the most desired class, with respect to class C2 also enterprise makes some amount of profit from the customer. Say, for instance, a leaf node Leaf-2 (Fig. 6) comprises the class probabilities C1 = 0.2, C2 = 0.6, C3 = 0.2. This means, for a customer who has fallen into Leaf-2 contains the qualities of all the three classes in different degrees and also yields the profit with respect to each class except C3. For instance, according to a domain expert, if C1 probability is 1.0 then enterprise gains a profit of $1000 or if C2 probability is 1.0 then the profit is $500. Hence, even if the customer purely belongs to class C2, enterprise earns $500. However, a leaf can never have both C1 probability 1.0 and also C2 probability 1.0. In Fig. 6, the instance which has fallen into that leaf node will have ‘Non-churn and active’ class probability 0.2. Hence, with respect to class C1, from him/her enterprise makes the profit of 1000*0.2 = $200. As the customer also has C2 probability 0.6, with respect to this feature he/she yields a profit of 0.6*500 = $300. However, no profit can be gained with respect to class C3 (Churner) probability which is 0.2, since this class represents that the customer will not stay with the enterprise. With respect to total staying probability, profit for the enterprise is 300 + 200 = $500. In this case, profit obtained from a customer by shifting him/her from an undesired leaf S to desired one D is,
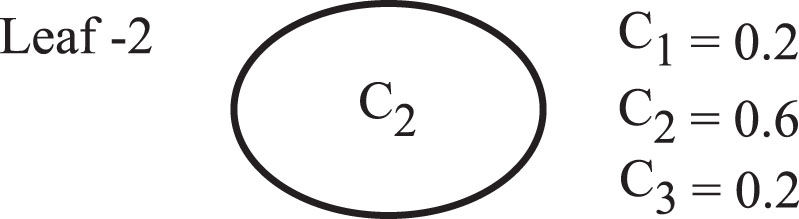
A Leaf node representing probabilities w.r.t. 3-classes.
In Equation (8), PA1 is the profit if C1 probability is 1.0 (100% class C1 customer), PA2 is profit if C2 probability is 1.0 (100% class C2 customer), PC1(D) and PC1(S) are class C1 probability in destination leaf and source leaf respectively, PC2(D), PC2(S) are class C2 probability in destination and source leaf nodes respectively. The procedure for calculating net profit for changing the customer’s instance from source leaf S to ith destination leaf Di in the case of 3-class problems is given in Algorithm 4.
A customer’s instance Y is considered, which has fallen into the leaf L1 according to its attributes’ values, which represents the undesired class (Churner) as shown in Fig. 7. We can consider L2 as one of the potential destination leaf nodes for customer Y as its class label is C1 which is most desirable. Here we proceed with the assumptions; if the customer’s C1 class probability is 1.0 then profit is $1000, C2 class probability is 1.0 then profit is $500. Based on the class probability values of the leaf node, profit, when Y has fallen into L1, is 1000*0.2 + 500*0.1 = $250. Profit if any instance falls into L2 is 0.8*1000 + 0.1*500 = $850. The difference in the profit if the instance is shifted from L1 to L2 is 850–250 = $600.If the cost incurred for the actions to shift from L1 to L2 is $200, then the net profit will be 600–200 = $400. In a similar fashion, we find the expected net profit after moving to other potential destination leaf nodes. Whichever the leaf yields maximum net profit; to that leaf customer Y is shifted.
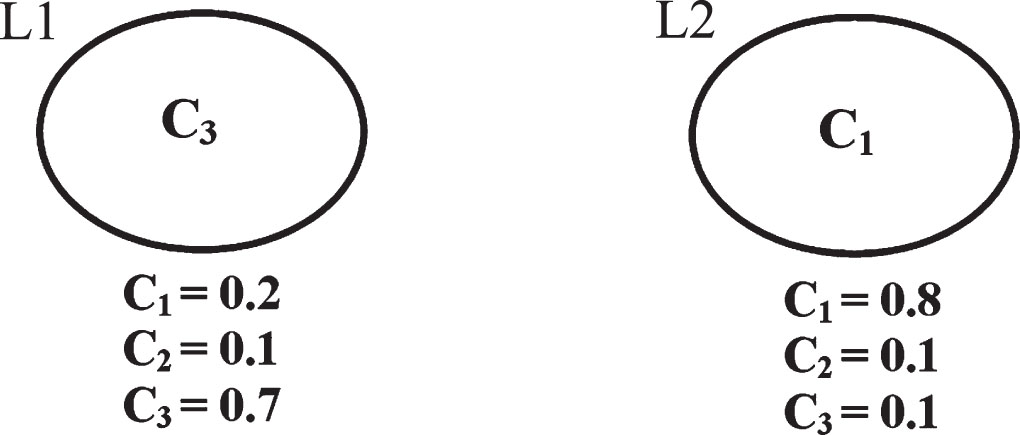
3-class example.
For detailed illustration, an instance of customer Z belonging to our case study is considered, where attributes’ values are A1 = A11, A2 = A22, A3 = A31, A4 = A41, A5 = A52. According to the suggestion of a domain expert in the Telecom business, profits of $1000 and $500 are considered if the customer’s C1 class and C2 class probabilities are 1.0 and 1.0 respectively. Action costs of the attributes are taken in the range of $[0–200].
In the PET shown in Fig. 8, Z falls into the leaf node L5 which is less profitable leaf with class C2. Profit obtained from Z if he/she remains in L5 is (PA1*PC1(S) + PA2*PC2(S)) = 1000*0.28 + 500*0.57 = $565. An attempt is made to find the best destination node for customer Z with a maximum net profit. Z cannot be moved to L1 since its class label is also C2. Moreover, L1’s C1 and C2 probabilities also lesser than that of L5’s. Instance cannot be moved to L2 or L3 or L4 since these leaf nodes’ class label is C3 which is completely undesirable. Net profit, if Z is moved to L6 is [(1000 * 0.8 + 500 * 0.1) – 565] – 50 = $235. (Only attribute ‘A1’ value to be changed from A11 to A12. Cost for this change is $50 from the cost matrix of A1). Z cannot be moved to L7 which is undesirable leaf node (Class C3). Net profit, if Z is moved to L8 is [(1000 * 0.7 + 500 * 0.1) – 565] – (100 + 50) = $35. Two attribute values are changed. Attribute A1 value is changed from A11 to A12 and attribute A3 value is changed from A31 to A32. Net profit, if this customer is moved to L9 will be [(1000 * 0.54 + 500 * 0.42) – 565] – 100 = $85. Only one action i.e. A3 value is changed from A31 to A33 is required. Further, no other leaf nodes among L10, L11, L12, L13, L14, L15, L16 or L17 yields a profit if Z is shifted to them. Z is moved to leaf L6 to obtain maximum net profit. Eventually, source leaf node for the instance Z is L5, destination leaf is L6 with Net Profit = $235 with one action on attribute A1 whose value is changed from A11 to A12. In this example, customer is transformed from class C3 to C1. It can be concluded that our proposed method works well and provides profit maximization solution to such 3-class contexts of Telecom business.
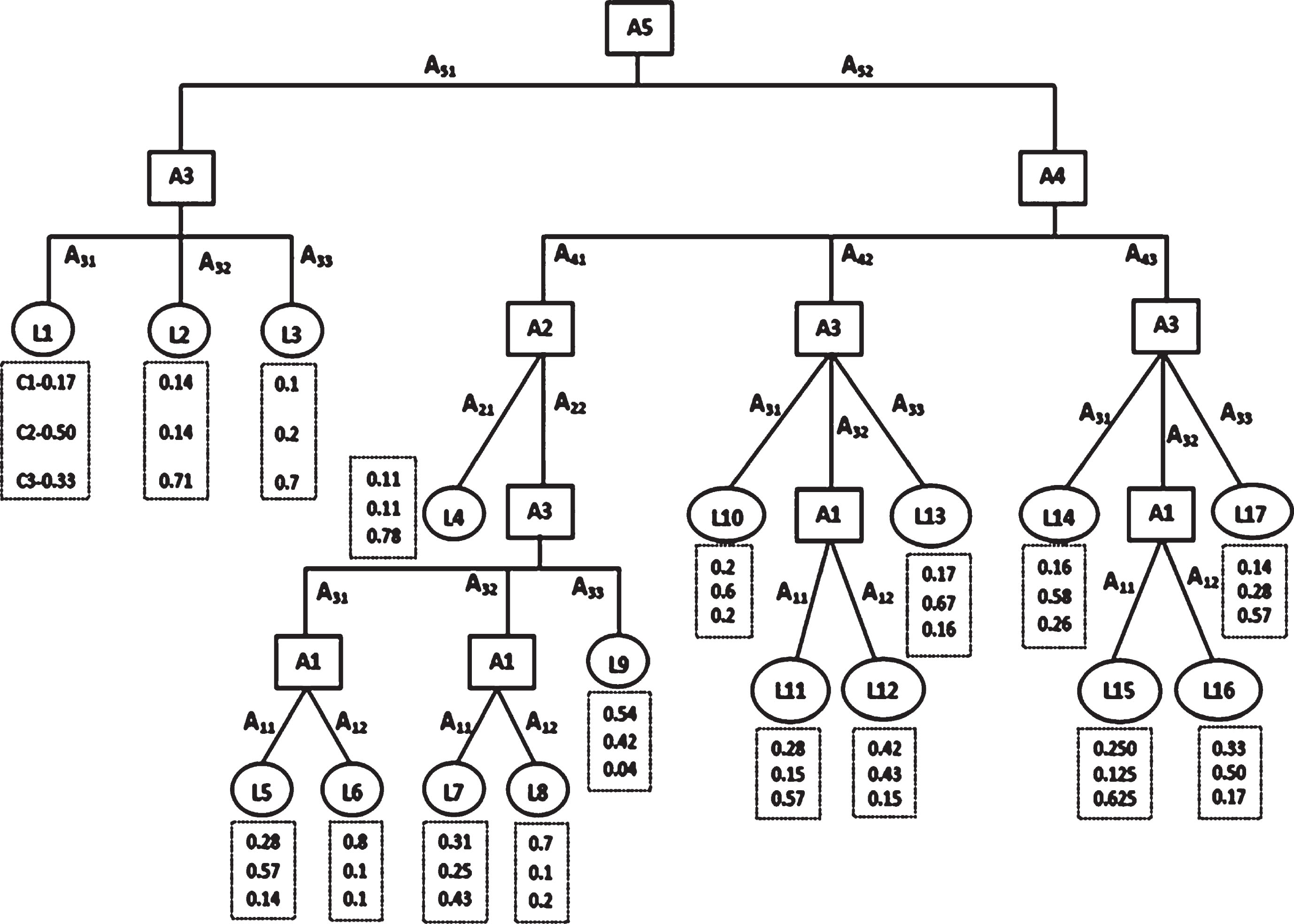
Probability Estimation Decision Tree for 3-class Telecom data.
Often, datasets of business sectors like Telecom, are composed of four, five and more customer classes. In CRM, in one scenario customers are classified as high stay(highest profitable), latent stay, spurious stay, and low stay and in another context, they are classified as stay customers, discount customers, impulsive customers, need based customers, and wandering customers or churn customers(zero profitable) [7]. In the present most challenging scenario of Telecommunications sector to stay alive in their business and for maximizing the profit, most care in various dimensions are being taken. In this business in many instances, customers are categorised as belonging to ‘n’ number of classes and they are arranged in the order of priority in the descending order viz., C1, C2, C3, C4, ... , Cn based on the amount of profit obtained by them. The intuition is, the amount of profit yielded by the customers will be in the descending order from C1 to Cn - 1. As the class Cn represents that the customer leaves the enterprise, no profit is expected with respect to this class. Then we try to transform a customer from the undesired/less desirable class to a more desirable class with a maximum net profit.
If a customer is predicted as belonging to an undesired class Cn, then an attempt is made transform him/her to a more desired class among C1, C2, ... ,Cn - 1 whichever is more beneficiary to the enterprise. In the n-class scenario, class transformations can be as shown below:
(Cn ⟶ C1/ C2/ ... / Cn - 1) (Cn - 1 ⟶ C1/ C2/ ... / Cn - 2) . . (n-1). (C2 ⟶ C1)
In the case of n-class scenario where n≥2, it is to be noted that, if a customer falls into a leaf node L of the PET, then he/she can likely have the characteristics of all classes. Then except that with respect to class Cn, from all other classes, a customer generates some amount of profit to the enterprise. The total profit obtained from a customer when he/she falls into a leaf node L will be
In Equation (10), PCj(D) and PCj(S) are the probability of class-j in destination and source leaf nodes respectively. Last term in eq. (10) is the total cost incurred on all actions for transforming an instance from source leaf to destination leaf. According to the procedure discussed above, for computing profit in the case of multi-class problems, a method is presented in Algorithm 5.
In this section, first, the performance of our proposed algorithm is analyzed and then the computational time is verified on various benchmark datasets and a real world Telecom dataset. Then, the run time comparison of our method with the other state-of-the-art methods is performed.
Performance of ‘Dest_leaf_finder’ algorithm
Computational complexity of ‘Dest_leaf_finder’ algorithm is determined by the number of primitive operations i.e. comparison operations. This algorithm, for each internal node, needs to compare with maximum ‘a’ number of (‘a’ is total number of attributes in the dataset) attributes to identify that attribute. After the attribute identification, to find that attribute’s value, ‘v’ number of comparisons required where ‘v’ is the average number of outcomes of each attribute. Therefore, (a + v) comparisons required up to this stage. If each path contains on average ‘q’ nodes, then total number of comparisons will be (q(a + v)). If the potential destination leaf nodes are ‘p’ then (pq(a + v)) comparisons are needed to find optimal destination leaf node for an instance which has fallen in an undesired leaf. If the total number of instances where we need to find the destination leaf is ‘t’ then (tpq(a + v)) comparisons are required. Eventually, execution time is O(tpq(a + v)).
Experimental setup
During all the experiments discussed in this section, we have implemented the proposed method Dest_leaf_finder in Java programming language and the experiments are conducted on a dual core Pentium 4, 2.5 GHz processor with 4GB RAM running with Windows7 Operating System. Weka source code (Java) has been used for tree construction. All continuous attributes in the datasets are discretized using the Fayyad & Irani’s MDL method [9]. Before applying our proposed postprocessing algorithm on the classifier, we have also evaluated the classifier’s performance by using precision, recall, accuracy, and F-measure. The constructed classifier is tested using 10-fold cross-validation. For evaluating PET’s probability estimation capability, AUC measure is used [15, 19].
We first perform experiments on UCI data and present the scalability feature of our method. Then, the proposed method is compared with the ensemble tree based state-of-the-art methods followed by single tree based state-of-the-art methods. Then, we also verify the performance of our method on the other decision tree construction algorithms. In the end, we focus and demonstrate the time efficiency of our method on the case study problem of the real world Telecom sector.
Statistical test setup
For comparing the performance of the proposed postprocessing method against the state-of-the-art methods, and also to compare the performance of the classifier adopted in our research with other classifiers, we have performed the statistical tests using the popular web statistical tool named STAC (http://tec.citius.usc.es/stac/) [37]. According to the characteristics of the data and as suggested by the online tool, the nonparametric test named Friedman aligned ranks test is performed. In all the experiments in the subsequent sections, the null hypothesis (H0) for Ranking [11, 33] is that the means of the results of two or more algorithms are the same. The null hypothesis (H0) for Post-hoc multiple comparisons [3, 23] is the mean of the results of each pair of groups is equal.
Analysis with UCI ML data
The efficiency of our algorithm is verified on ten UCI Machine Learning datasets. The datasets pertaining to classification are taken from UCI ML repository [2] with different number of classes. We have used the Weka (version of 3.8) source code in Java for the Tree construction. Then, we have implemented our algorithm i.e. Dest_leaf_finder in Java programming language.
For each dataset, classes are supposed to have the priority from least to high and tried to convert the instances from low priority class to a higher level priority class such that net profit obtained is maximum. According to attribute’s nature, few of them are assumed as changeable and the remaining as unchangeable. We assumed the classes in the descending order of amount of profit and computed the net profit. The details of UCI datasets which are used in the experiments are shown in Table 5.Technical evaluation measures of the PET constructed on each dataset by using C4.4 algorithm, size of the tree, and the number of leaf nodes of each tree constructed on a dataset also shown in Table 5. The reason for taking these datasets is, they have the sufficient number of records and supporting with n-class data.
UCI datasets used in the experiments and technical evaluation measures of C4.4 on the datasets
UCI datasets used in the experiments and technical evaluation measures of C4.4 on the datasets
We perceived these datasets as the business data and during the calculation of net profit, in case of a 2-class problem, if an instance has 1.0 probability of belonging to class Non-churn, then profit of $1000 is assumed. Costs of actions are taken in the range $[0–200]. When handling the multi-class datasets, profit obtained when an instance purely belongs to class C1 and Cn are taken as $1000 and $0 respectively. If there are n classes of instances and if an instance falls into a leaf node representing class-k (k > 1 and k < n) with 1.0 probability, then we have taken a profit of $(1000/k). However, w.r.t. class Cn a profit of $0 is assumed.
From each dataset, each time we have randomly taken a significant amount of examples so as to verify the runtimes of the method. The graphs showed in Fig. 9 presents the run time behavior of the algorithm on 10 UCI datasets. In each graph, x-axis represents the number of instances taken from a dataset and y-axis represents total execution time to find best destination leaf node for each of those instances with a maximum net profit. All the graphs shown in Fig. 9(a) through 9(j) describe running time of Dest_leaf_finder. When tree size is large and it contains a huge number of leaf nodes, run times of Dest_leaf_finder increases since more number of comparisons have to be done to achieve the objective. This fact is observed on the runtimes on the datasets Connect-4 and Hypothyroid.
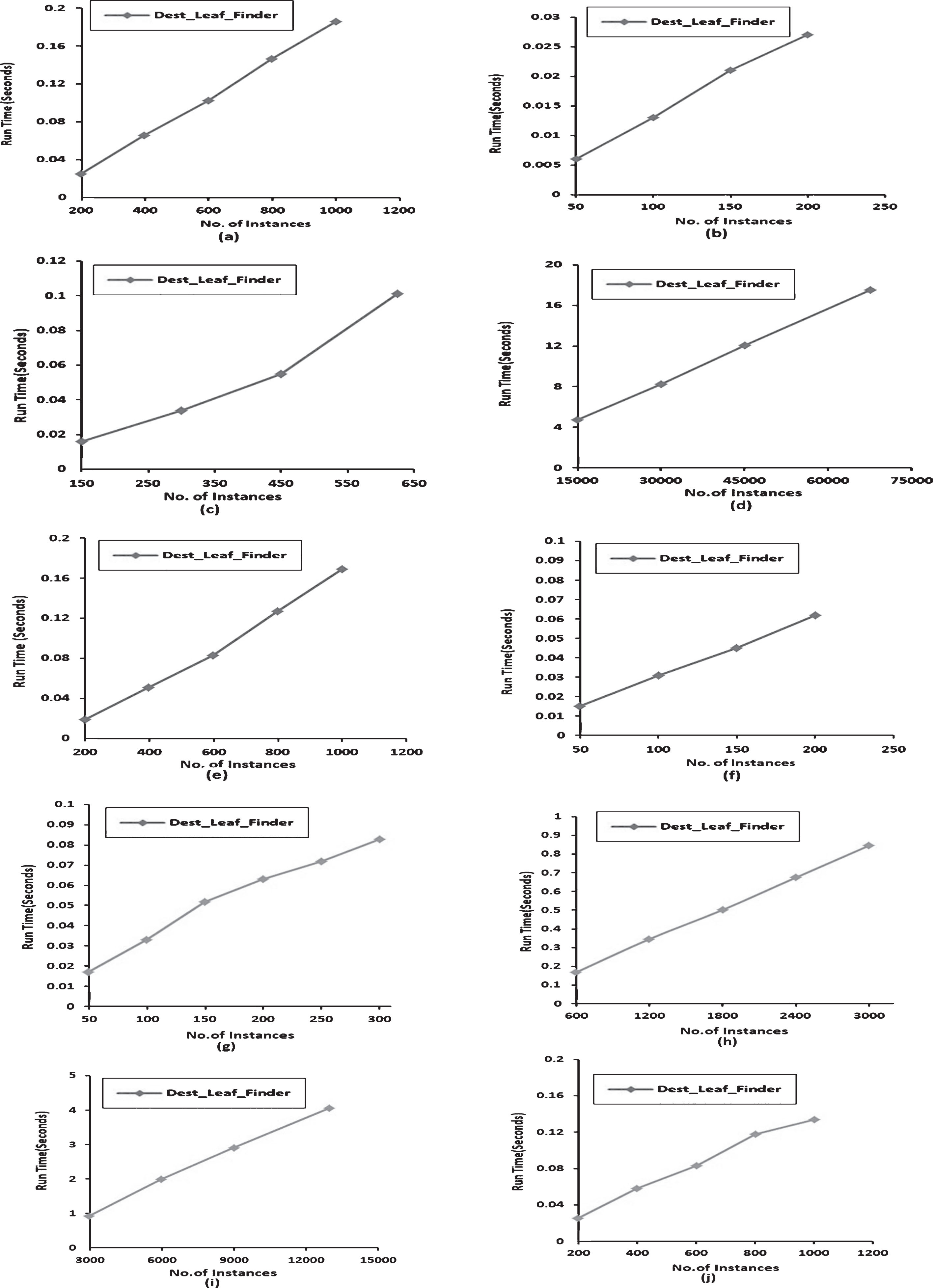
Run Times of Dest_leaf_finder on UCI datasets. (a) Anneal (b) Autos (c) Balance Scale (d) Connect-4 (e) German (f) Glass(g) Heart-c (h) Hypothyroid (i) Nursery (j) Solar.
With the help of our experimental results on UCI ML datasets, it can be concluded that the proposed algorithm, for all kinds of datasets, the running time to achieve the objective function is increasing linearly with the increase of data size and exhibiting the scalability.
For comparison, we consider two state-of-the-art techniques viz., Integer Linear Programming (ILP) method [49] and Sub-optimal search algorithm [32], which determines a set of actions that can transform the input instance’s class from undesirable status to desirable. To the best of our knowledge, these are the state-of-the-art ensemble tree based methods for extracting profitable actions. These algorithms mine the best actionable plans from additive tree Model (ATM). Run times of our Dest_leaf_finder algorithm are compared with ILP and Sub-optimal search algorithm on 9 benchmark datasets from the UCI Machine Learning repository and the LibSVM website [51] used in sub-optimal search’s and ILP’s actual experiments. To compare with these state-of-the-art methods, from each dataset we have randomly taken 30 instances from the dataset and produced 30 problems with the same parameter settings. For each dataset, we solve these 30 problems and record the average run time to output the solution. The prime intention of our Dest_leaf_finder is finding the best destination leaf(with maximum net profit) for an input instance which possess undesirable class. By considering all possible solutions and required action costs, Dest_leaf_finder suggests the best destination leaf with an utmost net profit. Hence, we look into the comparison of runtimes of the methods for finding the solution.
Table 6 presents a clear comparison of our Dest_leaf_finder and the two state-of-the-art methods viz. Integer Linear Programming (ILP) and Sub-optimal search algorithm in terms of the runtime for finding the solution. On average Dest_leaf_finder run time is 35.14×10-3 % of Sub-optimal search algorithm and 16.35×10–3 % of ILP. In all observations, Dest_leaf_finder execution time is significantly less than those of Sub-optimal search and ILP particularly for the datasets Liver disorders (53.3×10–5 % and 30×10–5 %), Australian (2.15×10–5 % and 3.7×10–5 %), Breast cancer (260×10–5 % and 12×10–5 %). When dataset contains more attributes, Dest_leaf_finder run time is slightly more and however much less than Sub-optimal search algorithm and ILP. This can be observed in the datasets A1a (11083×10–5 % and 5945.3×10–5 %), DNA(8501×10–5 % and 1076×10–5 %) and Mushrooms (10355×10–5 % and 7198×10–5 %).
Comparison results of proposed method and two state-of-the-art ensemble tree based algorithms on nine benchmark datasets
Comparison results of proposed method and two state-of-the-art ensemble tree based algorithms on nine benchmark datasets
ILP and Sub-optimal search are employing the ensemble of trees for postprocessing. Postprocessing ensemble of trees obviously requires more computational time.
To compare the performance of Dest_leaf_finder(T3) with Sub-optimal search(T2) algorithm and ILP(T1), statistical tests are performed using the online statistical tool named STAC [37] on the run times given in Table 6. For the experimental results shown in Table 6 where the number of groups k = 3, number of samples n = 9, paired data, the normality condition is not satisfied, but the condition of homoscedasticity is satisfied. Hence, according to the characteristics of the data and as suggested by the online tool the nonparametric test namedFriedman aligned ranks test is performed. For Ranking [11, 33], the established null hypothesis (H0): “the means of the results of two or more algorithms are the same”. From the statistical test results furnished in Table 7, the null hypothesis (H0) has been rejected since the p-value is 0.00106 which is less than the level of significance 0.05. As can be seen from the results in Table 7, it can also be interpreted that there is a significant difference among the mean runtimes and Dest_leaf_finder got the highest rank. For Post-hoc multiple comparison [3, 23], the null hypothesis (H0): “the mean of the results of each pair of groups is equal”. In Pairwise comparison, Dest_leaf_finder is significantly different from ILP. Hence, it can be concluded that the proposed method is best among the compared methods with respect to run time.
Results of Friedman aligned ranks test on run times in Table 6
Results of Friedman aligned ranks test on run times in Table 6
Yang proposed Leaf_Node_Search algorithm [34], a single decision tree based method, to extract actionable knowledge. Kalanat et al. presented F-CEAMA [28] and OF-CEAMA [27] methods for mining actionable knowledge from a single fuzzy decision tree. To our knowledge, these are the state-of-the-art single tree based methods for mining actionable knowledge. Hence, we have compared the performance of our method with them.
For all these methods i.e. Yang’s method, F-CEAMA, OF-CEAMA, and our Dest_leaf_finder, costs of actions are taken in the range $[0–100]. A profit of $1000 is considered, for a customer’s sample, if the probability of belonging to class C1 is 1.0. Experiments are conducted on the original experimental setup as was done by Kalanat [27, 28].
The methods are implemented in Java programming language and the experiments are conducted on a dual core Pentium 4, 2.5 GHz processor with 4GB RAM running with Windows7 Operating System. Experiments are conducted on UCI datasets which are shown in Table 8. All these datasets, except Australian, are imbalanced where majority instances are labelled with ‘Non-churn/Positive’ class. Therefore, from each dataset, instances are randomly selected such that numbers of positive and negative/Churn instances are equal. As Kalanat’s methods [27, 28] use a fuzzy method, their methods’ performance is significant on numeric attributes only. Hence, the datasets are used in two ways. In the first version, we have taken all types i.e. numeric andcategorical attributes(N&C) and in the second version, only numeric attributes(N) from the datasets are taken and conducted the experiments. In these experiments, we have not considered comparing the profits obtained after changing the instance from one leaf to another.
UCI Datasets used in the experiments for run time comparison with single tree based state-of-the-art methods
UCI Datasets used in the experiments for run time comparison with single tree based state-of-the-art methods
The reason is, our method extensively searches all possibilities and eventually outputs only the optimal solution with maximum net profit without leaving any best option which is also illustrated in sections 3.4 and 3.5. The constructed classifier is tested using 10-fold cross validation.
F-CEAMA works with an assumption that all attributes are flexible (whose values are possible to change). On the other hand, OF-CEAMA, Dest_leaf_finder, and Yang’s method considers the reality and separates the attributes as flexible and non-flexible. Experimental results shown in Table 9 describes that when compared with these three methods Dest_leaf_finder exhibits better computational performance. We have presented the run times of our method in both cases i.e. treating all attributes as flexible and only the selected attributes as flexible. When all attributes are flexible, then runtime of Dest_leaf_finder slightly increases since each path from the root to the leaf node has to be fully processed. If the average length of the paths from the root to a leaf node is ‘len’, then, for every path ‘len’ number of comparisons have to be performed. In the other scenario, we only try to change the values of required flexible attributes. In this case, along a path, if a non-flexible attribute is encountered and its value is required to change, then that path is ignored and comparing the values of remaining attributes’ values along that path is not performed. The reason why the run times of F-CEAMA and OF-CEAMA are more than that of Dest_leaf_finder is since their search space is more. This is because, for an instance, F-CEAMA considers multiple source leaf nodes whereas Yang’s method, and our Dest_leaf_finder considers only one source leaf for an instance. Yang’s method considers a large number of candidate actions that leads to more computational complexity when compared to our method. Out of all the attributes, when only numeric attributes are taken from the dataset, then the tree size and number of leaf nodes decrease. Then, Dest_leaf_finder’s runtime decreases accordingly. On the other hand, in the same scenario, the other methods computational time is not decreasing since; the fuzzy concept is appropriate for numeric attributes and they apply the fuzzy approach in every phase of finding fuzzy net profit. Above all, Dest_leaf_finder’s approach is different since it works for multi-class applications whereas the other methods deal the problem as 2-class only.
Run Time comparison results of Dest_leaf_finder and other single tree based state-of-the-art methods
In order to statistically analyze the performance of Dest_leaf_finder with other class of state-of-the-art profit maximizing postprocessing methods based on a single tree viz., Yang’s method, F-CEAMA, and OF-CEAMA tests are performed using STAC on the run times given in Table 9. For the experimental results shown in Table 9 the number of groups k = 5, the number of samples n = 7, paired data where normality has not satisfied and homoscedasticity satisfied. Hence, according to the characteristics of the data and as suggested by the online tool the nonparametric test named Friedman aligned ranks test is performed. From the results furnished in Table 10, it can be interpreted that there is a significant difference among the mean runtimes and the proposed methods implemented in two ways i.e. Dest_leaf_finder(Only) where only numeric attributes are taken and Dest_leaf_finder (all) i.e. all attributes in the dataset are taken got the highest ranks. Post-hoc multiple comparison results also prove that Dest_leaf_finder is significantly different from F-CEAMA, and OF-CEAMA. Therefore, we can say that the proposed method outperforms the compared methods with respect to runtime.
Results of Friedman aligned ranks test on data in Table 9
Results of Friedman aligned ranks test on data in Table 9
To verify the performance of our method on other decision tree construction algorithms, we have used two other standard decision tree construction algorithms viz. Random Tree and Decision stump. Our method is based on a single decision tree. The reason for using these algorithms is, they also generate a single decision tree and the Random Tree algorithm generates a large tree and Decision stump generates a very short tree. Hence, our method can be best compared with the help of these two decision tree construction algorithms. Random Tree algorithm has been introduced by Leo Breiman. During the tree construction, this algorithm finds the best splitting attribute at each node among the randomly chosen subset of attributes. On the other hand, Decision stump [44] algorithm produces a decision tree with only one level and outputs class label of an instance based on a single attribute. For comparison, we have used the dataset in Table 2. Figures 10(a), 10(b) and 10(c) show the PETs constructed using C4.4, Decision stump, and Random Tree respectively on the dataset in Table 2. Table 11 compares the run times and net profits of Dest_leaf_finder on various decision tree construction algorithms on the Telecom sample dataset shown inTable 2.
(a) PET constructed using C4.4. (b) PET constructed using Decision stump. (c) PET constructed using Random Tree.
Performance comparison of Dest_leaf_finder on the trees constructed using various Classifiers on Telecom dataset in Table 2
If an instance has 1.0 probability of belonging to class Non-churn, then profit of $1000 is considered. Cost matrices which are shown in Fig. 5 areused.
Details of the trees constructed using various methods on Table 2 along with their technical evaluation measures are shown in Table 12. As can be seen from Table 12, accuracy and AUC values of Decision stump method are not up to the mark. To differentiate the three methods, a sample X from the dataset in Table 2 has been taken and net profits, when our Dest_leaf_finder is applied on the three trees built using the three methods have been computed. X=Service_Level = Low, Data usage = High, Gender = Male, Call charges = Low. For this sample, C4.4 produced a maximum net profit($500) when compared with the other two methods ($450 and $100). The reason is, C4.4 produced a balanced decision tree with size 8 and 5 leaf nodes.
Details of PETs constructed on Telecom dataset (Table 2) using various classifiers
On the other hand, Random Tree generates relatively large decision tree with more number of leaf nodes. If the height of the tree is more, then there is a possibility of making more attribute value changes which eventually leads to more cost and thereby leads to a reduction in net profit. For performing more number of comparisons and actions it also takes more runtime. Hence, the run time of our Dest_leaf_finder increases when the tree is built using Random Tree method. When the tree is built using Decision stump, a very short tree with only one level is obtained every time. But, the technical interestingness measures of the Decision stump are not in the acceptablerange.
However, as always a single comparison is to be performed, computation time can be very less with Decision stump. The other drawback when the tree is built using Decision stump is, the objective of obtaining maximum net profit does not fulfil. The reason is, always there will be only one possible destination leaf for an instance which has fallen into an undesired leaf node. The total net profit obtained for all the instances (labelled with class ‘Churn’) from the dataset in Table 2 by postprocessing the trees built using C4.4, Random Tree, and Decision stump are $2390, $2100, and $700 respectively where C4.4 is yielding maximum.
Experiments also conducted on10 UCI datasets to verify the performance of Dest_leaf_finder on three decision tree algorithms. Table 13 compares the run times on three decision tree construction algorithms. Same profit values and action costs are employed as discussed in Section 4.2. For each dataset, trees are built using the three decision tree methods. For each instance in a dataset, a destination leaf node with a maximum net profit is computed on each tree separately. Such a way computational time for all the instances in each of the 10 UCI datasets is recorded on three trees. It has been observed that Decision stump is outperforming the other two. But the Decision stump’s technical evaluation measures are poor on all the datasets as proven in the following statistical analysis.
Run time comparison of ‘Dest_leaf_finder ’ on three Decision Tree construction algorithms on UCI data
To compare the runtime performance of the classification model constructed using C4.4 against the models built using Random Tree and Decision stump statistical tests are performed using STAC on the data in Table 13. For the given data in Table 13, the number of groups k = 3, number of samples n = 11, paired data where normality is not satisfied and homoscedasticity satisfied. Hence, according to the characteristics of the data and as suggested by the online tool the non-parametric test named Friedman aligned ranks test is applied. From the results shown in Table 14, it can be interpreted that there is a significant difference among the mean runtimes and Decision stump got the highest rank followed by C4.4. In Pairwise comparison, C4.4 is significantly different from Random Tree but has no significant difference from Decision stump.
Results of Friedman aligned ranks test on data in Table 13
Results of Friedman aligned ranks test on data in Table 13
Complete technical evaluation measures of three decision tree algorithms are presented in Tables 15, 16, and 17. These results also depict that C4.4 exhibits better performance in all aspects. However, it can be observed from Table 17 that the accuracy and AUC measures of Decision stump are not in the acceptable range on many datasets. For Decision stump, average accuracy and AUC values are 64.38 and 0.6791 respectively which are not up to the mark.
Technical evaluation measures of C4.4 on UCI datasets
Technical evaluation measures of Random Tree on UCI datasets
Technical evaluation measures of decision stump on UCI datasets
After Decision stump, C4.4 run time performance is fine when compared with Random Tree. Average accuracy and AUC values of C4.4 are 79.666 and 0.8588 which are even better than the values of Random Tree i.e. 75.81 and 0.79.
Table 18 compares the accuracy of three classifiers and Table 19 compares the AUC of three classifiers on 10 UCI datasets.
Comparison of Accuracy of three classifiers
Comparison of AUC of three Classifiers
For the statistical analysis of the accuracy and AUC of C4.4 against two other classifiers, we have used the same web platform STAC. For the given data in Tables 18 and 19, the number of groups k = 3, number of samples n = 10, paired data where normality is not satisfied and homoscedasticity not satisfied. Hence, the nonparametric test i.e. Friedman aligned ranks test is performed. The statistical test results presented in Tables 20 and 21 depict that there is a significant difference among the mean accuracy and also among the mean AUC values. Regarding two metrics, C4.4 got the least rank with respect to minimization and therefore provides the highest accuracy and highest AUC. The Post-hoc multiple comparison results in Tables 20 and 21 also describe that in pairwise comparison, C4.4 is significantly different from Decision stump, but not significantly different from Random Tree with respect to accuracy and AUC.
Results of Friedman aligned ranks test on Accuracy data in Table 18
Results of Friedman aligned ranks test on AUC data in Table 19
The run time of our Dest_leaf_finder increases when tree size increases. A tree possessing acceptable technical evaluation measures (Accuracy, AUC, etc.) and is shallow with less number of leaf nodes is preferable for our work. The benchmark method C4.4 serves this purpose. It can be concluded that still, C4.4 is the remarkable classifier since its accuracy and AUC are significant and produces reasonably shallower trees which are suitable for the research in this paper.
We consider the real Telecom dataset whose details are discussed in Section 3.2 for experiments. First, we perform the experiments on the total dataset and show the runtime results. We show that our method is efficient and scalable in this 2-class scenario. Thereafter, we verify the performance of the proposed method on the sample data extracted from the original dataset. Later, to demonstrate the performance of our method on multi-class setting, we also consider the 3-class version of this data and perform the experiments.
Experiments on 2-class real Telecom data
In this section, we verify the performance of our Dest_leaf_finder on the large real time Telecom dataset, whose details are discussed in Section 3.2. Out of the 15000 customers records in this dataset, 2500 are ‘Churn’ and the remaining 12500 are ‘Non-churn’. To avoid imbalanced decision tree thereby predicting most of the customers as ‘Non-churn’, we have randomly sampled 2500 ‘Non-churn’ records out of the 12500 records, and all the 2500 ‘Churn’ records are used. Experiments are performed totally on 5000 records.
A PET is built using C4.4 method. After the PET is constructed, it is tested using 10-fold cross validation method. The constructed PET has 734 leaf nodes. Out of them, 388 represented the class label ‘Churn’ and the remaining 346 represented the class ‘Non-churn’. Costs are taken in the range $[0–200]. If an instance has 1.0 probability of belonging to class Non-churn, then a profit of $1000 is assumed. Then, we applied our Dest_leaf_finder on the constructed PET.
Performance comparison with other Tree construction algorithms on Telecom data: Performance comparison of proposed method is also done on various other tree construction algorithms on the real Telecom dataset. Technical evaluation measures of the PETs constructed on the Telecom dataset on 5000 records using the three decision tree algorithms is presented in Table 22. The results in Table 22 depict that C4.4 shown better results than those of the other two. We have made the comparison of run times by using the three PETs separately. Each time a set of records from the dataset are taken and given as the input to Dest_leaf_finder. For each of these set of records, the proposed algorithm determines optimal destination leaf with maximum net profit on three trees separately. Total runtime for all the records in the set is recorded. Each time we have increased the size of the input data samples. Runtimes of the proposed method on the real Telecom data on different classifiers is presented in Table 23.
Technical evaluation measures of various decision tree algorithms on Real Telecom dataset
Technical evaluation measures of various decision tree algorithms on Real Telecom dataset
Performance comparison of Dest_leaf_finder on Real Telecom dataset using various Tree construction algorithms
From the results shown in Table 23 it has been observed that the proposed method is scalable when it is applied on the tree constructed using C4.4. On the other hand, runtimes of Dest_leaf_finder are increasing more when it is applied on the tree constructed using the Random Tree. Total and average run times of the method when applied on C4.4 is at least ten times less than that of Random forest. Though the Decision stump’s runtime values are better than that of C4.4, it is not considered since its accuracy and AUC values are low. From the results in Table 22, it can be seen that the accuracy and AUC measures of Decision stump are 60.23 and 0.601 which are not in the acceptable range. On the other hand, C4.4 exhibited comprehensive values for accuracy and AUC i.e. 88.04 and 0.892 respectively.
Statistical test: Statistical tests are performed on the run times presented in Table 23 to compare the performance of C4.4 with other classifiers using the STAC platform. For the given data in Table 23, Friedman aligned ranks test is performed since normality not satisfied and homoscedasticity is satisfied. From the results shown in Table 24, it can be interpreted that there is a significant difference among the mean runtimes and Decision stump got the highest rank followed by C4.4. In Pairwise comparison, C4.4 is significantly different from Random Tree but has no significant difference from Decision stump with respect to runtime.
Results of Friedman aligned ranks test on data in Table 23
To validate the efficiency of our proposed algorithm, we have performed the experiments on the subset of real Telecom data discussed in Section 3.4. This dataset contains 14 examples as given in Table 2 whose profit value (PA) and cost matrices details are also discussed in Section 3.4. Experimental results are presented in Fig. 11, where the log scale is used in all the graphs on both x-axis and y-axis and incremented by multiples of 10. For each instance, the run time to find the best destination leaf node with maximum net profit is recorded. For notable observation of the run times of the proposed algorithm, one instance has been randomly taken from the dataset and it is iterated for a large number of times and the run times are recorded. Figure 11(a) depicts the run time of one instance on a different number of iterations with the proposed method. This has been observed for different instances from the dataset and also for a different number of iterations. As the other case, we have taken the entire dataset and noted the execution time on large number of runs. In this case, from the dataset, each time one instance is given as input to Dest_leaf_finder for finding the best solution, and the run time is recorded separately. Such a way, run time is recorded for all the instances of the dataset. This process is repeated for a large number of times on the same dataset to have clear observation. The graph shown in 8(b) depicts that in all the cases, run times are increased linearly with the increase in the size of the dataset. The total net profit obtained after transforming all the ‘Churn’ customers as ‘Non-churn’ is $2390. However, the net profit obtained for each of the customer’s instance is not presented in the experimental results since in all scenarios our method provides a maximum possible value.
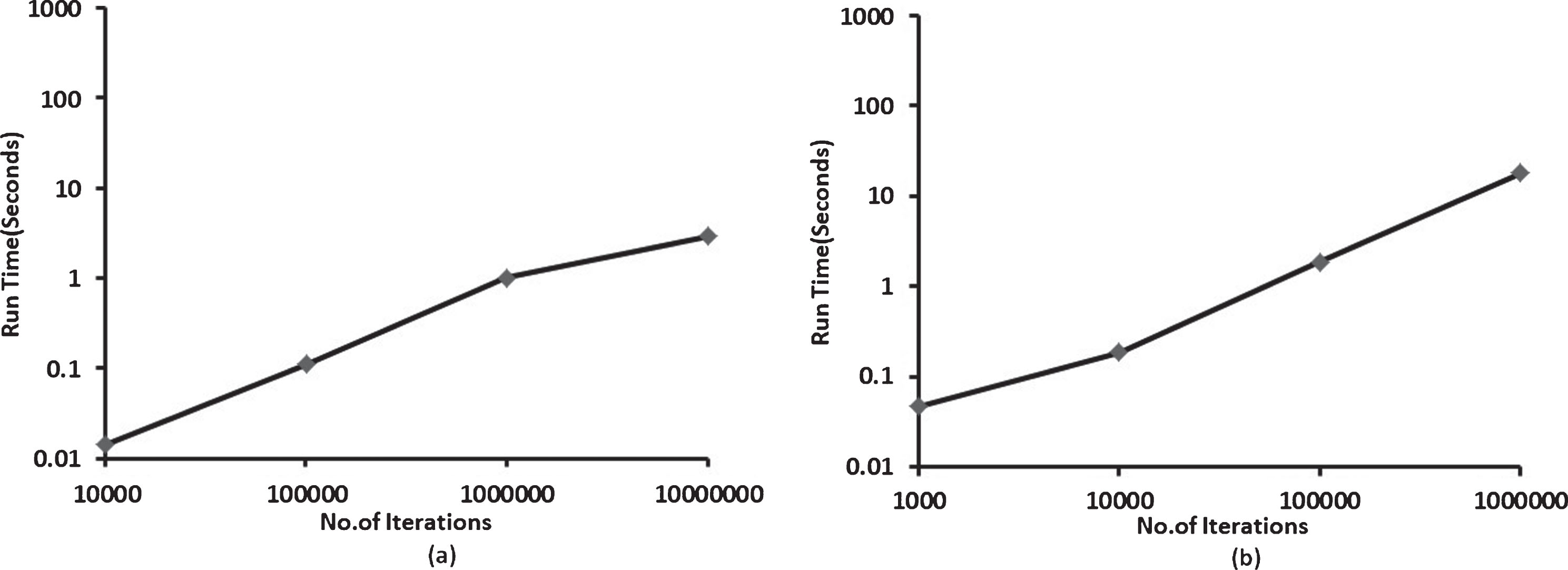
Run Times of Dest_leaf_finder on the sample 2-class Telecom dataset. (a) Single instance of 2-class Telecom data (b) Entire 2-class Telecom data.
To explain the working of our proposed method for multi-class setting, we have used the 3-class version of the real Telecom data with 125 customers’ records which is discussed in Section 3.5. In this case, an attempt is made to change ‘Churn customer’ as either ‘Non-churn and active customer’ and if not possible at least as a ‘Non-churn but inactive customer’. However, a ‘Non-churn but inactive customer’ will be converted as a ‘Non-churn and active customer’. This scenario is familiar in the Telecom industry since, a good percentage of customers are not cancelling their subscription, stay with the service provider but inactive in using the services thereby leading to least profits. Profits are considered such that if the customer’s C1 class probability is 1.0 then profit is $1000, C2 class probability is 1.0 then profit is $500 according to the expert in the Telecom business. First, one record is taken from the dataset and it is iterated significantly a large number of times and the total run time is noted. Figure 12(a) shows the running times of Dest_leaf_finder for this scenario. Here the observed run times are high as compared with the case observed in Fig. 11(a) where dataset size is 14 and the number of leaf nodes in the tree is 5 only. As the 3-class Telecom dataset contains 125 records, the size of the induced decision tree is large with 17 leaf nodes. Hence, there are 16 possibilities for finding the destination leaf. This is the reason for the increase in the run time as compared with the run times in the case of 2-class dataset in Fig. 11(a).
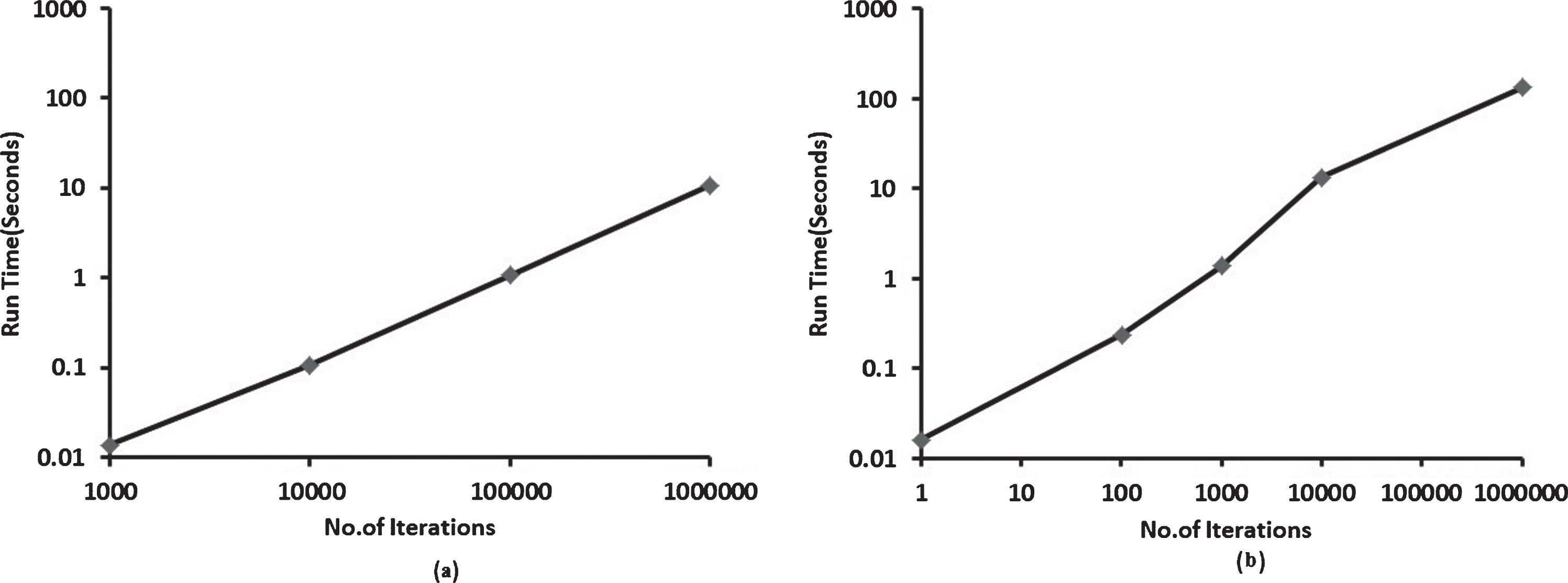
Run Times of Dest_leaf_finder on the real 3-class Telecom dataset (a) Single instance of Telecom data (b) Entire Telecom dataset.
As another case, we have also iterated this entire dataset significantly large number of times to clearly verify the runtimes. The results are depicted in Fig. 12(b). For the same scenario shown in Fig. 11(b) for the 2-class dataset, the recorded runtimes are low. The reason for the increase in the runtime for Telecom dataset is, in one iteration 125 records are given as input to the large tree whereas in the former case (Fig. 11(b)) 14 records as input to a simple decision tree.
Dest_leaf_finder fits well and it is relevant to the Telecom sector, the industry facing high attrition rate and fall down in profits due to various classes of reluctant customers. When the churning problem of Telecom sector is perceived as a 2-class problem, the work of Dest_leaf_finder is much easier since it tries to find a destination leaf which is labelled with ‘Non-churn’ only. For the other practical case where the customers are treated as belonging to three classes, the proposed method provides optimal profit maximizing solution. It sets most of the existing customers to be in higher desirable classes in this case.
According to circumstances, even if the Telecom customers are classified as belonging to more than three classes based on the profitability, the proposed method can shift the customers from lower profitable classes to higher profitable classes. Eventually, the proposed method’s objective is increasing profits of Telecom sector which is a vital task for it. It can be concluded that for all contexts of the case study problem, proposed method provides maximum possible net profit and its run time efficiency is fine and especially its performance on the C4.4 decision tree is superior. The proposed method provides an efficient solution by reducing the search space in finding the solution and incorporating some of the steps like the early stopping of considering a candidate destination leaf when an unchangeable attribute is encountered along the path of destination leaf. Thus, the proposed method can provide efficient and lucrative solution to the Telecom sector.
In the challenging Telecom industry, to support the decision making process, decision makers rely more on various data mining methods since the undesired status of the customers need to be changed to the desired one to acquire more profits. In this paper, we presented a method, suitable for Telecom sector, for automatic mining of knowledge in the form of actions from probability estimation decision trees (PETs) that can change a customer’s class from undesired to a desired one with the maximum net profit. We presented a method Dest_leaf_finder which produces customized retention and more profit yielding actions for each customer of a Telecom service provider who is predicted to be churner/less profitable. Present research treats the actions extraction problem as a 2-class problem, but the number of classes of customers of Telecom sector can be of more than two. Dest_leaf_finder provides a profit maximization solution for the multi-class setting of Telecom business when the customers’ classes are in the order of profitability in descending order viz., C1, C2, C3, C4, ... , Cn. If a customer’s instance has fallen into a leaf node with class-i (i > 1 and i≤n) of PET which is undesirable/less profitable then Dest_leaf_finder suggests the actions to shift that instance to a possible and desirable/more profitable leaf node with class-j (j < i and j≥1). We have discussed the working of our method with the help of a case study pertaining to Telecom sector. First, a 2-class scenario in this sector is addressed followed by providing a solution for a 3-class case. Then, we have formulated and provided a solution to this domain with n number of classes of customers where n≥2. Eventually, our research perfectly fits the Telecom sector which is the big victim due to churning and less profitability.
Experimental results on realistic Telecom case study data and UCI ML datasets prove that our Dest_leaf_finder achieves remarkable runtime performance when compared with the ensemble tree based and also single tree based state-of-the-art methods. Experimental results also demonstrated that, when compared with other decision tree algorithms, our proposed algorithm exhibited better performance on C4.4 decision tree algorithm. Irrespective of the number of classes of customers of Telecommunications enterprise, the method discussed in this paper provides an effective solution.
As future work, research can be performed through integrating more domain knowledge and can be executed as a domain driven approach for versatile problems of other sectors viz. E-Commerce, medicine, education, software industry employee’s attrition, etc. This work can also be extended to the fields where we find uncertain data pertaining to classification.