
Abstract
Combining natural language processing technology, image analysis technology and malware detection technology, a novel Android malware detection method, named BIHAD (an improved IndRNN and attention-treated DenseNet-based pipeline model), is proposed in this paper. First, in order to describe the behavior of Android malware, multiple features are used to construct a more stable discriminant method. Second, the embedding technology is introduced to map all behavior information into a vector space, which implements the extraction of the joint embedded information of semantics and images. Third, an improved Independently Recurrent Neural Network (IndRNN) is used to extract valuable texture information from the original values of the gray image, and effectively utilized the long distance information contained in the gray image. Finally, Hierarchical Attention Dense Convolutional Network (HADenseNet) is used to ensure the maximization of information flow between layers in the network, improving the utilization of semantic distribution and spatial context information. Especially, Hierarchical Attention can enhance the representational ability for key features. The comparison of the BIHAD model with several existing malware detection methods indicated a significant improvement in F-score achieved by the BIHAD.
Keywords
Introduction
With billions of people using smartphones, smart devices are used to store sensitive personal information more frequently than laptops and desktops. Mobile device security is a security area of rising significance and cumulative need, but it is a comparatively weak area in protecting user’s data privacy [1, 2]. To put this into perspective, according to a recent report from Kaspersky Lab, up to $1 billion was stolen in roughly 2 years from financial institutions worldwide due to malware attacks. In addition, malware authors use some techniques, such as instruction virtualization, packing, polymorphism, emulation, and metamorphism to write and change malicious codes that can evade detection, which culminated in a massive proliferation of new malware samples due to their wide availability [3].
The traditional static signature matching technology [4] obtains the bytecode data stream information by the reverse technique and then matches with the data segment of the malicious signature sample to ascertain whether the detected file is a malicious file. To a certain extent, traditional static signature matching technology is incompetent to unknown malware, because the accuracy of malware detection depends on whether the feature library is perfect. Static malware analysis techniques offer a fast and useful mechanism for extracting meaningful information from a suspicious application. Different techniques, which fall within the scope of the so-called obfuscation techniques [5], are deliberately employed with the aim of shaping the code into a new different scheme. For example, a series of useless system calls can be introduced into a section of a piece of code, which is executed based on a condition, whose evaluation is always false when is executed. Therefore, static analysis is susceptible to obfuscation techniques and cannot effectively capture semantic information and sequential patterns in strings.
Word embedding technology is introduced to extract unknown behavior information for the malware to be detected, which provides more information for additional morphology parsing, reducing the impact of obfuscation techniques and the risk that virtual machines may be infected in dynamic analysis. Clearly, a better characterization of Android malware would achieve better accuracy for malware detection [6]. Word embedding is a technique in Natural Language Processing (NLP) that transforms the words in a vocabulary into dense vectors of real numbers in a continuous embedding space [7]. A typical word embedding method relies on the co-occurrences of a target word and its context, while traditional NLP systems represent words as indices in a vocabulary that does not capture the semantic relationships between words. Word embedding such as those learned by neural networks can explicitly encode distributional semantics in learned word vectors. We proposed a general framework to encode different types of behavioral information while using a neural joint model to detect Android malware. Compared with a set of neural network models, the proposed method has stronger generalization ability and can describe the behavior of Android malware more comprehensively.
Related work
The number and complexity reached by the newest malware forces make it an inevitable choice to explore new advanced techniques capable of analyzing and tackling the different problems. The huge amount of malware makes this impossible for human engineers to perform traditional software analysis for every malware sample. In this case, the analysis methods of malware can be divided into machine learning (ML) based methods and deep learning (DL) based methods. The ML-based detection methods can identify and detect malware using static or dynamic analysis to extract a set of features. Navarro et al. [8] proposed an ontology-based framework to shape the relationships between application and system elements. Considering the details of similarities among malicious programs, Chen et al. [9] discussed the construction of malware samples under three different threat models and analyzed how the ML-based classifiers are misdirected. Further, they proposed KuafuDet to address the adversarial environment, which can boost the detection accuracy by at least 15%.
Deep learning [10, 11], which simulates the mechanism of a human brain to interpret data, is a new area of the ML research, and it is increasingly applied to Android malware detection. Albasir et al. [12] proposed a novel framework based on deep learning. They utilized the deep learning ability to classify power consumption signals. Karbab et al. [13] and Yuan et al. [14] adopted the DL-based methods to detect malware automatically, both of which improved detection accuracy compared to the ML-based methods.
In this paper, we proposed an Android malware detection framework based on DL to improve the utilization of semantic distribution information and spatial context information. This framework is applied to learn a nonlinear embedding and to encode different types of semantic information (see the details in section 3). Specifically, the improved texture features are integrated into word and character embedding. This approach allows the proposed neural joint model to simultaneously capture semantic and image information and to deal with unseen words that might not be in the vocabulary, while also alleviating the degradation of detection performance due to the presence of too many new words. Experimental results show that the proposed BIHAD is consistently and significantly superior to other existing methods.
The main contributions of this paper are as follows: To obtain the distribution semantics of words from a text corpus, we combined different types of behavior information of malware and implemented the extraction of joint semantic and image information. We also enhanced the quality of word vectors by capturing the semantic information of malware and their relationships. This word embedding technology is used to solve too many new word problems, so that we can obtain representations of these unseen words, reducing the impact of the obfuscation technique and facilitating the promotion of the representations. The proposed neural joint model (BIHAD) can automatically identify and learn the semantics and sequential patterns and do not rely on any other complex or expert features for the learning task.
Methodology
The overview of BIHAD model
We proposed a malware detection algorithm combined the improved IndRNN, Hierarchical Attention [15] and DenseNet [16] to form a neural joint model (BIHAD). First, we used BiIndRNN to encode pixel information from gray-scale image into a texture-level representations. However, texture features are not able to exploit semantic distribution information and the character embeddings is not able to exploit long sequences information and ignores word boundaries. It is necessary to consider word embeddings. Therefore, texture representations, word embeddings and character embeddings are fed into a Hierarchical Attention (HA) Dense Convolutional Network (DenseNet) to learn the representations of behavior information contained in a malware. Specifically, the BiIndRNN and HADenseNet in the proposed framework are integrated to form a pipeline, i.e. the output vectors of IndRNN [17] units in the BiIndRNN are used as the input vectors of HADenseNet. Moreover, the parameters of BiIndRNN are shared by both the BiIndRNN and HADenseNet networks, so they are jointly affected during training. Figure 1 provides an overview of our architecture. The related source code is released on our github page2.
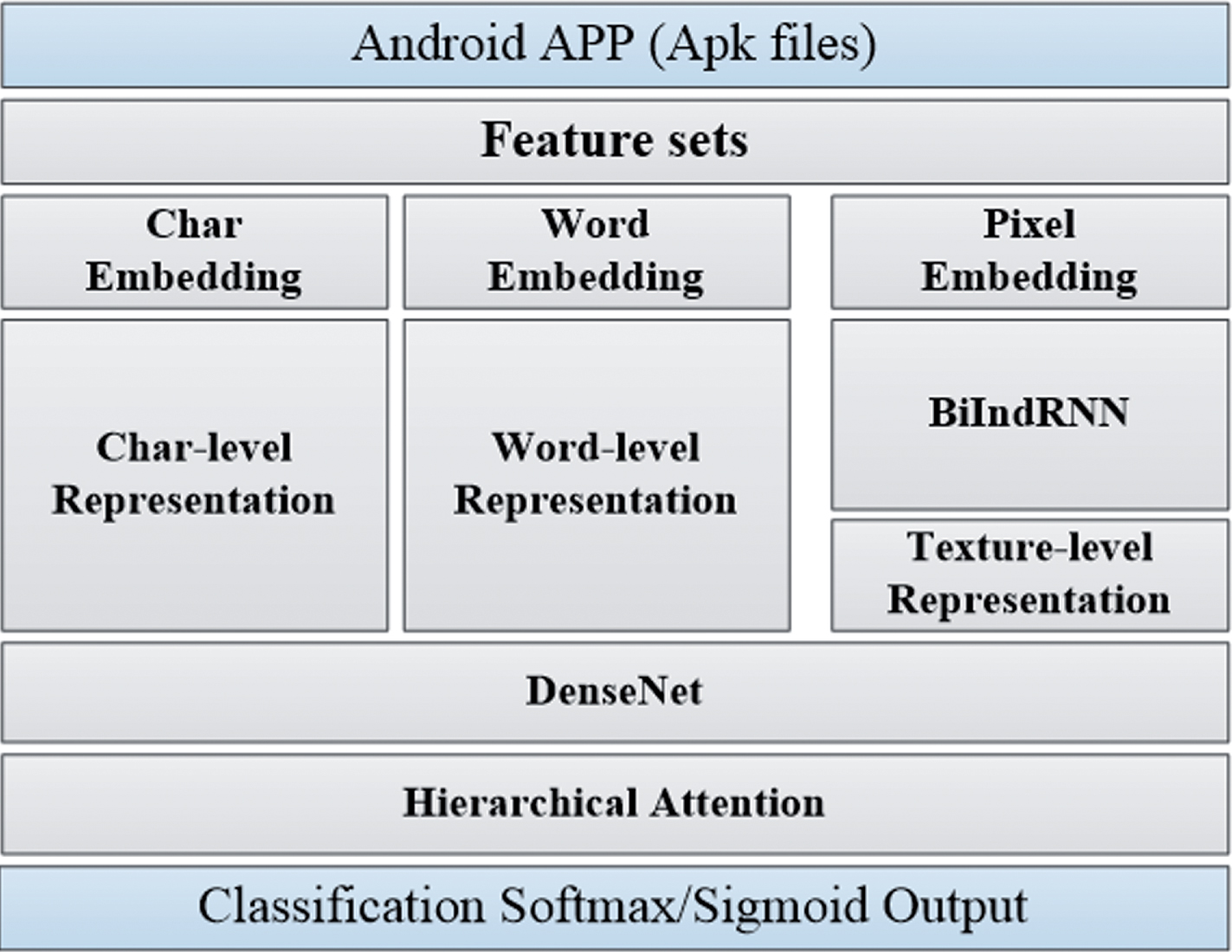
An overview of BIHAD architecture.
This remaining content of this section is arranged as follows: Section 3.2 mainly introduces the feature model, which maps the behavior information of malware into texts and then converts them to gray-scale images. The details of the proposed BIHAD model will be given in Section 3.3.
Feature extract
Malicious activities are usually reflected in specific patterns and combinations of various features. There are distinct patterns or combinations of features extracted between malware and benign software. We try to bypass complex code analysis and use a lightweight static analysis to extract features to reflect this difference. We designed the feature model with three necessary elements, including permissions, components and suspicious API calls. This strategy allows us to obtain good performances while keeping the complexity as low as possible. Permission features: Malicious behaviors of an application require certain permissions to launch goals. It means that permissions defined in an application can imply the latent malicious behaviors of an application. In fact, some experienced anti-malware developers can roughly identify malware based on the list of requested permissions. Component features: Application components are the essential building blocks of an Android application, which includes activity, service, content providers and broadcast receivers. The name of each component is extracted and gathered in a component feature set as these features may be useful in identifying well-known components of Android malware. Suspicious API call features: Certain API calls are frequently found in malware, which makes malware to access sensitive data possible. As such, these calls may imply the malicious behaviors of an application and the coding habits of the developers. The suspicious API calls introduced in [18] are extracted into the selected API feature set, which may be useful for distinguishing the benign application from the malware.
These features were extracted and stored in a text database comprising of all observable strings. Table 1 lists the representative observable strings extracted from an application. All these information are helpful for effectively identifying malware. As a result, we extract words, characters and texture features from a set of observable strings and embed them into a joint vector space to fully describe the behavioral characteristics of a malware. This representation enables us to automatically identify the combinations and patterns of malware features.
Representative observable strings extracted from an application
Representative observable strings extracted from an application
In order to better describe the malware behaviors, we explain the texture features in particular. Note that gray-scale images in traditional malware analysis methods allow researchers to understand the structure of malware files without disassembling. Previous work [19, 20] has proven the effectiveness of gray-scale images for the neural network model. A typical approach is to reformat the malware binary file as a sequence of 8-bit strings, and each 8-bit further read as an unsigned integer. Compared with previous work, the purpose of this paper is to map a set of strings consisting of malware behavior features into a gray-scale image. Each character in a set of strings can be reformatted as a decimal-encoded representation of an integer value of ASCII (in the range [0,255]). In particular, the vector is set to a fixed-line width so that the entire file ends up in a two-dimensional array. This visualization of this two-dimensional array helps malware researchers intuitively understand the spatial information of malware and the behavioral characteristics of sequential patterns. Figure 2 illustrates the visualization process of extracting pixel information from a gray-scale image and encoding them into a vector representation at pixel-level.
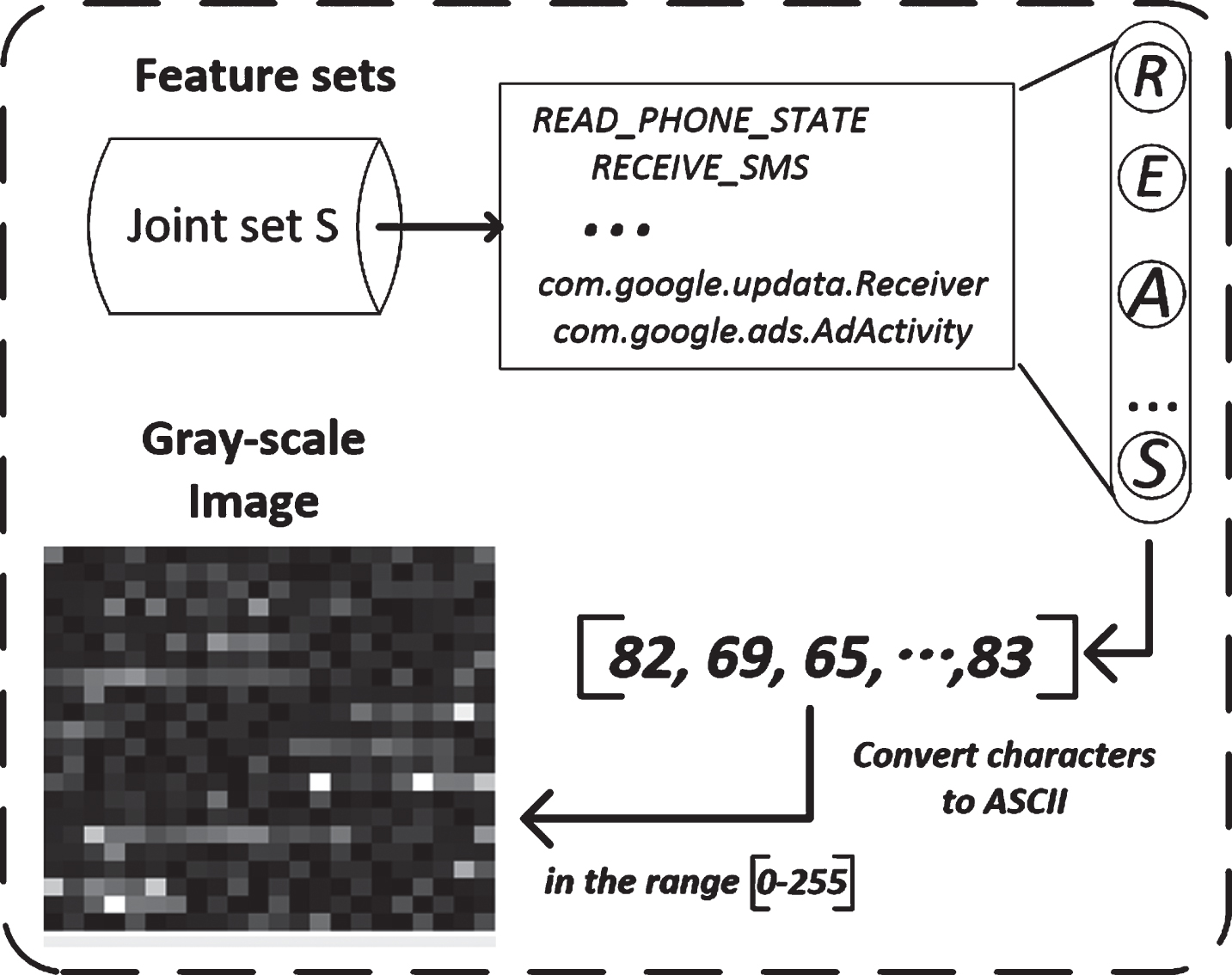
Android malware visualization process.
The improved Independently Recurrent Neural Network (IndRNN)
Li et al. [17] proposed a new type of recurrent neural network (RNN), referred to as independently recurrent neural network (IndRNN), which has been demonstrated to be effective on multiple fundamental tasks. However, the standard IndRNN often ignore future context information in the processing sequences. One obvious solution is to add future information to predict the output together. This is very useful for us to access previous and future context information. Therefore, we further proposed a new type of IndRNN, referred to as bidirectional independently recurrent neural network (BiIndRNN), to improve the modeling ability for integrating forecast knowledge.
The BiIndRNN for texture level representations
The texture is a description of the spatial distribution pattern, which includes important text structure and position distribution between characters. In order to improve the information representation ability of images, based on the texture similarity of the same type of malware, we used the BiIndRNN model to extract the texture features from a gray-scale image. The extraction process of the texture feature is shown in Fig. 3.

The BiIndRNN for texture-level representations.
Given a gray-scale image g = (P1, P2, . . . , P N ), p i denotes its i-th pixel and Emb (P i ) denotes the embedding of this pixel. To use pixel information, the BiIndRNN layer takes the pixel embeddings as input. The hidden state h of the BiIndRNN unit at time step t can be described as:
Where W is the input weight and u is the recurrent weight that is diagonalizable. The Hadamard product ⊙ of two matrices u and ht-1 with the same dimensions can be represented in the form of a matrix product, which is the entry-wise product. For example, if
Then,
In our implementation, the BiIndRNN contains the forward IndRNN
Where W
n
and u
n
are the n-th row of the input weight and recurrent weight, respectively. To capture the future information, we also added a corresponding
Each neuron in an IndRNN deals with one type of spatial-temporal pattern independently. For each time t, the input Emb (P
i
) is provided to IndRNN in opposite directions at the same time, and both one-direction IndRNN determines the output. Thus, we will obtain two vectors for a pixel embedding, the one is the vector from the normal sequence processed in the left-to-right direction by a hidden state
Where “[]” is the concatenation operation. Each hidden state h t contains information about the whole input sequence, which focuses on the parts surrounding the t-th pixel of the input image. In this way, the hidden state h t contains the information of both the preceding pixels and the following pixels and gets a texture-level vector representation T i at time t.
Where “[]” denotes the vector concatenation. The concatenated vectors are inputted into an improved HADenseNet algorithm module, where a DenseNet is used to extract the context information and retain the correlation information; subsequently, an attention mechanism is used to enhance the probability weight of the target. Figure 4 illustrates this layout schematically.
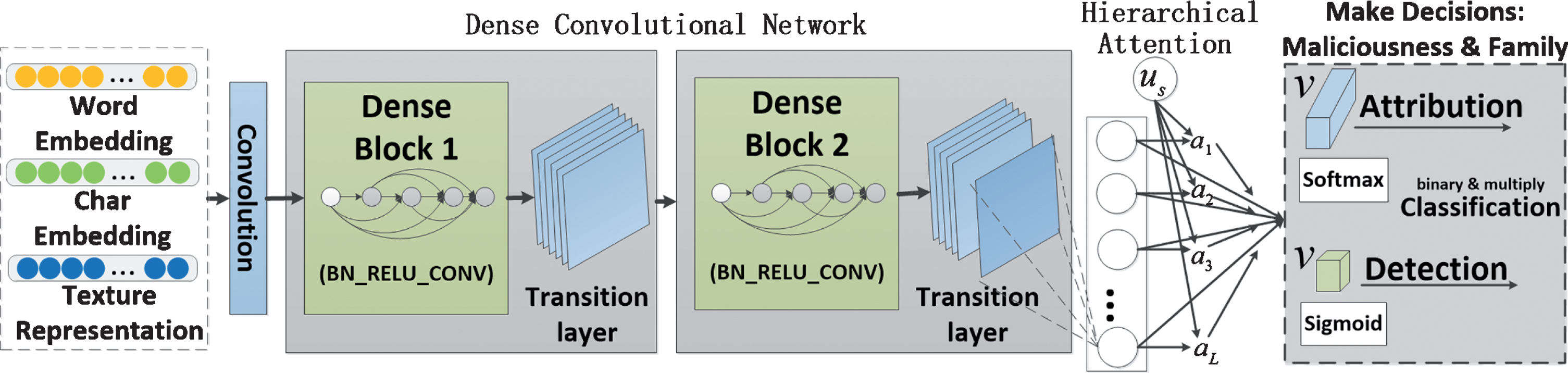
The HADenseNet for Android malware detection and attribution.
The DenseNet comprises L layers, each of which implements a non-linear transformation H
l
(•), where Hℓ (•) serves as a composite function of three consecutive operations: Batch Normalization (BN), rectified linear units (ReLU) and convolution. The l-th layer has l input, and feature maps are passed on to all L-l subsequent layers. We denote the output of the l-th layer as
Where [x0, x1, . . . , xl-1] refers to the concatenation of the feature-maps produced in layers. In addition, the transition layers between two adjacent blocks are referred to change feature-map sizes via convolution and pooling.
The weight a
i
of each word xl,j is computed by
After the above calculation, we can get the normalized importance weight a i for each word. The vector v depends on a sequence of words (xl,1, . . . , xl,T) in the l-th layer, which computed as a weighted sum of these words. Lastly, the vector v can be invoked as features for malware binary or multiclass classification.
Decision-making: There are two tasks in the decision making module: the detection task for binary classification and the attribution task for multiclass classification.
For the detection task, the Sigmoid function is used as the output layer to model the binary probabilities.
The Sigmoid function converted the classification result into label probability:
For the attribution task, the Softmax function is used as the output layer to model the multiclass probabilities, i.e. y
multiclass
∈ [0, 1]
k
.
The Softmax function gives a probability distribution over the K classes by exponentiating and normalizing:
Having the same architecture in both the detection and attribution subtasks makes the development and the evaluation of a given design simpler.
In order to prove that the proposed algorithm has good generalization ability, we carried out experimental research from the following aspects: (1) In the case of ensuring that the variable parameters of different models are as consistent as possible, we demonstrated the superiority of the proposed algorithm (BIHAD) in terms of performance. (2) We evaluated the impact of different attention mechanism for the neural joint model performance. (3) We evaluated the efficiency of BIHAD. (4) To highlight the contribution of this study, we compared BIHAD with previous similar studies. (5) We demonstrated that the proposed BIHAD can be effectively applied for large-scale detection. (6) We conducted an additional study to evaluate the resiliency of BIHAD for sophisticated obfuscation schemes. (7) To verify that the proposed BIHAD can reliably detect different malware families, the performance of BIHAD in malware family identification was evaluated.
Datasets
A key challenge in Android malware detection research is the availability of representative data. Drebin [18] is an Android dataset with 5, 560 malware collected from August 2010 to October 2012. All malware samples are labeled by one of 179 malware families. AMD [25] is the newest dataset with 24,553 malware files collected from 2010 to 2016. All malware samples are categorized into 135 varieties among 71 malware families. Along with these malware datasets, we also collected a lot of real-world Android applications (including 4,664 benign apps) from various resources.
Here we made some comparison between the DREBIN and the AMD for further experiments. Table 2 shows the size of the overall features. Note that even though there are a fixed number of system permissions, but developers can still declare self-defined permissions so that the words in a vocabulary has increased. As described in the previous section, we use the word embedding to count the frequency of occurrence of words in all samples, which focus on words with higher frequency. This makes the words of low frequency almost ignored during the feature extraction phase.
Size of extracted feature sets on Drebin and AMD datasets
Size of extracted feature sets on Drebin and AMD datasets
Additionally, AndroZoo (AZ) [26] is an online Android app collection that archives both benign and malicious apps. In order to demonstrate the performance of the proposed method in large-scale detection, we used 110,000 samples from the AZ dataset (55,000 benign apps and 55,000 malware) for further experiments. The Praguard dataset (PG) [27] is an obfuscation benchmark suite, which contains 1,497 obfuscated malware. We used the Praguard dataset to evaluate the resiliency of the proposed method for sophisticated obfuscation schemes.
Experimental results of neural joint networks comparisons on the two benchmark datasets
Experimental results of neural joint networks comparisons on the two benchmark datasets
In the baseline experiment, we utilized CNN to extract the semantic distribution and spatial information and achieved good results. However, it is not yet possible to compare with the results given by DenseNet. When we use DenseNet, the detection rate (recall) was improved, such as LSTM+DenseNet and IndRNN+DenseNet. We can see that the advantages of DenseNet in dealing with high-dimensional eigenvectors, which ensures that the information flow between layers is maximized, and enhances the propagation and reuse of features, resulting in better performance than other baselines. Moreover, when we stacked hierarchical attention on top of DenseNet, the detection rate of all baselines were improved. Hierarchical attention is used to achieve integration information flows and to avoid loss of semantic information between layers.
Experimental results demonstrated that the attention mechanism is important for revealing malicious behavior patterns. As presented in Table 3, the proposed BIHAD-based produces the best performance under all metrics. It demonstrated the superiority of the proposed method in this paper. Additionally, Fig. 5 shows the training and validation losses over 50 epochs. It is seen that the validation losses are similar to the training losses.
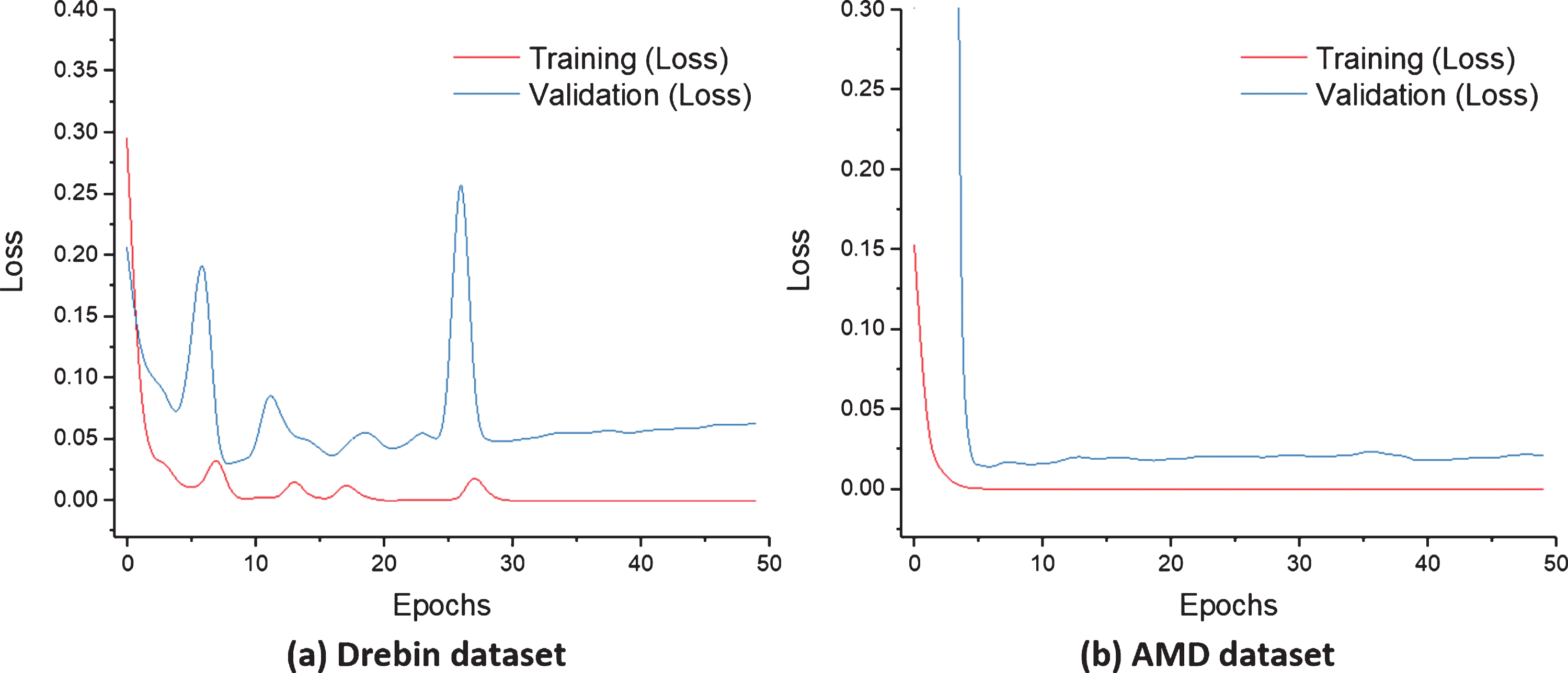
Training and validation loss for the two benchmark datasets.
In particular, we evaluated the efficiency of BIHAD against rival methods and recorded the overall runtime of BIHAD for classifying 1,865 samples from the Drebin test set and 1,728 samples from the AMD test set. Figure 6 show the overall runtimes of different neural joint models for the classification on two benchmark datasets. The result shows that for the BIHAD model, the overall runtimes for classifying the Drebin test samples and the AMD test samples are only 6.69 seconds and 4.05 seconds, respectively.
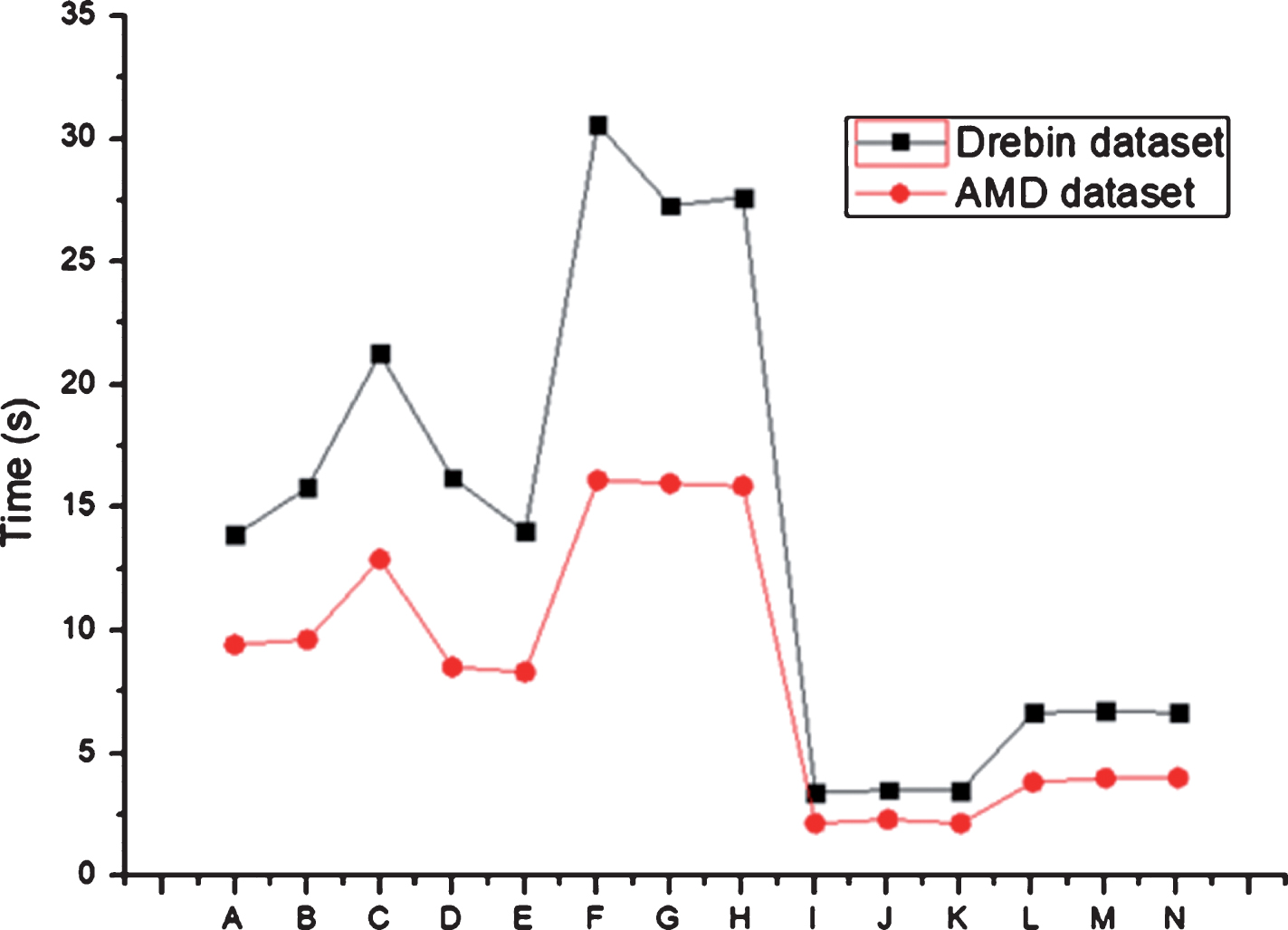
The overall runtimes of different neural joint models for classification are compared on the two benchmark datasets.
In this study, we compared three attention mechanisms to verify the effect of different attention mechanisms on performance. The details are given in Table 4. As we can see, self-attention [28] is closest to our results on the Drebin dataset, while it performs poorly on the AMD dataset. The performance of the multi-headed attention [29] on both datasets was stable, but it is still not comparable with the result given by hierarchical attention. This may be explained by the complexity of Self- and Multi-headed attention, which makes the classifier learn too much noise so that the performance is reduced.
Experimental results of different attention mechanisms comparisons
Experimental results of different attention mechanisms comparisons
In this paper, we evaluated the efficiency of BIHAD in detecting arbitrary malware. On the desktop computer (GeForce GTX 1060 with 8GB RAM) we achieved a remarkable analysis performance. As shown in the previous sections, our system consists of two parts: the feature extraction and the classification. We focused on evaluating the processing time for feature extraction and then giving an average runtime for processing one sample.
In general, the last classification takes much less time than the feature extraction. The results are shown in Fig. 7. For different applications, the classification typically requires a fixed processing time due to the fixed feature space size. The two figures in the first column show the relationship between the apk file size and the runtime of the feature extraction. The two figures in the second column show the relationship between the apk file size and the runtime of classification. The two figures in the third column show the relationship between the apk file size and the overall runtime. As can be seen from the third column, most of the apk files are less than 10MB, and the overall runtime is less than 0.14 seconds. The main contributor to the overall runtime of our system is in the feature extraction phase. Larger apk files require more processing time, which is almost of linear relation. In contrast, the classification phase takes very little time, and most of the sample classification time is less than 0.014 seconds. This is explained by the fact that no matter how large the file is, it is ultimately mapped to a fixed-length vector. Therefore, all samples are processed at similar times in the classification phase.
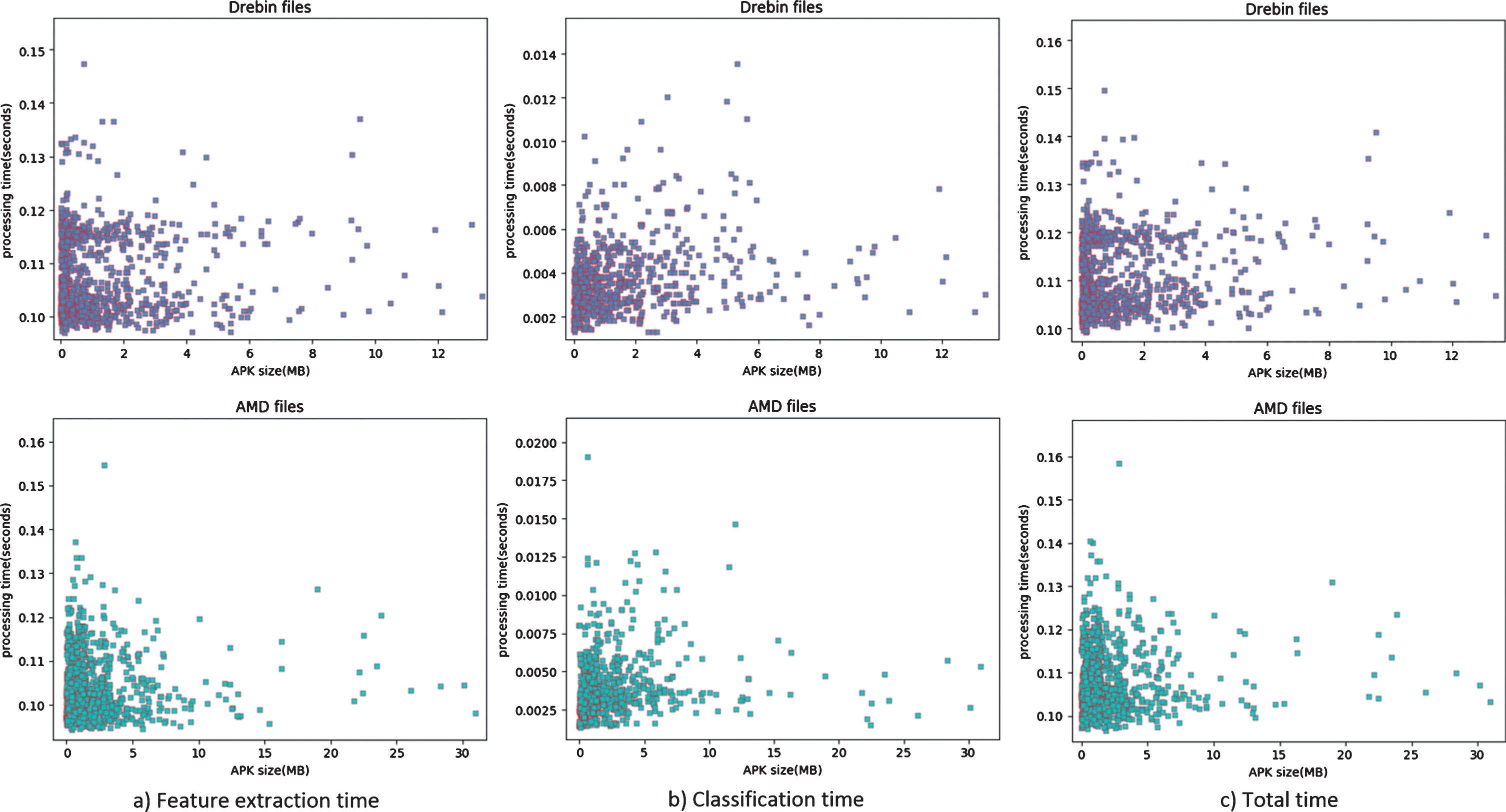
The overall runtime for processing one sample from two benchmark datasets.
On average, the BIHAD is able to analyze a given application in 0.1279 seconds and 0.1128 seconds for the Drebin dataset and AMD dataset, respectively. Compared to the state-of-the-art method FM [30] (4.7 ms and 0.021 ms for encoding and prediction, respectively), it seems that our system does not have any advantage in processing time. However, this is not the case. To begin with, our system processing one sample for prediction is almost negligible. Secondly, the feature sets used in our system are simpler and smaller than sets used in DREBIN [18] and FM [30], so under the same condition, our system should take less processing time than the two state-of-the-art techniques (DREBIN and FM).
In order to highlight the significance of this research result, a comparison is made with previous similar researches for the two benchmark datasets. Table 5 displays the results compared with [18, 31–33] and [30]. The proposed BIHAD gives a detection rate (recall) of 99.47% on the Drebin dataset that is superior to the state-of-the-art result given in FM [30], which is 99.01%. Moreover, it also gives a better detection rate on the AMD dataset. Experimental results show that the research method in this paper was comparable to other state-of-the-art approaches.
Results of our architecture compared to previous findings
Results of our architecture compared to previous findings
In order to confirm our algorithm is more suitable for large-scale malware detection, we evaluated the performance of BIHAD on AndroZoo dataset (including 110,000 samples). As shown in Table 6, when the number of samples increases, the model fits the data distribution better. However, when the number of samples is too little, the framework becomes under-fitting, which will cause it to fall into a local optimum, resulting in the value of the function being far from the desired target. We think this kind of fluctuation is reasonable. The robustness was evidenced by the small difference in performance metrics for the various sizes of datasets. Overall, the proposed BIHAD always maintains a high F-score (ranging from 98.66% to 99.46%), even in large-scale detection.
The effect of dataset size on experimental results
The effect of dataset size on experimental results
We evaluated the effectiveness of our model against obfuscated datasets. As shown in Table 7, our original dataset (OBF0, OBF25, OBF50 and OBF100) consists of samples from various sources (AndroZoo dataset and Praguard dataset). Table 7 also lists the percentage of applications that are obfuscated (obf%). The corresponding obfuscated malware was obtained from the Praguard dataset.
The obfuscated datasets used in the study
The obfuscated datasets used in the study
We obtained an F-score of 99% for the OBF0 dataset (the non-obfuscated set of samples) as shown in Table 8. Moreover, we repeated the experiment with the completely obfuscated set of samples (OBF100) and obtained similar F-score, showing its stability even in the presence of complicated obfuscation. We also evaluated the performance of our model against a mix of the obfuscated dataset (OBF25 and OBF50), as it would be encountered in the real world. In this case, our F-score was 98.68% (25% obfuscated samples) and 98.73% (50% obfuscated samples) respectively. These results show that the emergence of many obfuscation techniques makes it more difficult to classify benign and malicious samples. However, our proposed model still maintains a high detection rate (recall rate), although the overall performance is slightly reduced. We have observed that malware use more obfuscation than benign applications, which could make the sample more easily identifiable as malware.
Evaluation of classification on the obfuscated datasets
We selected 20 malware families in the Drebin dataset and 10 malware families in the AMD dataset. Furthermore, we evaluated the performance of BIHAD for malware family identification, which is an important task for malware attribution. For this task, the BIHAD is established to identify a certain malware family among samples from other families. We eventually analyzed 4,664 samples on the Drebin dataset and 2,085 samples on the AMD dataset. We grouped them into 20 different malware families and 10 different malware families, respectively. Table 9 and Table 10 illustrates the name, number, and detection performance of each family.
Detection performance of per malware family on the Drebin dataset
Detection performance of per malware family on the Drebin dataset
Detection performance of per malware family on the AMD dataset
Ideally, multi-family malware corpus stems from a uniform distribution, i.e. each malware family contributes the same number of samples. However, this leads to a distribution that significantly differs from reality, which is difficult to gauge whether such experiments provide statistically reliable results that can generalize. In order to confirm that the BIHAD-based detection scheme proposed in this paper is applicable to the identification of malware families. We evaluated the detection performance of each malware family separately. Experimental results demonstrated that the proposed BIHAD could reliably detect all families with an average F-score of 95% on the Drebin dataset and an average F-score of 98% on the AMD dataset respectively. Seven families on the Drebin dataset and seven families on the AMD dataset can be identified perfectly. Martín et al. [34] proposed a method that combines dynamic analysis and Markov chain for Android malware family attribution. Compared with [34], we reached the best results in the identification of most of the malware families on the Drebin dataset. It is also worth mentioning that, despite the different families identified, we achieved similar results to what was reported by [35] and [36]. It indicated that our approach is comparable to the state-of-the-art approaches.
For the knowledge representation of words, characters and texture features, a novel Android malware detection solution based on a neural joint model (BIHAD) is proposed. It used different types of feature to construct a stable decision method. Firstly, using image analysis techniques to convert behavior information of malware into texture features. The texture feature reflects the similarity between image blocks, which contain rich spatial and sequential patterns information. Secondly, on the basis of word-level embedding fully expressing the semantic information of the malicious code, the character-level embedding is used to provide information gain for the word-level feature. In order to make full use of behavior information of malware, we implemented the extraction of joint semantic and image information. Lastly, we used the neural joint model to extract the robust features that can improve the classification accuracy. Experimental results demonstrate that the proposed algorithm has certain advantages in performance and runtime.
This study describes a feature model based on static analysis. In future work, we will investigate the effectiveness of dynamic features generated by dynamic analysis. These dynamic features can be easily incorporated into the system so that the learning algorithm can take the advantages of both static and dynamic features. Another important consideration is the modularity of the system. We also plan to explore new network architectures such as replacing components in the network with newer and better-performing versions.
Footnotes
Acknowledgments
The authors would like to thank the Editor-in-Chief, the Associate Editor, and the reviewers for their insightful comments and suggestions. This work was supported by the Research Innovation Project of Graduate Student in Xinjiang Uygur Autonomous Region (XJ2019G065), the Cernet Next Generation Internet Technology Innovation Project (NGII20170420) and the Xinjiang Uygur Autonomous Region Cyber Security and Informatization Project (XJWX-1-Z-2019-1021).