
Abstract
Execution traces comprehension is an important topic in computer science since it allows software engineers to get a better understanding of the system behavior. However, traces are usually very large and hence they are difficult to interpret. Parallel, execution traces comprehension is a very important topic into the algorithms learning courses since it allows students to get a better understanding of the algorithm behavior. Therefore, there is a need to investigate ways to help students (and teachers) find and understand important information conveyed in a trace despite the trace being massive.
In this paper, we propose a new approximation for execution traces comprehension based on fuzzy linguistic descriptions. A new methodology and a data-driven architecture based on linguistic modelling of complex phenomenon are presented and explained. In particular, they are applied to automatically generate linguistic reports from execution traces generated during the execution of algorithm implemented by the students of an introductory course of artificial intelligence. To the best of our knowledge, it is the first time that linguistic modelling of complex phenomenon is applied to execution traces comprehension.
Throughout the article, it is shown how this kind of technology can be employed as a useful computer-assisted assessment tool that provides students and teachers with technical, immediate and personalised feedback about the algorithms that are being studied and implemented. At the same time, they provide us with two useful applications: they are an indispensable pedagogical resource for improving comprehension of execution traces, and they play an important role in the process of measuring and evaluating the “believability” of the agents implemented.
To show and explore the possibilities of this new technology, a web platform has been designed and implemented by one of the authors, and it has been incorporated into the process of assessment of an introductory artificial intelligence course. Finally, an empirical evaluation to confirm our hypothesis was performed and a survey directed to the students was carried out to measure the quality of the learning-teaching process by using this methodology enriched with fuzzy linguistic descriptions.
Keywords
Introduction
Computer games for motivating students
Keeping students motivated is an important goal for undergraduate students [1]. In particular, a challenge in teaching introductory artificial intelligence (AI) is to provide students with significant experiences and frequent feedback [2]. In this sense, computer games-based learning methodologies are being employed to provide students with motivating experiences.
Computer games have a long history of motivating learning computer science. In fact, integrating games into the computer science curriculum has been gaining acceptance in recent years, particularly when they are used to improve student engagement in introductory courses. It is important to note that computer games are not used for teaching in the classic way (serious games), but students design and implement their own computer games and artificial intelligence agents.
Feedback and motivation are also indispensable components of an effective teaching and learning environment in education [3–6]. Additionally, personalisation offers possibilities to deliver feedback that is the most appropriate for the user’s expertise, cognitive abilities and that addresses their current moods and attentiveness [7]. However, providing students with personalised, immediate and motivating feedback is a complex task, and it is usually a standardised process (every student receives the same feedback, e.g., knowledge of the correct response) due to the large number of students [7]. In writing skill, for example, truly immediate feedback is impractical [8].
Therefore, our idea is to provide students with two benefits: a learning methodology for artificial intelligence based on computer games and personalised feedback.
Challenges for incorporating games into an introductory AI subject
In 2011, a project-based learning methodology based on computer games was designed and implemented into the introductory artificial intelligence subject at the University of Bío-Bío.
The AI projects consist of developing a 2D computer game (see Fig. 1) based on the classic Pac Man computer game with some important differences. The player navigates through a maze containing four rewards and three opponents. The goal of the game is to have energy as long as possible by collecting the rewards and escaping from opponents. The three opponents roam the scene and chase the player. The player begins with 20 energy points. If the player comes into contact with an opponent, he loses 5 energy points. If the players earn a reward, he gets 10 extra energy points. The game ends when all the energy has been collected. The player loses 1 point of energy every five seconds.
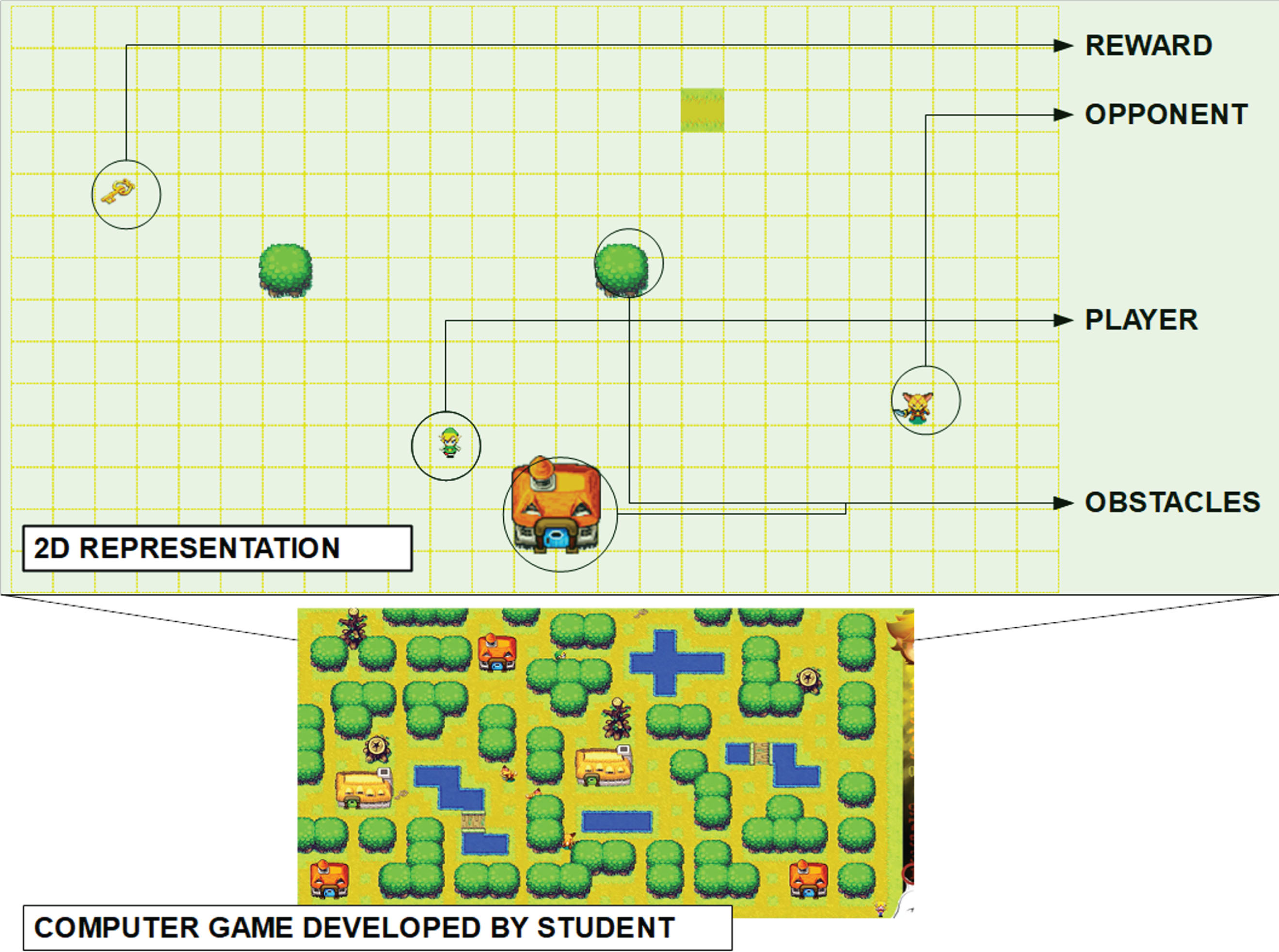
Example of a computer game developed by a student at the University of Bio-Bio. In the figure is shown a complete scenario (down) and a 2D scenario with the entities explained in Section 3 (top).
The player and opponents are computer game bots designed and implemented by the students using the heuristic algorithms studied during the course. The student must design and implement adequate heuristics metrics to design believable agents. An important project requirement is that the bots must be implemented by using heuristic algorithms, while opponent bots must be programmed by using the breadth-first search algorithm.
The traditional assessment of this kind of project has been performed by visually checking if the bots developed by the students have been correctly designed (revising the code developed for each student) and implemented (revising the codes functionality). This process has important flaws. It is a It is a
A possible solution is to analyse execution traces or employ code debugging so that the programs can be analysed, but as it has been mentioned and explained in several works [9], even this alternative could result in a very complex task due to the large amount of generated data. For example, for an actual play session, each line of a log file is formed by almost 21 values which are generated each second, so the total size for this file is approximately 800 lines (see Fig. 2 to understand the difficulty of interpreting this kind of file).
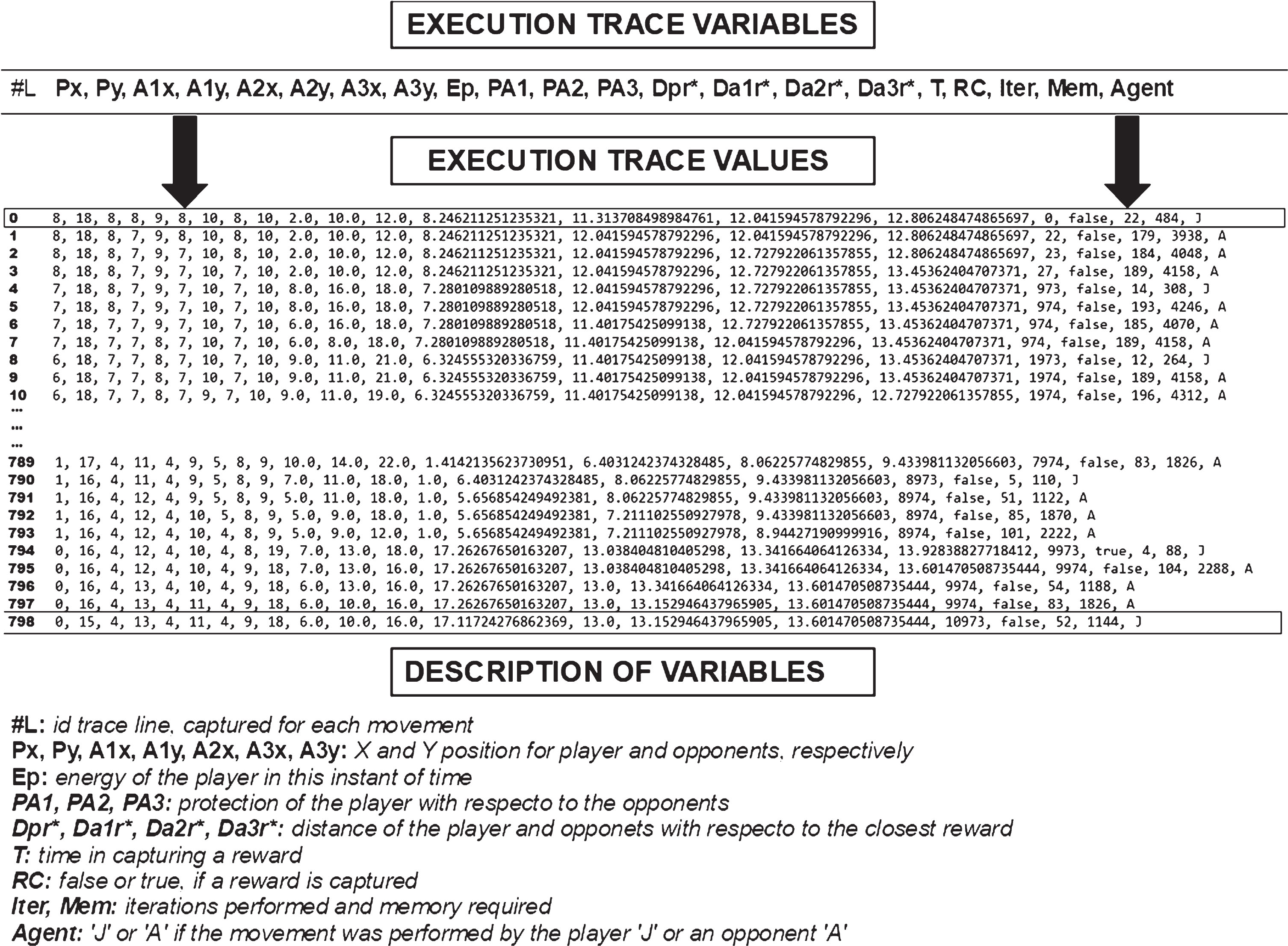
An example of an execution trace. For each line is shown the values for each variables. Description of the variables is also provided in the figure. Comprehending an execution trace can be a very difficult task.
In this scenario, fuzzy linguistic descriptions technology could play a key role in the computer game-based methodology since it would allow us to: Interpret large amounts of numerical data quickly and accurately. Provide students with immediate, personalised and accountable feedback Obtain a better understanding of the content. This implies a greater motivation for addressing the subject and a greater cohesion and effectiveness regarding the information that is conveyed to the students in the early stages of their learning. Obtain a better understanding of the execution traces. This implies having a useful complement for the classic debuggers, which sometimes require expert knowledge.
In the literature, some works have been proposed to provide learners and/or teachers with resources based on fuzzy linguistic descriptions from data generated in the teaching-learning process. In the non-fuzzy area, works can be grouped into five main categories: statistical, natural language processing (NLP), information extraction (IE), clustering and integrated-approaches [10]. Several examples of successful applications can be found in the literature: automatic creation of summary assessments for intelligent tutoring systems [11], automatic generation of formative feedback in the university classroom for specific concept maps scaffold students’ writing [12], a framework to provide students with feedback on algebra homework in middle-school classrooms [13], automatic test-based assessment of programming [14], automatic assessment of free text answers using a modified BLEU algorithm [10], and feedback for serious computer games to provide learners with useful and immediate information about the player’s performance [15].
In the fuzzy logic area [16], the following works should be mentioned: linguistic summaries of graph datasets using ontologies [17], automatic textual reporting in learning analytics dashboards [18], feedback reports for students based on several performance factors [19], and reports describing the learner’s rating in a specific learning activity [20]. In [21] linguistic descriptions were used for improving the player experience in a computer game called YADY (your actions define you). There are remarkable differences with respect to the present work. In [21], the feedback aimed to improve the player experience; the current work focuses on providing users (students) with written, immediate and interpretable feedback that aims to support the teaching-learning process.
In this paper, a methodology and a data-driven architecture software are proposed to automatically generate personalised and technical feedback from the data generated during the algorithm execution implemented by the students. A combination of three computational techniques is proposed: bot’s behaviour analysis, computational perception networks and natural language generation based on templates. The idea is that each student receives immediate, technical and personalised feedback about their mistakes made during the development of the project, and they learn about how heuristic algorithms can be employed for programming computer game bots. Additionally, another important challenge for us is to assess the ”believability” of the AI agents implemented by the students, hence a similarity measure between linguistic descriptions for evaluating and comparing the behaviour between agents and human expert players is also proposed (see Restrictive Equivalent Functions in Section 2).
Additionally, this approach is very beneficial to the teachers since it allows them to: Save time for evaluating other aspects of the projects, which implies a better understanding of the projects. Enhance the traditional process of assessment providing students with personalised and technical feedback. Support individual project-based learning to obtain a more closed tracing of the projects and the opportunity to focus on the weak skills of the students and strengthen those skills.
It is important to note that our approach aims to support the traditional process of project evaluation and not to replace it. Additionally, our approach can be seen as a useful tool for improving the decison-making process into the classroom. As is mentioned in [22] “decision-making performs a vital role in our daily life” and teachers/students are countinuosly confronted with challenging situations that demand decision making [23]. As a consequence fuzzy data-driven decision making approaches should be taken into account [24–26]
To show and explore the possibilities of this new technology, a web platform has been designed and implemented by one of the authors following the phases and steps established in the methodology detailed in Section 1. Finally, our framework is evaluated by using a survey directed to students and comparing the results of the application of the proposed approach with the human expert assessment.
The structure of the paper is as follows. Section 2 introduces several general concepts regarding project-based learning in artificial intelligence and provides a very brief review of the state-of-the-art of the different involved disciplines. Then, in Section 3, a methodology for incorporating linguistic descriptions of data into the AI projects is proposed. Section 4 details the software architecture for providing teachers and students with personalised and technical feedback. Afterwards, Section 6 explains the experimentation and evaluation carried out on the projects of the student by employing an adaptation of the Turing test. Finally, Section 7 provides future work and some concluding remarks.
Preliminary concepts
Automatic generation of reports in natural language and fuzzy linguistic descriptions technology
The automatic generation of reports in natural language is a sub-field of AI, which allows us to produce natural language (and/or graphs) as output on the basis of data input. There are two main methods (which are compatible with each other) for generating reports in natural language from datasets: natural language generation (NLG) and linguistic description discipline (LD).
The NLG field is focused on converting any kind of data into informative texts. NLG models and techniques have been applied for textual reporting in various domains, such as meteorological data [27, 28], care data [29], project management [30], and air quality [31]. An important and extensive survey of the state-of-the-art in this discipline can be found at [32]
The LD discipline [33] combines several sub-areas and as is mentioned in [34]: “it is a young field, to achieve a general approach capable of building different types of linguistic descriptions for any kind of application domain is still an open challenge, although some steps have been made in this direction”.
In this sense, we can mention here the linguistic description of the data (LLD) approach, which has been applied in several practical cases where data is the main input 1 . LDD is a research area with similar objectives as NLG. However, as it is mentioned in [35], ”in the fuzzy logic and soft computing field, this task is performed by employing fuzzy logic machinery (mainly linguistic variables [36], inference fuzzy rules and fuzzy quantifiers)”. More formally, following [35], LDD is defined as the task of extracting knowledge in natural language sentences and combining it with useful and explainable graphs from some input data by producing an abstraction composed of linguistic terms and inference fuzzy rules [35]. The LDD models and techniques have been applied for textual reporting in various domains such as air quality index textual forecasts [37], and weather forecasts [38].
Additionally, the linguistic description of complex phenomena (LDCP) [39] paradigm aims to extract and represent knowledge by using natural language sentences as if they were produced by a human expert, describing the most relevant aspects of a phenomenon for certain users in specific contexts. The LDCP technique has been used in domains such as deforestation analysis [40], big data [41], advice for saving energy at home [42], self-tracking physical activity [43], cosmology [44, 45], and driving simulation environments [46]. The construction of sentences in LDCP is a process influenced by the computational perception concept. The algorithms employed in LDCP approaches generate all possible sentences combinations to create candidate descriptions from data, which have been previously transformed in variable and linguistic terms. Then, linguistic terms are summarised, and template descriptions are defined to automatically generate linguistic descriptions which are put together with explainable graphs to provide users with more complete textual and visual information.
LDCP is based on the Computational Theory of Perceptions [47] and it grounds on the fact that human cognition is based on the role of perceptions, and their remarkable capability to granulate information in order to perform physical and mental tasks without any traditional measurements and computation. LDCP is based on the concept of Computational Perception (CP). A CP is a pair (A,W) described as follows:
A = (u1, …, u n ) is a vector of linguistic expressions (words or sentences in Natural Language) that represents the whole linguistic domain of CP.
W = (w1, …, w n ) is a vector of the validity degrees w i ∈ [0, 1] of each u i . w i represents the suitability of a i to describe the current perception of a specific aspect of the monitored phenomenon.
For example, suppose the following values:
u1= “The current situation is dangerous”, w1 = 0.8
u2= “The current situation is risky”, w2 = 0.2
u3= “The current situation is easy”, w3 = 0.0
u4= “The current situation is safe”, w4 = 0.0
We use Perception Mappings (PM) to aggregate CPs. We distinguish two kind of PMs, namely, First Order PMs (1PMs) and Second Order PMs (2PMs). We define a 1PM as a triple (Z,y,g); where Z is a special type of CP with a numerical value z, y is a 1CP, g is a function W = g (z), the function g (z) can be implemented by using membership functions w i = μ i (Z) associated with each component a i of A and therefore: W=(μ1 (Z) , μ2 (Z) , …, μ n (Z)) where n es the elements of elements in A. A 2PM is a tuple (U,y,g); where U is a vector of input CPs, y is the output CP and g is an aggregation function implemented by using a set of fuzzy rules (see several examples of PM later on).
Similarity measures and restricted equivalence functions
Measuring and evaluating the believability of the agents acting in a computer game is an important challenge in AI [48–50]. A method based on the similarity between fuzzy linguistic descriptions is proposed here. The main idea consists in establishing a similarity measure between linguistic reports by computing a similarity degree between its components.
An essential component of the fuzzy linguistic descriptions are the well-known linguistic vectors which employs linguistic terms for its implementation. At this level, similarity measures can be employed in order to measure the similarity between the corresponding components. We have selected the called restricted equivalence functions (REF) because we proved in [51] that they work very well in practice. Of course, others similarity measures could be used to compare fuzzy linguistic descriptions (for example [52]).
Finally, bots and human players can be compared from their automatically generated respective reports, which finally provides us with a measure of believability. It will be studied in detail in the Section 1.
A REF [53] is a function that establishes similarity between the elements of a domain. A REF can be formally defined as follows:
f (x, y) = f (y, x) for all x, y ∈ [0, 1] f (x, y) =1 if and only if x = y
f (x, y) =0 if and only if x = 1 and y = 0 or x = 0 and y = 1 f (x, y) = f (c (x) , c (y)) for all x, y ∈ [0, 1], c being a strong negation. For all x,y,z ∈[0, 1], if x ≤ y ≤ z, then f (x, y) ≥ f (x, z) and f (y, z) ≥ f (x, z)
For example, g (x, y) =1 - |x - y| satisfies conditions (1)-(5) with c (x) =1 - x for all x ∈ [0, 1].
Methodology for incorporating linguistic descriptions of data in AI projects
As mentioned in the introduction, the assessment of computer game-based learning projects is a very complex task. Here, a methodology for supporting this process by using fuzzy linguistic descriptions is proposed in detail.
This methodology is based on providing teachers with a complete tutorial reconstruction and a guide for designing and implementing a data-to-text system capable of automatically generating linguistic reports from execution traces obtained by capturing highlighted variables involved in the computer game. This system can be easily incorporated into the learning-teaching process which employs computer game-based learning for support. As a result, a computer-assisted assessment tool based on fuzzy linguistic descriptions technology is obtained. The proposed methodology is formed by three phases: bot behaviour analysis, linguistic descriptions of data and evaluation.
Phase 1. Bots behaviour analysis
In this phase, a set of actions performed by the agents is analysed to establish a set of behaviour patterns. The first step is the
The second step is the
The third step is the
The fourth step is the
For example, movements performed by the player could be conditioned by the movements performed by the opponents, e.g., if an opponent is close to the player, then the player will go far away from the opponent, so the player and opponent are related, and it provides us with an interesting behaviour pattern. Here, the action is “to move close to the opponent” and the effect would be “to move far away from the opponent”. Note that several actions and effects could be given at the same time in a particular instant of time, for example an action could be given by “to move close to the reward” and the effect could be “to move closer to the reward”. The idea of behavior pattern will be formalized by using computational perceptions.
Note finally that patterns are related to the metrics defined in the previous step and the metrics should be define from them. For example,
The result of this phase is a set of behaviour patterns derived from actions performed by entities in the virtual world. These behaviour patterns are designed and implemented by using a computational perception network (see Fig. 4).
Phase 2. Linguistic descriptions of data in a 2D virtual world for automatically generating behaviour profiles
The aim of this phase is to establish a cognitive computational model from previously identified behaviour patterns. Knowledge representation techniques can be employed here to generate linguistic descriptions using the following steps:
This phase provides us with a complete specification of the behaviour profile, which is a graphical and textual report describing the most relevant information about the behaviour of the computer game bots acting in the computer game.
Evaluation: A Turing test for computer game bots based on LLD and REFs
There is an important difference between the algorithms employed for programming bots and classic algorithms, for example, to get the optimal way to go from one place to another one. While classic algorithms aim to simulate near-optimal intelligent behaviour, the gaming bot algorithms aim to provide us with interesting and fun opponents for human players, not optimal opponents [55].
A variation of the Turing test was proposed and designed in [56] to test the abilities of the computer game bots to impersonate human players. The idea is as follows: “Suppose we are playing an interactive video game with some entity. Could you tell, solely from the conduct of the game, whether the other entity was a human player or a bot? If not, then the bot is deemed to have passed the test”.
This kind of Turing test is redefined and adapted for our methodology by using LDCP and REFs. Our idea is to establish a formal and effective method of measuring the believability of the agents acting in the computer game. A comparison between the automatically generated profiles (bots and players) is performed by establishing a similarity measure between them.
For us, a heuristic algorithm is near-behavioural (for us it is an “optimal” algorithm) when bots profiles are similar to human profiles (defined by the teacher as an evaluation pattern, i.e., requirements that must met by the bots). This novel process of assessment for heuristic algorithms in computer games will be detailed in the Section 5.
A data-driven software architecture based on linguistic modelling of complex phenomena
A data-driven software architecture based on LDCP is proposed here (see Fig. 3). This architecture aims to implement the phases and steps described in the previously detailed methodology. It is formed by four modules: tracing, computational perception network, behaviour profile report generation and evaluation. They are explained in detail in the following.
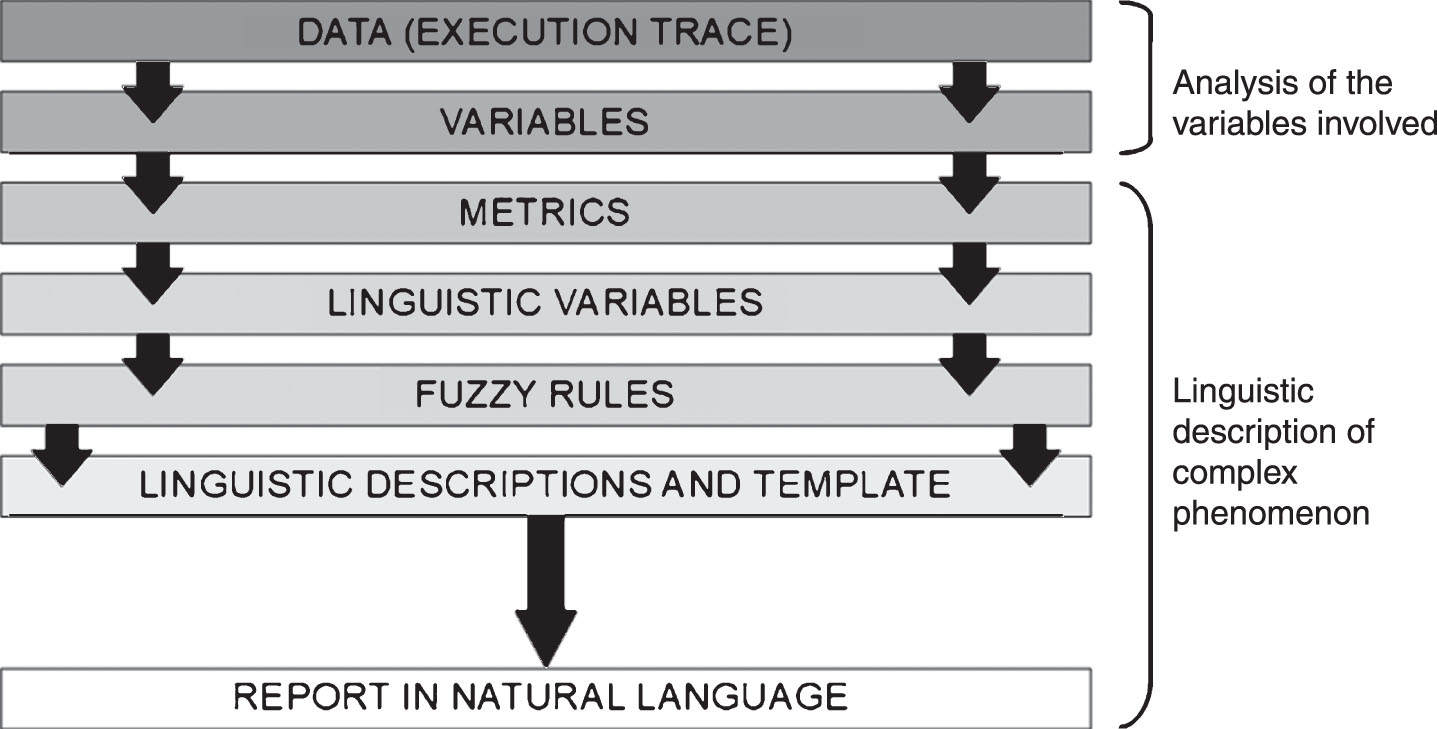
A data-driven software architecture for trace comprehension based on LDCP.
The tracing module aims to implement the functionality explained in phase 1, and it is incorporated into an event handler layer of the computer game architecture. This starts when a movement is performed by the player or the opponents, then an event is launched, and a function is called, which creates a new execution trace row. Each row is formed by the values of the metrics described in Section 1, namely: player position; opponent position (for each opponent); player energy; protection with respect to the opponent (for each opponent); distance between the player and the closest reward; distance between the opponent and the closest reward (for each opponent), time elapsed, if the reward was captured in this movement (true or false), number of iterations, memory used and which entity performed the movement (character ’J’ for the player, character ’A’ for the opponent).
At the end of each play session, these values are written in the output trace file. Note that, the output of this module is a file containing the needed data captured during the execution of the algorithms implemented in the project (see Fig. 2).
Computational perception network module
A computational perception network is used to implement the functionality explained in phase 2. An extension of the computational perception network presented in [21] is performed. In this case, additional variables must be considered, and the computational perceptions network must be enhanced. Additionally, rules and templates must also be updated for these new requirements.
Please note that the design of computational perceptions depends on the designer criterion. Here, after intensive experimentation we decided to make the linguistic model simple and functional but to keep it easy tounderstand. A computational network is formed by two kind: first-order computational perceptions (called 1CP) are the metrics perceived by the agents (distance,protection, energy, time, iterations, memory) and second-order computational perceptions (called 2CP) are the mental objects built by using metrics in the world [39].
First-order computational perceptions
The process of construction of a computational perception network starts with the selection of the metrics and the creation of a set of linguistic variables from them. An important requirement here is that the problem domain must be known by the designer. We use 1CP to process the input data. Here the inputs are numerical data obtained from varaibles and metrics defined in previous sections. Computational perception network: CP means Instant CP; ∑CP means play session CP.

A = (close, normal, far)
g: this function is built using three linguistic labels that are represented with trapezoidal membership functions close (0, 0, 4, 7) , normal (6, 9, 11, 14), far (13, 16, N, N)
Z = [0, N], being N the total number of walls in the game world.
A = (low, intermediate, high)
g: this function is built using three linguistic labels that are represented with trapezoidal membership functions (0, 0, 0, 2), (1, 3, 3, 5) and (4, 6, 380, 380)
Z = [0, N], being N the total of energy of the player (100 in our case)
A = (low, intermediate, high)
g: this function is built using three linguistic labels that are represented with trapezoidal membership functions (0, 0, 3, 6), (4, 7, 9, 12) and (10, 13, 100, 100)
Z = [0, N], being N the total number of iterations of the agent
A = (little, normal, large)
g: this function is built using three linguistic labels that are represented with trapezoidal membership functions (0, 0, 18, 30), (18, 30, 42, 54) and (42, 54, 104857600, 104857600)
Z = [0, N], being N the total of memory for the agent (104857600 in our case)
A = (low, normal, high)
g: this function is built using three linguistic labels that are represented with trapezoidal membership functions (0, 0, 768, 1280), (768, 1280, 1792, 2304) and (42, 54, 104857600, 104857600)
Z = [0, N], being N a maximum fixed in seconds for capturing a reward.
A = (short, large)
g: this function is built using two linguistic labels that are represented with triangular membership functions short (0, 0, 7) , large (5, N, N)
Finally, a set of if-then rules is defined by aggregating these linguistic terms, which have an associated fuzzy set (see Example 1).
Behaviour profile report generation module
A special kind of CP is employed here which is called CP play session, and it is denoted by ΣCP. Each ΣCP can be formally defined by using a vector of linguistic expressions ((a1, w1) , …, (a n , w n )). Each ΣCPs represents the whole linguistic domain. These kinds of CPs allow us to obtain the total number of times in which a value (a1, …, a n ) occurred during the execution.
These kinds of CPs provide us with a set of variables, their associated value and a degree α, which indicates the average for a particular value. For example, a value for CP situation could be “Safe” with 0.8 at an instant i and “Safe” with 0.7 at instant i + 1, and so on. Therefore, at the end of the execution, we have that a i (in the example “Safe”) has been given N times with N different degrees β1, …, β n (of course, some of these degrees could be equal). Thus, the final degree is calculated as follows: α i = ((β1 + … + β n )/N). For example, the following summaries can be obtained from different ΣCP (see Fig. 4).
The generation of the report is performed by using a set of ΣCP. For each CP a linguistic description is created in the function of the pair (a
i
, w
i
) ∈ ΣCP. Percentages are calculated for each ΣCP. The percentage p
i
is then transformed into a linguistic term of quantity as follows: few is when p
i
∈ [0, 1/3]; several is when p
i
∈ [1/3, 2/3] or many is when p
i
∈ [2/3, 1]. Next, we consider the following four cases: There exists a pair (a
i
, p
i
) ∈ ΣCP whose p
i
is greater than 66 percent. There exists a pair (a
i
, p
i
) ∈ ΣCP whose p
i
is greater than 33 percent. There are two pairs (a1, p1) , (a2, p2) ∈ ΣCP whose p
i
is greater than 33 percent. There exists no pair (a
i
, p
i
) ∈ ΣCP whose p
i
is greater than 33 percent.
The system selects, the most suitable linguistic expressions from among the available possibilities to describe the input data. Linguistic descriptions for each CP are stored in a list 1, 2, 3, 4 as follows:
Several cases may happen simultaneously, in this case (④, ③, ②,①), it would be the priority.
A complete example of the generation of behaviour profiles from an execution trace file is detailed in Example 1.
Attitude=(Cautious,0.54) ← Dist(O*,R*)=(High,0.29), Dist(P,R*)=(Normal, 0.33), Energy=(High,1) Situation=(Dangerous,0.83) ← Protection=(Low,0.5),Distance(P,O*)=(Close,1),Energy = (High,1) Movement=(Bad,0.77) ← Distance(P,R*)=(Normal,0.33),Distance(P,O*)=(Close,1), Energy=(High,1) Ability=(Dummy,0.76) ← Attitude=(Cautious,0.54), Situation=(Dangerous,0.83), Movement=(Bad,0.91) Skill=(Improvable,0.81) ← Attitude= (Cautious,0.54), Movement=(Bad,0.91), Time=(Small,1) Resources=(Efficient,0.84) ← Memory=(Low,0.69), Iteration=(Normal,1)
Subsequently, the ΣCP are computed as it was explained in Section 1: ΣCP
Attitude
= {(wise,17.53), (brave,101.55), (cautious,14.05), (passive,10.78) } ΣCP
Situation
{(risky,24.44), (dangerous,651.39), (safe,32.26), (easy,0) } ΣCP
Movement
{(good,24.21), (scared,0), (kamikaze,94.82), (bad,48.01) } ΣCP
Ability
{(skillful,7.56), (little skilled,0.72), (improvable,122.2), (very improvable,31) } ΣCP
Skill
{(expert,38.48), (intermediate,0), (basic,31.93), (dummy,94.88) } ΣCP
Resources
{(very efficient,41.42), (efficient,121.86), (inefficient,0), (very inefficient,15.33) }
Finally, the instantiation, for each template shown in the Section 4.3, is performed by using the generated ΣCP. An example of instantiation is shown in the Fig. 5.

Instantiation template for the execution trace of the Example 1 and the similarity between behaviour profile reports: human player versus bots.
A web application has been developed for providing students with a computer-assisted assessment tool. Computer-assisted assessment is a longstanding problem that has attracted interest from the research community since the sixties and has not yet been fully resolved [11]. The main aim is to study how the computer can help in the evaluation of students’ learning processes [57]. The literature has presented several advantages: It provides educators with didactic advantages [6]; that is, it is very useful for conveying instruction and information as well as pleasure and entertainment. It provides students with immediate information in a timely manner, and it is particularly useful when the number of students is high, and resources are scarce [7]. It is a quick way of providing feedback, and it reduces the teacher’s workload [8]. It can be personalised, which allows the process of assessment to be enhanced from both teacher’s and students’ points of view.
The web application has been incorporated into the process of assessment of an introductory AI course. Additionally, this portal has been incorporated into the teaching-learning process, which allows each student to consult the feedback any time he/she desires and compare different kinds of algorithms for programming computer game bots; the student can also establish his/her own plan for learning.
This section aims to explain in detail the use of the web platform for automatically generating human player and bot behaviour profiles from execution traces. A quick test of the application can be performed by downloading examples of traces at the following URL: http://youractionsdefineyou.com/assess/web/examples_traces
First, the user must access the URL: http://www.youractionsdefineyou.com/assess
The main window shows two options: log in and register. Registering a user consists of entering the email address, user name, full name, RUT (national identification in Chile) and a password. A confirmation via email is sent to the user if the registration was correct. The user log in consists of entering the user name and the password. Second, a behaviour profile report can be obtained by selecting and loading an execution trace file, and then, the behaviour profile report is automatically generated. Additionally, the report can be exported to PDF.
As we mentioned, one of the most important objectives in AI is to create an agent that simulates human abilities. Here, the bots behaviour profile is compared with the human expert player profile (see Fig. 7) by using a similarity measure based on REFs. The generation of a human player profile is performed in two steps: i) human player plays several play sessions; ii) teacher/evaluator defines a profile report from them. Note that, an “expert human player” profile candidate is selected and associated with a requirement of the project. Of course, others human expert profiles could be considered, it will depend on the objetives and features of the project. Attitude is mainly brave most of the time. Situation is mainly safe most of the time. Movements were mainly good most of the time. The player is an expert. The player is skilled. The use of computational resources is efficient in time and space
The final grade (from 1 to 7) is computed by using the similarity between the human behaviour profile and the bot profile. The equation for calculating the final grade is as follows:
G
Min
: 1 point (all the students have 1 point as a minimum score - it is mandatory at the University of Bío-Bío)
where S
REF
is a similarity measure between computational perceptions. The following definition formalises this measure.
Then, the linguistic vector percentages are calculated for each ΣCP by using their totals
Now, the similarity REF (0.240, 0.122) =1 - |0.240 - 0.122|=0.882 REF (0.569, 0.172) =1 - |0.569 - 0.172|=0.882 REF (0.172, 0.097) =1 - |0.172 - 0.097|=0.925 REF (0.017, 0.075) =1 - |0.017 - 0.075|=0.942
Hence,
The aim of this section is to show how fuzzy linguistic descriptions can be used to get more information about the algorithms implemented by the students. The classic human expert assessment for the computer game-based project at the University of Bío-Bío is based on the following guidelines. There are minimal requirements to pass the subject: 2D scenario, 4 rewards, 3 opponents, 1 player, opponents implemented with breadth-first algorithms all functionality; crash with stop (+1); crash without stop (-1); images (+3); life (+3); lose life (+3); Show life (+3); Stop play session correctly (+3); a star algorithm implementation (+3); additional tasks about the project performed in class (+2 per task); additional tasks about the project not performed in class (-2 per task); exceptional IA (+8)
In order to perform an empirical comparation, we are going to use the scores obtained in a classical assessment evaluation by the teacher and those automatically generated by the software tool (see Fig. 6). A comparative table was created in order to show both resulting scores. The empirical study is simple, illustrative. We must take into account the time employed in a classical assessment of the algorithm functionality. Supposing that teacher assesses each algorithm in five minutes, the teacher would need 50 minutes for evaluating 10 projects. Supposing that IA assesses user each algorithm in one second, the teacher would need 50 seconds for evaluating 10 projects.
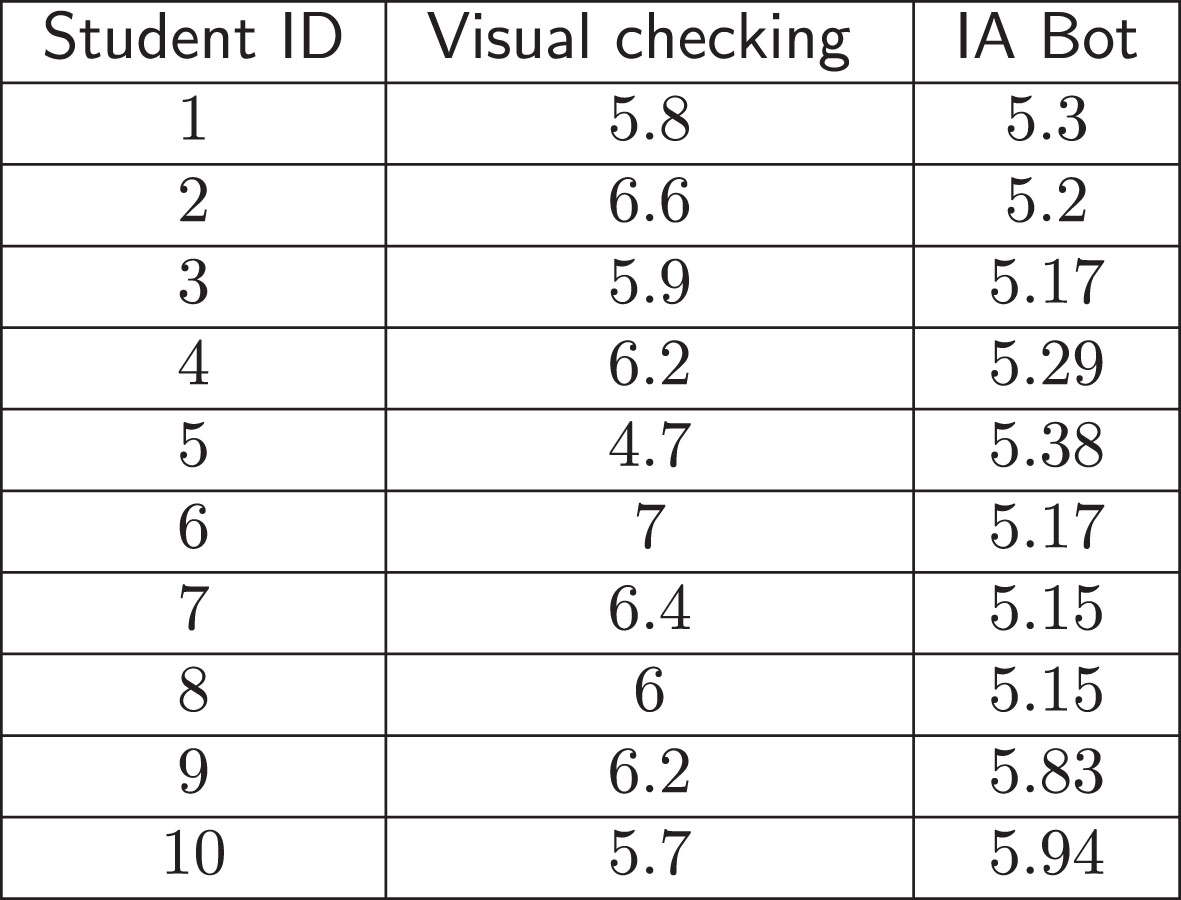
Scores obtained by students in the project and the scores obtained automatically.
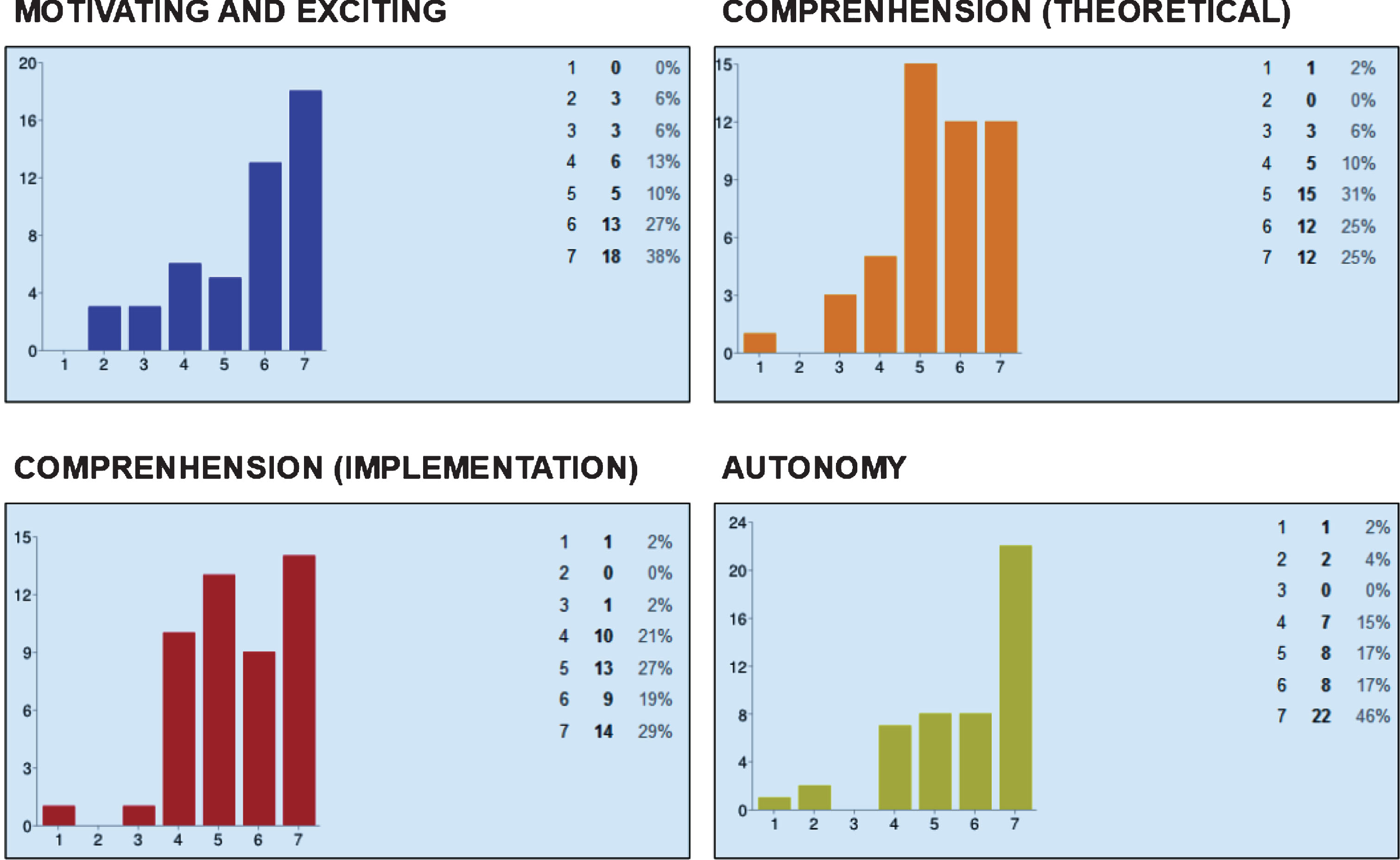
Bar Graphs obtained from the answers for the survey directed to the students.
The above examples support our initial hyphotesis. It is hard for a teacher to assess all the features involved in an implementation. However, although the teacher could do it, this is a task which needs too much time to be completed. The use of linguistic descriptions allows us to automatise this step, making the task easier for the expert and reducing time. The teacher could spend more time reviewing other features of the project that he might not be able to do because of lack of time.
Additionally, there are considerable differences between both scores. While in the first one, the difference between the respective scores is large, the scores obtained by using our methodology are more equidistant. In a second and unofficial round of revision, the teacher could check that the scores obtained are more adjusted to reality. However, a more deep analysis should be performed in the future work, for example by implementing intelligent artificial tutors based on fuzzy linguistic descriptions. It will be a great challenge for us which starts with the present work.
To measure the impact of teaching innovation, a survey directed to the students of the artificial intelligence class was carried out. Very interesting opinions from the students have been observed. A number of opinions were positive, which appears to indicate that a project-based methodology is very useful in allowing the students to achieve the competencies pertaining to the profile of a graduate. Other opinions were negative but constructive, which indicates that certain aspects of the class, namely, those related to the organisation and presentation of materials and assessments, should be improved. Others were negative but constructive with regards to the context of the class and pre-existing gaps in knowledge. Finally, a smaller number of negative, non-constructive opinions were registered, which criticised the teaching abilities of the instructor and the class contents. Measures have been taken in light of these findings, and a final methodology has been designed as a result. The results show that 38% of students very strongly agreed, 27% strongly agreed, and 10% agreed with the statement that “The development of the artificial intelligence project was motivating and exciting” whereas 13% slightly agreed, and 12% disagreed.
Positive results were also obtained regarding the statement. The project-based method greatly helped in understanding the theoretical concepts of the classž with 81% of students agreeing, strongly agreeing or very strongly agreeing, while 10% remained neutral, and 9% disagreed. Additionally, 75% of the students agreed, strongly agreed or very strongly agreed; 21% remained neutral, and 4% disagreed with the statement. The project-based method greatly helped in understanding how to implement the research techniques reviewed in class. For the next question, 79% of students agreed, strongly agreed or very strongly agreed; 15% remained neutral, and 6% disagreed with the statement “Carrying out this project autonomously helped me improve my professional skills and further prepared me for future employment”. The results of this survey indicate that the methodology made it possible for the project-workshop to be motivating and exciting. However, it failed to establish a connection between theoretical and practical content. It has been observed that autonomous work allows students to acquire working and programming skills. The majority of the students see this as a challenge. In general, the students stated that this type of methodology helped them achieve the desired abilities to learn a better understanding of the studied algorithms.
Conclusions and future work
In this paper, a new approach for execution traces comprehension based on the fuzzy linguistic description paradigm has been presented. For this purpose, a methology and a data-driven architecure have been established and explained in detail. A computational perception network and a behaviour profile report generation module have been defined and implemented on a web platform. This tool allows us to automatically generate interpretable and explainable reports in natural language about the execution traces of the algorithms designed and implemented by the students in their projects. An important and remarkable feature of our proposal is that it is capable of interpreting large amounts of numerical data quickly and accurately, providing students -and teachers- with immediate, personalised and accountable feedback, obtaining a better understanding of the execution traces.
The preliminary results show that our method can be used as a pedagogical resource providing teachers with a useful tool for identifying information about the quality of the heuristic algorithm designed by the students, which improves the teaching and learning process. The project created by the students can be evaluated at any time from two points of view: quantity (performance of the algorithm -space and time-), and quality (kind of situations, movements, attitudes, abilities, skills). A survey directed to the students of the artificial intelligence class has been carried out in order to measure the impact of teaching innovation.
As future work we would like to address several challenges: i) employment of our technology for improving the transparency, interpretability, and comprehension of algorithms; ii) design and implementation of intelligent tutors based on fuzzy linguistic descriptions; iii) incorporation of our technology in others educational disciplines to obtain personalised feedback; iv) quality assessment of automatically generated datasets.
Footnotes
Acknowledgments
This work has been performed in collaboration with the research group SOMOS (SOftware-MOdelling-Science) funded by the University of Bío-Bío. This document is especially dedicated to our partner and friend, Prof. Pedro Rodríguez (RIP).
Some authors refer to the linguistic descriptions as LDD, understanding linguistic descriptions as a tool to describe human perceptions.
The notation (x,y) is indicated the coordinate (x,y) into the 2D scenario.