
Abstract
Investigating clusters of experts is an interesting topic in the large-group decision-making (LGDM) problem, since being familiar with patterns (groups) of experts is beneficial to some other actions needed for decision-making (e.g., reconciliation of opinions derived from different expert groups). However, not too much attention has been paid to expert clustering in the LGDM problem under a linguistic environment. Besides, it seems that only the decision information is utilized to group experts while the auxiliary (outside) knowledge (e.g., expertise and occupation) about these experts has not been fully considered during the clustering process. To address this issue, this study proposes a hybrid method integrating outside knowledge about experts with practical preference information under the interval-valued linguistic environment to cluster experts. The method consists of four elements: pre-clustering of experts according to the given knowledge, the optimization model to transform the interval-valued 2-tuple linguistic (IV2TL) decision information, the data envelopment analysis-discriminant analysis (DEA-DA) model to deal with a two-cluster issue, and iterative clustering based on the DEA-DA model to cluster experts into multiple clusters. The feasibility and validity of the proposed method are illustrated with a real-world example. A comparison with the maximal tree clustering method in the linguistic environment is provided.
Keywords
List of notations
A linguistic term set A 2-tuple A linguistic term The value of symbolic translation The aggregation result of a set of linguistic terms An interval-valued 2-tuple The aggregation result of a set of linguistic intervals The expert set The alternative set The attribute set The IV2TL decision matrix The real-number decision matrix The separated group (or cluster) to contain experts The variable used to transform the IV2TL decision information into numerical values The importance degree of each
objective The discriminant score
Introduction
Group decision-making (GDM) problems have been the focus of academic research, which aims to achieve a solution for a specific decision problem among some experts (decision makers) [1]. Generally, the GDM process only involves a relatively small scale of experts (e.g., 3–5 persons) and the complexity of this problem is low [2]. However, nowadays the group scale enlarges with the increasing complexity of decision-making problems and development of information technology, especially for some problems concerning public interests [3]. Meanwhile, decision environment, groups, and attributes have experienced profound changes in modern GDM problems, due to rapid development of society and economy [4]. As a result, conventional GDM models cannot effectively tackle these complex problems in which multiple relations and interests should be simultaneously balanced. Chen and Liu [5] referred to such problems as the large GDM (LGDM) problems and characterized them by four features: (a) experts of the group are allowed to make decisions at different times in different places benefited from the internet; (b) the group size generally exceeds 20, and both competition and cooperation occur among experts owing to their various background; (c) connections may exist among different decision attributes; (d) preference information of experts is uncertain. As such, the first step is to find a suitable type of data to represent uncertain information given by experts. Currently, several modes have been adopted in GDM problems to assign values to decision attributes, such as fuzzy numbers [6], intuitionistic fuzzy numbers [7], interval-valued intuitionistic fuzzy numbers [8], and linguistic variables [9]. Since experts tend to express their opinions with qualitative information in the real world, it is more appropriate to utilize linguistic variables instead of numerical values to model the features of human decision-making. Furthermore, linguistic computing dealing with uncertainty has been widely applied to different types of decision-making problems in practice due to its good performance [10–12]. To effectively avoid loss and distortion of information in the course of linguistic information processing, Herrera and Martínez [13] developed the 2-tuple linguistic (2TL) representation model that consists of a linguistic term and a real number. In recent years, the 2TL representation model has been extensively utilized in the GDM problems [14]. However, in most cases, it is difficult for experts to express their preferences on decision attributes by means of a linguistic term, due to the complexity of human thinking process and that of decision-making problems under uncertainty [11]. Instead, the descriptions of decision attributes may fall between two linguistic terms (or a linguistic interval), in order to express their knowledge more accurately. For instance, the person may think that the price of a smartphone is between “Medium” and “High”. To solve this issue, Lin et al. [15] proposed the interval-valued 2-tuple linguistic (IV2TL) representation model to denote the interval-valued linguistic information, which satisfies the precondition that all experts share the same linguistic term set. Based on this, the present study will consider the LGDM problem under an interval-valued linguistic environment.
The procedure for the LGDM problem is generally composed of several major stages: expert clustering, weight determination for experts, weight determination for attributes, consensus reaching of experts, and comprehensive ranking [5]. Currently, research efforts have been conducted concerning the above stages, which lay a foundation for solving the LGDM problem [16, 17]. For instance, Liu et al. [11] developed a two-layer weight determination model to obtain expert weights in a cluster and the cluster weights, under the precondition that all expert clusters are known in advance. Liu et al. [4] adopted an objective method for assigning weights to the primary attributes based on decision information of all experts, where information transformation was achieved by means of a membership-based method directing at different expert groups (i.e., optimistic, neutral, and pessimistic). Due to the features of the LGDM problem, it also introduces some difficulties for experts to form a consensus in the decision-making process [18]. Suppose the preferences of all experts are various and mutually independent, then their thinking modes can be divided into three types: (a) experts in similar thinking patterns (a consensus exists); (b) the views of experts may change, but they all belong to a similar group; and (c) experts aggregate within groups (or similar sub-groups) [19]. The third thinking mode is the most common, which also reflects the focus of future study. Until now, many approaches have been put forward to help reach a consensus after decision information is collected from experts in the GDM and LGDM problems under various fuzzy environment [10, 21]. In the process, clustering experts can result in decision information in each cluster with higher consistency and a lower degree of conflict, consequently simplifying the consensus reaching process and significantly improving its efficiency in such problems [20, 23]. After acknowledging previous research, it can be seen that expert clustering acts as a critical role in the problem-solving process of LGDM, since it can avoid the redundant expert information, and reduce the complexity of group aggregation as well as workload of subsequent activities (e.g., weight determination for experts or attributes). Therefore, we devote ourselves to proposing a novel method for clustering experts in the LGDM problem.
Currently, the issues of expert clustering have been addressed by many methods under a fuzzy environment, but only a few direct at the LGDM problem under a (traditional) linguistic environment [22–25]. Wang et al. [26] measured the similarity between any two clusters and separated experts into clusters using an improved hierarchical clustering approach. Xu et al. [27] developed a risk measurement model for quantifying emergency events based on attributes assessed by linguistic information, and then utilized a group member clustering algorithm to generate several aggregates with equal levels of decision risk. Xiao et al. [28] collected the preference degree between alternatives from experts using the linguistic distribution assessment and adopted the preference clustering approach to decompose them into clusters. In the course of expert clustering, information processing (from linguistic information to numeric one) is an indispensable step in previous studies, but the existing methods are mainly used to deal with the general linguistic information, such as 2 tuples, which cannot be applied to clustering experts in the LGDM problems under an interval-valued linguistic environment. Even though linguistic information is transformed, the typical approaches to clustering analysis (e.g., the minimal spanning tree [29], the vector space clustering method [19], and the k-means range algorithm [30]) need to set the initial ranking of clustering elements and the whole process is irreversible. As such, these methods are not justified to deal with clustering issues in the LGDM problems. Moreover, it is difficult to provide an exact number or a range for the appropriate threshold, which significantly influences the number of clusters [26].
To address these shortcomings, the objectives of this study include two parts: (a) to reasonably transform the interval-valued linguistic information given by experts, which lays a foundation for the later process of expert clustering; (b) to solve the clustering issue without depending on an initial setting of the threshold which is normally difficult to be determined. For the latter, the idea of combining outside knowledge about experts with practical preference information is proposed to solve the clustering issue in the LGDM problems, when clustering standards are deficient. If we can firstly divide experts into several groups according to the outside knowledge, it will guarantee a sound consistency in each group and reflect the distinct features among various groups. However, even if in the same group, there also exist some members with different decision attitudes. Thus, we need to allocate the individuals with different attitudes in each group into a more suitable group. To achieve the two objectives, this paper combines the optimization model, the data envelopment analysis-discriminant analysis (DEA-DA) model, and iterative clustering to develop a hybrid method for clustering experts in the LGDM problem under an interval-valued linguistic environment. Not only does this method lay the foundation for weight determination for experts (attributes) and decision information aggregation, but it also extends the application of the DEA-DA model from the real number field to a linguistic environment.
The remainder of this paper is organized as follows: we first introduce some concepts, theorems and definitions regarding to the 2TL and IV2TL representation models in Section 2. In Section 3, a framework of the hybrid method for clustering experts is established to solve the LGDM problem under an interval-valued linguistic environment and its primary components are then introduced in detail. In Section 4, a practical example is illustrated to present the feasibility of the hybrid method, and then the proposed method is compared with the maximal tree clustering method under the 2TL environment. We conclude the paper and give some future extensions in Section 5.
Preliminaries
In this section, we first introduce basic concepts of the 2TL representation model as well as some definitions and theorems regarding 2-tuple(s). Then, the IV2TL representation model will be reviewed at the end of this section.
The 2TL representation model
Let S = {s i |i = 0, 1, 2, . . . , t} be a linguistic term set with odd cardinality. Any label s i represents a possible value for a linguistic variable, and it should satisfy the following characteristics: (a) the set is ordered: s i > s j , if i > j; (b) max operator: max(s i , s j ) = s i , if s i ≥ s j ; (c) min operator: min(s i , s j ) = s i , if s i ≤ s j ; (d) there is a negation operator: Neg (s i ) = s j , where j = t–i [13]. For example, S can be defined as S={s0= extremely poor, s1= very poor, s2= poor, s3= medium, s4= good, s5= very good, s6= extremely good}.
A 2TL representation model based on the concept of symbolic translation is used to represent the linguistic evaluation information by means of a 2-tuple (s i , α i ). Where, s i is a linguistic term in predefined linguistic term set S; α i is the value of symbolic translation and α i ∈ [-0.5, 0.5).
It is obvious that the transformation of a linguistic term into a 2TL representation consists of adding a value zero as a symbolic translation, i.e., Δ-1 (s i , 0) = i.
According to Definition 5, the properties of the 2-tuple deviation measure can be inferred as follows:
d ((s
i
, α
i
) , (s
j
, α
j
)) ∈ R. In particular, d ((s
i
, α
i
) , (s
j
, α
j
)) =0 if Δ-1 (s
i
, α
i
) = Δ-1 (s
j
, α
j
); d ((s
i
, α
i
) , (s
j
, α
j
)) = - d ((s
j
, α
j
) , (s
i
, α
i
)); d ((s
i
, α
i
) , (s
k
, α
k
)) = d ((s
i
, α
i
) , (s
j
, α
j
)) + d ((s
j
, α
j
) , (s
k
, α
k
)).
Based on the 2-tuple deviation measure, the 2-tuple covariance and the 2-tuple standard deviation are introduced respectively, which will lay the foundation for the optimization model under the interval-valued linguistic environment in Section 3.
Specifically, when j = k, the 2-tuple variances can be obtained as Definition 7.
Since the opinions of experts are largely restricted by some factors (e.g., their knowledge, environment, and working experience), the attribute descriptions provided by experts may fall between the two linguistic terms (linguistic intervals). To solve this problem, we introduce the concept of the IV2TL representation model [11, 15]. To ensure the aggregation results of these linguistic intervals could be explained without a loss of information, we assume that all the experts share the same linguistic term set.
Similarly, a linguistic interval [s i , s j ] can be transformed into an IV2TL representation [(s i , 0) , (s j , 0)]. Besides, the 2-tuple could also be considered as a special interval-valued 2-tuple in the form of (s i , α i ) = [(s i , α i ) , (s i , α i )].

Example of an IV2TL representation model.
This section mainly includes four parts: we first give the mathematical representation of the LGDM problem in an interval-valued linguistic environment. Based on GDM information, a framework of the hybrid method for clustering experts is proposed under the environment and its components including the optimization model and the DEA-DA model are then introduced in detail.
The LGDM problem under the interval-valued linguistic environment
In the LGDM problem, experts are invited to give their evaluations to the attributes of some alternatives. According to four features of the LGDM problem described in the introduction, suppose that E = {e1, e2, . . . , e
N
} (N ≥ 20) is the expert set, X = {x1, x2, . . . , x
m
} (m ≥ 2) is the alternative set, and U = {u1, u2, . . . , u
n
} (n ≥ 2) is the attribute set, then each expert e
k
∈ E should give the opinion to each attribute u
j
∈ U belonging to each alternative x
i
∈ X. Let
Thus, expert clustering in the LGDM problem under the interval-valued linguistic environment could be defined as the process of obtaining expert clusters based on the given decision matrix.
Framework of the hybrid method for clustering experts
Considering there is lack of mature standards to provide an exact number or a range for the proper threshold in the clustering issue, outside knowledge about experts (e.g., career, occupation, and age) can be regarded as the basis for pre-classification, and the attribute selection mainly depends on the actual decision-making issue. However, even if in the same group, there also exist some members with different decision attitudes. Based on this, the paper proposes a hybrid method for clustering experts in the LGDM problem combining outside knowledge and practical preference information. In other words, we firstly divide experts into several groups based on outside knowledge, and then allocate the individuals with different attitudes in each group into a more suitable group by means of the proposed method. Compared with traditional clustering methods, the method in this paper is applied under the precondition that partial information about experts is known. A framework of the hybrid method for clustering experts in the LGDM problem under the interval-valued linguistic environment is displayed in Fig. 2.
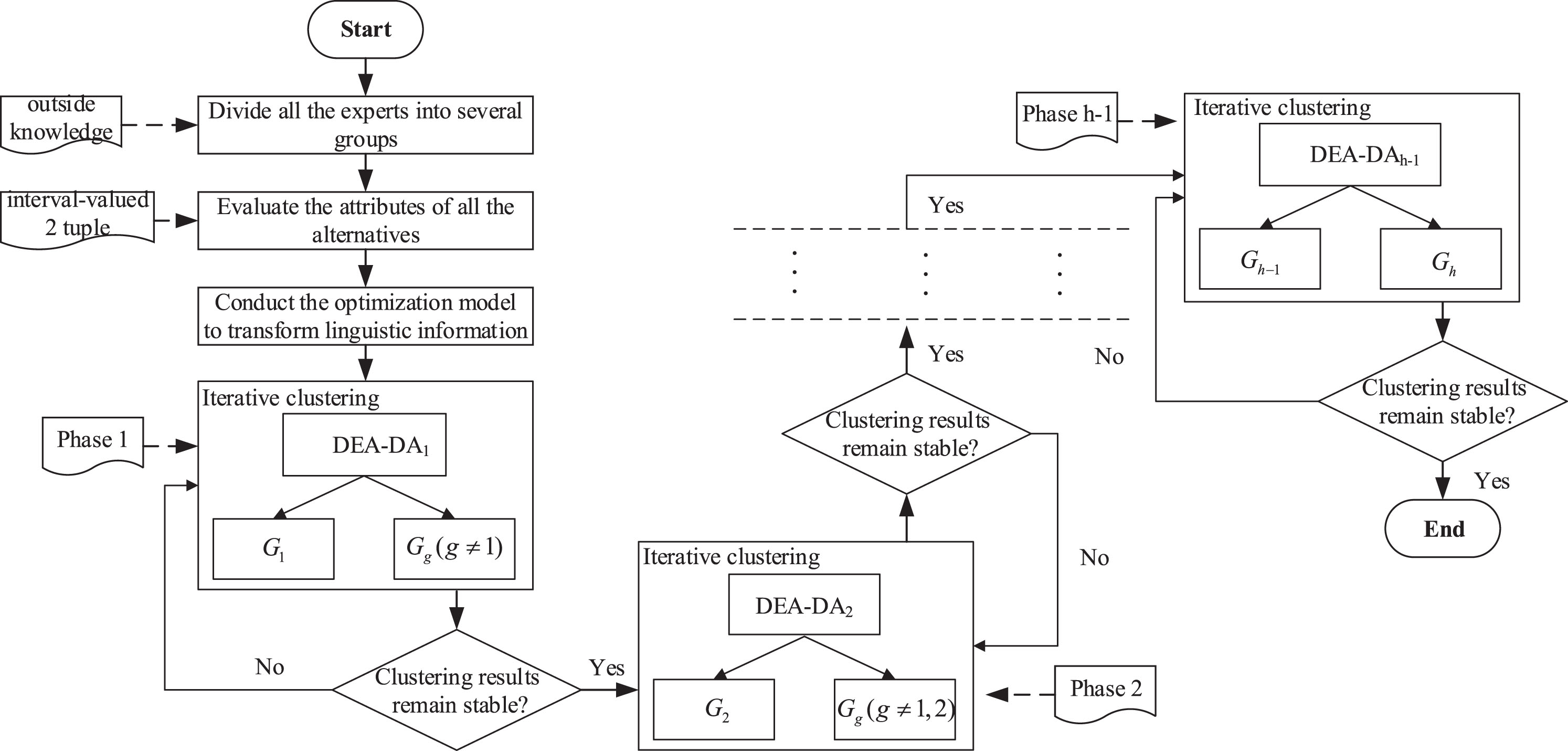
A framework of the hybrid method for clustering experts in the LGDM problem.
It can be seen that the hybrid method consists of four elements, that is, the IV2TL decision information, the optimization model, the two-stage MIP DEA-DA model (in what follows, this model is abbreviated as the DEA-DA model) to deal with a two-cluster issue, and iterative clustering to generate multiple expert clusters. Where, the optimization model developed in this study is used to transform the IV2TL decision information into information represented by 2 tuples (or finally numerical values); the DEA-DA model as a non-parametric approach proposed by Sueyoshi [33] incorporated the discriminant capabilities of DEA into DA (an important evaluation and clustering analysis method), in order to avoid misclassification and overlap in DA.
Suppose that there exist N experts in the LGDM problem under an interval-valued linguistic environment and the total samples G to be clustered consist of all the experts. If we divide all the experts into h (h ≥ 2) groups or sample groups according to their outside knowledge, suppose there exist N
g
experts in each sample group G
g
(g = 1, 2, . . . , h), and
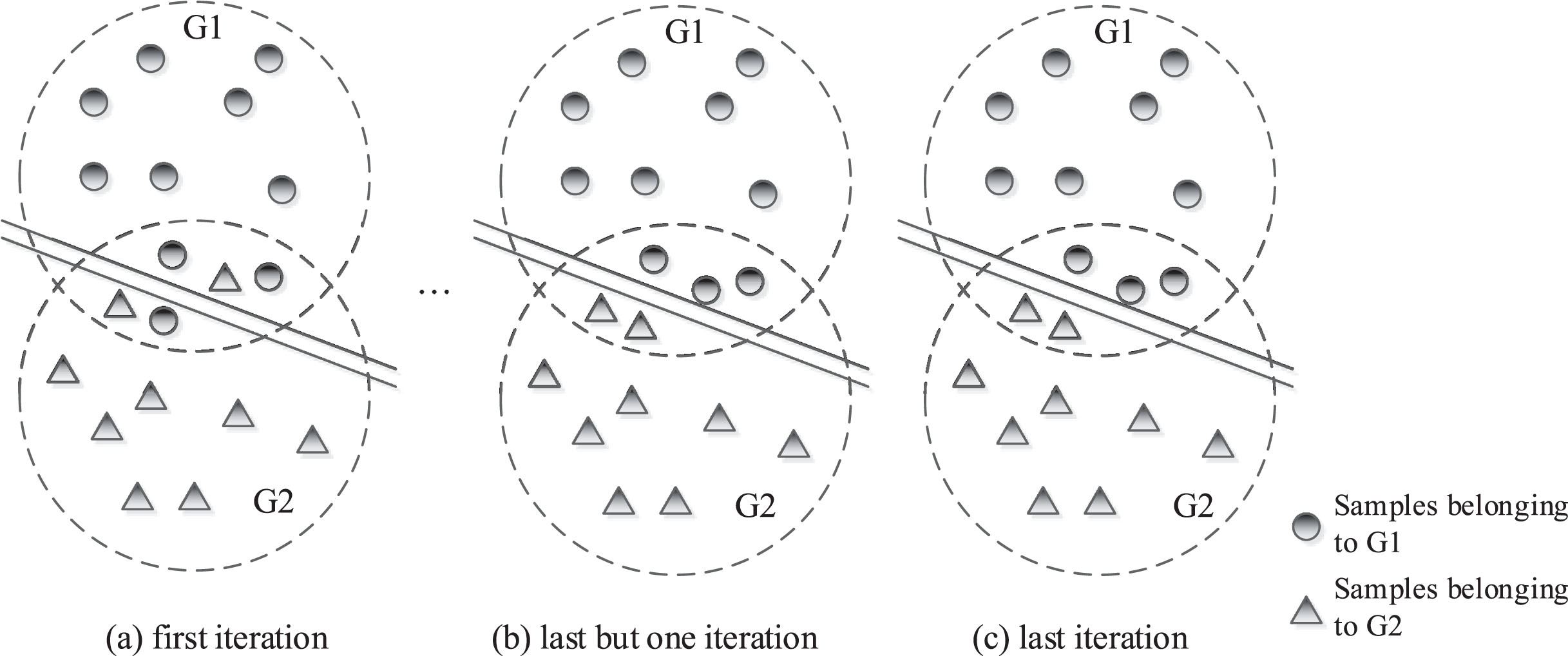
Visualization of iterative clustering.
Figure 3(a) represents the discriminant result obtained from the clustering of the original sample, which indicates the result achieved from the first iteration of the DEA-DA model based on the IV2TL decision information at the first phase. The two parallel lines in each iteration are regarded as the two hyperplanes determined in the HO model (the second stage of the DEA-DA model). It can be observed from this iterative process that the number of overlapping samples between the two sample groups would decrease gradually with a convergent trend as the iteration continues. The whole process will end until no overlapping areas exist.
To make a relatively comprehensive description of the evaluation information from all experts regarding different alternatives, this paper regards the attributes of each alternative as different evaluation objects. Thus, the number of attributes that all the experts evaluate increases from n to l = m × n. If we collect each line of

The expected clustering results.
To achieve this goal, variances are used to measure the deviation between samples and their sample means. There are numerous examples concerning the applications of variances [34–37]. Based on this, we use the concept of variance to establish the optimization model for clustering experts, which lays the foundation to construct the DEA-DA model under the interval-valued linguistic environment. If we divide all the experts into h (h ≥ 2) sample groups, there exist N
g
experts in each sample group G
g
(g = 1, 2, . . . , h), and
Based on Equation (5), in sample group G
g
, the mean
According to Equations (5) and (8), the variance
As clustering experts in the LGDM problem is based on the experts’ evaluations of each attribute of all the alternatives, this paper regards the importance degree of all attributes as equal to determine the value of μ more objectively. In this case, the variance weights of each attribute are all assigned to one. Then, the objective function with the maximum intergroup variance could be represented by
According to Equations (5) and (8), in the sample group G
g
, the variance
Similar to the disposal of variance weights of intergroup attributes, the objective function with the minimum intragroup variance could be represented by
If place the expressions f (μ) and f
g
(μ) into the above formula, then the formula could be further delivered as
The DEA-DA model (basically, the mixed integer linear programming) can produce a locally optimal solution for weight estimates of discriminant functions, further generating evaluation scores to determine group membership [33]. Suppose there are two sample groups G1 and G2 in G during phase g (g = 1, 2, . . . , h - 1), where there exist N1 and N2 experts, respectively and N1 + N2 ≤ N. We could obtain the DEA-DA model based on the general real-numbers
Assume
D1 = G1 - R1, D2 = G2 - R2,
where, D = D1 ∪ D2 indicates the overlapping or misclassified samples, which could be further judged through the discriminant model in the second stage.
Assume
Then, we classify the two sample groups G1 and G2 on a iterative basis, until samples belonging to G1 and G2 remain stable. Based on the framework presented in Fig. 2, the integrated process of the hybrid method is presented in Algorithm 1. Based on the clusters derived from the DEA-DA model at a given iteration, the principles to select the new group for clustering in the next iteration are: (a) if the two clusters are significantly unbalanced, the larger-size group will be handled further; (b) if the two clusters are nearly balanced, the group with more different group members pre-classified by outside knowledge would be selected.
The hybrid method for clustering experts in the LGDM problem in linguistic environment.
To investigate the feasibility and validity of the proposed hybrid method for clustering experts, the salary reform for teachers at the university is given as an example to show the application in the LGDM problem under an interval-valued linguistic environment. Then, we will compare the proposed method with another clustering method.
Example with the hybrid method
To reasonably determine the salary level of each professor, the university authority decides to enact a concrete salary reform plan. The financial department at the university invites 30 experts e k (k = 1, 2, . . . , 30), including administrative staff, research and teaching staff as well as retirees, to evaluate three candidate alternatives x i (i = 1, 2, 3). Assume that each alternative has three attributes (research contribution u1, teaching quality u2 and service assurance u3) and all the experts adopt the linguistic term set S= {s0= extremely poor, s1= very poor, s2 =poor, s3 =medium, s4 =good, s5 =very good, s6 =extremely good} to evaluate each attribute of all alternatives. Note that the number of experts, alternatives or attributes in reality may be much larger than that listed in the example.
The IV2TL decision matrix
The IV2TL decision matrix
The IV2TL decision matrix
The real-number decision matrix R
The variable results of the DEA-DA model at phase 1
The clustering results of the experts at phase 1
After using the COI model twice, the value of s* came to –0.035, which indicated group memberships of all samples were determined by the DEA-DA model for two iterations. Where, e1, e2, e4, e9 and e10 belonged to G1, while the rest of samples belonged to G2.
The variable results of the DEA-DA model at phase 2
The clustering results of the experts at phase 2
After using the COI model twice, the value of s* came to –0.005. It indicates that the group memberships of all samples were determined after adopting the DEA-DA model for the first time. Where, e3, e5, e7, e11, e15, e16, e17, e18, e19 and e20 belonged to G1, while e6, e8, e12, e13, e14, e21, e22, e23, e24, e25, e26, e27, e28, e29 and e30 belonged to G2.
The final clustering result for experts in the LGDM problem
It could be seen that the final clustering result was greatly different from the pre-classification. Overall, the scale of the groups varied with the order (Group 3 > Group 2 > Group 1). Only five administrative staff still stayed in the original group, while most of them were distributed to two other groups. The retiree staff group absorbed 5 members from other groups, resulting in a total number of 15 members.
Currently, research into the LGDM problems under the interval-valued linguistic environment is still at the early stage, and the relevant achievements are few [11]. Moreover, when the value of μ g is determined, the DEA-DA model with interval values is transformed from that with the IV2TL decision matrix into that with the general real-numbers. Based on this, this paper will compare the DEA-DA model with the maximal tree clustering method under the 2TL environment proposed by Yu and Fan [38]. The reason for selecting this method for comparison is that there is lack of study into expert clustering in the multi-attribute decision-making problems under the 2TL environment. Although the method selected mainly focused on the alternative clustering, similarly the algorithm can be also applied to clustering the experts. Therefore, we will briefly provide the procedure of the maximal tree clustering method to cluster experts based on the illustrative example as follows.
Considering there was a great deal of information in the matrix R′, the results of the similarity coefficient of all the experts were partly shown in Table 9.
The similarity coefficient matrix
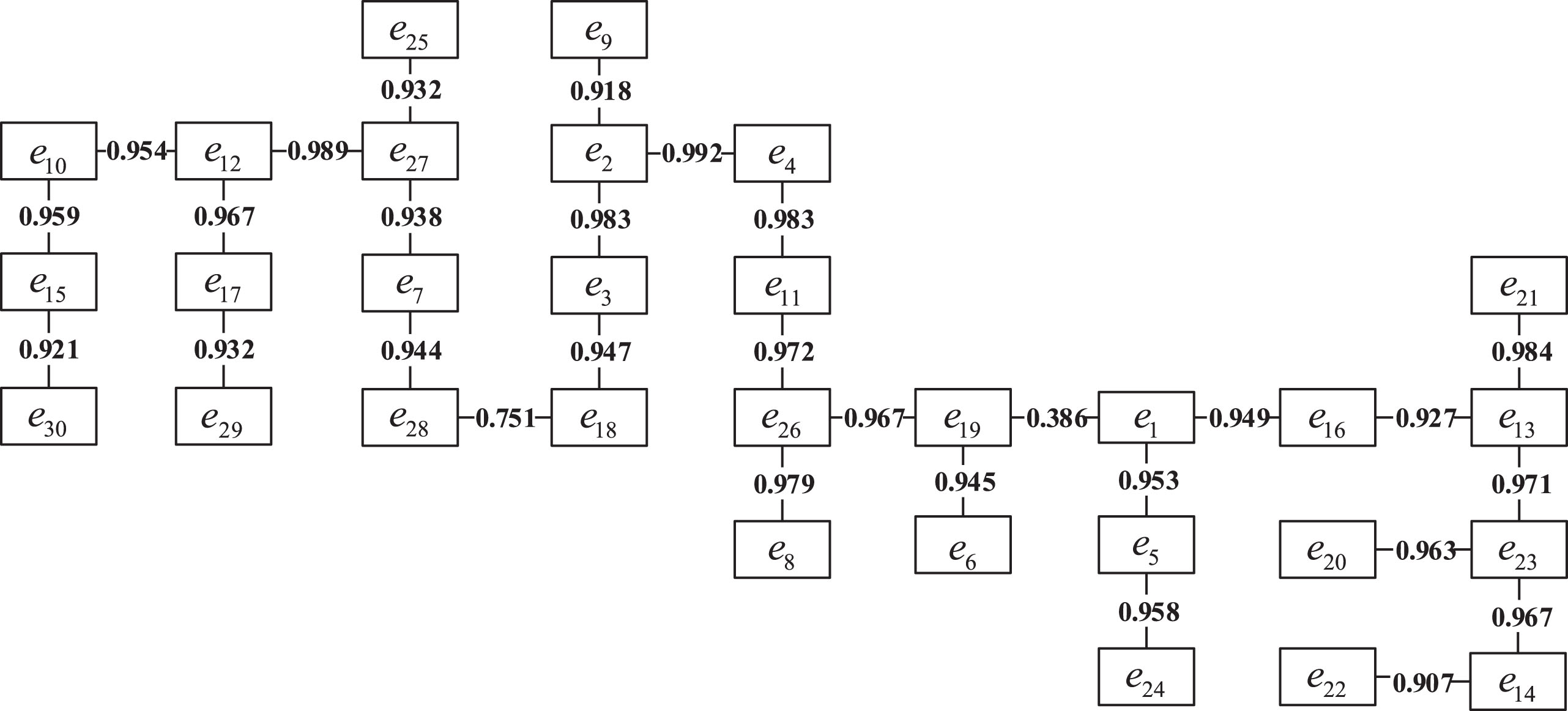
The results of the maximal tree I.
The clustering result for experts using the maximal tree clustering method
Comparing Tables 8 and 10, it could be seen that the clustering results by means of the two methods are completely different. The IV2TL representation model is a relatively new concept, and research into the GDM problems under the environment is still at an early stage. Meanwhile, regarding the clustering method proposed in this paper, there are nearly no directly comparable methods at present. As such, we only could make a comparison after the IV2TL decision information is transformed into the general real numbers using the optimization model. We attribute this as the reason for large differences in the clustering results. In the following, we would give some advantages of our proposed model over the one based on the maximal tree clustering method.
Firstly, more data information could be processed by the method proposed in this paper. The principle of the maximal tree clustering method is that the similarity coefficient as a relative index is the basis for clustering all the samples. From Equation (18), the calculation of similarity degree is based on the deviation between the value of each attribute and the mean of all the attributes in a sample. Thus, this approach is performed based on a comprehensive similarity index, and not directly on the original data set. In other words, some information in the original data set is neglected. Conversely, the proposed DEA-DA model through iterative clustering can explore the original data set fully, since it constructs several dividing lines (or hyperplanes) for the clustering through the original data of all the samples. It not only maintains the initial differences of all the attributes, but also has iterative clustering at each phase, which makes the clustering results stable. It doesn’t mean the maximal tree clustering method is not right, but what to stress is that the DEA-DA model used in this paper is nearer to the basic data resource (the original decision matrix provided by the experts).
Secondly, the guidance for selecting the range of the threshold is not clear for the maximal tree clustering method. To provide a brief description, we take five samples as an example to show the results of the maximal tree (see Fig. 6). When 0.62 ≤ λ < 0.75, all the samples are divided into groups ({e3}, {e5}, {e1,e2,e4}); when 0.75 ≤ λ < 0.84, all the samples are divided into groups ({e3}, {e5}, {e2}, {e1,e4}). It shows that different thresholds lead to the different clustering results, but how to choose the threshold range for this method is not so straightforward. However, we can pre-divide the experts into several groups based on some criteria, and then obtain the clustering groups with the DEA-DA model more easily without determining the threshold value.

The results of the maximal tree II.
To address the expert clustering issue in the LGDM problem under the interval-valued linguistic environment, we first assume some information about the experts is known, which could be regarded as the basis for pre-classification. Then, combining outside knowledge about experts and practical preference information, this paper proposed a hybrid method including the optimization model and the DEA-DA model with iterative clustering to cluster experts in the LGDM problem. The feasibility of the clustering method was illustrated by the example of the salary reform for professors at a university. In comparison with the maximal tree clustering method, two major advantages of the proposed method were given to expert clustering in the LGDM problem: (a) more information from the original data resource could be utilized; (b) it is not necessary to determine the threshold to obtain the clusters since importing groups divided by outside knowledge makes expert clustering much easier and more reasonable in an application scenario.
The main contributions of the paper could be summarized as follows: (a) we propose a hybrid method that combines the outside knowledge about experts with practical preference information, which can improve the clustering efficiency and distribute the distinct members in groups to a more reasonable group; (b) the IV2TL is integrated into the DEA-DA model after transformed by the optimization model, which extends the application area of the traditional DEA-DA model; (c) clustering experts in the LGDM problem can reasonably lay the foundation for experts’ weight determination and information aggregation based on the final clusters.
The key point of the research lies in a reasonable pre-classification for the experts, which should be guided by theoretical bases or practical experience. Here, the term “reasonable” doesn’t mean “unique”. Conversely, there should be massive reasonable criteria used for the pre-classification, and different ways of pre-classifications will lead to the distinct clusters. Once we decide to pre-classify the experts into several groups according to some criteria (say occupation), it means that we are interested in the opinion characteristics based on occupation. Similarly, we could also be interested in the opinion features from the age or salary perspective or from multiple perspectives (to pre-classify more groups). Future study will focus on the relationship between clustering results and the pattern of the pre-classified groups. Clustering experts under the interval-valued linguistic environment is the primary focus in this study. Based on the separated clusters, future study can consider how to reach a consensus within each cluster and among different clusters in order to aggregate decision information in the LGDM problem.
Footnotes
Acknowledgments
We gratefully acknowledge the financial support of the National Natural Science Foundation of China (Grant No. 71572123 and No. 71722004).