
Abstract
In this paper dynamic parameter adjustment in particle swarm optimization (PSO) for modular neural network (MNN) design using granular computing and fuzzy logic (FL) is proposed. Nowadays, there are a plethora of optimization techniques, but their implementations require having knowledge about these techniques in order to establish their parameters, because the performance and final results of a particular technique depend on the optimal parameter values. For this reason, in this paper the fuzzy adjustment of parameters during the execution is proposed, and this proposal allows to adjust the parameters depending on current PSO behavior in each iteration. The proposed method performs modular neural network optimization applied to human recognition using benchmark ear, iris and face databases. Two fuzzy inference systems are proposed to perform this dynamic adjustment, comparisons against a PSO without this dynamic adjustment (simple PSO) are performed to verify if the proposed adjustment using a fuzzy system is better improving recognition rate and execution time. The PSO variants presented in this paper are aimed at performing MNNs optimization. This optimization consists on finding optimal parameters, such as: the number of modules (or sub granules), percentage of data for the training phase, learning algorithm, goal error, number of hidden layers and their number of neurons.
Keywords
Introduction
Optimization techniques have provided a lot of advantages in solving real world problems; finding optimal parameters, architectures or solutions. These techniques have emerged from several years ago, for example: genetic algorithm (GA) [21, 31], ant colony system (ACO) [15] and particle swarm optimization (PSO) [16], as they are pioneering optimization methods that successfully demonstrated their advantages in areas of application. Recently other methods have also emerged based on different behaviors of nature, such as the firefly algorithm (FA) [56], grey wolf optimizer (GWO) [35], gravitational search algorithm (GSA) [40] or Cuckoo Optimization Algorithm (COA) [39] just to mention a few. All optimization techniques have parameters and of these depend on the final performance of the algorithm, some parameters can be easily adjusted using prior knowledge, but that can take a long time and we do not know in advance if they are the best parameters for a certain application or area.
The optimization methods mentioned above have been combined with other important intelligent techniques creating hybrid intelligence systems, such as artificial neural networks (ANNs) [23, 24], fuzzy logic (FL) [58], granular computing (GrC) [57, 59] and robotics [14], expert system (ES) [4] among others [3, 26]. There are quite a number of relevant works, where hybrid methods have been proposed, some are mentioned below. In [5], a new alpha level set optimization approach using PSO is applied, where hybrid random variables are simulated using fuzzy numbers. A hybrid modeling approach using response surface model (RSM) and support vector regression (SVR) is proposed in [30] and its results are compared with conventional techniques such as ANN, RSM and SVR are used to predict shear capacity of steel fiber-reinforced concrete beams (SFRCB). In [29], a fuzzy conjugate relaxed-finite step size method (fuzzy CRS) to improve the instability of the fuzzy first-order reliability is proposed. The method consists of two analyzer loops; the inner loop is established using the first-order reliability method (FORM) based conjugate search direction and relaxed approach and the outer loop is constructed using the genetic operator.
Artificial neural networks have been applied to human recognition, classification problems or time series prediction and their architectures have been improved using different optimization techniques [27], but conventional artificial neural networks have certain limitations to learn a large amount of information, for this reason, modular neural networks (MNNs) emerge to cover this limitation by creating experts modules which learn specific subtasks [47, 48]. Granular computing allows defining granules as sub granules or subsets allowing building computational models when a large amount of information is used [7]. Other intelligence technique capable to perform a human mind imitation is fuzzy logic, this technique employs modes of reasoning that are approximate rather than exact. A fuzzy inference system (FIS) has three components: fuzzy if-then rules, membership functions and an inference procedure performed by a reasoning mechanism [2].
In the literature, there are many works where of PSO and FL have been used, for example in image restoration [8], time series prediction [20, 34], control problems [6, 55], and other benchmark problems [42]. Fuzzy dynamic adaptation was already proposed and successfully applied to mathematical functions [37, 54], control problems [51, 52] and classification problems [33, 38]. In this paper, modular granular neural networks, fuzzy logic, granular computing and particle swarm optimization are combined to create a hybrid intelligence system applied to human recognition, performing a dynamic adjustment of PSO parameters using a fuzzy inference system to prove the effectiveness of this kind of adjustment combined with the intelligence techniques above mentioned. This work aims at achieving a better recognition rate, but also seeks to compare execution times against PSO variants and with other algorithms. The optimization techniques applied to human recognition usually have a slower convergence than when they are applied to other applications. Therefore, this work also aims at finding which technique allows a faster convergence.
This paper is organized as follows. A background is presented in Section 2. The proposed fuzzy parameter adaptation is described in detail in Section 3. The results obtained using the PSO variants are presented and explained in Section 4. Statistical comparisons of PSO results are presented in Section 5. Finally, in Section 6, the conclusions and future work are shown.
Related works
In this section some related works will be explained.
Modular granular neural networks
This type of artificial neural network and its optimization using a hierarchical genetic algorithm (HGA) were proposed in [46], and in that work the granulation of a database is proposed, where a main granule represents a whole database that contains images of persons. This granule can be divided into sub granules of different sizes that represent images of a number of persons. Each sub granule is divided into images sets for training and testing. Each image is divided into 3 parts, in the case of images for training each part is learned by a sub module. The set of images for testing is simulated in each sub module, and the responses of the sub modules are combined using “the winner takes all” method. The number of sub granules and sub modules architectures are optimized using an optimization technique. In Fig. 1, the granulation and optimization of a database using a MGNN is illustrated.
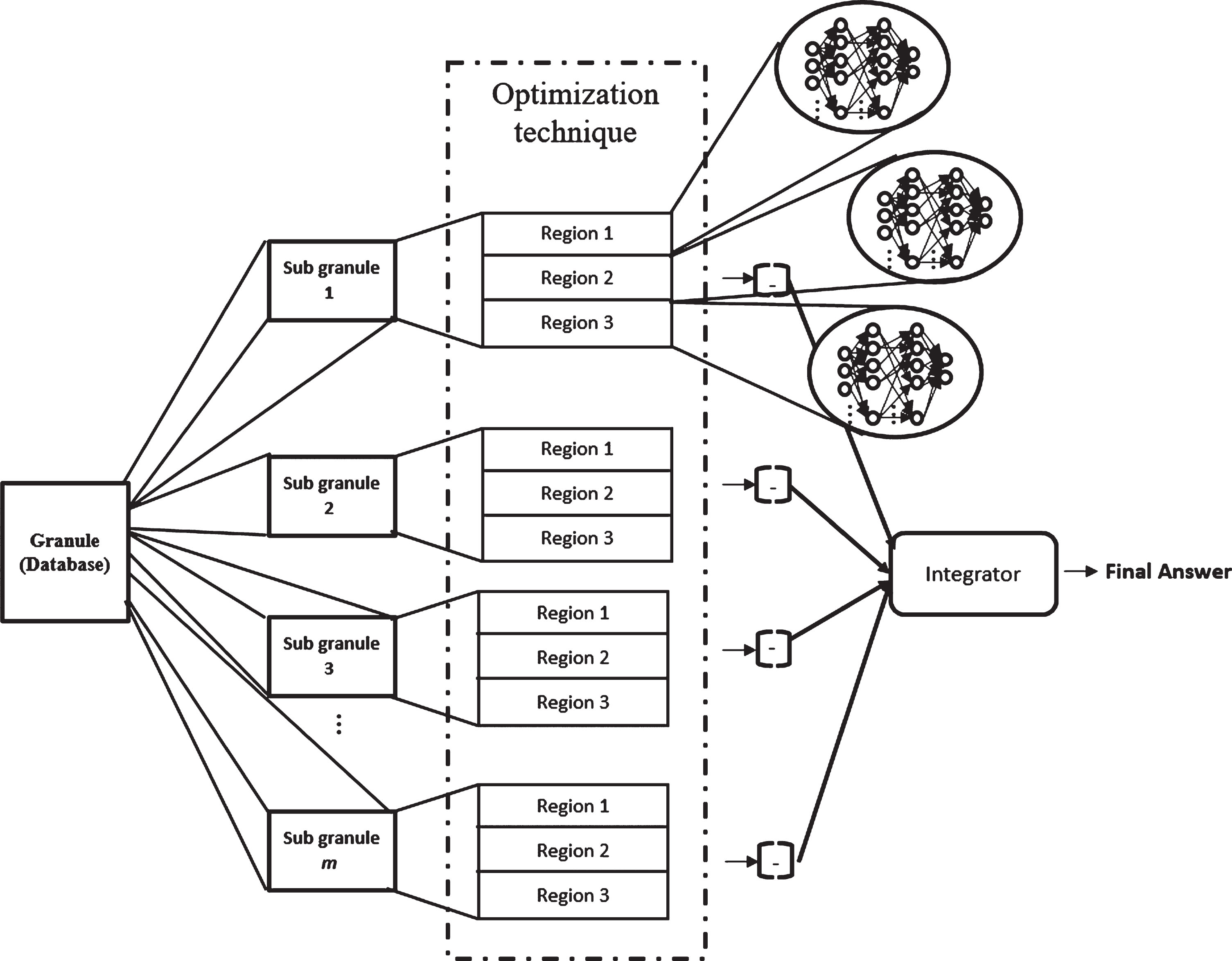
The general architecture of the MGNN granulation and optimization.
Particle swarm optimization was proposed in [16, 28] by R. C. Eberhart and J. Kennedy. This optimization technique is based on the social behaviors of fish schooling or birds flocking. A swarm contains particles, where each particle represents a solution and its next position in the search space is determined by Equation (1):
In this work, the star topology is used. In this variant, the neighborhood of each particle is the entire swarm. The PSO authors were improving the original algorithm, for this reason in this paper, the PSO with inertia weight (w) [17, 50] is used. A big inertia weight allows a global exploration to search new areas and a small inertia weight allows a local exploration, its value decreases linearly, this allows the exploration when PSO starts and in later iterations allows local explorations (exploitation). The particle velocity is determined by the Equation (2):

Pseudo code of the particle swarm optimization.
In this section the proposed PSO with fuzzy parameter adaptation and its application is described. The optimization technique with its fuzzy dynamic parameter adaptation designs the modular granular neural networks architectures applied to human recognition. In Fig. 3, the granulation and optimization of a database using a PSO variant is illustrated.
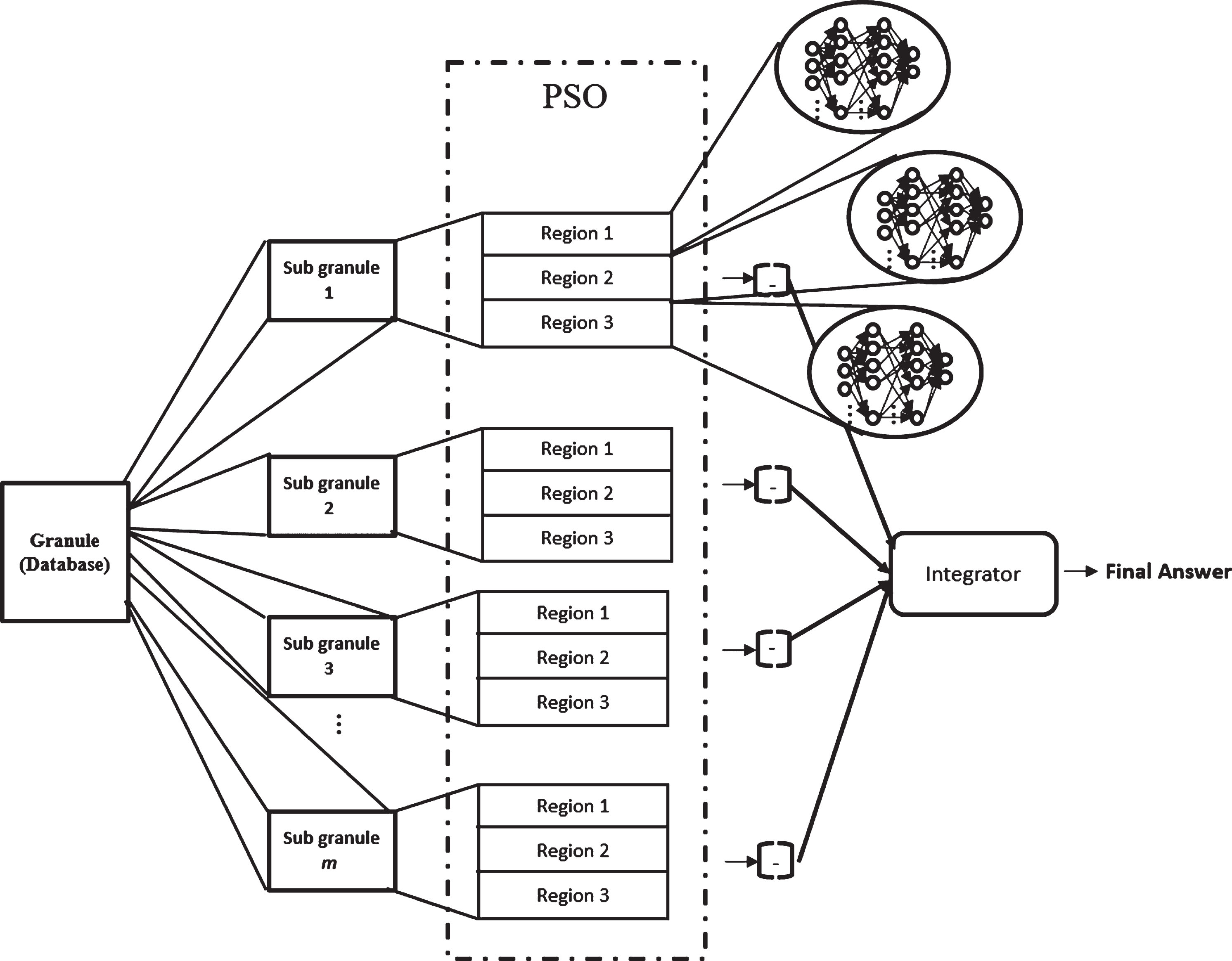
The general architecture of the MGNN granulation and optimization with a PSO variant.
In this work, two fuzzy inference systems are proposed to compare which of them is better to find the parameters of the PSO. Both fuzzy inference systems have 2 input variables and 3 output variables. All variables use 3 triangular membership functions and their linguistic labels are respectively “Low”, “Medium” and “High”. Figure 4 shows the structure of the fuzzy inference systems.
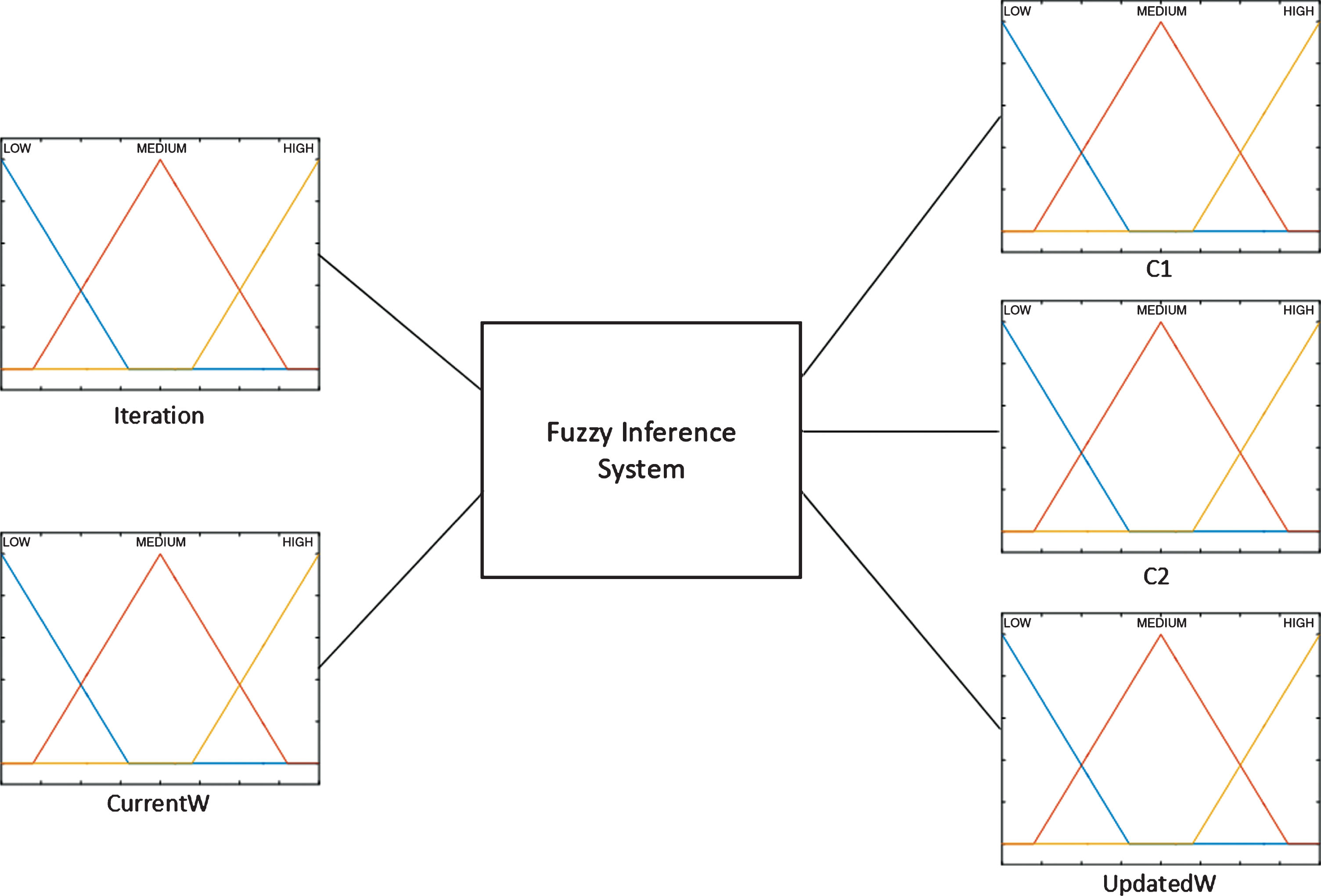
Fuzzy Inference System for dynamic adaptation.
The inputs variables are:
The outputs variables are:
The fuzzy if-then rules and type of the membership functions were obtained by experimental knowledge. The 9 fuzzy if-then rules used in the fuzzy inference systems are shown in Fig. 5. These fuzzy if-then rules are formulated with a goal; a balance among the output values c1, c2 and the update of w, this means that, if the value of the update of w is small, c1 and c2 will have high values and vice versa. For example, if the value of iterations is high and the current w is low, then the w update is allowed to remain low but c1 and c2 should be high. The ranges of the variables in each FIS are presented in Table 1. These ranges were obtained based on values suggested by specialists [18], ranges proposed by authors of this kind of adaptations [38, 52] and “trial and error”.

Fuzzy Inference System to dynamic adaptation.
Ranges of variables
The objective function is to minimize the error of recognition and is given by Equation (3):
Each dimension of the particle represents a parameter of the MGNN to be optimized. The total number of parameters (dimensions) is calculated by:
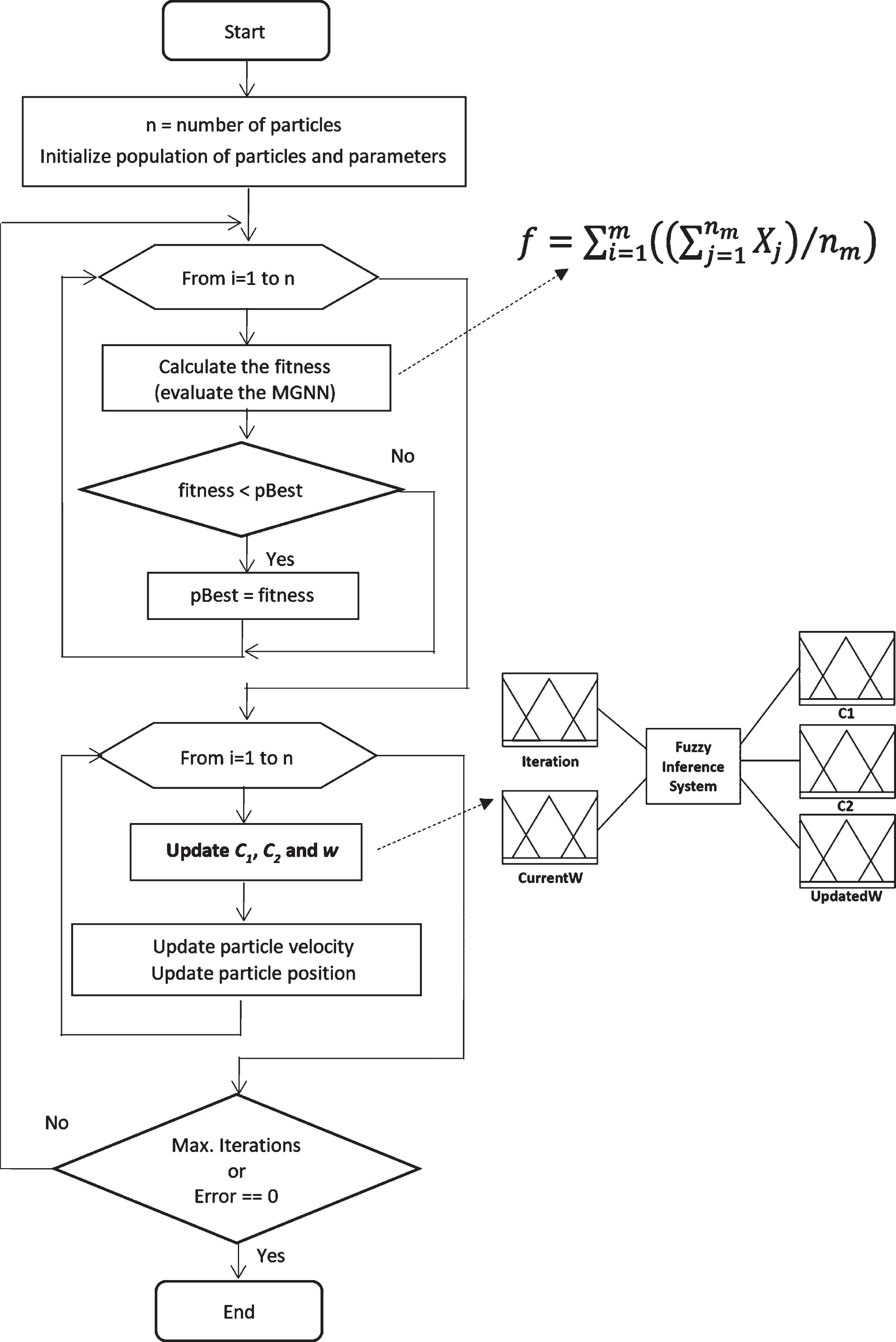
Diagram of the proposed method.
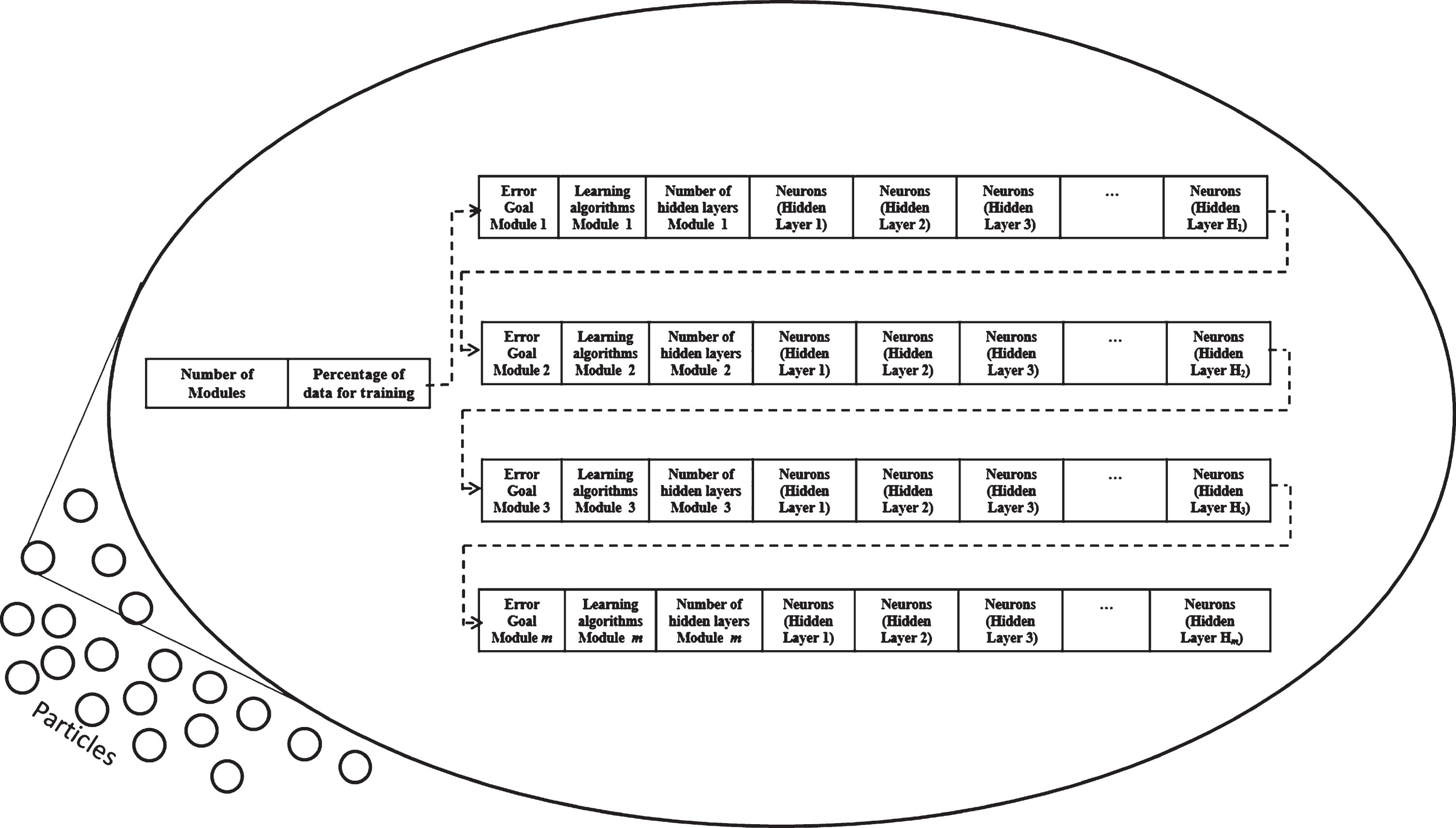
Particle dimensions.
In this work, multi-layer feed-forward neural networks are used. As learning method a supervised learning algorithm was selected, which is the backpropagation algorithm. In this algorithm, the input signal is propagated through the neural network layer-by-layer, and then an error is calculated using the inputs and the desired outputs, the synapses weights are modified, repeating these steps until convergence [44]. Due to its ability to handle large learning problems, it has been used in a wide research area, such as human recognition [43]. To perform the modular granular neural networks training, three backpropagation algorithms used in previous works were selected [46, 48].
This selection was performed because their performances are faster and their achieved results are better than other backpropagation algorithms: radient descent with scaled conjugate gradient (SCG) Gradient descent with adaptive learning and momentum (GDX) Gradient descent with adaptive learning (GDA).
The search space was established using the minimum and maximum values also used in [48]. This particle swarm optimization has two stopping conditions: when the maximum number of iterations is achieved or when the objective function has a value equal to zero.
The initial parameters of the PSO algorithm are shown in Table 2. It is important to remember that these values (C1, C2 and w) are only the initial ones, during the execution of the algorithm the values will be continuously updated, but to compare results, a PSO without fuzzy dynamic adaptation is used (in this work called “simple PSO”).
Initial parameters of the PSO
Initial parameters of the PSO
The description and the pre-processing applied to the databases used are presented below.
Ear database. The ear database is from the University of Science & Technology Beijing (USTB) and contains 77 persons, where each person has 4 images of one ear. The image dimensions are 300 x 400, with BMP format [10]. A sample of the images of a person is shown in Fig. 8. The pre-processing for each image of this database is: the image is manually cut, the image is resized to 132 x 91 pixels and automatically the image is divided into three regions of interest (helix, shell and lobe) [22, 46]. In Fig. 9, the pre-processing process is shown.
Sample of the Ear Database from USTB.
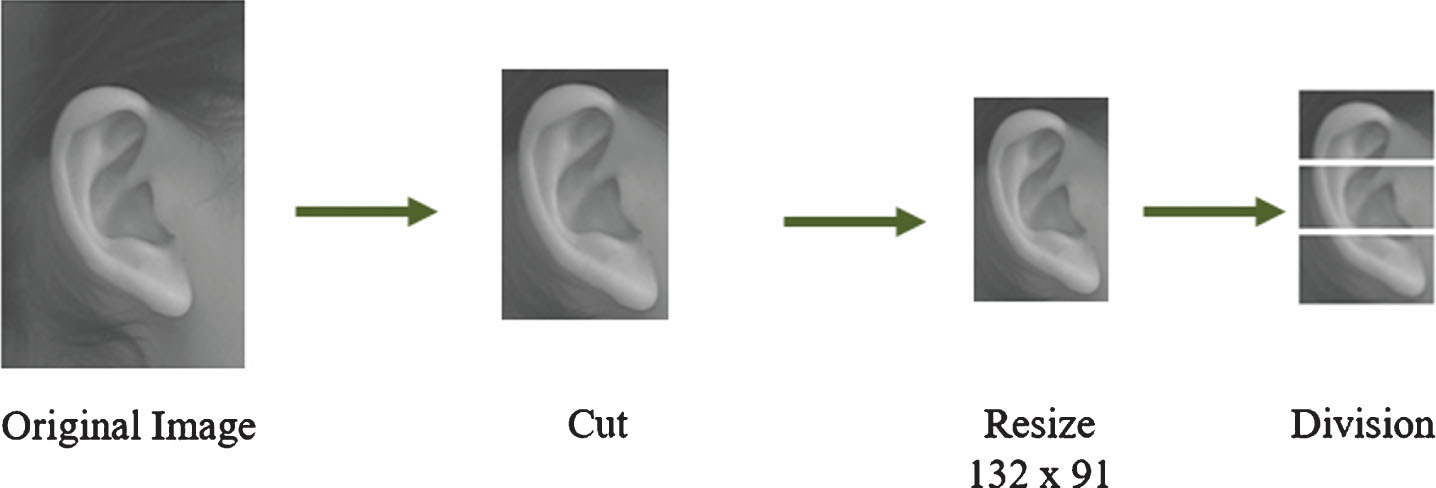
Sample pre-processing for ear database.
Iris database. The iris database is from the Institute of Automation of the Chinese Academy of Sciences (CASIA) [11] and contains 77 persons, where each person has 14 images (7 for each eye). Each image has a dimension of 320×280, JPEG format. Figure 10 shows a sample of the images of this database.

Sample of the Iris database from CASIA.
The pre-processing for this database was proposed by Masek and Kovesi [32]. This is used to obtain coordinates and radius of iris and pupil to perform a cut in the iris, the image is resized to 21×21 pixels and finally, each image is automatically divided into three parts. In Fig. 11, the pre-processing is shown.

Sample pre-processing for iris database.
Face database. The face database is from the AT&T Laboratories in Cambridge [12] and contains 40 persons, where each person has 10 images. The image dimensions are 92×112 pixels, PGM format. Figure 12 shows a sample of the images of this database.

Sample of the ORL database.
As pre-processing process each image is automatically divided into three regions of interest (front, eyes and mouth). Figure 13 shows the pre-processing process.

Sample pre-processing for ORL database.
Selection method. As it is known, the artificial neural networks have a learning phase, and in this phase they learn information. Usually, when databases for human recognition are used, a 70 or 80 percent of the images of each person are used for the learning phase, and the rest of images are used to test the artificial neural network (testing phase). In [46], another method to perform the selection process was proposed, where the percentage of data for training can vary (and be optimized) and the images for each phase are randomly selected unlike the conventional method where the percentage is always fixed and the same images are always selected for each phase. In this work, the percentage of images for training phase is optimized by the particle swarm optimization. In Fig. 14, the selection methods are illustrated.

Selection methods.
The results achieved by different variants of PSO (simple PSO, PSO using the FIS#1 and PSO using the FIS#2) applied to human recognition are presented in this section. For the ear database, 30 runs are performed using up to 80 and 50 percent of the data. For the iris database, 20 runs are performed using up to 80 and 50 percent of the data and for the ORL Database, 5 runs were performed using respectively 4 and 5 images for training, but only results using 4 images are shown in Section 4.3. Finally, a summary of results of all databases is shown in Section 4.4.
Ear results
The results achieved using the ear database are presented below. Only the best result of each PSO variant is shown.
Results using a percentage of data for training up to 80%
In this test, each PSO variant can use up to 80% of data for the training phase. In Table 3 the best result of each variant is shown. It can be observed that the 3 variants achieve the same result, but the PSO with the FIS#2 designed a MGNN with less number of modules.
The best results (up to 80%, Ear)
The best results (up to 80%, Ear)
The behavior of run #1 of the simple PSO is presented in Fig. 15. This run was one of the fastest runs to obtain an error value equal to zero. In Fig. 16, the average of convergence of the 30 runs of each PSO variant is shown. Although in the first iterations the simple PSO showed less error, in the end, the other variants of PSO had a better behavior.

Convergence of run #1 of the simple PSO.

Average of convergence (Test #1, Ear).
In this test, each PSO variant can use up to 50% of data for the training phase. In Table 4 the best result of each variant is shown. It can be observed that the variant of PSO with the FIS#1 achieves the best result and also uses less number of modules. The behavior of run #20 of the PSO with the FIS#1 is illustrated in Fig. 17.
The best results (up to 50%, Ear)
The best results (up to 50%, Ear)

Convergence of run #20 of PSO+FIS1.
In Fig. 18, the average of convergence of the 30 runs of each PSO variant is presented. For this test, the PSO with the FIS#2 had a best behavior.

Average of convergence (Test #2, Ear).
The results achieved using the iris database are presented below. Only the best result of each PSO variant is presented.
Results using a percentage of data for training up to 80%
In this test, each PSO variant can also use up to 80% of data for the training phase. In Table 5, the best result of each variant is shown. It can be observed that the simple PSO and the PSO with the FIS#2 achieve an error of recognition equal to zero with almost the same number of modules.
The best results (up to 80%, Iris)
The best results (up to 80%, Iris)
The behavior of run #11 of the PSO with the FIS#2 is presented in Fig. 19. This run achieved an error value equal to zero in the iteration number 11.

Convergence of run #11 of PSO+FIS2.
In Fig. 20, the average of convergence of the 20 runs of each PSO variant is presented. For this test, the PSO with the FIS#2 also had a best behavior than the other variants.
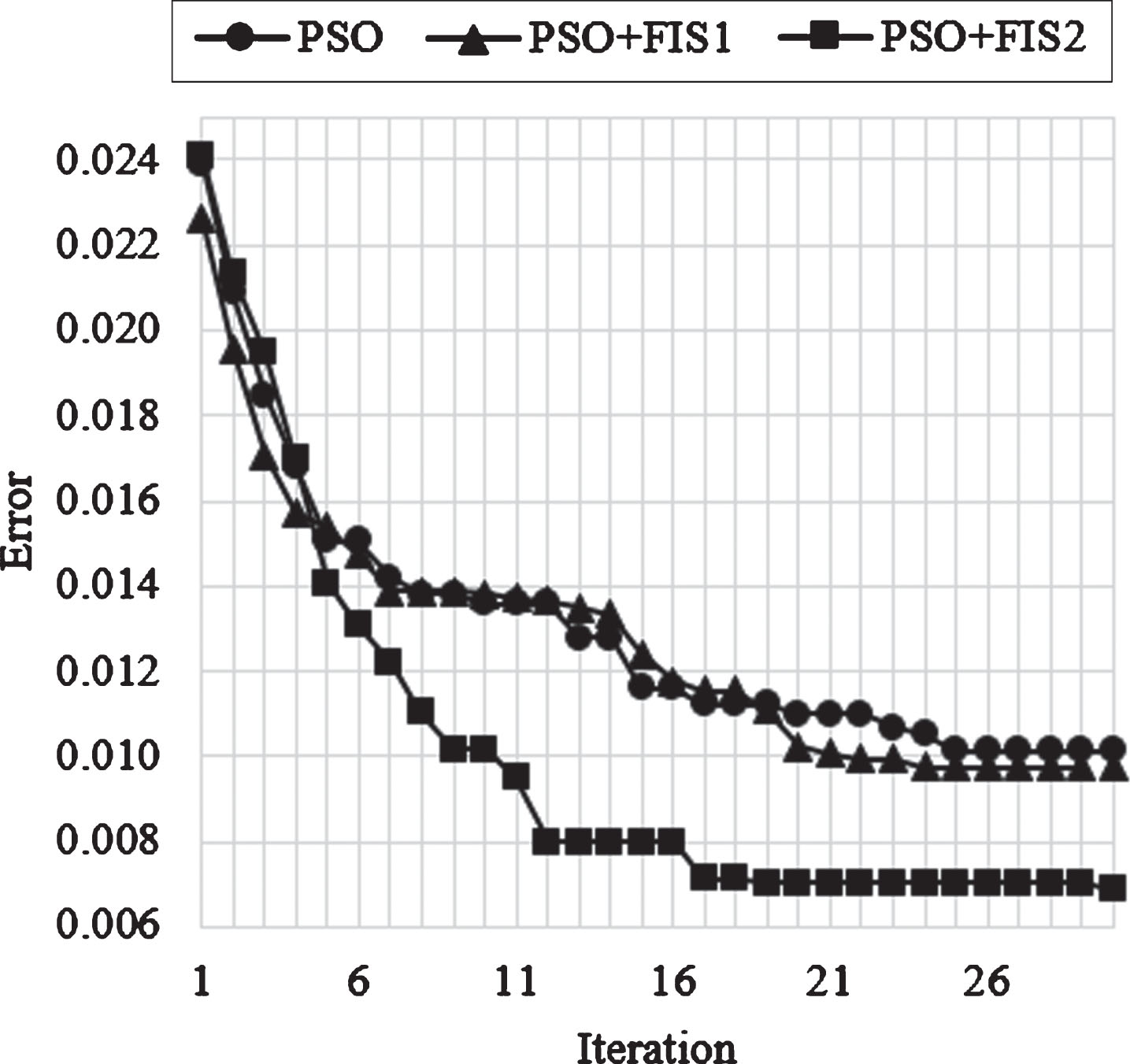
Average of convergence (Test #1, Iris).
In this test for the iris database, each PSO variant can use up to 50% of data for the training phase. In Table 6 the best result of each variant is shown. It can be observed that the PSO with the FIS#1 and the PSO with the FIS#2 achieve the same error of recognition with almost the same number of modules. The behavior of run #3 of the PSO with the FIS#2 is presented in Fig. 21. This run obtained a 97.59 % of recognition rate, and error value equal to 0.0241. In Fig. 22, the average of convergence of the 20 runs of each PSO variant is shown. For this test, the PSO with the FIS#2 had also a best behavior than the other variants.
The best results (up to 50%, Iris)
The best results (up to 50%, Iris)

Convergence of run #3 of PSO+FIS2.

Average of convergence (Test #2, Iris).
To test the effectiveness of the proposed method, a well-known benchmark database is used: the ORL database. The results of this database will be directly compared with other authors. The results achieved using this database, using 4 images for the training phase, are presented below. Only the best result of each PSO variant is shown. In Table 7, the best result of each variant is presented. It can be observed that the PSO with the FIS#1 and the PSO with the FIS#2 achieve an error of recognition equal to zero with the same number of modules. The behavior of run #1 of the PSO with the FIS#2 is presented in Fig. 23. This run achieved an error value equal to zero in the iteration number 13. In Fig. 24, the average of convergence of the 5 runs of each PSO variant is illustrated. The PSO with the FIS#2 had a faster convergence than the other variants.
The best results (4 images, ORL Database)
The best results (4 images, ORL Database)

Convergence of run #1 of PSO+FIS2.

Average of convergence (4 images, ORL database).
A summary of results is shown below and also comparisons with respect to other works using the ear, iris and face databases are presented. All the optimization techniques shown in this Section performed the same number of function evaluations. The summary of results obtained with the PSO and the two fuzzy adaptation methods for the ear database is shown in Table 8.
The summary of results (Ear Database)
The summary of results (Ear Database)
In some of our previous works, the modular granular neural networks have been optimized using different optimization techniques such as a HGA [46], a FA [48] and a GWO [47]. Also, other authors have used the same database, in [22] modular neural networks with two different integration methods (Winner takes all and Sugeno Integration) were performed. In [41], ear feature extraction is proposed and an artificial neural network for classification is used, also in [36] artificial neural networks are used, but the feature extraction is performed using eigenvectors.
In Table 9, the comparison between the non-optimized and optimized results is shown. When up to 80% of images are used, all PSO variants and GWO obtained an average of 100 recognition rate. When up to 50% of images are used, the best result is obtained by HGA, but the best average is obtained by the FA, this one achieved better results than any of the PSO variants.
Table of comparison of results (Ear Database)
The summary of results obtained with the PSO and the two fuzzy adaptation methods to the iris database are shown in Table 10. Also for iris database some of our previous works used other optimization techniques such as a HGA [45], a FA [48] and a GWO [47]. For this database, other authors have also presented results. In [19], contour segmentation of the iris was performed and train modular neural networks using 99 persons (1386 images). In [13], Daugman used 756 images of 108 persons, it means less number of images for training and testing, using different kinds of techniques for features extraction.
The summary of results (Iris Database)
In Table 11, the comparison of results for the iris database among the PSO variants and the other works is presented. When up to 80% of images are used, PSO+FIS #2 and GWO obtained the best average of recognition. In the case that 50% of images are used, the best result is obtained by HGA, but its worst recognition rate (94.64%) is lower than the PSO variants. The best average is obtained by the PSO+FIS #2 variant.
Table of comparison of results (Iris Database)
In Table 12, the comparison for the ORL database among the PSO variants results and the other works is presented. In [1], an adaptive technique for obtaining centers of the hidden layer neurons of a radial basis function neural network (RBFNN) for face recognition using FA is proposed. In [25], a GWO with Linear Collaborative Discriminant Regression Classification is proposed. In [49], feature selection using GA for face recognition based on principal component analysis (PCA), Wavelet and Support vector machine (SVM) is presented. In [47] and [48], modular granular neural networks are optimized using respectively GWO and FA. When 5 images for the training phase are used, any PSO version is better than the other works, and when 4 images for the training phase, the PSO+FIS #2 has better performance.
The summary of results (ORL Database)
Comparisons of execution times are presented in this section. In Table 13, averages of execution times are presented. In this table can be observed, for the ear, a faster convergence of the PSO+FIS#2 when up to 80% of data is used (achieved a 100% recognition rate). When 50% is used, also PSO+FIS#2 is faster than the others, but it is important to remember that FA achieved better results. For the iris, PSO+FIS#2 was faster than other algorithms when up to 80% are used, and when 50% is used the faster algorithm was PSO+FIS#1. For the ORL database, PSO+FIS#2 was faster than the PSO+FIS#1 and the simple PSO.
Execution times of the optimization techniques (Average)
Execution times of the optimization techniques (Average)
In Figs. 25 and 26, the execution times of each run for the ear are shown respectively when up to 80% and 50% of data are used. In Figs. 27 and 28, the execution times of each run for the iris are respectively shown when up to 80% and 50% of data are used.

Execution time (Ear, 80%).

Execution time (Ear, 50%).

Execution time (Iris, 80%).
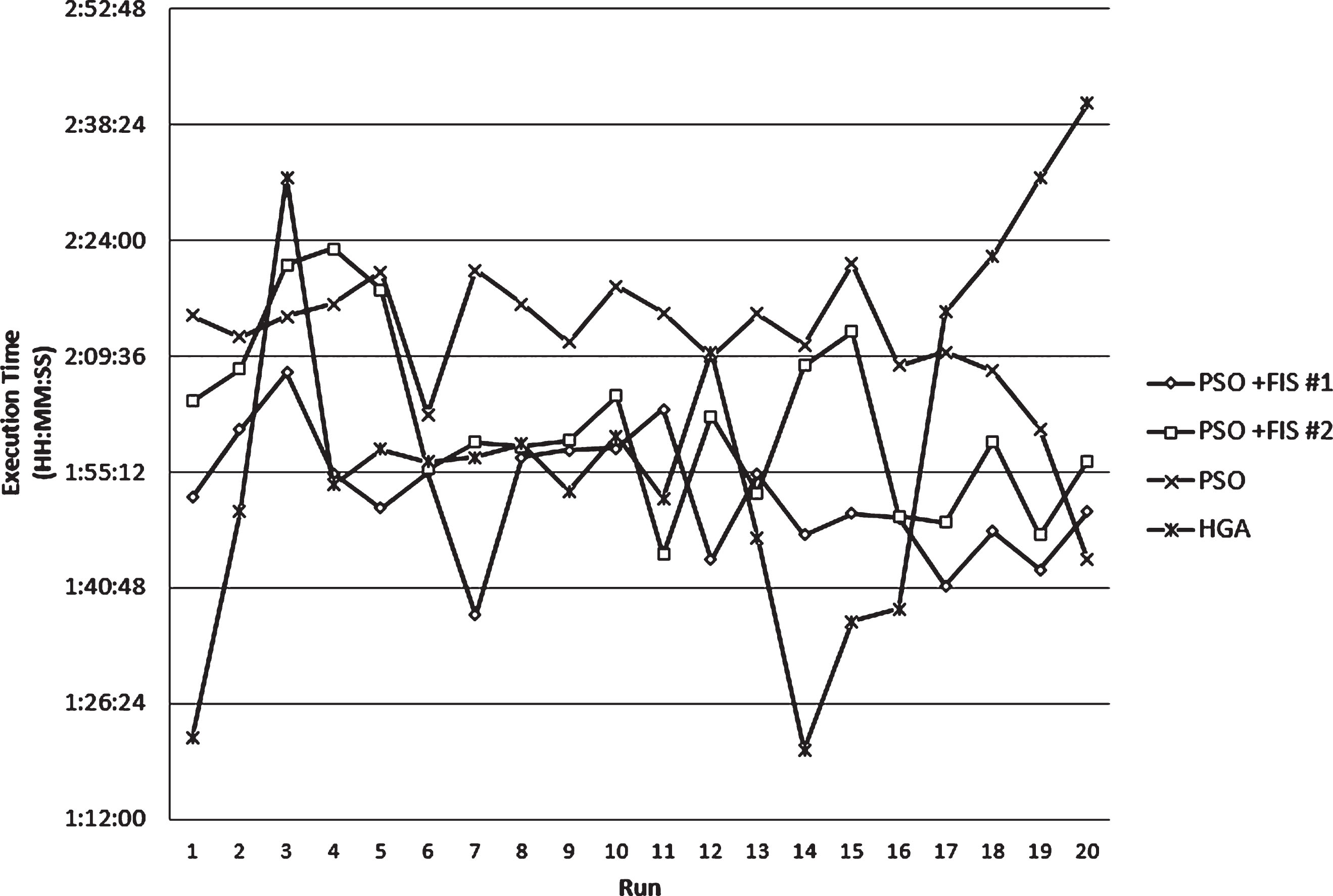
Execution time (Iris, 50%).
In Fig. 29, the execution times of each run for the face database are respectively shown when 4 images for the training phase are used.
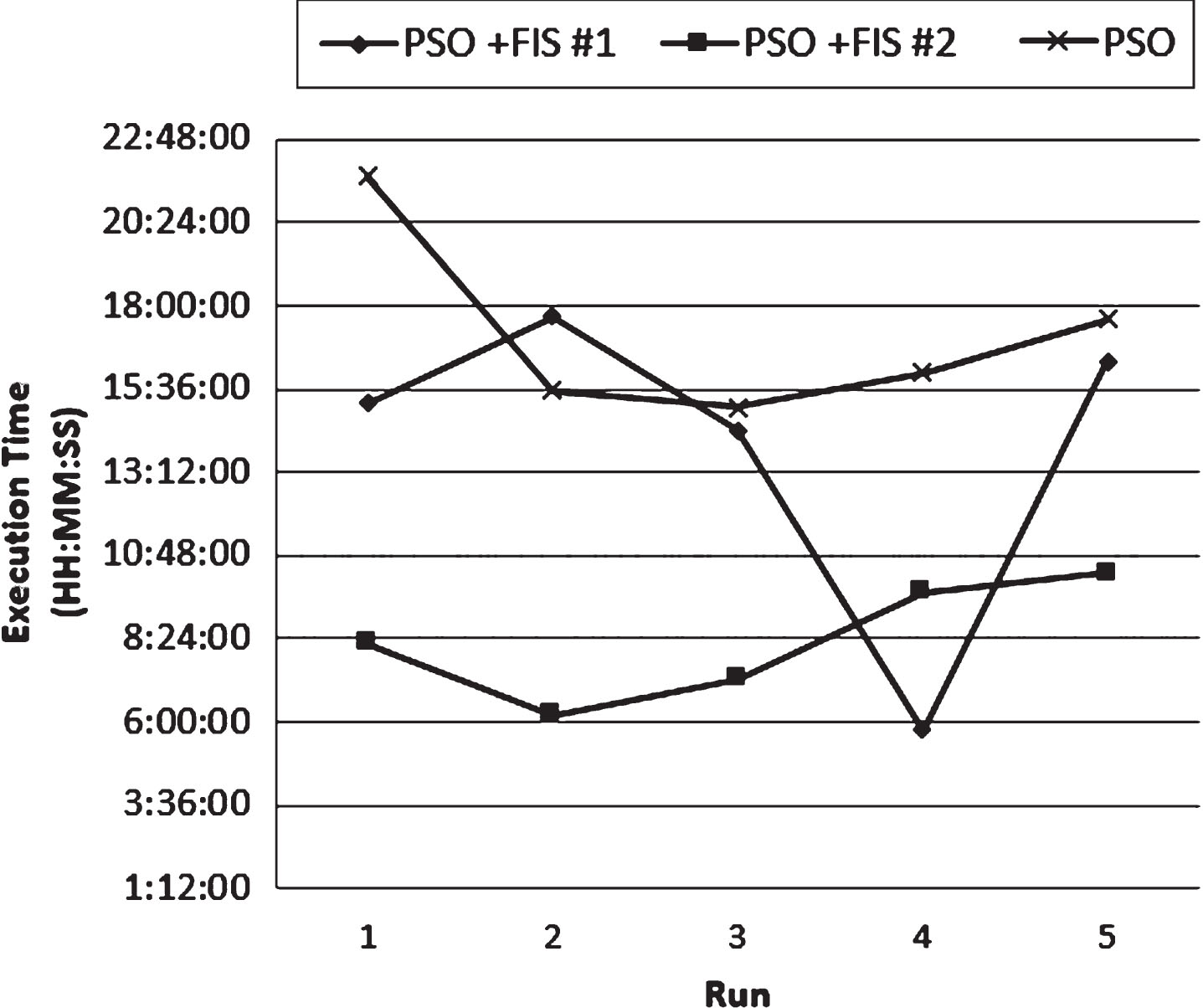
Execution time (ORL database, 4 images).
To verify which PSO variant is better, statistical t tests were performed to verify if there is sufficient statistical evidence to prove it. In this section the statistical tests for ear, iris and face database are shown.
Results for ear database
When the ear database is used with up to 80% of data for training, all PSO variants achieved the same results, for this reason t-tests are omitted when 80% is used. In Table 14, the t-values for the ear database using up to 50% for training phase are shown. As results show, with a t-value of 2.69, there is sufficient evidence to say that only PSO with the FIS#2 significantly improve results unlike the simple PSO. When the proposed method is compared with other optimization techniques such as: FA and GWO, these algorithms had a better recognition rate, although, any variant of PSO had a better execution time.
Values of the ear database (up to 50%)
Values of the ear database (up to 50%)
In Table 15, the t-values for the iris database using up to 80% for training phase are shown. As results show, with t-values of 2.82 and 2.59, there is sufficient evidence to say that PSO with the FIS #2 significantly improves results unlike the simple PSO and PSO with the FIS#1. Comparing with other algorithms, PSO+FIS#2 achieves significant improvements on the results obtained by HGA and FA with t-values of 3.30 and 5.83, respectively.
Values of the iris database (up to 80%)
Values of the iris database (up to 80%)
In Table 16, the t-values for the iris database using up to 50% for training phase are shown. As results show, there is sufficient evidence to say that PSO with the FIS#1 and PSO with the FIS#2 significantly improve results unlike the simple PSO. When both adjustments are compared, the PSO with FIS#2 is better. Comparing with the HGA, the PSO+FIS#2 achieves a better recognition rate, but there is not enough evidence to prove it.
Values of the iris database (up to 50%)
In Table 17, the t-values for the face database using 4 images are shown. PSO+FIS#2 results are used to compare because this variant had better results and a faster convergence. As results show, with t-values of 9.12 and 12.87, there is sufficient evidence to say that PSO with the FIS #2 significantly improve results unlike the GA and FA proposed by other authors.
Values of the ORL database
Values of the ORL database
Wilcoxon signed-rank tests were also performed for ear and iris database. The critical values are shown in Table 18, where the different values of α are shown depending of the statistical significance and number of samples.
Critical values
Critical values
In Tables 19 and 20, the results of the Wilcoxon tests for the ear and iris databases are respectively shown. To compare the results achieved with 5% level of significance, the result in the column named “
Wilcoxon test results (Ear)
Wilcoxon test results (Iris)
When PSO and PSO+FIS#1 are compared, we fail to reject the null hypothesis for all the tests. This means that the best PSO variant is PSO+FIS #2. For ear database, we only fail to reject the null hypothesis when results are compared with HGA.
For the iris database, we only fail to reject the null hypothesis when results are compared with GWO using up to 80% of data and with HGA using up to 50% of data.
In this paper, a fuzzy dynamic adaptation approach is proposed to dynamically establish the PSO parameters, and this optimization technique is applied in designing modular granular networks architectures applied to human recognition seeking to minimize the recognition error. The proposed adaptation aims at dynamically tuning parameters of PSO during its execution, and this allows to improve its performance and to find better parameters depending on current behavior in each iteration. To perform a comparison, two fuzzy inference systems were proposed, and different runs with each fuzzy inference system were performed and comparisons with a simple PSO were made to evaluate which PSO variant is better. The proposed method is applied to human recognition using the ear, iris and face as biometric measurements, where different PSO variants design MGNNs architectures using up to 80 and 50 percent of the data for the training phase. This design implies parameters, such as the number of modules (sub granules), percentage of data for the training phase, goal error, learning algorithm, number of hidden layers and their respective number of neurons. Based on the results achieved by the PSO variants, better results were obtained when the fuzzy dynamic adaptation is implemented. If we compare the results of the proposed method against other optimization techniques, such as HGA, FA or GWO, the PSO results achieved the same or better results (except for ear database using up to 50 percent of data for training). If execution times are compared, PSO with dynamic parameter adjustment had a faster convergence than simple PSO and other optimization techniques. As a conclusion, this optimization technique can improve its performance if the parameters are correctly established depending on its behavior. As future works other fuzzy inference systems will be proposed using other variables, in order to increase the difference between this and the other methods, also a comparison among architectures will be performed in order to reduce their complexity.