
Abstract
Motivated by a widely studied computer vision task: image inpainting, we became interested in a less concerned problem image outpainting. By which, contents beyond the image boundaries may be extrapolated. In recent years, deep learning methods have achieved remarkable improvements in image inpainting, these techniques can be considered to be applied to image outpainting as solutions. However, many of these inpainting methods generate image blocks generally resulting in blur or smooth. Recently, hallucinating edges for the missing holes before completion has been proved to be a state-of-the-art image inpainting method. Refer to the aforementioned method, we propose a three-phase outpainting model that consists of an edge generation phase, an image expansion phase and a refinement phase. In order to depict the edge lines more accurately, we adopt a comparatively effective focal loss for edge prediction. An optimization stage with a refinement network is also added since large portions outside the image need to be inferred, and discriminator in this stage works on a decreased patch size with a coarse-to-fine fashion. In addition, with recursive outpainting, an image could be expanded arbitrarily. Experiments show that an image can be effectively expanded by our method, and our outpainting method of predicting edges and then coloring is generally superior to other methods both quantitatively and qualitatively.
Introduction
Image inpainting focuses on hallucinating the inner missing holes within an image. It is widely applied for image restoration and editing. Compared with image inpainting, extrapolating beyond the image boundaries (outpainting) has been paid less attention by researchers. The difficulty of image outpainting lies in that it refers to insufficient adjacent information to infer the content of large blank areas outside the image. Like the requirements of inpainting, the inferred image contents should look plausible both visually and semantically, and the expanded parts should integrate well with the original image. Although the task is challenging, image outpainting can achieve a lot of novel applications, such as image texture synthesis, image panorama reproduction, etc.
The methods of image inpainting provide a good reference for outpainting. Thus, we first review the approaches taken by the former. Before the deep learning technology, traditional diffusion-based [1–4] and patch-based [5–7] methods are used for image inpainting. The diffusion-based methods propagate background information to the empty areas, while the patch-based methods search for the most matching image blocks in a known image set. However, these two methods are difficult to recover complex and locally unique image contents.
Recently, the emerging deep learning technologies have achieved amazing success in image inpainting. These methods learn the distribution of data and convert masked inputs into complete outputs in an end-to-end manner. Most of these learning-based approaches require training on large datasets. Meanwhile, in order to produce more plausible results, generative adversarial networks (GANs) [8] are mostly applied to the inpaiting models. Most of these methods can generate meaningful missing areas, but there are also cases such as blurring, unclear edges, and lack of details. To alleviate these problems, Nazeri et al. [9] proposed to predict the edges of the missing contents before completing the image. A well-trained edge generator depicts the edges in the missing area as a reference for the following inpainting task. Their method exceed many of the most advanced ones with clearer edges and richer details filled in the missing areas. Our image outpainting work is also inspired by this painting process of edge first and then color. In line with [9], we infer the edges of the content before coloring it. However, the edge prediction model in [9] sometimes can not accurately depict the edges of large missing portions, or when the texture of the image is dense. We investigate a comparatively effective focal loss for edge prediction since edge is a sparse information. And we add a refinement phase in which the discriminator works in a coarse-to-fine fashion with a decreased effective patch size.
Our model is based on generative adversarial networks and consists of three modules: edge prediction module, image outpaining module, and refinement module. The goal of edge prediction module is to infer edges of possible contents outside the border of an input image. Combined with the inferred edge information, the image outpainting module adds color and texture to paint outside the image border. In the refinement module, we re-extract edges of the outpainted image as a new condition and refine the outpainted image to be closer to the ground truth. The three steps correspond to the procedures of painting. Several outpainting results are shown in Fig. 1.

Outpainting results obtained by our algorithm. As shown in each line: (a) input image to be expanded. (b) extended edge map. (The region available in the center is calculated by Canny edge detector; whereas the regions on the left and the right are hallucinated through our edge generator network.) (c) output result after outpaining and refinement.
Our main contributions are summarized as follows:
First, we introduce the hallucinated edge information to help solve the computer vision problem of image outpainting, which has received little attention. With the help of edge information, the outpainting result has more detailed information, and the boundary between adjacent objects become clearer.
Second, since the edge information is very sparse, we use a more effective focal loss [10] to train the edge prediction network. Meanwhile, we apply the recent spectral normalization [11] to architecture to make the training process more stable. In addition, we take the idea of image reconstruction by adding an optimization stage with a patch decreased discriminator, and obtain a better outpainting result in a coarse-to-fine fashion.
Third, we expand the image arbitrarily by a recursive outpainting method and obtain visually realistic results. The experiments show that our method performs better than other methods on multiple datasets, especially when recursive outpainting.
As one of the first attempts, Wang et al. [12] proposed a data-driven approach with graph matching to address image outpainting. Although it can achieve plausible results, it largely relies on the external library images for reference. Similar to the diffusion-based and patch-based inpainting methods, it compares the compatibility between low-level image features, and may lead to the semantic inconsistency. In addition, we would like to solve this problem through deep learning methods.
With a series of different encoder-decoder structures and adversarial training methods, deep learning technology has been widely used in image inpainting. Context encoder [13] completes images with a rectangular missing area in the center. To optimize context encoder, Iizuka et al. [14] added several dilated convolution layers [15] to enlarge the receptive field of the filters, and introduced a newly added local discriminator to achieve visually credible results. To the best of our knowledge, Sabini et al. [40] first proposed and studied the problem of image outpainting based on the adversarially training architecture of [14]. Liu et al. [16] adopted partial convolutions in conjunction with perceptual loss and style loss. The partial convolutions filter the valid pixels in the original image by masking the convolution operation in each layer. Computed by a pre-trained VGG network [17], perceptual loss and style loss proposed by Gatys et al. [18] are used to minimize the feature difference between the output image and the ground truth. Contextual attention [19] generates a rough estimate of the missing area in the first stage, and in the second stage the refinement network sharpens the result by replacing the patches in the roughly estimated area with the most similar ones from the background.
Recently, a group of image inpainting algorithms achieved state-of-the-art results by referring to the predicted edge or segmentation information. Free-form [20] inpainting utilizes hand-drawn sketches to guide the inpainting process. Nazeri et al. [9] proposed the EdgeConnect, which contains an edge generator and an image completion network. The edge generator infers the edges in the missing area, and the image completion network uses the hallucinated edges as a priori to fill in the missing regions. Song et al. [21] proposed to predict the segmentation labels in the missing areas first, then complete the image with reference to the segmentation. Xiong et al. [22] introduced a foreground-aware inpainting method, which is very similar to [9]. It predicts contour of the foreground rather than detailed edges of the whole picture. In addition to inpainting, You et al. [23] proposed to reconstruct high-fidelity images from sparse edge and color information. For synthesizing photo-realistic images from semantic label maps, Wang et al. [24] showed that when edge information is added, boundaries between adjacent objects become sharper.
Approach
As shown in Fig. 2, our progressive outpainting architecture consists of three phases: Edge prediction phase, Image outpaining phase and Refinement phase. In edge prediction phase, mask, masked edge map, and masked graysale image are the inputs of generator to predict the full edge map. In image outpaining phase, predicted edge map and masked color image are passed to generator to perform the outpainting task. In the last refinement phase, the outpainted image and its edge map re-extracted with Canny are input into generator to further improve the outpainting quality.
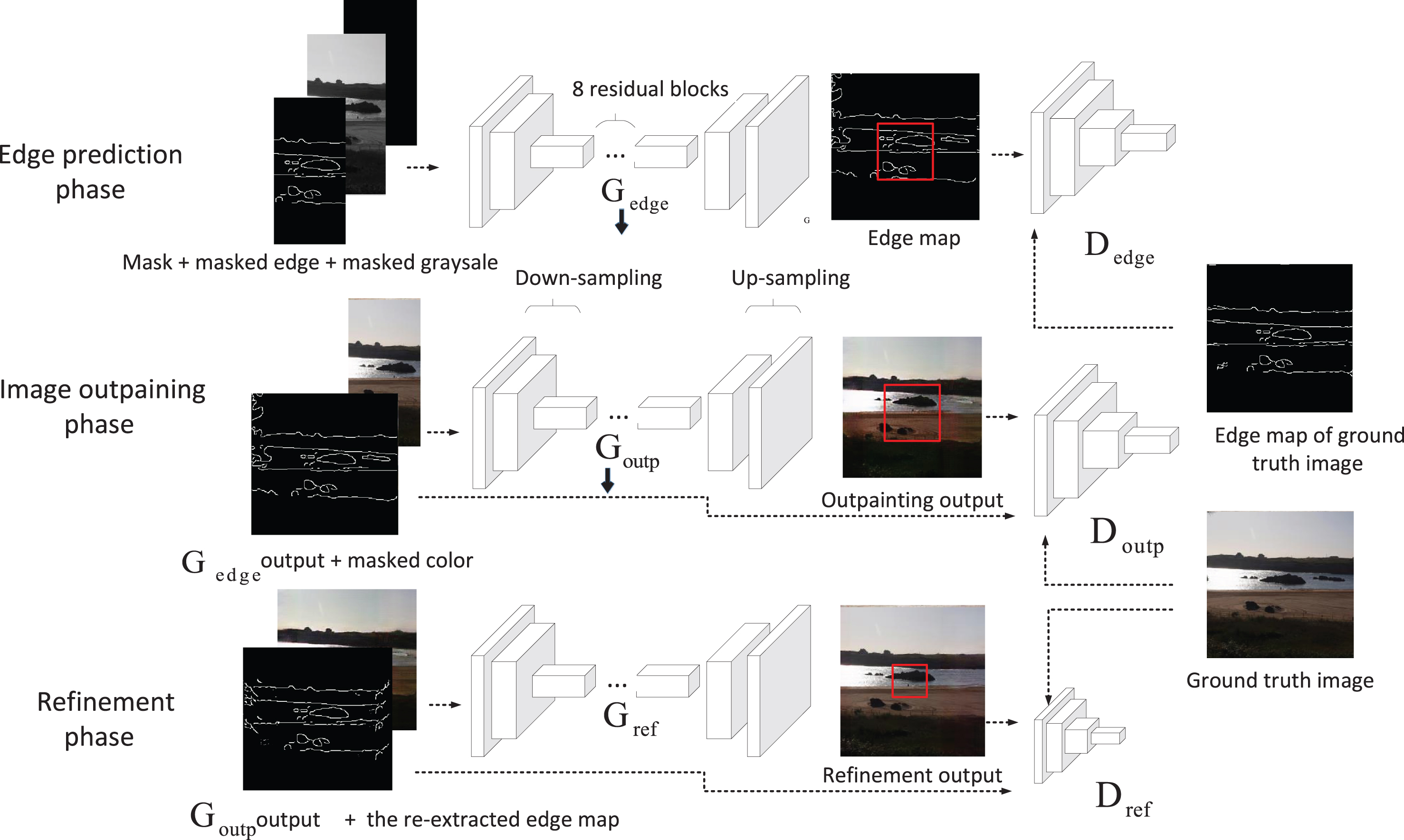
Network architecture of our proposed method. It consists of edge prediction phase, image outpaining phase and refinement phase. Each stage contains a generator and a discriminator respectively. Compared with the first two phases, the effective patch size of the discriminator decreases in the third phase (marked with red rectangles on the output images for illustration).
Edge is an important reference information for image outpainting. We choose Canny [25] algorithm to generate the one-pixel wide image edges (1 represents edge, 0 represents non-edge), instead of dense edge information extracted by HED [26]. Compared with HED, Canny is more robust and has been effectively applied in image reconstruction and inpainting. Reference to [9], we set the parameter σ = 2 to control the amount of edge information extracted from an image, because too many or too few edges both affect the quality of the generated images. We use the following pipeline for training. The given training image I
gt
is transformed into a grayscale image I
gray
with which Canny extracts the edges. We define a mask M to mask out the central regions of the grayscale image I
gray
and the edge map C
gt
:
For many image generation problems, minimizing L1 or L2 distance in pixel space is used as an important means of forcing the output to approach the target. However, this is not very effective for edge maps C
pred
and C
gt
because the edges in them are very sparse. For the potential imbalance problem, we cannot determine the appropriate weights for each pixel. Therefore, we seek solutions from the idea of considering whether each pixel in the image is an edge pixel or not. For the target edge map C
gt
extracted by Candy and the generated edge map C
pred
, we calculate their binary cross-entropy between each pixel pair. Then, a focal loss [10] is used to balance the influence of pixels in the image. Since edges are sparse, edge pixels are assigned a higher weight.
C
pred
and C
gt
are fed into the discriminator, which checks whether the edge map is real. In order to maintain a more stable training process, we apply the recent spectral normalization [11, 28] to both generator and discriminator. As shown below, we use the hinge loss to train generator and discriminator respectively, σ denotes the ReLU function.
For the total loss of edge prediction phase:
The generator of image outpainting network takes the masked color image
The outpainting network is trained by a joint loss, including L1 loss, perceptual loss, and adversarial loss. Like the edge prediction part, we use hinge loss as the adversarial loss. The difference is that in addition to the predicted image I
pred
or the ground truth image I
gt
, we also input the combined edge map C
comp
to the discriminator. Then, the adversarial loss is defined as:
We introduce the commonly known perceptual loss [29], which includes feature loss L
feat
and style loss L
style
. L
feat
and L
style
are calculated by feature representation extracted from VGG-19 [17], which is pre-trained on ImageNet dataset [30]. Ψ
i
stands for the feature map of the i-th convolution layer. Convolution layers conv1-1, conv2-1, conv3-1, conv4-1, and conv5-1 are used for calculation. Feature loss encourages the predicted image I
pred
to be perceptually similar to the ground truth image I
gt
, it is defined as
Feature map Ψ
i
is actually a Gram matrix whose shape can be defined as C
i
× H
i
× W
i
. Style loss is calculated as
For the total loss of outpaining phase:
The refinement phase is inspired by [23], except for a decreased effective patch size of the discriminator, its network structure and overall loss calculation are exactly the same as outpainting phase. With a coarse-to-fine fashion from the discriminator, this phase outputs images with higher frequency details and more optimized color distribution. We extract the edges of an expanded image I comp = I gt ⊙ (1 - M) + I pred ⊙ M with Canny, and then input the expanded image and edge map into the refinement generator. It is very similar to reconstructing an image from both edge and color domains. We re-extract edges so that all edges (including the predicted areas) are from the Canny algorithm, and the input image is treated as a collection of colors.
Experiment
Problem description
With our image extension method, for the m × n size input image I s , a larger m × (n + 2k) size image I o will be output. Image I o is actually expanded on the left and right sides of image I s . The extended parts integrate well with the input, and the whole output image looks realistic in texture details and semantics. In the experiments, we mainly achieve image extension with m = 256, n = 128, and k = 64. Our experiments are separately carried out on images partitioned from datasets ImageNet [30] and Places2 [33]. In addition, the whole CMP Facade dataset [34] is also used since it consists of only 606 images in total. Before training, all images are resized to the same size of 256 × 256.
Network architecture
Generators
Each of these three stages follows a generative adversarial model, i.e. a generator/discriminator pair. The generator we used is similar to the one proposed by Johnson et al. [29], which has been effectively applied to image translation [35], style transfer and super-resolution [32, 36]. It consists of three convolution layers that down-sample the inputs, eight residual blocks [37] and three deconvolution layers that up-sample an image to the original size. In order to gain larger receptive fields, dilated convolutions [15] with a dilation rate of 2 are used in each residual layer. Except for the last layer, all layers are composed of Convolution-SpectralNorm-InstanceNorm-ReLu modules. The last layer varies according to the generator at each stage. In the generator of edge prediction stage, the last layer has a channel size of 1 with sigmoid activation; while in the two phases of image outpaining and refinement, it has a channel size of 3 with tanh activation.
We use c/r/d-k-n*n-s to denote the structure and type of each layer, where k represents the number of filters in each layer, n*n represents the size of the filters, and s represents the stride of filters. In addition, c/r/d denotes the type of each layer, where c represents the convolution layer, r represents the residual block, and d represents the deconvolution layer. Thus, the structure of the generators is represented as: c-64-7*7-1, c-128-4*4-2, c-256-4*4-2, r-256-3*3-1, r-256-3*3-1, r-256-3*3-1, r-256-3*3-1, r-256-3*3-1, r-256-3*3-1, r-256-3*3-1, r-256-3*3-1, d-128-4*4-2, d-64-4*4-2, d-1/3-7*7-1.
Discriminators
A PatchGAN [35, 38] (a 70*70 effective patch size for the first two phases while 36*36 for the refinement phase) is adopted as the Markovian discriminator for each stage, where all the layers are composed of Convolution-SpectralNorm-InstanceNorm-LeakyReLu modules. In the discriminator, the stride of the first three layers is 2, and that of the last two layers is 1. Thus, the structure of the discriminators is represented as: c-64-4*4-2, c-128-4*4-2, c-256-4*4-2, c-512-4*4-1, c-1-4*4-1.
Result
The training and testing calculations are implemented by PyTorch and accelerated with a GPU of NVIDIA GTX 1080 Ti. Algorithm Adam [39] is used to optimize our network during the training procedure. We start to train from the edge prediction network, and remove the discriminator until convergence. Then we jointly train the outpainting phase with the edge prediction generator until convergence. Finally, we remove the discriminator in the outpainting phase, and jointly train the refinement phase end-to-end with the generators from the first two phases until convergence. Our experiments and verifications are carried out on the datasets ImageNet, Places2 and CMP Facade respectively. We compare with current state-of-the-art methods qualitatively and quantitatively.
Qualitative comparisons
As far as we know, Sabini et al. [40] first proposed a adversarial training method based on [14] to hallucinate past image boundaries. Referring to the idea of EdgeConnect [9], we divide image generation into two parts: drawing edge and coloring. When edge information is well rendered, the model focuses primarily on coloring, and is liberated from the consideration of structure. The pre-generated edge map provides great convenience for subsequent coloring. Figure 3 compares our extension method with several state-of-the-art ones including EdgeConnect, Sabini’s, and PartialConv [16]. EdgeConnect and our method output extended images with more rational structure and richer details than other ones. Our model further improves the generation effect by optimizing the loss function and adding an refinement phase, which is reflected in the following quantitative comparison.

Qualitative comparison with the state-of-the-art methods.
Figure 4 shows the detailed comparison of our method and EdgeConnect in edge prediction and final outpainting output. In the first two lines, it’s obvious that our method can more reasonably predict the contours of the buildings and their windows. In the last two lines, it can be seen that our predictions for the contours of the figure’s arm and the riverside birds are more vivid. With a more efficient edge prediction, our outpainting outputs result in more reasonable and rich details than EdgeConnect.

Detailed comparison between our method and EdgeConnect: (a) input image to be expanded. (b) extended edge map by EdgeConnect. (c) outputing result by EdgeConnect. (d) extended edge map by our method. (e) outputing result by our method.
We evaluated the outpainting results using the following metrics: 1) mean L1 loss; 2) peak signal to noise ratio (PSNR); 3) structural similarity index (SSIM) [41]; and 4) Fréchet Inception Distance (FID) [42].
L1 loss, PSNR and SSIM regard the image as a collection of independent pixels, which may result in inaccurate perceptual judgment. Recent studies show that human perception evaluation of images can be measured with deep image features. With the pre-trained Inception-V3 [43] model, FID calculates the Wasserstein-2 distance between the features of the outpainted and ground truth images. It has been found to work surprisingly well as a perceptual similarity metric.
Table 1 shows the metric results on ImageNet, the comparison shows that our method outperforms other methods.
Comparison of L1 loss (lower better), PSNR (higher better), SSIM (higher better) and FID (lower better) on ImageNet dataset for reference
Comparison of L1 loss (lower better), PSNR (higher better), SSIM (higher better) and FID (lower better) on ImageNet dataset for reference
In Fig. 5, we show more outpainting results of our model separately trained on the datasets ImageNet, Places2 and CMP Facade.

Outpainting results of our model on the datasets ImageNet, Places2 and CMP Facade. As shown in each line: (a) ground truth image. (b) input image to be expanded. (c) extended edge map. (The region available in the center is calculated by Canny edge detector; whereas the regions on the left and the right are hallucinated through our edge generator network.) (d) output result after outpaining and refinement.
In order to get a much bigger image, we cut appropriate parts from the expanded output image and fed each part into the model recursively. After redundant information is removed, all the new outputs are integrated, in which way we can arbitrarily extrapolate outside an image by recursively enlarging it. As Fig. 6 shows, we extend the image width to 3 times of the input and 1.5 times of the ground truth. Although the successive iteration process may introduce more noise, the outpainting landscapes are still relatively visually realistic. Obviously, we can also flexibly add masks with different positions and sizes to achieve a variety of painting outside the image boxes.

With recursive outpainting, each right outpainted image is 3 times of the corresponding middle input and 1.5 times of the left ground truth.
In addition, we make a more comprehensive evaluation of the images based on visual quality by conducting a user survey. Specifically, we randomly select 30 images in the test dataset, then obtain the outpainting results of each method, and asked 20 users to choose the single best one. Finally, we collect 500 valid votes and count the number of times that each method is selected as the best by users, as shown in the Outpaint 1× column of Table 2. It turns out that our method is chosen the most, far more than other two methods without reference to edge information. Since EdgeConnect has achieved very good painting results and our idea is largely based on EdgeConnect, we only exceeds EdgeConnect to a relatively small extent.
User selection counts of each method
User selection counts of each method
Then for the outpainted images, we repeat the recursive outpainting process one and two times, expanding each new image’s width up to factors of 1.5 and 2. Meanwhile, we repeat the same selection process for each iteration. From the columns Outpaint 2× and Outpaint 3×, we notice that as the area to be extrapolated increases, our method greatly exceeds others including EdgeConnect.
Edge detection [25, 44–48] is to detect the pixels around which the gray level of other pixels has changed dramatically. We believe that different objects in one image cause this change, so these pixels can be treated as a set to mark the boundaries of different objects. In addition to Canny [25], we also use techniques Sobel [44] and Roberts [48] to detect edges for the outpainting process as comparisons. It has been stated that we utilize a comparatively effective focal loss for edge prediction in the first phase. However except Canny, other methods cannot be treated as binary masks (1 represents edge, 0 represents non-edge), we have to replace the focal loss with the L1 loss when using Sobel and Roberts as detectors. Figure 7 shows the outpainting comparisons of our model with different edge detections. And from the quantitative comparisons in Table 3, we can see our architecture with Canny edge detection performs better than the same architecture with other detection methods.

Outpainting comparisons of our model with different edge detections: (a) input image to be expanded. (b) extended edge map with Sobel edge detection and outpainting output. (c) extended edge map with Roberts edge detection and outpainting output. (d) extended edge map with Canny edge detection and outpainting output.
L1 loss (lower better), PSNR (higher better), SSIM (higher better) and FID (lower better) of our model with different edge detections
We proposed a method to achieve remarkable image outpainting gradually, which refers to the painting steps of edge first and color next. Our model consists of three phases: the first phase predicts edges of possible contents outside the image box; the second phase colors and draws details based on the predicted edge information; and the third phase re-extracts edges of the expanded image and further enhance the painted result through a new image reconstruction process. We adopt the focal loss in edge prediction phase to depict edge lines more accurately and utilize variable Markovian discriminators to paint in a coarse-to-fine fashion. Comparison with other painting methods shows that our method is superior. In addition, we study the recursive outpainting as a method of arbitrarily enlarging an image. Although more noise will be mixed in with continuous iterations, the recursively outpainted result remains relatively visually realistic. Referring to the work of high resolution image synthesis and semantic manipulation, we plan to investigate editable and high-resolution image outpainting in the future.
Acknowledgment
This work is supported by National Key Research and Development Plan of China (2017YFF0211801), and the Opening Project of Beijing Key Laboratory of Internet Culture and Digital Dissemination Research.