
Abstract
Failure mode and effect analysis is a powerful risk analysis tool in engineering management. When properly conducted, FMEA can make a huge contribution to reduce costs. The traditional FMEA ranks the failure modes on the basis of Risk Priority Number, which is defined as the multiplication of three risk factors. However, this method has always been criticized for it can’t handle the situation where the information given is uncertain or ambiguous. In order to extend the application of FMEA under the fuzzy environment, in this paper, we proposed a novel risk assessment model known as probabilistic linguistic ELECTRE II method to rank failure modes based on FMEA. To realize this goal, probabilistic linguistic term sets (PLTSs) that consider both the hesitant information and probabilistic information are introduced to depict decision maker’s cognitive information. To better use the PLTSs in the decision-making process, some important information measures are defined, and a method to obtain the combined weight based on entropy weight of PLTSs is also proposed. Subsequently, we establish a score-deviation based PLTS-ELECTRE II model to study FMEA as a multi-criteria group decision-making problem. Finally, we successfully apply this model in a nuclear reheat valve system and the effectiveness of the proposed method is verified by sensitivity analysis and comparative analysis.
Keywords
Introduction
Failure Mode and Effect Analysis (FMEA) is an engineering technique used to define, identify, and eliminate known and/or potential failures, problems, errors, and so on [1, 2]. It’s a safe and specialized tool that has played an important role in numerous professional fields, such as reliable management [3], quality management [4], risk management [5] and so on. When properly performed, FMEA can make a huge contribution to reduce costs. To conduct an FMEA, a cross-functional team of decision-makers (DMs) must be established initially. As brainstorming or some other analytical method (such as AHP) applied, the team determine all possible FMs, and investigate the consequence of component failing through a specified FM. Several risk factors of FMs are taken into account: the probability of occurrence (O), the severity of the failure (S) and the probability of not detecting the failure (D). Certain values are given by DMs to evaluate the weight of risk factors and the performance of FM. After these preparations, the Risk Priority Number (RPN), which is calculated by multiplying the values of risk factors is introduced to determine the risk prioritization of all FMs. However, limitations and shortcomings are obvious and summarized as follows: (i) It is hard for DMs to give crisp numbers to determine the value of risk factors when FMs are evaluated in a complex system. (ii) Experts evaluate the relative performance of criteria by using their experience and professional knowledge, which presents the challenge of scientificity and objectivity in weight determination. (iii) The RPN calculating function is always being doubted for lacking complete scientific explanation about its derivation. Therefore, it is necessary to improve the traditional FMEA method, expand the application of FMEA in fuzzy environment, and make it more scientific and practical.
As FMEA can be treated as a multi-criteria decision making (MCDM) problem, many researchers use MCDM techniques corporated with fuzzy theory to determine the risk priority of FMs [6]. Carpitella et al. [7] established an FTOPSIS-based approach to prioritize FMs in street cleaning vehicles. Mohsen and Fereshteh [8] proposed an extended VIKOR method with Z-number to evaluate the risk of potential FMs in Geothermal Power Plant. Hajiagha et al. [9] solved a real-world problem of ranking causes of delay in Tehran metro system by VIKOR method, where the uncertainty is captured by Fuzzy Belief Structures. Wang et al. [10] proposed a new FMEA model that integrates COPRAS and ANP methods to rank the risk of hospital service FMs under interval-valued intuitionistic fuzzy context. Huang et al. [11] employed an improved TODIM method with linguistic distribution assessments to determine the risk priority of failure modes in a grinding wheel system. Certa et al. [12] proposed an ELECTRE Tri-based approach for the classification of FMs. The literature review reveals the following research gaps. First, although there are many kinds of research on FMEA under the fuzzy environment, these studies only consider one aspect of uncertain information, and seldom consider the hesitant information and probability information provided by DMs at the same time. Second, though the outranking method is an efficient MCDM technique to determine which FM is preferable, incomparable or indifferent [13], there is a limited study to extend the outranking method on FMEA under complex fuzzy environment.
In practical FMEA problem, due to its complexity and uncertainty, DMs like to express their opinions with linguistic terms. However, due to lack of sufficient relevant knowledge or different professional background, DMs may not able to give accurate opinions but hesitate between different linguistic terms. Rodríguez et al. [14, 15] proposed the concept of hesitant fuzzy linguistic term sets (HFLTSs), which is able to capture the hesitate information of DMs. However, the HFLTSs unable to describe the probability information in the process of opinion aggregation, and the probabilistic linguistic term set is suitable to solve this problem. In addition, compared with other outranking methods, the ELECTRE II method [16] is one of the best known and most widely used ranking method, it ranks the alternative from the best option to the worst option, which is especially suitable for sorting the risk of FMs.
Based on the above discussion, in this paper, we propose a novel FMEA model, extending the ELECTRE II method under a probabilistic linguistic environment to analyses the risk prioritization in FMEA problem. The innovations and contributions of this paper are summarized as follows:
(1) We employe PLTSs, which can avoid information loss or distortion, depict both the hesitate information and probability information given by DMs in FMEA problem. It is more flexible for DMs to express their opinions in linguistic terms.
(2) To better use the PLTSs in the decision-making process, we defined some important measures for PLTSs, and a method to obtain the combined weight based on entropy weight of PLTSs is also been proposed.
(3) We establish a score-deviation based PLTS-ELECTRE II model to study FMEA as a multi-criteria group decision-making problem under a complex fuzzy environment.
(4) We successfully apply this model in a nuclear reheat valve system and the effectiveness of the proposed method is verified by sensitivity analysis and comparative analysis.
The remainder of this paper is organized as follows: In section 2, some basic definitions and operation laws related to PLTS are introduced. New measures for PLTS are defined in section 3, containing new ordered relationships, hybrid PLTS-Hellinger distance measure and entropy weight for PLTSs. In section 4, a novel risk priority model of extended ELECTRE II method based on PLTS for FMEA is proposed. In section 5, a case study is presented. Section 6 presents a sensitivity analysis and comparative analysis. And section 7 makes a summary.
Preliminaries
In this section, some basic concepts and definitions are introduced. They will be utilized in the later analysis.
Linguistic term set and hesitant fuzzy linguistic term set
Xu [17, 18] proposed a finite and totally ordered discrete linguistic term set (LTS) S ={ s t |t = - τ, . . . -1, 0, 1, . . . τ }, where the s t expresses a possible value for a linguistic variable, such as “very low”, “high”. Usually, it is required that: (1) The set is ordered: s α > s β if and only if α > β; (2) there is a negation operator: neg (s α ) = s-α.
For the convenience of operation, we need to transform the linguistic term to a definite semantic value [21]. A simple and commonly used transformation method is to divide the evaluation scale of the linguistic information on average.
In addition, the membership degree γ that expresses the equivalent information to the linguistic variable s
t
is obtained with the following function g-1:
Pang [24] defined PLTS by adding probabilistic information to HFLTS.
If the probabilities of all possible values in a PLTS can’t be explicitly provided, then these values are considered to have the same probability. In this case, PLTS degenerate to HFLE [25]. We assume that each value in HFLE has the same probability, then generate HFLE to PLTS by:
In this case, the sum of probabilities of all values in a PLTS equals 1.
In real-world problems, probabilistic information exists everywhere, it contains important meaning and can’t be ignored. In the example above, h s (x1) ={ s-2, s0, s1 } means a DM is not sure to give his/her assessment by which linguistic term from these three elements. And L1 (p) ={ s-2 (1/3) , s0 (1/3) , s1 (1/3) } collects the very probability of each value being selected by this DM as his/her assessment. Compared to HFLE, PLTS not only collects various aspects of probabilistic information and show it in an explicit style but also keeps the original linguistic information without any distortion.
Aggregation operator for PLTSs is provided in Ref [24]:
Hellinger distance is used to measure the difference between two continuous or discrete probability distributions. Compared with other probability distance measures, such as Kullback-Leibler (KL) divergence, the advantages of Hellinger distance are that the HD (f, g) satisfies the property of symmetry and bounded, that is 0 ⩽ HD (f, g) ⩽1.
Since the concept of PLTS is defined, a lot of work has been done to study its characteristics [28–35]. Gou [36] redefined some more logical operational laws for PLTSs based on equivalent transformation functions. Wu [37] presented new operations of PLTSs based on the adjusted PLTSs and the semantics of linguistic terms. Bai [38] proposed a possibility degree formula for PLTSs comparison. Liu [39] proposed the general operational laws for PLTSs by Archimedean t-conorm and t-norm and Linguistic scale functions. To better use the PLTSs in the FMEA process, we have improved the previous work and put forward our own method. We use the linguistic transformation function g to redefine the score and deviation degree of PLTS, making the comparison result more accurate and clear. By merging the Hamming distance and Hellinger distance, we define a hybrid distance for PLTSs, which calculate the difference of probability information and hesitation information separately. A method to obtain combined weight based on entropy weight of PLTSs is also proposed. The adjusted weight will make the ranking result more accurate.
A new ordered relationship for PLTSs
Pang [24] defined the score and deviation degree of L (p) with linguistic variables, we extend his definition by introducing function g. In this way, the calculation result of the original function is quantified and a crisp number is obtained.
Given two PLTSs L1 (p) and L2 (p): If E (L1 (p)) > E (L2 (p)), then L1 (p)> L2 (p) ; If E (L1 (p)) < E (L2 (p)), then L1 (p)< L2 (p) ; If E (L1 (p)) = E (L2 (p)), then If σ (L1 (p)) > σ (L2 (p)), then L1 (p)< L2 (p) ; If σ (L1 (p)) < σ (L2 (p)), then L1 (p)> L2 (p) ; If σ (L1 (p)) = σ (L2 (p)), then L1 (p) = L2 (p).
A PLTS is composed of several linguistic terms and their respective probability. Therefore, the distance between any two PLTSs should contain both hesitant information and probabilistic information. In the following section, we will introduce two hybrid distance measure for any two PLTSs.
Let S ={ s t |t = - τ, . . . -1, 0, 1, . . . τ }, L a (p) and L b (p) be any two arbitrary PLTSs. The hybrid Hamming-Hellinger distance between L a (p) and L b (p) is defined as:
The distance satisfies: 0 ⩽ d (L
a
(p) , L
b
(p)) ⩽1 d (L
a
(p) , L
b
(p)) =0 if and only if L
a
(p) = L
b
(p) d (L
a
(p) , L
b
(p)) = d (L
b
(p) , L
a
(p))
Since If d (L
a
(p) , L
b
(p)) =0, then Since
The parameter θ indicates the relative importance of hesitant information and probabilistic information in calculating the distance of PLTSs. # l = max(l a , l b ), l a and l b represent the number of elements contained by L a (p) and L b (p) respectively. The shorter one should be extended by adding the same value several times until it has the same length as the longer one. Here, we set the adding value to be the one that has the highest probability in the shorter PLTS. g function is applied to translate the linguistic variables to membership function. sρ(i) (i = 1, 2, . . . # l) is the i - th smallest linguistic term value in L (p). And for the linguistic terms that only exist in one PLTS, we set their probabilities equal 0 in the other PLTS.
Note if θ = 1, the measure degenerates to the distance measure of HFLEs, which ignores the probabilistic information; if θ = 0, the measure merely considers the probability distribution information of linguistic terms, which ignores the hesitant information.
Entropy [40, 41] is a measure of uncertainty in the information. In this section, it was used to determine the objective weight of evaluation factors where the assessments are given by PLTSs.
Let S ={ s t |t = - τ, . . . -1, 0, 1, . . . τ }, and X = [{ L(k) (p(k)) ij |k = 1, 2, . . . , # L (p) }] m×n (i = 1, 2 . . . m, j = 1, 2 . . . n), where m is the number of alternatives, and n is the number of criteria. Then normalize the original data by:
When the j - th criterion is a benefit criterion, or
When j - th criterion is a cost criterion.
Then the entropy measure for X is formed as:
Where
(ln 0 replaced by 0.)
The deviation degree and weight is calculated as:
Suppose the subjective weight is
In this part, an extended ELECTRE II method is proposed for ranking FMs. In Ref. [42] a hesitant fuzzy ELECTRE II is proposed to solve an MCDM problem under a hesitant fuzzy environment by means of score function and deviation function. Based on this, an extended ELECTRE II method was used to deal with FMEA problems, which considering both subjective weight and objective weight of risk factors. The assessments are taken the form of HFLTSs and the probabilistic information is also considered. Figure 1 shows the flow chart of the proposed approach.
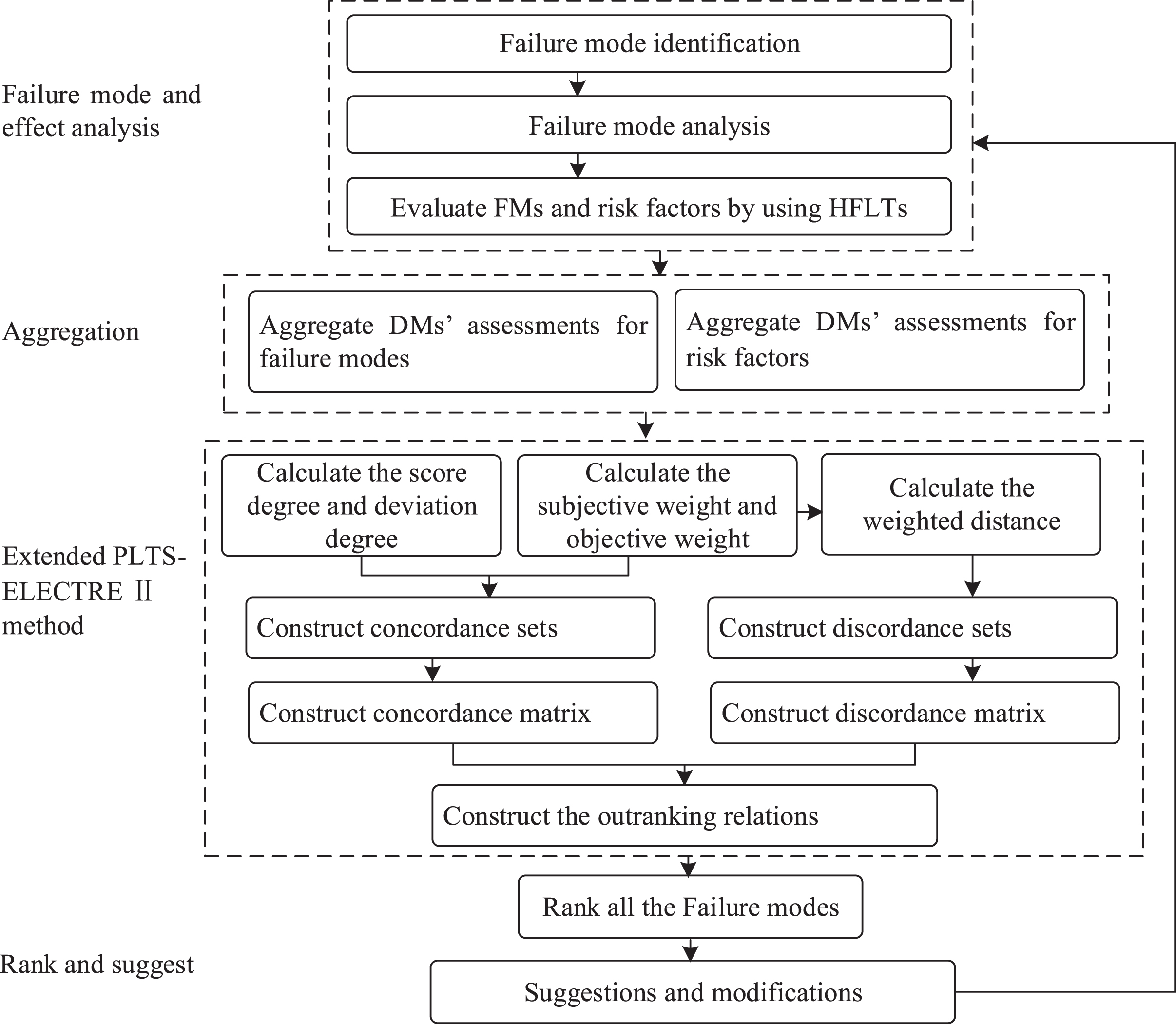
Flow chart of the proposed approach.
Let FM = { A1, A2, . . . . , A
u
} (u ⩾ 2) be a finite set of u FMs, RF = (r1, r2, . . . r
v
) be a finite set of v risk factors, TM = (TM1, TM2, . . . , TM
l
) be a team consisted of l experts, each TM is assigned a weight vector λ
i
, where λ
i
> 0 and
Suppose the evaluation matrix M
k
for all the FMs and the evaluation vector
The relative attitude weight vector ω = (ω C , ωC′, ωC″, ω D , ωD′, ωD″, ω J = ) of different types of hesitant fuzzy concordance, discordance and indifferent sets which depends on the DMs attitude is identified.
In algorithmic form, the application of score-deviation based PLTS-ELECTRE II involves the following steps:
i. Calculate the score degree E (L (P) ij ) and deviation degree σ (L (P) ij ) of the evaluation of each alternative with respect to each different criterion by using Eq. (9)-(10).
ii. Construct the probabilistic hesitant fuzzy concordance, discordance and indifferent set by the following rules:
(1) The probabilistic hesitant fuzzy strong concordance set J C kl :
(4) The probabilistic hesitant fuzzy strong discordance set J D kl :
(7) The probabilistic hesitant fuzzy indifferent set
Where
iii. Calculate the probabilistic hesitant fuzzy concordance index c kl (k, l = 1, 2, . . , m ; k ≠ l) as:
iv. Construct the concordance matrix by the indices c
kl
as:
v. Calculate the weighted distance between any two alternatives with respect to each criterion by using Eq. (11).
vi. Calculate the probabilistic hesitant fuzzy discordance index d kl (k, l = 1, 2, . . , m ; k ≠ l) as:
vii. Construct the discordance matrix by the indices d
kl
as:
Let c*, c0, c- be three decreasing levels of concordance satisfying 0 < c- < c0 < c* < 1, d0, d* be two increasing levels of discordance satisfying 0 < d0 < d* < 1. Defined two types of outranking relationships: a strong relationship A k S F A L and a weak relationship A k S f A L . Comparing to A k S f A L , A k S F A L represents that the judgment of A k is at least as risky as A l that yield a more refined and stricter ranking procedure.
The relationship A
k
S
F
A
L
is defined if any or both of the following set of conditions (a) and (b) hold:
The relationship A
k
S
f
A
L
is defined when the conditions (c) hold:
The ranking procedures consist of a direct ranking ν′ (x), a reverse ranking ν″ (x) and a median order
In this part, a case study of a reheat valve system in a nuclear steam turbine comes from [44] is adopted to demonstrate how to make use of the proposed FMEA approach.
Description
Operating under complex conditions, the nuclear reheat valve system is essential to the reliability of the whole nuclear power plant. The valve must be fully opened and closed timely when transporting radioactive medium with high temperatures and pressure. Any incorrect operation may cause serious consequences. To identify known and potential risk issues, FMEA was carried out to enhance the safety and reliability of processes in the nuclear reheat valve system. When implementing FMEA, it is necessary to form a team, which is composed of several individuals with multi-disciplinary and multi-functional backgrounds. Then, divide the valve system into various components. Through brainstorming, the possible failure modes of the analysis components are listed, and the influence and detection methods of these failure modes are also been discussed. After this preparation, eight FMs of nuclear reheat valve system were obtained, shown in Table 1.
The causes, effects, and detection methods of nuclear reheat valve system FMs
The causes, effects, and detection methods of nuclear reheat valve system FMs
Note: part of the FMs is listed in Table 1 due to space limitations and privacy regulations.
In order to analyses the risk priority of these eight FMs, a cross-functional team consisting of 4 experts is established, take S, O, and D as risk factors, and use seven-grade linguistic rating variables s ∈ S to evaluate each FM with respect to each risk factor, shown in Table 2. Meanwhile, five-grade linguistic weighting variables u ∈ U to assess the importance of each risk factor, as shown in Table 3. Each expert is assigned an importance weight λ = (0.23, 0.26, 0.25, 0.26), and experts assign the relative attitude weights of strong, medium and weak probabilistic hesitant fuzzy concordance, discordance, and indifferent sets as: ω = (ω C , ωC′, ωC″, ω D , ωD′, ωD″, ω J = ) = (1, 0.9, 0.8, 1, 0.9, 0.8, 0.7).
In order to analyses the risk priority of these eight FMs, a cross-functional team consisting of 4 experts is established, take S, O, and D as risk factors, and use seven-grade linguistic rating variables s ∈ S to evaluate each FM with respect to each risk factor, shown in Table 2. Meanwhile, five-grade linguistic weighting variables u ∈ U to assess the importance of each risk factor, as shown in Table 3. Each expert is assigned an importance weight λ = (0.23, 0.26, 0.25, 0.26), and experts assign the relative attitude weights of strong, medium and weak probabilistic hesitant fuzzy concordance, discordance, and indifferent sets as: ω = (ω C , ωC′, ωC″, ω D , ωD′, ωD″, ω J = ) = (1, 0.9, 0.8, 1, 0.9, 0.8, 0.7).
Evaluation of the FMs
Assessments on risk factors weights
The two linguistic term sets are described as:
In the following section, we use the proposed approach to construct and exploit the outrank relationships of all the identified FMs.
Weighted distances respect to risk factor S
Weighted distances respect to risk factor S
Outranking relations
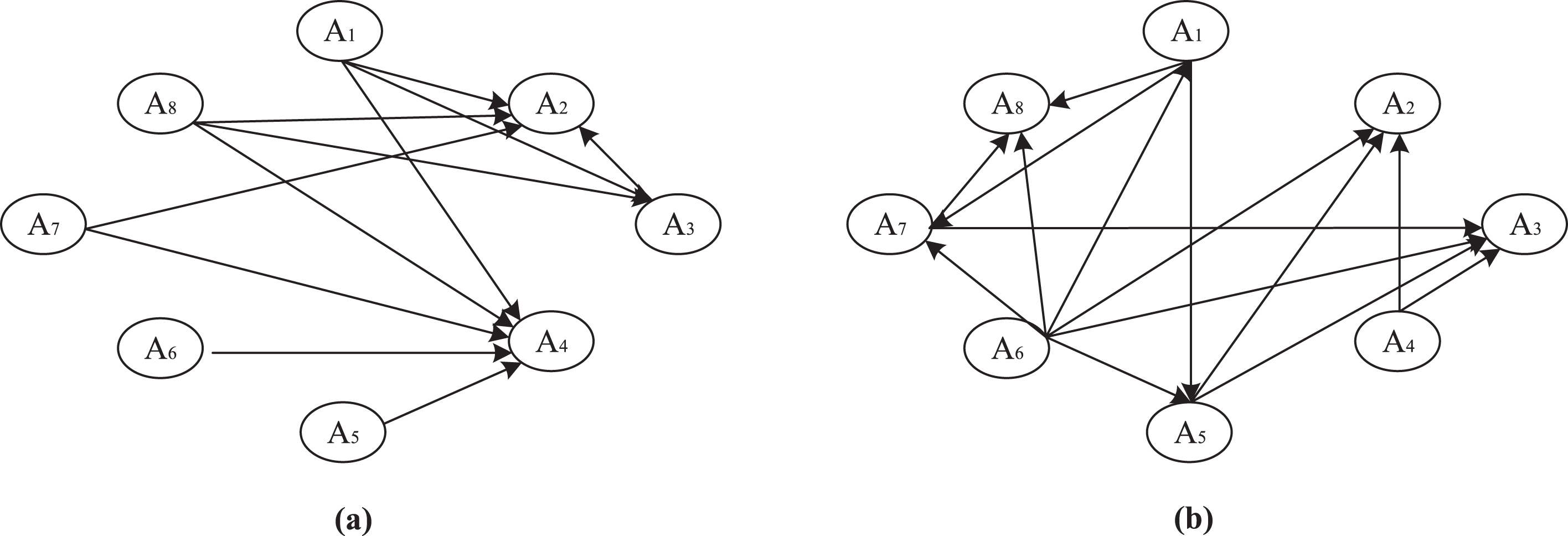
Strong (a) and weak (b) outranking graphs for FMs.
The ranking result of the FMs
So, the final ranking of the eight FMs is: A6 ≻ A1 ≻ A7 ≻ A5 ≻ A8 ≻ A4 ≻ A3 ≻ A2.
Note that “≻” means the risk of A i is greater than A j , and “∼” means the risk of A i is indifferent to A j .
In this section, sensitivity analysis and comparative analysis have been done to verify the validity of the proposed approach.
Sensitivity analysis
We perform a sensitivity analysis by changing parameter θ. θ indicates the different attitudes of DMs to the importance of probabilistic information and hesitant information. The hybrid Hamming-Hellinger weighted distances changed as θ varying from 0 to 1. Figure 3 shows the graphs of outranking relations when (c-, c0, c*) = (0 . 5, 0 . 6, 0 . 75, (d0, d*) = (0 . 5, 0 . 9. The final ranking results are presented in Table 7.
The final ranking results
The final ranking results
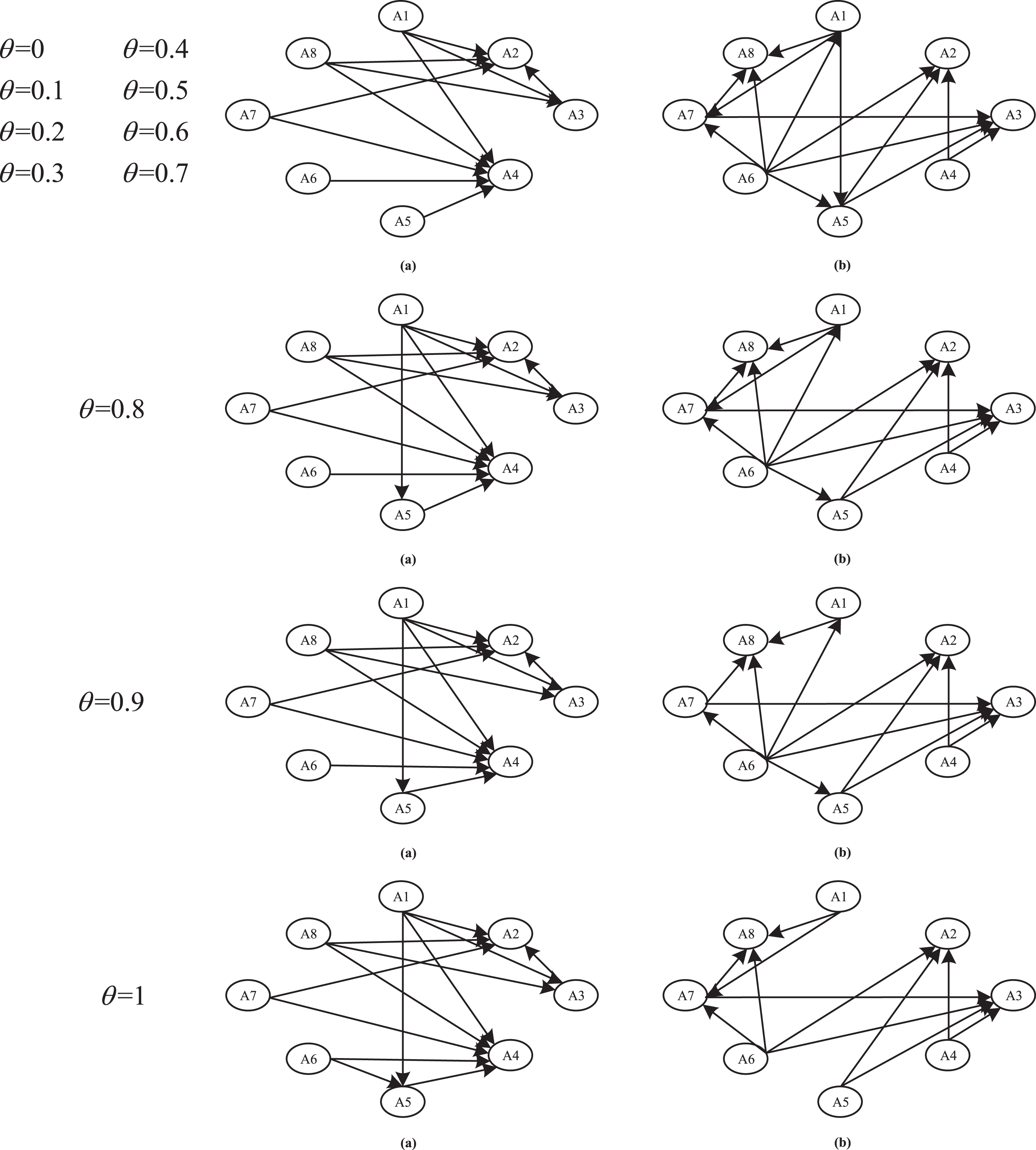
Strong (a) and weak (b) outranking graphs with the different value of θ.
From Fig. 3, we note that when θ between 0 and 0.7, the strong and weak outranking relations stay the same. As θ keeps increasing to 0.8, the weak relation that “A1S f A5” changes to strong relation that “A1S F A5”. When θ = 0 . 9, The previously accepted relation of “A1S f A7” is rejected. And the relation “A1S f A6” is also rejected when θ = 1. In Table 7, we can see that the ranking order get slight changes when θ ⩾ 0 . 9. These changes are not critical enough to influence the ranking order of all the FMs.
The HF-ELECTRE II method introduced in Ref. [45] only considers the hesitant information and the subjective weight of the criteria. In order to illustrate the advancement of the PLTS-ELECTRE II method, we investigate the same numerical example used in Ref. [45]. Moreover, some probabilistic information is added to make a comparison between these two methods.
Suppose that the weight vector of the criteria is w = (0 . 2 0 . 2 0 . 15 0 . 1 0 . 1 0 . 15 0 . 1) T , three DMs with the same importance, relative attitude weights of strong, medium and weak probabilistic hesitant fuzzy concordance, discordance, and indifferent sets are assigned as: ω = (ω C , ωC′, ωC″, ω D , ωD′, ωD″, ω J = ) = (1, 0.9, 0.8, 1, 0.9, 0.8, 0.7), θ is determined as 0.5, the probabilistic information is given and the decision matrix is presented in Table 8.
Probabilistic hesitant fuzzy decision matrix for the numerical example
Probabilistic hesitant fuzzy decision matrix for the numerical example
Rank these five alternatives in the framework of the proposed PLTS-ELECTRE II method, the calculation results are shown as bellows:
The objective weight: w o = (0 . 0563 0 . 0807 0 . 2150 0 . 0723 0 . 0847 0 . 3506 0 . 1404) T
The combined weight: w c = (0 . 0794 0 . 1137 0 . 2271 0 . 0509 0 . 0596 0 . 3704 0 . 0989) T .
When (c-, c0, c*) = (0 . 5, 0 . 6, 0 . 75, (d0, d*) = (0 . 5 0 . 9, the outranking relations are presented in Table 9, and the outranking graphs are presented in Fig. 4:
The outranking relations for the numerical example
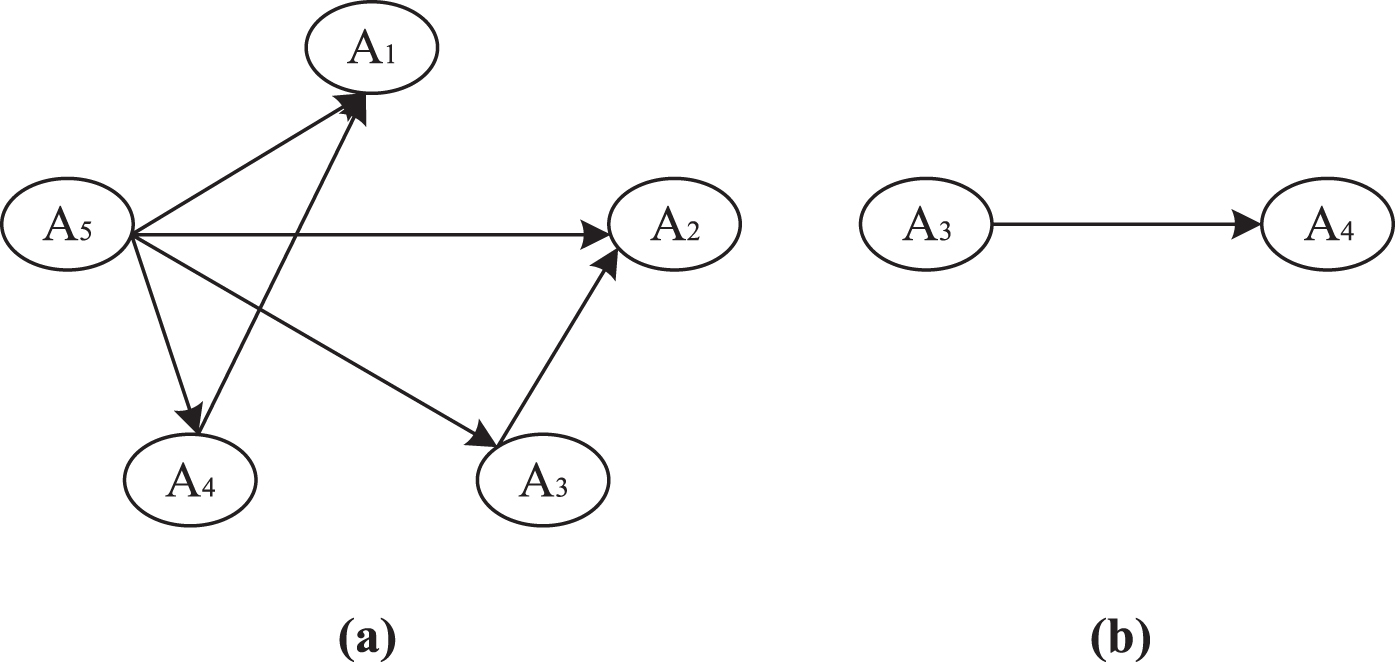
Strong (a) and weak (b) outranking graphs for the numerical example.
And the final ranking is: A5 ≻ A3 ≻ A4 ≻ A1 ∼ A2, this ranking order is different from A5 ≻ A3 ∼ A1 ≻ A4 ≻ A2 obtained by HF-ELECTRE II method. The advantages of our proposed approach are listed as following: Firstly, we use linguistic terms to assess the alternatives, which are more human-centered. It renders the assessment more explicit. Secondly, we combine the subjective weight and objective weight together, so the weight of the criteria is considered more systematically. This causes the result more accurate. And finally, In PLTS-ELECTRE II method, the importance of probabilistic information is reflected. Obviously, the proposed method takes into account more comprehensive information. Therefore, the results obtained are more convincing than the previous method.
FMEA is a powerful tool to deal with real-world engineering and management problems. When it is treated as an MCDM problem, the fuzzy set theory and outranking MCDM techniques can be applied to improve its effectiveness. In this paper, a suitable fuzzy set-PLTS which combine the hesitant information and probabilistic information together is applied to describe FMEA problem under a complex hesitant environment. An entropy weight which can measure the uncertainty of PLTSs, further determine the weight of criteria is proposed. Based on these discussions, a new FMEA model of score-deviation based PLTS-ELECTRE II is developed and has been successfully applied in a nuclear reheat valve system. The effectiveness of the proposed method has been verified by sensitivity and comparative analysis.
In further, more complex fuzzy environments will be considered in the FMEA problem [46–48]. In this paper, we suppose the risk factor is independent of each other. In fact, it does not conform to reality. Moreover, Linguistic term sets employed in this paper are suggested to be uniformly and symmetrically distributed, this also needs to be reconsidered by means of unbalanced linguistic term sets.
Disclosure statement
No potential conflict of interest was reported by the authors.
Footnotes
Acknowledgments
The authors are very grateful to the anonymous reviewers for their valuable comments and suggestions to help improve the overall quality of this paper. This work was supported by the National Natural Science Foundation of China under Grant No. 71871228.