
Abstract
During the last decade, ensemble clustering has been the subject of many researches in data mining. In ensemble clustering, several basic partitions are first generated and then a function is used for the clustering aggregation in order to create a final partition that is similar to all of the basic partitions as much as possible. Ensemble clustering has been proposed to enhance efficiency, strength, reliability, and stability of the clustering. A common slogan concerning the ensemble clustering techniques is that “the model combining several poorer models is better than a stronger model”. Here at this paper, an ensemble clustering method is proposed using the basic k-means clustering method as its base clustering algorithm. Also, this study could raise the diversity of consensus by adopting some measures. Although our clustering ensemble approach has the strengths of kmeans, such as its efficacy and low complexity, it lacks the drawbacks which the kmeans suffers from; such as its problem in detection of clusters that are not uniformly distributed or in the circular shape. In the empirical studies, we test the proposed ensemble clustering algorithm as well as the other up-to-date cluster ensembles on different data-sets. Based on the experimental results, our cluster ensemble method is stronger than the recent competitor cluster ensemble algorithms and is the most up-to-date clustering method available.
Introduction
According to some studies, as a task in the pattern detection [1, 2], statistical data analysis [3], machine learning [4, 5], optimization [6, 9], and data mining [10, 11] fields, clustering task has been regarded as a prominent issue [12, 16]. It is an important research direction in data mining. Actually, it has been regarded as a major task in the bioinformatics [17, 18], statistics, machine learning [19, 20], optimization [21, 22], data mining [23] and pattern recognition [24–27] communities [12].
However, there is no one clustering algorithm that can be efficiently applied to all situations. Therefore, such a variation in the clustering algorithms has been viewed more a challenge than a gift, because all of them have distinctive weaknesses and strengths; hence, no algorithm would be appropriate for each dataset. Actually, as one of the weak clustering algorithms, it is a fundamental clustering algorithm that involves in the consensus building [28–31], but not the only one [32, 33]. The global clustering algorithms have been regarded in the opposition of the local clustering algorithms such as k-means. Despite their acceptable functionality, they possess clear weaknesses like the increased time complexity (because they possibly require computation of the distance between each pair of the data objects). A number of these algorithms are the global k-means (gk-means) [34], density-based spatial clustering of the applications with noise (DBSCAN) [35], clustering by fast search and find of density peaks (CFSFDP) [36], CHAMELEON [37], and spectral clustering algorithms [38, 39]. Therefore, clustering ensemble has been proposed [40–42]. Indeed, ensemble as a general concept has been successfully used in many more applications [20].
Based on the studies, ensemble clustering is still regarded as a device and research field of an examined theory. In this regard, a review paper has been reported in [43] for different methods. Since accuracy in the clustering would not have a simple meaning like classification, another concept has been introduced for its assessment, stating that an appropriate (or an accurate) partition is the one with the highest similarity to the other partitions established on the certain data-set; in fact, a more reasonable partition refers to the partition with higher stability. Therefore, for a reason as the same as the one reported for the appropriateness of a different set of classifiers for the ensemble classification, a collection of the partitions could be regarded as a suitable ensemble, if its basic partitions are as diverse as possible. Actually, a collection or set of partitions should be generated via applying a
The problem of the recognition of the relatively accurate number of labels in the clustering task is the first one. Despite the classification problems, any real information would not be found about labels in clustering task.
The problem of the achievement of diverse partitions [45–47], which characterizes the entire data-set is the second one. In an ensemble, although numerous weak models would be combined as a strong learner, the more the base models cover weaknesses of each other, the better the ensemble would perform. This means that any partition in the ensemble should cover the remaining partitions weaknesses. Hence, it is necessary to provide multiple complementary partitions through the k-means clustering algorithms.
The problem to determine the level of matching between the clusters of two partitions is the third one [47]. In spite of the classifications wherein each label would be uniquely allocated to a predefined category, the labels, in the clustering task, readily present if any pair of the data objects are in a similar cluster or not and they would be meaningless in any other way. Actually, clusters with a similar label in 2 distinct partitions are meaningless comparatively. Hence, prior to any work in the ensemble clustering, label of the various partitions must be relabeled with regard to the correspondence. Additionally, even 2 clusters of a similar partition probably determine a real cluster.
The problem to combine the relabeled base partitions is the fourth one. A specific data objects possibly possesses dissimilar labels in the different partitions. Hence, determining a final label as ensemble vote known as the consensus label would be necessary. In the ensemble learning, although multiple poor learners are combined as a strong learner, the more effective the consensus label constructor (or consensus function), the better the ensemble learner would perform.
Therefore, the present research aims at resolving each sub-problem stated above via defining the valid local clusters. An intracluster similarity criterion would be applied for measuring similarities between those clusters. Transforming the problem into a weighted graph, the graph cut is applied on it to extract a partition.
Part 2 of the present research reviews the related studies and Part 3 deals with the introduced method. Moreover, Part 4 presents the experimental outputs and Part 5 concludes the research and discusses further research.
Related work
The first problem in clustering ensemble is known as the ensemble generation attempts for the generation of a series of the valid and different base partitions using many approaches. For instance, it is possible to generate the first problems using a random base clustering algorithm on a given data-set with changes in its inputs [48–50]. Moreover, it is possible to generate the ensemble using a distinct base clustering algorithm on the certain data-set [41, 52]. One of the other ways is creation of a series of the valid and diverse base partitions using a base clustering algorithm on different subspaces from the certain data-set [53–61]. Then, a series of the valid and distinctive base clustering results could be provided using the base cluster algorithm on different sub-sets that could be produced with replacement or without replacement through the given data-set [51, 62].
Researchers introduced a lot of solutions for solving the second problem; the first one is an approach with regard to the co-occurrence matrix (CoM). According to some studies, the approach is popular as the most traditional procedure [63–66]. One of the other approaches has been considered a graph cutting-based one. According to the approach, the problem of finding a consensus clustering would be initially become a graph partitioning problem. Afterwards, the final clusters would be achieved by the partitioning or graph cutting algorithms [40, 67–69]. In this regard, 4 graph-based ensemble clustering algorithms have been considered to be CSPA, MCLA, HBGF, and HGPA.
Some studies called the other approach the voting one [54, 70–72]. Therefore, a re-labeling should be initially performed. A near work [73] has been done where it also used the reliable clusters and then merged them through a second graph clustering algorithm. It suffers from the non-smoothness in its cluster-cluster similarity function. Also, its cluster-cluster similarity function has not any maximum bound value. It also ignored many important density measurements. All of the mentioned problems are solved here.
In researchers’ communities, the ensemble clustering methods are regarded as the ones that are able to find clusters with the arbitrary shapes [74–78]. Hence, a method for finding clusters with the arbitrarily-shaped clusters has been considered to the clustering ensemble. Therefore, it seems to be necessary to make a comparison between our new method with a number of methods like CHAMELEON [37, 79] as well as CURE [80]. In fact, a collection of the hierarchical clustering algorithms with the aim of the data clustering with the arbitrary shape utilized the advanced procedures, involving some parameters. CHAMELEON [37, 79] as well as CURE [80] are 2 examples of such clustering algorithms. The CURE clustering algorithm would take some sampled data-sets and partition them. Then, a pre-defined number of the distributed sample points would be selected in each partition. Afterwards, a single link clustering algorithm would be applied for merging the same clusters. As a result of the sampling randomness, CURE would be an instable clustering algorithm and the CHAMELEON clustering algorithm would initially transform the data-set into a k-nearest neighbors’ graph and divide it into m smaller sub-graphs with the graph partitioning technology. Next, the base clusters shown by the sub-graphs would be hierarchically clustered. Based on the experimental outputs in [37], the CHAMELEON algorithm would be more accurate than the DBSCAN and CURE algorithms.
Our contribution
This part presents definitions and the related symbols. Therefore, the ensemble clustering problem would be defined. Then, we present the introduced algorithm and finally analyze the algorithm.
Preliminary materials
Various distance/similarity criteria are found between 2 clusters. We defined a
Note that
If the dis
k
1k2 is greater than 2γ (i.e. the two clusters have no Overlapping Region (OR) denoted by OR
k
1k2), the similarity of them is defined based on Den
BtoU
k1k2; otherwise, it is computed according to a better density ratio, i.e. the density of the OR
k
1
k
2 to that of the UR
k
1
k
2. It means the Den
OtoU
k1k2 is used as similarity of them where Den
OtoU
k1k2 is computed by Equation (8).
Now, we define SIS between the 2 clusters
Now, consider a complete graph

Ensemble generation
A set of the base partitions would be established on the basis statement ’02’ of the algorithm depicted in Algorithm 1. According to this pseudo code, for each partition, a random integer number in interval
In addition, time complexity of kmeans method is O (|D:1|CI) where I is the number of cycles kmeans method iterates before its convergence. As k-means method functionality might be influenced by several variables, it is considered to be a poor learner. For instance, it has a great sensitivity to the initial cluster centers (i.e. initial seed points) [25, 26]. Thus, selecting diverse initial cluster centers frequently results in diverse partitions. Additionally, k-means method tends for finding the spherical clusters in the relatively smooth dimensions, which would not be appropriate for data-sets with other distributions. Hence, it has been tried for providing numerous partitions produced by kmeans method for creating an ensemble of acceptable partitions on the data-set via the distribution of diverse data rather than the use of a robust clustering algorithm.
As the kmeans method, i.e. base clusters’ generator in our algorithm depicted in Algorithm 1, has a time complexity of O (|D:1|IC), clusters generator section in our work, i.e. the statement ’02’ in our algorithm depicted in Algorithm 1, is in the worst case a member of O (|D:1|1.5IB) so that I is the number of cycles kmeans method iterates before its convergence and B refers to the quantity of the base produced partitions. To better understand, the pseudo code for generation of the ensemble in Algorithm 1 is
Graph transformation of ensemble
It is notable that the class labels indicated certain concepts in the supervised learning whereas the cluster labels represent just data group feature and thus could not be compared in the cluster analysis across various partitions. Hence, diverse clustering labels should be aligned in the ensemble clustering. Moreover, as kmeans clustering algorithm could just recognize the uniform and spherical clusters, some clusters in a unique partition could innately be one cluster. Consequently, it is crucial to analyze the relationships between the clusters using a between-cluster similarity measure.
Several studies in the field introduced a lot of criteria [37, 83–85] for the measurement of the similarity between clusters. For instance, distance between the farthest or closest data object of the 2 clusters in the chain clustering algorithm would be utilized to measure the cluster separation [84, 85]. On the one hand, these clusters have sensitivity to the noise as a result of their dependence on some objects. Therefore, in the center based clustering algorithms, the distance between the clusters’ centers measures the absence of correlation between these 2 clusters. Even though the measure has been regarded to be a computationally efficacious and robust measure for addressing noise, it could not show boundary between the two clusters.
Therefore, number of the similar objects generated by 2 clusters has been utilized for representing their similarities in the cluster grouping algorithms. Thus, the measure would not show possible incorrectness of the cluster labels of a number of objects. Hence, a number of such objects can significantly influence measurement. Moreover, as 2 clusters of a unique partition would not have any common objects, the measurement could not be utilized for measuring their similarities. Even though there have been reported acceptable functional implementations of diverse measures, these would not be appropriate for the ensemble clustering. As mentioned earlier, the basic produced partition
Suppose Φ:i and
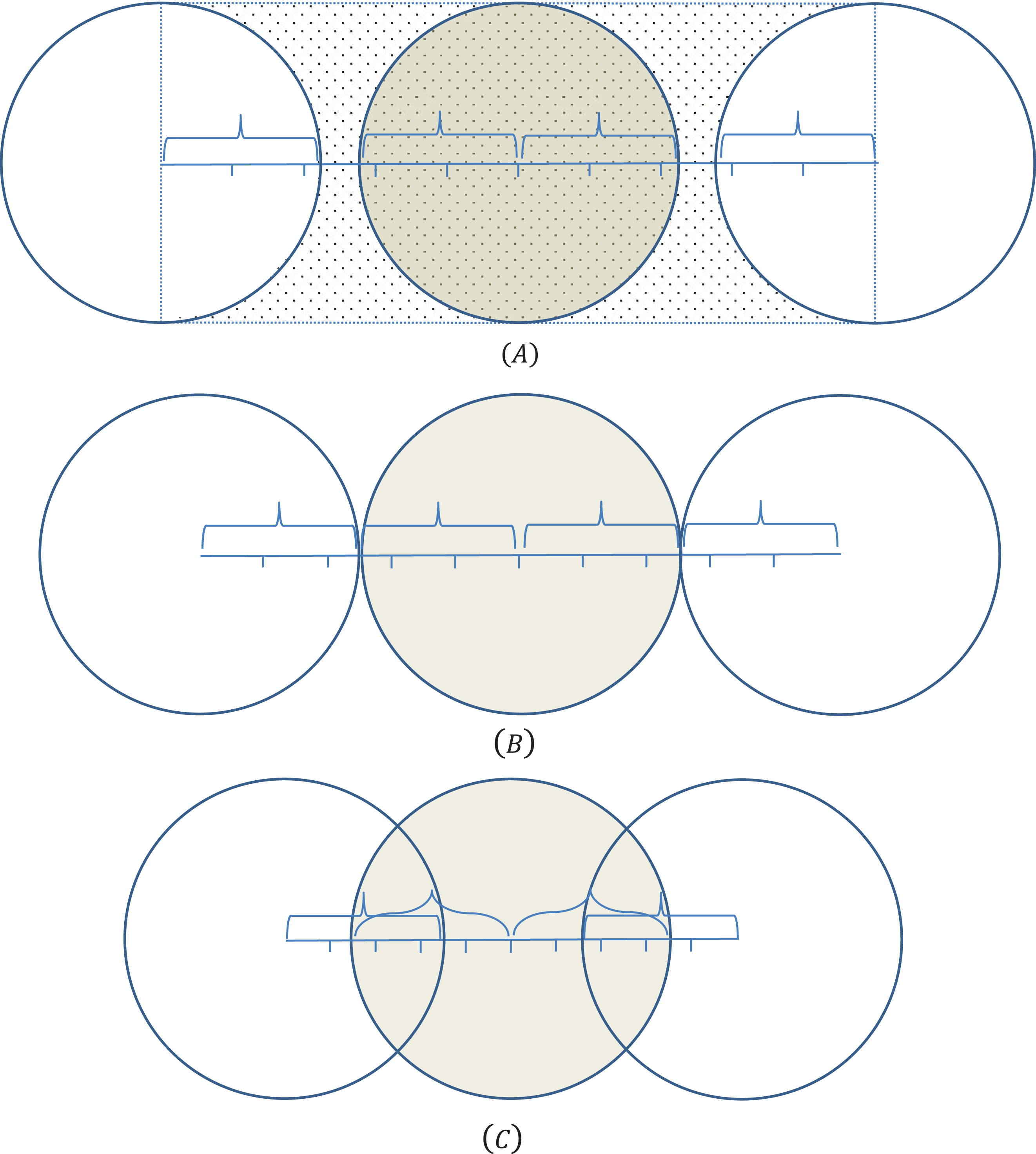
The pa: for a = 0 to a = 10 when the distance between centers of clusters are (A) larger than, (B) equal to and (C) less than 4γ. The middle point is.
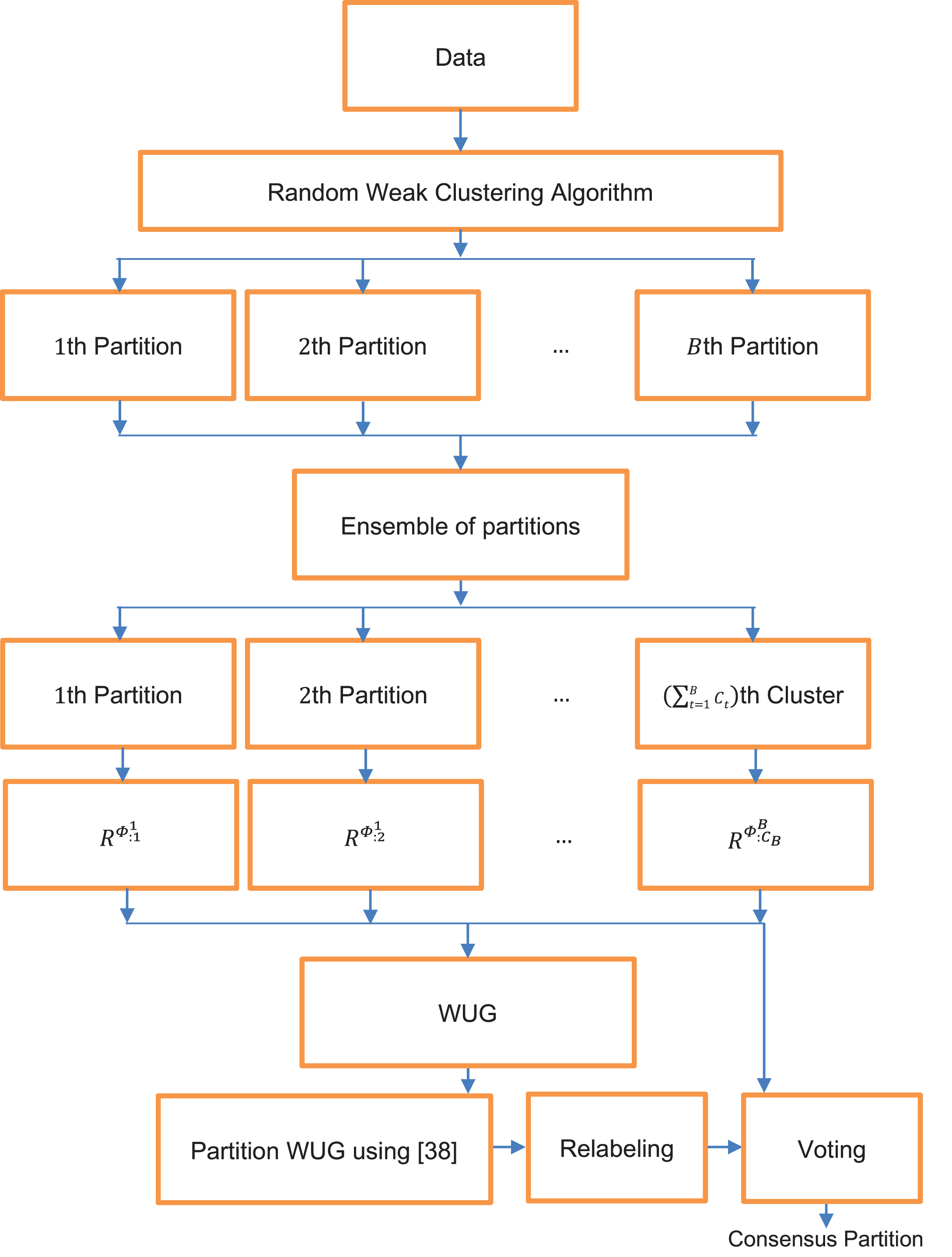
Block diagram of the proposed ensemble framework.
Considering the similarity criterion, a weighted un-directed graph (WUG) has been created that is represented by G (
It is notable that the SIS between two clusters would be utilized as the weight of the edge connecting them; that is, weight would be computed based on Equation (12) so that the higher the SIS between them, the more probable they exhibit an equal cluster. Now we have a graph partitioning problem [38]. Hence, a partition of vertices in graph G (
Following assurance of the ensemble of the aligned (or re-labeled) partitions out of the main ensemble of the partitions, Λ, where
The whole complexity of the algorithm equals
Experimental analysis
In this section, we conduct two experimentations using the proposed algorithm and present them on two subsections. First, we present our assessment metrics. Then, analysis of our method’s parameters is presented. After that, the first experimental subsection is presented where we compare our method with the traditional ensemble clustering algorithms. After that, the second experimental subsection is presented where we compare our method with the modern ensemble clustering algorithms.
Assessment metrics
To evaluate our method its efficacy is computed based on external metrics. We also present the consumed times by different methods. Notably, 2 external criteria are utilized for measuring similarities between the output cluster tags forecasted by various approaches and ground-truth cluster tags of the used data-sets. Assume that the partition like the ground-truth cluster tags of the data-set is designated by π*. Therefore, Equation (15) defines the target partition π*:
Assume we have 2 partitions defined on a data-set D; that is, φ* (consensus partition) and π* (a partition similar to the target tags of that data-set), values between φ* and π* could be as n
ij
represents numbers of the similar data objects in cluster
Therefore, the more the partition φ* (consensus partition) as well as the partition π* (the partition similar to the target tags of data-set) have similarity to each other, the higher these metrics.
Here, some adjustments would be provided for diverse ensemble clustering algorithms for ensuring their reproducibility.
Therefore, number of the clusters in all base partitions would be randomly adjusted in the introduced ensemble clustering algorithm in which kmeans clustering algorithm has been applied for producing their primary partitions. Actually, in all traditional and advanced clustering algorithms, number of the clusters in each base primary partition of the ensemble would be given as a prior information and k-means clustering algorithm would be employed for generating their primary partitions. To set parameter γ in our ensemble method, we set B to 10 and make an experimental analysis in Fig. 3 for Iris [87] and Wine [87] data-sets. The results presented by Fig. 3-a indicate that the best value for γ is 0.5. Therefore, we use 0.5 for variable γ from now on. By setting the parameter γ to 0.5, we have about 100 clusters in our ensemble according to Fig. 3-b. Freezing the parameter γ at 0.5, we perform a similar experimental analysis in Fig. 4 for different values of parameter B. The results presented by Fig. 4 indicate that the best value for B is 20. However, parameter B would be always 20 from now on. Therefore, for the compared methods, their parameters have been determined on the basis of their researchers’ recommendations. Finally, quality of the clustering algorithms would be expressed as the average over 50 independent runs.
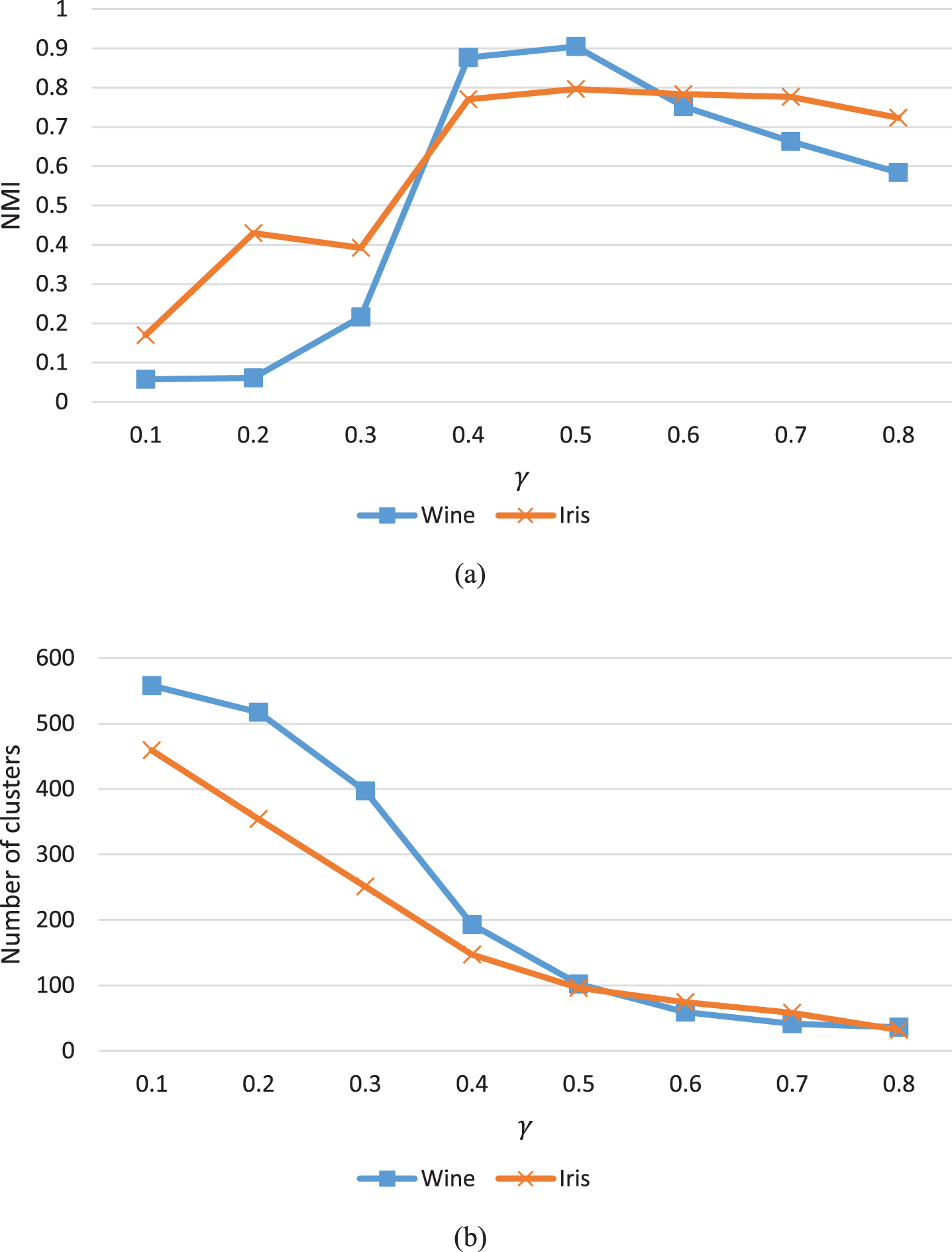
(a) The performance of our method on Iris and Wine data-sets in terms of NMI for different γ values when B is 10. (b) The number of formed clusters in our ensemble method for different γ values when B is 10.
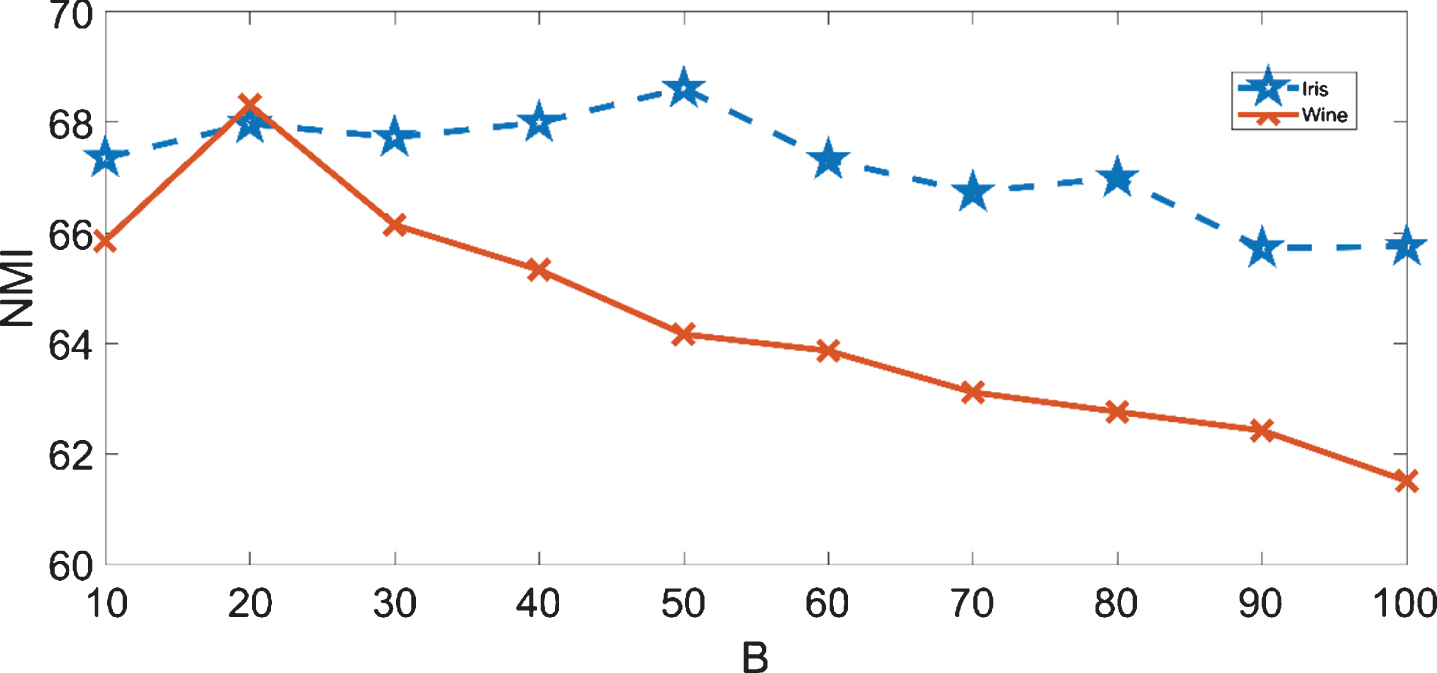
The performance of our method on Iris and Wine data-sets in terms of NMI for different B values when γ is 0.5.
All data-sets are first normalized according to Equation (18).
Benchmark data-sets
Experimental evaluations have been performed on 8 benchmark data-sets. These data-sets are: Ring, Banana, Aggregation, Imbalance, Iris, Wine, Breast, and Digits with respectively 1500, 2000, 788, 2250, 150, 178, 569, and 5620 objects and 3, 2, 7, 2, 3, 3, 2, and 10 clusters. The cluster distributions of the artificial 2D data-sets, i.e. Ring, Banana, Aggregation, Imbalance, have been shown in Fig. 5. The real-world data-sets are derived from the UCI data-set repository [87].
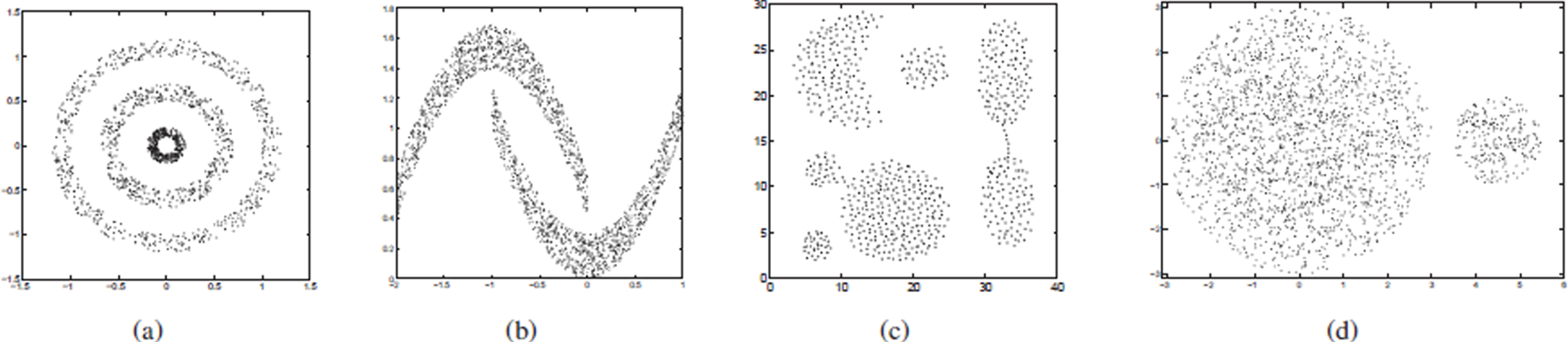
Scatter plot of four artificial data-sets: (a) Ring, (b) Banana, (c) Aggregation, and (d) Imbalance.
For investigating this algorithm efficacy, a comparison has been made between the algorithm and the traditional ensemble clustering algorithms like the evidence accumulation clustering (EAC) along with the single-link clustering algorithm as the consensus function (EAC+SL), the average-link clustering algorithm as the consensus function (EAC+AL) [48], the weighted connection triple (WCT) along with the single-link clustering algorithm as the consensus function (WCT+SL), the average-link clustering algorithm as the consensus function (WCT+AL) [65], the weighted triple quality (WTQ) along with the single-link clustering algorithm as the consensus function (WTQ+SL), the average-link clustering algorithm as the consensus function (WTQ+AL) [65], the combined similarity measure (CSM) along with the single-link clustering algorithm as the consensus function (CSM+SL), the average-link clustering algorithm as the consensus function (CSM+AL) [65], the cluster-based Similarity Partitioning Algorithm (CSPA) [40], the HyperGraph Partitioning Algorithm (HGPA) [40], the Meta CLustering Algorithm (MCLA) [40], (11) the selective un-weighted voting (SUW) [54], (12) the selective weighted voting (SWV) [54], the expectation maximization (EM) [74], and finally the iterative voting consensus (IVC) [77].
Additionally, a comparison has been made between this new method and other strong base clustering algorithms like normal spectral clustering algorithm (NSC) [39], the density-based spatial clustering of the utilizations with noise algorithm (DBSCAN) [35], as well as the clustering by rapid search and find of the density peak algorithm (CFSFDP) [36]. It is notable that the comparison aims at testing if the introduced method would be a solid method or not.
Then, we applied a Gaussian kernel for the NSC algorithm and a value 0.1 × k where 1 ⩽ k ⩽ 20 has been selected as the kernel parameter, i.e. σ2. Finally, the most acceptable partition obtained by changing the above parameters has been chosen to compare them.
It should be noted that both the CFSFDP and DBSCAN algorithms need the input parameter ɛ. Therefore, ɛ-value has been estimated with the average distance between each data point and the respective average point designated by
To describe other methods, we initially employ kmeans clustering algorithm 1000 times with different initializations over a given data-set D. For each partition, a random integer number in interval
Experimental results
In this subsection, we initially utilized diverse consensus functions for extracting the final partitions. It is notable that it is necessary to have an edited EAC (EEAC) for applying EAC on some ensembles [88, 89]. Also, we applied the model introduced in Part 3.4 as a distinct consensus function for the extraction of the final partition out of the output graph of Algorithm 1. Figures 6 and 7 schematically represents the experimental outputs of distinct ensemble clustering techniques on diverse data-sets with regard to ARI metric (and NMI metric). According to the analyses, this new consensus function introduced in Part 3.4 has been considered to be the most acceptable method followed by the EEAC+SL consensus function. As demonstrated, MCLA and EEAC+AL consensus functions have been the 3rd and 4th ones. Hence, this new mechanism introduced in Part 3.4 has been viewed as the dominant consensus function.
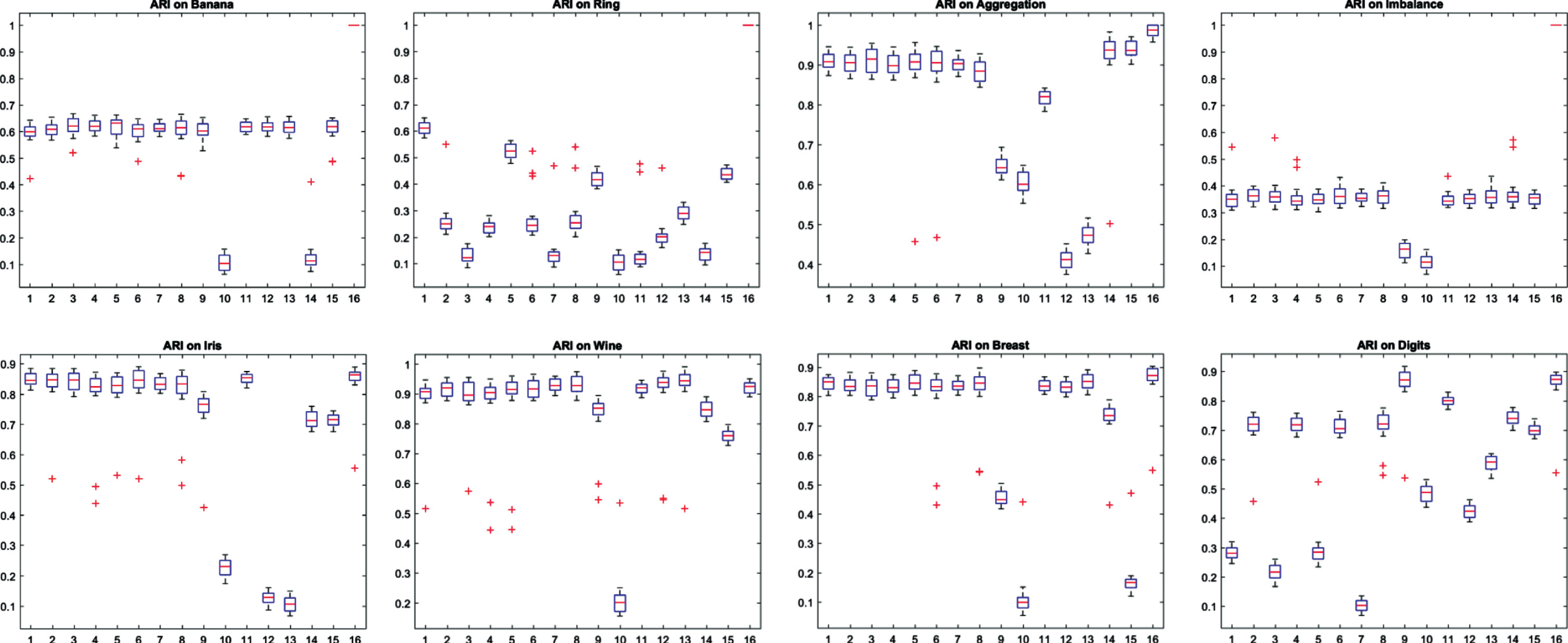
Experimental results of different ensemble methods on different data-sets in terms of ARI. EAC+SL, EAC+AL, WCT+SL, WCT+AL, WTQ+SL, WTQ+AL, CSM+AL, CSM+SL, CSPA, HGPA, MCLA, SUV, SWV, EM, IVC and proposed methods are respectively methods 1–16.
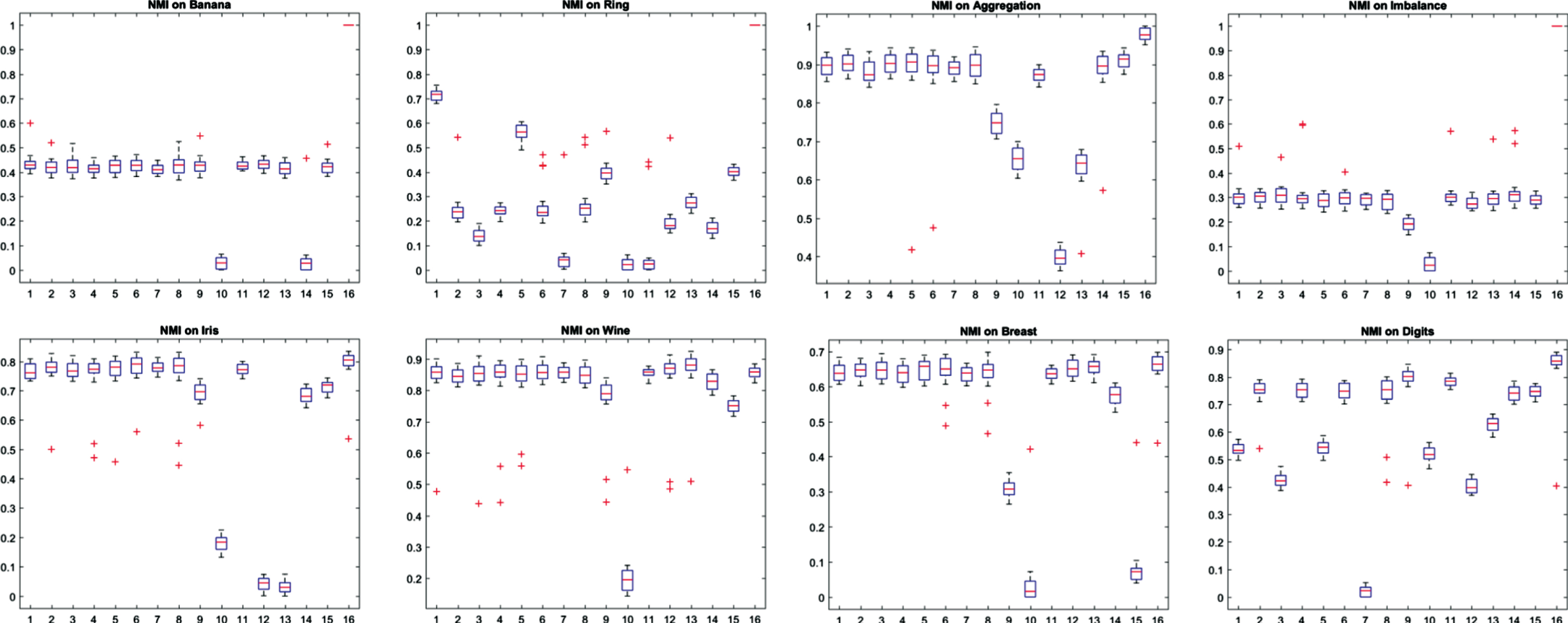
Experimental results of different ensemble methods on different data-sets in terms of NMI. EAC+SL, EAC+AL, WCT+SL, WCT+AL, WTQ+SL, WTQ+AL, CSM+AL, CSM+SL, CSPA, HGPA, MCLA, SUV, SWV, EM, IVC and proposed methods are respectively methods 1–16.
Considering ARI and NMI metrics, Figs. 6 and 7 compare efficacies of diverse ensemble clustering algorithms on the artificial as well as the real-world data-sets. According to Figs. 6 and 7, this new ensemble clustering algorithm increases clustering accuracy in both of the synthetic and the real-world data-sets in comparison with other available ensemble clustering algorithms in terms of ARI metric (and NMI metric). Based on the experimental outputs, this algorithm could efficiently recognize or identify diverse clusters and enhance the functionalities of the traditional ensemble clustering algorithms.
Benchmark data-sets
Used data-sets include Semeion, Multiple-Features, Image-Segmentation, Forest-CoverType, MNIST, Optical-Digit-Recognition, Landsat-Satellite, ISOLET, USPS, Letter-Recognition, Breast-Cancer, Bupa, Glass, Galaxy, SAHeart, IonoSphere, Iris, Wine, and Yeast respectively with 1,593, 2,000, 2,310, 3,780, 5,000, 5,620, 6,435, 7,797, 11,000, 20,000, 683, 345, 214, 323, 462, 351, 150, 178, 1,484 instances and respectively with 10, 10, 7, 7, 10, 10, 6, 26, 10, 26, 2, 2, 6, 7, 2, 2, 3, 3, 10 numbers of real target clusters. All data-sets are from UCI data-set repository [87] except data-set MNIST [90] and data-set USPS [91].
Modern ensemble methods
In the current subsection section, our ensemble will be compared to some of the state-of-the-art methods. The methods comparing to our methods include H[ybrid B[i-P[artite G[raph F[ormulation (HB-PGF) [67], Ensemble of Locally Reliable Clusters (ELRC) [73], Sim-Rank Similarity (S-RS) [92], W [eighted C[onnected T[riple (W-CT) [65], C [luster S [election E [vidence A [ccumulation C [lustering (CS-EAC) [93, 94], W [eighted E [vidence A [ccumulation C[lustering (W-EAC) [95], W [isdom of C [rowds E [nsemble (WCE) [96], G [raph P [artitioning with M [ulti-G [ranularity L [ink A [nalysis (GPM - GLA) [95], T [wo-level co-association M [atrix E [nsemble (TME) [97], E [lite C [luster S [election E [vidence A [ccumulation C [lustering (ECS-EAC) [89], and Average Linkage Second Diversity Measure (ALSDM) [29, 98].
To describe the setting, we again employ kmeans clustering algorithm 1000 times with different initializations over a given data-set D. For each partition, a random integer number in interval
Experimental analysis
Comparison of the proposed ensemble method with the different modern ensemble ones, which are presented in Part 4.4.2, for different data-sets presented in Part 4.4.1 in terms of ARI metric is depicted in Fig. 8. It is notable that result of each method on each data-set is an average of 50 independent trials here. We assume that the ARI value of each method on different datasets is a variable, we perform a Friedman test on the results presented by Fig. 8. The P-value is about 0.01 that there is a significant difference between the variables. The post hoc analysis indicates most of this difference comes from the ALSDM and our algorithm with a P-value of about 0.041.
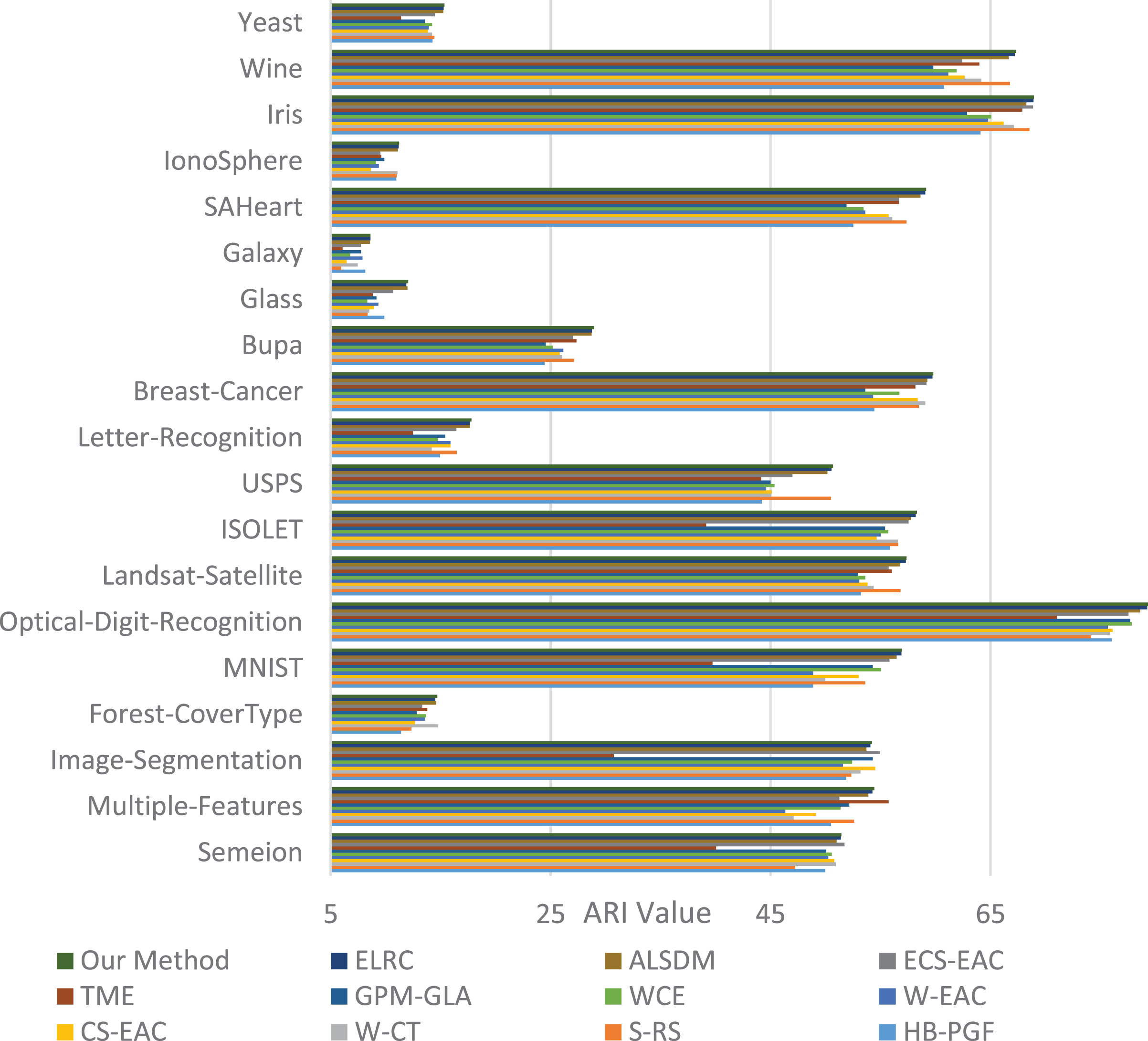
Comparison of the proposed ensemble method with the different modern ensemble ones in terms of ARI. Horizontal axis depicts the ARI value.
Figure 9 depicts the consumed time of the different algorithms in terms of the number of instances. We used KDD-CUP99 data-set with 1048576 instances and 2 clusters here. It is obvious that our method is not the best, but it is still more scalable than most of the state of the art ensemble methods.
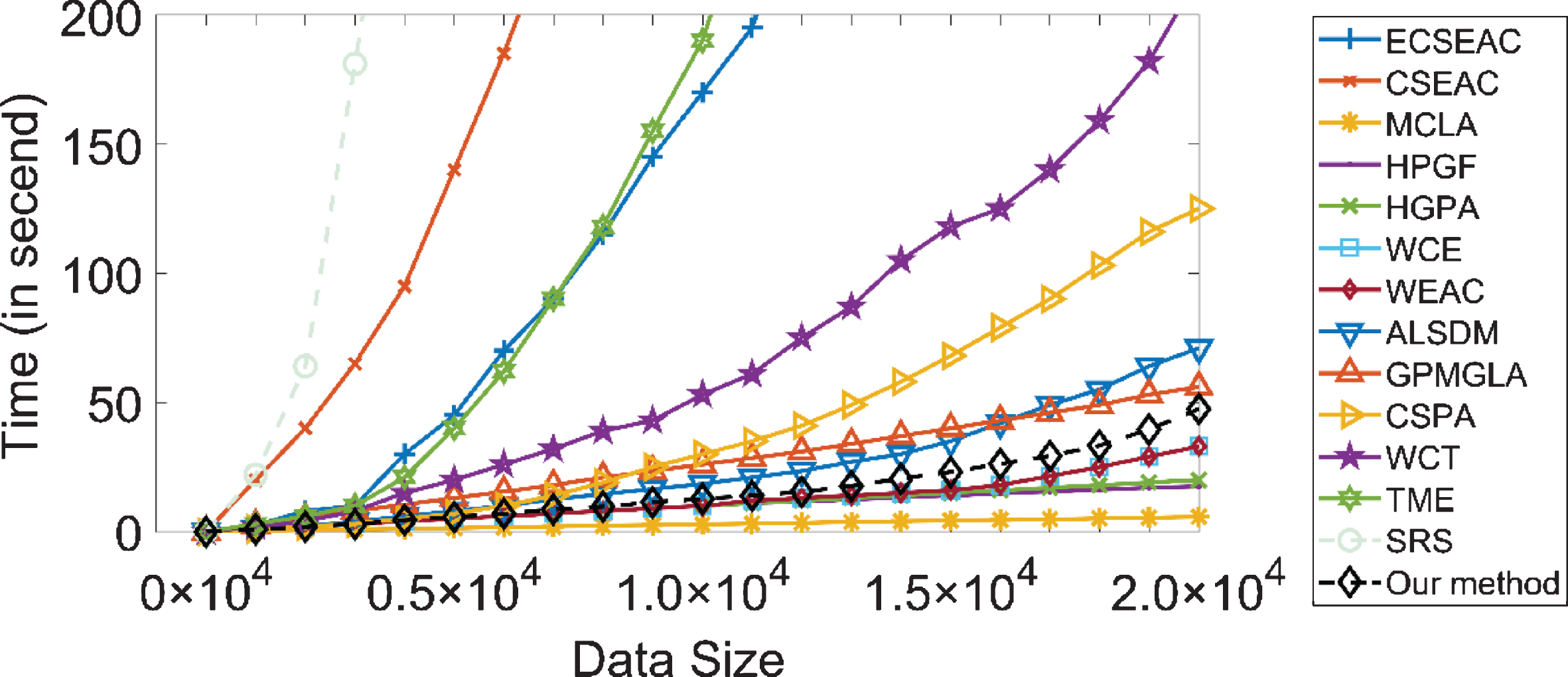
The consumed time analysis of the different algorithms in terms of the number of instances.
As the basic clustering algorithm k-means clustering algorithm is extensively regarded as a low-computational algorithm, it has been regarded as a poor clustering method as several variables influenced their performance that includes improper selection of the initial cluster centers and dissimilar data distribution. Therefore, the present research aimed at introducing one of the novel ensemble clustering algorithms with the multiple kmeans clustering algorithm. This new ensemble clustering method enjoys benefits of kmeans clustering algorithm including its low computation and great speed but it has important disadvantage like incapability of detecting the nonspherical and nonuniform clusters. Actually, our ensemble clustering algorithm could enhance quality and stability of kmeans clustering algorithm and it is proved that aggregation of multiple poor partitions would be more acceptable than or equal to a strong partition. The research also tried for solving each ensemble clustering problem via describing the valid local clusters. Moreover, the research called data surrounding a cluster center in kmeans clustering as the valid local data clusters. Therefore, for generating distinct clustering, a duplicate approach of the production of the poor clustering results; namely, the use of the kmeans clustering algorithm as the base clustering algorithm has been utilized on the nonappeared data in the formerly valid local clusters. Hence, empirical analyses compared this new ensemble clustering algorithm with multiple available ensemble clustering algorithms and 3 strong basic clustering algorithms running on a series of artificial and the real-world bench-mark data-sets. Based on the empirical outputs, this ensemble clustering algorithm outperformed the advanced ensemble clustering procedures. Furthermore, effectiveness of our ensemble clustering algorithm has been investigated with the result of its suitability to address the large-scale data-sets.
Compliance with ethical standards
Conflict of interest
The authors declare that they have no conflict of interest.
Ethical approval
This article does not contain any studies with human participants or animals performed by any of the authors.
Footnotes
Acknowledgments
Research results of 2017 general topic “classroom teaching evaluation research based on core literacy” (Project No.: cd-db17207) of the 13th Five-year Plan of Beijing Education Science.