
Abstract
This paper deals with improving the approximation capability of fuzzy systems. Fuzzy negations produced via conical sections are a promising methodology towards better fuzzy implications in fuzzy rules. The linguistic variables and the fuzzy rules are induced automatically following a fuzzy equivalence relation. The uncertainty of linear or nonlinear systems is thus dealt with. In this study, the clustering is optimized without human intervention, but also the best inference mechanism for a particular dataset is prescribed. It has been found that clustering based on fuzzy equivalence relation and fuzzy inference via conical sections leads to remarkably accurate approximations. A fuzzy rule based system with fewer control parameters is proposed. An application on telecom data shows the use of the methodology, its applicability to a real problem and its performance compared to other alternatives in terms of quality.
Introduction
Fuzzy rule based systems (FRBSs) are one of the most important areas of application of fuzzy set theory. Research on fuzzy modeling has a long history in soft computing [1], especially in fuzzy control [2] and expert systems [3, 4]. Early research on the development of fuzzy expert systems involved an expert providing the set of linguistic IF-THEN rules, while recent research deals with automatically derived rules via fuzzy clustering [5, 6] and fuzzy inference variations [7–9].
Among the methods for fuzzy clustering, the fuzzy equivalence relation has recently gained momentum due to its hierarchical structure and its guarantee for a solution [10–12]. Other widely used clustering algorithms are the fuzzy C-means and fuzzy K-means algorithms and their derivatives [13, 14]. All the above machine learning techniques broaden the application of FRBSs, while they improve the generation of linguistic variables and fuzzy rules directly from data without any human intervention.
Various attempts have been proposed to automatically extract fuzzy rules from experimental input/output data. Among these, learning methods based on clustering and recognition of patterns [15–17]. These are computational procedures for generating fuzzy rules by learning from examples. These procedures lead to automatically derive membership functions and fuzzy if-then rules from a set of given training examples as Wang & Mendel and Hong & Lee have shown [15, 16]. The main problems in the use of such pattern-based algorithms are: 1) the clustering algorithms are heuristic in nature and 2) certain assumptions are made about the structure of the data (e.g. choice of a distribution, number of clusters, etc.). Such assumptions may be wrong when it is difficult to discern patterns in the data.
Motivated by the need to create fuzzy system models with better approximations and less risk for some erroneous assumption about the data, this paper presents a promising new prototype for the development of FRBSs. The fuzzy equivalence relation is used to cluster the data automatically.
Another design parameter of FRBSs is the type of fuzzy inference. There exist three fuzzy modelling inference systems: Mamdani models, Takagi-Sugeno models and genuine type inference fuzzy models [18]. In Mamdani fuzzy systems, both the antecedent and consequent of each rule is a fuzzy set. Takagi-Sugeno systems assume a crisp consequent for each rule, usually a first-order polynomial function of the input variables. Their fuzzy inference mechanism is the so-called engineering implication. This is different from a logical implication, so various attempts in the literature propose genuine logical implications instead, which are compatible with the Compositional Rule of Inference (CRI) of Zadeh [19]. In theory, it has been proven [20] that fuzzy inference systems function as universal approximators. However, Mamdani and Sugeno fuzzy systems perform only conjunctional (t-norm type) fuzzy implications, while genuine logical fuzzy systems are able to perform any type of fuzzy implications [21].
In this work, the fuzzy implications used are a special class of fuzzy implications derived from fuzzy negations via conical sections. The research tested various classes of implications towards choosing the best. This has led to a different unsupervised machine learning methodology. The fuzzy linguistic variables and the rules of FRBSs are derived automatically.
This paper is organized as follows. Section 2 presents terminology and notation. Section 3 explains the proposed fuzzy implications derived from fuzzy negations. Section 4 presents the proposed clustering method and linguistic variables identification. Section 5 is about the generation of fuzzy rules. Section 6 deals with the ideal number of fuzzy terms. Section 7 discusses fuzzy inference and the performance evaluation of various fuzzy inference choices. Finally, in Section 8, an application clearly shows the advantages of the proposed methodology. Discussion and conclusions follow in Sections 9 and 10.
Terminology
Basic notions from fuzzy equivalence relations and rule based systems are summarized below.
Fundamentals of fuzzy set theory
Let X be a universal set. Every function of the form
A fuzzy set
A fuzzy set
The α-cuts of a fuzzy set are defined as
It is known that α-cuts uniquely determine the fuzzy set
A trapezoidal fuzzy number
Fuzzy relations on fuzzy numbers
Some notions from the theory of fuzzy relations on fuzzy numbers are presented here, which will be used in fuzzy clustering.
A fuzzy relation
A fuzzy relation on a single universe Xis also a relation from X to X. In that case, it is called a fuzzy binary relation. It is called compatible relation if the following conditions hold for
Fuzzy equivalence relation
A fuzzy relation
A fuzzy equivalence relation induces a set of equivalent ordinary relations on X defined by the α-cuts of
Let
∪ denotes the max operator for the set union and ∘ denotes the max-min composition.
Each α-cut of
Fuzzy rule based inference systems
Linguistic variables are essential to rule based systems, because they are used in the determination of the truth of fuzzy rule antecedents and in approximate reasoning. Formally, a linguistic variable is a quintuple (x, T (x) , U, G, M) in which x is the name of the variable; T (x) is the term set of x, that is, the set of names of names of linguistic values of x with each value being a fuzzy number defined on U; G is a syntactic rule for generating the names of values of x; and M is a semantic rule for associating with each value its meaning. Informally speaking, a linguistic variable is a variable whose values are words or sentences rather than numerical entities [22]. For example, “height” can be a linguistic variable with values “short”, “medium”, “tall”. In this paper, the use of fuzzy term is an abbreviation for the fuzzy number associated with each linguistic term.
A fuzzy rule is an IF-THEN statement of the form:
R
l
: IF x1 is
where R
l
represents the l-th rule (l = 1 … M) and the
The operator ⊗ is usually the min (Mamdani) or prod (Sugeno) implication operator, or it can be a logical fuzzy implication derived from the Compositional Rule of Inference (CRI) of Zadeh [19].
Based on CRI, the fuzzy syllogism is defined as follows. Given a fuzzy set
The output of the fuzzy rule based system is obtained by aggregation of the M fuzzy results by union
It must be recalled that fuzzy rule based systems (FRBSs) are composed of a knowledge base (fuzzy rules and information provided by the user), a fuzzification interface, that transforms the crisp values of the input variables into fuzzy sets; an inference engine that uses the fuzzy values from the fuzzification interface and the fuzzy rules to perform the reasoning process; and a defuzzification interface which takes the fuzzy result from the inference and performs a mapping from the fuzzy set of the control variable to a crisp result. The defuzzification strategies used in this investigation are the Center of Gravity and the Mean of Maxima [23].
The production of fuzzy implications from fuzzy negations is presented in this section. The new strong fuzzy negations via conical sections presented in [24, 25] are combined with f-generated implications I (x, y) = f-1 (x · f (y)), where f is a decreasing function [26]. The result is the Equation 4 used in the proposed methodology. A short theoretical background is provided here for better understanding the formula at the end of this section.
Genuine type fuzzy implications
(I1) x1 ⩽ x2 then I (x1, y) ⩾ I (x2, y), i.e., I (· , y) is decreasing,
(I2) y1 ⩽ y2 then I (x, y1) ⩽ I (x, y2), i.e., I (x, ·) is increasing,
(I3) I (0, 0) = 1,
(I4) I (1, 1) = 1,
(I5) I (1, 0) = 0 .
The set of all fuzzy implications will be denoted by FI.This study aims to determine which fuzzy implications best suit the application under investigation. Some fuzzy implication formulas examined are in Table 1.
Some fuzzy implication formulas by various authors
Some fuzzy implication formulas by various authors
The special class of fuzzy implications derived from fuzzy negation
A fuzzy negation N is a generalization of the classical complement or negation ¬. Fuzzy negation truth table consists of the two conditions: ¬1 ≡0 and ¬0 ≡1 .
N (0) = 1, N (1) = 0, (N1)
N is decreasing. (N2)
A fuzzy negation N is called strict if, in addition,
N is strictly decreasing, (N3)
N is continuous, (N4)
A fuzzy negation N is called strong if the following property is met,
N (N (x)) = x, x ∈ [0, 1]. (N5)
In this paper the strong negation will be denoted by
N S (x) x ∈ [0, 1].
Examples for fuzzy negations are given in the Table 2 below:
Examples of fuzzy negations with properties
The paper [24] proves a new family of strong fuzzy negations, which is produced by conical sections and is given from the following formula
According to the Definition 2, the above strong negations are f- generators so if in the following formula N is used instead of f,
Clustering is necessary in order to group a large number of data and thus reduce the number of cases. Fuzzy clustering is a preliminary step for linguistic variables determination [27] and the subsequent extraction of expert rules from data. There exist various clustering algorithms in the literature [5, 14]. The proposed clustering method in FRBS is based on fuzzy equivalence relation [10–12]. The algorithm does not require any human intervention, thus making it suitable for machine learning and automatically generated fuzzy rules. In the following subsections is the description in detail of how the various system interfaces function. Figure 1 shows the proposed FRBS structure.
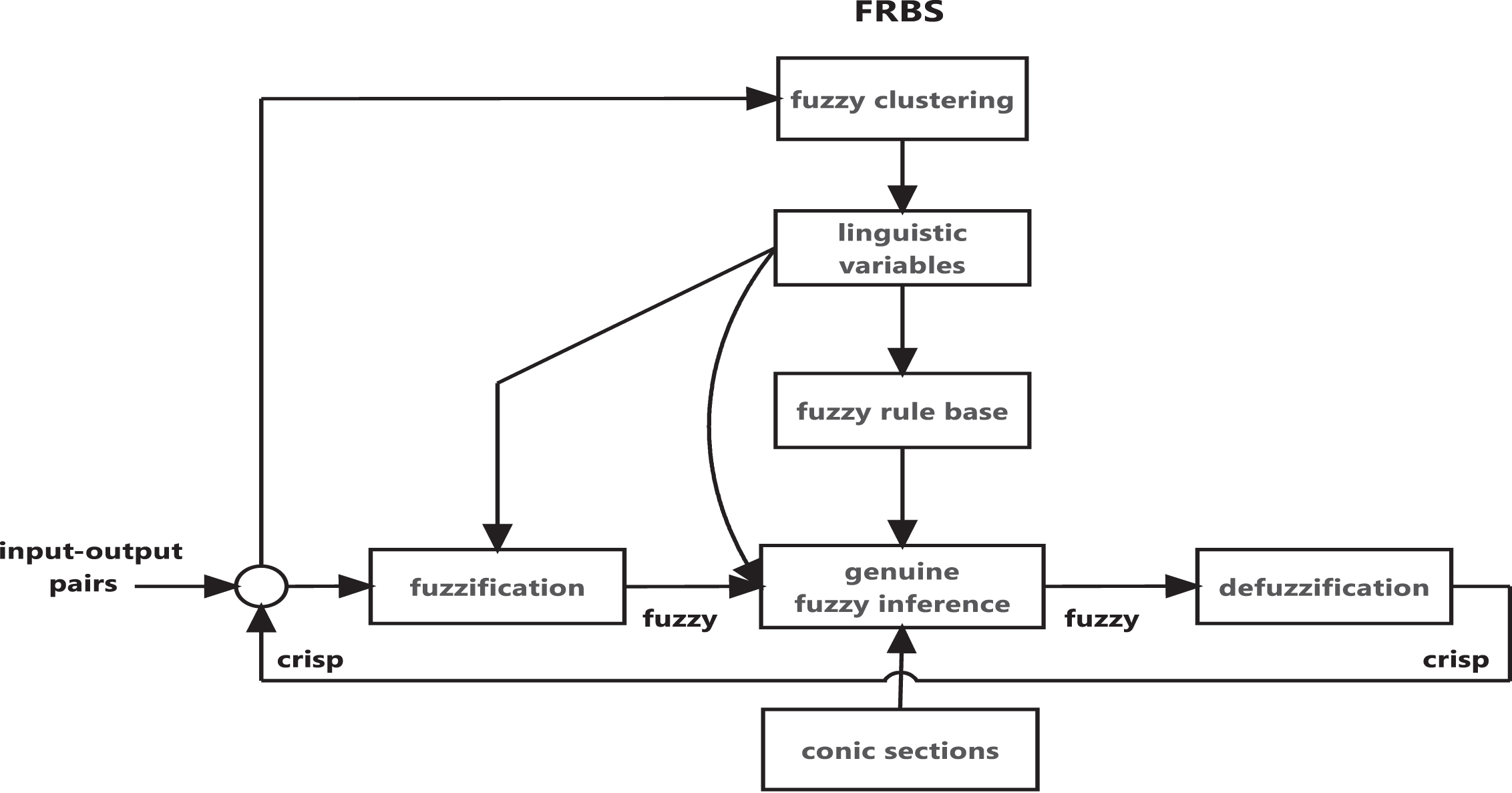
Structure of a fuzzy rule based system integrating fuzzy clustering and genuine fuzzy implications from conical sections.
At first the creation of a fuzzy equivalence relation matrix from the data is shown. This ultimately leads to group the possible solutions for linguistic variables by means of a hierarchical group of partitions of the available dataset. To achieve this, one may take advantage of the basic property of fuzzy equivalence relation to partition a set X into a family of disjoint subsets { α S1, α S2, …, α S k } , 0 ⩽ α ⩽ 1.
The procedure starts by forming a fuzzy compatible relation from a given data sequence {x1, x2, … x
n
}. The numerical values that characterize a fuzzy relation can be derived by a similarity measure [28]. In this paper, the min-max method of the similarity was used. First, a compatible matrix C = [c
ij
] n×n (symmetric and reflexive) is formed where
The α-cuts of fuzzy equivalence relation are equivalent ordinary relations. Different α-cuts values of
The linguistic variables are formed automatically in such a way that the membership functions of the linguistic terms share a portion of their space with their neighboring clusters in order that every input to be able to fire more than one fuzzy rules. The ideal number of clusters depends on the relative importance of the specific problem and is decided automatically using cluster validity described in Section 4.3.
The partitions derived from the fuzzy equivalence relation are used to generate the fuzzy terms of the linguistic variables. Suppose that it is given a set of input-output data pairs:
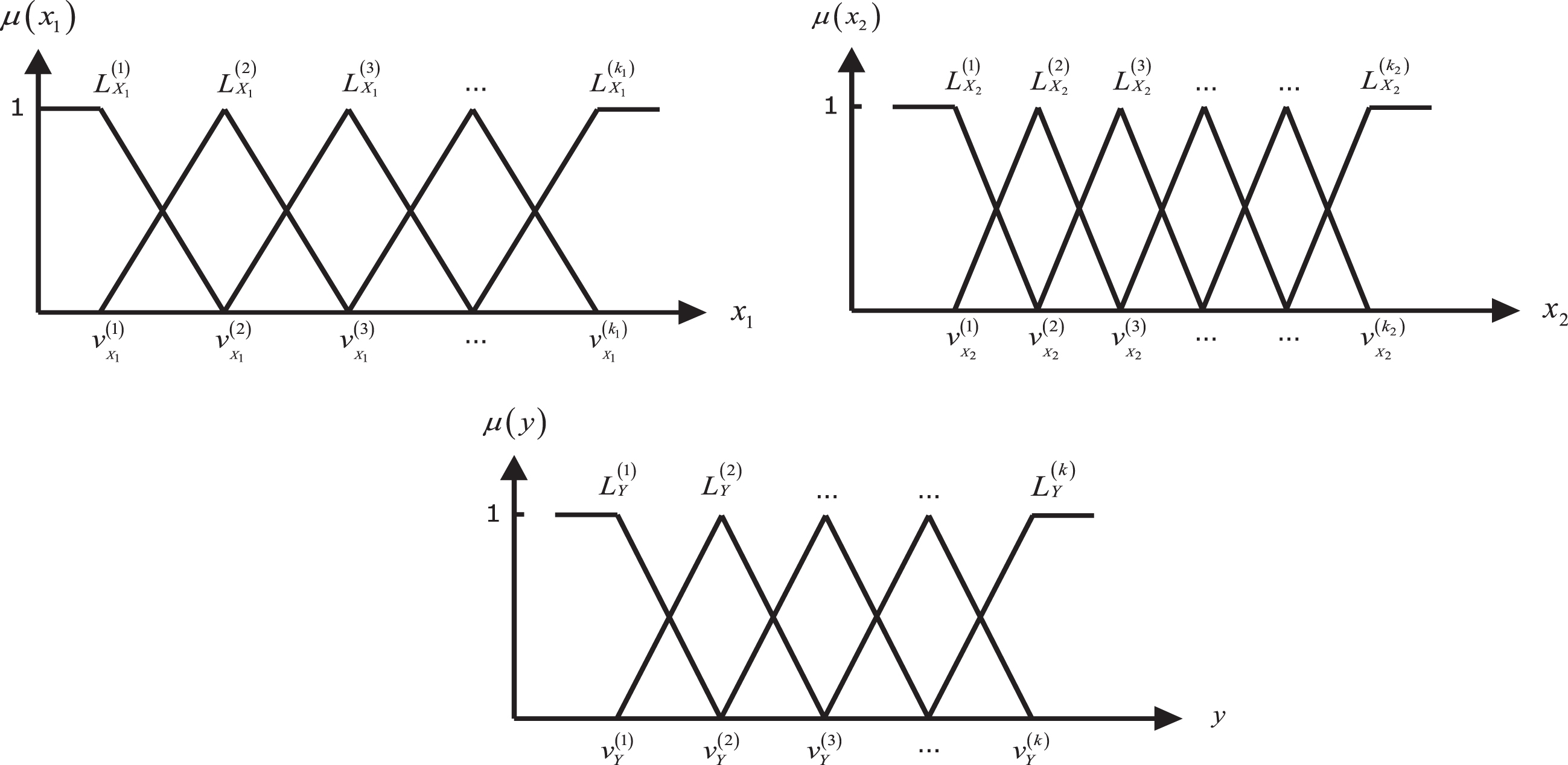
Partitioning of the inputs spaces X1, X2 and output space Y into fuzzy regions and their corresponding membership functions.
A problem one faces when clustering is to decide the optimal partitioning into clusters. In the case of large multi-feature data sets, visualization of data of more than three dimensions is impossible. There must be another way to form clusters when one cannot visualize. A procedure for evaluating the results of clustering known as Dunn’s index of cluster validity [29] has been chosen. Cluster validity consists of a set of techniques for finding the set of clusters that best fits natural partitions without any a priori class information. The outcome of the clustering process is validated by the designated cluster validity index. The index is defined in Equation 6:
In this section the method to generate fuzzy rules from data is presented. A fuzzy rule is of the form
If X1 is
where
Creation of output subsets for each partition derived from clustering
Suppose S1, S2, . . . S
l
are partitions of X derived from clustering, where l is the number of partitions. The image of S
j
under function fs : X → Y is the subset of Y that consists of the images of the elements of S
j
. That is
In case of multi-dimensional datasets, the above equation becomes
Generation of fuzzy numbers on the Y j partitions
The elements of set Y
j
, namely yj1, yj2, . . . , y
jc
j
are considered to represent statistical samples. The mean of each sample
Fuzzy comparison between the created fuzzy numbers
and the fuzzy terms
A proximity criterion is used to find the nearest fuzzy distance between
The goal is to associate the fuzzy linguistic terms that represent the input variables with the fuzzy linguistic terms of the output variable. By performing k · l fuzzy comparison between
The elements of the proximity matrix with the lowest value per column j give the desired fuzzy rules as
As it was mentioned earlier, the number of fuzzy terms in the proposed method comes from the optimum number of clusters obtained as shown in Section 4.3. The necessary condition in forming fuzzy rules is that for every x i ∈ X i , there is at least one antecedent for each rule, which is true over x i at least to a fixed degree a > 0. Formally,
The ideal overlapping is found by the following formula:
Varying the base width of fuzzy terms, different PI are computed. Best is the one closer to 0.5 as an ideal value of overlapping.
Fuzzy inference choices
Using the fuzzy rules obtained from the procedures above, a fuzzy inference mechanism is needed to perform the actual mapping from the input variables to the output variable. There exist more than one choices for the fuzzy inference.
To explain those choices, let us suppose that the problem involves a two-feature dataset (two inputs one output). Then, a fuzzy control rule system is of the form:
The inference process is performed according to Equation 3 as follows:
Types of FRBS according to their inference
The aggregation method applied is either the max or sum of the fuzzy results
Final approximations of the FRBS are obtained by both types of systems and the results after applying fuzzy clustering and fuzzy inference are compared with the original output values using performance metrics.
A generalization of fuzzy implications was presented in Section 3. Fuzzy implications from conical sections provide a much broader spectrum of choices for the genuine type fuzzy implications. The proposed approach, being an integration of fuzzy clustering with automatic fuzzy rule generation, benefits from the flexibility of genuine type fuzzy implications, because the produced FRBS has a small set of fuzzy rules with well overlapped fuzzy terms of the linguistic variables. This freedom allows us to find an implication that better represents the available dataset.
Performance evaluation
To evaluate the approximation performance, three measures are usually applied. The normalized mean squared error (NMSE), the root mean squared error (RMSE) and the mean absolute error (MAE).
Given a set of output values and their approximated ones
RMSE is the square root of MSE, defined as follows:
MAE is defined as follows:
Note that the last metric (MAE) does not penalize huge errors as MSE does. Thus, it’s not sensitive to outliers compared to the mean square error. For more interpretations, see [32].
Case study
To illustrate the proposed methodology, an application concerning cell phone activity data is examined. The data were offered by the Telecom Italia Big Data Challenge 2014 [33], which is a rich source on telecommunications data for major Italian cities. We processed the raw data for the city of Milan and formed the data set in Table 4 comprised of 24 hours of cell phone activity for a particular day. Variable X represents the hours of day and Y is a measure of telephone activity (received/sent SMS, incoming/outgoing calls and internet activity). One can immediately observe the low cell phone activity during night hours and the high activity during the midday. The goal of this example application is to create a FRBS that better approximates the non-linear behavior of the underlying system. Finally, a fuzzy implication that better suits the problem is selected.
Case study dataset
Case study dataset
The proposed methodology is presented step by step below.
Transitive closure
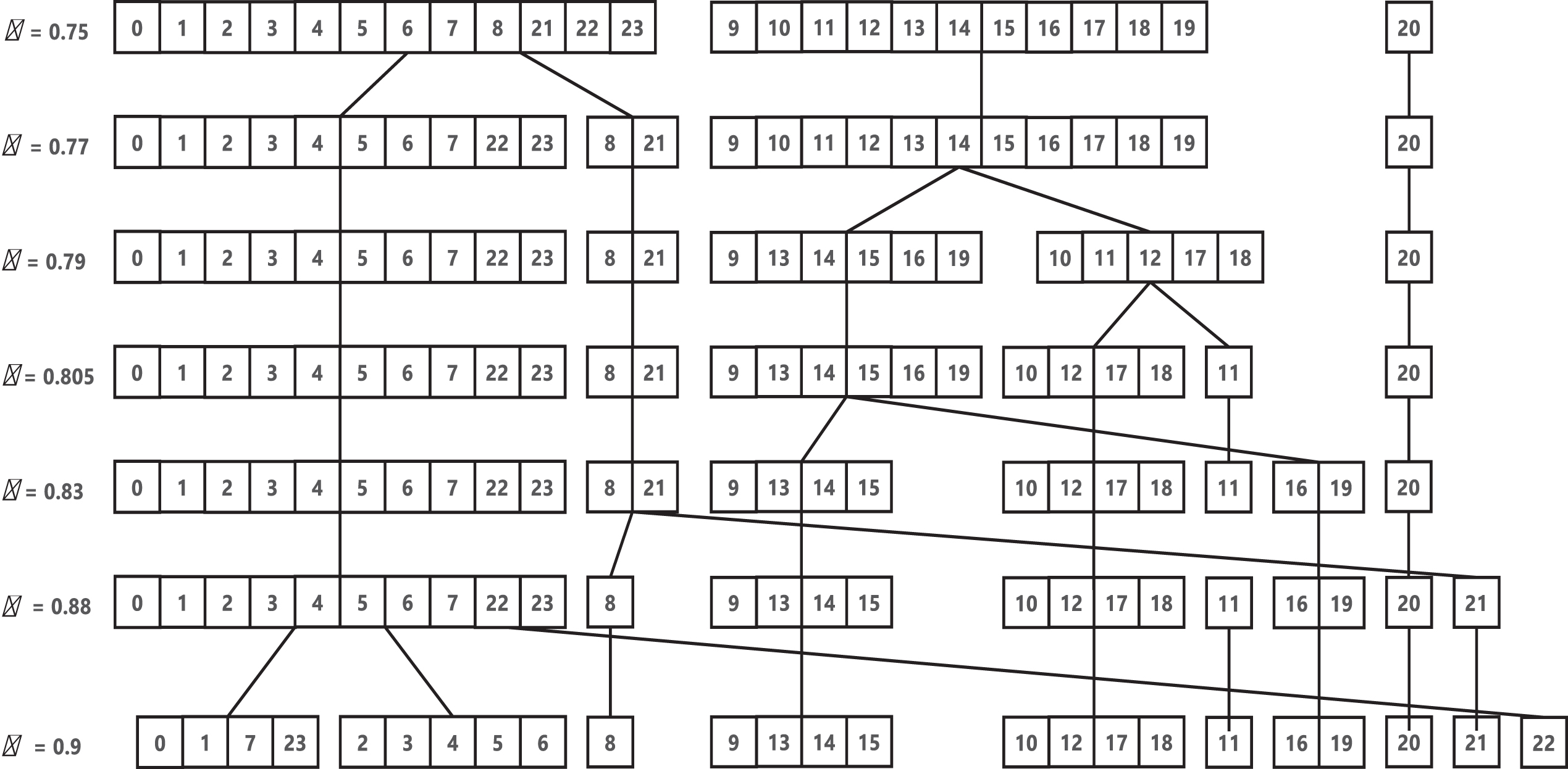
Hierarchical structure of partitions created by
Cluster values of Y for various α-cuts
Cluster validity values for various numbers of clusters
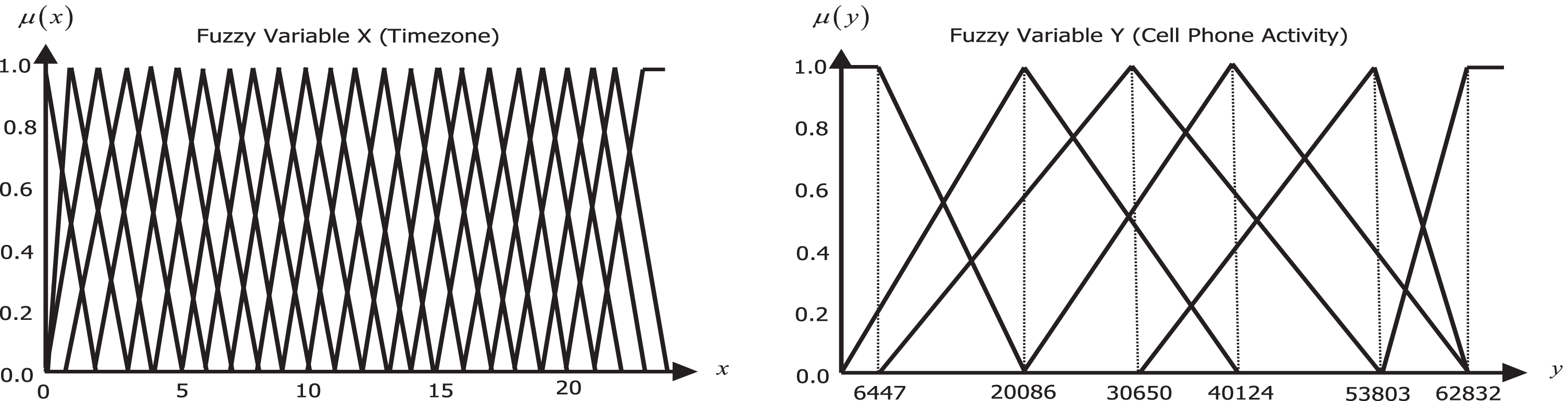
Final fuzzy variables induced from data after fuzzy clustering and optimization.
PI values for fuzzy terms of X and Y
The fuzzy proximity matrix for the creation of the fuzzy rule base
Fuzzy linguistic variables and expert rules in fuzzy control language specification IEC 61131-7
Fuzzy system responses for various fuzzy implications
The best approximation was obtained with fuzzy implications derived from conical sections with conic parameter m = 0.1.
Figure 5 shows the result which is 72% improvement compared to Mamdani inference.
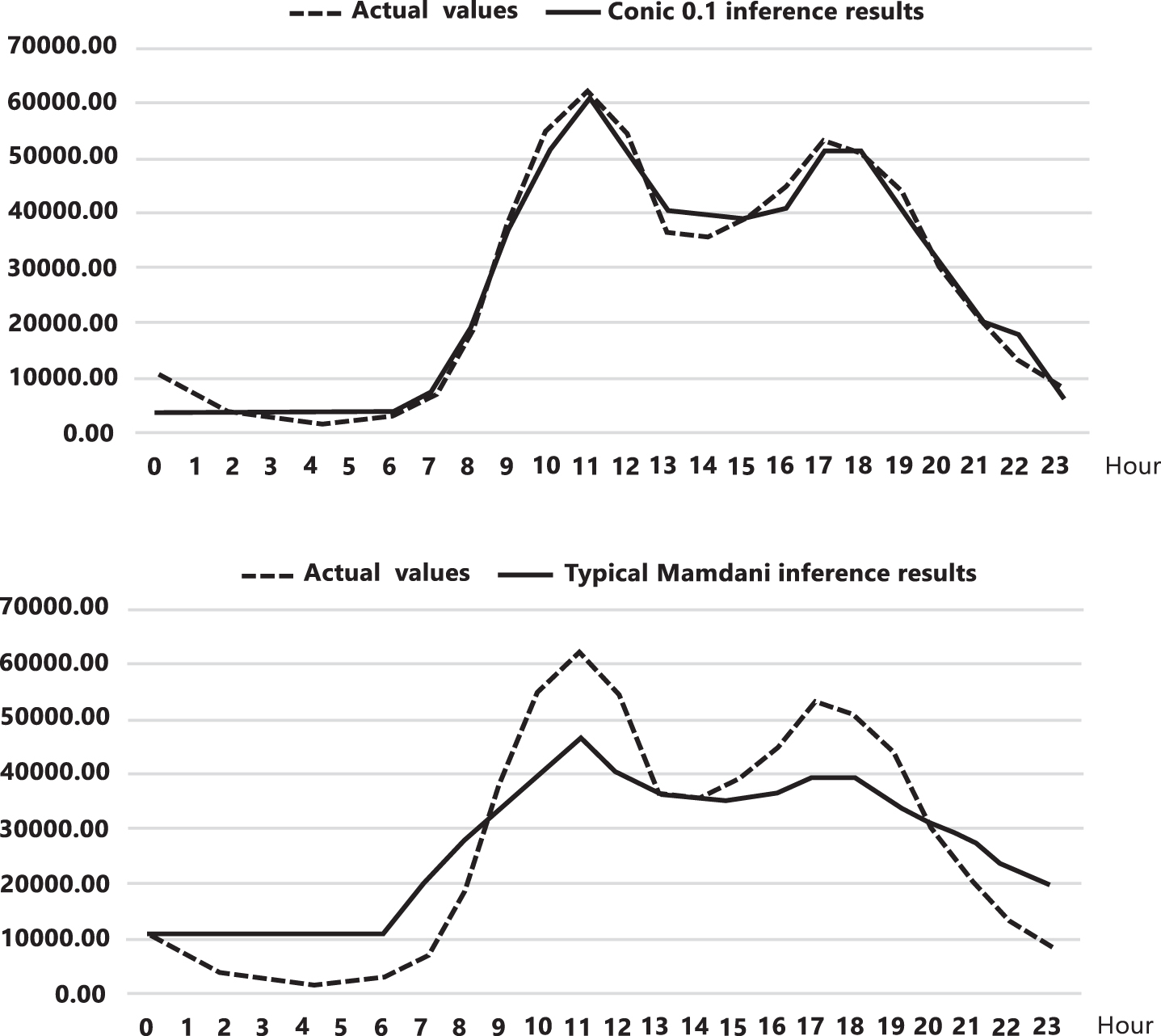
Comparison of inference implementations.
In general, genuine logical fuzzy inference performed better than non-genuine fuzzy inference, with Lukasiewicz implication being also a good choice. However, the flexibility of conical sections and the single control parameter m, allows us to achieve better approximations. The proposed method reached the highest approximation accuracy with value m = 0.14. Figure 6 shows how the normalized mean squared error drops. In conclusion, this methodology gives a superior rule based system.
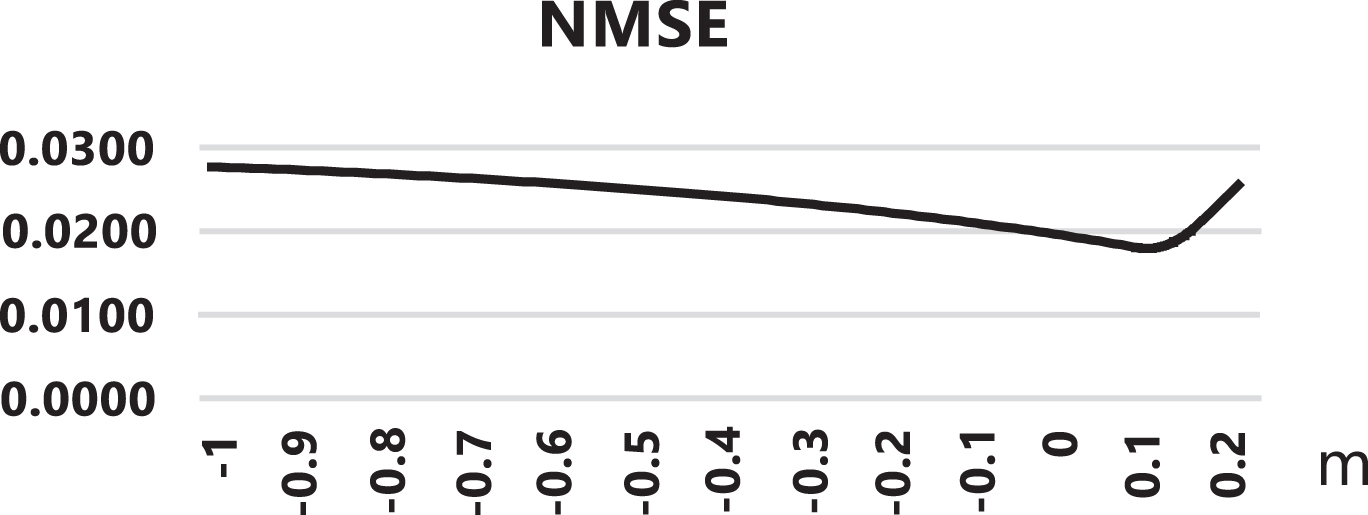
Normalized Mean Squared Error (NMSE) curve.
The traditional FRBSs require appropriate clustering to derive a relatively small set of fuzzy rules directly from the data. Still, it is difficult to automatically induce the linguistic variables and fuzzy rules when the data structure is not obvious. Other clustering methods assume an intuitive choice of the initial number of clusters. This may be subjective (heuristic) and not always effective.
The proposed method uses a fuzzy equivalence relation to cluster the data. For each variable, a set of optimal fuzzy linguistic terms are identified. Both the ideal number of linguistic terms and their degree of overlapping is decided algorithmically using cluster validity and the fuzzy proximity index respectively. Then, a fuzzy rule base is derived which is easy to interpret and applicable to any fuzzy inference engine.
In order to study the selection of the most appropriate fuzzy implication, a class of fuzzy implications derived from conical sections was examined. Generally genuine fuzzy implications performed better over well overlapped membership functions. From this case study, it was demonstrated that the proposed integration of clustering, rule generation and conical fuzzy implications improved the approximation accuracy of FRBS, plus with fewer control parameters. So, any system designer has now the ability to select the best fuzzy implication corresponding to the particular application.
Conclusions
This paper contributes in showing that the selection of fuzzy implications produced via conical sections improves the approximation capability of fuzzy systems. It also presents a new method for fully automatic production of fuzzy rules based on equivalent relation clustering. The parameters of clustering are decided and optimized by the algorithm and not assumed by humans, saving us a significant amount of work. The proposed methodology improves and automates the clustering and finds the impact of various fuzzy implications.