
Abstract
The textile industry has a long history and a large market scale around the world. High-speed loom belongs to the high-end production equipment of the textile industry with the characteristics of high precision, high speed and high efficiency. However, due to its expensive cost and complex structure, there might be significant loss once a high-speed loom breaks down. At present, the monitoring and troubleshooting of high-speed loom operation mainly depend on the experience of maintenance people to carry out inspections, which is inefficient, time-consuming, laborious and less efficient. In this paper, a fault diagnosis method for high-speed loom based on rough set and Bayesian network is investigated. Rough set theory is applied to reduce the attributes of fault causes and results and find the minimum reduction and classification rules. Then, a Bayesian fault diagnosis network model is built, and the probability of each fault cause is calculated to find the maximum probability. Finally, the diagnosis results are obtained. The experimental results have demonstrated the reliability and convenience of the faults diagnosis method for the high-speed loom.
Introduction
Fault diagnosis technology is widely used in agriculture, medical treatment, automobile and household appliances. It has also gained much research efforts in industrial applications. Especially in the textile industry, there is no mature and effective fault diagnosis system for high-speed looms because of its high cost, complex structure and various electrical equipment [1–3]. At present, a high-speed loom is mainly based on on-site signal detection and real-time personnel monitoring. The information of high-speed looms can only be seen in factories, and the real-time data can not be saved and analyzed. When a fault happens, simple faults can be analyzed, but when the fault is complex, it can only be detected and maintained by the staff, and can not be carried out according to the operation data information. Fault analysis is far from the realization of intelligent fault diagnosis. However, with the continuous development of sensor technology, sensors can monitor the running status of high-speed looms in real-time and provide digital feedback. This investigation provides good support for fault diagnosis of high-speed looms and improves the reliability and automation of intelligent fault diagnosis system of high-speed looms.
At present, in the field of industrial fault diagnosis, support vector machine, artificial neural network and decision tree are the main diagnostic methods [4–6]. There are many different models designed to deal with specific areas of problems, such as hydraulic systems, wind turbine systems, engine systems, etc. [7–13] In some previous studies, Wang et al. proposed a multi-feature fusion diagnosis method of support vector machine, which extracts the typical features of fault signals, calculates the weight of each feature with information entropy, and effectively diagnoses the fault of the hydraulic system by SVM classifier [7]. A fault diagnosis method based on a multi-stage fuzzy support vector machine (FSVM) classifier for wind turbine faults is proposed by Hang et al. [8]. Empirical mode decomposition is used to extract fault eigenvectors from vibration signals, and FSVM is used to solve the problem of outlier or noise classification. Experiments show that the method has good diagnostic performance and high diagnostic accuracy. Simani et al. proposed a fault diagnosis method for wind turbine simulation model based on neural network, selected a nonlinear autoregressive network architecture with external input topology and used the high-precision quasi-base model to simulate the normal and fault behavior of wind turbine to test the fault diagnosis scheme and verify its feasibility [9]. Huang et al. proposed a fault diagnosis method combining decision tree and expert system for fuel cell engines. After data preprocessing and feature selection, they imported the training set and stored the rules in the knowledge base to get the fault results and classify the faults [10]. In the field of loom fault diagnosis, there are two kinds of fault diagnosis: fabric fault diagnosis and production system fault diagnosis. Moreover, the fault diagnosis method for high-speed loom is not mature enough. Qayum et al. used a method to find the design repetition quickly [14], applies the image processing technology to detect the textile rotary printing, and extracts the complete design pattern from the acquired image for further processing of fault detection. Seçkin and his team proposed a method about how to simulate the production process and how to use machine learning to regress from time-series data to predict the possible production failure [15], which proved to have a high success rate. Mutlu et al. put forward a method based on FMEA and FTA to analyze the ring-spinning process in the textile industry [16], so that decision-makers and engineers can easily reduce the number of hazards and risks in occupational health and safety in practice. Nazlı et al. combined the advantages of fault tree analysis (FTA) and the algorithm of fuzzy probability estimation of time (BIFPET) to improve the performance of FMEA [17], and successfully applies it to analyze and evaluate the potential risks in the finishing process of a textile company’s fabric dyeing department. GüLTEKİN proposed an image processing algorithm for the automatic detection of wear defects of yarn bobbins and fabrics [18], and achieved relatively successful results. Weldeslasie et al. discussed the diagnosis and correction of yarn faults by the expert system [19], and develops a domain knowledge model using the decision tree. Besides, the prototype system of the yarn fault knowledge base is developed and evaluated. Experiments verify the performance superiority of the prototype system.
These models and methods have some shortcomings: support vector machine is difficult to implement large-scale training samples, and it is difficult to solve multi-classification problems; the network structure of artificial neural network needs to be formulated in advance or modified by a heuristic algorithm in the training process, and excessively depends on learning samples; when dealing with inconsistent data of different types of samples by a decision tree, the information gain tends to be more numerical and easy to over-fit. Bayesian network is an uncertain causal correlation model with a strong ability to deal with uncertain problems. It can express and fuse multi-source information. However, when most attribute information of test samples is missing, the algorithm has a high false alarm rate. Rough set theory is an effective tool for dealing with ambiguity and uncertainty. It can deal with knowledge on the premise of maintaining key information and obtaining minimum knowledge representation. Chang et al. combined rough set theory and Bayesian Network to analyze the causes of influenza, and verified its effectiveness and conciseness [26]. Xie et al. put forward a fault diagnosis method combining the Bayesian network and rough set theory for the transformer system [27]. Experiments verify the feasibility and accuracy of the two methods in the field of transformer system fault diagnosis. Aiming at the blank of fault diagnosis of the high-speed loom, this paper deeply analyzes the fault types, modes and causes of the high-speed loom, and integrates rough set and Bayesian network technology into the fault diagnosis algorithm of the high-speed loom. Firstly, the fault data of high-speed loom is input into the diagnosis system, and the decision table is established by rough set theory. Then the minimum reduction table is obtained by using the reduction function of rough set attributes. Then, the Bayesian network theory is used to build the fault diagnosis model of the high-speed loom. Finally, the fault result of the high-speed loom is output. This algorithm can reduce the complexity of the diagnosis model and realize the fast and accurate analysis of the fault. The specific block diagram of the algorithm is as follows.
The rest of this paper is organized as follows: Section 2 gives an overview of rough set theory and Bayesian network theory. Section 3 enumerates the causes and results of common faults in a high-speed loom system and uses Rough set and Bayesian network theory to introduce the process of building a fault diagnosis model. Section 4 gives an example of high-speed loom fault diagnosis based on rough set and Bayesian network whose feasibility and accuracy are verified by simulation and comparing with several common fault diagnosis methods. Section 5 summarizes this work conducted in this paper.
Rough set theory and bayesian network
Rough set theory
Rough Set, proposed by Z. Pawlak in 1982, is a processing method for uncertain information [22]. Rough set theory is a theory for analyzing and processing data. It can deal with uncertain and incomplete data information well. It can also make full use of existing information, fully mine data, and find relevant knowledge and rules. It is core is to reduce the data, then analyze and process it, and finally get the solution [23–25].
Knowledge theory of rough set
In the theory of rough set, knowledge is regarded as a kind of ability to classify objects. Their attribute sets represent objects, and classification is also represented by attributes, thus generating concepts, which constitute knowledge modules. In other words, knowledge is composed of the classification module of the object domain, which provides the obvious facts about reality, and also has the reasoning ability to deduce the fuzzy facts from the obvious facts.
Given an object domain of interest, any subset X ∈ U is called a concept or category in U, and any concept family in U becomes the knowledge of related U.
Generally speaking, not only a single classification but also some classification families on U. A U-based classification family is defined as a U-based knowledge base, which represents various basic classification methods of one or a group of intelligent institutions. The knowledgebase can be expressed as K = (U, R), where R is a classification on U (also known as an equivalence relation), then U/R is all equivalence classes of R.
In order to express knowledge better, the knowledge expression system of IS =〈 U, A, Va, f 〉 is introduced: U is the theory field; C is the set of conditional attributes, D is the set of decision attributes, C ∩ D = A is the set of attributes; Va is the value field of attribute a ∈ A; f : U → Va is the single shot, so that any element in the theory field u takes attribute a has a unique definite value in Va. This way of definition makes the knowledge of objects easy to describe in the form of a decision table.
Precise set and boundary region of rough set
Given the set U and the set R of equivalence relations, the partition of data set U under the set R of equivalence relations is called knowledge, which is denoted as U/R. A given knowledge base is a relational system K = (U, R), U is a domain, and R is a family of equivalence relations of U.
Let X ⊆ U, R be an equivalence relation on U. When X can be expressed as a certain R basic category, X is said to be definable on R. Otherwise, X is undefined on R. The R definable set is also referred to as the R precision set, and the R undefined set is also referred to as the R inexact set or the R rough set. For rough sets, it can be defined approximately, using two specific sets, namely the upper approximation and the lower approximation of the rough set.
The R-lower approximation of X:
The R-upper approximation of X:
The boundary area BNR (X) is the difference between the upper approximation
Knowledge reduction is one of the core contents of the rough set. It deletes irrelevant or insignificant knowledge while maintaining the classification ability of the knowledge base [20-28].
Let Q ⊆ P, if Q is independent and IND (Q) = IND (P), then for any Q′ ⊂ Q,
IND (Q′) = IND (P) is not valid, and Q is the reduction of P, recorded as RED (P). CORE (P) is the intersection of all reduction attributes, expressed as CORE (P) = ∩ RED (P). The result of the reduction may not be unique, but the core is unique.
The decision table is a unique and important knowledge expression system, which plays a crucial role in decision application. According to the current conditions, it will delete the redundant attributes which have little effect on decision-making and make the final solution without changing its classification ability.
Let IS =〈 U, A, V, f 〉, where A = B ∩ C is the set of attributes, B is the set of all conditional attributes, C is the set of all result attributes, and the knowledge expression system with conditional attributes and decision attributes is called decision table. Two-dimensional tables are commonly used to represent decision tables, in which columns represent the same attributes and rows represent decision rules.
For decision tables, it can be seen that all row and column attributes are composed according to the corresponding equivalence relations, and the reduction of decision tables is of great significance in the application of rough set theory. To simplify the decision table is to delete the unimportant attributes without changing the classification ability.
In this paper, the CEBARKCC attribute reduction algorithm is used to deal with redundant information. Based on information theory, this algorithm uses information entropy as an evaluation parameter to judge the importance of information, so as to achieve the fast query function of attribute set reduction in rough set theory.
CEBARKCC attribute reduction algorithm is as follows: suppose that there are n events (X1, X2, . . . , Xi, . . . , Xn) in a certain probability system X, the probability of the generation of the ith event Xi is Pi (i = 1, 2, . . . , n), when Xi occurs, the amount of information given is called self-information, we look at the number of semesters of self-information as information entropy, and record it as H(X):
We introduce it into the rough set theory, let S = (U, R) be an information system, P ⊆ A, let
The conditional entropy H(Q|P) of attribute set Q (U|IND (Q) = { Y1, Y2, . . . , Ym }) relative to attribute set P (U|IND (P) = { X1, X2, . . . , Xi, . . . , Xm }) is defined as:
And,
Here are some related theorems. Theorem 1:H (Q|P) = H (Q ∪ P) - H (P).
Theorem 2: If U is a domain, P is a set of conditional attributes of U, d is a decision attribute, and domain U is consistent with d on P, then an attribute r in P is unnecessary for decision attributed, then its sufficient condition is H ({ D } |P) = H ({ d } |P - { r }).
Suppose S = (U, R) is a decision attribute system, where R = C ∪ D, C is the set of conditional attributes, D is the set of decision attributes, and A ⊂ C, then the importance of any attribute a ∈ C - A is defined as:
Theorem 3: If H (D|A) = H (D|A ∪ { a }), then POSA∪{a} (F) = POSA (F).
According to the set of cores in the decision table, the CEBARKCC algorithm searches for the condition attribute that makes H (D|B ∪ { a }) the smallest as the condition attribute of the core and repeats this step. When H (D|B) = H (D|C) is obtained, the reduction result of the decision table is obtained. The specific steps are as follows:
Step 1: define decision table S = (U, C ∪ D, V, f);
Step 2: calculate the information entropy H (D|C) of the corresponding condition attribute set C according to the decision attribute set D;
Step 3: calculate the core property set C0. Let Att = C - C0 and B = C0;
Step 4: when |B| = 0, calculate the information entropy H (D|B);
Step 5: if H (D|B) = H (D|C), the reduced decision table will be obtained. If H (D|B) ≠ H (D|C), then continue to step 6;
Step 6: for ai ∈ Att, the information entropy H (D|B ∪ { ai }) of condition attribute set B∪ { ai } corresponding to decision attribute set D is calculated;
Step 7: search for attribute ai. When an attribute ai is searched to minimize H (D|B ∪ { ai }), there will be Att = Att -{ ai }, B = B∪ { ai }.
Bayesian networks include directed no-return graphs and local conditional probability distribution tables, which represent the correlation between nodes and the probability of occurrence of node correlation [29]. There is a formula BN = (G, P) , BN is the abbreviation of the Bayesian network, G is a directed no–return graph composed of many nodes, P represents the conditional probability of nodes. Following is an example of the concepts related to Bayesian networks.
The block diagram of Bayesian network structure is shown in Fig. 2.
Algorithm block diagram.

Bayesian network structure block diagram.
The Bayesian probability distribution formula is as follows:
According to the Bayesian network structure in Fig. 2, the child nodes connected to the parent node are independent of each other.
Aiming at the problem of high-speed loom fault diagnosis, the Bayesian network is constructed according to the following steps [30, 31]:
All the causes and results of high-speed loom faults are expressed as nodes of the network.
It uses directional wires to connect the cause and result of the failure.
The probability of each node can be calculated according to the influence of fault causes on fault results.
Suppose the set U = [X1, X2, . . . , Xn, C] is discrete, where X1, X2 … , X
n
denotes the cause variable, C denotes the result variable, C can take c1, c2, . . . , c
n
. The failure cause variable X
i
can take many values. If the sample Y
i
= [x1, x2, . . . , x
n
], the corresponding failure result c
i
probability is:
Among them, P (x1, x2, . . . , x
n
|c
i
) P (c
i
)/P (x1, x2, . . . , x
n
) is a Bayesian formula, P (x1, x2, . . . , x
n
|c
i
) is a priori probability, P (c
i
) is the total probability of failure result c
i
, P (x1, x2, . . . , x
n
) is the joint probability of failure cause x1, x2, . . . , x
n
. When calculating the posterior probability of a system, the joint probability β is a fixed value because the fault causes of the system are known as x1, x2, . . . , x
n
. Then the upper formula can be simplified to:
Because the specific Bayesian network structure can not be determined with only sample data, it is necessary to learn the Bayesian structure.
Assuming that all the learning samples are m, that is, the number of nodes is m, and can form a Bayesian network, then the number of networks is:
Therefore, it is challenging to retrieve the required network from such a large number of networks, so it is essential to choose an efficient search method. At present, there are two commonly used search methods: scoring optimization and constrained search. The scoring optimization method improves the Bayesian network structure by scoring function, and finally finds the most suitable network model. Although the constraint method is more intuitive, it has higher complexity and is more sensitive to errors. This fault diagnosis system adopts the K2 scoring optimization method:
In the [0,1] interval, there exists a joint probability distribution of several random variables, assuming that there are d variables μ
i
, and
Then its probability density function is:
Its statistics are:
Then the probability distribution is Dirichlet distribution. Assuming that the prior probability of parameter β of Bayesian network obeys Dirichlet distribution, then:
If the network structure is known, the process of parameter learning is scoring by querying historical data or expert knowledge, then deducing the conditional probability of each node in the network, and determining the probability distribution table of nodes.
In the case of incomplete data, it is more difficult to get the appropriate network structure than in the case of complete data. This fault diagnosis system learns from the network when the fault data is incomplete.
Bayesian classifier
Bayesian classifiers are NB (Naive Bayesian Classifier), TAN Bayesian Classifier, GBN (General Bayesian Classifier). The fault diagnosis system uses NB (Naive Bayesian Classifier) model.
NB (Naive Bayesian Classifier) is a classification method based on Bayesian Theorem. It is called “Naive” because it assumes that “the features of the items to be classified are independent of each other,” thus simplifying the problem and effectively reducing the complexity of classification [32, 33]. When the NB (Naive Bayesian Classifier) model is used to calculate the probability of high-speed loom failure, the total probability p (C
j
) of each fault in the sample is calculated first, and the frequency of the fault occurrence can calculate the prior probability of the fault, that is:
Among them,
Through the above method, the probability p (x1, x2, . . . , x n |c j ) p (c j ) of all the fault results in sample Y i = [x1, x2, . . . , x n ] is calculated, and the final diagnosis result is found to be the most probable fault result.
Causes and results of common faults
A high-speed loom system is a complex system that integrates machinery and electricity. Given the different faults of high-speed looms, there is occasionality between faults and fault causes. A fault may be caused by one or more fault causes, and a fault cause may also cause one or more faults [34, 35]. High-speed loom faults include mechanical and electrical faults. Because the probability of mechanical faults is minimal and the signal acquisition is difficult, this paper mainly analyses and diagnoses the electrical faults of high-speed looms. The high-speed loom is a system. When something goes wrong, the situation becomes very complicated.
By consulting the literature and debugging on-site, this paper sorted out the common causes of high-speed loom faults, solutions and results of faults. They are shown in Tables 1 and 2.
Type of cause of failure
Type of cause of failure
Fault result types
Tables 1 and 2 number the common failure causes and failure result in types of high-speed loom respectively, to facilitate the subsequent processing by rough set and Bayesian theory. The cause and result of the failure are not merely corresponding. For example, the fault of let off the servo and take-up servo can cause the fault of let off, and at the same time, it may lead to the phenomenon that the tension is too large or too small. In order to get an accurate fault result type, we need to apply the follow-up algorithm for analysis and processing.
In the actual work, the acquisition of fault causes is uploaded to the remote server after the local operation is completed. We can judge whether the running state of each part of the loom is healthy by the circuit hardware detection system developed by ourselves, and obtain the data source of fault judgment.
In the process of high-speed loom fault diagnosis, rough set theory is applied to reduce attributes of fault causes and results to find the minimum reduction and classification rules, and then the Bayesian fault diagnosis network model is built according to classification rules. Finally, the probability of each fault reason is calculated by the Bayesian fault diagnosis network, and the maximum probability of the fault reason is the final diagnosis. Figure 3 is the flow chart of fault diagnosis.

Fault diagnosis flowchart.
In this paper, the prior probability p (C i ) of high-speed loom fault results and the strength of fault cause set are obtained by analyzing nearly 500 high-speed loom fault data that were collected in the field. Because there are few electrical data of high-speed loom at present, some subjective experience is temporarily added to the causal relationship between the cause and result of some faults [36–38]. The prior probability table of high-speed loom faults is shown in Table 3.
Lever failure prior probability table
The prior probability in Table 3 refers to the probability of fault occurrence obtained from previous experience and analysis. It is an inference based on the existing knowledge. It comes from subjective experience estimation. A proper and accurate prior probability of fault can improve the accuracy of fault diagnosis of the high-speed loom.
The strength table of the causality of high-speed loom faults is shown in Table 4.
High-speed loom failure causality strength table
Table 4 shows the connection between the failure cause and failure result, that is, the probability P (A j |C j ) of A j in the case of failure C j . The above table is equivalent to the decision table when using rough sets. The data in the table is a constant value. First, the data must be processed into discrete data. The size of the data reflects the strength of the causal relationship between X and A. Here, R ij is used to represent the strength of the relationship between them.
To discretize the values in the table: 0 < R
ij
⩽ 0.25, R
ij
= 1; 0.25 < R
ij
⩽ 0.5, R
ij
= 2; 0.5 < R
ij
⩽ 0.75, R
ij
= 3; 0.75 < R
ij
⩽ 1, R
ij
= 4;
The decision table of high-speed loom fault diagnosis is shown in Table 5.
High-speed loom Failure Decision Table
Applying rough set theory to attribute reduction of Table 5, two minimum attribute sets {A1, A2, A3, A5, A6, A8, A9} and {A1, A2, A4, A5, A6, A8, A9} are obtained. Select {A1, A2, A3, A5, A6, A8, A9} as the minimum reduction. The minimum reduction is shown in Table 6.
Minimum reduction
According to the relationship between fault causes and fault results in Table 6, a network model based on NB (Naive Bayes) is constructed, as shown in Fig. 4.
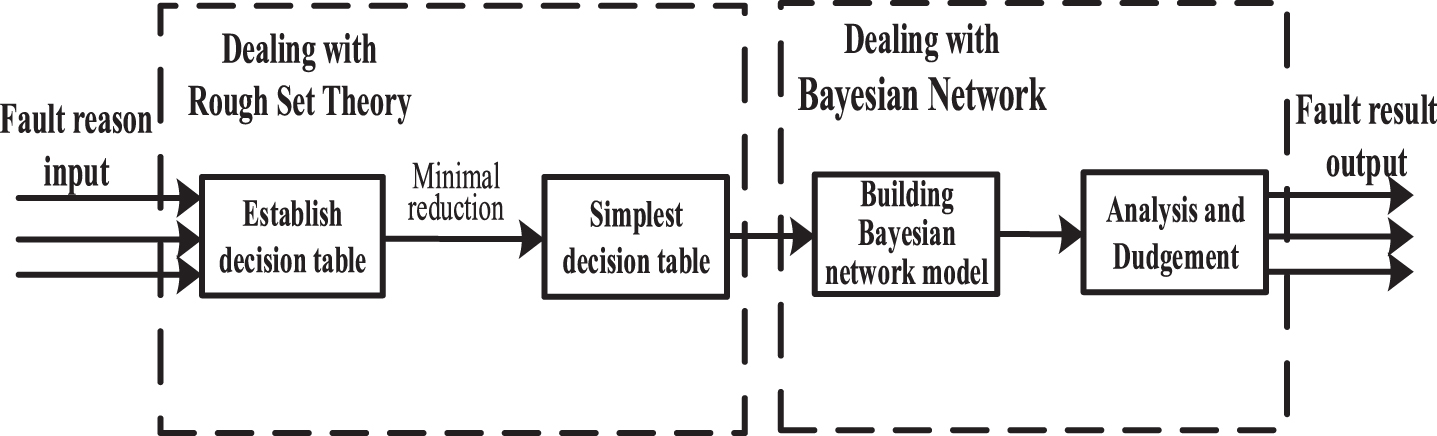
Lobe fault Bayesian model.
From Fig. 4, it can be seen that there is uncertainty between the causes and results of high-speed loom faults, which is a one-to-one, many-to-many relationship. Then the model is learned, because the sensor information of the high-speed loom is not detected at the same time, but detected at different angles when the spindle of the high-speed loom moves to different angles, so this paper uses incremental learning method to make the node information better expressed in the network. Figure 5 is a Bayesian network learning structure.
Bayesian network structure learning.
A simple example of fault diagnosis
Following is an example to verify the feasibility of the high-speed loom fault diagnosis model:
In a certain experiment, when the high-speed loom stops due to weft breakage in normal operation, it stops at the weft stopping angle, that is, A1 = 1, A2 = 0, A3 = 0, A5 = 0, A7 = 0, A8 = 0, A9 = 0. Combining the High-speed loom Fault Causality Intensity Table and Fault Prior Probability Table, the probability of each fault condition is obtained as follows:
Similarly available:
From
Therefore:
After the above calculation, the probability of P (C1|A1, A2, A3, A5, A6, A8, A9) is the highest, so the diagnosis result is the fault of weft accumulator. In the field fault detection, weft storage is found to be short of yarn, which results in weft breakage stopping and is consistent with the diagnosis results.
Using this method to diagnose high-speed loom fault has the advantage of high fault-tolerant rate. Even if the phenomenon of misdiagnosis occurs, it can also be sorted according to the probability calculated in the process of diagnosis, and then it can be repaired, which greatly reduces the workload of maintenance personnel.
Comparison of Several Fault Diagnosis Methods
The feasibility of fault diagnosis method for high-speed looms based on rough set and Bayesian is verified above, but the accuracy is not proved yet. In this paper, “Weka” (software for data mining) is used to simulate common fault diagnosis methods and fault diagnosis systems using rough set and Bayesian combination of fault diagnosis methods, and then verify the accuracy of fault diagnosis, through statistical diagnosis of the correct number of samples to calculate the accuracy of diagnosis.
Among the table, the “*” represents the missing high-speed loom attributes.
Table 7 is reduced by rough set theory, and Table 8 is the minimum reduction.
High-speed loom Failure Data Sheet
High-speed loom Failure Data Sheet
High-speed loom Failure Data Table After Attribute Reduction
In the table, the “*” represents the missing high-speed loom attributes.
“Weka” software is used to train and simulate the samples of Naive Bayesian Network, Neural Network and Decision Tree. The number of training samples and test samples are shown in Table 9. Moreover, the simulation results are shown in Fig. 6.
The Distribution of Sample Number
The correctness of Fault Diagnosis for Several Diagnostic Methods.
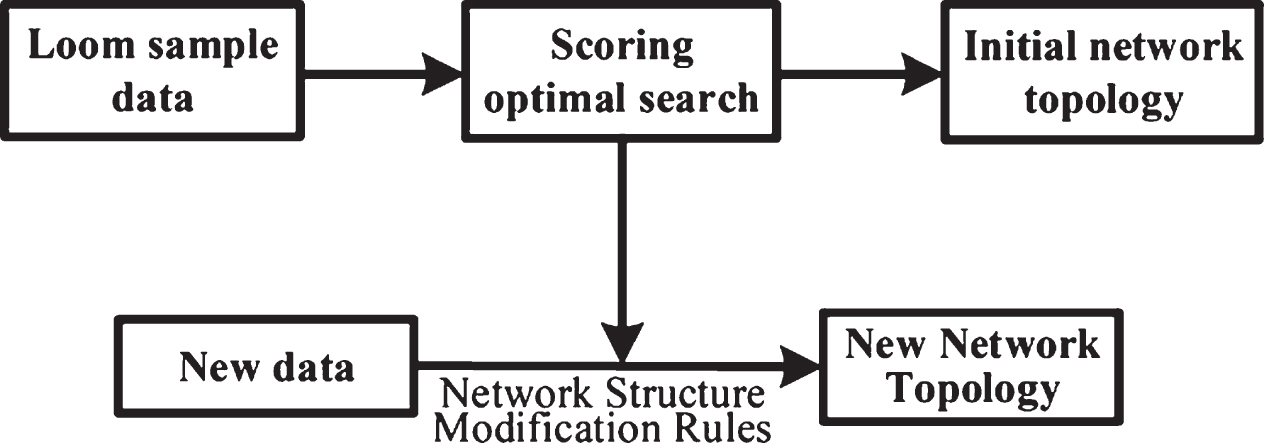
Figure 6 shows that in the case of incomplete fault data of high-speed loom, the fault diagnosis accuracy of naive Bayesian network simplified by rough set theory is much higher than that of decision tree and neural network, with an average accuracy of 89.6%. Moreover, the accuracy of the fault diagnosis method fluctuates less, which means that the algorithm has high stability.
The false alarm is an important parameter to improve detection accuracy. The false alarm rate of several diagnosis methods is calculated by large-scale data simulation. The results are shown in Fig. 7.
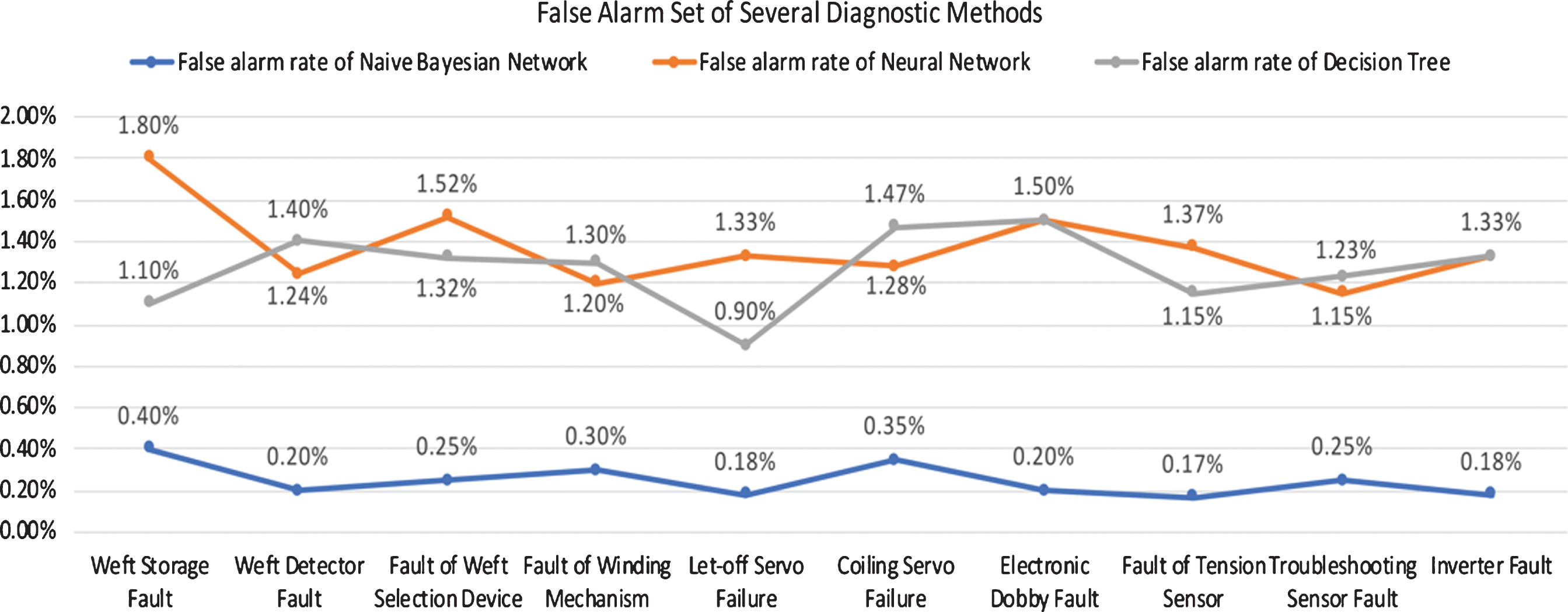
False Alarm of Several Diagnostic Methods.
As can be seen from Fig. 7, the fault diagnosis method of rough set and Bayesian network is used to get a low false alarm rate, which proves the high detection accuracy of this method from another perspective.
In conclusion, in the fault diagnosis system of the high-speed loom, the method of combining rough set and Bayesian networks not only has higher diagnosis accuracy, but also has a lower false alarm rate, which proves that the performance of this method is superior.
For a system, if facing any fault, the system does not exceed the permitted scope of the index and can meet the needs of users, then the system is robust.
In order to test the robustness of the algorithm, this paper adopts software fault injection technology. Because the high-speed loom belongs to a mature and stable industrial machine, and there will be no high concurrent faults, so we give up the pressure test and mainly use the method of error information input to test the robustness of the algorithm. 800 error information generated randomly and 200 fault reasons collected on-site for fault diagnosis tests are taken as input and transmitted to the fault diagnosis system to compare the accuracy of the diagnosis results. In order to judge the robustness of the algorithm. The initial success rate and the current success rate are shown in Fig. 8.
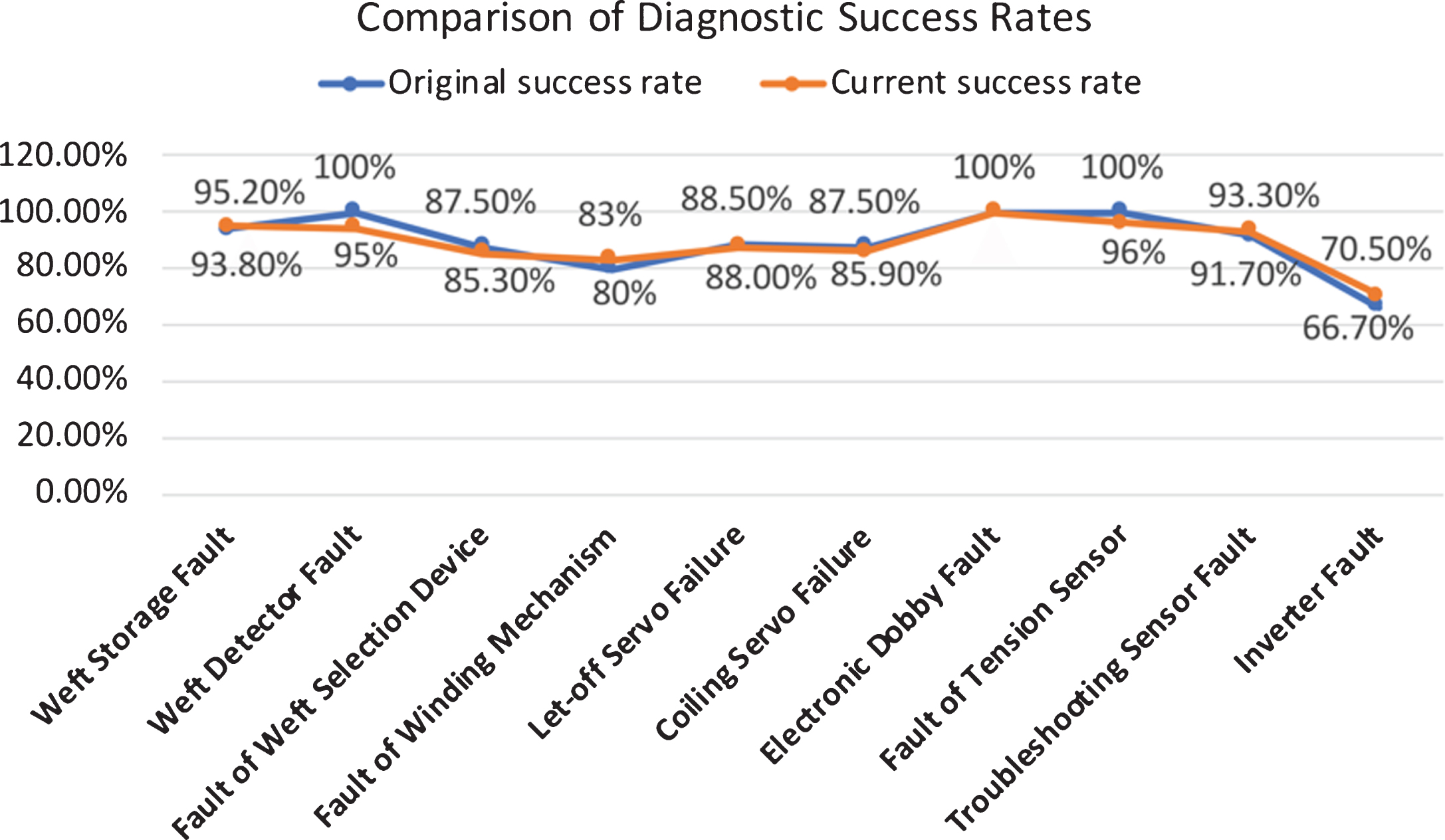
Comparison of Diagnostic Success Rates.
It can be seen from Fig. 8 that even if a large amount of wrong information is input, the diagnosis success rate of the fault diagnosis system only fluctuates within a limited range, and the deviation of the diagnosis result obtained is not significant, which proves that the algorithm has good robustness.
Through a comprehensive analysis of a high-speed loom system, this paper mainly introduces the results, causes and solutions of common high-speed loom faults. In this paper, rough set theory and its attribute reduction method, Bayesian network theory, and its network model building method are briefly introduced. A high-speed loom fault diagnosis model based on rough set theory and Bayesian network is constructed. Then the feasibility of the model is proved by an example. The reason for the failure is determined by the production field control system through the circuit hardware detection method to determine the operation status of each part of the high-speed loom. After the failure reason is found, it is transferred to the remote cloud server. Further fault detection is carried out on the remote server. When the fault detection system on the remote server receives the fault information, it will not directly process it, but first trigger a status flag bit and timer, when it receives the same fault information again after a while, it will process the information. This can ensure that the input is reliable fault information, not a false alarm. In the whole process of system processing, the hardware detection and network status of the production site are maintained. All of these ensure that the algorithm is stable and reliable. A large number of missing or incomplete high-speed loom fault data are collected in the field. The naive Bayesian network, neural network and decision tree are trained, studied and verified by data mining software Weka. Firstly, rough set theory is used to reduce the fault data of high-speed loom. Then train the data. After the training and learning of the naive Bayesian network, the fault reason data is input to get the fault result. The accuracy of the method is 89.6%, and the false alarm rate is about 0.2%. In this paper, the method of wrong input is used to analyze the robustness of the system algorithm. Even if there is a large number of wrong input interference, the diagnosis system can still work typically, and the success rate of diagnosis fluctuates in a limited range, which proves that the system algorithm has good robustness Compared with other methods, the results of rough set and naive Bayesian network are better than other methods. It shows that the fault diagnosis system has better performance under the condition of incomplete data and missing information.
Footnotes
ACKNOWLEDGMENTS
This work was supported by the National Key Instrument and Equipment Development of the National Key R&D Program of China (Grant No. 2017YFF0106404), the National Natural Science Foundation of China (Grant No. 51675160), the Hebei key research and development plan project (Grant No. 18214407D), and the Tianjin Science and Technology Commissioner Project (Grant No. H0302).