
Abstract
The widespread application of infrared human action recognition in intelligent surveillance has attracted significant attention. However, the infrared action recognition dataset is limited, which limits the development of infrared action recognition. Existing methods for infrared action recognition are based on features in the same sample, without paying attention to within-class differences. Motivated by the idea of weighting video information, this paper proposes a novel infrared action recognition framework to reweight the samples of training sets named REWS to solve the problems of limited infrared action data and the large within-class differences in the infrared action recognition dataset. In the proposed framework, we first map infrared action video data to a low-dimensional feature space, and use the cosine similarity between the feature data of the training set and the testing set to determine the weight of the training set samples. Each training set sample has an independent weight. Then, a support vector machine (SVM) is trained by the training sets with weights to recognize the infrared actions. Experimental results demonstrate that our approach can achieve state-of-the-art performance compared with hand-crafted features based methods on the benchmark InfAR dataset.
Introduction
Human action recognition is an automatic analysis of a piece of video to obtain the actions performed by the human body. It is widely used in daily life such as intelligent driving, intelligent nursing and intelligent monitoring [1]. Compared to visible light human action recognition, infrared action recognition is insensitive to illumination changes and can be used for 24-hour monitoring. At the same time, infrared action videos captured by thermal imaging cameras can suppress shadows, object occlusion and other interferences lower than human body temperature. Therefore, infrared action recognition has attracted increasing attention in recent years [2–7].
With the development of deep learning [8–14], human action recognition of visible light based on convolution neural network (CNN) has been developed rapidly. However, compared to the visible light human action recognition dataset, the infrared action recognition dataset size is small, and the infrared action recognition video lack of color and detailed appearance information. So the existing visible light human action recognition algorithms cannot be directly applied to the infrared action recognition [3–5].
Recently, some deep learning algorithms for infrared action recognition have been proposed. Gao et al. [4] used the two-stream CNN framework to evaluate the infrared action recognition dataset InfAR built by them. The two-stream framework replaced the original video image steam network in the visible light two-stream framework with optical-flow motion-history-image(OF-MHI) steam network, the new two-stream framework contained OF-MHI steam network and optical-flow(OF) steam network. Jiang et al. [5] introduced the two-stream 3D CNN network framework for infrared action recognition, and introduced the discriminant code loss layer of the objective function. The two-stream framework contained the original infrared image net and OF net. It achieved better performance than [4] on the InfAR dataset. Liu et al. [6] used third-stream CNN for infrared action recognition to describe the movements of body parts across the whole video, to avoid generating information irrelevant to motion information based on local temporal information. The third-stream network was composed of spatial-temporal, local temporal and global temporal information. However, the infrared action dataset size is small, which makes it difficult for the deep learning model to be trained well. They used the third-stream CNNs framework as a feature extractor rather than a classifier, so that the benefits of hand-crafted and deep-learned features can be shared, the average precision of the experiments was the best on the InfAR dataset.
Liu et al. [7] proposed a hand-crafted features extraction method for infrared action recognition. Inspired by the idea of transfer learning, they used visible light data as auxiliary for infrared action recognition, and built the visible light dataset XD145 that had the same action with the InfAR dataset. XD145 as auxiliary data recognized infrared action with semi-supervised transfer learning, in the hand-crafted features extraction method achieved the best performance. But in reality, it is impossible to have a visible dataset and an infrared dataset with exactly the same action.
So the existing methods for infrared action recognition, mainly focused on extracting spatial temporal, local temporal and global temporal information of infrared action video, or used visible light action data as auxiliary data to recognized infrared action, etc. These methods focus on how to extract valid feature information in the same video action, and have achieved good results. However, the sample differences between the same type of action video have not attracted enough attention in infrared action recognition dataset. In fact, different samples in infrared action recognition dataset have different degrees of importance.
In daily life, there are many industrial products being produced every day, and the products will be graded. The infrared action recognition dataset is without exception. For getting closer to real life in the process of collecting infrared action recognition dataset, it is often necessary to consider complex factors such as ambient temperature, light intensity, background clutter, occlusion of objects [4]. In the process of collection, it is impossible for each sample of the same class to have the same above factors exactly. There are some samples, the occlusion is serious or the movement trajectories are not obvious. Moreover, there are few infrared action recognition datasets that are currently published. The dataset size is small compared to the visible dataset KTH [15], HMD51 [16], and UCF101 [17]. In order to highlight multi-scene in the infrared action recognition dataset, the within-class differences are large. If each sample in the training set has the same weight, it will affect the overall average precision, which is obviously very unwise. The contributions of this paper include: A new infrared action recognition framework that could reweight the samples of training sets named REWS is proposed. We notice that there are a great within-class differences in the multi-scene infrared action recognition dataset, and it is necessary to reweight the training set samples when training the model. We propose a formulation that can be used to reweight the samples of high-dimensional video data. For multi-scene video infrared action recognition, the weight of each training set sample can be quickly distributed. Compared with the hand-crafted features and deep learning based methods, our method achieves the state-of-the-art results in infrared action recognition. The proposed REWS can achieve good performance efficiently, while the deep learning method requires time-consuming pre-training to obtain a robust model [4–6]. In addition, we don’t use visible light data as auxiliary to recognize infrared action compared to [7], so don’t require time-consuming feature alignment and generalization processes.
The rest of this paper is organized as follows: Section 2 reviews related work reported, and highlights the difference of our framework. Section 3 describes the proposed method. The experimental results are presented in Section 4. Section 5 concludes the paper with the remarks and future work.
Related work
Some methods for samples reweighting have been applied to domain adaptation (DA) and transfer learning (TL) [18], and other related fields. In the field of hyperspectral image classification, Aydemird et al. [19] used a subtractive clustering-based approach to select the initial labeled training samples to solve the problem that hyperspectral images have only a small number of labeled samples and classification performance is highly dependent on the size of labeled data. It provided the most useful sample for graph-based self-training. Rakesh et al. [20] proposed a Semi-Supervised Metric Transfer Learning framework to solve the problem about using normal Euclidean distance function fails to capture the appropriate similarity or dissimilarity between samples. This framework can achieve better performance in the field of image classification by learning instance weights to reduce both statistical and geometric distribution, and by learning the regularization distance metric to minimize the within-class co-variance and maximize the between-classes co-variance. Hubert et al. [22] proposed a semi-supervised landmark selection algorithm for different data structures in the source domain and target domain, which can identify representative cross-domain feature data. However, this method is a landmark selection algorithm based on data features, with a large amount of statistical calculation. Li et al. [23] proposed a prediction reweighting framework for different data distributions in the training and testing data in the domain adaptation. This framework is to reweight predictions of the training classifier on testing data according to their signed distance to the domain separator, which is a classifier that distinguishes training and testing data. They propagate the labels of target instances with larger weights to ones with smaller weights by introducing a manifold regularization method. In this way, the label of the target instance with larger weight is propagated to the target instance with smaller weight. This framework has achieved good results in image-to-image, text categorization, and text-to-image recognition benchmark datasets. Li et al. [21] proposed an unsupervised domain adaptation framework to learn two different transformations for the source domain and target domain, independently, so as to map the data into a shared latent space using different transformations. Then reweighting of the source domain samples in the shared latent space. The extensive evaluation of multiple standard benchmarks and large-scale datasets such as classification, text categorization and text-to-image recognition verifies the superiority of the method.
Transfer learning and heterogeneous domain adaption have two or more source domain and target domain, but the video data of infrared action recognition is a single domain. Therefore, the transfer learning algorithms based on samples reweighting cannot be directly applied for single domain infrared action recognition. So we are not simply applying this idea, we need to change it to be used for infrared action video with high-dimensional data, and modify to achieve the single domain of samples reweighting.
The weighting idea in reference [30–32] is mainly aimed at the key feature information in the same human action video. When deep learning methods are used for human action recognition, the model training process also involves weight adjustment, but deep learning methods based on the key features of a single sample [4–6, 10–12]. Besides, the training set samples are independent, and each training set has the same weight. However, the model we proposed adds the weight of the training set sample rather than just the features of a single sample. Each training set sample has an independent weight. Our samples reweighting method is based on samples, which can avoid the huge amount of calculation caused by the feature weight adjustment process based.
According to our surveying, there is currently no paper to implement reweight the samples of training set for infrared action recognition. Firstly, we use improved dense trajectories (iDTs) [24] method to extract the infrared action feature in the video, and adopted efficient Locality-constrained Linear Coding (LLC) [25] to encode the features of actions and principal component analysis (PCA) to reduce the features dimension. Then, we map the features of the dimension reduction in an infinite dimensional reproducing kernel Hilbert space (RKHS). Finally, by using the new training set features with the weights, the support vector machine is trained and the testing sets are recognized.
The proposed method
REWS approach of samples reweighting proposed in this paper, the infrared action recognition framework, is shown in Fig. 1. The proposed REWS consists of three stages. In the first stage, the improved dense trajectories features of the infrared action video are extracted. Aiming at the problem of the huge amount of calculation and memory consumption caused by projection of high-dimensional video features data, we firstly encode the high-dimensional video feature data by LLC and then conduct PCA dimensionality reduction, so as to obtain low-dimensional features. In the second stage, the encoded action features are mapped in the RKHS. We learned a projection for the training and testing set to ensure the original data structures of both. The cosine similarity between the training and the testing set is used in the RKHS to determine the weight of training set sample. In the third stage, the support vector machine (SVM) is trained with the weights of training set and training sets, and finally the testing set labels are output.

Framework of samples reweighting for infrared action recognition. The proposed REWS consists of three stages, feature extraction and encoding, reweighting samples and classifier training.
Feature extraction and encoding
In this paper, we adopt to improve dense trajectories (iDTs) [24] to extract features of action in infrared video. iDTs obtains the motion track through the intensive sampling of the human motion video, and eliminates the influence of camera motion on the accuracy decline. The process of feature extraction is more focused on the movement of the human body. For iDTs, SURF feature and optical stream are used to calculate the projection transformation matrix of the current frame and the previous frame to obtain the motion trajectories. The feature information is extracted by iDTs, including trajectories, histograms of optical flow (HOF), histograms of oriented gradient (HOG) and motion boundary histograms (MBH). HOF calculates the histogram of the direction and amplitude information of the optical flow. HOG calculates the histogram of the gray image gradient. MBH calculates the histogram of the optical flow image gradient, which can also be understood as the HOG feature calculated on the optical flow image. Since the optical flow image includes the x direction and the y direction, MBHx and MBHy are calculated respectively. We choose the default parameter setting for iDTs.
For iDTs, a large number of local trajectory descriptors are obtained due to the intensive sampling of human motion trajectories. So the number of interest points obtained by sampling is large, which will lead to high computational complexity and memory consumption. We adopt Locality-constrained Linear Coding (LLC) scheme to represent the iDTs to avoid this problem. LLC method projects each local descriptor into its local coordinate system by using position constraints, and obtains the final projection coordinate through the maximum pool. The k nearest neighbors search is firstly carried out to accelerate the approximation speed, then a constrained least square fitting problem is solved. LLC uses multiple bases to represent iDTs, which can bring less quantization error while maintaining local smoothness and sparsity. On the premise of considering both efficiency and construction error, the LLC coding scheme is applied to iDTs with 5 local bases, the codebook size of all training and testing sets is set to 4000.Therefore, the dimension of the encoded iDTs features is 4000.
Principal component analysis
After LLC coding, the features are still high-dimensional and somewhat redundant features. Furthermore, the encoded action features need to be projected into a low-dimensional RKHS. Reweighting of high-dimensional features will bring a great amount of calculation. Therefore, effective features in RKHS are limited. It is impossible to project all features into low-dimension space. So we need a compact representation of the features. For this reason, the commonly used linear dimension reduction method principal component analysis (PCA) is used to preprocess these high-dimensional features. By maximizing the sample variance, PCA method ensures that the new feature dimensions are not related to each other. Firstly, by eliminating the correlation between features, then adjusting the scaling factor to make new features have the same variance. New features that retain more than 99% of the original features representation, and feature dimensions can be reduced from 4000 to less than 600.
Samples reweighting
For matching the first-order and high-order statistic of the coding action features, we reweight sample of the training sets in the low-dimensional RKHS, rather than the original space. In view of the problem that separately projecting the training and testing set into RKHS would lead to inconsistent data structures, we learned a projection for the training and testing set to ensure the original data structures of both. Our method learns a feature map, ψ represents transforming the original feature x to RKHS, X12 indicates that there are 12 different action classes features as follows:
We use simple, efficient linear kernel to construct the kernel matrix K, Y to represent new features that project original features into RKHS. P denotes the projection matrix, the projection matrix P is calculated by (4). New features representation can be calculated by the follow:
If the training set sample and the testing set sample have k nearest neighbors, they will have the same label. The distance between samples with high similarity is relatively close, and the distance between samples with low similarity is far. Yj and Yl are used to represent the new features of the training and testing set after projection transformation. To keep the training and testing set data projected into the same structure in RKHS, we minimize the follow:
Where L = D-W, L is the graph Laplacian matrix [29], D is a diagonal matrix, its ith diagonal element is calculated as the sum of ith row of W, Xj represents the new features. W is a symmetric adjacency characterizing the sample relationship. For the problem that there is a great within-class differences in the dataset of benchmark infrared action recognition, we used the cosine similarity between the samples of the training set and the unlabeled testing set to determine the weight of the training set samples for the first time. The matrix is obtained by cosine similarity as follows:
The weight of training set sample is determined by judging the cosine similarity between the training set samples and testing set samples. The sample weight with high similarity in the training and the testing set is increased, the sample weight with low similarity is reduced. Where
Therefore, by introducing the learned new features into (3), the trace of the matrix is denoted by
Currently, the sample weight adjustment process of transfer learning related reference [21] doesn’t achieve the weight adjustment of high-dimensional video data. Moreover, its algorithm is applied in multiple domains, but infrared action recognition is a single domain. So it is impossible to directly apply its weight adjustment process to infrared action recognition. Firstly, we need to extract the high-dimensional feature data of infrared action video. Secondly, we reduce the dimension of the high-dimensional feature data to obtain the low-dimensional data before projection. In the reweighting samples stage, we learn a projection for the training and the testing set, and use the cosine similarity to calculate the weight of each training set sample after projecting the low-dimensional data. In summary, our goal is to project original features into RKHS, keep the new training and testing set features with similar data structures, and reweight for new features learned. Therefore, our objective function can be expressed as:
Finally, according to the constrained optimization theory, the Lagrange multiplier λ is introduce:
The decomposition of (6) is optimized to obtain the projection matrix P, where the parameters β and λ are both greater than zero. The matrix G is the sub-gradient of ∥P ∥ 2,1, Pi is the ith row of the P matrix, G is calculated by the follow:
In this paper, we learn [21] proposed method abstracted feature vectors into graph vertices by:
In this way, the training set sample weight α is calculated by the follow:
Input infrared action video, calculate iDTs features, use LLC coding, and reduce the dimensions by PCA to get the underlying feature representation. Set the number of iterations T, λ, β, number of neighbors, and subspace dimensions. Calculate the kernel matrix K, initialize the matrix G, and construct the Laplacian matrix L. Calculate the projection matrix P. The original features obtained after PCA dimensionality reduction are projected in an RKHS using the projection matrix P. SVM introduces the training set labels to classify the testing set data and outputs the testing set labels. Determine the weight of each training set sample by the cosine similarity of the training and the testing set. Determine whether the number of iterations T reaches the maximum value. If the maximum value is not reached, return to step d to start the next iteration. When the maximum value is reached, the testing set labels are output.
Experimental results
Datasets
The InfAR dataset [4] consists of 600 human action videos taken by infrared thermal imaging cameras. The dataset contains videos of 12 different action classes: fight, handshake, handclapping, hug, jog, jump, punch, push, skip, walk, wave1 and wave2. Each action class was performed by 40 volunteers. Each action class contains 50 video clips, and each of which lasts an average of 4 seconds. The frame rate of the action video is 25 fps and the resolution is 293×256. The shooting scene of video is in line with the actual situation, containing one or multiple actions performed by one or several persons in each video, reflecting the complexity of the background, seasonal differences, within-class differences, and presence or absence of occlusion, etc.
Sample example diagram of 12 different action classes with simple and complex backgrounds in InfAR dataset is shown in Fig. 2. Each subgraph in Fig. 2, on the left is the sample with a simple background, on the right is the sample with a complex background. We mark the action being performed with a red box in the picture on the right to see more clearly from the Fig. 2. It’s important to note that we define a simple background and a complex background simple, which is not simply defined by several persons as background in each action video sample. Figure 2 is just to make it more intuitive that the details of each sample are different for the action of same class. There are no two identical samples, but some samples have very high similarity to other samples of the same class, and some samples have very low similarity to samples of the same class. In our algorithm, infrared video samples with many people as background can also be recognized as highly similar to other samples of the same class. Although there are several persons as background in these samples, they have less occlusion than the same class samples, the trajectories of actions are more obvious. The sample with low similarity is that the human is performing actions in video may be obscured by others, resulting in the action is not obvious. Normally, the proportion of these sample is less, but it exists in the actual situation, which cannot be removed directly.

Example diagram of a simple background sample and a complex background sample. The image on the left of each action is a sample with a simple background, and the image on the right is a sample with a complex background. The complex movements in the background are marked in red boxes for clarity.
In order to further illustrate the sample differences of the same class action, Fig. 3 gives an example of a trajectory figure of sample with simple background and sample with complex background. According to the reference [24], the trajectory figure is the feature information figure of infrared action recognition. The trajectory figure of fight in Fig. 3(a) is more obvious, and the background in Fig. 3(b) is more complex than that in Fig. 3(a), because the others in the background are still moving, making the trajectories of the fight action less obvious. From the Fig. 3 we can see, there is a certain gap between the trajectories of the same type of action, indicating that there is indeed a difference between different samples of the same class.

This is an example of two different sample trajectories of the same fight action. Trajectories of sample with simple backgrounds and sample with complex backgrounds: (a) simple and (b) complex. In the figure, the green represents the trajectories of human action, and the red dots are the trajectory positions in the current frame.
In our experiments, 50 video clips of each action category in InfAR dataset are randomly split into training and testing sets, 30 samples as training sets, and the rest samples as testing sets. Figure 4 shows the parameter settings of the REWS.
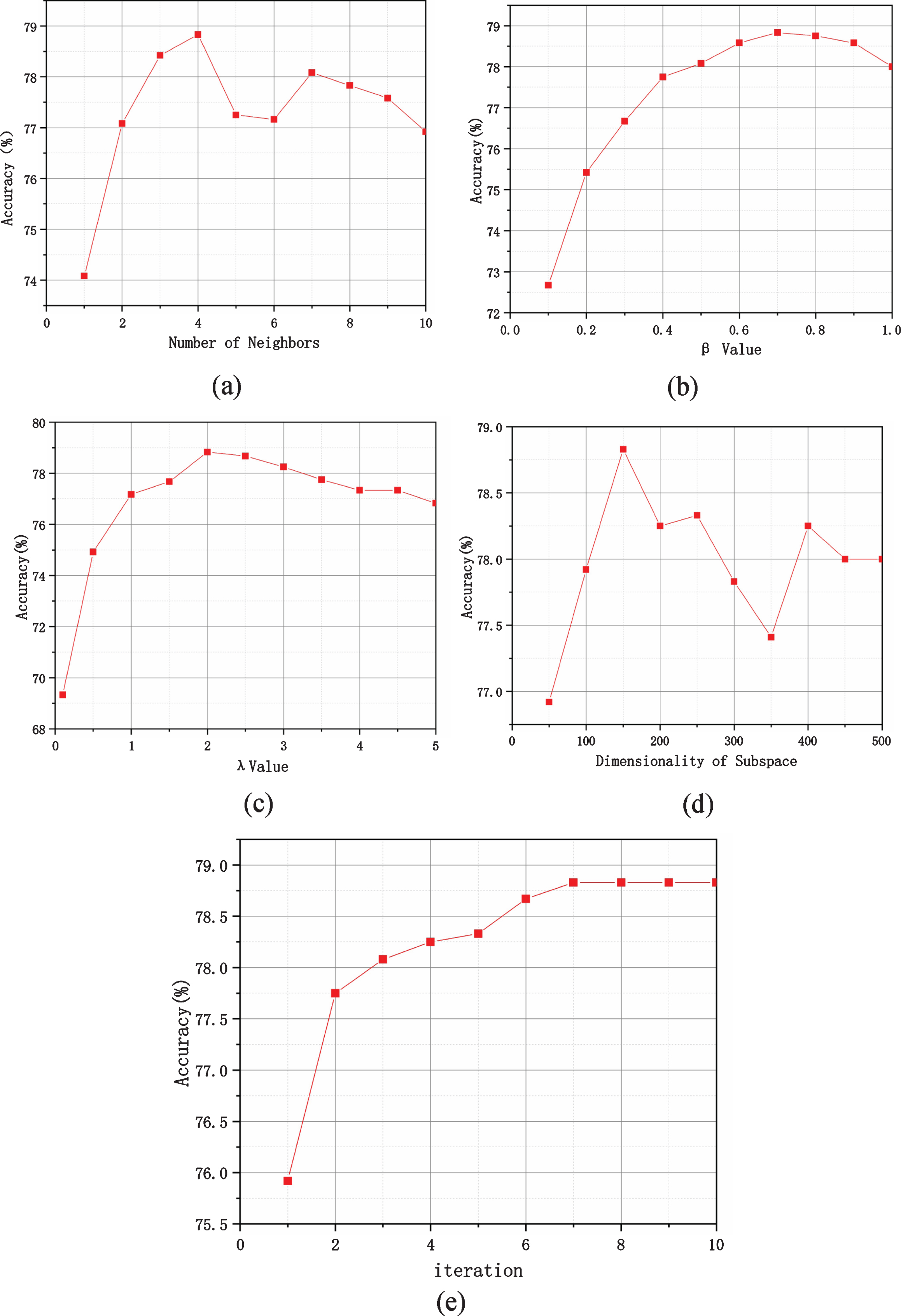
The sensitivity of each parameter of our REWS is (a)–(e). The a, b, c, d and e represent the number of neighbor k, β,λ, dimensionality of subspace and number of iterations, respectively. It can be seen that compared with the value change of other parameters, the value of β is the most sensitive.
The a, b, c, d and e in the Fig. 4 represent the number of neighbor k, β, λ, dimensionality of subspace and number of iterations, respectively. For each evaluation, we repeat the experiments with the same setting 5 times and report the average accuracy. Accuracy represents the average precision of 12 classes action. It can be seen from the Fig. 4 that when they were taken 4, 0.7, 2, 150 and 7 respectively, the average precision of all action categories are up to 78.83%. It can be seen that compared with the value change of other parameters, the value of β is the most sensitive. If the value changes by 0.1, the accuracy will change greatly, because β determines the weight of the training set sample, which also reflects the importance of samples reweighting in the training sets.
In order to show the superiority of our proposed framework REWS, Fig. 5 shows two confusion matrices. We directly train the SVM as a baseline without reweighting of the training set. In Fig. 5(a) and (b) are the baseline and our proposed method, respectively. In the confusion matrix of each class action precision in InfAR dataset, the main diagonal is the precision of each action. It can be seen from the Fig. 5 that the proposed method has higher classification accuracy for almost all action classes. We draw the precision of each action into Fig. 7 to have a more intuitive contrast. As shown in Fig. 7 that the most obvious precision improvement is the punch and push actions. As can be seen from Fig. 2(g) and (h), punch and push are so similar that it is even difficult for human to tell them apart. But our proposed algorithm has a significant improvement over the baseline, further illustrating the effectiveness of our proposed method.
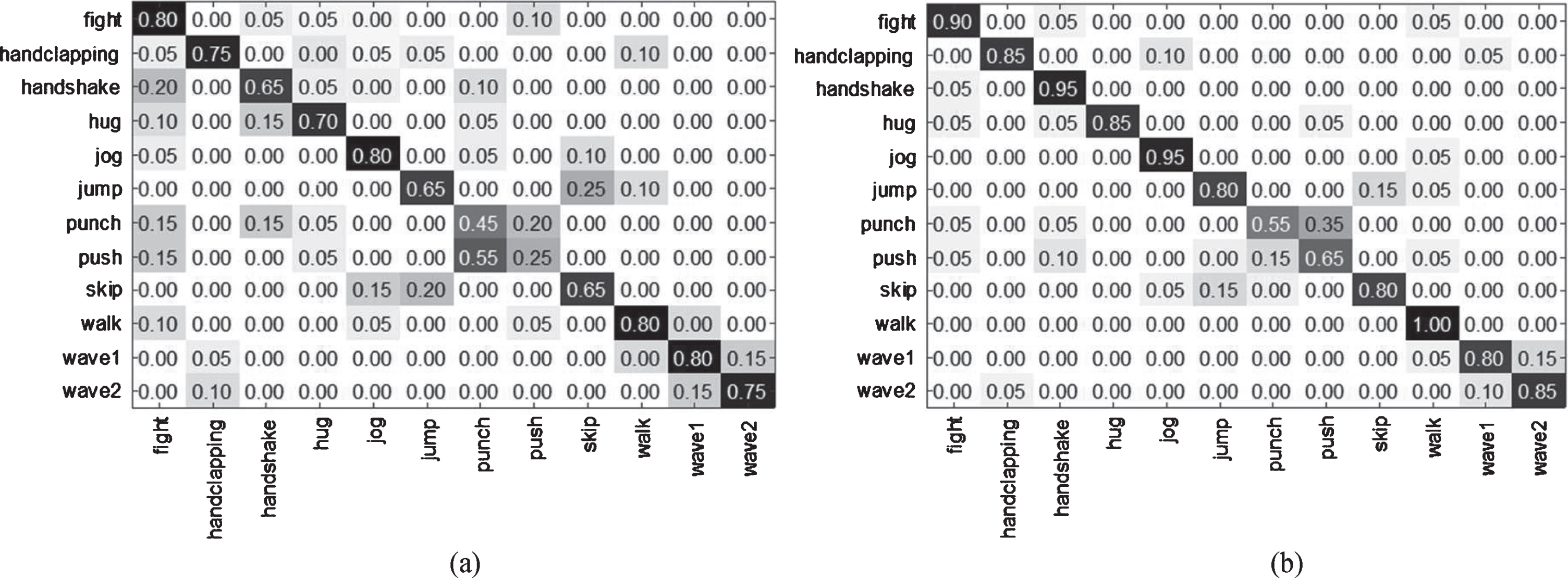
The confusion matrices of the precisions of each action: (a) the baseline and (b) the proposed method. In the confusion matrix of each class action precision in InfAR dataset, the main diagonal is the precision of each action.
To reflect classification results of 20 testing set samples of each class action, we present the testing result distribution graph of each action. Figure 6(a) shows the distribution results of the SVM directly trained without the weight of the training set. Figure 6(b) shows the testing set result distribution of our proposed REWS. The total number of testing set samples in the two pictures are 240. Moreover, almost each type of action in Fig. 6(b) recognizes more correct samples than in Fig. 6(a).

The testing result distribution graph of each action: (a) the baseline and (b) the proposed method. In the test result distribution diagram for each action, the main diagonal is the correct number for each action. The total number of testing set samples in the two pictures are 240.
Table 1 shows the comparison between REWS and other action recognition methods. For comparison purposes, all methods are implemented using the same experimental setup. The average precision of our method is 78.83%; it is improved compared with the baseline without samples reweighting 6.91%. Our method and CDFAG method extract the same trajectories features, after adding weights to all training sets, the average precision was 3.41% higher than CDFAG. We do not require to introduce visible light data for infrared action recognition, because in reality it is impossible to have two visible and visible datasets with the same action. So we don’t require time-consuming feature alignment and generalization process. Compared with the two-stream CNNs and 3D CNNs, the average precision is 2.17% and 1.33% higher, respectively. Besides, compared with the state-of-the-art deep learning method currently only 0.42% less, reaching the most advanced performance. Our approach achieved state-of-the-art results in infrared action recognition compared with hand-crafted and deep learning based methods.
Comparison of REWS and other infrared action recognition methods

Comparison of the precisions for each action of SVM and REWS. The proposed method has higher classification ac-curacy for almost all action classes.
However, TSTDDs approach composed of hand-crafted and deep-learned features. The three-stream CNNs model they proposed requires a combination of trajectory constraint sampling (hand-crafted features) and pooling strategy (deep-learned features), which makes the model more complex and difficult to implement. In addition, the deep learning method requires time-consuming pre-training to obtain a robust model. Compared with TSTDDs approach, the approach REWS we proposed only needs to adopt an efficient method improved dense trajectory (hand-crafted features) to achieve the performance of TSTDDs. The proposed REWS has no complex image stream extraction process and is relatively simple and easy to implement. At the same time, the model we proposed don’t require time-consuming pre-training process [4–6], and can balance classification accuracy and time efficiency.
We execute our codes with MATLAB R2017b on a 64-bit Windows 10 PC with Intel i7 CPU 6-core 3.20 GHz and 16 GB RAM. The average time for each video clip feature extraction is 24.55 s, the LLC encoding requires 5.77 s. For sample reweighting of each training set, the average time is 9.43e-05 s.
This paper we propose a novel infrared action recognition framework to reweight the samples of training sets. For the first time, we noticed the importance of reweighting the training samples in the multi-scene infrared action recognition. Each training set sample has an independent weight. The weight of the training set sample was determined by the cosine similarity of the training and the testing set. The model is obtained by training SVM which uses the training set sample data with weight. Then the model is used to classify the testing set obtaining the average accuracy 78.83%, which is higher than the existing hand-crafted extraction feature method. Our samples reweighting method is based on samples, which can avoid the huge amount of calculation caused by the feature weight adjustment process based. Our future work is to extend samples reweighting method based on samples into deep learning methods to improve the performance of infrared action recognition. In addition, the existing visible light action recognition method is modified for infrared action recognition.