
Abstract
Aiming at the problem that the Aspect-based sentiment analysis in Chinese has low recognition rate due to many steps, this paper proposes an improved BiLSTM-CRF model based on combine the Chinese character vector and Chinese words position feature, which can extract attribute words and sentiment words jointly simultaneously, while extracting Polarity judges of sentiment words. Experiments show that the improved model improves the precision rate by 9.2% 13.32%, recall rate improves 0.48% 21.29%, F-measure improves 7.33% 15.74% compared with Conditional Random Fields (CRF) model and Long Short Term Memory (LSTM) model on the self-built 6357 mobile reviews dataset. The experimental results show that the model improves the accuracy of Aspect-based sentiment analysis and can effectively obtain the information required by users need in evaluation texts.
Keywords
Introduction
Product evaluation is consumer feedback on various aspects of the product, such as product quality, merchant service attitude, and logistics speed. These reviews not only provide references to other consumers with purchasing decision, but also provide strategies to merchants to improve products and services. How to quickly process and analyze the evaluation data, and mine the user’s sentiment contained in the product features from the text comments, and then reuse these sentiments is a hot topic in current text mining research [1].
Sentiment analysis or opinion mining is a computational study of people’s opinions, emotions, emotions, evaluations and attitudes on products, services, organizations, individuals, problems, events, topics and their attributes. It is a sub-task of text classification and natural language processing. One of the more important research directions in Natural Language Processing (NLP) [2]. Sentiment analysis is mainly divided into two categories. One is coarse-grained sentiment analysis, which is the overall sentiment of a chapter or sentence. The core of its analysis is to determine whether the sentiment reflected by a subjective text is positive, negative or neutral, etc. Such as E-commerce website evaluations have “good”, “middle”, and “bad” tags. The other is Aspect-based sentiment analysis, which focuses on judging their emotional attitudes at the attribute level or word perspective. For example, the comment “The phone looks beautiful and the battery is not durable”. When the attribute word is “appearance”, the emotional word is “very beautiful” and its emotional polarity is positive. When the attribute word is “battery”, its The emotional word is “not durable”, and its emotional polarity is negative. Because coarse-grained sentiment analysis only gives a whole sentence of emotional polarity, there is no too much reference value in the product, and it may even mislead consumers. Therefore, Aspect-based sentiment analysis is needed for comments to obtain product attributes and corresponding emotional polarity.
Aspect-based sentiment analysis is specific to the feature of the product, and uses information extraction technology to extract comment elements such as comment subjects, evaluation features, evaluation words, and text sentiment in the comments [3]. Providing valuable detailed information for practical applications.
This paper mainly research on two issues of recognition of attribute words and sentiment words and sentiment polarity classification in the Chinese mobile reviews. The evaluation element extraction problem is transformed into a sequence labeling problem. By improving the BiLSTM-CRF model, a Chinese character vector and Chinese words position combined as input BiLSTM-CRF model is proposed. By comparing experiments results with different models have confirmed the effectiveness of the proposed model.
The rest of the paper has been organized in the following manner: Section 2 discusses the existing work in literature. Section 3 presents the related theoretical research and methodology. Section 4 describes the proposed model. Section 5 presents the experimental work and results. The conclusion and future work is presented in Section 6.
Related works
At present, there are two main methods for Aspect-based sentiment analysis: 1) Firstly, attribute words and sentiment words are extracted separately, and then the attribute words and sentiment words are matched, finally, the sentiment words are polarity judged. In this method, attribute words extraction, emotional words extraction, the matching of two, and the judgment of the polarity of emotional words all may cause recognition errors, resulting in a low final recognition rate. 2) The method of joint extraction of emotional words of attribute words, Then judge the polarity of the emotional words. This method has one less step than the previous method, and the recognition rate can be improved slightly. In the process of Aspect-based sentiment analysis, the more steps of recognition, the greater chance of misrecognition. When the sentence contains only one attribute word and emotional word, the method of extracting attribute words and emotional words separately can meet the needs, but There are multiple attribute words and emotion words in a sentence in a review. If the method of extracting attribute words and emotion words separately is still used, the final recognition result will be poor. Therefore, this paper adopts the method of joint extraction of attribute words and emotional words to improve the accuracy of extraction of evaluation elements.
The traditional method of jointly extracting attribute words and emotion words is to use templates. Meng Yuan et al. [4] adopted a method based on domain ontology to extract feature point pairs. Jiang Tengmin et al. [5] focused on the analysis of syntactic structure, and excavated eight rules to extract the attribute words and emotion words from financial data. In machine learning algorithms, the extraction of evaluation objects and evaluation words can be achieved by using sequence labeling. Recent studies have shown that the sequence processing of text input is beneficial to improve the overall performance [6]. The mature models in sequence labeling tasks include Hidden Markov Model (HMM) [7], Conditional Random Field (CRF), and deep neural networks. Shi Hanxiao et al. [8] identified the sentiment words and attribute words in the review sentence by improving the conditional random field (CRF) algorithm. Huang et al. [9] used bidirectional Long-short-term memory (BiLSTM) network and CRF model for sequence tagging. This experiment is mainly used for part-of-speech tagging, chunk analysis and named entity recognition tasks. Wang et al. [10] proposed use a combination of recursive neural networks and CRF to extract evaluation objects and evaluation words. Al-Smadi et al. [11] first used the BiLSTM-CRF model to extract attribute words and sentiment words from the Arabic hotel dataset, and then used the LSTM model to judge sentiment polarity. Han Hu et al. [12] used a multi-layer attention mechanism neural network model to achieve sentence-level and text-level text sentiment classification.
Through the analysis of the above researches, it is found that the research on Aspect-based sentiment analysis has made some progress, but because Chinese sentiment analysis is late start compared with many countries, and because of the particularity and complexity of Chinese language, Aspect-based sentiment analysis in Chinese has led to There are two issues: Chinese Aspect-based sentiment analysis process have low recognition rate due to many steps Lack of large-scale standard Chinese Aspect-based sentiment analysis corpora.
Aiming at above issues, the contributions of this article are mainly: This article converts the evaluation element extraction problem into a sequence labeling problem, studies the method of data labeling definition, and proposes an improved BiLSTM-CRF model to jointly extract attribute words and emotional words and perform polarity judgment on emotional words. The steps of Aspect-based sentiment analysis are reduced, and the accuracy of Aspect-based sentiment analysis is improved. Due to the large number of English public data sets for fine-grained sentiment analysis [13–16], but there are few public datasets used for Chinese Aspect-based sentiment analysis, and they may not suitable to this topic, so this paper use self-built datasets.
Methodology
Data preprocessing
Chinese word segmentation
Chinese word segmentation is to divide the sequence of Chinese characters into single Chinese character, which is a basic step in NLP in Chinese. Word segmentation is not required in the English field. In English, words are separated by spaces. In Chinese, There is no interval between Chinese words, and different Chinese character combinations have different meanings. Because of the difference, Chinese word segmentation is extremely important for Chinese natural language processing. This article uses the jieba word segmentation tool to implement the word segmentation function.
Stop word processing
In order to improve efficiency, After word segmentation of text is used to filter out high-frequency but low-influence words, such as the pronouns “ ”, “
”, “ ”, the preposition “
”, the preposition “ ”, and the tone particles “
”, and the tone particles “ ”, “
”, “ ”, etc. In addition, English numbers, punctuation marks, emoticons, and special symbols often appear in comments texts. These symbols or words not only contribute little to the determination of emotional polarity, but also affect the speed and effect of model calculation. In this paper, the stopwords of Harbin Institute of Technology and Baidu stopwords are used to remove stopwords in the Chinese texts.
”, etc. In addition, English numbers, punctuation marks, emoticons, and special symbols often appear in comments texts. These symbols or words not only contribute little to the determination of emotional polarity, but also affect the speed and effect of model calculation. In this paper, the stopwords of Harbin Institute of Technology and Baidu stopwords are used to remove stopwords in the Chinese texts.
Data annotation definition
Corpus refers to large-scale language examples in statistical natural language processing. In the field of affective analysis, the corpus of coarse-grained affective analysis and Aspect-based affective analysis are different.
There are many researches on Aspect-based sentiment analysis corpus in English. Wiebe et al. [17] annotated the English news corpus, and manually annotated the emotional elements such as viewpoint holder, evaluation object, subjective expression and polarity. Hu and Liu [18] manually marked the product evaluation objects, evaluation polarity and evaluation intensity of English product field comments. Task4 [19] of semeval-2014 provides English data sets in notebook and hotel fields. Zhang Yue [20] proposed a Chinese online shopping evaluation annotation method based on ten key information. From the above analysis, we can see that there are more English corpus and less Chinese corpus in affective analysis corpus, and almost no Chinese corpus for aspect-based affective analysis.
The most used English Aspect-based sentiment analysis corpus is SemEval-2014’s notebook and restaurant corpus. It includes sentences, attribute words of sentences, and the corresponding polarity of attribute words and the position which influence the polar words. However, the corpus does not directly label the emotional words, and it is not intuitive to use the range of emotional words for polarity judgment. In Zhang Yue’s labeling method, the ten elements based on viewpoints are the source of the viewpoint, the scope of the viewpoint, the product object, the concept node of the ontology, the scope of the viewpoint expression, the head of the viewpoint, the negative, the degree, the tendency and the degree of tendency [20]. The annotation method of Zhang Yue’s is too detailed, which increases the difficulty of labeling and reduces the labeling efficiency; and the data storage format is XML, which need much time and great efforts to be parsed when reading the data. This paper comprehensively considers the advantages and disadvantages of the two above-mentioned labeling methods, and combines the needs of sentiment analysis of product evaluation attribute levels to develop a four-element labeling system, which is defined as follows:
In the formula:
Sentence——the original Chinese comment;
Aspect ——attribute words in the review, if there are multiple attribute words separated by English semicolons;
Emotion ——emotional words in sentences;
Polarity ——It is the polarity judgment of emotional words, which are divided into positive, negative and neutral, the value is (1, 0, -1).
This paper uses the method based on word {B, I, O} labeling. B indicates the beginning of the target Chinese word, I indicates the remaining part of the target Chinese word, and O indicates other words that do not belong to the target Chinese word. The specific annotations are defined shown in Table 1:
Experimental data label definition
Aspect-based sentiment analysis needs to obtain the evaluation object and evaluation point from the text, and then judge the sentiment polarity of evaluation point. The specific evaluation objects and evaluation views are shown in the following example: Example 1: Example 2:
 ,
,  .
. ,
,  .
.
The underlined Chinese words in the example sentences are the evaluation objects, and the words in parentheses are the evaluation opinions. The definition of evaluation object is extended in the product comment review to the product itself, the attributes of the product, and some services related to the product.
The final output of Aspect-based sentiment analysis in this paper is: Example 1 output: Example 2 output:
 ,
,  .
. ,
,  .
.
Conditional random fields model
Conditional Random Fields (CRF) is a conditional probability distribution of another set of output sequences given a set of input sequences, which has a good effect in the sequence labeling task. The linear chain conditional random field model is widely used in aspect-based extraction task. The linear chain condition random field applied to the product Chinese review text model is shown in Fig. 1 below:
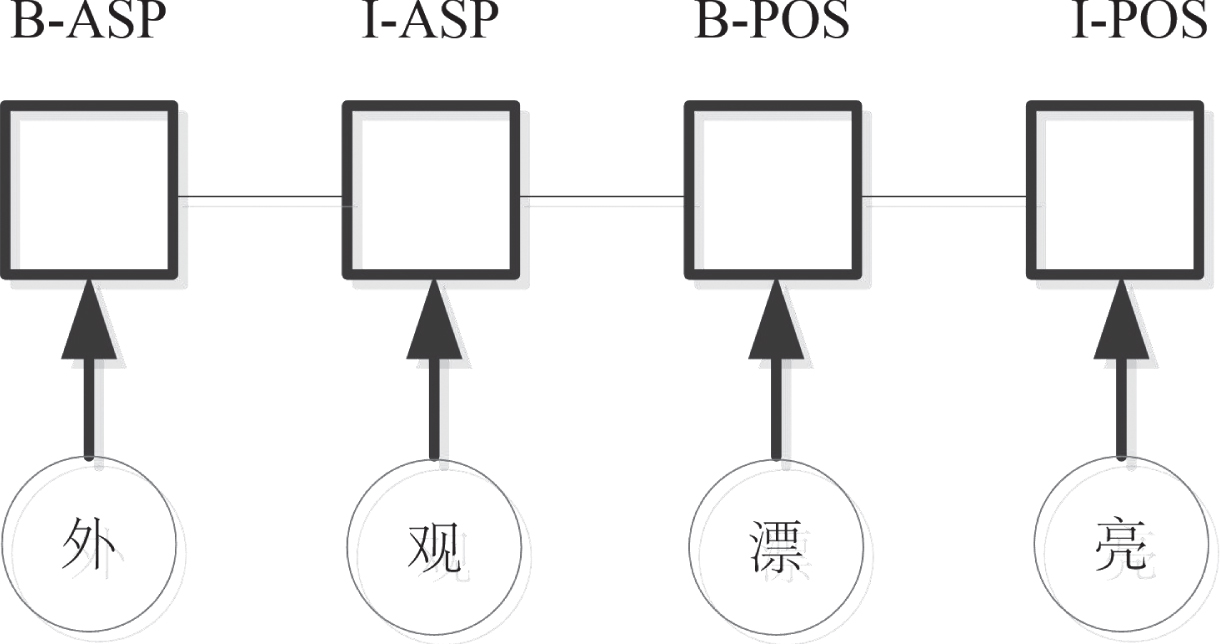
Sequence labeling model based on CRF.
In the example “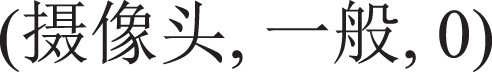 ”, “
”, “ ” is an attribute word, and “
” is an attribute word, and “ ” is an emotional word. According to the definition of the experimental data in Table 1, “
” is an emotional word. According to the definition of the experimental data in Table 1, “ ” is the first Chinese character of the attribute word, which label is “B-ASP”; “
” is the first Chinese character of the attribute word, which label is “B-ASP”; “ ” is the remaining word of the attribute word, the corresponding label is “I-ASP”; “
” is the remaining word of the attribute word, the corresponding label is “I-ASP”; “ ” Is the first Chinese character of an emotional word with a positive emotional polarity, the label is “B-POS”; “
” Is the first Chinese character of an emotional word with a positive emotional polarity, the label is “B-POS”; “ ” is the remaining part of the emotional word, and the corresponding label is “I-POS”. The linear chain conditional random field model predicts the label corresponding to each word. The advantage is that the label information of adjacent words is considered, while the disadvantage is that it cannot handle the problem of long-distance dependence. For example, in the sentence “
” is the remaining part of the emotional word, and the corresponding label is “I-POS”. The linear chain conditional random field model predicts the label corresponding to each word. The advantage is that the label information of adjacent words is considered, while the disadvantage is that it cannot handle the problem of long-distance dependence. For example, in the sentence “ ”, the linear distance between the attribute word “
”, the linear distance between the attribute word “ ” and “
” and “ ” is 6, when the CRF model label “
” is 6, when the CRF model label “ ”, the “
”, the “ ” label influence whit it will be reduce, leading to a reduction in the accuracy of the annotation.
” label influence whit it will be reduce, leading to a reduction in the accuracy of the annotation.
At present, the most commonly used deep learning models in the field of natural language processing are Recursive Neural Network and Recurrent Neural Network (RNN). Among them, the recurrent neural network is a network with memory function, which is very suit to solving sequences label problem.
Recurrent Neural Network (RNN) can obtain the current input and previous input information. The output is determined by the input of the current moment and the output of the previous moment. RNN uses back propagation and the mechanism of memory can solve the problem of continuous sequences [21]. For serialized feature tasks, such as sentiment analysis, keyword extraction, speech recognition, machine translation, and stock analysis, it is suitable to use RNN.
In theory, RNN can process infinitely long sequences and can capture long-range dependent information, but in practice, the longer the input sequence, deeper the network, and the problem of gradient explosion and gradient disappearance during network training will eventually lose learning information about nodes farther away from the current node. Therefore, researchers have proposed a variant structure of RNN called Long Short-Term Memory (LSTM) [22], which avoids long-term dependence and gradient disappearance through the design cyclic layer.
Bi-directional long-short term memory model
Bi-directional Long-Short Term Memory Model Model (BiLSTM)has the advantage of being able to consider both past features and future features, but it cannot fully consider the association between adjacent tags, while CRF takes full advantage of local features to consider the interaction of tags between neighboring words, but requires artificially constructed features engineering. Therefore, combining BiLSTM with CRF gives full play to the advantages of both and makes up for the shortcomings of both. The BiLSTM-CRF model takes the context feature representation learned by BiLSTM as the input of CRF, and CRF learns the label-related constraints from it to ensure the validity of the final labeled sequence. The model structure is shown in Fig. 2.
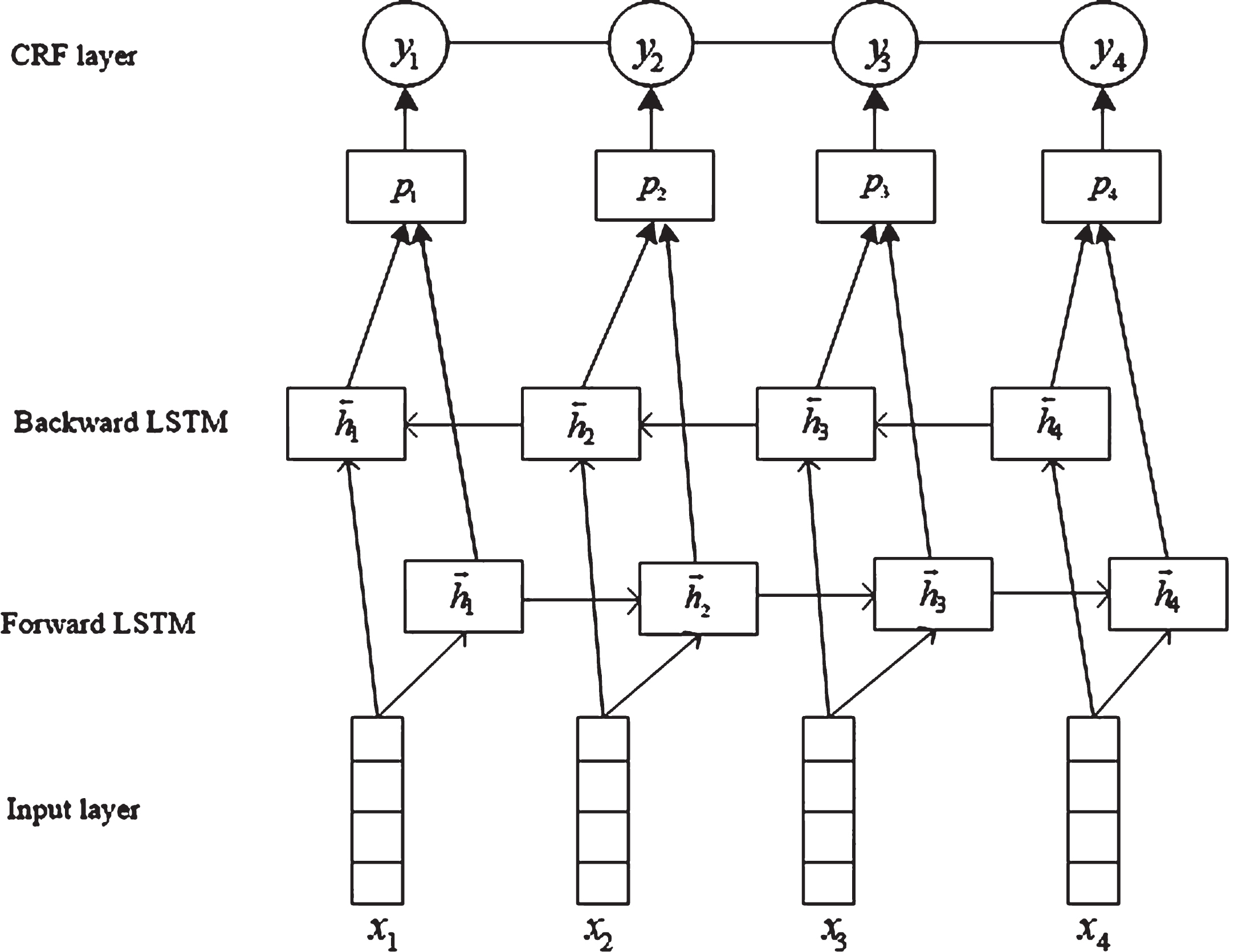
BiLSTM-CRF sequence labeling model.
In the BiLSTM-CRF model of Fig. 2, the first layer is the input layer, and the word or words in the sentence are converted into vector features by pre-training or random initialization, then them input into the model.
The second layer of the model is the bidirectional LSTM layer, which automatically extracts sentence features. The vector (x1, x2, …, x3) sequence is the input of the bidirectional LSTM. The output sequence (h1, h2, …, h
n
) of the forward LSTM and the output sequence (h1, h2, …, h
n
) of the reverse LSTM are spliced by position to obtain a complete sequence
The third layer of the model is the CRF layer, which performs sequence-level annotation of sentences. There is a transfer matrix A, A
ij
in the CRF layer that represents the transition probability of the Ith label being transferred to the Jth label. For a sequence y = (y1, y2, …, y
n
) of predictive labels corresponding to an input sequence x = (x1, x2, …, x
n
), the predicted score is calculated as follows:
It can be seen from the equation that the prediction score of the entire sequence is equal to the sum of the scores of the respective positions, and is determined by the output matrix P of the bidirectional LSTM layer and the transfer matrix A of the CRF, and the normalized probability is:
The model is trained to obtain the optimal labeling sequence by maximum likelihood estimation. The formula is as follows:
The model uses the dynamic Viterbi algorithm to solve the optimal path in the prediction process as shown in the equation:
BiLSTM-CRF generally uses word vectors or words vectors as input. Although the words vector contains rich semantic information, the words vector has the disadvantage of unregistered words; the word vector has the advantage of solving the unregistered words, but the word vector lacks some specificity, the semantic information is weak, and it is impossible to distinguish one Chinese word in different phrase its different meanings.
In order to compensate for the defects of word vectors and the lack of word vectors, this paper uses the combination of word vectors and words position features as input, so that the input layer contains richer semantic information. The model structure is shown in the Fig. 3:

BiLSTM-CRF sequence labeling model based on vector and word position information.
The first layer of the model in Fig. 3 is the input layer, the second layer is the bidirectional LSTM layer, and the third layer is the CRF layer. The second and third layers of the model are same as the BiLSTM-CRF model of Fig. 2, the difference is that the input layer of this section model is a combination of the singele Chinese character vector and the Chinese words position feature to include more useful information. The next step is to focus on the processing of the input layer.
Since the model cannot directly process the Chinese text, all inputs need to be processed into corresponding identifiers. The training data of this paper consists of two parts: Chinese characters and corresponding label information. Therefore, it is not only necessary to convert Chinese characters into vectors, but also to convert the label information into specific identifiers. Then, after the text sequences are segmented, the position information of the words is extracted. Finally, the vector, the tag information identifier, and the word position information are taken as common inputs. The word is converted into a word vector, and the label information is defined according to Table 1 for the Chinese comments:
The label information of the above formula is identified by a digital form, and is defined as follows:
The Chinese word position feature is to judge by the length of each part after the sentence segmented. If the length is 1, it is a single word, and it is identified by the number “0”. If it is a Chinese phrase, the Chinese word of the phrase is identified by the number “1”, the last Chinese word is identified by the number “3”, and the rest is identified by the number “2”. For example: “ ,
,  ” The label for this sentence shown in Table 2:
” The label for this sentence shown in Table 2:
Mobile phone evaluation

The input to model is:
The first line in the formula is the position of the Chinese word in the vocabulary, Each number corresponds to a 100-dimensional word vector. The second line is the identifier corresponding to the example sentence, and the third line is the word position feature of the example sentence.
Data collection
There are very few public datasets about Aspect-based sentiment analysis in Chinese public data, Moreover they may not meet the research needs of this topic. Therefore, this article selects a brand mobile phone of Jingdong Mall in China as the research object, crawled the mobile phone reviews as the experimental dataset. By scraping a total of 7,416 pieces of data, through deduplication and filtering of irrelevant reviews, 6357 experimental data are finally obtained. According to the ratio of 6 : 2: 2 to divide the training set, validation set, and test set. The final training set has 3811 data, the validation set has 1273 data, and the test set has 1273 data.
Experimental design
The training process of the model is to find the most suitable parameters by continuously iterating on the training set, so that the model can better fit the data of the training set. The Adam (Adaptive Moment Estimation) algorithm is used to converge the model and update the parameters. The Adam algorithm is a first-order optimization algorithm of the stochastic gradient descent algorithm, which can iteratively update the network weights based on the training data to make model converge faster. At the same time, in order to prevent over-fitting, Dropout is introduced at each node of the training network, and regularization is used to prevent over-fitting, in case the model has higher prediction accuracy on the training data, while the lower prediction accuracy in the test data. To improve the generalization ability of the model. The parameter settings for the improved BiLSTM-CRF model are shown in Table 3:
Model parameter setting
Model parameter setting
In order to verify the performance of the improved BiLSTM-CRF model in Aspect-based sentiment analysis tasks, this paper uses precision (Precision, P), recall (Recall, R) and F-value (F-measure) as evaluation criteria for evaluation factor extracted results. The evaluation elements refer to attribute Chinese words and emotional Chinese words. Defined as follow:
TP——The number of evaluation elements extracted by the model is the correct number. FP——The number of evaluation elements extracted by the model is the error number FN——The number of evaluation factors not extracted by the model.
In order to verify the effect of the improved BiLSTM-CRF model in the mobile reviews dataset, three comparative experiments were designed: the word vector comparison experiment of different dimensions, experiments 2 shown the comparison between improved BiLSTM-CRF model and BiLSTM-CRF model before improvement. Experiments 3 between the modified BiLSTM-CRF model and different models of CRF and BiLSTM.
Experiment 1: Experiment of the word vector dimension. In order to verify the influence of the vector dimension on the results of Aspect-based sentiment analysis, based on the improved BiLSTM-CRF model, the input Chinese word vector dimensions were tested from 100, 150 and 200 dimensions. The experimental results are shown in Table 4 as follows:
Word Vector Experiment Results for Different Dimensions
Word Vector Experiment Results for Different Dimensions
From the experimental results in Table 4, when the dimension of the word vector increases from 100 to 200, the precision, recall and F-measure of the model decrease slightly, with the precision decreased by 1.29% and the recall falling by 3.11%, F-measure decreased by 2.21%. The reason for the decline may be the length of the comment in the reviews corpus. The length of the corpus comment is shown in Fig. 4:

Histogram of the length of the comment statement in the corpus.
As shown in the Fig. 4, the length of the statement is concentrated below 100 words, only a small portion of reviews length exceeds 100, but does not exceed 200. As seen from Table 4, the F-measure of the word vector from 100 dimensions to 150 dimensions decreased by 0.34%. Therefore, when the vector dimension is gradually increased by more than 100 dimensions, some redundant information may be generated, which results in the model getting worse when extracting semantic features. Therefore, the Chinese word vector dimension of Experiment 2 and Experiment 3 is fixed at 100 dimensions.
Experiment 2: Comparison between original BiLSTM-CRF model with the improved BiLSTM-CRF model. The input of the original BiLSTM-CRF model is a 100-dimensional Chinese word vector. The input of the improved BiLSTM-CRF model is a combination of a 100-dimensional Chinese character vector and Chinese characters position feature. The experimental results of the two models shown in Table 5:
Model improvement comparison experiment results
It can be seen from Table 5 that the improved BiLSTM-CRF model is improved by 1.28%, 0.24%, and 0.75%, respectively in terms of precision, recall, and F compared to the original BiLSTM-CRF model. The improved model adds a word position feature to the input layer. The word position feature not only compensates for the lack of specificity of the single Chinese character vector, but also increases the semantic properties of the Chinese word of the vector, which is more effective compare with the individual word vector.
Experiment 3: Comparative experiments of different models. The same data was tested in the CRF model, the BiLSTM model and the modified BiLSTM-CRF model. The experimental results are shown in the Table 6:
Experimental Results of different models
In Table 6 ASP, ASP, POS, NEG, ZER, and ALL represent attribute words, emotional words with positive polarity, negative emotional words, polar neutral emotional words, and overall extraction. Attribute word extraction: The improved BiLSTM-CRF is 6.7% and 10.54% higher than the BiLSTM and CRF models, respectively; Positive polarity extracted: the improved BiLSTM-CRF ratio BiLSTM, CRF model F-measure were increased by 5.63% and 14.07%, respectively; Negative polarity of the sentiment word extraction: the improved BiLSTM-CRF increased by 13.26% and 34.73% compared with the BiLSTM and CRF models, respectively; Polarity-neutral emotional word extraction: the improved BiLSTM-CRF has an F-measure of 8.15% and 49.98% higher than that of the BiLSTM and CRF models respectively. The overall extraction situation: the improved BiLSTM-CRF is 7.33% and 15.74% higher than the BiLSTM and CRF models, respectively.
Top 10 attribute rankings: Count the extracted attributes. The top 10 attributes are shown in Fig. 5.

The top 10 attributes in product reviews.
The top ten attributes in Fig. 5 are “Appearance”, “Screen”, “Photographing”, “Running Speed”, “System”, “Hand Feel”, “Customer Service”, “Price”, “Size”, and “ Logistics “ Seven of these attributes belong to the product feature elements of mobile phones. These attribute words are also commonly used functions of mobile. Among them, the “appearance” attribute is at the top of the list, users are more concerned about the face value of the phone. There may be too many women in the user group of this mobile phone; the two attributes of “customer service” and “logistics” are evaluations of merchant services. It can be seen that merchants’ service attitudes occupy a certain position in online shopping decisions.
Comparison chart of bad reviews: Compare the bad reviews of the top ten attributes, as shown in Fig. 6.

The positive and negative evaluation ratio of attributes.
Among the top ten attributes, the “Customer Service”praise was lower than the negative rating, indicating that the seller’s service on this phone was poor, and the product’s “Appearance”, “Photographing”,“Running Speed”, “System” and other attributes were well received, It is far greater than the negative evaluation, indicating that the performance of this phone is very good. If the top ten properties of the phone have already met the buyer’s demand, users can consider buying the phone, but if consumers are more concerned about the quality of seller’s service, You can choose other stores to buy this phone.
Word cloud display: Word cloud is to count the frequency of each attribute word and use the word frequency to determine the importance of the attribute. The larger the word frequency of the attribute, the more users of the product care about the attribute. This brand phone the word cloud display is shown in Fig. 7.

Attribute word cloud display.
Words with larger fonts have more frequent words, and are also attributes that users care about. The attributes that the users of the mobile phone dataset in this article pay more attention to are the commonly used attributes of “screen”, “appearance”, “photographing”, and “running speed”.
This paper studies the Aspect-based sentiment analysis task and transforms it into a sequence labeling problem. Based on the BiLSTM-CRF sequence labeling model, a BiLSTM-CRF model based on the combination of word vector and word position features is proposed. The experimental results show that the improved model has better effect than the initial model, BiLSTM and CRF models.
The research in this paper only conducts experiments in the mobile phone dataset. The next step is to apply the model to data experiments in different fields to verify the generalization ability of the model.
Funding
This work was supported by the Research on Calligraphy Culture Inheritance Technology of Ancient Inscription Based on Artificial Intelligence, NSFC via project 62076200 and the Application Research of Font Generation Technology Based on Artificial Intelligence [grant number 2020JM-468], Shaanxi Natural Science Foundation.