
Abstract
In this paper, a bilateral spectrogram filtering (BSF)-based optimally modified log-spectral amplitude (OMLSA) estimator for single-channel speech enhancement is proposed, which can significantly improve the performance of OMLSA, especially in highly non-stationary noise environments, by taking advantage of bilateral filtering (BF), a widely used technology in image and visual processing, to preprocess the spectrogram of the noisy speech. BSF is capable of not only sharpening details, removing unwanted textures or background noise from the noisy speech spectrogram, but also preserving edges when considering a speech spectrogram as an image. The a posteriori signal-to-noise ratio (SNR) of OMLSA algorithm is estimated after applying BSF to the noisy speech. Besides, in order to reduce computing costs, a fast and accurate BF is adopted to reduce the algorithm complexity O(1) for each time-frequency bin. Finally, the proposed algorithm is compared with the original OMLSA and other classic denoising methods using various types of noise with different signal-to-noise ratios in terms of objective evaluation metrics such as segmental signal-to-noise ratio improvement and perceptual evaluation of speech quality. The results show the validity of the improved BSF-based OMLSA algorithm.
Keywords
Introduction
Speech is an important carrier of human communication, but its quality can be inevitably degraded by background noise, especially in an adverse acoustic environment, which may not only decrease the speech intelligibility, but also cause human auditory fatigue. Generally, speech enhancement (SE) techniques aims to extract clean speech from the noisy speech signals by suppressing or eliminating the noise, so that the intelligibility and/or the quality of speech can be improved [1]. Besides for speech communication, SE techniques are also often used as a front-end processing in speech recognition, speech coding and intelligent communication equipment in recent years [2].
During the development of speech enhancement techniques, some classical algorithms, such as spectral subtraction, wiener filtering, subspace method, minimum mean square error estimation, and so on, have been catching researches continuously [3–6]. The subspace algorithm is excellent at suppressing the musical noise problem, and at the same time can balance the speech distortion and noise residual problems. In [7], the researchers tried to combine psychoacoustic masking effect into the subspace algorithm, and made efforts to improve the performance of the algorithm, and the subspace speech enhancement base on auditory masking (SSE-AM) achieved certain success. However, the subspace method relies on matrix operations and generally requires a large amount of computational load, which is not practical for the real-time processing requirements of speech enhancement. In [8], a priori SNR estimator based on united speech presence probabilities (PSNR-USPP) was proposed, which can improve the tracking performance of a priori SNR by combining maximum likelihood (ML) estimator with the decision-directed SNR estimator and reduce the musical noise simultaneously. However, when the noise power spectral density changes abruptly, the model parameter estimation of PSNR-USPP method does not have a good adaptability, and it is still a problem to estimate the non-stationary noise power spectral density.
It is worth mentioning that the statistical model based on short-time spectral amplitude (STSA) is the most widely used one among statistical model-based methods. Taking the minimum mean square error (MMSE) estimator as an example, the MMSE-based STSA estimator, proposed by Ephraim and Malah [9], could effectively suppress the musical noise. After that, they further proposed an MMSE-based short-time log-spectral amplitude (LSA) estimator [10], because the log-spectra match human auditory property better. However, because of the speech presence uncertainty, the multiplicative gain modifier of MMSE-LSA is not optimal, then Cohen proposed the MMSE-based optimally modified log-spectral amplitude estimator algorithm (OMLSA) [11]. OMLSA can adapt to adverse noise environment, avoid musical noise problem, and protect weak speech components. The gain function of OMLSA is related to the speech presence probability. However, when the speech presence probability is expected to be zero, i.e., in the silent period, because of underestimating the noise power spectral density in non-stationary noise environments, the value of the gain function is often not equal to zero. Therefore, OMLSA has the residual noise inevitably, and further improvement is necessary.
Bilateral filtering (BF) is a nonlinear image filtering technique proposed by Tomasi and Manduchi [12]. BF utilizes not only the spatial proximity information (geometric distance) of pixels to smooth out the noise, but also the gray similarity information to make the filter effectively preserve the image edge texture. Because of this property, BF has become widely used in many computer vision and image applications [13, 14].
To the best of our knowledge, BF has not been applied into speech signal processing and speech enhancement yet. In this paper, the bilateral filtering (BF) technique is first used to preprocess noisy speech spectrogram to implement speech denoising, which is named as bilateral spectrogram filtering (BSF). Herein, the spectrogram of clean speech is regarded as a clean image, each time-frequency (TF) bin represents a pixel, and the normalized noisy speech spectrogram is regarded as the corresponding image disturbed or atomized by certain noise. Thus, BSF has the ability to sharpen details, remove unwanted textures or background noise, and preserve edges of a speech spectrogram. Besides, in order to reduce computing costs, a fast and accurate BF is adopted to reduce the algorithm complexity to O(1) for each time-frequency bin [12, 15]. Therefore, the main contribution of the proposed improved OMLSA algorithm is that we first introduce BSF as a preprocessing scheme, and then estimate the a posteriori SNR from the BSF enhanced speech. Experimental results show that, by combining with BSF, the performance of OMLSA can be improved in terms of segmental signal-to-noise ratio improvement (SegSNRI) and perceptual evaluation of speech quality (PESQ), especially in adverse acoustic environment.
Improved OMLSA speech enhancement algorithm
Overview
The additive noise signal d (n) and the clean speech signal x (n) are assumed to be independent uncorrelated, and the noisy speech signal y (n) can be modeled as:
Then the short-time Fourier transform (STFT) of Equation (1) can be given by:
Taking advantage of the speech presence probability, OMLSA is the optimally modified log-spectral amplitude estimator based on MMSE-LSA. By combining with BSF, the block diagram of the improved OMLSA is illustrated in Fig. 1, where
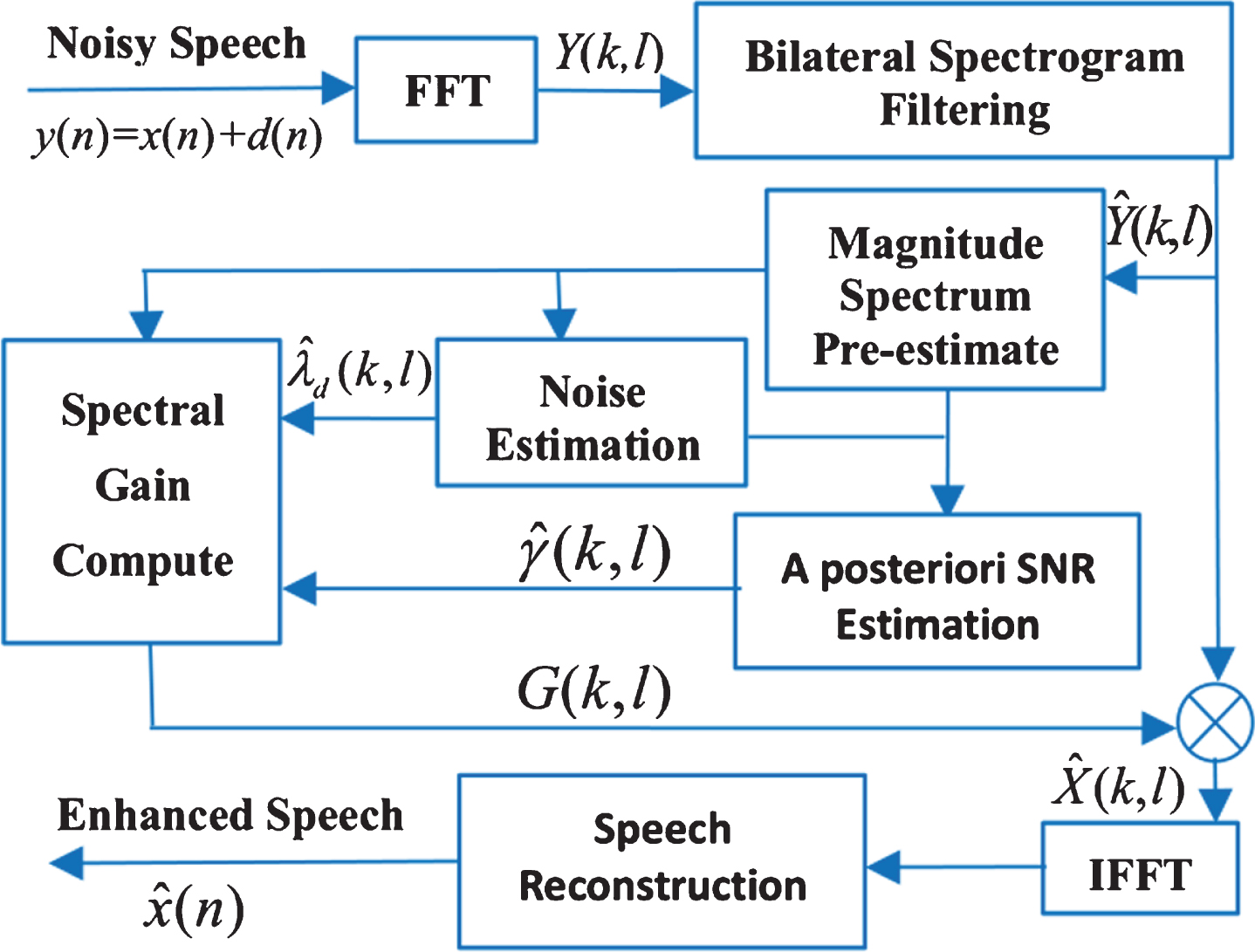
Block diagram of improved OM-LSA algorithm.
The purpose of MMSE-LSA is to calculate a spectral gain function and perform
The proposed improved OMLSA algorithm utilizes the speech absence probability based on a binary hypothesis model:
Accordingly, the spectral gain function of the improved OMLSA algorithm can be given by:
The estimated magnitude of the clean speech can be written as:
In the end, the phase information of noisy speech and inverse FFT (IFFT) are used to reconstruct the enhanced speech signal in the time domain.
Spectrogram preprocessing
The spectrogram is obtained by calculated the logarithmic envelope of the power spectral density (PSD) of speech signal, and the expression is given by:
There are two reasons for preprocessing and normalization about spectrogram. On one hand, the dynamic range of PSD can be reduced by Eq. (11), and the distribution of light and shadow corresponding to the mean and variance of spectrogram are more uniform. On the other hand, in order to facilitate the image processing, it is necessary here to transform the speech spectrogram to a range of 0–255 gray values [19, 20].
If the normalized spectrogram is marked as
Here, since the range of pixel grayscale value generally ranges from 0 to 255, to transform the speech spectrogram into image grayscale value processing, the value of
Originally introduced by Tomasi and Manduchi [12], bilateral filters are edge preserving operators that have found wide spread use in many computer vision and graphics tasks like image denoising [21, 22], texture editing and relighting [23], tone management [24], demosaicking [25], stylization [26], optical-flow estimation [27] and stereo matching [28].
To the best of best our knowledge, the BF method has not been introduced for speech denoising yet. Based on the BF method, we propose a BSF for speech denosing. In practice of speech signal, the proposed filter input
Let
The bilateral filter has turned out to be versatile tool that has found widespread application in image processing, computer graphics and computer vision. However, a direct computation of BF requires
The enhanced speech spectrogram can be obtained by using BSF [32], expressed as:
Finally, the PSD represented by the enhanced spectrogram
In order to validate the performance of the improved OMLSA speech enhancement algorithm based on the bilateral spectrogram filtering, experiments were carried out in different noise environments. Four types of noise are selected from the Noisex-92 database [33], including stationary white Gauss noise, non-stationary white Gauss noise (obtained by increasing white Gauss noise by 15 dB in some periods), factory noise and babble noise. The clean speech comes from TIMIT standard speech database [34]. Speech data of 30 people are selected, of which 50% are male utterances and 50% are female utterances. The clean speech signal and four kinds of noise are mixed to get the noisy speech with the input SNR of –5 dB, 0 dB, 5 dB and 10 dB [35]. The sampling rate of all signals is 16 kHz, the frame length is 16 ms, the frame shift is 8 ms, and the window function is Hanning window. Other parameters used in the algorithm are determined experimentally as: σ
r
= 40, σ
s
= 16, Ω = 9
All test data are processed and analyzed by the following six popular speech enhancement algorithms, including M1: subspace speech enhancement base on auditory masking (SSE-AM) [7], M2: a priori SNR estimator based on united speech presence probabilities (PSNR-USPP) [8], M3: OMLSA (original method before improvement by proposed algorithm in this paper) [11], and M4: proposed improved OMLSA based on bilateral spectrogram filtering (IOM-BSF).
In this section, we chose two objective evaluation indices to test and compare the four algorithms mentioned above. The first one is segmental SNR improvement (SegSNRI) [36, 37]. Since the speech signal is a short-term stationary signal that changes slowly, the SNR should be different in different time periods. Therefore, segmented SNR can be used to evaluate speech enhancement performance. First frame the speech, then calculate the SNR for each frame of speech, and finally find the average. Specifically, the SegSNR can be calculated from the following equation:
The second objective index is perceptual evaluation of speech quality (PESQ) [38]. It is the result of integration of the perceptual analysis measurement system (PAMS) and perceptual speech quality measure (PSQM) 99, an enhanced version of PSQM. PESQ is expected to become a new ITU-T recommendation P.862, replacing P.861 which specified PSQM and measuring normalizing blocks (MNB) [38, 39]. The higher the PESQ score, the better the subjective speech quality. In addition, PESQ is a good approximation to the mean opinion score (MOS) [40], which is a subjective testing tool.
Figure 2 shows the experimental results of the SegSNRI scores of the four methods participating in the comparison. Evidently from Fig. 2, under various unused environments, the SESNRI score of enhanced speech processed by OM-BSF algorithm in this paper is basically the which is superior to the original OMLSA algorithm, and also superior to other traditional speech enhancement algorithms, indicating a good overall level of noise suppression and voice quality improvement. It is noteworthy that the leading margin is relatively large at low SNR (–5 dB), which also shows that IOM-BSF algorithm has better suppression performance for the adverse noise environment.

Performance measures (SegSNRI) of four methods under different input SNRs and different noise environment types.
Figure 3 shows the experimental results of PESQ improvement score (PESQI) among the four methods. Figure 3 shows that the PESQI score of the IOM-BSF algorithm is the highest with white noise, non-stationary white noise and babble noise, which indicates that the subjective speech quality is better in both stationary and non-stationary noise environments. It also illustrates that IOM-BSF algorithm has less residual noise after speech processing. PSNR-USPP algorithm is also an optimization algorithm based on statistical model, so it is used for comparison. It achieves good results in dealing with factory noise. This is due to the introduction of a posteriori SNR without speech frame-delay, which improves the tracking performance of a priori SNR [8]. On all accounts, from the perspective of Figs. 2 and 3, the overall robustness of the IOM-BSF algorithm is better, which proves the effectiveness and superiority of the proposed algorithm.

Performance measures (PESQI) of four methods under different input SNRs and different noise environment types.
For the sake of intuitiveness and subjectivity, we give a comparison of the processing effects and of the waveforms and spectrogram. Figure 3 highlights the enhancing ability of the proposed IOM-BSF technique in producing less residual noise and less speech distortion than the SSE-AM, PSNR-USPP and OMLSA under factory noise environment with 5 dB input SNR.
Figure 4 demonstrates that with the increase of noise non-stationarity, the spectrogram results of three competing algorithms become inferior. Because in this case, the noise spectrum estimation cannot follow the dramatic change of background noise in time. In addition, spectrogram of SSE-AM shows excessive distortion. However, IOM-BSF algorithm has a better performance owing to the property of image enhancement with edge preserving for BSF. The enhanced version OM-BSF has removed most of the noise and fuzzy areas. Especially, according to the area circled in the figure, the residual noise is less and the speech enhancement quality is better.
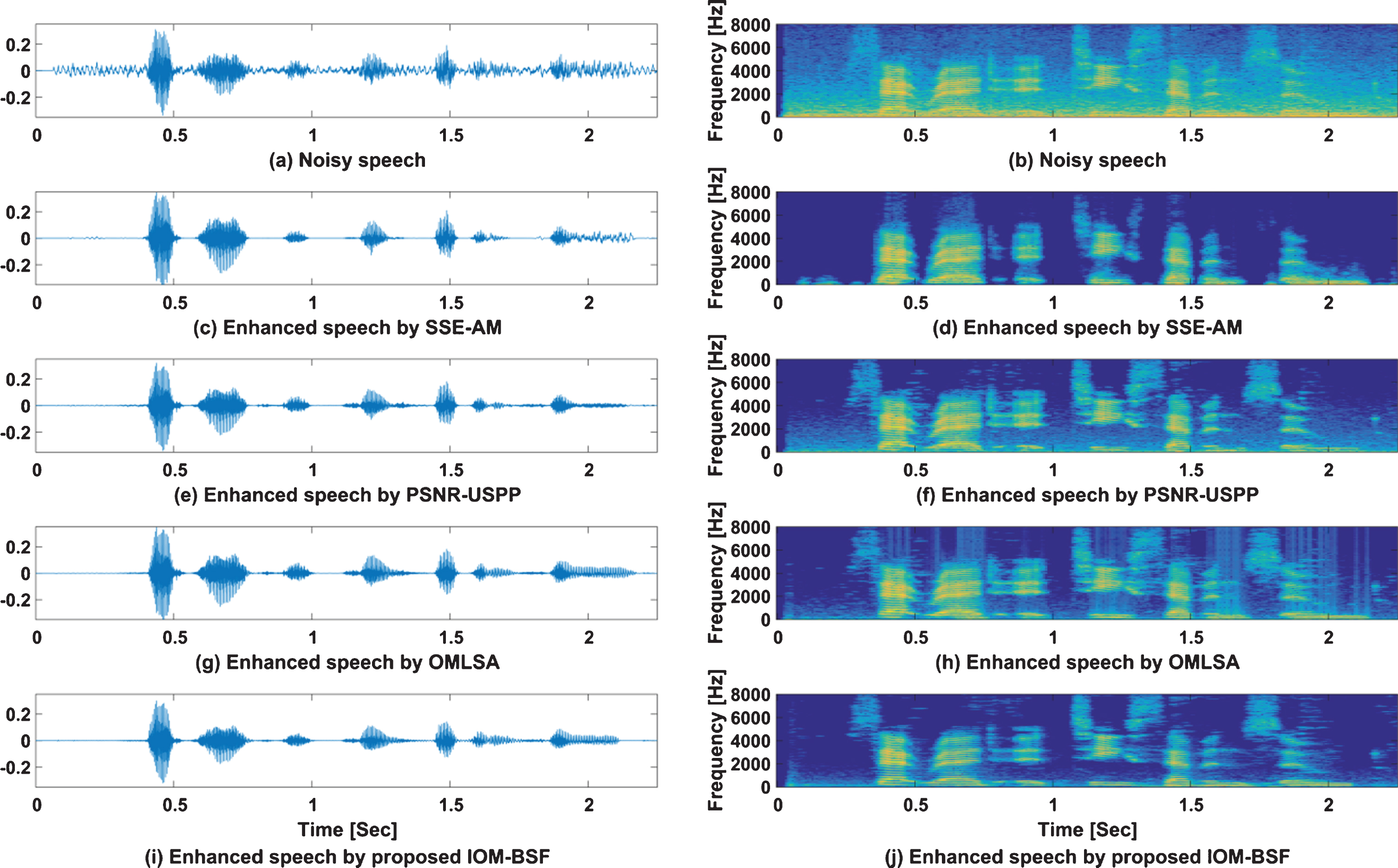
Waveforms and spectrograms for noisy speech corrupted with factory noise at 5 dB enhanced by 4 algorithms.
Inspired by bilateral image filtering which can not only remove noises but also preserve edges, we proposed an BSF-based OMLSA algorithm for speech enhancement. By using BSF as a preprocessing scheme on noisy speech, we estimate the noise power spectral density using the IMCRA from the BSF enhanced speech signal, and we apply OMLSA to further reduce its residual noise finally. The proposed algorithm is tested and compared with classical speech enhancement algorithms in various noise environments. Experimental performance evaluations indicate that, in terms of averaged SegSNRI, combined with BSF, the performance of IOM-BSF compared with the original OMLSA improved by 1.65, 2.91, 3.17, 2.27, respectively under –5 dB, 0 dB, 5 dB, 10 dB conditions. And in terms of averaged PESQI, the performance of IOM-BSF compared with the original OMLSA improved by 0.33, 0.39, 0.30, 0.12, respectively under –5 dB, 0 dB, 5 dB, 10 dB conditions.
Evaluation results also show that the proposed algorithm outperforms other competing methods in terms of the amount of noise reduction, while the speech distortion remains acceptable, especially in adverse acoustic environments where the input SNR is extremely low or highly non-stationary noise exists. Hence, we can conclude that the introduction of bilateral image filtering as a preprocessing scheme in speech enhancement processing is effective and profound.
Footnotes
Acknowledgments
This work was supported in part by the National Science Fund of China (grant 11974086), in part by the Postgraduate Innovative Capability Cultivation Program by Guangzhou University (grant 2018GDJC-M20), in part by the Special Innovation Project of Department of Education of Guangdong Province (grant 2017KTSCX141), in part by the Open Fund of National Environmental Protection Engineering and Technology Center for Road Traffic Noise Control, and in part by the Guangzhou Science and Technology Plan Project (grant 201904010468).