
Abstract
The intrusion detection of railway clearance is crucial for avoiding railway accidents caused by the invasion of abnormal objects, such as pedestrians, falling rocks, and animals. However, detecting intrusions using deep learning methods from infrared images captured at night remains a challenging task because of the lack of sufficient training samples. To address this issue, a transfer strategy that migrates daytime RGB images to the nighttime style of infrared images is proposed in this study. The proposed method consists of two stages. In the first stage, a data generation model is trained on the basis of generative adversarial networks using RGB images and a small number of infrared images, and then, synthetic samples are generated using a well-trained model. In the second stage, a single shot multibox detector (SSD) model is trained using synthetic data and utilized to detect abnormal objects from infrared images at nighttime. To validate the effectiveness of the proposed method, two groups of experiments, namely, railway and non-railway scenes, are conducted. Experimental results demonstrate the effectiveness of the proposed method, and an improvement of 17.8% is achieved for object detection at nighttime.
Introduction
The safe operation of railways has become challenging with the rapid development of railway transportation networks. To ensure the safety of the track, Yang et al. propose a void-disease identification algorithm to promote the application of ground-penetrating radars to detect ballastless track subgrade diseases in high-speed railways [1]. And we solve railway safety problems from the perspective of effective railway intrusion detection measures [2, 3]. Approaches for the intrusion detection of railway clearance can be divided into contact and noncontact approaches. Contact detection methods include dual grid and fiber grating detection [4]. Noncontact methods include infrared radiation technology [5] and image processing-based detection [6]. Among these methods, strategies based on image processing exhibit application potential. Target detection techniques, such as scale-invariant feature transform (SIFT) [7], histogram of oriented gradients (HOG) [8], and Haar features [9], are used to process images captured by video surveillance systems. However, these methods for obtaining features through image processing are susceptible to interference from the complex environment of a railway scene, such as uneven lighting, occlusion, and noise. Their shortcoming of poor anti-interference ability will cause the detection effect to fail in meeting the requirements for actual use. Therefore, more reliable and effective detection methods should be used.
Deep learning has recently dominated the fields of computer vision, natural language processing, and automatic control. The hierarchical features extracted using deep learning are more discriminative and representative compared with those extracted using other methods. Hence, several prominent object detection frameworks, such as regions with convolutional neural networks [10], you only look once [11], and single shot multibox detector [12], have been proposed on the basis of convolutional neural networks (CNNs) [13]. These deep learning-based methods with enhanced anti-interference ability have been successfully applied to object detection in the railway scene. In these methods, a deep learning model can be derived by training a large number of railway scene images; the model is then optimized to achieve good results in accordance with the particularity of a railway scene [14–16].
Although object detection issues using visible RGB images have been considerably addressed for the intrusion detection of daytime railway clearance, object detection using infrared images at nighttime remains a challenging task due to the lack of sufficient training samples of infrared images of railway scenes. A comparison between visible RGB and infrared images of a railway scene is shown in Fig. 1. A normal deep learning model experiences difficulty in detecting objects, such as falling rocks, people, and trains, from infrared images because of the lack of color texture information. To solve this problem, we propose a transfer learning method that can generate a composite image similar to that of the infrared image style, and then using this composite image to train the SSD model. From the perspective of transfer learning, visible RGB images captured during the day are used as the source domain, and infrared images captured at night are used as the target domain. Our method includes two phases: generating training samples and detecting targets. The first stage is inspired by the image generation function of a generative adversarial network (GAN) [17], and an approach for generating sample augmentation methods using CycleGAN is proposed [18]. This method generates a sufficient number of composite images under the condition that a large number of RGB images are visible in the source domain. A composite image with a style similar to an infrared image in the target domain is then used as the training sample. In the second stage, a recent successful SSD model is utilized. We modify the SSD network to make it suitable for railway intrusion detection, and then the model is trained using the labeled samples obtained during the first stage.

Image comparison. (a) RGB railway image. Lighting conditions are good, and objects are easily visible. (b) Infrared railway image. Images are acquired at night. The light is uneven, and the objects are unclear.
The remainder of this article is organized as follows. Related studies are presented in Section 2. A data augmentation method based on the CycleGAN algorithm is proposed in Section 3. A method for railway intrusion detection based on the SSD model is introduced in Section 4. The experimental results are discussed and analyzed in Section 5. Lastly, the conclusions of our work are drawn in Section 6.
Deep learning algorithms work efficiently depending on the ability of their data to express characteristics; however, they require the support of a large amount of data [19]. In practical applications, collecting a large amount of data in advance is a necessary condition for training deep learning models, and only a sufficient amount of data can meet the needs of practical applications. However, obtaining training data for special scenarios, such as rain, snow, and night, is difficult. The performance of a model trained without sufficient data is inadequate. Therefore, investigating how deep learning models can be trained using a small amount of data is important. Common data expansion approaches are mostly based on image processing methods, such as mirroring, rotation, and random cropping. These strategies are simple, easy to implement, and can increase the amount of data. However, these methods can occasionally exert negative effects, such as the occurrence of a vertical flip operation during facial recognition. Therefore, a data expansion method based on image processing cannot fully solve the problem of small training data and can only be used as a method for producing supplementary data.
With the rapid development of deep learning, new methods with stronger practicability and effectiveness have provided faster solutions for data expansion. In the classification of tumor gene expression data, Jian et al. indicated that the application of deep learning is rare due to insufficient training samples for gene expression data [20]. Accordingly, they proposed a sample expansion method to solve this problem. Inspired by the concept of a denoising automatic encoder (DAE) [21], their method obtains a large number of samples by randomly cleaning partially corrupted inputs. The extended samples obtained using this method cannot only maintain the advantages of corrupted data in DAE but can also solve the problem of insufficient training samples for gene expression data to a certain extent. Li et al. investigated the object detection problem in small and complex indoor scenes [22]. They proposed a target detector based on the deep learning of small samples by considering the small sample size of an indoor scene, the complex background, and the poor effect of object detection. This method uses a synthetic sample generator to automatically enhance the training samples. First, the target area is extracted from the training set. Then, the target area is segmented to obtain the foreground target. Finally, the random foreground target and the background image are fused to generate a composite image.
Data expansion has progressed considerably with the emergence and development of GANs [23–25]. Goodfellow et al. proposed GAN, which consists of two networks, namely, a generator network and a discriminator network. The network inputs the D-dimensional noise vector and converts the noise vector into an image. Zhu et al. proposed a data enhancement method using GAN because of the small amount of labeled data and the uneven label distribution [26]. Their method can complement and complete data manifolds and find good margins between neighboring classes. With the further development and improvement of GAN, the DCGAN [27] and CGAN [28] architectures were presented. DCGAN replaces the generator and discriminator structures in GAN with two CNNs and then learns and modifies the CNN framework. Diaz-Pinto et al. explored the glaucoma assessment system and found that its performance was highly influenced by the number of labeled images used in the training phase. Their method was proposed to solve the problem of synthesizing retinal fundus images by training a variational autoencoder [29] and the DCGAN model on 2357 retinal images, improving system performance [30]. CGAN adds conditional constraints on the basis of ordinary GANs by adding “train” as a condition to ordinary GANs used to generate train images. The function of inputting text as a condition for generating a required picture can be realized through CGAN. With the emergence of the CycleGAN network, the capabilities of GANs have been further enhanced. Zhu et al. used a pair of GAN networks to construct a ring network structure that realizes the conversion of two different types of domain images, including the conversions of landscape and oil paintings and horses and zebras. This feature provides a good direction for expanding data. Fang Liu applied CycleGAN as the core of the method to perform unpaired image-to-image translation between different MR image datasets [31]. The new technique further improved the applicability and efficiency of CNN-based segmentation of medical images. Liang et al. used CycleGAN to synthesize CT images from CBCT images [32]. They also compared the CycleGAN model with DCGAN and PGGAN, and proved that CycleGAN is superior to the other two models [33]. Proposes modified CycleGAN that generates an even distribution of heterogeneous face data. Combined with other methods proposed by the author, the accuracy of age estimation was improved.
In the current study, the SSD algorithm is used for target detection in night railway scenes. Samples of daytime railway scenes are generated using the CycleGAN network to obtain samples of nighttime railway scenes to augment the data. This feature solves the problem of insufficient training samples and trains the SSD models efficiently to improve detection accuracy.
Generation of synthetic images using GANs
CycleGAN
GAN initially generates images on the basis of noise to observe its specific distribution. The traditional GAN is unidirectional, and it includes a generator G and a discriminator D. The generator and the discriminator confront each other during the training process. Generators continuously improve the ability to generate fake data, and discriminators continue to improve the ability to distinguish between true and fake data. In the end, the network is dynamically balanced to produce images that meet requirements.
CycleGAN is essentially a ring network composed of two pairs of mirrored GANs. The structure contains two generators G and F and two discriminators D A and D B . The core idea of CycleGAN involves the use of the paired GANs to realize mutual conversion between two domain data. Figure 3 shows the network structure of CycleGAN.
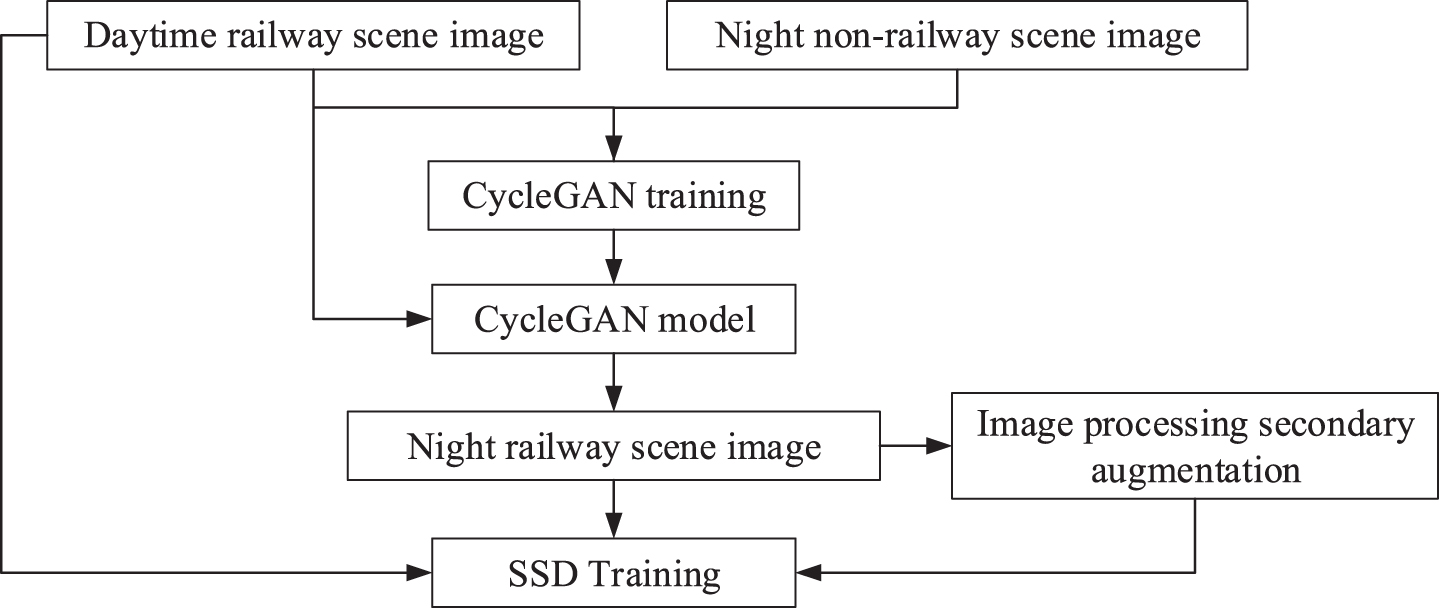
Flow chart of the proposed approach.
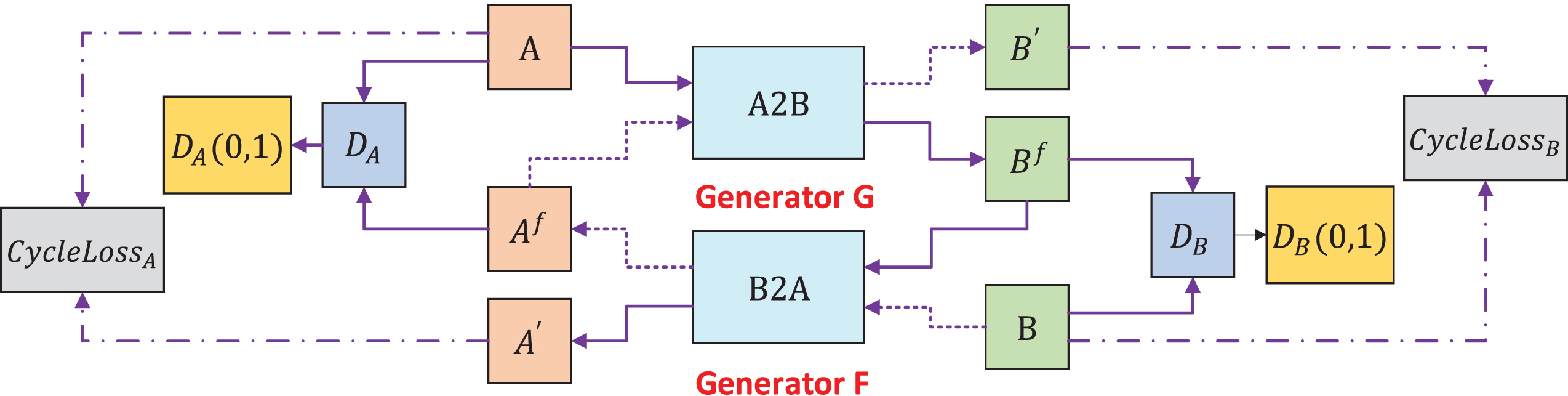
Structure diagram of CycleGAN. The CycleGAN network includes generators G and F and discriminators DA and DB. Generator G converts the A domain image into the B domain image, and generator F converts the B domain image into the A domain image, i.e., Af and Bf are generated. Simultaneously, the generator can also generate Af and Bf to the corresponding original image, i.e., A′ and B′ are created. Generator loss is calculated using A, A′ and B, B′. Discriminator loss is calculated using A, Af and B, Bf. False and true data are denoted by 0 and 1, respectively.
In CycleGAN, if an existing generator G can convert the image style of the A domain to the B domain and a generator F can convert the image style of the B domain to the A domain, then generators G and F should be equivalent. That is, after the A domain image is converted to G (A) by G, generator F can convert G (A) to the B domain. Similarly, the B domain can also perform the corresponding processes of F (G (A)) ≈ A and G (F (B)) ≈ B. Therefore, by using a cycle consistency loss to incentivize this behavior, the cycle loss formula is expressed as
For the mapping function G : A → B and its discriminator D
A
, the discriminator loss is expressed as
Similarly, for the mapping function F : B → A and its discriminator D
B
, the discriminator loss is expressed as
All the losses of the final network are added and expressed as follows:
The generator consists of an encoder, a converter, and a decoder. The coding part consists of a CNN, which performs the function of extracting features from the input image. The input image size is [1, 256, 256, 3]. After the three-layer convolution module, the output scale is a characteristic map of 1×64×64×256. The converter uses a nine-layer ResNet module. Each ResNet module is a neural network layer composed of two convolutional layers that can retain the original image features during the conversion process. The output scale is still 1×64×64×256. The decoder consists of two deconvolution modules and one convolution module for recovering low-level features from the feature vectors. The output is generated by using the Tanh activation function to achieve the conversion between the source and target domains.
The discriminator belongs to a convolutional network. It extracts features from the image and then adds a convolutional layer, which produces a 1D output to determine whether the extracted features belong to a particular category. An inputted image is predicted by the generator as an original image or an output image.
The CycleGAN network must be trained to generate images. We use daytime RGB and nighttime infrared images as source and target domain data, respectively. These two types of images are used as training samples to train the CycleGAN model. The source domain data include the RGB data of 2255 daytime railway scenes, including 1800 training and 455 test data. The target domain data contains 400 nighttime infrared images as training data.
Model training and parameter setting
The CycleGAN model is used to transform the image style to ensure that data are changed from the daytime scene to the nighttime scene. The training effect of the CycleGAN model determines the amount of information contained in the training data of the SSD model, which will affect the learning effect of the SSD model.
The input image of the CycleGAN model is a three-channel RGB image with a default size of 256×256. Image normalization includes random cropping, random mirroring, and normalization operations. Most parameters in the CycleGAN training process are default values. The initial learning rate is set to 2 × 10 ∧ (–4), the decay_epoch is set to 100, the learning rate linear decay rate is zero, and the maximum epoch is set to 200. The optimizer uses the Adam [34] algorithm and the hyperparameter sets of β1 = 0.5 and β2 = 0.999. Model training is completed in Windows 7 with PyTorch 0.4.1 [35].
Figure 6 intuitively presents that image quality and effects are gradually improved and the capabilities of the generator and discriminator are significantly improved as the number of iterations increases. After training is completed, we can obtain the CycleGAN models in different stages and use the generator model to generate a large amount of target domain data. The target domain data generated by iterating the model at different times are considerably different. This substantial difference can enrich the characteristics of the data, make the target domain data sufficient, provide additional information and improve learning results. Figure 7 compares the original image with the generated image. The CycleGAN algorithm runs on a computer equipped with a Nvidia GeForce RTX 2080 graphic card. The processing time is 78.2 ms to convert an RGB picture to an infrared picture.

Generator structure.
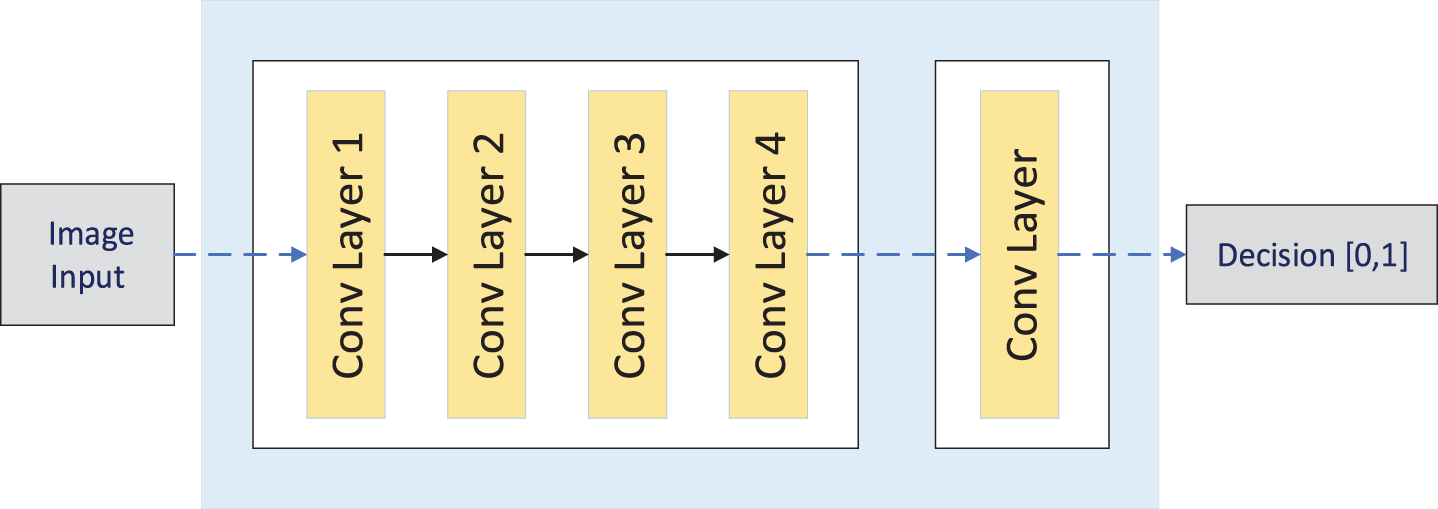
Discriminator structure.

Image generation process. The daytime RGB image is at the top row. The middle row image is generated after 20 training iterations. The bottom row image is generated after 60 training iterations.

Images generated using our data augmentation method. (a) Daytime images of non-railway scenes. (b) Generated infrared-style images of non-railway scenes. (c) Daytime images of railway scenes. (d) Generated infrared-style images of railway scenes.
This study trains the SSD model by using a large number of nighttime infrared images of railway scenes to realize the detection of railway foreign objects in a nighttime scene.
The SSD algorithm is a one-stage detection method based on a feed forward convolutional network. This algorithm uses multi scale feature maps for different scale predictions, and predicts on the basis of aspect ratio to achieve fast and effective detection results. The SSD object detection procedure is described as follows. First, input a picture is inputted to the SSD network, and feature maps are extracted from the picture is subjected to convolutional neural network (CNN) to extract features to generate a feature map. Then the six-layer feature map is extracted, and default boxes are generated at each point of the feature map. Finally, all the generated default boxes are collected. The final default box is selected by NMS (non-maximum suppression) and used as the output result. Figure 9 shows the network structure of the SSD model.

Flowchart of SSD.

SSD network structure.
The SSD network adopts VGG-16 as the basic network. The VGG-16 network is characterized by its small convolution kernels and sufficient number of network layers, which can contribute to achieving a good feature extraction function. VGG16 contains 13 convolutional layers, 3 fully connected layers and 5 pooling layers. The size of the convolution kernel used in the convolution layer is 3, that is, both width and height are 3. The pooling layer uses the method of maximum pooling. Both the convolutional layer and the fully connected layer use Rectified Linear Unit (ReLU) as the activation function. The diagram of VGG16 is shown in Fig. 10.
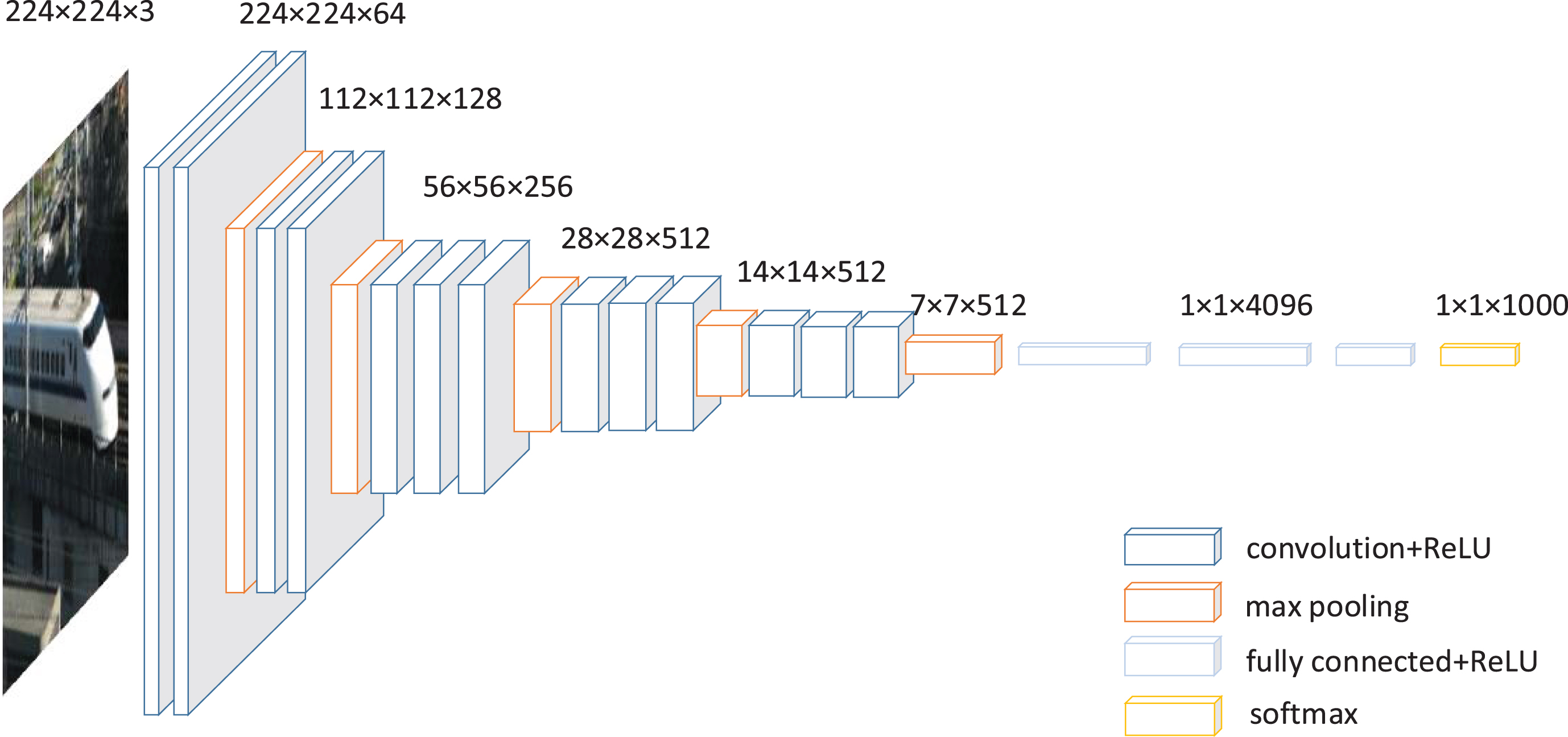
Diagram of VGG16 Network.
After establishing VGG-16, SSD is connected to a plurality of convolutional feature layers of different sizes, including conv4_3, fc7, conv6_2, conv7_2, conv8_2, and conv9_2. The prediction values of multiple scales can also be obtained using these auxiliary convolutional layers to detect targets of different sizes. The number of a priori frames set by various feature maps is different. The settings of the a priori box include dimensions and aspect ratio. For the scale of the a priori frame, the scale of the a priori box increases linearly as the size of the feature map decreases, and the calculation method is as shown as follows:
To determine aspect ratio, a
r
∈ { 1, 2, 3, 1/2, 1/3 } is generally selected. For a specific aspect ratio, the formula for calculating the width and height of the a priori box is expressed as follows:
The loss function of SSD is defined as the weighted sum of localization loss and confidence loss as follows:
The following confidence loss is the softmax loss:
SSD obtains the object’s target category and score after matching the a priori box and produces the final test result through a step of nonmaximum value suppression.
To verify the feasibility and effectiveness of the proposed method, we conduct two sets of experiments. Experiment 1 is the detection of humans and cars in non-railway scenes at nighttime. Experiment 2 is the detection of trains and humans in railway scenes at nighttime.
Experiment 1: Detecting pedestrians and cars in a non-railway scene
The data set of Experiment 1 is provided in Table 1. The image processing method for data set 1-F includes horizontal mirroring, Gaussian noise, and Gaussian blur.
Data set of Experiment 1
Data set of Experiment 1
The model is trained after preparing the data set. The SSD model plays a decisive role in the actual detection effect. For the learning ability of the model, parameter setting in training is crucial for the detection result. We choose SSD300, which is a three-channel RGB image with dimensions of 300×300 after the input image is preprocessed. The initial learning rate, lr_policy, stepvalue, gamma, and maximum epoch are set to 5 × 10-4, multistep, 60000 and 80000, 0.1, and 100000, respectively. After many times of practice, we find that setting the learning rate and step value to the above values can make the objective function converge to minimum within an appropriate time, and make the model train better. The maximum epoch is set to 100000 to ensure that the model can be fully trained without underfitting and overfitting. The optimization algorithm is SGD, and the momentum is set to 0.9. The SSD computes mAP with an11-point interpolated average precision. The model is trained on a Linux 16.04 system. The SSD model runs on a computer equipped with a Nvidia GTX 1080 graphic card. It takes 25 ms to process a picture.
All the final models trained from the training set listed in Table 1 are tested on 1-T. Some detection results are presented in Fig. 11. Figure 11(a) shows some results of SSD model trained only by daytime dataset, in which pedestrians and some cars of small sizes are missed. The detection results of SSD model trained by generated images are shown in Fig. 11(b), in which all the objects are correctly detected. Figure 11(b) demonstrated that the generated images by CycleGAN is effective to improve detect rate for infrared images.

Test results of Experiment 1. (a) Detection results of the model trained on dataset 1-Awith missing detection. (b) Detection results of the model trained on dataset 1-E.
The result comparison is reported in Table 2. Table 2 shows that the model trained on training set 1-A obtains low detection accuracy on test set 1-T primarily due to the apparent difference between day and night images. The considerable difference between the training and test sets produces poor learning results, model performance, and detection effect. We used data set 1-B generated by CycleGAN to train SSD and obtain a significantly improved test result than that of training set 1-A. Table 2 presents highly similar test results of models trained using datasets 1-B and 1-C. We combine datasets 1-B and 1-C to obtain dataset 1-D. The model obtained by training the SSD model via image processing on data sets 1-D and 1-E are also tested. The results show that the detection effect is significantly improved and exhibits enhanced detection capabilities.
Comparison of the test results of the models trained on different datasets on dataset 1-T
The data sets used in Experiment 2 are reported in Table 3. To demonstrate the effectiveness of our method, a data augmentation method based on PixelDA [36] is included in Experiment 2 for comparison. PixelDA is a pixel-level domain adaptation algorithm. A PixelDA model was trained using RGB railway scene images and non-railway scene infrared images, which is the same as that of the CycleGAN model. A data set entitled 2-C was generated by the trained PixelDA model conditioned on the daytime railway images. In test set 2-T, we only have samples labeled as “person.” The environment and parameters of the training model are approximately the same as those in Experiment 1. However, the step value in Experiment 1 is set to 80000 and 100000, and the maximum epoch is set to 120000 in Experiment 2.
Data set of Experiment 2
Data set of Experiment 2
The final models trained from training sets 2-A and 2-B are tested on 2-T. Several sample detection results are presented in Fig. 12. In Fig. 12, the SSD model trained by daytime dataset fails to detect the pedestrian, whereas the SSD model trained by our CycleGAN strategy works well. The comparison of Fig. 12(a) and Fig. 12(b) demonstrates the proposed data augmentation strategy via CycleGAN is effective.

Test results of Experiment 2. (a) Detection results of the model trained on dataset 2-Awith missing detection. (b) Detection results of the model trained on dataset 2-B.
The result comparison is reported in Table 4. In Table 4, we first test dataset 2-T on the model trained on dataset 2-A. Given the considerable difference between day and night image features, the training and test sets are unrelated with poor detection effect. We then use the style-transformed dataset 2-B to train the SSD model and test dataset 2-T. Form Table 4, we can clearly see that an improvement of 17.9% is achieved compared with the SSD model trained only by the daytime dataset. Compared with data augmentation strategy based on PixelDA, an improvement of 9.3% is obtained. This finding indicates that the model exhibits good detection ability at the railway site at night.
Comparison of the test results of the models trained on different datasets on dataset 2-T
The analysis of Tables 3 and 4 demonstrate that differences in the scenes will seriously influence the effectiveness of target detection. When image detection in a night scene is performed using a model trained on daytime data, the detection effect is poor and cannot meet the needs of practical applications. The collection of training samples for night scenes is difficult. CycleGAN can transform the style of daytime data that we already have and enable us to obtain the same style of data as nighttime infrared images. The conversion function of CycleGAN can reduce the workload of data collection. Simultaneously, the combination of image processing and expansion can considerably increase the amount of training set data. The proposed method is practical and improves detection accuracy and the effect of SSD model training.
Given that the difference between night and day scenes is too large and many interference factors affect the detection process, the ideal result cannot be obtained in target detection. The imaging effect of the image to be inspected is the major factor that influences the detection effect. The imaging effect of the test image is the primary reason that affects the detection effect. The imaging results of commonly used infrared cameras are poor. Uneven light, insufficient color information, and other factors exert serious impact on the detection effect. For the test samples of infrared images used in the experiment, train lights, streetlights, and other strong light sources will cause them to lose local information and also interfere with the detection of surrounding objects. Hence, the effect of target detection is significantly affected. In addition, most cameras are installed in fixed positions and do not have an autofocus function. The resulting incomplete image display, poor feature extraction, or loss of target information will affect the detection results. Furthermore, the target position, size of the occluded part, and light interference will change the original characteristics that the target should exhibit. Therefore, the parameters learned by the model do not play an efficient role, resulting in poor detection effect. Accordingly, using as many nighttime scene samples as possible to train the model can enrich the diversity of the training samples, improve the learning ability of the model, enhance the detection of complex night scenes, and obtain satisfactory results.
Compared with the regular training set with a sufficient amount of data, the SSD detection model cannot perform good detection results in night scenes and can only be used to analyze experimental results. However, we use CycleGAN to transform existing data into data with the desired style. The overall style of the generated image demonstrates the characteristics of a nighttime infrared image. The features extracted via model training are biased toward an actual night scene and can improve detection performance. Simultaneously, the amount of training data increases, the adaptability and anti-interference ability of the model improve, and good detection results are obtained under the characteristics of complex night scenes.
The style conversion function of the CycleGAN model can solve the problem of insufficient samples, improve the ability of the SSD model to detect night images, and achieve good detection effects.
Conclusion
The invasion of railways by abnormal targets is an important issue that threatens railway safety. Most existing detection methods for railway scenes are only suitable for daytime, and their detection effect on nighttime images is poor. However, the amount of infrared railway image data captured at night is small, and using this type of data as the training set for model training is challenging. To solve this problem, we propose a method for generating samples using CycleGAN. The railway image of a daytime scene is generated as a composite image with the same style as a nighttime infrared image. The generated image is used as the training set to train the SSD model. The accuracy of the proposed method for detecting infrared images at night is 17.77% higher than that of the daytime model. The overall detection ability of this method is better than those of the traditional approaches.
In the future, we plan to detect railway foreign objects in other abnormal scenarios and will adjust the SSD network to further improve its accuracy in target detection.
Footnotes
Acknowledgments
This research is supported by National Natural Science Foundation of China (62071006), Beijing Natural Science Foundation (4182020), and Key Laboratory for Health Monitoring and Control of Large Structures (KLLSHMC1901), Shijiazhuang, 050043.