
Abstract
Classification methods play an important role in many fields. However, they cannot effectively classify the samples from sample spaces that are varying with time, for they lack continual learning ability. A continual learning classification method for time-varying data space based on artificial immune system, CLCMTVD, is proposed. It is inspired by the intelligent mechanism that memory cells of the biological immune system can recognize and eliminate previous invaders when they attack again very fast and more efficiently, and these memory cells can evolve with the evolution of previous invaders. Memory cells were continuously updated by learning testing data during the testing stage, thus realize the self-improvement of classification performance. CLCMTVD changes a linearly inseparable spatial problem into many classification problems of several different times, and it degenerates into a common supervised learning classification method when all data independent of time. To assess the performance and possible advantages of CLCMTVD, the experiments on well-known datasets from UCI repository, synthetic data and XJTU-SY rolling element bearing accelerated life test datasets were performed. Results show that CLCMTVD has better classification performance for time-invariant data, and outperforms the other methods for time-varying data space.
Introduction
Machine learning has made remarkable progress over the past two decades in the field of medical [38], industrial produce [32], social life [42], systems and control engineering [29, 43], equipment fault diagnosis [20, 44] and national security [24]. Supervised learning classification methods, such as Bayesian networks (BN) [1, 34], k-nearest neighbors (kNN) [28], artificial neural networks (ANN) [23, 30], support vector machine (SVM) [13, 15] and deep learning (DL) [41], play an important role in the field of machine learning. The supervised learning classification method generally uses labeled training data to build a classification model, also referred to as classifier, between data and labels. The classification model is used to classify unlabeled testing data in one of the known classes [3].
Abundant results on supervised learning classification methods were achieved in improving classification accuracy, enhancing classification efficiency, increasing the capacity of dealing with big data, and widening the practice range [17]. However, these research achievements are mainly for the data which is generally an independent of time, and little attention has been paid to the classification method for time-varying data space [4, 40]. In fact, the time-varying data space is frequently observed in the scientific research and engineering fields. But these classification methods cannot effectively classify time-varying data space, and this is illustrated in Fig. 1. There are 3 types of samples, and the sample spaces at t1 and t2 time are shown as in Fig. 1a and 1b respectively. The classification model trained by partial of these samples at t1 time has better classification performance for some time. However, its classification performance gets worse over time. For instance, it cannot effectively classify the samples which are generated between t1 and t2 time.

Sample spaces at different times.
To periodically retrain the classification model based on the newest data or to generate a function between old data and new data are general ways to keep classification performance. A moving-window neural network classification algorithm is proposed to classify the time-varying data [39]. The result of a two-dimensional synthetic experiment shows that it has higher accuracy compared with existing neural network classification algorithms. However, its classification performance was not validated in high-dimensional time-varying data. A process support vector machine model (PSVM) expands the information processing mechanism of the traditional SVM to the time domain [33]. The input of PSVM is a time-varying function. It has a good practical effect on pattern classification problems of time-varying signals. However, how to choose the kernel function of the PSVM is difficult. A new class of probabilistic neural networks (PNNs) [22] and a new time-varying long term synaptic efficacy function-based leaky-integrate-and-fire neuRON model [2] is proposed to work in nonstationary environment. They generate a function between old data and new data, thus making the new data apply to the classification model, but it is difficult to generate the correct function in general.
The image representation of time-series signals in the BoF framework treats a time-series classification problem as a texture recognition task [26]. Experimental results on the UCI time-series classification show that it has higher accuracy. A numerically efficient adaptive sensor fault diagnosis method based on reconstruction-based contributions for continuous time-varying processes is proposed [21]. It guarantees a correct diagnosis of single sensor faults with large magnitudes. A real-time engine load classification from sensed signals can be implemented for the same type of engine with different numbers of cylinders [35]. It was verified by five classes of engine load in the V12 marine diesel engine and has higher accuracy. A classification method of univariate time series based on the framework of information geometry is proposed [14]. It is to project the data from manifold to tangent space. It achieves better performance on a synthetic data and a set of benchmark data sets. An edge computing-based method for real-time fault diagnosis and dynamic control of rotating machines is proposed [12]. It processes sensor data in real time and thus shows potential applications in the rotating machines where fault diagnosis and dynamic control are highly time sensitive. A hybrid method combining the extended Kalman filter (EKF) with cost-sensitive dissimilar ELM (CS-D-ELM) is proposed [19]. The raw data are preprocessed by EKF to produce inputs for the CS-D-ELM classifier. Experimental results show that it is more suitable for real-time fault diagnosis. A recursive variant of the Parzen kernel density estimator to track changes of dynamic density over data streams in a nonstationary environment is proposed [27]. It has low computational complexity, and can efficiently tracking nonstationary probability density. However, these methods have more parameters need to be set.
Therefore, to carry out continual learning classification method research is another way to solve this problem [11]. The classification model can be improved by continual learning the testing samples during the testing stage, which ensures it to keep better classification performance.
The biological immune system is a very complexity and continual learning system. There are many artificial immune algorithms are inspired by its various intelligent mechanisms, such as negative selection algorithm, artificial immune network algorithm, and clone selection algorithm [6, 25].
This paper proposed a continual learning classification method for time-varying data space based on artificial immune system, CLCMTVD, which is inspired by intelligent mechanism that memory cells of the biological immune system can recognize and eliminate previous invaders when they attack again very fast and more efficiently, and these memory cells can evolve with the evolution of previous invaders. Memory cells were continuously updated by learning testing data during the testing stage, thus realize the self-improvement of classification performance.
The rest of the article is structured as follows. Section 2 is the model of the proposed method. An extensive experimental evaluation of our approach is provided in Section 3. This paper is concluded in Section 4.
When invaders first attack cells, many appropriate antibodies can be generated by the immune system. After clearing the invaders, appropriate memory cells are born. When the invaders attack again, they can be eliminated very fast and more efficiently [7, 16]. Memory cells can evolve with the evolution of previous invaders. Memory cells were continuously updated by learning testing data during the testing stage, thus realize the self-improvement of classification performance.
The body is like a state space, and the memory cells are used as a classifier, and this classifier can improve itself in real-time according to different invaders.
Definitions
In order to understand this method better, some concepts used throughout the rest of this paper are defined as follows:
(1) Antibody: A feature vector coupled with its sampling time and associated type. It is used to activate a cell and culture appropriate memory cells. Training samples are used as antibodies in this method.
(2) Antigen: It is the same in representation as an antibody. It is used to attack the immune system. Testing samples are used as antigens in this method.
(3) Cell: It is the basic element of body, store related information, and has a certain shape and size.
There are many ways to describe a cell and a cube or square is used as a cell in this paper. For it is easy to describe the cell division; the cube or square with different sizes could be viewed as the cell with different passages. In other words, the cells with the same passage have the same size.
(4) Cell division: The process of a cell divides into more daughter cells under the cell division strategy. A square cell can divide into 22 daughter cells and a cube cell can divide into 23 daughter cells in this method.
(5) Passage number (p): The number of times a cell divides. The passage of the initial cell is 0 in this method. The small p value indicates high passage.
(6) Passage of memory cell (pm): This is one of two parameters that need to set in this method. This value is used to ensure every memory cells have the same passage.
(7) Hollow cell: The cell without storing information.
(8) Memory cell: The cell with information about antibodies.
(9) Multi-label cell: The cell with information of more than one antibody with different types.
(10) Sole label cell: The cell with information of one type antibody.
The cell of n-dimension and m types is described as:
All types of cells in this paper are described as follow: Hollow cell: Memory cell: Sole label memory cell: Multi-label memory cell:
(11) Affinity (
There are many ways to calculate affinity. In this paper, the affinity is calculated by Equation (1).
where a1, a2, …, a m are the components of each type of affinity in the cell; d is the Euclidean distance between the memory cell and the antigen.
(12) Cell division strategy: A strategy that makes the cell to divide. A high passage cell should be divided when it attacked by antigens.
(13) Memory cell inactive time (mcit): A memory cell will lose parts or all memory mcit after its last activation. This is the other parameter that needs to set in this method.
Invaders can be recognized and eliminated by antibodies when they first attack the immune system. Then the immune system cultivates memory cells to remember these invaders. These invaders can be recognized and eliminated very fast and more efficiently when they attack the immune system again [7, 16]. These memory cells are not invariable but evolving with the evolution of previous invaders. The model of CLCMTVD is inspired by this.
The main framework of the model includes culture memory cells process (training process) and recognition antigens process (testing process).
In this paper, all data should be normalized to [0, 1] n . Suppose the body is [0, 1] n and cells are not overlapped. The cell and body have the same size at initialization time.
Training process
The main function of this process is to culture memory cells. Cells divide and renew under the active by antibodies, and some of them evolved into memory cells. There are two main modules in the training process, include the activated cell module, and the cell division model. The framework of the training process for n-dimensional data (n≤3) is described as follows.
Step 1: Initialization, assign value to pm and mcit, and initialize cell set
Step 2: To culture cells.
This step includes an activated cell module and a cell division model, and it is a recursive call. In this recursion pattern, two modules each call the other.
The main function of the activated cell module is that whether a cell that is activated by antibodies needs to divide according to cell division strategy. The flowchart of the activate cell module is shown in Fig. 2.

The flowchart of the activated cell module.
The main function of the cell division module is to divide a cell into daughter cells, and initialization the parameters of its daughter cells. The flowchart of the cell division module is shown in Fig. 3.
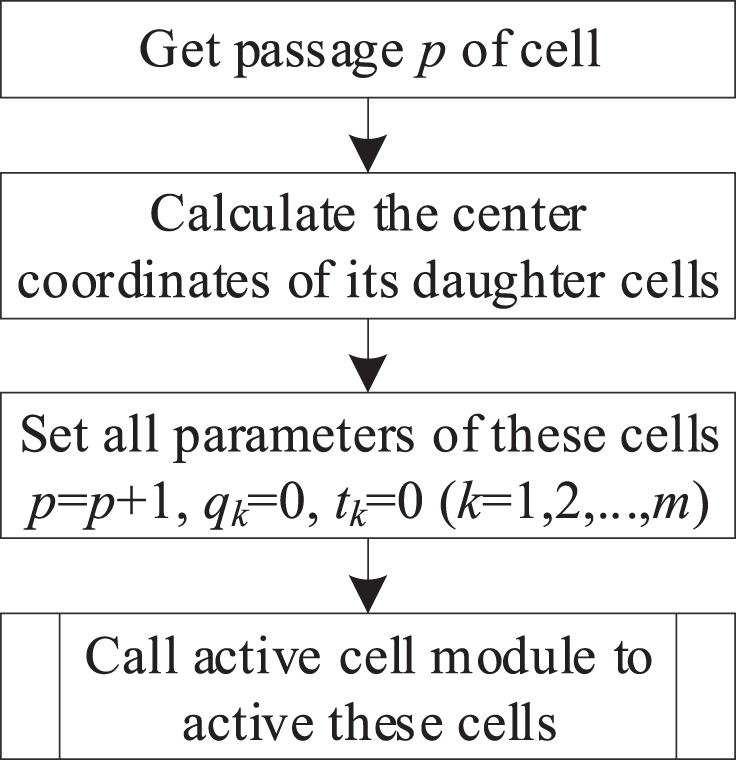
The flowchart of the cell division module.
During the training process, the recursive function calls are used a number of times. This training progress is described in [0, 1]2 as shown in Fig. 4. There are 3 types of samples, and the training samples and the initial cell are shown in Fig. 4a. The parameter pm = 4, and the cell division progress is shown in Fig. 4b, 4c, and 4d. All cells are shown in Fig. 4e. Different colors represent different types of memory cells, and the white represents hollow cells. Squares of different sizes are different passage cells, the larger size of the square, and the higher passage of cell.

The training process in [0, 1]2.
There are 112 cells, and 58 of them are memory cells. The last activation time of all cells set as 0. Cell 1, cell 4 and cell 8 are hollow cells, they are recorded as < 0.125, 0.125, 2, 0, 0, 0, 0, 0, 0>,<0.3125, 0.0625, 3, 0, 0, 0, 0, 0, 0>,<0.40625, 0.09375, 4, 0, 0, 0, 0, 0, 0>, respectively. Cell 9, cell 49 and cell 99 are sole label memory cells, they are recorded as < 0.46875, 0.09375, 4, 0, 0, 0, 0, 1, 0>,<0.53125, 0.46875, 4, 0, 0, 2, 0, 0, 0>,<0.71875, 0.84375, 4, 4, 0, 0, 0, 0, 0>, respectively. Cell 76 is a multi-label memory cell, and has two types of information. It is recorded as < 0.71875, 0.71875, 4, 2, 0, 3, 0, 0, 0 > .
An n-dimensional cell will divide into 2 n daughter cells. This can lead to very low efficiency for high-dimensional data. In this paper, an n-dimensional (n > 3) data (d1, d2, …, d n ) will be divided into n fragments, (d1, d2, d3), (d2, d3, d4), ... , (dn-2, dn-1, d n ), (dn-1, d n , d1), (d n , d1, d2), and then these fragments are used to culture memory cells respectively. For example, a 20-dimensional cell will divide into 220 = 1048576 daughter cells, but only 20×23 = 160 daughter cells are generated in this method. The flowchart of the training process for n-dimensional data (n > 3) is shown in Fig. 5.

The flowchart of the training process for n-dimensional data (n > 3).
Memory cells can recognize and eliminate invaders very fast and more efficient when they attack the immune system again. The type of antigen can be recognized by the affinity between this antigen and memory cells. Memory cells are used to recognize antigens in the testing progress of CLCMTVD. The hollow cells which are attacked by antigens can evolve into memory cells, and some memory cells these are not active for some time can be updated, even eliminated during the testing stage.
The framework of the testing process for n-dimensional data (n≤3) is described as follows.
Step 1: To delete the inactive sole label memory cells, and update the inactive multi-label memory cells.
If the last activation time of sole label memory cells is more than mcit, these memory cells need to delete. The parameters of these cells set as 0, such as q ik = 0, t ik = 0. If the last activation time of one type of multi-label memory cells is more than mcit, these memory cells need to update. The parameters of this type of these memory cells set as 0, such as q ij = 0, t ij = 0.
Step 2: To obtain the cell this is attacked by antigen.
If antigen attacks a high passage hollow cell, this cell needs to divide according to the cell division strategy.
Step 3: To find adjacent memory cells of this cell, and return the affinity.
If this cell is a hollow cell, return the affinities of its adjacent memory cells. If this cell is a memory cell, return the affinities of its adjacent memory cells and this memory cell.
Step 4: To determine the type of this antigen.
The type of this antigen is voting by the affinities, it is the same as the memory cell with the highest affinity.
Step 5: To update the memory cells.
If the sampling time of this antigen is later than the last activation time of these memory cells, update the last activation time of this cell and its adjacent memory cells. If this cell is a hollow cell, it will evolve into a memory cell.
Step 1, Step 2 and Step 3 can be named as the detection model, and Step 5 can be named as the updated model. The flowchart of the testing process for n-dimensional data (n≤3) is shown in Fig. 6.
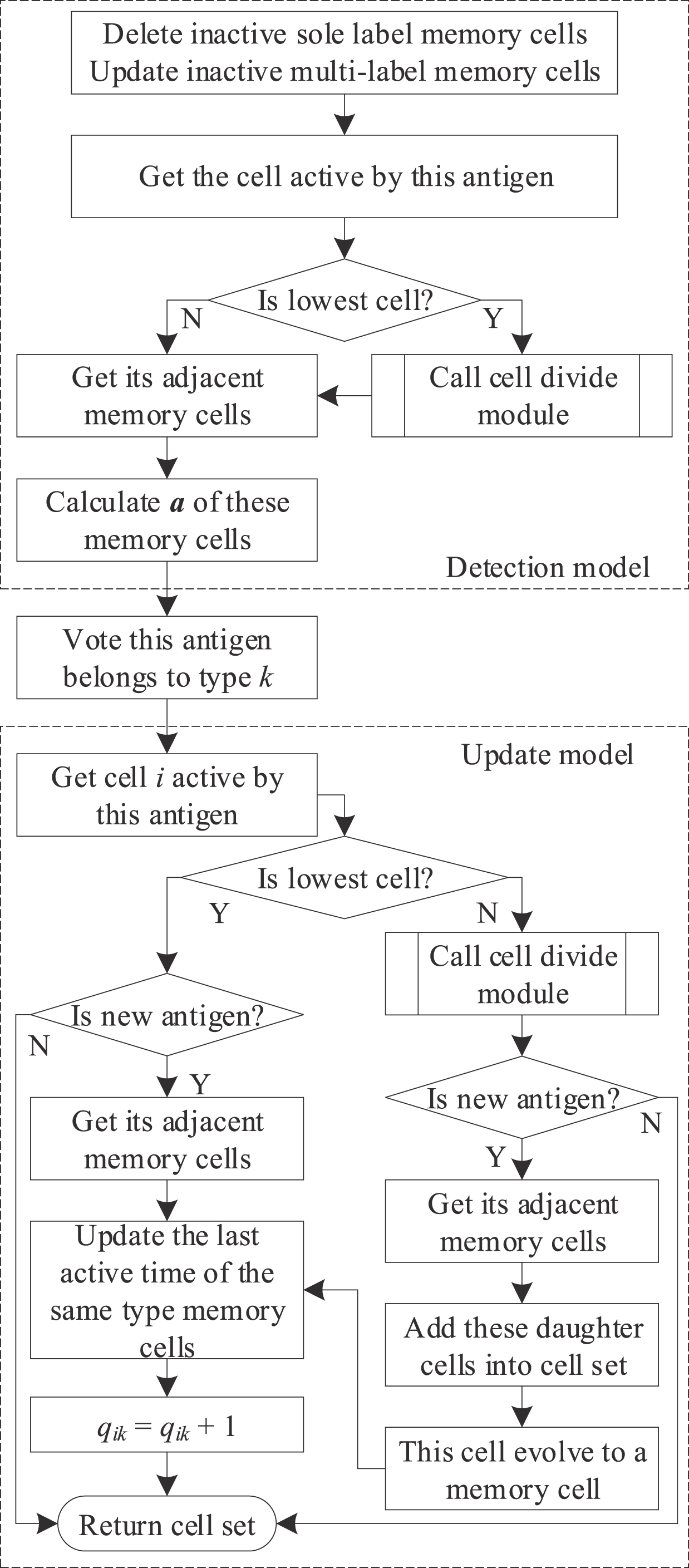
The flowchart of the testing process for n-dimensional data (n≤3).
The testing progress is described in [0, 1]2 as shown in Fig. 7. There are 3 types of samples, and the cells are cultured as shown in Fig. 7a. Suppose at t = 5, the brief descriptions of these memory cells are shown in the second column of Table 1. There are two antigens t1 and t2, and their sampling times are 6 and 7, respectively.

The continual learning testing progress (pm = 3, mcit = 2).
Descriptions of memory cells
At t = 6, an antigen t1 attacks cell 4, and this is a high passage hollow cell. Cell 4 divides into 4 daughter cells, cell 4, cell 29, cell 30 and cell 31. The adjacent memory cells of cell 4 include cell 17, cell 20 and cell 24, as shown in Fig. 7b. Antigen t1 belongs to type 2, and cell 4 evolved into a memory cell, as shown in Fig. 7c. The last activation time of cell 4, cell 17 and cell 20 update to t = 6; the last activation time of cell 24 does not update for its type is not the same to cell 4, as shown in the third columns of Table 1.
At t = 7, an antigen t2 attacks cell 7. The adjacent memory cell of cell 7 is cell 5, as shown in Fig. 7b. Antigen t2 belongs to type 3, and cell 7 evolved into a memory cell, as shown in Fig. 7d. The last activation time of cell 5 and cell 7 update to t = 7. At the same time, cell 13, cell 20 and cell 25 inactive more than mcit. Cell 13 and cell 25 was eliminated, and Cell 20 was updated, as shown in the fourth columns of Table 1.
For n-dimensional data (n > 3), the last activation time of memory cells should be updated after determining the type of this antigen. The flowchart of the continual learning testing process for n-dimensional data (n > 3) is shown in Fig. 8.

The flowchart of the testing process for n-dimensional data (n > 3).
When all data have the same sampling time (namely, data independent of time), CLCMTVD degenerates into a common supervised learning classification method. The memory cells cannot update during the testing stage.
In order to determine the performance and possible advantages of the proposed method, we carried out the experiments on well-known datasets from UCI repository, synthetic data [8], and XJTU-SY rolling element bearing accelerated life test datasets [5] and compared our results to those obtained by other classical classification algorithms.
The basic classification performance
CLCMTVD is a continual learning classification method that is used for time-varying data space. When all data have the same sampling time (namely, data independent of time), CLCMTVD degenerates into a common supervised learning classification method. Therefore, it must have better classification performance like other supervised learning classification methods.
This section applies twenty standard data benchmark datasets to validate the proposed method. The results were compared to the classification methods including Naïve Bayesian networks (NB), C4.5 algorithm, kNN, RIPPER, back propagation algorithm (BP) and sequential minimal optimization algorithm (SMO).
The datasets
We tested the CLCMTVD on 20 well-known datasets without missing values from the UCI repository to assess its classification performance and possible advantages [8]. The brief descriptions of these datasets are shown in Table 2.
Descriptions of datasets
Descriptions of datasets
Every dataset was divided into ten mutually exclusive and equal-sized subsets. For each classification method, nine subsets were used to train, and one subset was used to test. Cross-validation was run 10 times for each method, the data averaged.
CLCMTVD has bad classification performances of KR-vs-KP and Spambase datasets when they are used to train directly. Most of the value in these two datasets is the same, this causes the fragments are similar. In this paper, these two datasets are preprocessing with Principal Component Analysis (PCA), and their principal component scores instead of these two datasets.
Effect of parameter pm on the classification performance
The basic classification performance of CLCMTVD is only related to parameter p m. It determines the quantity and quality of cells. The quantity of cells affects the run efficiency of CLCMTVD, and the quality of cells affects the precision rate of CLCMTVD.
The precision rate (P) is defined as follows:
Where TP is the number of true positives, FP is the number of false positives.
The main space consumption is used to store cells, and the data store space is related to pm, n, and m. For a n-dimension and m types datasets, the maximum store space is (n + m+1)*n*(2 pm ) 3 (n > 3), and (2 + m+1)*(2 pm ) n (n≤3).
Experiments were carried out on Balance, Ionosphere, Iris, Letter, Segment, and Wine datasets to illustrate the effects of parameter pm on the classification performance of CLCMTVD, as shown in Fig. 9. There is no obvious regular between precision rate and pm. At the moment, the value of pm depends on experience.
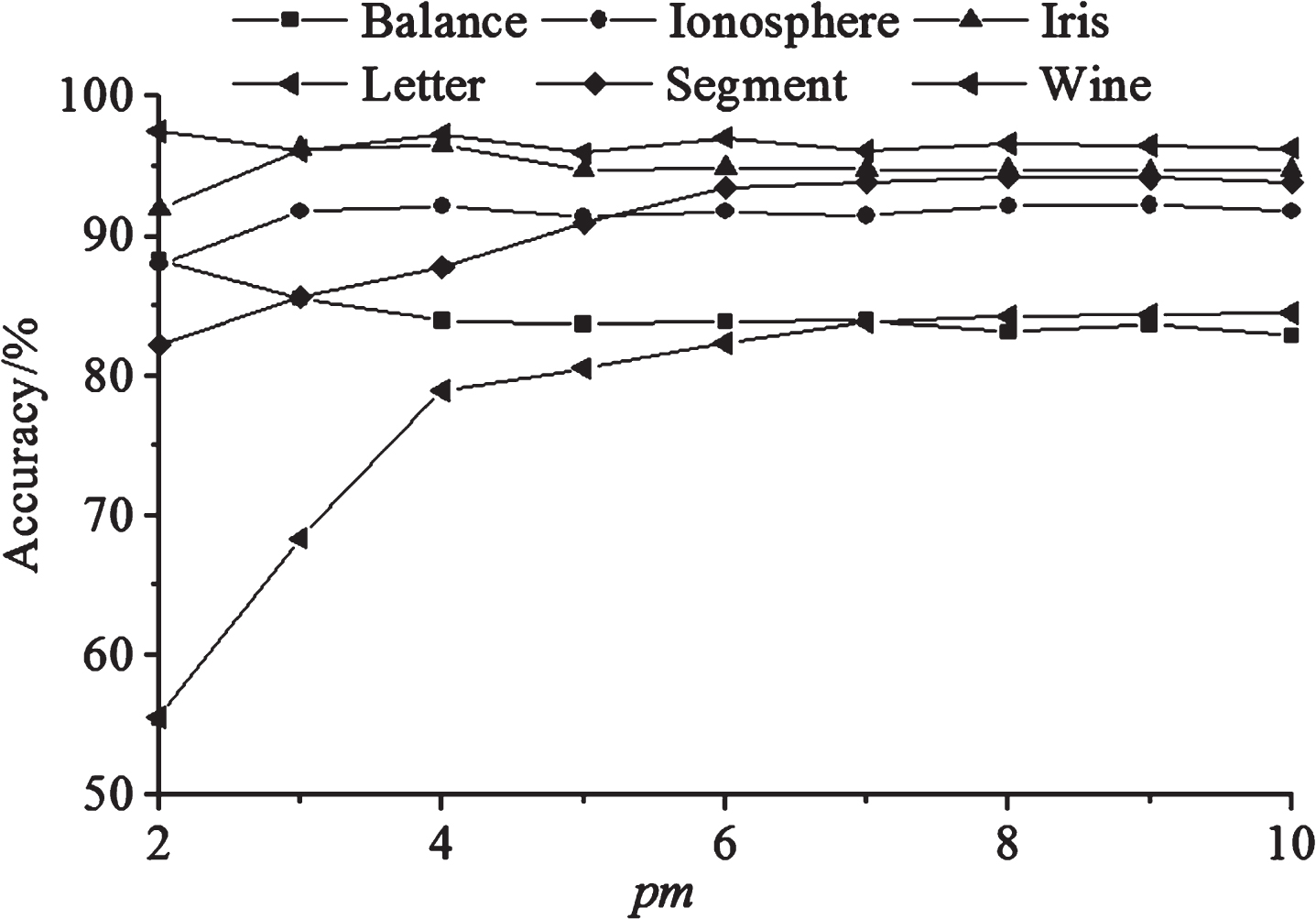
The effects of parameter p m on the classification performance of CLCMTVD.
The results are shown in Table 3, and the results of other methods are from previous literature [31].
The precision rate of each algorithm in each dataset (%)
The precision rate of each algorithm in each dataset (%)
Table 3 shows that the solutions obtained by the CLCMNLD are higher than the worst solutions that were obtained by the other algorithms. For Ionosphere and Iris datasets, CLCMTVD has the highest precision rate.
We tested the CLCMTVD on 2-dimensional time-varying synthetic data space to assess its classification performance and possible advantages. There are 3 types of samples, and the sample spaces at different dimensionless time are shown in Fig. 10.

The sample spaces at different dimensionless time.
CLCMTVD has two parameters, pm and mcit, need to be initialized. Parameter pm determines the size of memory cells, and mcit determines the speed of memory cells updating. Obviously, the number of cells and memory cells increases and the computational efficiency decrease with the increase of pm.
Eighty percent of samples from the first 100, 200, 300 and 400 dimensionless times randomly selected are used as training samples, and the rest samples are used as testing samples. All results were repeated 50 times, the data averaged. With the training samples from the first 100 dimensionless time as an example, the memory cells at different dimensionless time are shown in Fig. 11.

The memory cells at different dimensionless time (pm = 4, mcit = 10).
The classification performances have similar change rules with different training samples when all the other settings are the same, as shown in Fig. 12. The classification performance of CLCMTVD is based on the relative position and quantity of the different types of memory cells. The number of memory cells increases with the mcit increase and reduce the classification performance.
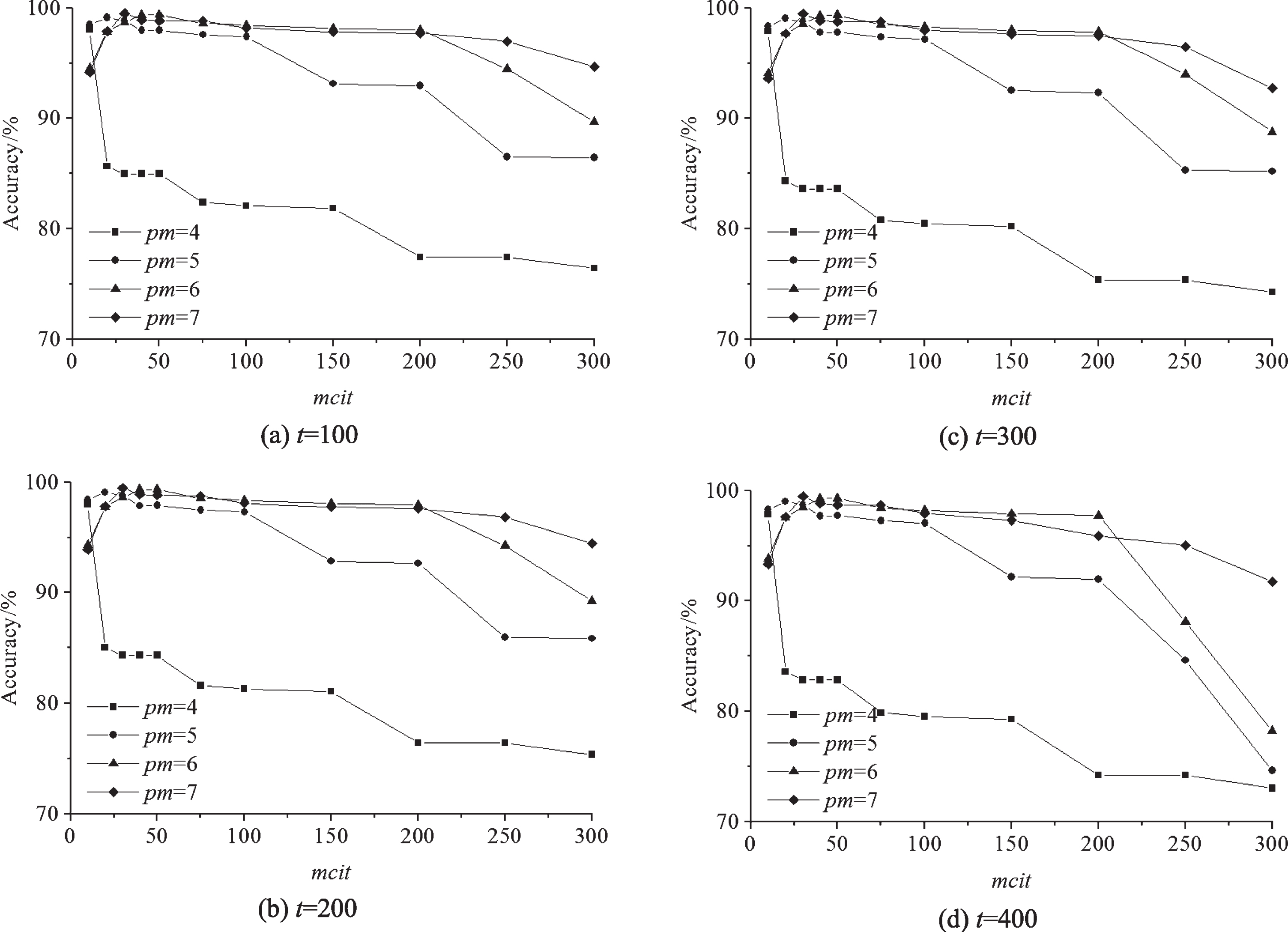
The classification performance with different parameters.
When pm = 4 the precision rate decreases with the mcit increase. This is because when pm is relatively small, the size of memory cells is relatively large. These memory cells occupy relative large spaces at some time. These spaces increase with the mcit increase and leading to low precision rate.
When pm = 5, pm = 6, and pm = 7 the precision rate increased firstly and decreased later with the mcit increase. This is because when pm is relatively large, the size of memory cells is relatively small. These memory cells occupy relative small spaces when mcit is relatively small, and they occupy relative large spaces when mcit is relatively large. All of these can lead to low precision rate.
When the memory cells and samples space change synchronous, CLCMTVD can get the best classification performance.
The classification performances change little with different training samples when all the other settings are the same because the memory cells evolve into a similar situation with the passage of time. Figures 13–15 and 16 show the memory cells with different training samples at different dimensionless times, and parameter pm = 5 and mcit = 20.

The memory cells at different time (Initial t = 100).

The memory cells at different time (Initial t = 200).
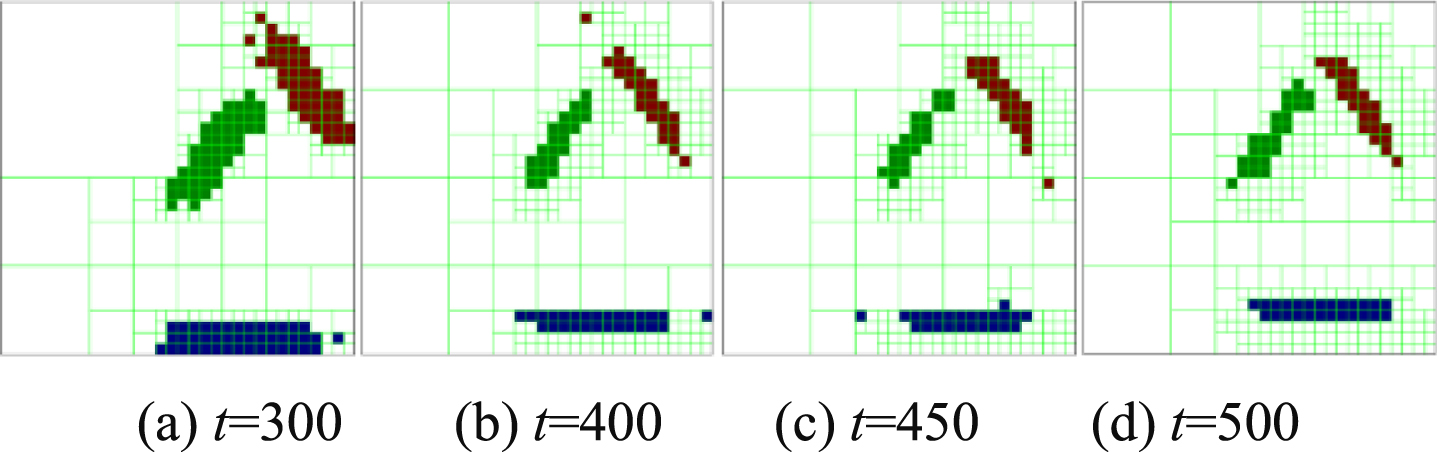
The memory cells at different time (Initial t = 300).

The memory cells at different time (Initial t = 400).
Figures 13a, 14a, 15a and 16a shows the initial memory cells, and these memory cells are different. Figures 13d, 14d, 15d and 16d shows the memory cells at dimensionless time t = 500, and these memory cells become very similar after a period of time for evolution. Figures 13c, 14c and 15b also shows this phenomenon.
We tested the CLCMTVD on 2-dimensional time-varying synthetic data space as shown in Fig. 10. The samples from the first 100, 200, 300 and 400 dimensionless times are used as training samples, and the rest samples are used as testing samples. The results were compared to BP, SVM, CNN and LSTM.
BP has 9 neurons of the hidden layer. SVM has RBF kernel and the parameters c and g are determined by adopting the cross validation method. The samples are transformed to grayscale images with 28*28 pixels, and then 15 Layers CNN which includes 3 convolutional layers, 3 normalization layers, 3 active layers, 2 pooling layers and 1 fully connected layer was used to classify these images. Bidirectional LSTM has 100 hidden units and 20 batch size. The parameter pm and mcit of CLCMTVD are 5 and 20 respectively. We also take sampling time as an attribute of samples for BP and SVM, recorded as BPt and SVMt respectively. The results of BP, BPt, SVM, SVMt, CNN and LSTM were repeated 50 times, the data averaged. The results of CLCMTVD only calculated once, because the classification results and the memory cells generated by CLCMTVD are constant when the training samples and all parameters do not change.
Figure 17 and Table 4 show that CLCMTVD has the highest precision rate because CLCMTVD can continuously update its memory cells by learning testing data during the testing stage.

The results of different methods.
The results of different methods
We tested the CLCMTVD on XJTU-SY rolling element bearing accelerated life test datasets to assess its classification performance and possible advantages.
The datasets
XJTU-SY rolling element bearing accelerated life test datasets [5] are provided by the Institute of Design Science and Basic Component at Xi’an Jiaotong University (XJTU), China and the Changxing Sumyoung Technology Co., Ltd. (SY) China.
The datasets were acquired by conducting many accelerated degradation experiments. A total of 3 different operating conditions were set in the accelerated degradation experiments, and 5 bearings were tested under each operating condition. We tested the CLCMTVD on one of them, and the brief descriptions of is shown in Table 5. Every instance includes horizontal vibration signals and vertical vibration signals.
Descriptions of datasets
Descriptions of datasets
The raw data is analyzed by “db16” wavelet for eight layers to get the high-frequency wavelet coefficients energy of each layer as the signal feature. The horizontal vibration signals and vertical vibration signals of each instance generate 8 signal features respectively. Every sample is composed of horizontal signal feature and vertical signal feature. All the samples are normalized to [0, 1]16.
The results and discussion
The first 40 samples from each datasets are used as training samples, and the rest samples are used as testing samples. The results were compared to BP, SVM, CNN and LSTM.
BP has 45 neurons of the hidden layer. SVM has RBF kernel and the parameters c and g are determined by adopting the cross validation method. The samples are transformed to grayscale images with 32*32 pixels, and then 15 Layers CNN which includes 3 convolutional layers, 3 normalization layers, 3 active layers, 2 pooling layers and 1 fully connected layer was used to classify these images. Bidirectional LSTM has 100 hidden units and 20 batch size. The parameter pm and mcit of CLCMTVD are 5 and 200 respectively.
Table 6 shows the detailed accuracy by class for every algorithm, including true positive rate (TPR), false positive rate (FPR), precision rate (P), recall rate (R), and F-Measure.
The detailed accuracy by class for every algorithm
The detailed accuracy by class for every algorithm
The recall rate (R) and F-Measure are defined as follows:
Table 6 shows that CLCMTVD has the better classification performance.
In this paper, we proposed a continual learning classification method for time-varying data space based on artificial immune system, named CLCMTVD. It can change a linearly inseparable spatial problem into many classification problems of several different times, and most of them are linearly separable spatial problems.
We carried out the experiments on well-known datasets from the UCI repository, synthetic data and XJTU-SY rolling element bearing accelerated life test datasets to assess the performance and possible advantages of CLCMTVD. The results of experiments on well-known datasets from the UCI repository show that CLCMTVD has better classification performance when it degenerates into a common supervised learning classification method. The result of experiments on 2-dimensional synthetic data and XJTU-SY rolling element bearing accelerated life test datasets show that CLCMTVD has the best classification performance for time-varying data space.
It is noteworthy that the CLCMTVD is incomplete. There are many future woks to do to improve it. The model only uses very simple classification strategies; it should combine with other classification methods to expand its advantage. It should be improved to apply to more complex time-varying data space.
Footnotes
Acknowledgments
This work was sponsored by the National Natural Science Foundation of China (Grant No. 52075310).