
Abstract
In the field of security, the data labels are unknown or the labels are too expensive to label, so that clustering methods are used to detect the threat behavior contained in the big data. The most widely used probabilistic clustering model is Gaussian Mixture Models(GMM), which is flexible and powerful to apply prior knowledge for modelling the uncertainty of the data. Therefore, in this paper, we use GMM to build the threat behavior detection model. Commonly, Expectation Maximization (EM) and Variational Inference (VI) are used to estimate the optimal parameters of GMM. However, both EM and VI are quite sensitive to the initial values of the parameters. Therefore, we propose to use Singular Value Decomposition (SVD) to initialize the parameters. Firstly, SVD is used to factorize the data set matrix to get the singular value matrix and singular matrices. Then we calculate the number of the components of GMM by the first two singular values in the singular value matrix and the dimension of the data. Next, other parameters of GMM, such as the mixing coefficients, the mean and the covariance, are calculated based on the number of the components. After that, the initialization values of the parameters are input into EM and VI to estimate the optimal parameters of GMM. The experiment results indicate that our proposed method performs well on the parameters initialization of GMM clustering using EM and VI for estimating parameters.
Keywords
Introduction
With the rapid development of new generation information technology, such as mobile internet, big data, cloud computing and artificial intelligence, the service and applications of network and data are growing explosively. Meanwhile, malicious network activities and network policy violations have been frequently exposed, such as extortion virus attacks, data leakage, Botnet traffic attack, which have brought great challenges to the cybersecurity. Consequently, Intrusion Detection Systems (IDSs) have emerged with a group of methods to detect the intruders who break the computer system or misuse the system resources [1, 2]. One of the popular intrusion detection methods is to use machine learning and data mining techniques for Internet traffic malicious/benign classification based on the statistical traffic characteristics [2–5].
Generally, machine learning and data mining techniques can be divided into classification and clustering [6]. Classification analysis is known as supervised learning methods, which deal with already labeled or classified data. The goal of the classification is to determine a certain object to belong to the explicit group. Clustering analysis is known as unsupervised learning methods, which do not depend on the predefined labels. And the objective is to calculate the difference between the data and to classify data into groups based on the similarity or dissimilarity measures [7–9]. Once the data labels are not known, the clustering analysis methods can only be used.
The clustering methods can be divided into three general categories: partitional methods evaluating partitions based on some criterion, distance-based methods calculating the distance between clusters, and parametric model based methods built via probabilistic mixture models [7, 10]. The most widely used probabilistic mixture model is Gaussian Mixture Models(GMM) [10, 12–15], which is a probabilistic model assuming all the data samples fitting a mixture of a finite number of Gaussian distributions with unknown parameters. GMM is flexible and powerful to apply prior knowledge for modeling the uncertainty of the data. The advantage of GMM is that the amount of learning parameters is small and the involved parameters can be efficiently estimated [16]. Many researches on mixture models have given attention to the parameters estimation. Commonly, Expectation Maximization (EM) is considered an efficient algorithm to estimate the parameters of GMM by maximizing the log-likelihood function [17, 18]. Afterwards, Variational Inference (VI) has been proposed to estimate the value of the parameters through maximizing the evidence of lower bound in a coordinate ascend mechanism [19–21]. However, both EM and VI are quite sensitive to initial values in the iterative updating of parameters, and the performance of GMM clustering method strongly depends on the initial starting points [10, 23–25]. Therefore, we concentrate on the parameters initialization while EM and VI are used to estimate the optimal parameters of GMM.
In the process of GMM parameters estimation, a critical issue is to determine a proper number of GMM components. Generally, the larger the number is, the greater amount of calculation on all components is, and the higher the fitness of GMM is to the data in learning stage. Furthermore, the calculation load is higher and under-fitting may occur in the testing stage. Therefore, it is important to choose the proper value of GMM components number. In most cases, the value of the components number is set to a random value, which does not satisfy the data distribution neither lead to overfitting and poor generalization [26, 27]. In [28], Bayesian Information Criterion (BIC) is used to choose proper number from a series of comparisons on the GMM clustering results. However, this method often leads to get an unreasonably high number of poorly components. In [23], a robust EM clustering algorithm is developed to automatically obtain an optimal number of clusters. On the whole, all initialization techniques can be generally divided into deterministic and stochastic [13, 27]. The deterministic initialization methods estimate the start points based on the results from the clustering algorithms, such as hierarchical clustering [29]. The disadvantage of the deterministic methods is that they can not be compatible with other possible initial values, which may lead to an incorrect solution for the final results. The stochastic initialization methods choose the start points from any one in the parameter space. The choosing rule is to try different starting values and finally determine the one that yields the best results, such as BIC [28]. Because of the initialization steps repeating several times, the choosing procedures of BIC need to cost more time and computing resources comparing with the deterministic methods. In addition, there are some other initialization techniques in the literature referring to some more comprehensive reviews [13, 31]. However, there are few papers to compare the proposed initialization techniques to asses which one is the best method. That is because some methods lack the compatibility, that are only suitable for some special scenarios. In this paper, we try to solve the compatibility problem based on Singular Value Decomposition (SVD) to make our initialization method suitable for a variety of data sets, such as high-dimensional. SVD is considered as a popular deterministic initialization method for Nonnegative Matrix Factorization (NMF) [32, 33]. SVD can factorize the data matrix into the form of multiplication of three matrices, including left-singular matrix, singular values matrix and right-singular matrix. These matrices can be interpreted as the features and clusters of the data sets. Therefor, we apply SVD to initialize the parameters of GMM.
GMM has several parameters to learn. In addition to considering the number of components, the initialization of the means and variances in GMM is also important. When the number of GMM components is determined, it means that the data can been divide into multiple initial clusters. The means and variances of the initial clusters from the data can be calculated. By definition, there is only one way to calculate the row mean by computing the average of the elements along the row axis and returning a row vector. Unlike the mean, the variance has many structures, such as diagonal, compound-symmetry, unstructured, time-series, and spatial [34]. For a whole data set composed of several clusters, the variance of the data set also has multiple types. For example, each cluster has its own general covariance matrix, all clusters share the same general covariance matrix, each cluster has its own diagonal covariance matrix and each cluster has its own single variance [35]. In this paper, we choose the type that each cluster has its own general covariance matrix. And we calculate the covariance matrix of each cluster through the classical maximum likelihood estimator, which is an unbiased estimator of the corresponding clusters’ covariance matrix [36].
Based on the above analysis, in this paper, we propose a new parameters initialization method based on SVD for GMM on the network threat detection. Firstly, GMM is built which contains several parameters, such as the number of GMM components, the mixing coefficients of the components, the mean of each component and the covariance of each component. Secondly, we use SVD to factorize the data matrix. Then we obtain the number of GMM components according to the singular values matrix. Meanwhile, the data are divided into several initial clusters. Next, we calculate the mean of each component according to the definition. And we calculate the covariance of each component through the classical maximum likelihood estimator, respectively. Thirdly, based on the initialization values of the parameters, EM and VI are used to continue to inference the optimal parameters of GMM, respectively, until GMM converges to its maximum output value and the optimal values of the parameters reaching steady state. Once these parameters are estimated, they are used to assign the network data samples into threat group or normal group based on the posterior probabilities of inclusion. The experiment results indicate that our proposed initialization method based on SVD provides more accurate parameter initialization, better generalization for GMM, lower computational complexity and less running time.
The rest of this paper is structured as follows. In Section 2 we introduce GMM for the data set containing several parameters, then EM and VI are used to inference the optimal values of the parameters. In section 3 we propose the parameters initialization method based on SVD. In section 4 we describe the overall solution framework of the model. In section 5 we describe the experiment setting and results in detail. In section 6 we conclude the paper.
GMM and parameters inference
In this section, we firstly introduce GMM for the data sets, containing several parameters. Then, we describe the process of EM algorithm to estimate the optimal values of the parameters. Next, we describe the process of VI algorithm to estimate the optimal values of the parameters.
GMM
GMM is powerful model-based to draw the entire data set to solve the clustering problem, while the clustering problem is reduced to estimate the parameters of the GMM. Suppose data set X = (x1, x2, …, x
n
, … x
N
), x
n
= (xn1, xn2, …, x
nD
)
T
, n = (1, 2, …, N) contains N independent D-dimensional samples, which are divided into Kclusters. The data is identically distributed by the multivariate Gaussian mixture model, which is a linear combination of more than one Gaussian distribution [37]. The Probability Density Function (PDF) is given by
In (1) and (2), K is the number of GMM components, π
k
is the mixing coefficients of the kth component satisfying the constrains 0 ≤ π
k
≤ 1 and
EM algorithm is considered to be the most effective method of parameter estimation, which operates with the complete-data log likelihood function, starting from parameters with initial values and iterating through E-step and M-step. The complete-data log likelihood function of N data samples is given by [34, 38]
At the E-step, EM calculates posterior probabilities that the nth sample belongs to the kth component. For GMM, the posterior probabilities are calculated by
In (4)-(6), we note that the value of highest posterior probability depends on the parameters π k , μ k and ∑ k . In some situation,one drawback of EM is that it converges slowly, so that many algorithms have been proposed to speed up the convergence while keeping its simplicity [38]. Another drawback of EM is that the solution highly depends on the initial values of the parameters and consequently produce sub-optimal maximum likelihood estimates [10, 27]. To overcome these limitations, it needs to propose a new method to set the proper initial position for the parameters, which is also helpful to speed up the convergence. In this paper, we pay much attention to calculate the initial values of parameters K, π k , μ k and ∑ k .
In the EM algorithm, it needs to calculate the expectation of the complete-data log likelihood with respect to the posterior of the latent variables. However, in some practice instance, the dimension of the data set is too high, or the posterior distribution has a highly complex form, so that it is hard to compute the expectation. In such situation, approximation schemes are considered effective to solve these problems. One of the widely applied approximation techniques is Variational Inference(VI), which uses more global criteria to computer the posterior [26, 39].
In this paper, we calculate the variational inference approximation solution for (1). Our goal is to infer the posterior distribution for the mean vector μ k and the covariance matrix ∑ k , given the samples x n drawn independently [38, 41].
In VI framework, X = (x1, x2, …, x N ) is regarded as data set. For each sample x n , it has a corresponding latent variable z n , which comprises a l-of-K binary vector with elements Z = {z nk }, k = 1, 2, . . . , K. z n , π k , μ k and ∑ k are regarded as latent variables as well as parameters, and can be written as Θ = {Z, π k , μ k , ∑ k }. The mixture model can be denoted as p (X|Θ), the goal is to find an approximation for the posterior distribution p (X|Θ) as well as for the model evidence p (X). Then we introduce conjugate prior distributions over the parameters Z, π k , μ k , ∑. The analysis will be become considerably simplified.
Dirichlet distribution is used over the mixing coefficient π
k
as follows [39]
Similarly, an independent Gaussian-Wishart prior is used to control the mean μ
k
and covariance ∑
k
of each component as follows
According to the general expression for the optimal solution
respect to all the distributions of
We obtain the variational update equations of the intermediate parameters, given by
To calculate the expectations E [z
nk
] = r
nk
, which obtained by ρ
nk
given by (12). In (12), the expression involves the expectations with respect to the variational distributions of the parameters, and these are easily evaluated by
See the above formulas, like EM algorithm, we note that the optimal solutions depend on the expectations evaluated with respect to the distributions of other variables. So the variational update Equations (12)-(21) must be solved iteratively. The parameters should be initialized carefully. In most situation, parameter initialization of VI is considered random [26, 44], or an explicit value, such as zero matrix or one matrix. However, an inappropriate initialization may could cause local maximum or overfitting [45]. Therefore, in these iterative algorithms, we attach great importance to the parameter initialization.
Singular Value Decomposition (SVD) is a popular matrix decomposition technology, which can factorize the whole data set into the form of multiplication of two or more matrices, enhancing the interpretability of the data set [46, 47]. Furthermore, the factorized matrices by SVD have some helpful characteristics and significance for analyzing the original data [48]. Therefore, we propose a new initialization method for GMM parameters based on SVD. Our objective is to find initial positions for GMM to group the data into Kclusters, which is equivalent to the components number of GMM. Then we calculate the mixing coefficients, the mean and covariance based on the initial Kclusters, each of that contains some independent samples.
In this paper, by SVD the data set N × D matrix X is factorized into X = USV T , where U is an N × N orthonormal matrix, S is an N × D rectangular diagonal matrix with non-negative and decreasing diagonal entries and V is an D × D orthonormal matrix. V T is the conjugate transpose of V. U and V T are called left-singular vector and right-singular vector, respectively.S is determined by X. Singular values s i in singular values matrix S are sorted in descending order on the diagonal [48]. The faster the singular values decrease, the greater the change of the singular values is, and the more information about the clusters the front singular values contains.
This is the theoretical basis for parameters initialization in the following sections. Next, we introduce our proposed initialization method based on SVD for GMM parameters as follows:
(1) The data factorized by SVD. Given the data set N × D matrix X, SVD works by factorizing X into X = USV T , and we can obtain U,S, V T . Then, we determine the initial values of the GMM parameters based on the negative values in U and S.
(2) The number of the GMM components K initialization. On one hand, singular values in S are listed in descending order. Few of the first largest singular values can be extracted to contain enough information of the whole data set [47]. Therefore, we calculate the first singular value s0 divided by the first singular value s1 to estimate the downward trend of the singular values matrix. On the other hand, the dimension of S is the same as that of the data X. A larger number of dimension will increase the dispersion of the singular values. Therefore, we need to consider the dimension ofSwhen we keep the number of the singular values. Finally, we estimate the reserved number K′ of the singular values depending on the first two singular values and the dimension of D, given by
The first K′ singular values of S are kept, and correspondingly, we extract first K′ columns of U. According to the row sequence number of the maximum values of each column, the data are assigned into K′ clusters. Each cluster is described by one Gaussian model. So the number of clusters K′ is equal to the number of Gaussian models K. Further more, the number o GMM components is K = K′.
(3) The initial subsets based on SVD. In step (2), U is converted to be an N × K singular vector. Based on the theoretical basis of SVD [48], the rows of U come from mapping the rows of X. The values represent the relevance between the data and the clusters. The bigger the value is, and the more relevant it is. So we achieve cluster information from U. At first, we find the maximum value in each column of U. And, we list the sequence numbers corresponding to the maximum values. Then, we put the data samples with the same sequence numbers into one cluster. Finally, the data samples are segmented into K initial subsets {X k } (k = 1, 2, …, K) and with the kth sequence number assigned into the kth cluster. The length of the kth initial subset is defined as len (X k ).
(4) The mixing coefficients
(5) The mean
The covariance
Initialization based on SVD only computes the matrix factorization once. Then the initialization process is to convert how to treat negative values in S and U and how to deal with the data in the initial clusters. Therefore, the initialization based on SVD is deterministic and generalize, meaning that it is not specifically designed for a special kind of data.
The overall solution of the model contains two parts: Parameters initialization, parameters estimation. In parameters initialization part, firstly, SVD is used to factorize the data matrix X to obtain U, S, V T . Secondly, the number of clusters K′ is calculated based on S. Then the number of GMM components K can be calculated based on K′. Next, the data set are segmented into K subsets {X k } based on K′ and U. Thirdly, the mixing coefficients π k , the mean μ k and the covariance ∑ k are calculated. In parameters estimation part, based on the initialization values of the parameters, EM and VI are used to continue to inference the optimal parameters of GMM, respectively, until GMM converges. The overall solution of the model is shown in Fig. 1.
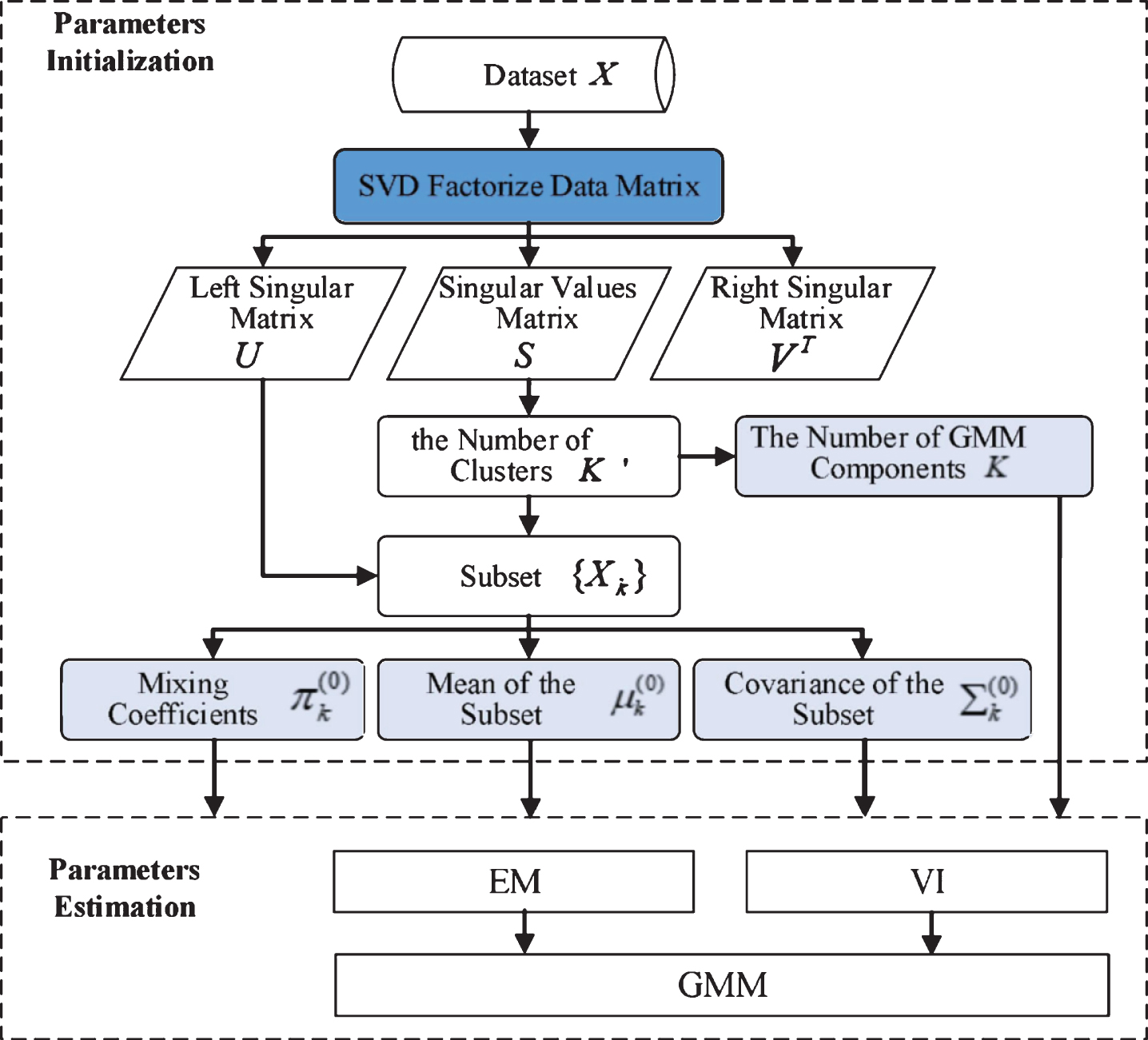
Overall solution of the model.
In this section, to evaluate the performance of our proposed method, a series of experiments are arranged with respects of EM and VI algorithms in multivariate GMM starting with different initialization methods. The objective is to illustrate the performance of our method by comparing with different other methods working on different data sets.
Experimental data sets and Settings
In this paper, our goal is to evaluate our proposed method to initialize parameters in Gaussian mixture clustering models to analyze network security data to find the hidden threat behavior. To illustrate our proposed method works helpful, we get some public security data sets and UCI common data sets with different dimensions and clusters. We investigate the performance of five different initialization methods: RndEM [27], ∑-EM [13], K-means (denoted as KmEM), Random method and our proposed method (denoted as SVD-based). And we use the Adjusted Rand Index(ARI) to evaluate the performance of the experiments. All experiments are preformed in JetBrains PyCharm 2017 with python 3.6 interpreter on a laptop Intel CORE i5-6200U 2.3 GHz with 8GB RAM running the Windows 10 OS.
Data sets
In this section, we introduce the data sets containing the security data sets and common data sets from UCI machine learning repository [50]. The details of the data sets are presented in Table 1.
The details of the data sets used ins the experiments
The details of the data sets used ins the experiments
In Table 1, there are 7 data sets containing 5 security data sets in first five and 2 common databases from UCI machine learning repository in last two. These data sets have their own characteristics. Firstly, the data sets have different sample sizes, attribute dimensions and the number of the original clusters. Among them, KDDCUP 10percent Multiclass.csv and KDDCUP 10percent 2class.csv are the biggest data sets with big sample size. Secondly, the data sets have different sample distribution, Spambase.csv, Phishing Websites.csv, Iris.csv and Wine.csv are balanced data sets, while Websites Phishing.csv, KDDCUP 10percent Multiclass.csv and KDDCUP 10percent 2class.csv are unbalanced data sets. In unbalanced data sets, the minority examples are more likely to be misclassified. Thirdly, the data sets have different overlap degree, which is measured by silhouette coefficient. The silhouette coefficient score is bounded between -1 for incorrect clustering and +1 for highly dense clustering. When the core around zero indicates the clusters is overlapping. Among all the data sets, KDDCUP 10percent Multiclass.csv, KDDCUP 10percent 2class.csv and Spambase.csv have lower overlap degree, while Phishing Websites.csv and Websites Phishing.csv have higher overlap degree. Fourthly, the data sets have different attribute types. The attribute types of Spambase.csv, KDDCUP 10percent Multiclass.csv, KDDCUP 10percent 2class.csv and Wine.csv are integer and real. The attribute types of Phishing Websites.csv and Websites Phishing.csv are binary. The attribute type of Iris.csv is real. These differences in data sets lead to different performance of GMM models.
We compare our methods with the following baseline approaches: RndEM [27] is a staged approach to specify initial values by finding a large number of local modes. This method valuates the likelihood at the initial valid random start and chooses the parameters with highest likelihood. ∑-EM [13] is proposed to initialize EM algorithm to determine the number of GMM components. The method finds initial parameter by choosing samples with higher concentrations of neighbors to form clusters and then eliminates the fake components by comparing the Bayesian Information Criterion (BIC). KmEM [29, 51] can divide data sets into Kclusters through assigning each sample to the nearest cluster center. KmEM is conceptual simplicity and computational scalability, so it is widely used as a initialization method to separate samples into different groups at first step and it can quickly provide a reasonable single-membership partition as a starting sample for GMM inference.
RndEM, ∑-EM and KmEM have already used as initiation methods for EM. While there are few literatures to study the initiation method for VI. So we can only compare our proposed method with the approaches for EM. Actually, both our proposed method and the baseline approaches are working in the stage before EM and VI estimating parameters. Therefore, the baseline approaches are very suitable for comparison.
Evaluation metrics
In this paper, we use the ARI to evaluate the all experiment results which are shown in section 5.2. ARI computers the similarity between two clusters by computing all pairs numbers of samples, and the pairs that are assigned in the same or different clusters according to the true cluster labels and the predicted cluster labels [13, 52]. The range of the ARI values is [–1, 1]. When the ARI values are negative indicating the clustering results are bad and the predicted labels are independent. On the contrary, When the ARI values are close to 1 indicating the clustering result is a perfect match between the true labels and predicted labels. The advantage of ARI is that it does not make any assumption on the cluster structure and it can be used to compare the similarities between clustering results of any clustering algorithm. But ARI needs to know the true labels. The ARI is defined as follows:
Evaluation on the number of GMM components based on SVD
In GMM, the number of mixing components K is important, which determines the final clustering results. In this section, we use our proposed method to obtain the initia value of K. Firstly, we use SVD to factorize the data matrix to divide the data into K initial clusters which is equivalent to the mixing components of the probabilistic model. Secondly, the mixing coefficients π k of each component is set to 1/K, the mean μ k of each component is set to equal the mean of X, and the convariance ∑ k of each component is set to equal the covariance of X. Thirdly, we input these initial values into GMM, then the parameters are further estimated by EM and VI respectively. To illustrate the effectiveness of the proposed method, we manually set K to the fixed numbers in the range [2, 10]. By comparing the performance of GMM with initial value based on SVD and fixed value, we can find our initialization algorithm computing K value based on SVD is appropriate. The number of model iteration is performed to 100. The performance of GMM clustering using EM and VI estimating parameters initialized based on the fixed values setting and SVD is summarized in Tables 2 and 3.
Summarized Adjusted Rand Index (ARI) and the components number of GMM clustering using EM estimating parameters with fixed values setting and SVD-based initialization methods
Summarized Adjusted Rand Index (ARI) and the components number of GMM clustering using EM estimating parameters with fixed values setting and SVD-based initialization methods
Summarized Adjusted Rand Index (ARI) and the components number of GMM clustering using VI estimating parameters with fixed values setting and SVD-based initialization methods
Tables 2 and 3 summarize the ARI and the components number of GMM clustering using EM and VI estimating parameters with fixed values setting and SVD-based initialization methods, respectively. Firstly, we fix the range of the components number is [2, 10], and calculate the ARI of GMM. Then we calculate the components number based on SVD and the ARI of GMM.
From the experiment results, we find that, in most cases, the numbers of components corresponding to the best ARI in the fixed range and the numbers of components based on SVD are not the same. And theyare not equal to the original numbers of the clusters in Table 1. Furthermore, in most cases, the ARIs based on SVD are better than that of the original clusters, and close to the highest ARIs in the fixed range. However, comparing the best the components numbers and ARIs through the numerous attempts in the fixed range like BIC, our SVD-based method only executes once to get better results. For Websites Phishing.csv, Iris.csv and Wine.csv, our SVD-based method receive the best performance, which is the same to that of the original clusters. Therefore, our proposed approach is recommended for the numbers of components initialization. Comparing the ARI of the same data sets and the numbers of components in Tables 2 and 3, we find VI is better than EM on the parameter estimating for GMM clustering. Especially on the big data sets, such as KDDCUP 10percent Multiclass.csv and KDDCUP 10percent 2class.csv, the performance is greatly improved by VI. Maybe it is easy for EM to fall into the local optimum in the iterative process. However, the efficiency of VI is lower than that of EM in the whole process, especially on the big data sets. This can be explained by the complexity of the algorithms, where the steps of VI are more complicated than that of EM according to the formulas (12)-(24) and (4)-(6). Therefore, if the performance is the final target, VI is recommended for the optimal parameter estimating.
In last section, through comparing the performance of the components initial number K based on fixed values with a range [2, 10] andSVD - based, we find that the component initial number K based on SVD can provide preferable effect. In this section, we want to prove the initialization values of the mixing coefficients π k , the mean μ k and the convariance ∑ k based on SVD are useful to improve the performance of GMM, comparing the fixed initialization values. For the initialization values based on SVD, the values of K are calculated by the first two singular values and the dimension of D, the values of the mixing coefficients π k , the mean μ k and the convariance ∑ k are calculated based on K. As the comparative algorithm, the parameters values are all initialized to the fixed value, such as the components number K is set to equal the length of true labels K0, the mixing coefficients π k of each component is set to 1/K, the mean μ k of each component is set to equal the mean of X, and the convariance ∑ k of each component is set to equal the covariance of X. The number of model iterations is performed to 100. All parameters initialized based on SVD and the fixed values of GMM clustering using EM is summarized in Tables 4 and 5.
Summarized the performance of all parameters initialized based on SVD and the fixed values of GMM clustering using EM
Summarized the performance of all parameters initialized based on SVD and the fixed values of GMM clustering using EM
Summarized the performance of all parameters initialized based on SVD and the fixed values of GMM clustering using VI
Tables 4 and 5 summarize the ARI and the components number of GMM clustering using EM and VI estimating optimal parameters with K initialized and all parameters initialized by SVD-based method and fixed method, respectively. Firstly, we calculate the components number K based on SVD and the ARI of GMM while other parameters initialized on the fixed values. Secondly, we calculate all parameters initialized based on SVD and the ARI of GMM. Thirdly, we calculate the ARI of GMM when all parameters initialized on the fixed values. From the experiment results in Tables 4 and 5, we find that, in most cases, the performance of all parameters initialized based on SVD is better than that of only K initialized based on SVD. Meanwhile, the performance of all parameters initialized based on SVD is far better than that of all parameters with fixed values. In addition, comparing the results between Tables 4 and 5, we find the performance of VI is better than that of EM on the parameter estimating for GMM clustering.
In the existing literatures, there already have been some deterministic initialization methods, such as RndEM, ∑-EM and KmEM. In this section, we compare our initialization methods by SVD-based and other deterministic methods. In SVD-based initialization method, the values of the parameters are calculated based on the matrix decomposition of the original data set. In RndEM, ∑-EM and KmEM, the components number K is calculated according to the steps of the algorithms, respectively. And then the initialization values of the mixing coefficients π k , the mean μ k and the convariance ∑ k are calculated based on K. The number of model iterations is performed to 100. The performance of GMM clustering using EM and VI initialized based on different methods is summarized in Tables 6 and 7
Summarized the performance of all parameters initialized based on different methods of GMM clustering using EM
Summarized the performance of all parameters initialized based on different methods of GMM clustering using EM
Summarized the performance of all parameters initialized based on different methods of GMM clustering using VI
Tables 6 and 7 summarize the ARI and the components number of GMM clustering using EM and VI estimating all parameters based on different methods, respectively. RndEM, ∑-EM and SVD-based methods calculate the components number K according to the theory. In KmEM, the initialized values of K come from the length of true labels K0. From the experiment results in Tables 6 and 7, we find that, in most cases, SVD-based method prefers over other methods. The performance of KmEM is the worst on the security data set. And RndEM comes the next. ∑-EM and RndEM show similar results on the components number K, while the ARI of ∑-EM is better than that of RndEM. Moreover, we can not use RndEM, ∑-EM to calculate the components number and the final ARI successfully on the big data, such as KDDCUP 10percent Multiclass.csv and KDDCUP 10percent 2class.csv. In the algorithmic program, we upload the whole data set into the memory at one time. Then the program calculate the Euclidean Distance between any two samples. When the amount of data is large, there is a memory overflow problem happening. To solve this problem, we will change the way to the algorithmic program. However, RndEM and ∑-EM have another obvious drawback that is the calculation process complicated, spending high source and taking long time. In conclusion, SVD-based method demonstrates good overall performance on all the parameters initialization, and performs well no matter how large the amount of data is and what the type of data is. Therefore, SVD-based is recommended as an excellent initialization method.
This section compares the computational cost of the initialization methods. We analyze the computational complexity based on the execution time of the algorithmic program, which is related to the number of iterations of some basic statements in the algorithm. The more iterations, the more time the method takes. In this section, we assume that the number of iterations of the algorithm is s, the number of samples is N, the dimension is D, and the number of clusters is K. The theoretical value of the computational complexity is analyzed in Table 8, where the execution time of the algorithm increases with the increase of the data size. Furthermore, we record the actual values of the computational complexity when the algorithmic programs are running. The actual values of the computational complexity is record in Table 9.
Summarized the computational complexity of different initialization methods
Summarized the computational complexity of different initialization methods
Summarized the running time of the initialization methods
Table 8 summarizes the computational complexity of different initialization methods. We find that the computational complexity is relate to the dimension and the number of the samples. When the dimension of the samples is higher than the number, the complexity of the SVD-based method is greatest. However, this case is rare in big data analysis. In actually, the number of the samples is far bigger than the dimension, and the complexity of the SVD-based method is lowest. By contrast, the complexity of ∑-EM is greatest, RndEM takes the second place, and KmEM takes the third place, whose complexity is less than that of SVD-based method.
Table 8 records the actual running time of different initialization methods. We find that SVD-based method cost the least time, KmEM cost less time, RndEM cost more time, and ∑-EM cost the most time. The results in Table 8 are consistent with those in Table 9. Therefore, we can conclude that SVD-based method outperforms other initialization methods in the computational complexity and running time.
EM and VI are important for parameter estimation in GMM. Initialization is a crucial step in EM and VI that is because initialization can determine the convergence of the mixture models to the local maximum and also affect the speed of convergence. Presently, there already have been some initialization strategy for EM. However, no one outperforms other methods. Meanwhile, the majority of existing methods perform well on the simulate data but does not experience experiments on the real data sets. And the majority of existing methods have high complexity on the big data especially when deal with a large number of clusters.
Our proposed strategy is based on SVD to factorize the data set matrix to get the singular value matrix and singular matrixs. Then we calculate the number of the components of GMM by the first two singular values in the singular value matrix and the dimension of the data. Next, other parameters of GMM, such as the mixing coefficients,the mean and the convariance, are calculated based on the number of the components. The performance of GMM clustering using EM and VI estimating optimal parameters based on SVD initialization parameters is compared to three other initialization approaches on the security databases and common databases from UCI machine learning repository, which have different clusters, dimensions and types. However, SVD has some defects. For example, when the dimension of the data set is very high, the calculation complexity will be high. And when the data set matrix is too sparse, the effect of matrix decomposition is poor. Therefor, our proposed strategy can not deal with high dimension and sparse data set well.
The experiment results indicate that our proposed method performs well on the components number of GMM clustering using EM and VI estimating optimal parameters, and also other parameters containing the mixing coefficients, the mean and the convariance. And VI is better than EM on the optimal parameter estimating for GMM clustering. Especially on the big data set. Furthermore, our proposed method has good performance no matter how large the amount of data is and what the type of data is. Therefore, our proposed approach is recommended for the parameters initialization of the EM and VI optimal parameter estimation in GMM.
Footnotes
Acknowledgments
The author would like to thank the editor and the referees for their helpful suggestions and comments that considerably improved this paper. This paper is based upon the work supported by National Natural Science Foundation of Zhejiang Province (LY20F020012, LQ19F020008), National Natural Science Foundation of China (61802094, 61272539, 72002133), Ministry of Education of China Science Foundation (19YJC630174), China Postdoctoral Science Foundation (2018M630461), Natural Science Foundation of Beijing Municipality (4194076).