
Abstract
Indoor air pollution (IAP) has become a serious concern for developing countries around the world. As human beings spend most of their time indoors, pollution exposure causes a significant impact on their health and well-being. Long term exposure to particulate matter (PM) leads to the risk of chronic health issues such as respiratory disease, lung cancer, cardiovascular disease. In India, around 200 million people use fuel for cooking and heating needs; out of which 0.4% use biogas; 0.1% electricity; 1.5% lignite, coal or charcoal; 2.9% kerosene; 8.9% cow dung cake; 28.6% liquified petroleum gas and 49% use firewood. Almost 70% of the Indian population lives in rural areas, and 80% of those households rely on biomass fuels for routine needs. With 1.3 million deaths per year, poor air quality is the second largest killer in India. Forecasting of indoor air quality (IAQ) can guide building occupants to take prompt actions for ventilation and management on useful time. This paper proposes prediction of IAQ using Keras optimizers and compares their prediction performance. The model is trained using real-time data collected from a cafeteria in the Chandigarh city using IoT sensor network. The main contribution of this paper is to provide a comparative study on the implementation of seven Keras Optimizers for IAQ prediction. The results show that SGD optimizer outperforms other optimizers to ensure adequate and reliable predictions with mean square error = 0.19, mean absolute error = 0.34, root mean square error = 0.43, R2 score = 0.999555, mean absolute percentage error = 1.21665%, and accuracy = 98.87%.
Introduction
At an average, human beings, especially the elderly population and new-borns, spend almost 80–90% of their time in the indoor environments and hence are the most susceptible to indoor pollution [1]. Within the past few years, IAQ has become the main cause behind excessive exposure to harmful pollutants [2, 3].
Several studies conducted in the past 150 years show that non-industrial IAQ plays a major role in the decayed quality of public health [4]. Still, there is a lack of scientific interest related to IAQ research, monitoring and policy management in the developed countries. Currently, it is possible to improve IAQ by using the latest technological advancements [4]. Internet of Things (IoT) can be used to monitor IAQ in the building environment. It can be defined as a paradigm where different objects with sensing capabilities are connected to the internet [5, 6]. IoT is an effective approach to design flexible health care systems and also allows the development of real-time health monitoring platforms for efficient decision making [7]. IoT offers relevant requirements for IAQ monitoring using wearable sensors that can upload data to dedicated servers and smartphones for further analysis of measured parameters [8]. The IoT is also used for real-time transmission of collected physical information. Moreover, IoT can be further combined with artificial intelligence, machine learning and deep learning approaches to develop intelligent systems for IAQ management. These methods can help in Big Data analysis while supporting the development of reliable prediction systems for building health and general well-being.
Considering the impact of IAQ for occupational health, government and municipal authorities need to install real-time supervision systems to detect unhealthy situations for enhanced living environments, at least at highly populated public places such as hospitals and schools [9]. Usually, simple building air management steps taken by homeowners and building operators can lead to significant positive impacts on IAQ; preferably, they can avoid smoking indoors and switch to natural ventilation whenever required [10]. However, it is relevant to implement real-time supervision systems to detect unhealthy behaviour and to ensure adequate ventilation with proper use of heating, ventilation, and air conditioning (HVAC) systems.
IAQ monitoring and evaluation systems allow efficient monitoring and decision making to promote occupational health. Distributed as well as the local assessment of chemical concentrations (e.g., pollution monitoring and gas spill detection) is relevant for safety and security applications. It also contributes to enhanced control on HVAC systems for energy efficiency [11, 12]. IoT based IAQ measurement provides a consistent stream of data for informed decision-making and reliable management of building automation systems [13, 14]. Furthermore, the prediction models can help building occupants to take preventive steps for enhanced IAQ, especially for children, elderly and people that are already suffering from serious respiratory health issues [15].
This paper presents an experimental analysis of efficient IoT based IAQ monitoring system. Seven different optimizers are used to design prediction model and their performance is compared. The main contribution of this paper is to provide a comparative study regarding the performance of Keras optimizers for predicting IAQ to design a reliable system for enhanced public health and well-being. The main objective is to reduce the prediction error to take adequate decisions in order to prevent serious building health problems for enhanced occupational health. Also, if the hours of forecasting can be increased, the occupants can follow relevant preventive measures to stay safe ahead of time. The rest of the paper is divided into four different sections, where the first section provides a background of the study stating the relevance of PM on IAQ along with related work done by previous researchers in this domain. The second section describes information about the materials and methods used for the development of the prediction system. The third section provides a comparison between seven different optimizers for the IAQ prediction system, along with results and discussions. And the last section is dedicated to the conclusion of this experimental analysis.
Background
Poor IAQ is rising as a significant challenge that leaves a relevant impact on the poorest and unprotected individuals worldwide [10]. Its association with human well-being is comparable to sexually transmitted diseases and tobacco use [10, 16]. The Environmental Protection Agency (EPA) in the United States takes the responsibility to develop regulations for maintaining indoor and outdoor air quality. Studies published by EPA also reveal that indoor pollutant levels are approximately one hundred times higher than outdoor pollutant levels, leading to some of the most significant environmental problems affecting general well-being [17].
There is a wide range of primary and secondary pollutants that contribute to poor IAQ; however, PM levels are recognized as major contributing parameters for decayed public health [18]. For routine monitoring and regulatory purposes, ambient PM is divided into two different quantities: PM10 and PM2.5. They represent mass concentrations of tiny particles collected by automatic systems as per international sampling standards related to ‘inhalable’ and ‘respirable’ particles. M10–2.5, particles with the aerodynamic diameter >2.5 microns, but≤nominal 10 microns are defined as coarse fraction particles. Particles with diameter <1 micron are represented by PM1.0. Furthermore, “Ultrafine” particles (UFP) are the particles with diameter < 0.1 microns (100 nm) in size [18].
PM is a multifaceted combination of liquefied and solid biological and mineral particles suspended in the air [19, 20]. PM generally includes dirt, dust, smoke, soot, and liquid droplets that can penetrate the lower airways of humans leading to severe harmful health effects. Indoor exposure to PM in developing countries increases the risk of acute lower respiratory infections [21, 22]. Several studies reveal that excessive exposure to PM levels is closely associated with mortality among young children [23, 24]. At the same time, it is a prominent cause of several chronic health problems, including chronic obstructive pulmonary disease, cardiovascular disease, and lung cancer among adults [25, 26].
Approximately 60,000 premature deaths are reported every year in the United States, and they are directly linked to poor air quality levels. The cost of healthcare facilities for treating diseases associated with air quality reach $150 billion [27]. As per a report presented by the European Environment Agency in the year 2016, air pollution caused 400,000 premature deaths within the European Union (EU). PM levels lead to 412,000 premature deaths in 41 different European countries 374,000 were reported in the EU [28]. Moreover, the cost of dealing with the harmful effects of air pollutants emitted from industrial facilities in 2012 was estimated somewhere around 59 to 189 billion euros in the EU [29]. The highly populated cities in India contribute to the highest pollution levels in the world, and the capital city of Delhi is mentioned on the top of the list. As per a study conducted by CNN in the year 2019, 21 out of the world’s 30 most polluted cities were from India [30]. The statistics of the year 2016 reveal that 140 million people out of 1.38 billion population in are affected by air quality, which is ten times worst as compared to the safe limit set by WHO [31]. Poor IAQ is the second major cause behind the increased mortality rate in India [32]. The 2018 Environment Performance Index Results report ranked India 177th among 180 countries based on 24 performance indicators covering ecosystem vitality and environmental health [33]. Moreover, over 1,00,000 deaths are reported in 29 Indian cities due to rising PM2.5 levels [34]. The adverse effects of ultrafine air particles are further linked to lung health and systemic circulation, where toxic components can cause potential tissue damage and inflammation [35]. It is necessary to notice that PM exposure is ubiquitous, and there is no defined and studied “safe” level. Hence, behavioural modification strategies can play a considerable role in enhanced overall health and well-being. The technology inspired PM monitoring and prediction systems can help policymakers to develop solid strategies for maintaining public health. That is why several researchers in the past few years have contributed their ideas in this direction. Numerous experimental studies from recent years are highlighted in Section 1.2.
Related work
Ghaemi et al. [36] proposed a Spatio-temporal system designed using the LaSVM-based online algorithm for dynamic prediction of air pollution in Tehran. The authors used meteorological data on carbon monoxide (CO), nitrogen dioxide (NO2), sulfur dioxide (SO2), ozone (O3), and PM10 from few target locations in Tehran. These pollutant concentrations were further used to calculate Air Quality Index (AQI) and then a prediction system was designed to estimate those values based on past monitoring. This system was able to predict AQI values for the next 24 hours with a root mean square error (MSE) of 0.54, the overall accuracy of 0.71, and a coefficient of determination equal to 0.81.
Another air quality prediction system was proposed by Zheng et al. [37] with the Multiple Kernel Learning approach. The four parameters used in this experimental study were O3, NO2, SO2, PM, fine suspended particulates and respirable suspended particulates. The performance of the proposed system was further compared with the Random Forest (RF), classical autoregressive integrated moving average (ARIMA) model, support vector machine (SVM), long short-term memory (LSTM) and multiple-layer perceptron (MLP) neural network.
Soh et al. [38] designed an adaptive deep learning model for predicting air quality using spatial-temporal relations. This model was developed based on two datasets collected from 76 different locations of 23 cities of Taiwan and Beijing. The prediction system was mainly designed for predicting PM2.5 based on wind direction, wind speed, temperature, humidity, PM2.5, and PM10 features. The system was able to forecast air quality for 48 hours using a combination of different neural networks, including LMST, Convolution Neural Network (CNN), and Artificial Neural Network (ANN) for extracting spatial-temporal relations.
Zhu et al. [39] proposed an air quality forecasting system using machine learning methods that could provide a prediction for around 24 hours. This study focused on three air pollutants: SO2, PM2.5 and O3. The data was collected from two different weather stations located in the two suburban residential areas of Illinois. The authors in this study presented refined models for predicting IAQ by using advanced regularization techniques for performance optimization.
Tiwari et al. [40] also designed an air pollution level prediction system by considering four major pollutant concentrations: O3, CO2, SO2, and NO2. The authors of this study presented a feed-forward ANN-based model for predicting IAQ. The three input parameters applied at the input of ANN were Mean, 1st Hourly Max and 1st Max Value, whereas the output parameter was AQI. Furthermore, the ARIMA model was used to validate the predicted AQI.
In this experimental analysis, we designed an IoT based monitoring system for measuring essential IAQ parameters, and the prediction system was further developed using Keras optimizers. Although there are several libraries and frameworks available for handling time series analysis, the authors decided to work with Keras due to its ability to handle small datasets more efficiently. This open-source library is also preferred for the simplicity of coding environment, core architecture, and ability to run on the top of relevant frameworks such as TensorFlow, Theano, and R. The details about data collection, pre-processing and system development are described in the further sections.
Data collection and pre-processing
Dataset
Chandigarh is a union territory in India and is the capital of two neighbouring states, Punjab and Haryana. The estimated population of the city is 1.06 million with a higher number of vehicles and industrial units that lead to severe air pollution. This experimental analysis is carried out to estimate the state of IAP by measuring pollutant concentrations in the area that is badly affected by poor air quality. The sensor network was installed in the cafeteria of an educational institute (National Institute of Technical Teacher’s Training and Research) in Chandigarh city. The cafeteria stays populated throughout the day with peak traffic between 11:00 am to 11:30 am and 4:00 pm to 4:30 pm. The sensor network was placed close to the cooking area. The data was recorded for 6 months, two readings per hour, from 5th April to 4th September 2019.
As per WHO, the pollution index for Chandigarh city is 51.32. Moreover, air quality and air pollution are moderate, with an estimated value of 54.57 and 45.43, respectively. The PM10 level usually stays around 110, whereas PM2.5 is observed to be 59. However, the PM10 pollution level in the city is reported to be very high around the year. On the other side, the temperature typically varies between 48- and 106-degrees Fahrenheit over the year, and humidity stays within the estimated range of 24% to 97%. But as the vehicle traffic and industrial pollution is increasing with each passing day, the scenario may be more complicated in the coming years [41]. Hence, an early evaluation of air pollution levels and their impact is necessary.
Requirements:
Arduino Uno ESP8266 Module SDS011 PM Sensor DHT11 Sensor Connecting wires
Arduino IDE Python NumPy library Seaborn library Keras optimizer library
Methodology
The design of the prediction system is based on the real-time data collected using IoT sensor networks installed in Chandigarh City. The framework of the methodology is given in Fig. 1.

Framework of the methodology.
The entire process can be categorized into three stages as data collection, data pre-processing and prediction model design. The detailed explanation of the methodology is given below.
For analysing the levels of IAP and to design a prediction system for timely indication of critical instances, an IoT sensor network with PM, temperature, and humidity sensor was developed. Real-time data was collected with the help of the Arduino Uno based sensor network that uses the SDS011 sensor for measuring PM2.5, PM10 and DHT11 for measuring temperature and humidity. Table 1 shows the specifications of the essential hardware used for the cyber-physical system. The data was sent to the ThingSpeak channel for online storage by using the ESP8266 module. The diagram representing a sensor network for measuring pollutant concentrations is shown in Fig. 2.
Specifications of sensors used for designing an IAQ monitoring system
Specifications of sensors used for designing an IAQ monitoring system
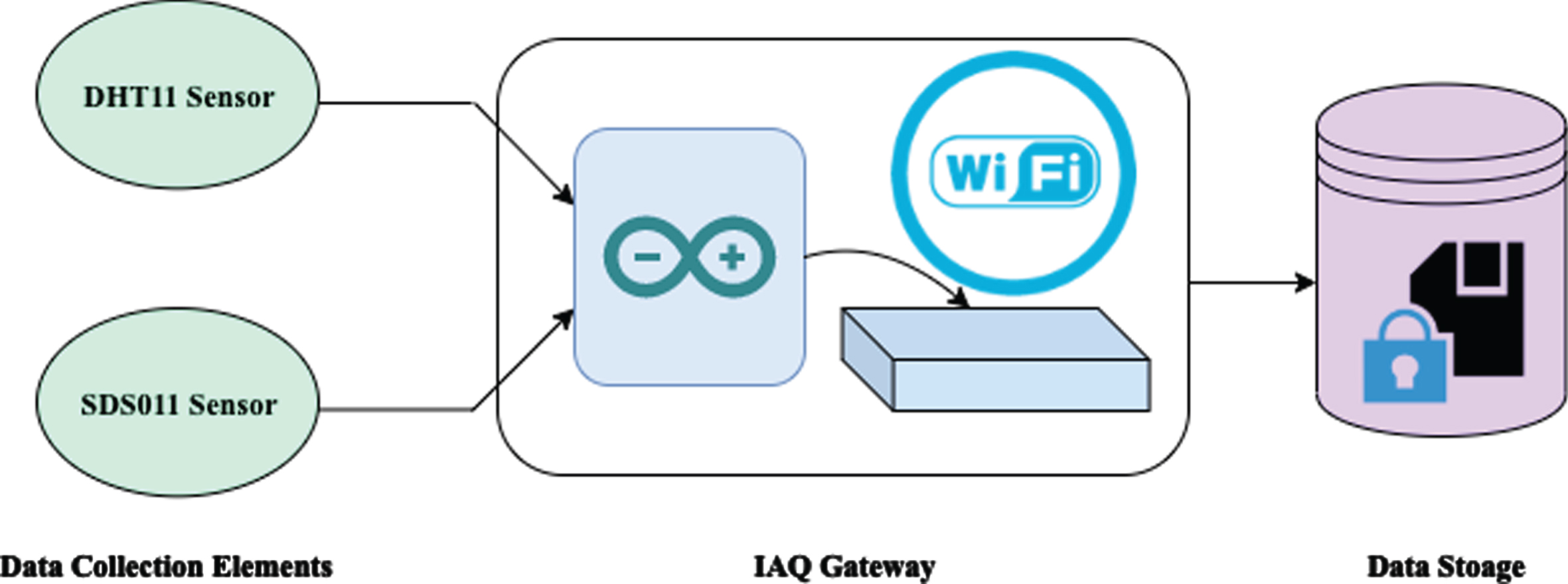
Framework of IoT sensor network for measuring pollutant concentration.
Table 1 shows the specifications of data collection elements used to record real-time measurements from the target monitoring area. However, the accuracy of the sensors installed is a crucial factor to verify the reliability of the monitoring system.
The decision for selection of SDS011 laser sensor over other low-cost sensors was supported by existing studies conducted by early researchers [42–44]. PM NOVA sensor was also pre-calibrated in the factory; however, the reliability test is required to ensure its accuracy for the IAQ monitoring system. The reliability test was conducted after 24 hours of a pre-heating period that is required to ensure accurate readings in a particular environment. The reliability of the sensor was continuously tested against the monitoring air station operated and maintained by the pollution control board in the city. The performance of the sensor was stable and within the accuracy range specified by the manufacturers. In order to maintain the accuracy of readings, careful sensor placement procedures were followed so that the normal flow of air cannot be blocked towards the chamber of the laser dust sensor.
The sensor network recorded data for four parameters PM2.5, PM10, temperature, and humidity. The natural deposition process of PM is greatly affected by relative humidity and temperature. Studies reveal that temperature has a negative correlation with PM10, whereas relative humidity has a positive correlation with PM10 [45].
The pollutant concentrations are further used to determine the AQI. It is basically an indicator of pollution levels as defined by EPA in the United States for public use. The formula specified for AQI calculations is given by Equation 1.
Where I represent AQI, C is pollutant concentration, C low Clow is a concentration breakpoint, which is equal to or less than C. C high Chigh is a concentration breakpoint that is equal to or greater than C. I low Ilow and I high Ihigh are the index breakpoints corresponding to C low Clow and C high Chigh, respectively. By using this equation, the AQI for real-time IAQ data of IoT sensor network located in Chandigarh city is calculated. This data was further pre-processed and trained with the help of optimizers. The details are described in the further sections.
The collected air pollution data and calculated AQI values are paired together to create the desired data format that can be further processed through the prediction model. The hourly mean values of the recorded parameters were processed. However, the recorded data had several missing values and multiple records at some hours during 6 months of monitoring. To deal with the missing values and inappropriate entries in the dataset, the dataset was pre-processed. Masking approach was used to impute the missing values in the dataset, and the rows having NaN values were dropped to clean the data. After data pre-processing, a dataset containing relevant values of parameters was obtained. For visualization of available multidimensional data Kernel Density Estimation (KDE) algorithm is utilized. It helps to plot the shape of distribution by keeping the density of the observations in one axis and height along the other axis. The matrix plot of the pairwise relationship between parameters (AQI, PM10, PM2.5, Temperature and Humidity) of the available training dataset is shown in Fig. 3.

Pairwise relationship between AQI, PM10, PM2.5, Temp and Hum parameters of the available training dataset.
In order to design a prediction system, first of all, it is essential to define input features for the network. For the proposed system, the prediction label was assigned to AQI, and rest four parameters (Temp, Hum, PM10, and PM2.5) were considered as input features. Descriptive statistics of these features were obtained to get more insights into the shape of each attribute. The model generated several statistical values for each attribute in the input training data: mean, std, min, max, 25%, 50% and 75%; where mean represents mean of each input parameter, std represents Bessel-corrected sample standard deviation, min and max show minimum and maximum values in the distribution, respectively. The 25%, 50% and 75% are sample quantile values. In general, quantiles are the points in the distribution with respect to the rank order of the values present in the distribution. In this, 25% shows lower quartile, 75% is the upper quartile and 50% is middle quantile that can be also referred to as median. The list of extracted descriptive statistics for each attribute are shown in Table 2.
Statistical properties of four input parameters under consideration.
Statistical properties of four input parameters under consideration.
After feature extraction, the entire input dataset was converted into a float datatype by scaling all values between 0 and 1; this task is performed by using Equation 2. The scaling is performed because optimize-based prediction model works best when the input values fall in the range of 0 and 1.
Where Norm Data represent normalized dataset, x is the parameter value, mean (x) represent mean of respective parameter value and std (x) represent the standard deviation of the respective parameter value. The dataset was further divided into three parts: 60% for training, 20% for testing and 20% for validation of the model.
In this section, the authors describe the different approaches for IAQ prediction. The selection of the right optimizer and configuration of a set of parameters can help to squeeze even the last bit of accuracy for the prediction model. This experimental analysis is based on seven different optimizers, and their performance is compared based on mean absolute error (MAE), MSE, Root Mean Square Error (RMSE), R2 Score (Co-efficient of determination), Mean Absolute Percentage Error (MAPE) and Accuracy. In the section, the optimizers tested by the authors are succinctly explained.
Gradient descent (GD) is a fundamental technique for training and optimizing intelligent systems. It basically considers the following equation for minimizing loss function and for enhancing system accuracy:
Where ‘η’ represents learning rate, ‘∇J (θ)’ is the gradient of loss function-J(θ) w.r.t parameters- ‘θ.’
Stochastic Gradient Descent (SGD) optimizer is known as the simplest form of GD in terms of its behaviour and concept as well [46]. It starts with a small learning rate and follows the gradient on the cost surface. After each iteration, it generates new weights that are better than the old ones obtained in the previous iterations. It mainly includes support for learning rate decay and momentum. In the training network, a random batch of samples is taken for each iteration and values of θ are updated every time.
The mathematical representation for SGD is shown below:
Where, x(i) and y(i) indicate training examples.
Adagrad or Adaptive Learning Rate optimizer simply follows the learning rate (η) to adapt as per the input parameters [47]. It works by making small updates for the frequent parameters and big updates for the infrequent parameters. Hence, this optimizer is widely recommended for handling sparse data.
In the previous method, we made updates at once for all parameters θ because all θi components were having the same η . But in the case of Adagrad, all parameters θi follow different η at every time step t. For Adagrad, we set
Where ∈ = 10e - 8.
The biggest benefit of Adagrad is that it does not require manual tuning of η. In most cases, the default value is taken as 0.01.
Adadelta is basically an extension of Adagrad; it works for removing the decaying learning rate problem of the previous algorithm. Instead of using all previously squared gradients, Adadelta restricts the window of all accumulated past gradients to a fixed size w [48].
Instead of storing w previous squared gradients, Adadelta defines the sum of gradients in a recursive manner as the decaying mean of the past squared gradients. The final formula for Adadelta is defined below:
Here the denominator just represents the Room Mean Square (RMS) error criterion of the gradient and can be written as RMS [g]
t
; hence, the 5th equation can be rewritten as:
One important thing to note about Adadelta is that one need not put special efforts for setting η.
Room Mean Squared Propagation (RMSprop) algorithm is also a kind of adaptive learning rate method [49]. Both Adadelta and RMSprop were developed independently in the same duration to resolve the radically diminishing learning rate problem of Adagrad. RMSprop is almost identical to the first update vector of Adadelta and can be given as:
Note that RMSprop also divides the model learning rate by the exponentially decaying average of squared gradients.
Adaptive Moment Estimation (Adam) optimizer is recommended for average [50]. This algorithm makes use of adaptive learning rates for each parameter and momentum to ensure fast convergence. While storing the exponentially decaying average of the past squared gradients such as AdaDelta, Adam also keeps track of the exponentially decaying average of the past gradients m(t). The final formula for updating parameter with Adam optimizer is:
Here vt and mt are the uncentered variance and mean of the gradients, respectively.
This optimizer works well in the practical environment with its fast convergence rate and comparatively higher learning speed.
The v t factor of the Adam optimizer update rule leads to the inversely proportional scaling of the gradient with respect to the ℓ2 norm of the past gradients as well as the current gradient |gt|2
Here, the basic equation is represented as:
It was further updated by Kigma and Ba [51], to achieve more stable value. In order to avoid confusion with Adam, the new equation was represented by u
t
that represents infinity norm-constrained v
t
. The new equation can be shown as:
Where β2 represents decay rate whose default value is 0.999. With this improvement in the equation, the final Adamax update rule can be represented as:
It is important to mention that u
t
is dependent on the max operation; it does not go towards zero as v
t
and
Generally, Adam is represented as the combination of momentum and RMSprop; on the other side, the Nadam optimizer or Nesterov-Accelerated Adaptive Moment Estimation is the combination of Adam and Nesterov Accelerated Gradient (NAG) [52]. Hence, the final update rule for Nadam can be represented by adding the Nesterov Momentum term to the Adam equation. The new rule can be shown as:
Where β1 is the decay rate with a default value of 0.9.
All these optimizer algorithms present small parametric variations over one another that add the difference to their overall performance in designing prediction system for IAQ.
Following the concept of seven different optimizers discussed in section 2.4, the IAQ prediction model was designed. The main idea was to compare the performance of all these optimizers based on relevant regression metrics so that the most efficient optimizer can be identified to design a real-time, intelligent IAQ monitoring and prediction system. Figure 4 shows the stages of the IAQ prediction model designed for this comparative study. The data obtained from the hardware module is fed to the prediction algorithm. However, instead of putting raw data as it is, the pre-processing stage is added to the system. The first most step at this stage was to clean the dataset by following the masking approach discussed in section 2.3.2. After that, the response label was applied to the AQI parameter and the rest parameters (PM10, PM2.5, Temp and Hum) were considered as input features to train the prediction model. It is crucial to mention at this stage that statistical feature extraction was used to describe the dataset. None of the input parameters were discarded at this stage since several studies report that PM concentrations are greatly affected by temperature and humidity levels [35, 53]. Hence, all four input parameters were used for training to ensure that their overall impact is utilized for designing efficient prediction model. After feature selection and label assignment, the data were normalized by following the technique mentioned in section 2.3.3. The normalized data was then used to train model containing seven different optimizers and then their performance was compared using six different regression metrics, including MSE, MAE, RMSE, R2 score, MAPE and Accuracy. Based on these metrics, the best model was selected for designing an intelligent IAQ prediction system that can be used for real-time analysis in the future. The results obtained after training the prediction model with the seven optimizers are discussed in the next section.

Stages of IAQ prediction model for comparing performance of seven optimizers.
This section describes the results obtained with each optimizer and their performance comparisons. After obtaining a normalized dataset, the sequential model for prediction system was initialized with 64 nodes in the hidden layer. Rectified Linear Unit (ReLU) was applied as an activation function for all seven optimizers. The major rationale for using ReLU is that it allows gradient to be non-zero and ensure automatic recovery during the training process. It involves simple and fast mathematical computations as compared to Sigmoid and Tanh activation functions; hence, is believed to be computationally less expensive.
The training set was applied to all seven optimizers separately, and model performance was evaluated in terms of MSE, MAE, RMSE, R2 Score, MAPE and Accuracy. At the initial level, 1000 epochs were set for all seven optimizers and then early stopping condition was applied with a common patience parameter value of 10. Early stopping condition allows the training to stop when chosen performance measures stop making further improvements. It helps to avoid unnecessary computations for the optimization model and describe how fast it can converge for the best performance.
For all optimizers, the learning rate was adjusted to reduce the error and, ultimately, to obtain the best possible prediction for AQI with that particular optimizer. The prediction performance of optimizers was finally compared on the basis of important regression metrices. A comparison of the obtained parameter values is shown in Table 3.
Comparison table showing performance of prediction models with seven different optimizers
Comparison table showing performance of prediction models with seven different optimizers
From the comparison table, it is clearly visible that the best performance for AQI prediction was presented by the SGD optimizer with MSE = 0.19 AQI and MAE = 0.34 AQI, RMSE = 0.43, R2 Score = 0.99955, and MAPE = 1.12665. Furthermore, the accuracy of model trained with SGD optimizer was highest (98.87%) as compared to model trained with other six optimizers. The above performance was obtained with the low learning rate of 0.001, and it was recorded at a very early stage during the 50th epoch. Very close performance was shown by Adagrad with MSE = 0.20, MAE = 0.35, RMSE = 0.45 and Adamax with MSE = 0.21, MAE = 0.34, RMSE = 0.45 respectively. However, in terms of the overall accuracy, Adamax performed comparatively better with the accuracy value of 98.83%; however, it was restricted to 98.67% in case of Adagrad. Adagrad was able to achieve this performance with the learning rate of 0.02; whereas Adamax managed to achieve this performance with the learning rate the same as SGD, i.e., 0.001. However, the epoch for both these optimizers was comparatively high with count 140 for Adagrad and 100 for Adamax. Adadelta also performed well to reduce error but it took 600 epochs to achieve this performance and that too with a higher learning rate value of 0.03. Nevertheless, in terms of the accuracy measure, it stood third with 98.82%. Although RMSprop and Adam converged faster but the error reduction as well as the overall accuracy was poor as compared to SGD.
The graphical plot for MSE and MAE of SGD is shown in Fig. 5, and graphical representation of these performance metrics for other 6 optimizer models are shown in Fig. 6. and 7. One can observe minute variation in the graphs but even a slight improvement in accuracy is valuable for the AQI prediction model as it can prevent severe health issues in the building environment.

Graphical plot of SGD performance metrics a) MAE and b) MSE.

Comparative graphical representation of MSE for six models.
Comparison in terms of RMSE, R2 Score, MAPE and Accuracy are shown in Fig. 8. RMSE is the most widely used metrics for evaluation of regression models; its value is desired to be low as prediction models with larger errors are not reliable. As sesen from Table 3 and Fig. 8, SGD shows the least RMSE value as compared to other models. R2 Score is generally defined as the ratio between the MSE of the model and MSE of the baseline where MSE (model): Mean Squared Error of the predictions against the actual values MSE (baseline): Mean Squared Error of mean prediction against the actual values. The value usually varies between -∞ to 1. Higher the value (close to 1), better the model. In the given model, the highest R2 Score is reported for the SGD model with 0.999555. MAPE is another commonly used measure to determine forecasting accuracy due to its advantage of interpretability and scale-independency. As it is a measure of error, the ideal value is desired to be at the lower side of the scale. For the given comparative study, SGD presents the minimum value of MAPE (1.126650) as compared to other optimizers. The accuracy measure is generally evaluated for classification problems. However, to compare the performance of different optimizers for designing a reliable prediction system, the forecasting accuracy of different optimizers was also determined using MAPE. The best results were presented by SGD with highest accuracy (98.87%).

Comparative graphical representation of MAE for six models.

Model performance comparison in terms of RMSE, R2 Score, MAPE and Accuracy.
Generally, SGD follows frequent updates, and the parameters have a high variance. It leads to more fluctuation of the loss function to the different intensities. As a result, this algorithm works better to discover new; and moreover, better local minima, i.e. the smallest value of the function on the entire domain of the function. That is why SGD has shown better convergence with the least error for the AQI prediction. The error curve of SGD based prediction model is shown in Fig. 9. and it shows the Gaussian distribution.

Error histogram of AQI prediction for SGD model.
Consequently, SGD is the best solution for designing an IAQ prediction system; the graph showing prediction accuracy with respect to the true values is shown in Fig. 10. It shows that prediction values are closely aligned to the true values. Therefore, the SGD optimizer can ensure reliable prediction results using real-time IAQ monitoring data.

Predictions for AQI with respect to the true values of AQI.
Furthermore, the performance of the SGD based prediction model is compared with the existing literature. The comparison on the basis of a few essential parameters is performed in Table 4.
Comparison of the SGD-based prediction model with existing literature
From the analysis of Table 4, it is clear that the SGD optimizer-based prediction model demonstrates prediction for 96 hours; whereas the range was limited to 24 hours [36, 39], 48 hours [38] and 12 hours [37] for the existing methods. At the same time, the MSE, MAE, RMSE, R2 Score, MAPE and Accuracy value of the SGD based model for AQI prediction is far better than the existing systems.
In this paper, a comparative analysis for AQI prediction using optimizers was given. We evaluated these models with the help of real-time data collected from the IoT sensor network. The acquisition module was installed at a cafeteria of college campus in Chandigarh city for assessment of IAQ. The system was designed for two main IAQ parameters: PM10 and PM2.5; however, it is also applicable to other pollutants as well. The temperature and humidity parameters were also considered to assess thermal comfort along with IAQ. The sensors used for this model were calibrated using standard procedures and reliability tests were conducted so that higher accuracy can be ensured for training. The experimental design and comparative study show that the SGD optimizer can provide highly accurate predictions as compared to Adam, Adagrad, Adadelta, Nadam, RMSProp and Adamax optimizer. The SGD optimizer-based model have MSE and MAE of 0.19 and 0.34 respectively for a prediction of 96 hours. Furthermore, other evaluation metrics are also presented favorable results for SGD based model with RMSE = 0.43, R2 score = 0.999555, MAPE = 1.12665 and Accuracy = 98.87%. Based on the experiments, the following conclusions can be obtained: (1) The SGD optimizer-based prediction model offers better prediction ability as compared to other optimizers. (2) This system is capable of forecasting severe air pollution in a more efficient manner as compared to existing methods. (3) Feature extraction and learning rate adjustment perform a significant role in improved AQI forecasting.
The main limitations of this study are related to the experimental analysis, which is restricted to only two IAQ parameters (PM10 and PM2.5) and two thermal comfort parameters (temperature and humidity). Moreover, this study is limited to comparative analysis only; it is possible to add more value by designing an automated system with a standalone app that could predict real-time results for IAQ. As future work, we are planning to work on a higher number of pollutants by considering their relative impact on the health of building occupants. Furthermore, the quality of the model can be improved by using long-duration monitoring as it can provide more stable and adequate results for prediction. The authors want to use different machine learning methods to find the best model for enhanced system performance so that the system architecture can be improved. The proposed air quality prediction system will be automated to provide an open-source application programming interface (API) that can be easily used by everyone. This API should allow agile and easy manipulation of the prediction system with real-time data collected by third-party air quality monitoring systems. In order to assess the state of IAP, it is first important to know the parameters that affect IAQ and the level of exposure to the building occupants. This model provides insights into the monitoring and control mechanisms as it allows people to apply preventive measures ahead of time by observing predictions. Therefore, pollution studies, prevention policies and management techniques are greatly dependent on prediction system models.