
Abstract
Concept factorization (CF) is an effective matrix factorization model which has been widely used in many applications. In CF, the linear combination of data points serves as the dictionary based on which CF can be performed in both the original feature space as well as the reproducible kernel Hilbert space (RKHS). The conventional CF treats each dimension of the feature vector equally during the data reconstruction process, which might violate the common sense that different features have different discriminative abilities and therefore contribute differently in pattern recognition. In this paper, we introduce an auto-weighting variable into the conventional CF objective function to adaptively learn the corresponding contributions of different features and propose a new model termed Auto-Weighted Concept Factorization (AWCF). In AWCF, on one hand, the feature importance can be quantitatively measured by the auto-weighting variable in which the features with better discriminative abilities are assigned larger weights; on the other hand, we can obtain more efficient data representation to depict its semantic information. The detailed optimization procedure to AWCF objective function is derived whose complexity and convergence are also analyzed. Experiments are conducted on both synthetic and representative benchmark data sets and the clustering results demonstrate the effectiveness of AWCF in comparison with some related models.
Introduction
Matrix factorization represents a group of models to decompose a target matrix into some factor matrices among which non-negative matrix factorization (NMF) is one of the most famous models. Mathematically, NMF aims to approximate a data matrix by the product of two non-negative matrices; one is called the dictionary matrix and the other is the representation coefficient matrix [1]. In the past decades, a lot of efforts have been made on NMF; therefore, many improved model variants and new applications were developed such as the GNMF [2], NLCF [3], GDNMF [4], SILR-NMF [5], PFNMF [6] and FNMFG [7]. There are some review papers from which we can find the recent advances on NMF [8, 9].
As a popular low-rank feature extraction model, NMF can only transform the data into its coefficient representation linearly, which cannot characterize the possible nonlinear structure of data. To get rid of this limitation, Xu and Gong proposed the concept factorization (CF) model in which the dictionary matrix is set as the linear combination of samples [10]. Due to such improvement, CF can be performed in the RKHS and accordingly acquires the ability of nonlinear modeling. Since the CF model was proposed, researchers have been working on improving its performance or applying it into new applications. Below we give a short review to its recent advances. The models such as the locally consistent concept factorization [11], dual-graph regularized concept factorization [12] and graph regularized multilayer concept factorization [13], were proposed to enforce the regularity of learned coefficient representation matrix in CF to coincide with the data manifold. Inspired by the local coordinate coding, the connections between the dictionary matrix (i.e., the linear combination of samples) and coefficient matrix were extensively explored by some models such as the local coordinate concept factorization [14], its graph regularized version [15] and adaptive weighting version [16]. By jointly optimizing the graph matrix to make full use of the data correlation between multiple views, Zhan et al. proposed a CF-based multiview clustering method for data integration [17]. Liu et al. proposed a semi-supervised matrix factorization method (termed constrained CF, CCF) model to constrain the extracted the data concepts to be consistent with the given label [18]. To further improve the performance of CCF, Zhang et al. proposed a robust semi-supervised adaptive concept factorization (RS2ACF) framework [19]. On one hand, it is simultaneously stable to small entry-wise noise and robust to sparse errors; on the other hand, it can propagate the available label information to unlabeled data by learning an explicit label indicator. Sometimes, the pairwise constraints can be treated as semi-supervised information as well and used to build semi-supervised CFs [20, 21]. Under the CF framework, Peng et al. proposed a joint structured graph learning and clustering model [22].
Though CF obtained increasing popularity in diverse fields, most of its existing variants directly commit to reconstructing the original data. This neglects a common case that the real-world data may have only a few meaningful features but many redundant or even corrupted features. Therefore, it is not reasonable to treat the importance of all features equally. In other words, if some dimensions of the feature vector were noisy, it is meaningless to reconstruct them accurately. Accordingly, feature weighting has been a hotspot in many fields such as machine learning and data mining. For example, Peng et al. improved the data gravitation model by using the discrimination and redundancy to measure the importance of features [23]. In [24], Phan et al. proposed to combine the genetic algorithm and support vector machine for feature weighting and parameter optimization in classification task. To achieve the purpose of feature selection, a cluster-dependent feature-weighting mechanism was introduced to reflect the within-cluster degree of relevance of a given feature [25]. Besides these shallow ones, deep leaning models were also competent in feature weighting tasks. A contextual reweighting network (CRN) was proposed to complete the image geo-localization task, which can predict the importance of each region in the feature map [26]. In order to identify the critical frequency bands and channels in EEG-based emotion recognition, Zheng et al. employed the deep belief network to learn the weights of all feature dimensions [27]. In [28], Nguyen et al. introduced a new convolutional neural network equipped with feature weighting and boosting abilities for few-short foreground object segmentation in images. Generally, the existing measures of feature weighting as [23, 25] are of limited adaptability while the deep learning models are of insufficient interpretability.
In this paper, we propose to improve the performance of CF model from the perspective of investigating the contributions of each feature dimension in discriminative data representation learning. Specifically, when treating CF as a data reconstruction model, it is more appropriate to assign a small value to measure its importance if one feature dimension is contaminated or less important in differentiating samples from different classes. Then, this feature will play a smaller role in determining the cluster assignments of data points. Inspired by [29, 30], we introduce a feature auto-weighting variable into the CF objective function with the purpose of adaptively learning the importance of each dimension of the feature vector. In the newly formulated Auto-Weighted Concept Factorization (AWCF) model, the feature auto-weighting variable is jointly optimized with the original two variables (i.e., the linear coefficient matrix in constructing the dictionary matrix, and the data representation coefficient matrix) in CF, which explicitly provides us the insight to the feature importance map.
The main contributions of this paper can be summarized as follows. We propose an improved CF model to learn data representation by explicitly considering and adaptively learning the different contributions of different feature dimensions. Specifically, this is achieved by incorporating a feature auto-weighting variable into the CF objective function, which satisfies the non-negativity and normalization constraints. We design an efficient algorithm to optimize the objective function of AWCF under the alternating direction optimization framework. The newly introduced feature auto-weighting variable is jointly optimized with the original two CF variables. Moreover, the complexity and convergence of the optimization algorithm are provided. We conduct extensive experiments on both synthetic and representative real-world data sets to evaluate the effectiveness of AWCF. The experimental results demonstrate that the learned data representation is more efficient in clustering by introducing the feature weighting technique. Besides, the feature map can be obtained.
The remainder of the paper is organized as follows. In section 2, we first provide a brief introduction to NMF and CF and then formulate the AWCF model objective and derive its optimization. Experiments are conducted to evaluate the performance of AWCF in data clustering in section 3. Section 4 concludes the whole paper.
Auto-weighted concept factorization
In this section, we first revisit the NMF and CF models which serve as the building blocks to our new development. Then, we propose the model formulation, optimization of the AWCF model whose convergence and complexity are also given.
Review of NMF and CF
Given the data matrix
A major limitation of NMF is that it can only be performed in the original feature space. If data distribution is extremely nonlinear, NMF may not be sufficient to reconstruct the data directly as
When performing data reconstruction, the CF model neglects taking the importance of features into consideration. In other words, CF treats the importance of each dimension of the data feature vector equally. As shown by the left hand side of Figure 1, we use 1’s to denote such importance measurement. In a compact matrix form, the conventional CF essentially uses an identity matrix
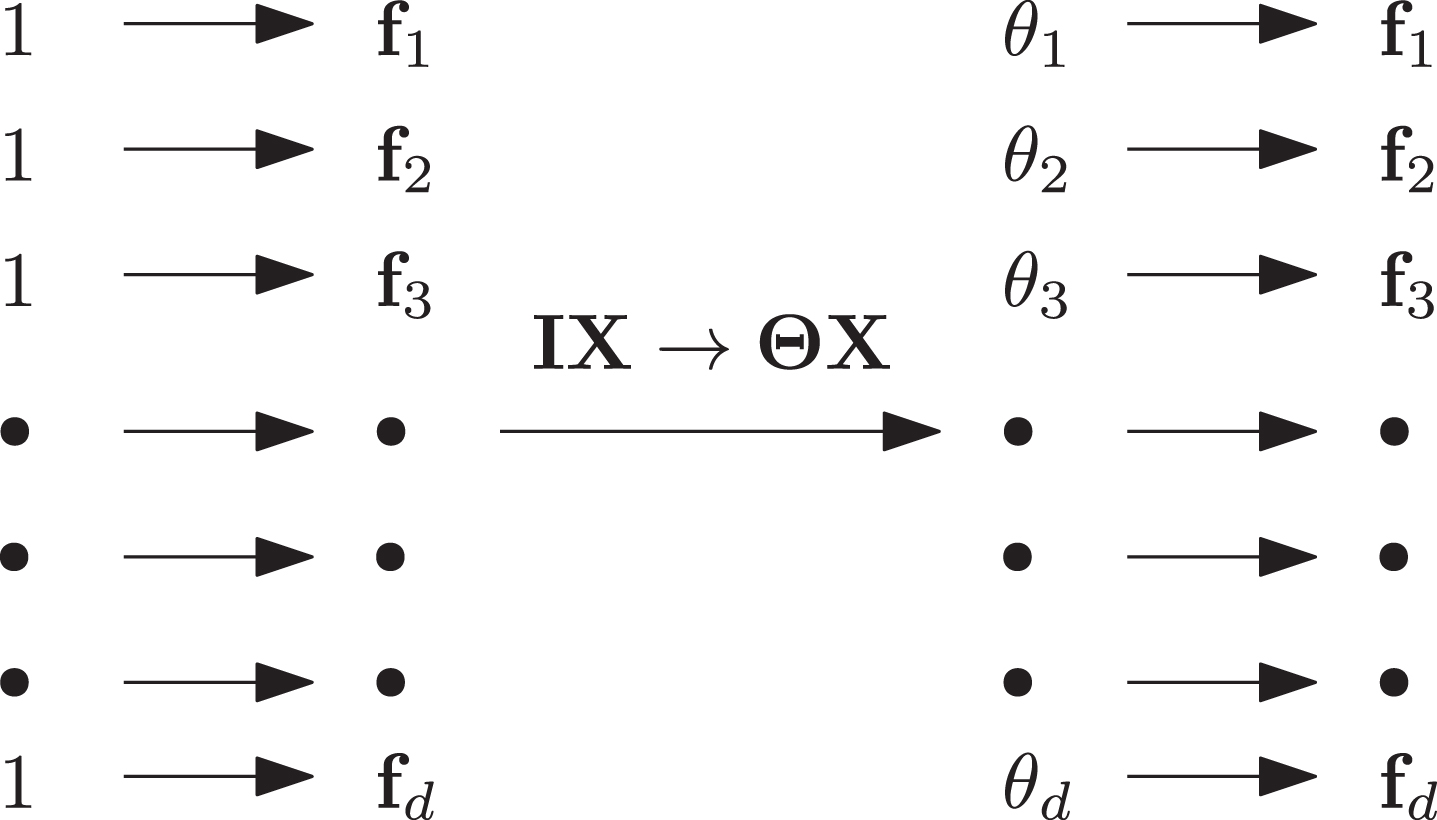
Graphical show of the feature importance in both CF (left) and AWCF (right).
Let {
Since there are three variables (
■ Update
■ Update
Based on the above analysis, we summarize the complete optimization procedure to AWCF objective in Algorithm 1.
1:
2:
3: Update variable
4: Update variable
5: Update variable
6: Normalize
7:
According to the transformation from optimization problems (5WV) to (5similiarCF), we know that the general form of AWCF is same as CF model during the iterations of updating
From Algorithm 1, we can observe the difference in optimization between AWCF and CF is the calculation of
Experiments
In this section, we first conduct experiments on a synthetic data set to show the rationality of the learned weights by AWCF and then evaluate the effectiveness of the feature auto-weighting strategy in AWCF by comparing it with other models on clustering some benchmark data sets.
Experiments on synthetic data
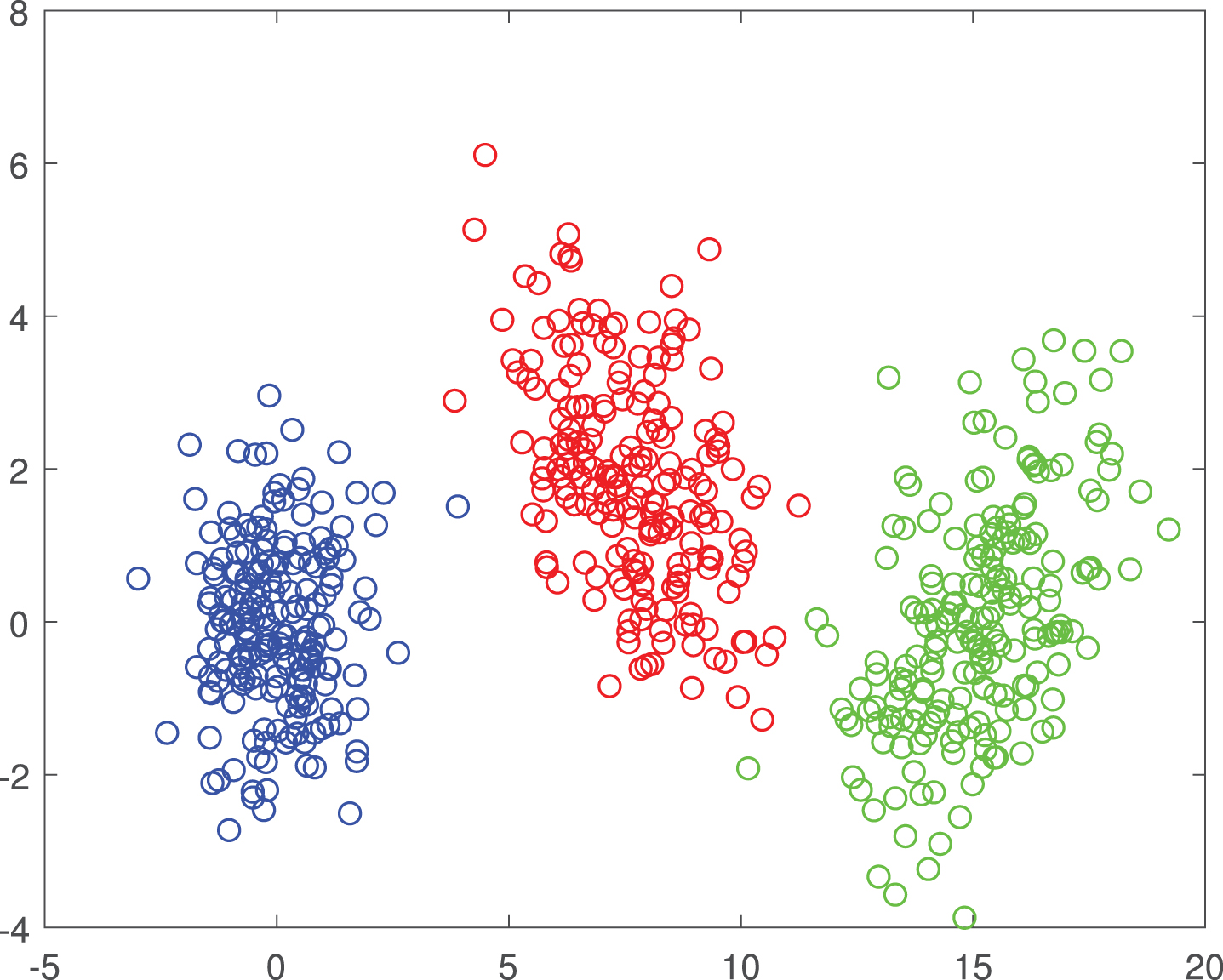
The synthetic data set with three Gaussian distributed clusters.
From the perspective of feature selection, if we only use the first dimension of data, the clustering performance is definitely better than that with only the second dimension. Therefore, we project these data points to x-axis and y-axis and the results are respectively shown in Figures 4 and 5. From Figure 4, we can observe that it is much easier to differentiate these data points with such x-axis one-dimensional representation. However, the projected data points on the y-axis in Figure 5 have large overlapping areas and therefore it is hard to make differentiation. Such result demonstrates that AWCF can learn a meaningful feature map.

The learned weight
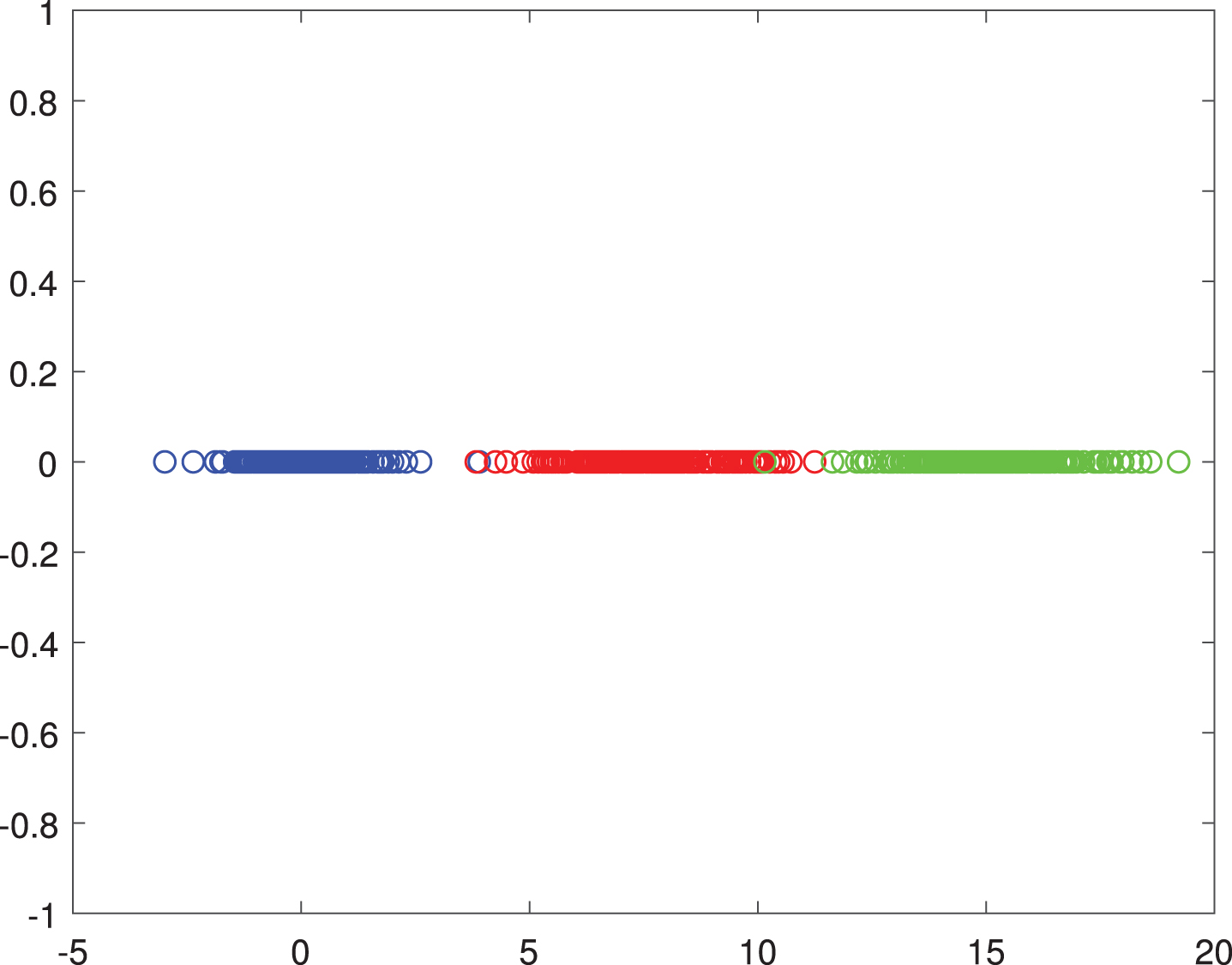
The projected data onto x-axis.
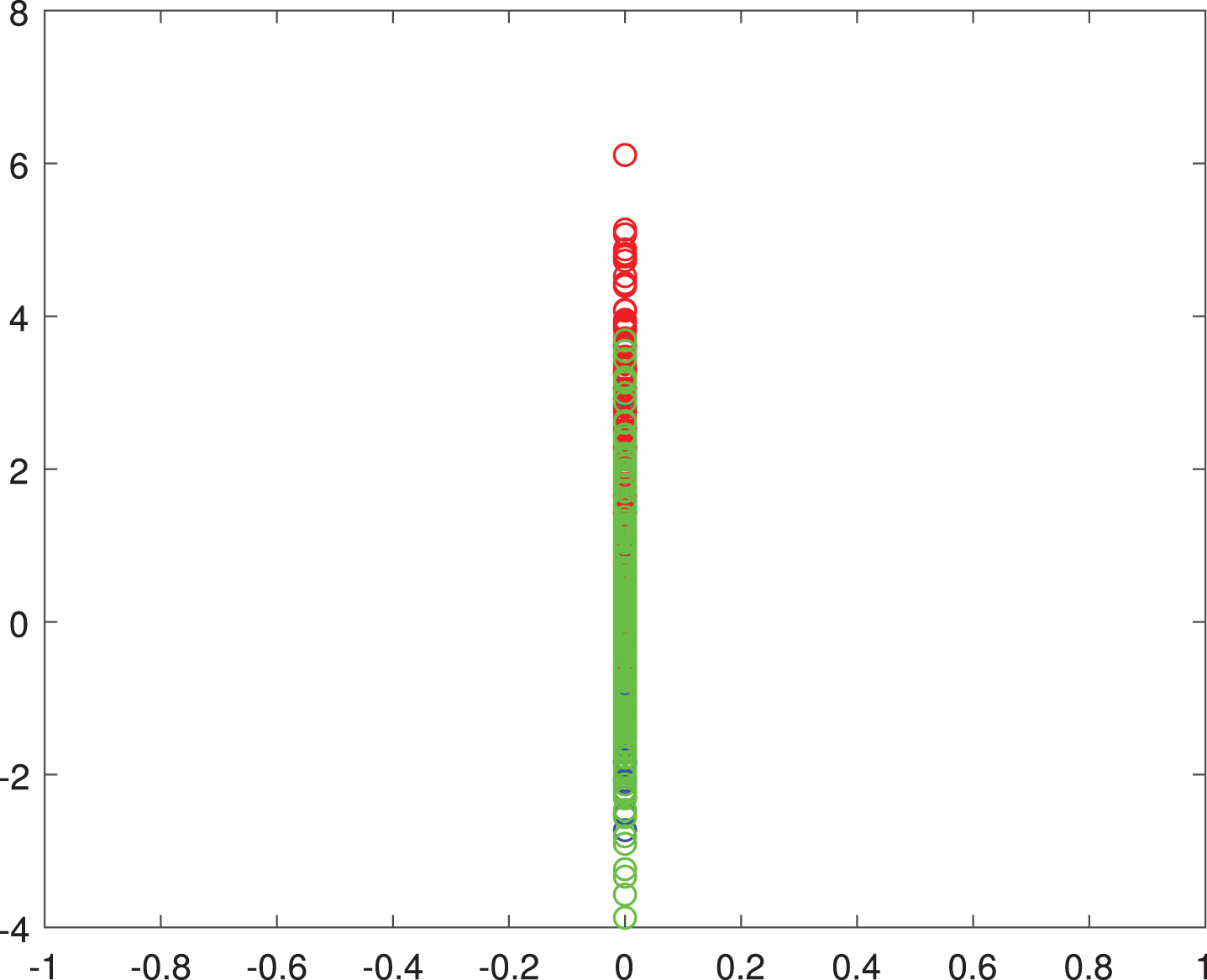
The projected data onto y-axis.
Description of the data sets for data clustering
Description of the data sets for data clustering
Three well accepted clustering measurements are adopted as metrics, i.e., Accuracy (ACC), Normalized Mutual Information (NMI) and Purity to evaluate the clustering performance. The exact definitions to them can be found in [32].
Clustering Performance (%) of compared algorithms on Yale
Clustering Performance (%) of compared algorithms on ORL
Clustering Performance (%) of compared algorithms on ISOLET
Clustering Performance (%) of compared algorithms on PalmData25
Since the main innovation of our proposed AWCF model is the introduction of the feature auto-weighting variable in CF, below we mainly provide the pairwise comparison between the clustering results respectively obtained by them. Specifically, as shown in Table 2, AWCF obtains 5.4%, 7.6% and 5.2% improvements in comparison with CF respectively in the three metrics of accuracy, NMI and purity on the Yale data set. NCut takes the second place, which has overall 1% weaker performance to AWCF. According to the performance in this figure, we can roughly categorize these five clustering models into two groups. One includes the Kmeans, NMF and CF and the other includes the NCut and AWCF. There exist significant performance differences between these two groups. Similarly, based on the results in Figure 3, we can find the improvements achieved by AWCF with respect to CF are respectively 3.4%, 2.8%, 3.0% in the three metrics on the ORL data set. On the ISOLET data set, AWCF consistently outperforms its counterpart CF model and the improvements in terms of the three metrics, accuracy, NMI and purity, are respectively 4.2%, 2.5% and 3.9%. When the number of clusters k varies from 15 to 60 on the PlamData25 data set, AWCF has obvious superiority when compared with the other models. Though AWCF did not always get the best clustering performance when given lager ks, its average performance is also in the first place.
To illustrate the statistical significance between AWCF and the other models, we performed the paired students t-test on their clustering results. Here the hypothesis is the clustering performance (accuracy, normalized mutual information, and purity) obtained by AWCF is better than that obtained by the other (given) method. Each t-test was run on two sequences corresponding to the clustering results of the 20 tests by our method and the given method. From Tables 2 to 5, the statistical test results were reported by the binary values in brackets. For each entity in brackets, "1" means that the hypothesis is correct (true) with probability 0.95, and "0" means that the hypothesis is wrong (false) with probability 0.95. For example, when the clustering number is 14 on the Yale data set, we can find that the average performance of AWCF over the 20 tests is 44.9±4.8 while the average performance of CF over the 20 test is 39.9±3.8. The appended (1) means that the hypothesis "AWCF is superior to CF" holds based on the statistical test. Similarly, the true hypothesis that AWCF is superior to Kmeans, NMF and CF can be obtained when the number of clusters ranges from 6 to 12. In some cases, though the true hypothesis that AWCF is superior to NCut cannot be achieved, AWCF always obtained better average performance than NCut. Similar statistical test results can be found on the remaining data sets.
Based on the above analysis to the experimental results, we can conclude that it is beneficial for learning more efficient data representation by incorporating the feature auto-weighting strategy into the data reconstruction in concept factorization. In the proposed AWCF model, different discriminative abilities of different features can be well explored and exploited by the auto-weighting variable. As a result, the clustering performance is enhanced.

The visualization of feature maps on Yale (k = 15) and ORL (k = 40) data sets.
Figure 7 shows the elements of the learned
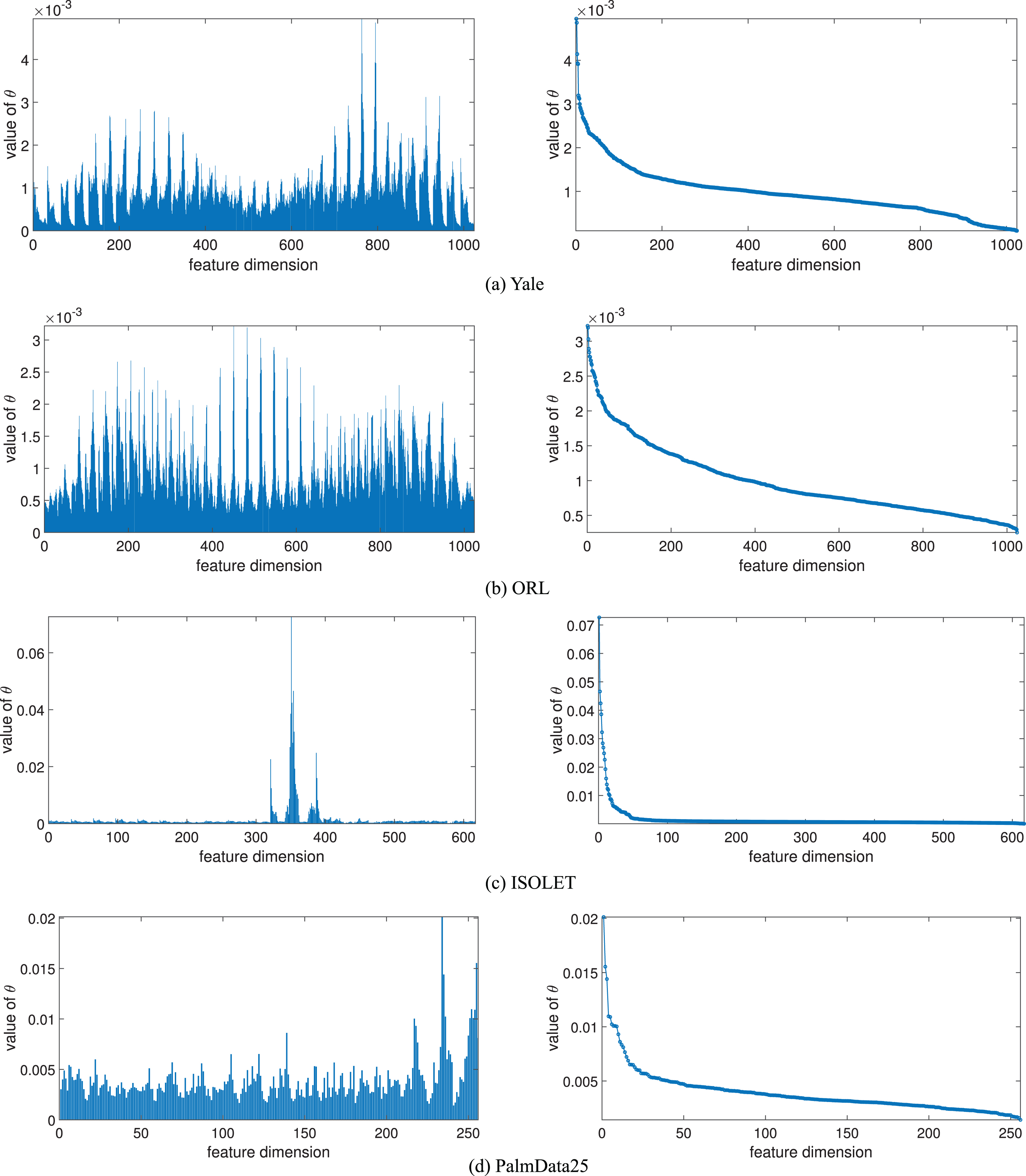
The value of

Convergence curves of CF and AWCF on four benchmark data sets.
In this paper, we proposed an improved concept factorization model which can simultaneously complete the data representation and feature map learning, termed Auto-Weighted Concept Factorization (AWCF). The learned weights could intuitively and quantitatively provide us with the importance of different features. Experiments on representative data sets demonstrated that effectively identifying the different discriminative abilities of different features can improve the model clustering performance. In current work, we only consider incorporating the feature auto-weighting variable into the conventional concept factorization. As our future work, we will consider more advanced CF variants based on which we expect to achieve more promising clustering performance.
Footnotes
Acknowledgment
This work was supported by Natural Science Foundation of China (61971173, U1909202, U20B2074, 61972121), Zhejiang Provincial Natural Science Foundation of China (LY21F030005), National Social Science Foundation of China (19ZDA348), Fundamental Research Funds for the Provincial Universities of Zhejiang (GK209907299001-008), China Postdoctoral Science Foundation (2017M620470), Acoustics Science and Technology Laboratory of Harbin Engineering University (SSKF2018001), Key Laboratory of Advanced Perception and Intelligent Control of High-end Equipment of Ministry of Education, Anhui Polytechnic University (GDSC202015), Jiangsu Provincial Key Laboratory for Computer Information Processing Technology, Soochow University (KJS1841) and Zhejiang Xinmiao Talents Program (2019R407030).