
Abstract
A webshell is a common tool for network intrusion. It has the characteristics of considerable threat and good concealment. An attacker obtains the management authority of web services through the webshell to penetrate and control web applications smoothly. Because webshell and common web page features are almost identical, it can evade detection by traditional firewalls and anti-virus software. Moreover, with the application of various anti-detection feature hiding techniques to the webshell, it is difficult to detect new patterns in time based on the traditional signature matching method. Webshell detection has been proposed based on deep learning. First, a dataset is opcoded, and the source code and opcode code features are fused. Second, the processed dataset is reduced using the SRNN and an attention mechanism, and the capsule network improves complete predictions for unknown pages. Experiments prove that the algorithm has higher detection efficiency and accuracy than traditional webshell detection methods, and it can also detect new types of webshell with a certain probability.
Introduction
With the vigorous development of the Internet industry, the concept of Internet + has been widely spread and practised in today’s globalization of the digital economy. This pioneering work extends the scope of the Internet to all aspects of our lives and in all walks of life. However, the increasingly serious hidden dangers of network security, especially in recent years, and the various network attack incidents have increased explosively. According to the statistics of “China’s Internet Network Security Situation in 2018” released by the National Internet Emergency Response Centre in April 2019. There were 478 research reports on high-level cybersecurity threats issued by cybersecurity professional institutions worldwide, which is an increase of approximately 3.6 times over the same year, of which 80 research reports were from 12 cybersecurity research institutions in China. Looking at the more than 400 research reports, it is not difficult to determine that cyberattacks were mainly concentrated in 53 confirmed APT attack organizations, such as APT28, Lazarus, Group 123, Sea Lotus, and Muddy Water. Reports also noted that the Middle East, Asia Pacific, America and Europe have become hot areas because of cyberattacks, and the vast majority of attacks are generally related to geopolitics, military agencies, financial institutions, diplomatic services and other government departments. Energy agencies are currently the main target of attacks. Additionally, APT attacks are gradually spreading to national service industries, such as health care, education, and transportation. Harpoon email attacks, waterhole attacks, network traffic hijacking or man-in-the-middle attacks are the mainstream attack methods of APT attack organizations. To prevent similarity with previous attack methods, these attacks mainly use open-source or public attack frameworks and tools combined with multiple technologies to perpetrate attacks. Webshell, a backdoor file that can read, write and steal information from a database, is an important part of APT attacks. In 2018, CNCERT monitoring found that approximately 24,000 domestic websites in China maliciously and silently had backdoor programs installed by approximately 16,000 IP addresses worldwide, of which webshells were widely installed and the most destructive. In the grim situation of network security, facing such security threats, many researchers working on network security are stressed. The command environment of webshell is similar to a webpage file, so it has the same static attribute characteristics and dynamic attribute characteristics as an ordinary webpage file. According to these two characteristics, there are two detection methods: static detection and dynamic detection. Static detection analyses malicious string or function characteristics, file attribute characteristics, statistical characteristics, etc. In this method, malicious strings or functions are collected to build feature libraries, which are matched with files to find high-risk web files. The technical problems faced by static and dynamic detection can be summarized in three aspects as follows: The constant changes in application plug-ins, technical frameworks and coding styles have led to major changes in web page attributes and internal logic[1, 2]. For example, sensitive data that are not suitable to be seen by visitors or other unrelated people need to be encrypted or encapsulated, resulting in the coincidence index and longest string presenting similar characteristics to the webshell. Network attacks and defences are actually a confrontation between forward and reverse. For attackers, after understanding the detection characteristics of webshell, they can camouflage it. Currently, machine learning algorithms are gradually becoming mature, and webshell detection has also begun to use machine learning algorithms [3–5]. However, different types of webshells adopt different detection features. Due to the lack of research on this particularity, the algorithms are difficult to learn, and the detection effect is not ideal.
In summary, webshell attacks have strong concealment, and a single static feature or dynamic feature can no longer meet the requirements [6]. To strengthen the detection effect and improve the accuracy, the following measures can be taken:
Increase the number of features, improve the characterization ability, reduce the influence of redundant features, improve the detection efficiency, and avoid overfitting.
NeoPI [7] is a popular webshell backdoor detection tool based on statistical features. It adopts the coincidence index, information entropy, longest character string, compression ratio and features to find hidden malicious code. Dynamic detection behaviour is divided into two categories: one is the behaviour of the webpage to execute system commands, operation database and access to the file system; the other is the behaviour of users visiting the webpage, including visit time, visit frequency, jump source, and dwell time. Due to the special function of a webshell, an exception is raised both in its own behaviour and the user’s access behaviour to it, thus providing the possibility to discover a webshell from behaviour patterns [7]. Wu et al. [8] proposed a hybrid webpage malicious code detection method based on machine learning. This method first crawls the webpage code file using a webpage crawler, then trains the collected feature set using a classification algorithm, and constructs a classifier based on the webpage code. Then, the constructed classifier is used to classify the extracted features of the web code. Finally, the webpage classified as malicious code is sent to the honeypot of a highly interactive client to detect whether the webpage is malicious. This method needs to collect samples in advance and finally needs dynamic behaviour detection. It is not convenient in use, and manual intervention is needed in the middle [8]. To detect web trojans, Nguyen [9] and others proposed a method of using statistical theory to analyse code features. The accuracy of the method detection depends entirely on the features extracted from the web page code to ensure, and the web page code is in the form of text. Hackers often transform and encrypt malicious code. It is quite difficult to extract the feature code from the web page code; additionally, the efficiency of detection is limited by the capacity of the feature library [9]. Yang et al. [10] proposed a scheme for detecting malicious sites by classifying URLs. This scheme uses a static method to find host-based features of the URLs of malicious sites. However, the limitations of this scheme are also obvious. Once some well-known sites are identified, this method cannot be used to detect them [10]. Huan, Zhang et al. [11] adopted webshell dynamic monitoring and detection methods, which were deployed and tested in the school system. To avoid causing damage and loss to the analysis system, our article uses static data. Because of webshell data malicious code, static detection can be executed without dynamic code, which will not cause damage to the analysis system and is relatively safe, and the method in this article cannot be restricted by the specific webshell execution process. Fangjian Tao et al. [12] used machine learning algorithms to automatically extract webshell features. We use SRNN, attention and capsule networks to mine the deep information of webshell features and increase the weight of key features so that the entire network can address these key features that contribute to improved classification performance. In terms of accuracy, our method is as high as 99.67%, and the experiment proves that it is superior to this algorithm.
To solve the above problems, it is very important to choose a suitable classification algorithm. Therefore, to solve the problems of incomplete feature coverage and low detection accuracy of web shell detection, SACapsNet, a deep learning method, is proposed in this paper, and a comparison experiment is designed to verify the effectiveness of this method. The experimental results show that this method can improve the performance and accuracy of webshell detection.
The innovation of this article is as follows: Joint research at the source code compilation level and source code level can effectively avoid the impact of webshell escape methods such as code commenting and code obfuscation. To further improve the detection accuracy, this paper introduces a slice recurrent neural network to improve operation efficiency. Additionally, compared with traditional feature extraction methods, attention has a stronger ability for feature correlation analysis. A capsule network is used for classification, and good experimental results are obtained on the results of data processing.
Compared with traditional methods, the webshell detection method based on deep learning focuses more on the source code level [13]. This article innovatively conducts joint research at the source code compilation level and source code level, which can effectively avoid the influence of webshell escape methods such as code annotation methods and code obfuscation methods [14]. In addition, in terms of the sample feature selection, traditional methods are mostly based on the character feature codes; therefore, they can only cover a single code statement, and the method in this article not only uses bytecode sequences as sample characteristics but also uses the source code as supplementary sample characteristics, which effectively uses the context information of the code and greatly improves the accuracy of model detection. To further improve the detection accuracy, this paper will introduce the slice cycle neural network to improve the operation efficiency. Additionally, compared with the traditional classification algorithm, the attention mechanism has a stronger feature correlation analysis ability, and the CapsNet can effectively detect the unknown samples that are difficult to process by the traditional method. According to statistics, among the known webshells, the majority of webshells are written in the PHP language. Therefore, this paper mainly studies a detection method for PHP-type webshells. This section will first analyse the PHP code compilation and execution process and design PHP code compilation results— the bytecode extraction method. Then, it describes how to use feature engineering to extract byte code sequences and source code together as sample features. Finally, it presents how to use the SACapsNet algorithm to train the webshell detection model.
We evaluate the models of this paper on a testbed, as shown in Fig. 1. We can see that the whole detection process is divided into three stages:
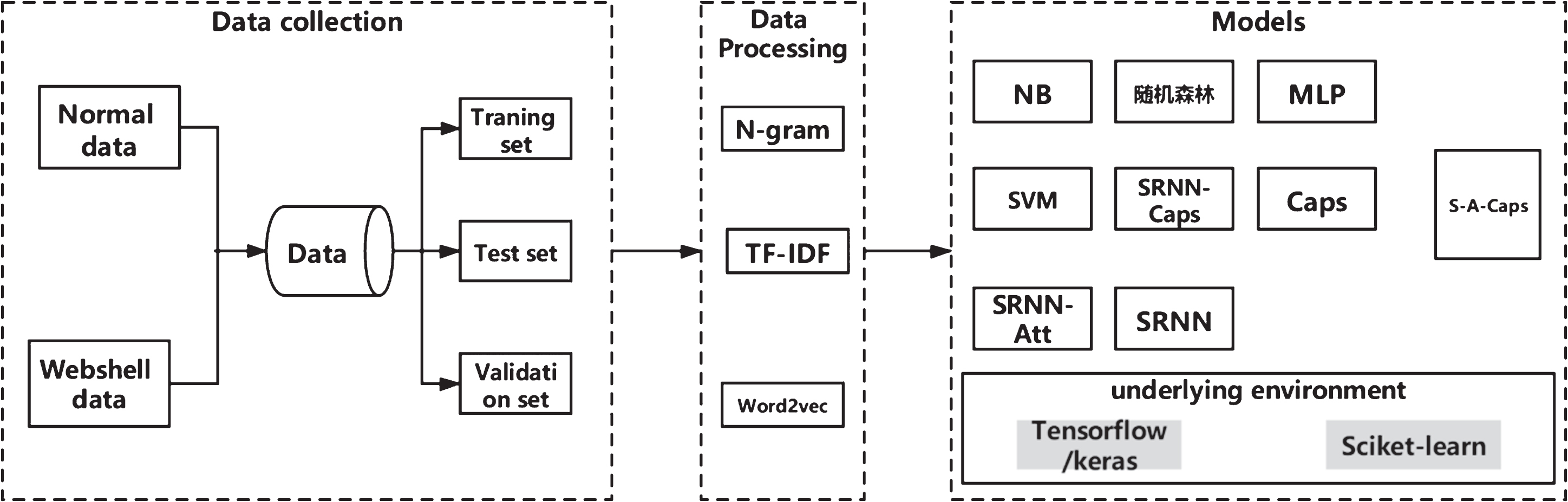
Webshell detection testbed.
The main job of data preprocessing is to extract opcode. Opcode is an intermediate language after PHP script compilation, such as bytecode for Java or MSL for NET. It includes operators, operands, instruction formats and specifications, and data structures that hold instructions and related information. PHP script execution includes four stages: lexical analysis, syntax parsing, opcode compilation, and opcode execution. In the third stage, the compiler binds opcode with corresponding parameters or function calls. Even if webshell dangerous functions are confounded and encrypted, opcode statements that are different from normal file compilation results will still appear at compile time. Therefore, according to this feature, opcode can be used to distinguish webshells from normal files, and the detection of files can be converted into the detection of opcode sequences. In this paper, the PHP plug-in VLD is used to compile and obtain the opcode of the PHP file [15].
Feature extraction
TF-IDF, n-gram & opcode
In this paper, before taking opcode samples as training sets for model training, opcode features should be processed and extracted to determine as many of the features of normal samples and webshell samples as possible. We split the opcode sample set using a similar method of bigram to obtain information about the byte code context. First, divide two adjacent opcodes into a phrase, count the number of times that phrase appears in the training set and use that number to represent the opcode example. Finally, after the phrase segmentation is completed, each opcode sample is represented as a word frequency vector. However, if only the bigram model is used for the segmentation of byte code, the training set contains a large number of opcode phrases, so the dimension of the word frequency vector matrix representing opcode samples will be very high, which will create considerable computational pressure to the subsequent model training. Therefore, we must perform feature filtering on the opcode phrase and filter the features that contribute little to the classification in the sample [16].
First, the statistical word frequency method was used to eliminate the characteristics with weak classification ability; that is, the frequency of each opcode phrase in the whole sample set was first counted, then the phrases with word frequency less than 30% were removed from the sample set, and the remaining opcode phrase was used to constitute the phrase dictionary. According to the characteristics of each sample, the word frequency matrix of the sample set is constructed. After obtaining the opcode vector matrix, we used the TF-IDF (term frequency-inverse document frequency) algorithm to analyse the word frequency of the matrix to obtain the features with high classification value in the sample set. The main idea of TF-IDF is that if a certain word or phrase has a high term frequency (TF) in a sample and a low frequency in other samples, it is considered that the word or phrase has good classification ability and is suitable for classification. Among them, TF refers to the number of occurrences of a word or phrase in a sample, and IDF (inverse document frequency) is the measure of the “weight” of the word or phrase.
Among them, N represents the total number of texts in the corpus, while N(X) represents the total number of texts containing words x in the corpus.
If a word appears infrequently in multiple samples but frequently in a particular sample, the greater the inverse document frequency IDF value of the word. If the word or phrase is common in all samples, IDF is very low. The frequency value of a word or phrase is multiplied by the value of the inverse document frequency to obtain the TF-IDF value [17].
The larger the value, the more important the word is in the sample, and the more it can represent the sample. Using the TF-IDF algorithm to process the word frequency matrix of the sample set, an opcode characteristic matrix that can reflect the importance of each sample will be obtained. Each column vector in the matrix corresponds to a bytecode feature, and each row corresponds to a PHP sample.
Word2vec was created by a team of researchers led by Google’s Tomas Mikolov. Subsequently, other researchers analysed and explained the algorithm. Compared with earlier algorithms, such as latent semantic analysis, the embedding vector created by the word2vec algorithm has many advantages. This algorithm will consider the context, and compared with the previous embedding method, the effect is better. After word embedding, each word can be represented as a fixed-length vector; thus, the feature dimension can be greatly reduced. So it is faster, and it is more passable [18].
To convert the data into the data format required by the neural network, the PHP source code is considered a different sequence of text made up of words. All strings (words) in each sample are encoded into numbers by word2vec technology. The process can be expressed as follows:
where W i represents the i-th word in the string sequence and Emb (W i ) represents the operation of encoding words into numbers. In particular, we set the maximum number of features per instance to L, and all sequences are filled or truncated to the same length. Each sample is represented by a k-dimensional feature [19].
After the above operations, each sample can be represented by a semantic feature matrix v2 ∈ Rm2, where m2 represents the number of features. In our work, we randomly initialize the embedding matrix and learn together with the rest of the model.
After extracting features through TF-IDF and word2vec, we can obtain two feature matrices stored, namely, TF-IDF embedding matrix V1 and semantic feature matrix V2. The two feature matrices are directly combined by the “[]” stitching operation so that TF-IDF features and semantic features interact closely. Finally, the fusion feature matrix is obtained. The matrix can be expressed as follows:
Each of these rows is a vector representation. Therefore, each sample can be represented by a fusion feature matrix m ∈ Rm1+m2, where m1 represents the TF-IDF feature dimension and m2 represents the semantic feature dimension.
Based on the feature fusion in the previous section, this paper inputs features into the SACapsNet model for training. The SACapsNet model effectively combines SRNN, an attention mechanism and a capsule network, so that the model can identify webshells more efficiently and accurately. This model is mainly divided into three parts. First, SRNN divides the fusion feature sequence into many subsequences. Second, the attention mechanism establishes a relationship between features, selects important features and eliminates features with less contribution. Finally, we use the capsule network algorithm to learn the features and recognize webshells.
SRNN
In many NLP missions, the recurrent neural network (RNN) has been a great success. However, the structure of this loop makes them difficult to parallelize, so training the RNN requires considerable time. Zeping Yu and Gongshen Liu of Shanghai Jiao Tong University [20], in their paper “Sliced Recurrent Neural Networks”, proposed a new architecture called “Sliced Recurrent Neural Networks” (SRNN). SRNN can realize parallelization by splitting the sequence into multiple subsequences. SRNN can obtain advanced information through multiple layers, and no additional parameters are required. The researchers demonstrated that the standard RNN is a special case of SRNN when linear activation functions are used. Without changing the loop unit, SRNN is 136 times faster than the standard RNN and may be faster when training longer sequences. Experiments on six large emotion analysis datasets show that the performance of SRNN is better than that of standard RNNError! Reference source not found..
Sliced recurrent neural network (SRNN). Based on the recurrent neural network (RNN), multiple subsequences of equal length are constructed by dividing the input sequence into several minimum values. The recurrent unit can process each subsequence simultaneously on each layer, and the information can also be transmitted through multiple layers.
The length of the input sequence X is T, and the input sequence is:
Similarly, we divide each subsequence N again into n subsequences of equal length and then repeat the slice operation k times until we have an appropriate minimum sequence length at the bottom layer (we call it 0-layer, as shown in Fig. 2). The k + 1 layer was obtained by slicing k times. The maximum small sequence length of 0-layer is:
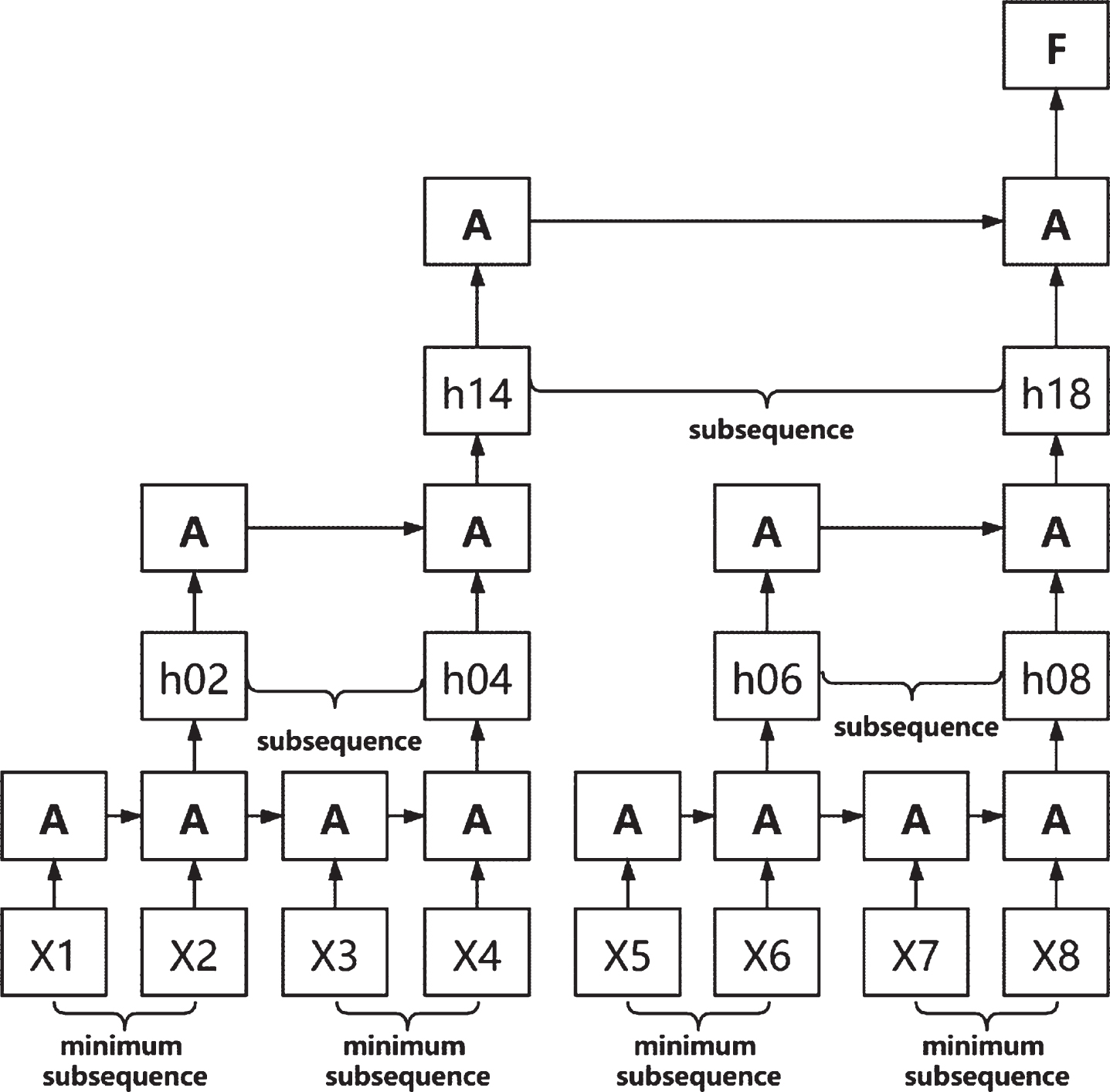
Sliced recurrent neural network.
The minimum number of subsequences at layer 0 is:
Since each parent sequence on the p layer (p > 0) is divided into n parts, the number of subsequences on the p-th layer is:
The subsequence length of the p layer is:
Consider Fig. 2 for example. The sequence length T is 8, the number of slice operations k is 2, and the slice number of each p layer is 2. After slicing the sequence twice, the 4 smallest subsequences are obtained at layer 0, and the length of each smallest subsequence is 2. If the length of the sequence or the length of its subsequences cannot be divided by n, we can use the fill method or select a different slice number on each layer. Different k and n can be used for different tasks and datasets.
The difference between SRNN and the standard RNN is that SRNN divides the input sequence into a number of smallest sequences and makes use of recurrent units on each subsequence. Thus, subsequences can be easily parallelized. In the first layer, the loop unit works on each smallest subsequence through a connection structure. Next, we obtain the last hidden states of each of the smallest sequences at layer 0, which are used as inputs to their parent sequences at layer 1. Then, we use the last hidden state of each subsequence on the (p-1) layer as the input of its parent sequence on the p layer and calculate the last hidden state of the subsequence on the p-th layer:
Among them,
In this model, we use BiLSTM (Bi-directional Long Short-Term Memory) instead of GRU for training.
The visual attention mechanism is a special brain signal processing mechanism of human vision. Human vision can quickly scan a global image to obtain the target area that needs to be focused on and then devote more attention resources to this area to obtain more detailed information of the target and suppress other useless information. This is a method allowing humans to use limited attention resources to quickly screen out high-value information from a large amount of information. It is a survival mechanism formed in the long-term evolution of humans, and the human visual attention mechanism greatly improves the efficiency and accuracy of visual information processing. In essence, the attentional mechanism in deep learning is similar to the selective visual attentional mechanism of human beings. The current attention mechanism has been widely used in image classification, object detection, pedestrian recognition and other computer vision fields [21].
In the attentional mechanism, each word of the objective function has to learn the probability information of word assignment in its corresponding source statement, which means that every time a word y i is generated, the same original intermediate semantics representation C will be replaced by C i , which changes constantly according to the currently generated word, as shown in Fig. 3. The process of generating the objective function becomes the following form:

Attention Mechanism.
Each C
i
corresponds to the probability information assigned by different sentences:
Among them, L x represents the length of the input sentence source, a ij represents the attention distribution probability of the j word in the source input statement when the i word is output by the target, and h j represents the semantic encoding of the j word in the source input statement.
We can imagine the constituent elements of the source in the attention mechanism as being composed of a series of <key, value > data pairs. Given the element query in a target, by calculating the correlation between the query and each key value, the weight of the value corresponding to each key can be obtained, and then the value is weighted and summed to obtain the final attention value. The idea is rewritten as the following formula:
The core of the attention mechanism is to select the information that is more critical to the target from the mass information and to extract irrelevant information so that the overfitting problem can be reduced more likely. Note that the activation function selected by the module is sigmoid, which can select key features while reducing irrelevant features and smooth the mismatch between the training set and the test set.
The important difference between the capsule network and the standard neural network is that the activation of the capsule is based on the comparison of multiple input attitude predictions. However, in a standard neural network, it is based on the comparison between a single input activity vector and a learned weight vector. One method for solving the problem of partial and global relationships is to find a tight clustering of high-dimensional votes; this method is called a routing protocol. Different from the input and output form of the CNN and the pooling operation of the CNN, the input and output of the capsule layer are all in vector form, and a dynamic routing algorithm is adopted to calculate these vectors. Each layer of the capsule network has several nodes, and each node represents a capsule. During the process of connecting the lower-level capsules to the higher-level capsules, the connection weight will change during learning, which will cause a change in the node connection degree, so it is called dynamic routing. In general, dynamic routing algorithms are used to train the network between two capsules [22].
The capsule network is similar to the fully connected neural network, but it has an additional coupling coefficient c for linear summation. Input S of the capsule network:
C is the coupling coefficient. It can be determined from the above formula that to obtain C, b must be obtained first. b can be calculated by the following formula:
The initial value of b is 0, so in the previous process of seeking S, W is set to a random value, b is initialized to 0 to obtain c, and u is the output of the upper layer capsule network, so S of the next layer can be obtained.
Unlike fully connected neural networks, we use the new activation function squashing in the capsule network, and the formula for the output v is:
The first part of the activation function is the scale of the input vector S, and the last part is the unit vector of S. Therefore, the squashing activation function not only retains the direction of the input vector but also compresses the modulus of the input vector between [0, 1].
The first layer of the CapsNet is the input layer, which is similar to the text classification of the LSTM framework [23] and CNN framework. The input data are the text data that have been preprocessed with text representation and feature extraction. The second layer is the Conv1 layer, which is a standard convolutional layer that converts word vectors in the input data into local feature outputs. Conv1 removes the pooling layer, retains the convolution layer that extracts features, and enhanced the nonlinear activation function. The third layer is the primary caps layer. This layer is still a convolutional layer, but different from an ordinary convolutional layer, in this layer, the objects participating in the convolutional operation change from single neurons to larger nerve capsules. At the primary caps layer, every eight features form a vector of length 8, which is encapsulated in a primary capsule to collectively reflect the features of a certain category and describe the probability of the existence of which category. The last layer, DigitCaps, is a fully connected layer, and the pooling operation is replaced by dynamic routing. The purpose of dynamic routing is to find the best weight value by continuously iterating the dynamic routing algorithm and finally obtain the classification of text. When the neural capsule performs dynamic routing, the minimum unit of data is a vector. Their training process can be divided into two stages: linear combination and dynamic routing. Since the object of linear combination is now changed from a neuron to a nerve capsule, the connection weight of the capsule also has the original scalar value and becomes the current vector, which is expressed as a matrix
Data sources and experimental platform
Datasets
Webshell malicious samples are mainly downloaded through public projects on GitHub. Since this article is only for the offensive detection of PHP files, there are a total of 566 malicious samples. The normal PHP samples are mainly from common PHP frameworks, including PHPCMS, WordPress, ordering, letter calls, and yii2. There are 5,376 samples in total.
A one-word trojan has a single function but is easy to deploy and not easy to discover.
Big trojans have many sentences, perfect functions and strong destructive power, but they are easy to detect by the system.
The confusing trojan sentence is between the big trojan and the one-word trojan and is not easy to detect by the system.
Ransomware trojans, which are more destructive, are often used to attack individuals.
The IndoXploit trojan is more concealed and causes greater harm to the system. This article selects a variety of types of webshell trojans, which enriches the diversity of data and thus simulates real attacks.
Experimental platform
The platform used in the experiments in this section was an Intel(R) Xeon(R) CPU e5-2650v4@2.20 GHz, 16 CPUs ×2.2 GHz, 64 GB of memory, 128 GB of mechanical hard disk memory, and the Ubuntu Linux (64-bit) operating system. The development language used to implement the algorithm was PYTHON, and the development tool was Anaconda3.
Evaluation criteria
Accuracy:
Precision: The number of samples that the model determines to be positive are truly positive samples; the predicted number of positive samples / the number of samples that are predicted to be positive (note: accuracy and accuracy are different); that is:
Recall: The number of positive samples that are determined as positive samples by the model. The proportion of the number of correctly classified positive samples to the number of positive samples is
Analysis: Accuracy and recall are a pair of contradictory measures. If the precision is high, only the samples that are most likely to be positive are selected; if many positive samples are missed, the recall rate will be low. If the recall rate is high, it can be achieved by increasing the number of selected samples. If all samples are selected, the recall rate is the highest. At this time, the precision rate is low.
Application: In the recommendation system, to less disrupt the user, the precision is higher; in the fugitive information retrieval system, it is more desirable to miss as few fugitives as possible, so the recall rate is higher.
F1-score: Before the introduction of the F1-score, first, the harmonic mean is introduced. The harmonic mean is also called the reciprocal mean, which is the reciprocal of the arithmetic mean of the reciprocal of each statistical variable in the population.
The general form of the F1 measure: F
β
can express different preferences for recall and precision rates:
When β>1, the recall rate is more significant. When β = 1, it is reduced to standard F1; when β <1, the precision is more important.
The general form of the F1 value is the harmonic mean of precision and recall.
Feature validity verification
As discussed earlier, the fusion features extracted in this article contain both TF-IDF features and semantic features (see section 2.2 for details). The appropriate fusion feature dimension has an important influence on the performance of the model. Table 3 shows the influence of fusion feature dimensions on the experimental results. It can be seen from Table 3 that with the increase in the feature dimension, the accuracy rate presents a trend of improvement. Finally, this paper adopts 352-dimensional fusion features, including 172-dimensional TF-IDF features and 172-dimensional semantic features.
Datasets
Datasets
PHP Webshell example
Feature Dimension Evaluation index
As discussed above, the proposed multimodel fusion network consists of a set of submodels, including the slice recurrent neural network, an attention mechanism and a capsule network. Different submodels have different functions and provide different performance gains for the entire network. To verify the necessity of these submodels and their impact on the overall network performance, we designed a set of baseline models to reflect the importance of the different submodels, as shown in Table 4. The description of the baseline model is as follows:
Model component performance table
Model component performance table
CapsNet: this model only uses a capsule network to extract features.
SRNN: This model uses only sliced recurrent neural networks to extract features. S + A: The model first uses slice recurrent neural networks to extract data timing information and remote dependency information. Second, the attention mechanism extracts the key features of context information extracted from the upper layer and calculates the weights. S + C: This model builds a deeper network using a capsule network based on a sliced recurrent neural network, which improves the utilization of semantic distributed information. A + C: This model combines attention mechanisms and capsule networks to learn deep semantic features.
As shown in Table 4, single models such as CapsNet and SRNN show good performance. CapsNet can extract deep semantic features; however, compared to SRNN, CapsNet performed slightly poorer than IRANet due to its inability to extract contextual information. In addition, since CapsNet and SRNN take the form of a single model and do not combine the advantages of other models, their overall performance was lower than that of other integration models.
In all the integration models, S + A performed best. This shows that the model has a strong generalization ability. This may be due to the ability of SRNN to extract contextual and remote dependency information, and the attention mechanism can refine context information. Compared with S + A, S + C lacks an attention mechanism, which causes the model to learn too much noise. Furthermore, A + C first makes use of the attention mechanism to increase the weight of key features so that the whole network can focus on the key features that help improve classification performance. Furthermore, the capsule network further learns the deep semantic information of key features. Therefore, the overall performance of A + C also performs well.
Model comparison
Capsule num comparison
Although the single model and the integrated model mentioned above have achieved good results, they still cannot be compared with the SACapsNet model proposed in this paper. Experimental results show that the proposed SACapsNet has superior performance, which proves that the adoption of the three-seed model in SACapsNet is important for revealing the malicious behaviour pattern and verifies the effectiveness of the fusion feature proposed in this paper in detecting webshells.
In the existing literature, researchers have proposed a variety of neural network-based classifiers for webshell detection tasks. To evaluate the performance of the proposed architecture in detecting webshells, this paper compares the proposed SACapsNets with a variety of advanced detection models used in previous literature, including four neural net-based classifiers (CNN, LSTM, BiLSTM, and CNN+LSTM)[24, 25]. Table 4 reports the results of comparing SACapsNet presented in this paper with these baseline models.
The experimental results show that the four methods based on neural networks have achieved good results [26]. These results prove that the neural network learning method has a strong generalization ability for webshell detection tasks. In addition, these neural network-based approaches can model complex functions and avoid the need to manually write and update detection rules, which is essential for webshell detection tasks. CNN+LSTM achieved the best performance with an accuracy rate of 99.59%. However, this still cannot be compared with the results of SACapsNet proposed in this paper. This is because the multimodel fusion network proposed in this paper integrates the advantages of multiple models. First, the independent recurrent neural network can fully extract semantic distribution information by using sequence context information and remote dependency information. Second, an attention mechanism is used to realize the integration of information flow and avoid the loss of semantic information in the process of transmission. Finally, capsule networks enhance the propagation of features when processing high-dimensional feature vectors. Therefore, SACapsNet proposed in this paper integrates the advantages of multiple models and can hierarchically express deeper webshell semantic information, resulting in better performance.
Model Parameter comparison
During the experiment, it was found that the number of capsules played an important role in the model. As seen from the table, with the increase in the number of capsules, the overfitting phenomenon occurred. An excessive number of capsules leads to the model learning too much noise and the overfitting state.
Not only does the number of capsules plays an important role in the model but the dimension of the capsule also affects the model. As seen in Fig. 4, the evaluation index of the model was relatively stable when the dimension was 8, and the model was not sufficient for learning key information when the dimension was less than 8. When it was greater than 8, overfitting also occurred.
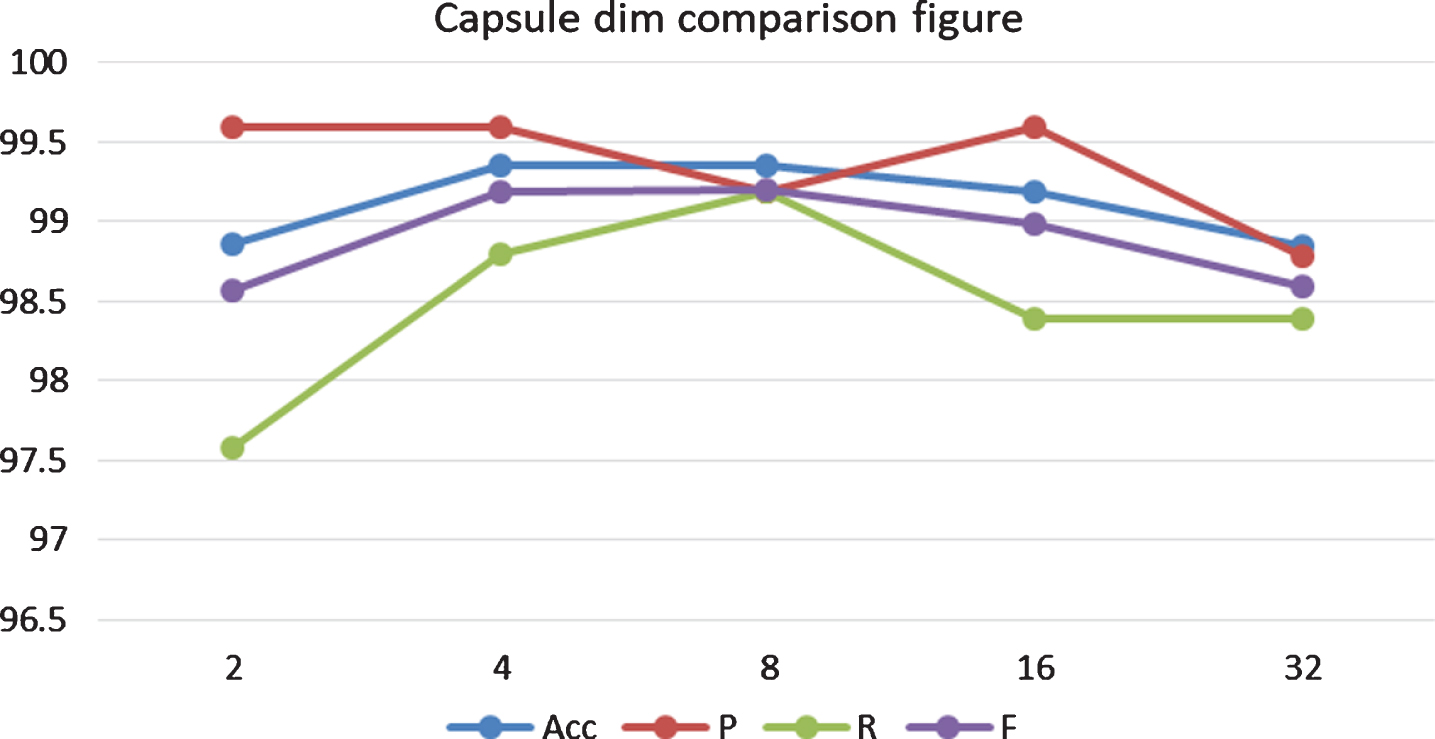
Capsule dim comparison.
This paper proposes a deep learning-based detection method that divides the main components of the sample PHP program code and opcode and uses an attention mechanism to extract important features. The experimental results show that static deep learning compared with mainstream deep learning, such as CNN, BiLSTM, CNN+LSTM, and the detection method achieved certain improvements in accuracy, false negative rate, and F1 score. The focus of future research should be to improve the time complexity of the model and make webshell detection faster. This model can be applied to the detection of other malicious codes.