
Abstract
In view of the characteristics with big data, high feature dimension, and dynamic for a large-scale intuitionistic fuzzy information systems, this paper integrates intuitionistic fuzzy rough sets and generalized dynamic sampling theory, proposes a generalized attribute reduction algorithm based on similarity relation of intuitionistic fuzzy rough sets and dynamic reduction. It uses dynamic reduction sampling theory to divide a big data set into small data sets and relative positive domain cardinality instead of dependency degree as decision-making condition, and obtains reduction attributes of big intuitionistic fuzzy decision information systems, and achieves the goal of extracting key features and fault diagnosis. The innovation of this paper is that it integrates generalized dynamic reduction and intuitionistic fuzzy rough set, and solves the problem of big data set which cannot be solved by intuitionistic fuzzy rough set. Taking an actual data as an example, the scientificity, rationality and effectiveness of the algorithm are verified from the aspects of stability, diagnostic accuracy, optimization ability and time complexity. Compared with similar algorithms, the advantages of the proposed algorithm for big data processing are confirmed.
Keywords
Introduction
Large-scale fuzzy information system has the characteristics of large data size, high feature dimension and heterogeneity, and so on. Traditional feature selection algorithms are inefficient or even impossible for attribute reduction of such information systems. Rough set is an effective way to deal with attribute reduction in discrete information systems [1], but when dealing with attribute reduction in continuous or fuzzy information systems, it is necessary to discretize the attributes firstly, which will lose part of the information. Fuzzy rough set is a generalization and extension of rough set. It has good effect in dealing with attribute reduction of continuous or fuzzy information systems [2], especially intuitionistic fuzzy rough set [3]. However, these methods need to compute the discernibility matrix [4], fuzzy similarity relation matrix [5], or the transitive closure and the closeness matrix [5, 6]. In addition, the computational ability and efficiency are limited using variable precision fuzzy rough sets [7], hybrid fuzzy rough sets [8] or extended fuzzy rough sets [9–11] for large fuzzy information system. How to solve attribute reduction and feature extraction of large-scale fuzzy information system with large amount of data, high feature dimension, dynamic and heterogeneous characteristics is an important issue in current big data processing.
In order to improve the efficiency of attribute reduction and extracting feature fault parameters and the adaptability of large data processing, based on the existing similarity relation of intuitionistic fuzzy rough set and the attribute reduction algorithm of dynamic reduction theory, multiple performance acceleration is realized at the data and method level [12]. At the data layer, generalized dynamic reduction theory is used to transform large-scale fuzzy information system into a series of small-scale fuzzy information systems. At the method layer, the principles of attribute reduction based on similarity and dissimilarity, relative positive domain and dependence degree of intuitionistic fuzzy rough set are used to maximize the efficiency of attribute reduction.
Generalized dynamic reduction theory
Presentation of dynamic reduction
As one of the important research contents of data mining and data reduction technology, attribute reduction refers to the deletion of redundant attributes and their attribute values in the decision table, but its prerequisite is to maintain the dependency relationship between condition attributes and decision attributes of the original decision table unchanged. At present, the reduction algorithm based on rough set theory can be divided into two kinds according to whether there is heuristic information or not. One is blind method, which does not use any heuristic information to obtain a reduction, but the result is unsatisfactory. The other is heuristic algorithm [13, 14], whose idea is to start with the core of the decision table and regard it as a reduction, then add attributes according to certain heuristic information, that is the importance of attributes, until the reduction of the decision table is obtained. For example, there are attribute reduction algorithms based on mutual information, based on discernibility matrix, and based on Pawlak attribute importance, etc. But the problem of these algorithms is that they can only reduce the small-scale compatible decision information system. When the decision information system has a large size of data, the generalization ability of the decision rules obtained by these algorithms is limited. At the same time, the decision information system contains a lot of noise data, so it is an urgent problem to get stability a reduction.
Aim to solve the above problems, Jan. G. Bazan has proposed dynamic reduction algorithms [15–17]. These algorithms are sampling large and complex decision information systems many times, and transform the reduction of complex systems into the intersection of several reductions of sub-decision information systems, and obtain more stable reduction. They have good adaptability to variable data sets, and provide an effective way to solve the attribute reduction for large-scale fuzzy information systems. The facts show that the reduction obtained by dynamic reduction has high stability. It has a good performance in big data processing, adaptability to variable data sets, stability of reductions, and anti-noise ability [18].
Determination of f-family range
–Determination of lower limit for f family
For attribute reduction of incremental data, each additional data are regarded as a sub-table, the original data are taken as a master table, and the parent table can also be regarded as a sub-table set too. Regardless of whether data increasing with time, attribute reduction can use sampling method to obtain sub-tables. If the original table has |U| data, and a new table should select about |U| /|F| data size each time. F is called the F family of decision information system DS. That is, for all decision subsystems P(DS) of DS, there are F ⊆ P (DS) and F ≠ Φ . |F| represents the capacity of the F family. According to the study of the F family capacity in document [19], it can get.
Where, P
G
(R) is the probability of dynamic reduction R appearing in a sub-table of the original decision table. MLE (P
G
(R)) is the maximum likelihood estimation of P
G
(R). ΔMLE (P
G
(R)) is the maximum acceptable error of MLE (P
G
(R)). t
α
represents the interval function related to the allowable maximum error, and it must satisfy,
When P
G
(R) =1/4, P
G
(R) • (1 - P
G
(R)) obtains the maximum value 1/4, and then the minimum value of |F| is obtained,
Where, the value of t α can be querying through the normal distribution table.
–Determination of upper limit of f family
If too many sub-tables are extracted, the computational complexity will increase and the time complexity of the algorithm will be improved. From Bernonlli’s idea, when the decision sub-tables extracted from the F family is large enough, the continued extraction of sub-tables has little effect on the stability of reduction. Therefore, there must be an upper limit for the capacity of F family. From the stability of reduction, Bazan, et al. [19], had studied the upper limit of F family capacity.
Given the initial decision system S = (U, C ∪ D), where U is an universe, C is a non-null conditional attribute set, D is a non-null decision attribute set, and S′ = (US′, C ∪ D) is a full sample decision system. Where, there is US′ =∪ { U B |B ∈ F }, and US′ ⊆ U. The similarity index β1 of decision classification ability between decision sub-system B and full sample decision system S′ is as follows:
Similarly, the decision-making ability index β2 between full sample decision-making system S′ and initial decision-making system S,
The stability parameter of F family relative positive domain is,
Obviously,
If
When the range of F family capacity is determined, it can replace the capacity cardinality of F family specified by experts in probabilistic extraction method. When the number of F family reaches this range, there is no need to extract sub-tables. Therefore, a dynamic reduction method without prior knowledge is obtained. Document [20] demonstrates that the number of effective sub-tables extracted by this method is less.
–F Sub-table extraction strategy
What kind of sampling strategy adopted to extract the subfamily F is the premise of dynamic reduction. The quality of sampling strategy will also directly affect the accuracy of reduction results. When decision tables contain massive data or are constantly changing, the used sampling strategies are different. When a decision table contains a big data information or the decision table is changing, direct reduction of the initial decision table will produce a great reduction error, so the results of reduction can not be used as a guide for drawing up decision-making rules, otherwise the decision-making will fail because of the instability of data. Therefore, when decision table contains massive data information or the decision table is changing, the decision rules obtained by static reduction can not describe the characteristics of the object to be studied very well, but the initial decision table is processed for extracting the sub-table family, that is F family, as the object of reduction, and then the reductions of the sub-tables are intersected, the relatively stable reduction is finally obtained. The characteristics of the initial decision table can be well described by these reductions that exist in most sub-tables. At present, there are two methods for F family sub-tables extraction: trace extraction and probability sampling [20]. Trace extraction method does not take into account the principle of determining the stability coefficient of the decision sub-table, can not extract representative reductions, and the accuracy of dynamic reductions is low [20]. Based on this, this paper chooses the probability sampling method. After the total number of sub-tables and the number of sub-tables in F family are determined, the decision-making sub-tables are extracted according to the following strategies. In order to make the probability of a reduction of F family sub-tables more than 1/2 and exist simultaneously in reductions of the initial decision table, the number of objects in the decision sub-tables that needs to be randomly extracted is greater than 50% of the original decision table. The steps of the probabilistic sampling method are described as follows:
Before sampling, this sampling strategy calculates the minimum number of decision sub-tables that need to be extracted. It takes accuracy as the first consideration factor, and then determines the size of a single decision sub-table as effective as possible. They consider reducing the reduction error.
–F-dynamic reduct
Where, any element in the system is called F-dynamic reduction of decision information system DT.
The final reduction of F-dynamic reduction is calculated by the intersection of all reductions of the initial decision information system and all reductions of decision information sub-system randomly extracted from it. Therefore, the reduction is the most stable and the generalization ability of the decision rules is the strongest. However, this method is too strict for the reduction of F family dynamic reductions, which is dependent on the initial decision information system. Document [21] uses dynamic reduction method to process UCI data sets. The results show that many data sets can not get F family dynamic reduction. Therefore, it need to generalize the dynamic reduction concept, and introduce (F–λ)-dynamic reduction, improve the ability of F family dynamic reduction.
Where, any element is called the (F-λ)-dynamic reduction of decision information system DT, and λ ∈ [0, 1] is called the precision coefficient of (F–λ)-dynamic reduction. | { B ∈ F : R ∈ RED (B, d) } |/|F| is called the stability coefficient of (F–λ)-dynamic reduction R relative to F family.
(F–λ)-dynamic reduction has the properties as follows, If F ={ DT }, then DR (DT, F) = RED (DT, d). If λ2 ⩾ λ1, then DR
λ
2
(DT, F) ⊆ DR
λ
1
(DT, F). DR1 (DT, F) = DR (DT, F).
(F–λ)-dynamic reduction of decision information system is an extension of F family dynamic reduction, and reduces the dependence on initial decision information system in F family dynamic reduction. However, when the data increases, the decision rules generated by the new decision information system will be greatly different from those generated by the original decision information system, which requires further expansion of dynamic reduction to improve the adaptability and generalization ability of reduction.
Where, any element is called F-generalized dynamic reduction of decision information system DT.
When the number of objects and attributes in the decision information system is very large, the complexity and difficulty computing the reduction of the decision system will become immeasurable. F-family generalized dynamic reduction is no longer to reduce the initial decision information system, but to intersect the reductions of all decision sub-systems randomly extracted. In a sense, generalized dynamic reduction is more extensive than dynamic reduction.
Where, any element is called (F–λ)-generalized dynamic reduction in the decision information system DT. Where λ ∈ [0, 1] is the precision coefficients of (F–λ)-generalized dynamic reduction, and | { B ∈ F : R ∈ RED (B, d) } |/|F| is called the stability coefficients of (F–λ)-generalized dynamic reduction R relative to F family.
(F–λ)-generalized dynamic reduction has the properties as follows, DR (DT, F) ⊆ GRD (DT, F). If λ2 ⩾ λ1, then GDR
λ
2
(DT, F) ⊆ GDR
λ
1
(DT, F). DR1 (DT, F) ⊆ GDR (DT, F). If DT ∈ F, then DR (DT, F) = GDR (DT, F).
Intuitionistic fuzzy rough set (IFRS) is the integration product of intuitionistic fuzzy set and rough set theory, and takes inclusion degree as a bridge between intuitionistic fuzzy set and rough set, and introduces variable precision concept. Therefore, IFRS has a certain fault-tolerant ability and can effectively deal with mixed data types in information systems, including symbolic data, continuous value data and fuzzy data. When IFRS are used for knowledge acquisition, firstly the intuitionistic fuzzy similarity relation should be established, and can be constructed by similarity measure between objects. Secondly, because the intuitionistic fuzzy relation must satisfy the two-dimensional constraint of the intuitionistic fuzzy set, i.e., the membership degree and the non-membership degree are not negative and the sum in the interval [0,1], and the similarity is a mapping x × y → [0, 1], which can only express the degree of similarity between two elements, that is, membership degree, but it can not express the degree of non-similarity between two elements, i.e., non-membership degree.
In intuitionistic fuzzy information system S = (U, C, V C , D, V D , F), ∀a ∈ C, if a is a continuous attribute or an intuitionistic fuzzy attribute, then an intuitionistic fuzzy similarity relation R a can be defined for a, and it can be simplified as R.
If R(x,y) = 1
L
, then R is self-reflexive. If R(x,y) = R(y,x), then R is symmetrical. If If T (R (x, z) , R (z, y)) ⩽ LR (x, y), then T is transitive. If
The properties of R determine the properties of knowledge obtained after the universe U is divided. If R is a general equivalence relation, the knowledge obtained after U/R is a clear equivalence class. If R is an intuitionistic fuzzy equivalence relation, the knowledge obtained after U/R is an intuitionistic fuzzy equivalence class, i.e., each class is an intuitionistic fuzzy set. If R is an intuitionistic fuzzy similarity relation, the knowledge obtained after U/R is an intuitionistic fuzzy similarity class. If R is a general intuitionistic fuzzy relation, then R divides the universe U into several intuitionistic fuzzy sets.
f (0) =0, f (∞) =1, f (•) ∈ [0, 1]. x ⩾ y ⇒ f (x) ⩾ f (y).
It is easy to be proved that Equation (12) satisfies the requirement of intuitionistic fuzzy dissimilarity definition [22].
The monotone decreasing function g (x) can select 1 - x, e-x or 1/(x + 1). Where, e.g., g (x) = e-x can be selected here, so that the similarity degree is shown in Equation (14),
Dissimilarity matrix and similarity matrix are fuzzy matrices satisfying self-reflexivity and symmetry.
Intuitionistic fuzzy similarity relations corresponding to continuous attributes or intuitionistic fuzzy attributes is R = (r ij ) n×n ={ (μ R (x i , x j ) , γ R (x i , x j )) |x i , x j ∈ U }. The construction problem discussed as below. Firstly, the similarity relation must satisfy the two-dimensional constraints of intuitionistic fuzzy sets. Secondly, when the intuitionistic fuzzy similarity relation by using similarity degree and dissimilarity degree is established, the corresponding relationship between similarity degree and dissimilarity degree should be considered. That is, for ∀x i , x j ∈ U, and there is a corresponding relationship between the membership degree μ R (x i , x j ) of similarity relation R and similarity degree s (x i , x j ), and between the non-membership degree γ R (x i , x j ) of similarity relation R and dissimilarity d (x i , x j ). Similarity degree reflects the degree of similarity between x i and x j , while dissimilarity degree does not reflect the degree of similarity. Finally, it should be considered the relationship between similarity degree and dissimilarity degree, i.e., 1 - s (x i , x j ) implies the concept of dissimilarity degree, while 1 - d (x i , x j ) implies the concept of similarity degree. Based on this, the construction theorems of intuitionistic fuzzy similarity relations are obtained as follow.
–First, the proof proves that binary relation R is intuitionistic fuzzy binary relation. According to Equation (15), it can be obtained that μ
R
(x
i
, x
j
) ∈ [0, 1], γ
R
(x
i
, x
j
) ∈ [0, 1]. Because of λ ∈ [0, 1], therefore
Therefore, 0 ⩽ μ R (x i , x j ) + γ R (x i , x j ) ⩽1, R is intuitionistic fuzzy binary relation.
–Second, ∀x i , x j ∈ U,
That is, R is self-reflexivity.
That is, R is symmetry.
So, R is an intuitionistic fuzzy similarity relation.
End.
From theorem 1, it can see that, when λ = 1 the sum of membership and non-membership of intuitionistic fuzzy similarity relation is 1, and then intuitionistic fuzzy similarity relation is transformed into ordinary fuzzy similarity relation. In practical application, λ can be selected according to specific preferences.
In conclusion, the intuitionistic fuzzy similarity relation R = (r
ij
) n×n ={ (μ
R
(x
i
, x
j
) , γ
R
(x
i
, x
j
)) | x
i
, x
j
∈ U } corresponding to continuous attributes and intuitionistic fuzzy attributes has been established. ∀x
i
∈ U (x
i
)
R
represents R similar classes of object x
i
, and are intuitionistic fuzzy subsets on universe U.
Since the general equivalence relation can be regarded as a special intuitionistic fuzzy relation, it can be treated as the same as the intuitionistic fuzzy similarity relation. For combinations of multiple conditional attributes, their similarity relations and similar classes are defined as follows.
RA1∪A2 = R
A
1
∩ R
A
2
.
It can be obtained from definition 13, if A1 ⊆ A2, then R A 1 ⊇ R A 2 , [x] A 1 ⊇ [x] A 2 . That is, the more attributes there are, the less similar classes there are.
Where, P-X = {x i |I ([x i ] P , X) 1 ⩾ k}. k is the preset lower approximation threshold, which reflects the fault tolerance of the system. The smaller the threshold k, the stronger the fault tolerance of the system.
Generally, the larger the relative positive domain is, the more perfect the knowledge in the knowledge base is, the more accurate the approximation of the concept is, and the smaller the boundary domain is, and vice versa.
Where, |pos C (D) | represents the cardinality of the relative positive domain pos C (D). The dependence degree of attribute group represents the inclusion relationship between two attribute groups, that is, when attribute group B depends on attribute group A (denoted as A ⇒ B), if and only if ind (A) ⊆ ind (B).
In a decision table, different attributes may have different importance. In order to find out the importance of some attributes (or attribute sets), the general method is to remove some attributes from the table, and then examine how classification will change without this attribute. If these attributes are removed, the corresponding classification changes greatly, then the importance of this attribute is high. Conversely, the importance of the attribute is low.
Algorithm process
The basic idea of dynamic attribute reduction algorithm for large data based on similarity relation of intuitionistic fuzzy attributes is described as follows. Firstly, the continuous attributes of decision tables are intuitionistic fuzzified according to the standardization method in document [23]. Then, the intuitionistic fuzzy decision information system is sampled by dynamic sampling technology, and the intuitionistic fuzzy decision information sub-system family {U1, U2, ⋯ , U n } is obtained. Secondly, for each decision information sub-system U i , the cardinality of the relative positive domain for each level attribute combination in U i is taken as the basis of heuristic search, and the attribute with the largest cardinality of the relative positive domain is selected and put into the candidate subset, ... ... . Until the combination of hierarchical attributes satisfies the criterion of the maximizing cardinality of the relative positive domain, and the reduction R i of the subfamily U i is obtained. This cycle lasts until all reductions {R1, R2, ⋯ R n } of the families of intuitionistic fuzzy decision information sub-system are computed. Finally, the relative reduction R of intuitionistic fuzzy decision information system is obtained by intersecting these reductions, that is R = R1 ∩ R2 ∩ ⋯ ∩ R n .
Based on the above ideas, the process of generalized dynamic attribute reduction algorithm based on similarity relation of intuitionistic fuzzy rough set is as follow as Fig. 1.
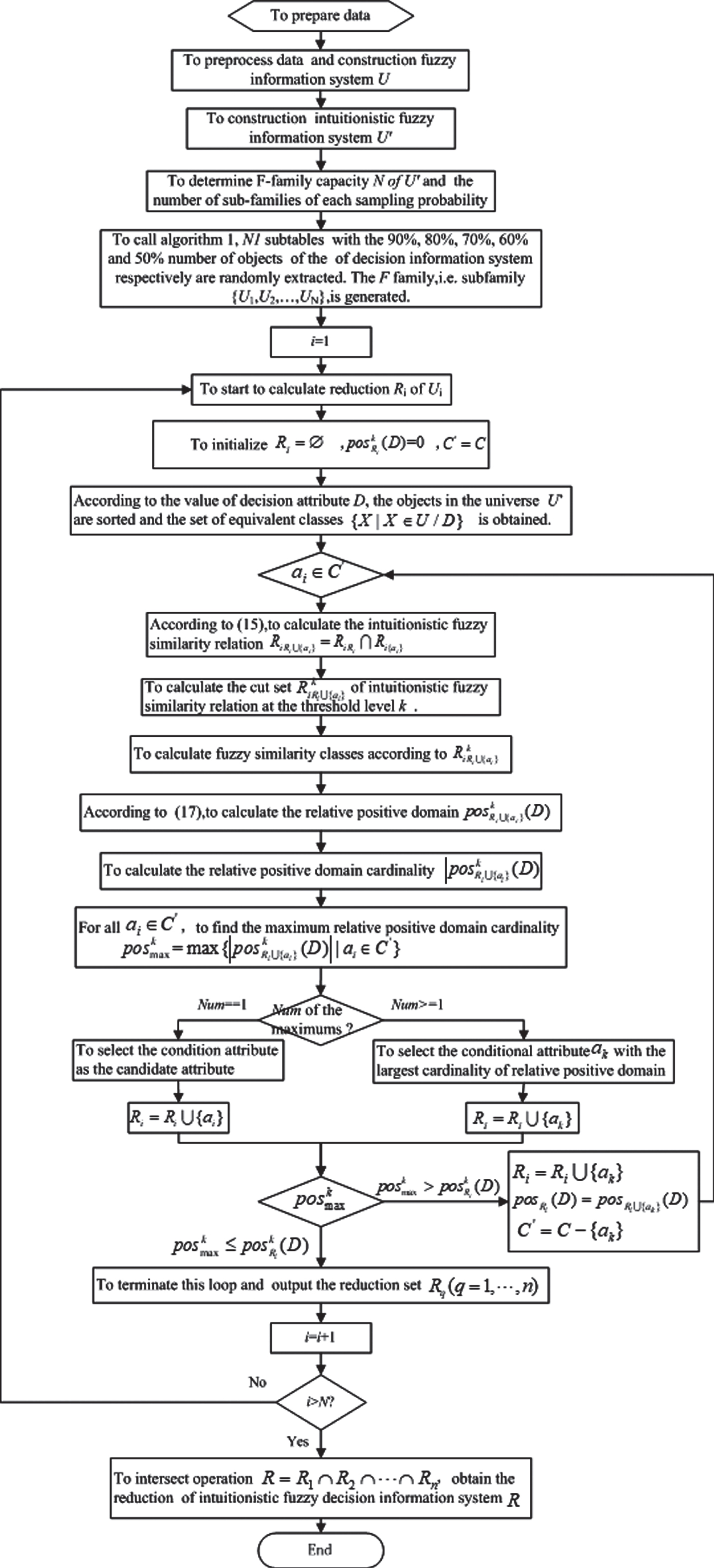
General dynamic attribute reduction based on fuzzy similarity relation of intuitionistic fuzzy rough set.
Generalized dynamic attribute reduction algorithm based on fuzzy similarity relation of intuitionistic fuzzy rough set and is described as follows,
Experimental results and analysis
Experimental data and parameter setting
In order to verify the principle, the performance of the algorithm is verified by the fault diagnosis case of certain aircraft in ground state. The engine fault diagnosis model can be represented by the following nonlinear equations [24]:
Where,
y——the output value. It indicates the engine state.
T1*——Total inlet temperature.
N1——Low-pressure rotor speed.
N2——High-pressure rotor speed.
Φ pc ——Tail nozzle indication value.
P M ——Lubricating oil pressure.
B——Vibration value of engine crankcast.
Let T = (U, S, R, D) be an engine fault fuzzy information system. Where U = x1, x2, ... , x n is a set of engine fault data, which is abbreviated as universe. R = total inlet temperature, low-pressure rotor speed, high-pressure rotor speed, tail nozzle indication value, lubricating oil pressure, vibration value of engine crankcast is a continuous conditional attribute set, respectively noted as R ={ r1, r2, r3, r4, r5, r6 }. D = engine state y is a discrete decision attribute set. S = R ∪ D is an all attribute set. The intuitionistic fuzzy information system of engine fault is obtained from the data in document [24], as shown in Table 1.
An intuitionistic fuzzy information system for engine fault(R100 %, π ij = 0.01)
The parameters are set as follows that fuzzy index π ij = 0.01, λ = 0 . 6, intuitionistic fuzzy partition threshold κ = 0 . 6. When the acceptable error ΔMLE(PG(R)) is 11.11%, α = 9, tα = 0.703, then |F| ⩽ 10. It is taken that |F| = 10. There are two subfamily tables for each sampling probability.
The subfamily is expressed as F - R(P G ,χ). Where, P G represents the sampling probability, χ represents the sampling times. Two subfamilies which are respectively containing 90%,80%,70%,60%,50% samples were sampled respectively from original decision information system, and they are noted as F-R (90 %,1) , F-R (90 %,2) , F-R (80 %,1) , F-R (80 %,2) , F-R (70 %,1) , F-R (70 %,2) , F-R (60 %,1) , F-R (60 %,2) , F-R (50 %,1) , F-R (50 %,2) , and their reductions are noted as R(90%,1), R(90%,2), R(80%,1), R(80%,2), R(70%,1), R(70%,2), R(60%,1), R(60%,2), R(50%,1), R(50%,2).
According to the algorithm 2, the reduction of the intuitionistic fuzzy information system is the result of intersection operation of sub-family reductions after dynamic sampling. Under the condition that the threshold is (α,β) = (0.6, 0.4), the reduction results of all sub-families are shown in Table 2. The intuitionistic fuzzy rough information system after attribute reduction is shown in Table 3.
Results of system and subfamilies reduction
Results of system and subfamilies reduction
1A: Algorithm in this paper and the algorithm based on the dependence degree. 2B: Algorithm based on discernibility matrix. 3C: Algorithm in document [27].
Intuitionistic Fuzzy Rough Information System after Attribute Reduction (π ij = 0.01, threshold (α,β) = (0.6,0.4))
The generalized dynamic reduction of whole intuitionistic fuzzy information system is as GDR IFRS ={ r1, r6 }. While the reduction of generalized attribute reduction based on discernibility matrix of intuitionistic fuzzy rough set is GDR IFRS ={ r1 }.
Rough set method is used to reduce the data in Table 1, and the attribute sets are reduced as {r1, r2, r4, r6}, {r1, r2, r5, r6}, {r2, r4, r5, r6} and {r1, r3, r5, r6}. Under the condition of 100% sampling probability, the generalized dynamic reduction of intuitionistic fuzzy information system is a subset of the static reduction of rough set. This shows that, compared with rough set reduction, generalized dynamic reduction can get more refined reduction.
The stability analysis of each sub-family reduction is shown in Table 2. The envelope of dynamic reduction is described by the number of attributes in dynamic reduction, as shown in Fig. 2. The envelope analysis shows that the generalized dynamic reduction based on the relative positive domain of intuitionistic fuzzy rough sets is relatively stable. When the sampling coverage is between 50% and 70%, the system reduction reaches the most stable state, as shown in Fig. 2(a). The generalized attribute reduction algorithm based on discernibility matrix of intuitionistic fuzzy rough set achieves the most stable state when the sampling coverage is more than 90%, as shown in Fig. 2(b). From Fig. 2, compared with the envelope range of the generalized dynamic reduction algorithm based on discernibility matrix of intuitionistic fuzzy rough set, the generalized dynamic reduction algorithm based on the relative positive domain of intuitionistic fuzzy rough sets is smaller than that of the generalized dynamic reduction algorithm based on discernibility matrix of intuitionistic fuzzy rough set. It shows that the stability of the generalized dynamic reduction algorithm in this paper is better than that of the algorithm based on discernibility matrix of the intuitionistic fuzzy rough set.

Variation curves of samples and reduced envelopes.
In the process of dynamic reduction, the cardinality of the relative positive domain keeps increasing and then remains unchanged. There is no case that the number of attributes is increasing while the cardinality, dependence and importance of the relative positive domain is decreasing, to see Fig. 3.

Variation curves of relative positive domain cardinality during reduction.
Rough set method is used to reduce the data of Table 4, the reductions are {r1, r2, r4, r6}, {r1, r2, r5, r6}, {r2, r4, r5, r6}, and {r1, r3, r5, r6}. Compared with rough set method, it is found that the algorithm proposed in this paper can get smaller reductions, and the number of reduction attribute is less, and the redundant information is less.
Diagnostic accuracy compared with other methods
Diagnostic accuracy compared with other methods
In order to further verify the validity of the extracted feature parameters, the 7∼9 samples are taken as test samples, the rest samples are taken as training samples, the attribute values in the reduction set are taken as BP neural network input, and the engine state is taken as output to compare and calculate. The results are shown in Table 4. In order to verify the scientificity of the algorithm and the validity of the feature parameters, the experiment adds the combination of some attributes excluded from the reduction to investigate the interference of redundant attributes.
The validation results show that, compared with rough set method, the proposed algorithm obtains fewer feature parameters, eliminates the interference of redundant attributes, and maintains the highest diagnostic accuracy of feature parameters obtained by rough set method. Redundant attributes r2, r4, r5 have less interference to diagnostic accuracy, while redundant attribute r3 has the greatest interference ability, and the combination precision of reduction containing attribute r3 is very low. The diagnostic accuracies of reductions {r2, r3, r6} and {r3, r6} are the same, it indicates that attribute r2 is redundant. The diagnostic accuracies of reductions {r2, r3, r5, r6} and {r2, r3, r6} is the same, it indicates that attribute r5 is redundant.
The diagnostic accuracy of reduction {r1, r6} is higher than that of reduction {r1, r2, r4, r6}, and attribute r2 is redundant, so the attribute r4 is not only redundant, but also has greater interference ability. Compared with the diagnostic accuracy of attribute combination {r2, r3, r4, r6}, the diagnostic accuracy of attribute combination {r2, r3, r5, r6} is lower. Under the condition that r2, r3, r4 are all redundant attributes, and r5 is redundant attribute too, so they can be removed from reduction. The diagnostic accuracies of reduction sets {r1} and {r1, r6} are the same, but it can not be explained whether attribute r6 is redundant. Because all of r2, r3, r4 are redundant attributes, the diagnostic accuracies of attribute sets {r2, r3, r4, r6} and {r2, r4, r5, r6} has reached or reached the same level of {r1} and {r1, r6}, and they are the highest. This shows that when the contribution of attribute r1 to correct diagnosis is 0, the attribute r6 plays an important role in making correct diagnosis. They are also the key attributes in describing the fuzzy information system and can not be omitted.
In summary, there are still too many redundant attributes in the attribute reduction using rough set method. The generalized attribute reduction method based on discernibility matrix of intuitionistic fuzzy rough set has the problem of over-reduction, and the key attribute r6 is omitted in the reduction set. However, the algorithm in this paper can get the relatively correct reduction set of intuitionistic fuzzy information system. In this way, fault diagnosis can be realized with fewer characteristic parameters, which greatly reduce the workload and improve the efficiency of fault diagnosis. At the same time, it can also solve the redundancy problem of diagnosis parameters.
Known from Table 1 and Table 3, the system needs 144 storage units to store before reduction. While after reduction, the system only needs 72 storage units, which reduces the storage space by 50%.
According to the classification and discrete results of document [28], the traditional rough set reduction algorithm is used to extract the diagnostic rules, if the total set {r1, r2, r3, r4, r5, r6} of conditional attributes as characteristic parameters, then there are 1024 diagnostic rules extracted from the decision table. Using the algorithm proposed in this paper, if the set {r1, r6} of reduction attribute is taken as characteristic parameters, then there are 32 diagnostic rules extracted from the decision table. The size of rule base is reduced by 98.88%.
This proves that the generalized dynamic attribute reduction algorithm based on relative positive domain of intuitionistic fuzzy rough set can get fewer rules after extracting the feature parameters. That is, 1024 diagnostic rules need to be stored before, while only 32 rules need to be stored, and the optimization effect is obvious. This greatly reduces the size of rule base, saves a lot of storage space, effectively solves the problem of big knowledge base, and improves the efficiency of diagnosis.
Time complexity analysis
Assumption S = (U, P ∪ Q, V, f) is an intuitionistic fuzzy knowledge representation system. Where, |U| = n, |P| = m, and the number of sub-families is |F|. In the dynamic sampling stage, each sampling almost needs to traverse the domain of the system. Therefore, the time complexity of the sub-family sampling process is O (mn|F|). In document [26], the maximum time complexity of the algorithm based on the intuitionistic fuzzy discernibility matrix of intuitionistic fuzzy rough set approximates to O (|F|m (m + 1) n2/2). The time complexity of the attribute reduction algorithm based on the dependency degree of intuitionistic fuzzy rough set is approximating to O (|F|m (m + 1) n2/2) [25]. The time complexity of the proposed algorithm in this paper is approximate to O (|F|m (m - 1) n2/2). Compared with other algorithms, the algorithm proposed in this paper has obvious advantages in time consumption and can save 27.69% time in the case in this paper.
Comprehensive analysis
A fuzzy rough set attribute reduction method based on fuzzy distance measure of similarity relation is proposed in document [27]. This method is similar to the method based on discernibility matrix and attribute dependency, but it is still powerless to solve the problem of large data sets. Therefore, it can only be compared with the proposed method for the small data set reduction results after generalized sampling.
The parameters are selected as follows p = 2, k = 3, δ = 0.001. According to the reduction results in Table 2, the algorithm in this paper obtains the same generalized dynamic reduction GDR IFRS ={ r1, r6 } as the method in document [27]. The difference is that the algorithm proposed in this paper has redundant attribute r3 in the reduction of subsets, while the algorithm in document [27] have redundant attribute r5 in the reductions of subsets, and the stability is also very good. This has been described above.
According to the fault diagnosis results in Table 4, the diagnostic accuracy of the algorithm in document [27] is the same as that of the algorithm in this paper. After removing redundant attribute {r5}, the diagnostic accuracy is also improved.
The time complexity of the algorithm in document [27] is O (mn2 + (m2 + m)/2). Combining with the sampling time complexity O (mn|F|) of the sub-family, the time complexity of the synthesis algorithm is
Conclusion
In view of the characteristics of dynamic, big data and fuzziness in big data sets, this paper innovatively proposes a generalized dynamic attribute reduction algorithm for big data based on dynamic reduction sampling theory and similarity relation of intuitionistic fuzzy rough set. The dynamic reduction theory is innovatively used to solve the problem of big data set and its dynamics, the intuitionistic fuzzy rough attribute reduction algorithm is used to solve the problem of fuzziness, and the cardinality of relative positive domain is innovatively used to replace the dependence degree as the criterion of reduction reasonableness. The stable reduction of decision table is obtained. The main conclusions and innovations are as follows: Using dynamic reduction sampling theory, after dynamic sampling, we divide a big data set into small data sets. Through real data validation, dynamic sampling can effectively solve the dynamic increment problem in large-scale fuzzy information system, and obtain stable reduction. The algorithm in this paper provides a selection scheme for data mining and knowledge discovery in dynamic large-scale fuzzy information system. The algorithm in this paper is an attribute reduction method based on relative positive domain cardinality of intuitionistic fuzzy rough set similarity, using relative positive domain cardinality instead of dependency degree as decision-making condition. It reduces the complexity of the algorithm, extracts the attribute combination with the largest relative positive domain cardinality, effectively extracts the key factors affecting the classification decision-making of the system, removes redundancy, improves the interference ability, and accurately describes the system. The obtained fault diagnosis rule base and sample storage space are optimized. Compared with similar attribute reduction algorithms, such as rough sets, the reduction algorithm based discernibility matrix and the reduction algorithm based dependence degree of intuitionistic fuzzy rough set, the algorithm proposed in this paper can not only overcome the problem of over-rough reduction and over-reduction, but also get more refined and reasonable approximation reduction, and reduce time consumption. It provides an effective and accurate way for big data processing. Compared with similar attribute reduction algorithms, such as the reduction algorithm based discernibility matrix and the reduction algorithm based fuzzy distance measure, the algorithm proposed in this paper can own small time complexity on the premise of ensuring diagnostic accuracy. More importantly, it has the ability to adapt to big data set reduction.
At present, incremental computing [29], parallel computing [30, 31] have become new hotspots of big data mining and attribute reduction, so the next research directions are: By putting the algorithm into bigger data sets and parallel computing environment for attribute reduction, the time complexity of the algorithm will be further reduced and the adaptability of the algorithm to big data processing will be further enhanced. The adaptability of the algorithm to hybrid information system will be studied, and the processing ability of the algorithm to discrete attributes and multi-decision attributes hybrid information system will be enhanced.
Footnotes
Acknowledgments
The author would like to thank those researchers such as LEI Yingjie, KONG Weiwei, who had studied intuitionistic fuzzy rough theories. The author would like to thank Jan. G. Bazan who proposed generalized dynamic reduction theory. This work is supported and inspired in part by a grant from them.