
Abstract
Fuzzy set (FS) theory is one of the most important tool to deasl with complicated and difficult information in real-world. Now FS has many extensions and hesitant fuzzy set (HFS) is one of them. Further generalization of FS is complex fuzzy set (CFS), which contains only the membership grade, whose range is unit disc instead of [0, 1]. The aim of this paper is to present the idea of complex hesitant fuzzy set (CHFS) and to introduce its basic properties. Basically, CHFS is the combination of CFS and HFS to deal with two dimension information in a single set. Further, the vector similarity measures (VSMs) such as Jaccard similarity measures (JSMs), Dice similarity measures (DSMs) and Cosine similarity measures (CSMs) for CHFSs are discussed. The special cases of the proposed measures are also discussed. Then, the notion of complex hesitant fuzzy hybrid vector similarity measures are utilized in the environment of pattern recognition and medical diagnosis. Further, based on these distance measures, a decision-making method has been presented for finding the best alternative under the set of the feasible one. Illustrative examples from the field of pattern recognition as well as medical diagnosis have been taken to validate the approach. Finally, the comparison between proposed approaches with existing approaches are also discussed to find the reliability and proficiency of the elaborated measures for complex hesitant fuzzy elements.
Keywords
Introduction
Fuzzy set (FS) as a generalization of crisp set was introduced by Zadeh [1] in 1965 to deal with the complicated and difficult information in real decision theory. In FS theory we have grade of membership whose value belongs to [0,1], where higher values denote higher grade of membership. FS have many applications in different fields like control theory [2], artificial intelligence [3], inference and reasoning [4]. Bustince et al. [5] worked on FSs and their extensions representation, aggregation and models. Measures of similarity between FSs is a great significance in FS theory, which gained great attention from the researchers. Measures of similarity have many applications in real life and very handy in many areas such as decision making [6] and cluster analysis [7]. Chen [8] described a similarity function to measure the degree of similarity between FSs. Chen [9] represented a comparison of similarity measures of fuzzy values. Pappis and Karacapilidis [10] introduced a comparative assessment of similarity measures of fuzzy values. Lee-Kwang et al. [11] gave the idea of similarity measures between FSs and between elements.
Many researchers raised the question, what will be the effect when we change the range of FS into unit disc in a complex plane. For handling such types of situation, Remote et al. [12] pioneered the conception of complex fuzzy set (CFS), as an extension of FS to cope with complicated and difficult information in real-life theory. The notion of CFS is characterized by complex-valued membership grade, which contains two-dimension information in a single set. Further, Tamir et al. [13] introduced the cartesian complex fuzzy set and the cartesian complex fuzzy membership where both real and imaginary parts take the fuzzy information. In polar representation the fuzzy information takes the absolute value and phase value of complex membership function. Complex fuzzy number is different from the complex fuzzy set. Zhang et al. [14] developed operation properties and δ-equalities of complex fuzzy sets.
Hesitant Fuzzy Set (HFS) is one of the most important extensions of the FS, which was proposed by Torra [15, 16]. A HFS is characterized by a membership function that when applied to a universal set X returns a finite subset of [0, 1] for each element of X. Torra and Narukawa [16] defined some basic operation of HFS. Rodriguez et al. [17] developed the concept of Hesitant fuzzy linguistic term sets for decision making. Farhadina [18] described the notion of distance and similarity measures for higher order hesitant fuzzy sets. Xia and Xu [19] defined the concept of hesitant fuzzy information aggregation in decision making. Wei et al. [20] developed the concept of hesitant fuzzy Choquet integral aggregation operators and their applications to multiple attribute decision making. Zhang [21] defined hesitant power aggregation operators and their application to multiple attribute group decision making. Xu and Xia [22] described the concept of distance and correlation measures of hesitant fuzzy information. Zhu et al. [23] gave the concept of hesitant fuzzy geometric Bonferroni means. Xia et al. [23] developed Some hesitant fuzzy aggregation operators with their application in group decision making. Tan et al. [25] described Hesitant fuzzy Hamacher aggregation operators for multicriteria decision making. Qian et al. [26] gave the concept of generalized hesitant fuzzy sets and their application in the decision support system.
The concept of similarity is a basic concept in human cognition. Similarity plays an essential role in taxonomy, recognition, case-based reasoning and many other fields. There are many aspects of the concept of similarity that have eluded formalization. According to [hesitant fuzzy set] formulation of a valid, general purpose definition of similarity is a challenging problem. There does not exist a valid, general-purpose definition of similarity. There does exist many special purpose definitions which have been employed with success in cluster analysis, search, classification, recognition and diagnostics. There are several similarity measures that are proposed and used for varied purposes [27]. The similarity measures are classified into three categories: 1) Metric based measures, 2) Set-theoretic based measures and 3) Implicators based measures. While dealing with distance based similarity measures, examples have been constructed for perceptual similarity where, every distance axiom is clearly violated by dissimilarity measures particularly the triangle inequality [16] and consequently the corresponding similarity measure disobeys transitivity. This model postulates that the perceptual distance satisfies the metric axioms, the empirical validity of which has been experimentally challenged by several researchers, particularly the triangle inequality (for details see [15] and [16, 29]). Similarly in case of set theoretic similarity measures, it is observed that crisp transitivity is a much stronger condition to be put upon similarity measure. Set theoretic similarity measures are further subdivided in three groups (a) measures based on crisp logic (b) measures based on fuzzy logic (c) measures based on hesitant fuzzy sets.
In this paper, we introduce complex hesitant fuzzy sets. The motivation is that when defining the membership of an element, the difficulty of establishing the membership degree is not because we have a margin of error (as in complex intuitionistic fuzzy set [30]), or some possibility distribution (as in type 2 complex fuzzy sets) on the possible values, but because we have a set of possible values. This is the case if we consider as possible values for the membership of x into the set A only two values 0.3ej2π(0.22) and 0.4ej2π(0.21). This situation can arise in a multicriteria decision-making problem. For example, when only some values of membership are possible for a given element because, e.g., some experts have only assigned such small and finite set. In this context, instead of considering just an aggregation operator [31], it is useful to deal with all the possible values. This situation, as we will discuss later, can be modeled using multisets. Nevertheless, such model is not completely adequate because the operations for multisets do not apply correctly to our sets according to their interpretation. Because of this and keeping the advantages of the similarity measures, in this paper the novel approach of complex hesitant fuzzy sets (CHFS) is introduced, which as the combination of complex fuzzy set and hesitant fuzzy set to cope with uncertain and unpredictable information in real decision theory. The CHFS contains the finite subsets of the grade of memberships in the form of polar coordinates belonging to unit disc in the complex plane. The CHFS is contains two-dimensional information in a single set. The fundamental properties of the proposed approach are also discussed in detailed. The proposed approach is more general than existing methods, by including the imaginary part in every membership grades. Further, we propose the VSMs and hybrid VSMs based on CHFS. Moreover, we present some new measures to solve MAGDM problems with hesitant complex fuzzy information. Finally, an illustrative example is provided to show the feasibility and validity of the new measures, to investigate the influences of parameter vector λ on decision-making results, and also to analyze the advantages of the proposed measures by comparing them with the other existing measures.
This paper is structured as follows. In section 2 we defined preliminaries. In section 3, the idea of the complex hesitant fuzzy set (CHFS) and its basic properties are introduced. We described the vector similarity measures (VSMs) such as Jaccard similarity measures (JSMs), Dice similarity measures (DSMs) and Cosine similarity measures (CSMs) for CHFSs. We also described the hybrid vector similarity measure for CHFS. In section 4, the demonstration of practicality and effectiveness of the proposed methods is illustrating by two practical examples. Furthermore, we discussed the comparison between the proposed approaches with existing approaches. The conclusion of this manuscript is discussed in section 5.
Preliminaries
In this section, we review basic notions like FSs, CFSs and HFSs. The basic properties of the existing methods are also discussed. Throughout this manuscript, the universal set is denoted by X. Where S, T ∈ FS (X).
S ⊆ T iff μ
S
(x)⩽ μ
T
(x) ; S = T iff T ⊆ S and T ⊇ S; S
c
= {〈 x, 1 - μ
S
(x) 〉 |x ∈ X}; S ∩ T = { < x, min { μ
S
(x) , μ
T
(x) } > |x ∈ X }; S ∪ T = { < x, max { μ
S
(x) , μ
T
(x) } > |x ∈ X }.
{ μS∪T (x) = max { γ
S
(x) , γ
T
(x) } . ejmax{ω
S
(x),ω
T
(x)}; μS∩T (x) = min { γ
S
(x) , γ
T
(x) } . ejmin{ω
S
(x),ω
T
(x)}; μ
S
C
(x) = { 1 - γ
S
(x) } . ej{2π-ω
s
(x)}.
In this section, the notion of CHFS and their operational laws are investigated. The proposed approach is also verified with the help of examples. The CHFS is a combination of CFS and HFS, to deal with uncertain and complicated information in real-life problems. Further, some similarity measures are also explored in this section to improve the quality of the research work. The notion of CHFS is explained below:
The notion of Similarity measures (SM) is a primary notion of human perspective. SM plays an important role in many fields such as decision making, machine learning etc. The VSM is one of the key instrument for the similarity degree between objects. For this motive we openly used Jaccard, Dice and Cosine SM. Now in this section we define vector similarity measures (VSM) and weighted vector similarity measures (WVSM) for complex hesitant fuzzy sets. We also define hybrid vector similarity measure and weighted hybrid vector similarity measure for complex hesitant fuzzy sets.
0 ⩽ J
AC
(S, T) ⩽ 1 J
AC
(S, T) = J
AC
(T, S) J
AC
(S, T) = 1, if S = T
1. Since
For k = 2
By continuing this process we get
2. By definition of JSM we have
3. By definition we have
Now as S = T then μ S i (x k ) = μ T i (x k ) for k = 1, 2, …, n this implies that γ S i (x k ) . ejω S i (x k ) = γ T i (x k ) . ejω T i (x k ) for k = 1, 2, …, n ⇒ γ S i (x k ) = γ T i (x k ) and ejω S i (x k ) = ejω T i (x k )fork = 1, 2, …, n. Thus
0 ⩽ D
Ic
(S, T) ⩽ 1 D
IC
(S, T) = D
IC
(T, S) D
IC
(S, T) = 1, if S = T
1. Since
For k = 2
By continuing this process we get
2. By definition of DSM we have
3. By definition we have
Now as S = T then μ S i (x k ) = μ T i (x k ) for k = 1, 2, …, n this implies that γ S i (x k ) . ejω S i (x k ) = γ T i (x k ) . ejω T i (x k )fork = 1, 2, …, n ⇒ γ S i (x k ) = γ T i (x k ) and ejω S i (x k ) = ejω T i (x k )fork = 1, 2, …, n. Thus
0 ⩽ Cos (S, T) ⩽ 1 Cos (S, T) = Cos (T, S) Cos (S, T) = 1, if S = T
1. Since
For k = 2
2. By definition of CSM we have
3. By definition we have
Now as S = T then μ S i (x k ) = μ T i (x k ) for k = 1, 2, …, n this implies that γ S i (x k ) . ejω S i (x k ) = γ T i (x k ) . ejω T i (x k ) for k = 1, 2, …, n ⇒ γ S i (x k ) = γ T i (x k ) and ejω S i (x k ) = ejω T i (x k ) for k = 1, 2, …, n. Thus
0 ⩽ H
yb
w
(S, T) ⩽ 1 H
yb
w
(S, T) = H
yb
w
(T, S) H
yb
w
(S, T) = 1 if S = T
From the (15) and (16) we have 0 ⩽ D
IC
w
⩽ 1 and 0 ⩽ Cos
w
⩽ 1 for all k = 1, 2, . . . , n. Thus (18) becomes
Since D
IC
w
(S, T) = D
IC
w
(T, S) and Cos
w
(S, T) = Cos
w
(T, S) this implies that H
yb
w
(S, T) = H
yb
w
(T, S). If S = T then from equation (4) and (6) we have D
IC
w
(S, T) = 1 and Cos
w
(S, T) = 1 this implies that H
yb
w
(S, T) = λ + (1 - λ) = 1.
Because D
IC
w
(S, T) ⩾ 0 and Cos
w
(S, T) ⩾ 0 this implies that H
yb
w
(S, T) ⩾ 0 for any value of λ ∈ [0, 1]. This completes the prove of 1.
In this portion the proposed VSMs for CHFSs are applied to pattern recognition and medical diagnosis. For this we defined the following two examples.
Pattern recognition
The tools of similarity measures have applications in pattern classification. In such a phenomenon, the class of an unknown pattern or object is found using some similarity measuring tools and some preferences of decision makers. In this section, the similarity measures developed so far in Section 3, are applied to a pattern recognition (building pattern recognition) problem where the class of an unknown building material needed to be evaluated. The results obtained using the similarity measures of CHFSs are then analyzed for description of the advantages of proposed work and the limitations of existing work. To explain the phenomenon, an illustrative example adapted from Reference [32] is discussed.
Next suppose an unknown pattern
The cause of this issue is to arrange the pattern S in one of classes S i (i = 1, 2, 3, 4, 5). For it, the proposed SMs have been determined from S to S i (i = 1, 2, 3, 4, 5) and are represented in Table 1. From the discussion given in Table 1 the similarity degree between S and S5 is the greatest one as obtained by all SMs. So as stated by the principle of the maximum degree of similarity all SMs allocate the unknown pattern S to the known pattern S5.
The vector similarity measures (VSMs) between S
i
(i = 1, 2, 3, 4, 5) and S
The vector similarity measures (VSMs) between S i (i = 1, 2, 3, 4, 5) and S
If we suppose the weight vectors of x k (k = 1, 2, 3, 4, 5) are 0.5, 0.5, 0.2, 0.3 and 0.4 respectively. Then we find the proposed SMs also represented in Table 2. From the discussion given in Table 2 the WSMs between S and S5 is the greatest one as obtained by all SMs. So as stated by the principle of the maximum degree of similarity all SMs allocate the unknown pattern S to the known pattern S5.
The weighted vector similarity measures (WVSMs) between S i (i = 1, 2, 3, 4, 5) and S
The graphical representation of VSMs between S i (i = 1, 2, 3, 4, 5) and S is shown in Fig. 1. The graphical representation of WVSMs between S i (i = 1, 2, 3, 4, 5) and S is shown in Fig. 2.
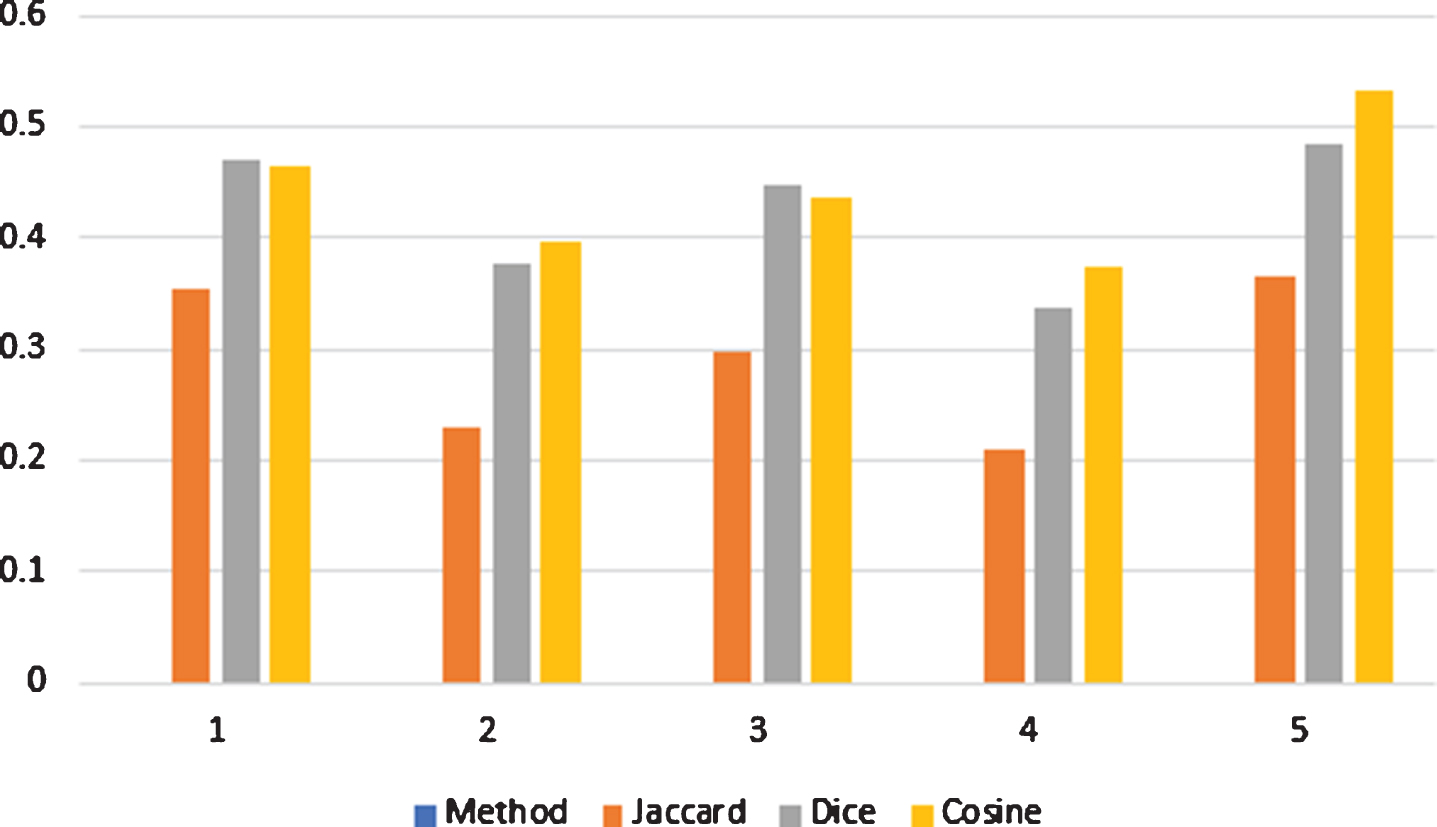
Graphical representation of the proposed measures, which is given in table 1.
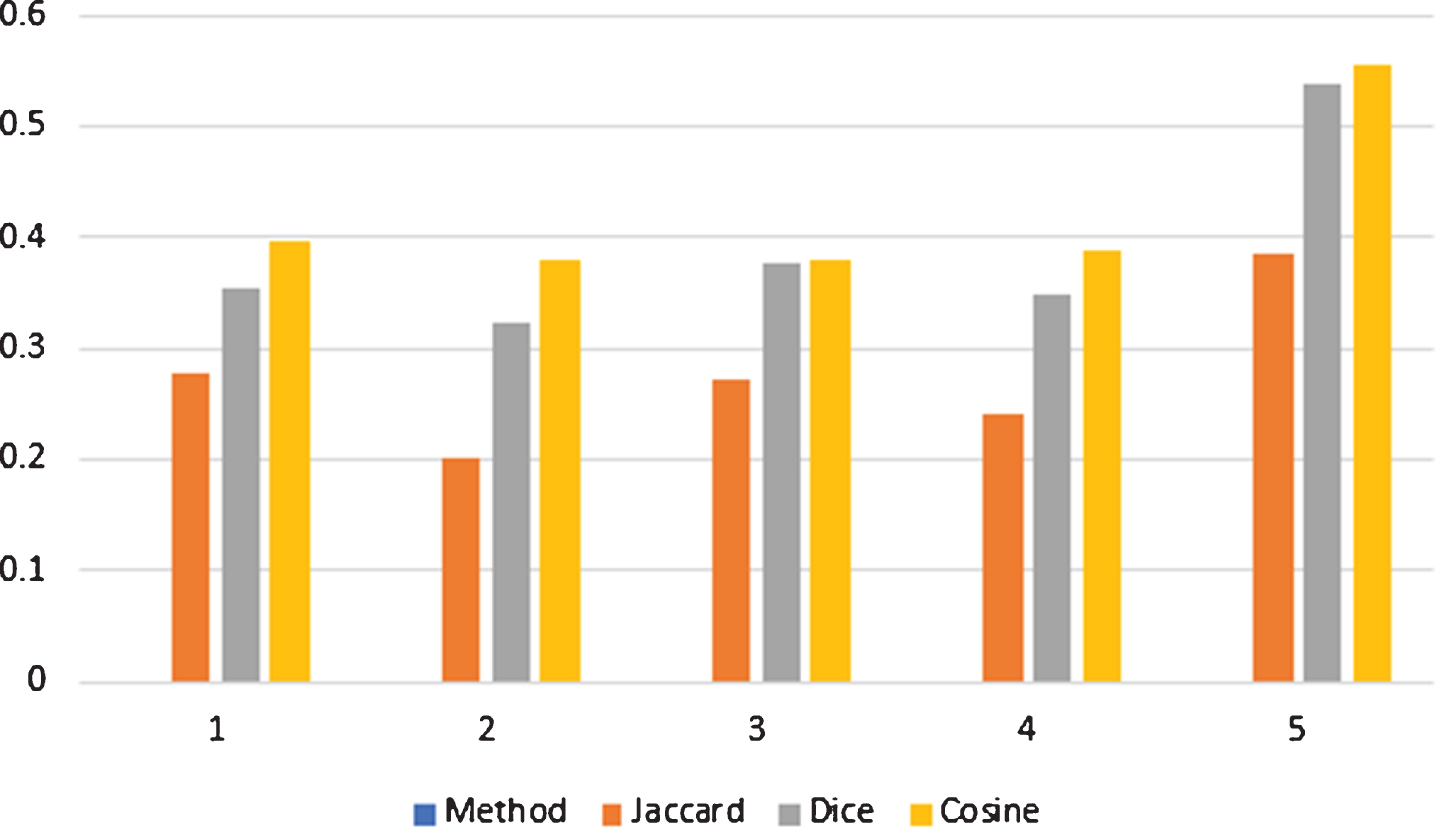
Graphical representation of the proposed measures, which is given in table 2.
In this sub-section, a modified algorithm for medical diagnosis is designed, which is improved based on Xiao’s algorithm [33]. The new algorithm utilizes the complex hesitant fuzzy similarity and distance measures which obtain excellent results in application.
Then we will find, which kind of diseases have of the which patient. The information related to this problems are given in example 6, which is discussed is below.
Each diagnoses D
i
(1, 2, 3, 4, 5) can represented as CHFSs according to the all symptoms are given below
The cause of this issue is to arrange the pattern P in one of classes D i (i = 1, 2, 3, 4, 5). For it, the proposed SMs have been determined from P to D i (i = 1, 2, 3, 4, 5) and are represented in Table 3. From the discussion given in Table 3 the similarity degree between P and D5 is the greatest one as obtained by all SMs. So as stated by the principle of the maximum degree of similarity all SMs allocate the unknown pattern P to the known pattern D5.
The vector similarity measures (VSMs) between D
i
(i = 1, 2, 3, 4, 5) and P
The vector similarity measures (VSMs) between D i (i = 1, 2, 3, 4, 5) and P
If we suppose the weight vectors of x k (k = 1, 2, 3, 4, 5) are 0.02, 0.08, 0.1, 0.3 and 0.5 respectively. Then we find the proposed SMs also represented in Table 4. From the discussion given in Table 4 the WSMs between D and D5 is the greatest one as obtained by all SMs. So as stated by the principle of the maximum degree of similarity all SMs allocate the unknown pattern P to the known pattern D5.
The weighted vector similarity measures (WVSMs) between D i (i = 1, 2, 3, 4, 5) and P
The graphical representation of VSMs between D i (i = 1, 2, 3, 4, 5) and P is shown in Fig. 3. The graphical representation of WVSMs between D i (i = 1, 2, 3, 4, 5) and P is shown in Fig. 4.
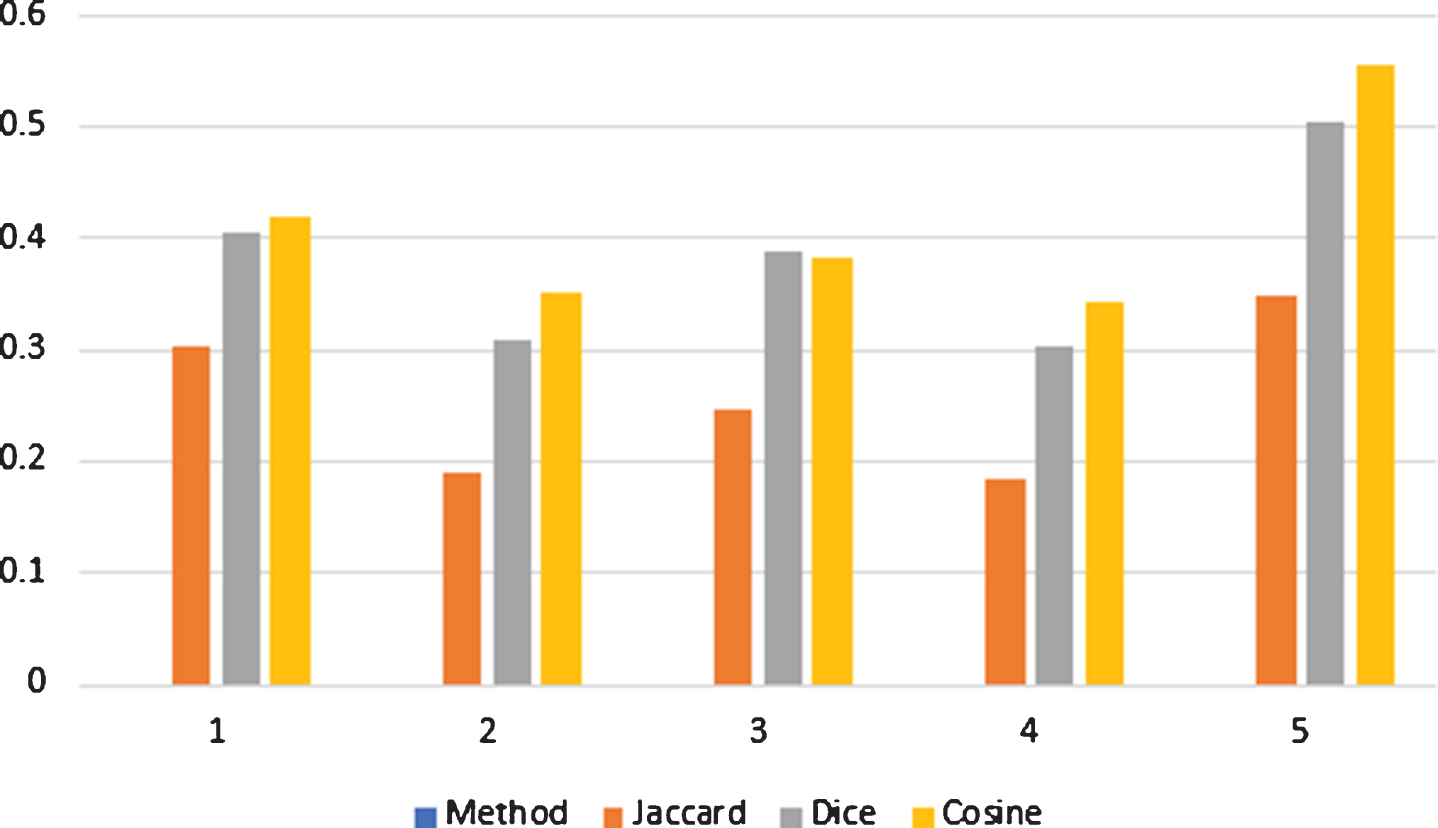
Graphical representation of the proposed measures, which is given in table 3.
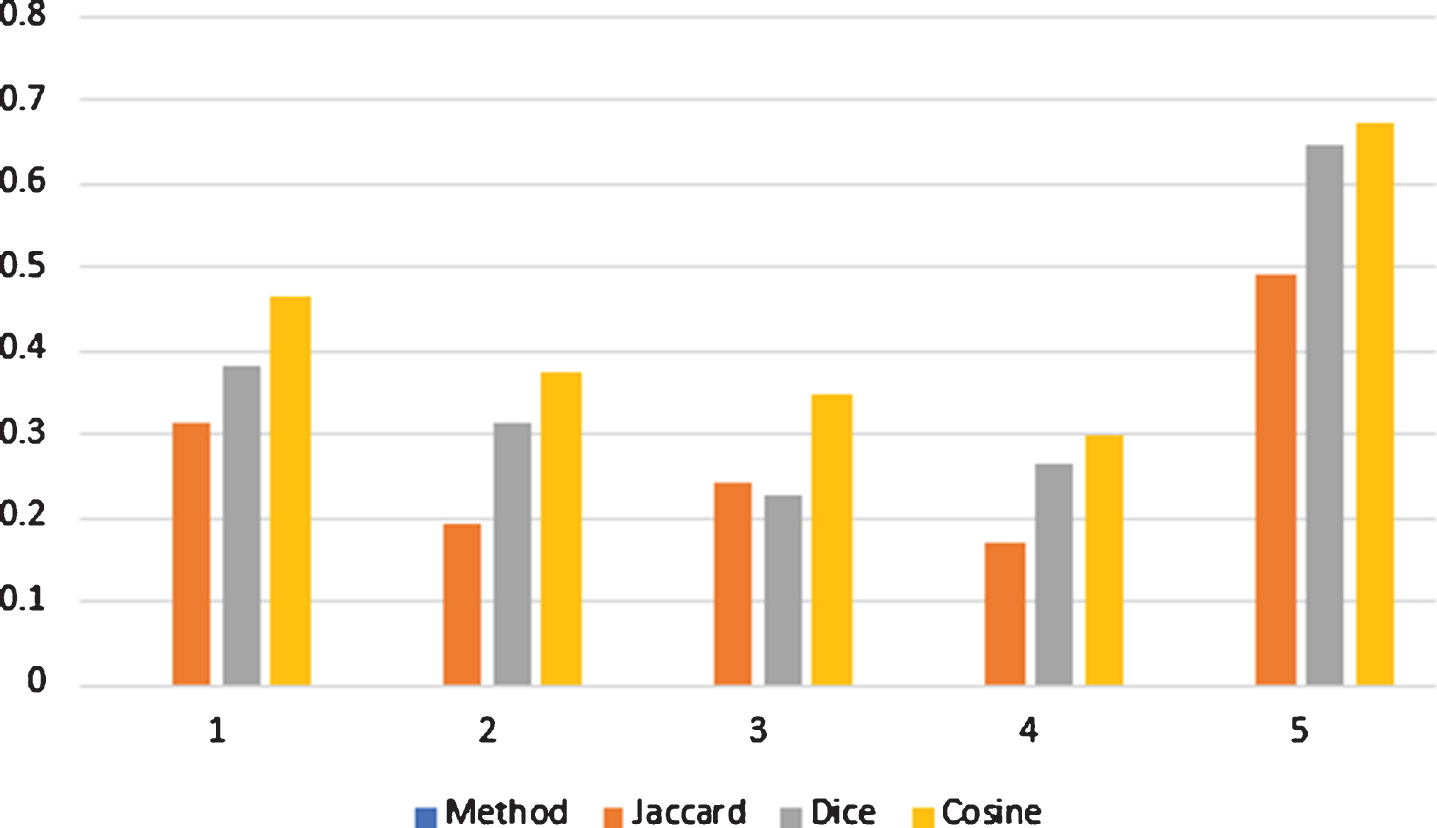
Graphical representation of the proposed measures, which is given in table 4.
Our newly proposed methods aim to develop the concept which deal with the new type of information such as CHFS and also handle the existing concepts such as FS, CFS, HFS. In this section we showed the effectiveness of our proposed work by comparing with existing methods.
Next suppose an unknown pattern
As e0 = 1 so the above value transformed into CHFSs as follows
And
The comparison results between the proposed SMs and existing SMs for example 7 are given in Table 5. We noted that the data of example 7 is in the form HFSs so through the existing SMs for HFS we find the similarity between S and S i (i = 1, 2, 3, 4, 5). As e0 = 1 then the given data for example 7 transformed to the CHFSs and by the proposed method we find the similarity between S and S i (i = 1, 2, 3, 4, 5) as shown in Table 5.
Comparison between proposed methods and existing methods for example 7.
Comparison between proposed methods and existing methods for example 7.
The comparison results for example 5 are given in Table 6. We noted that the data of example 5 is in the form of CHFSs and the existing methods are incapable of this type of data. The ranking order for example 5 and 6 is same. The SM between S and S5 is greatest in all SMs.
Comparison between proposed methods and existing methods for example 5.
Despite the fact that HFSs theory has been fortunately put in in different field, but in Some practical problems which occurs in real world the HFS cannot described effectively. For coping such type of problems the CHFSs is a powerful tool to describe the complication and uncertainty in real decision problem. CHFSs are the enlargement of CFSs and HFSs. The CHFS is described by membership grade which is a finite subset of a complex-valued membership grades belonging to unit disc in complex plan. On some occasions, CHFS solves the problems that HFS and CFS are not able to solve, which designates that CHFS is more dominant to manage the undetermined problems. The VSMs for HFSs are particular cases of the VSMs of CHFSs. As a result, the VSMs of CHFSs are the generalization of existing SMs, and acceptable to find an answer of the real-decision problem precisely than the drawbacks.
The graphical comparison between proposed methods and existing methods for example 5 is shown in figure in Fig. 5 and graphical comparison between proposed methods and existing methods for example 7 is shown in Fig. 6.
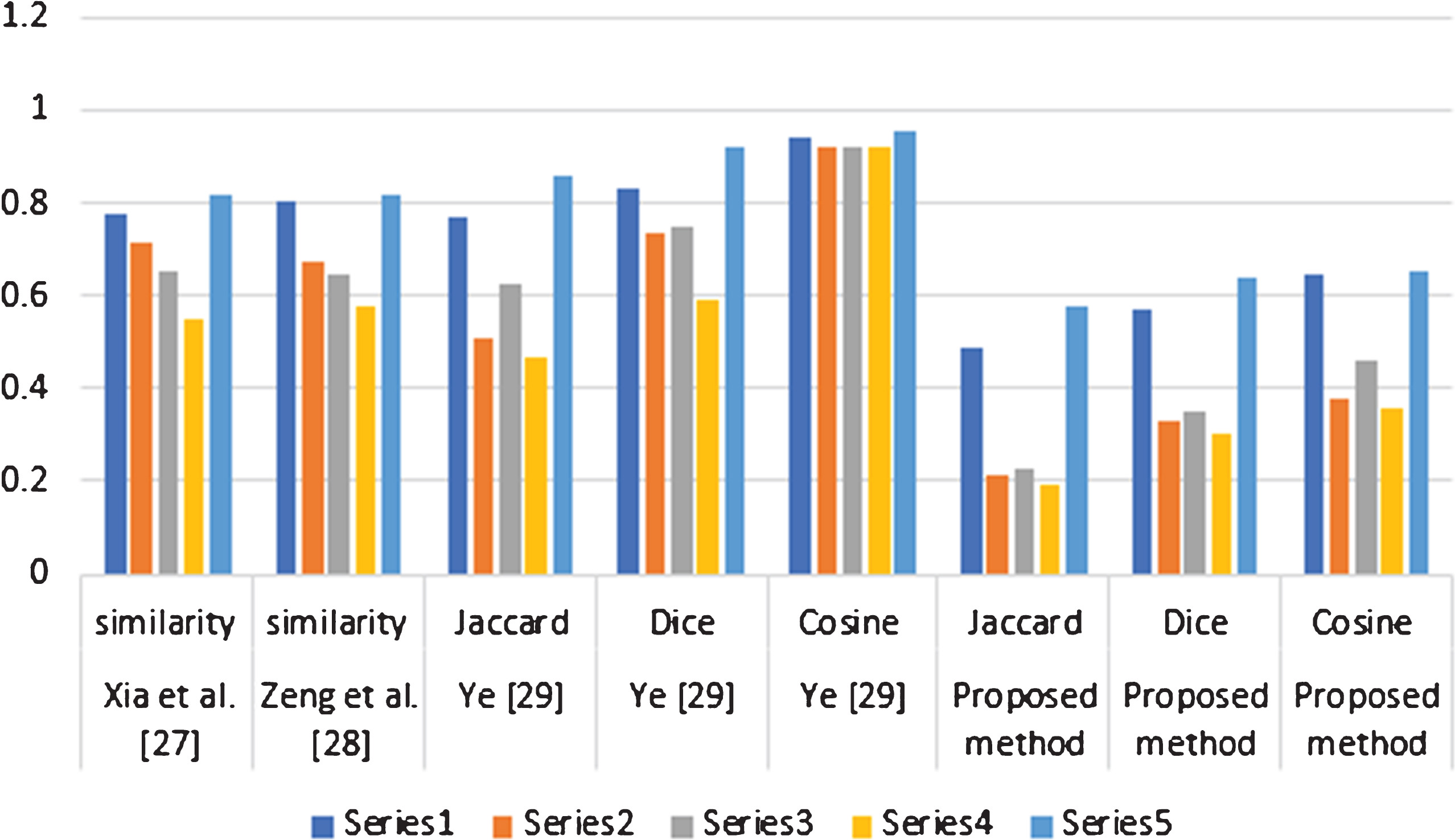
Graphical representation of the proposed measures with existing measures, which is given in table 5.
Graphical representation of the proposed measures with existing measures, which is given in table 6.
Form the above analysis it is clear that, the introduced measures based on the CHFS are more flexible and more superior than existing measures. The theoretical comparison of the explored measures and existing measures are discussed below: By choosing the values of imaginary part will be zero in the above all equation, then the introduced measures are converted it to for hesitant fuzzy sets which is discussed in ref. [27, 28]. By choosing the values of membership grades will be singleton set in the above all equation, then the introduced measures are converted it to for complex fuzzy sets. By choosing the values of imaginary part will be zero and the grade of membership will be singleton set in the above all equation, then the introduced measures are converted it to for fuzzy sets.
In this paper, we the basic idea of CHFSs and also described their basic properties. based on the explored idea, we propose a hybrid vector similarity measures, called the vector similarity measures (VSMs) such as Jaccard similarity measures (JSMs), Dice similarity measures (DSMs) and Cosine similarity measures (CSMs) for CHFSs are discussed. The special cases of the proposed measures are also discussed. The proposed measures can produce intuitive results and its feasibility is proven by comparing with the existing measures. In addition to this, the new method has more even change trend and better performance when the CHFSs have larger hesitancy. In addition, we then apply the new algorithm to pattern recognition and medical diagnosis and get the desired effect. The new algorithm has better resolution, which is helpful to ruling thresholds in practical applications. Consequently, the main contributions of this article are as follows: A method to express the CHFS in the form of polar coordinates belonging to unit disc in a complex plane is proposed, which is the first time to establish a link between them. A hybrid vector similarity measures, called the vector similarity measures (VSMs) such as Jaccard similarity measures (JSMs), Dice similarity measures (DSMs) and Cosine similarity measures (CSMs) for CHFSs are discussed. The special cases of the proposed measures are also discussed. By combing the notion of HFS and CFS is to explore the notion of CHFS is more powerful resolution and even more of a change trend than existing methods. A modified medical diagnosis algorithm is proposed based on Xiao et al. [33] method, which utilized the weighted summation to magnify the resolution of algorithm and increase the influence of conflicted data. The hybrid vector similarity measures and the modified algorithm both have satisfying performance in the applications of pattern recognition and medical diagnosis. It is well known that medical diagnosis is not a 100% accurate procedure and uncertainty is always present in cases. Though we get a definite result in Example 6 by the proposed algorithm, more cases are supposed to be examined in further research to get a safer result.
As a result, the measures in this paper can be used in a wider range of applications. Future research will extend the present work to consider the following two facts: (1) aggregation operators [34–39]. (2) methods [40], which will be more flexible for future directs.