
Abstract
Since label noise can hurt the performance of supervised learning (SL), how to train a good classifier to deal with label noise is an emerging and meaningful topic in machine learning field. Although many related methods have been proposed and achieved promising performance, they have the following drawbacks: (1) They can lead to data waste and even performance degradation if the mislabeled instances are removed; and (2) the negative effect of the extremely mislabeled instances cannot be completely eliminated. To address these problems, we propose a novel method based on the capped ℓ1 norm and a graph-based regularizer to deal with label noise. In the proposed algorithm, we utilize the capped ℓ1 norm instead of the ℓ1 norm. The used norm can inherit the advantage of the ℓ1 norm, which is robust to label noise to some extent. Moreover, the capped ℓ1 norm can adaptively find extremely mislabeled instances and eliminate the corresponding negative influence. Additionally, the proposed algorithm makes full use of the mislabeled instances under the graph-based framework. It can avoid wasting collected instance information. The solution of our algorithm can be achieved through an iterative optimization approach. We report the experimental results on several UCI datasets that include both binary and multi-class problems. The results verified the effectiveness of the proposed algorithm in comparison to existing state-of-the-art classification methods.
Introduction
Past decades have witnessed the success of supervised learning (SL) in machine learning field [7, 47]. SL is an effective tool to learn a classifier, and has been applied in various practical tasks, such as image classification [5, 52], emotion classification [53], and speech recognition [46]. In general, SL attempts to train a desired classifier from a labeled dataset. Many methods have been proposed for SL, including the k-Nearest Neighbor (k-NN), naive Bayes [11], support vector machine (SVM) [9, 45], AdaBoost [12, 38], regularized least squares classification (RLSC) [39], and kernel minimum squared error (KMSE) [17].
Among these SL methods, RLSC is commonly used because it can be easily solved and obtain promising performance. Xue et al. [49] discovered a local discriminative structure by building intra-class and inter-class graphs, and used the structure to develop discriminatively RLSC (DRLSC). From the reported results conducted on image recognition, DRLSC achieved better performance than the other graph-based learning methods. Different from the above approach, Gan et al. [18] utilized the second-order statistical magnitude of margin distribution to improve the generalization ability, and proposed generalized RLSC. The results showed that a large margin mean and small margin variance were beneficial and crucial to the performance improvement.
In fact, RLSC and its variants are ultimately a kind of SL. As we know, the performance of SL depends heavily on the quality of labeled training instances. However, collecting the instance labels is time-consuming and expensive. Moreover, reliable labels are not easily obtained because labeling experts may be fatigued and inexperienced. In such cases, the instances can be mislabeled by the experts [34]. Additionally, there is an increasing interest in using crowdsourcing, such as the Amazon Mechanical Turk [2, 33]. However, such an approach may lead to instances being mislabeled by the nonexperts. As one can imagine, such label noise can have a severe negative impact on the performance of the trained classifier [13]. Many related methods [6, 50] have been proposed and achieved promising performance. Generally speaking, these methods can be cast into two categories [15, 36]: (1) identifying and removing/correcting the mislabeled instances; and (2) training a robust classifier to label noise.
The first category attempts to improve the quality of the labeled instances through a preprocessing step. In this step, the mislabeled instances are firstly recognized through different strategies and then removed or corrected. Tu [43] designed a noisy label detection method by using density peak clustering [40]. The mislabeled instances were identified through local density and then removed. Bhadra and Hein [4] utilized a mutual consistency approach to identify and correct noisy labels, and introduced two effective strategies to solve the optimization problem. Meanwhile, Smith and Martinez [42] proposed PReprocessing Instances that Should be Misclassified (PRISM), which used different heuristics measures to remove the mislabeled instances. Experimental results showed that PRISM could improve both the quality of training instances and the classification performance. Zhang et al. [50] introduced adaptive voting noise correction (AVNC) to find and correct the mislabeled instances. Their experimental results verified the effectiveness, especially under the situation where each instance had more than one noisy label. Although these methods could improve performance in some scenarios, they might remove so many instances and thus waste instance information. In some cases, the mislabeled instances might be even erroneously corrected, which can lead to performance degradation.
The second category tries to modify the objective function to achieve robustness to label noise. Manwani [32] investigated the behaviors of different loss functions on label noise. Experimental analyses showed that risk minimization under a 0-1 loss function could yield promising noise-tolerance performance. Ghosh [20] provided a deeper theoretical analysis than the literature [32]. It proved that the loss function that satisfied some sufficient conditions could be robust under uniform and non-uniform label noise, such as 0-1 loss, Sigmoid loss, and so on. Additionally, Ghosh [19] attempted to find an appropriate loss function for deep learning. It showed that the loss function based on the mean absolute value of error was inherently robust to label noise. Liu [31] developed an improved kernel minimum square error classification (IKMSE) by minimizing an ℓ21-norm regularizer on the decision coefficient. IKMSE could reduce the negative influence of outliers. Similarly, Li [27] proposed an ℓ21-norm-based extreme learning machine (LR21-ELM) to decrease the harmful effect of mislabeled instances. Gong [21] aimed at learning a transductive classifier by penalizing an ℓ0 norm on the graph to filter out the mislabeled instances. For outliers with large residues, Jiang [23] introduced the capped ℓ1 norm to learn a robust dictionary [1, 28]. In order to effectively deal with the extremely mislabeled instances, Nie [37] presented the capped ℓ p -norm SVM (CappedSVM) to improve learning performance. Nevertheless, the negative effect of the extremely mislabeled instances could not be completely eliminated and the instance information was neglected and not fully discovered.
In order to completely eliminate the negative effect and avoid the information waste of the extremely mislabeled instances, we propose a capped ℓ1-norm RLSC method (i.e., CRLSC) based on a graph-based regularizer. In the proposed algorithm, we use the capped ℓ1 norm to modify the objective function of RLSC. The capped ℓ1 norm can adaptively find the extremely mislabeled instances and completely eliminate the corresponding negative influence. In order to avoid information waste and improve classification performance, we build a graph-based regularization term to exploit the mislabeled instances. Finally, we utilize an iterative optimization strategy to solve the optimization problem.
The organization of this paper is as follows. We give a review of related work in Section 2. Section 3 discusses the details of the proposed algorithm. The results from experiments conducted on several UCI datasets are reported in Section 4. Finally, we present a conclusion and directions for future work in Section 5.
Background knowledge
Regularized Least Squares Classification (RLSC)
Because RLSC [39] is easy to solve and can yield comparable performance to other SL methods (e.g., SVM, KMSE), it has become a useful technique in the machine learning field. Formally, suppose a c-class training dataset
According to the representer theorem [3], the classifier f (x) can be represented as
We then substitute Eq. (2) into Eq. (1) and achieve the following OP:
where
The above OP can be easily solved by matrix analysis. By taking the derivative of
The goal of CappedSVM [37] is to learn a linear model w
T
x + b that can be robust to label noise. In order to realize this goal, CappedSVM defines the objective function as follows:
CappedSVM utilizes a re-weighted method to solve the OP. The objective function of CappedSVM is then rewritten as below:
When M is fixed, CappedSVM can obtain the following solution:
When w and b are fixed, the solution of M is given as
In the experimental section of [37], the value of ɛ is set by selecting the 10% instances with the largest loss in the first five iterations. For a fair comparison, p of CappedSVM in our experiments is fixed to 1.
In this section, we will discuss the formulation and solution of the proposed algorithm.
Motivation
In some situations, the user may collect mislabeled instances because of inexperience or fatigue. Some existing methods attempt to identify and remove the mislabeled instances. However, this will result in data waste. As shown in Fig. 1, if the mislabeled instances are identified and removed, classification performance can be degraded. Hence, the mislabeled instances are considered as unlabeled ones by ignoring the labels and discovered by a graph-based regularizer in our algorithm.
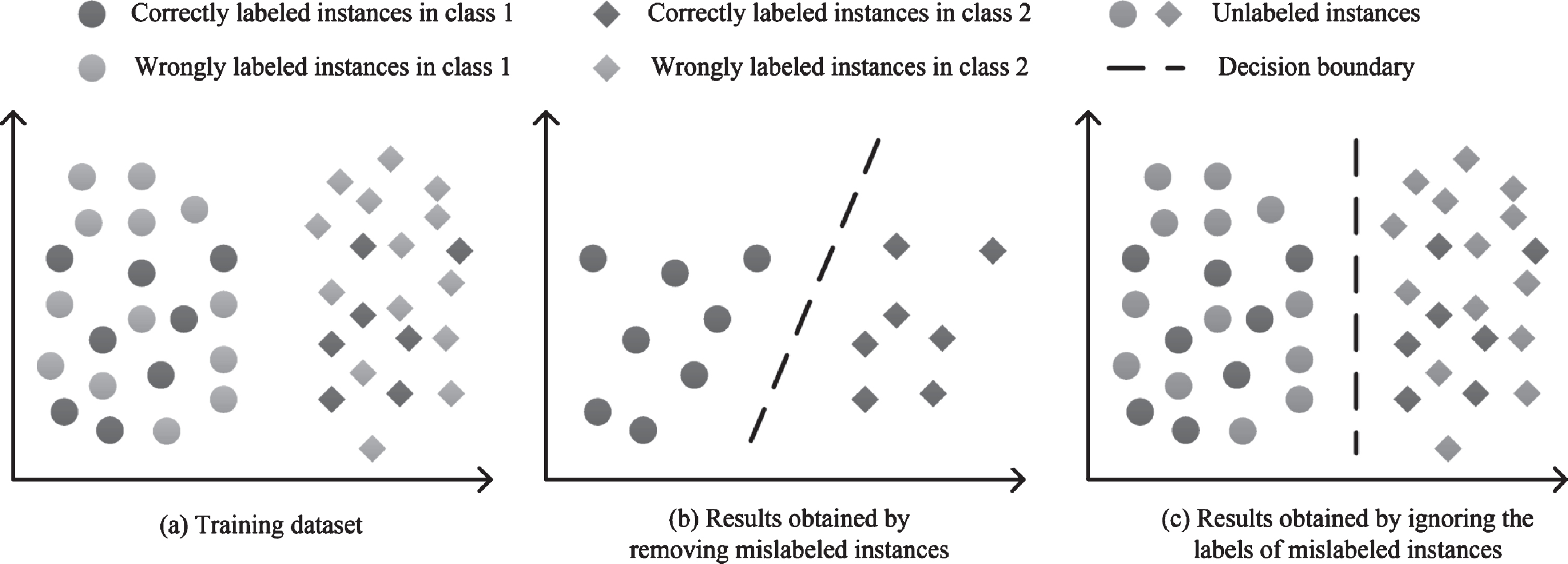
The motivation of the proposed algorithm. (a) A training dataset with noisy labels. (b) Results if the mislabeled instances are identified and removed. (c) Results if the mislabeled instances are exploited through a graph-based framework by ignoring the corresponding label information.
Additionally, the ℓ2 and ℓ1-norm loss functions are not robust enough to the label noise. As shown in Fig. 2, the loss can be infinite if the instances are not correctly classified. However, the capped ℓ1-norm loss reaches a maximum that is related to ɛ. This means that the negative effect of the extremely mislabeled instances with very large loss can be reduced.
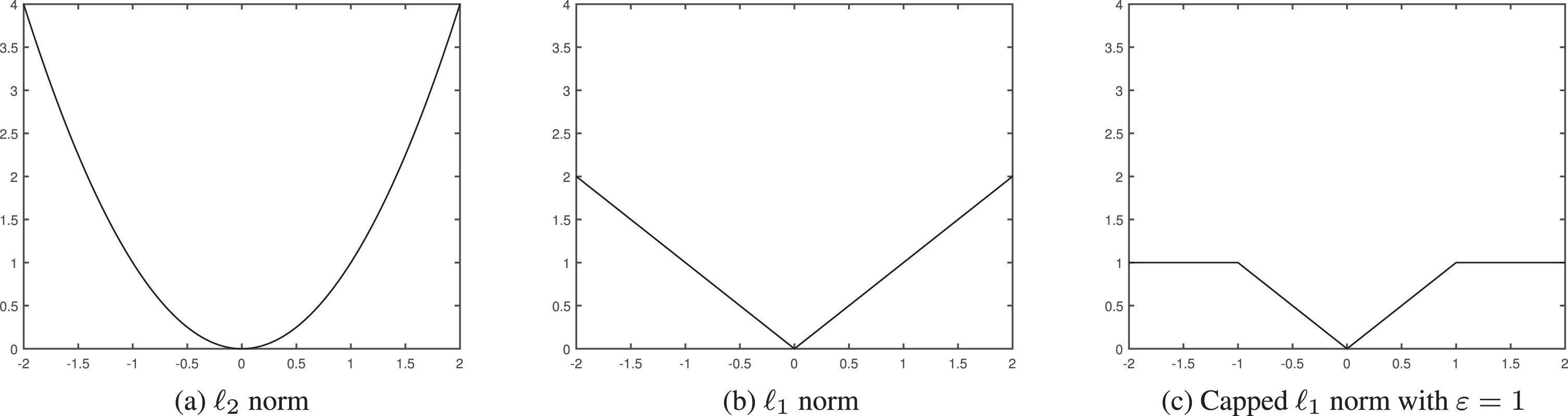
The illustrations of different loss functions.
According to the above analysis, we employ the capped ℓ1 norm to substitute for the ℓ2 norm in RLSC. Meanwhile, the instances that are likely to be mislabeled are explored through the graph-based regularization term.
Firstly, we build a p-nearest neighbor graph W as follows:
where N p (x i ) is a subset composed of p nearest neighbors of x i , and τ is a parameter.
Then, the graph-based regularization term can be written as
Finally, we have the following objective function of our algorithm:
where ɛ is a threshold parameter.
Since the above OP in the proposed algorithm is non-convex, it is difficult to solve. In this paper, we introduce an effective iterative optimization strategy as shown in [37]. The OP in Eq. (13) can be transformed as follows:
where R = diag ([r1, ⋯ , r
l
]) and
Jiang et al. [23] has proved that the OP in Eq. (132) will converge to the optimal solution of OP in Eq. (13). Hence, we have the following iterative process.
1) Update f (x) when r i is fixed.
Based on the representer theorem, the OP in Eq. (132) can be rewritten as follows:
By setting the derivative of
2) Update r i when f (x) is fixed.
r i can be computed according to Eq. (15).
By iteratively computing Eq. (17) and Eq. (15), we can achieve the optimal solution α*. The flow chart is shown in Fig. 3. The details of the proposed algorithm are given in Algorithm 1. Because the sequence of objective function values obtained by our algorithm is non-negative and decreases monotonically, i.e.,
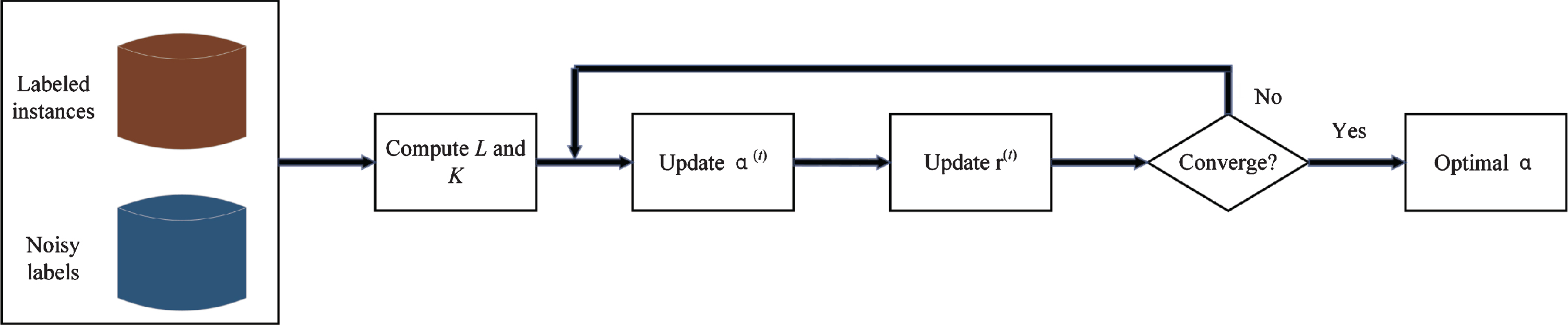
Flow chart of the proposed algorithm.
Compute the graph Laplacian L and the Gram matrix K;
Set
Update α(t) through Eq. (17);
Update
A toy experiment
We firstly conduct an experiment over a toy dataset (i.e., Fig. 4(a)). The dataset has 600 instances and is generated through a Gaussian distribution with a unit covariance matrix. The mean is (2, -2) for Class 1 and (-2, -2) for Class -1. Thirty instances are mislabeled and denoted as red rectangles in Fig. 4(b). The classification results obtained by RLSC and CRLSC are respectively reported in Figs. 4(c) and (d). From these figures, one can see that the instances on the left side of the ideal boundary are easily mislabeled by RLSC. However, CRLSC can achieve the desired results. Moreover, the weights of some extremely mislabeled instances are zeros, as shown in Fig. 4(d); this verifies the effectiveness of the capped ℓ1 norm.
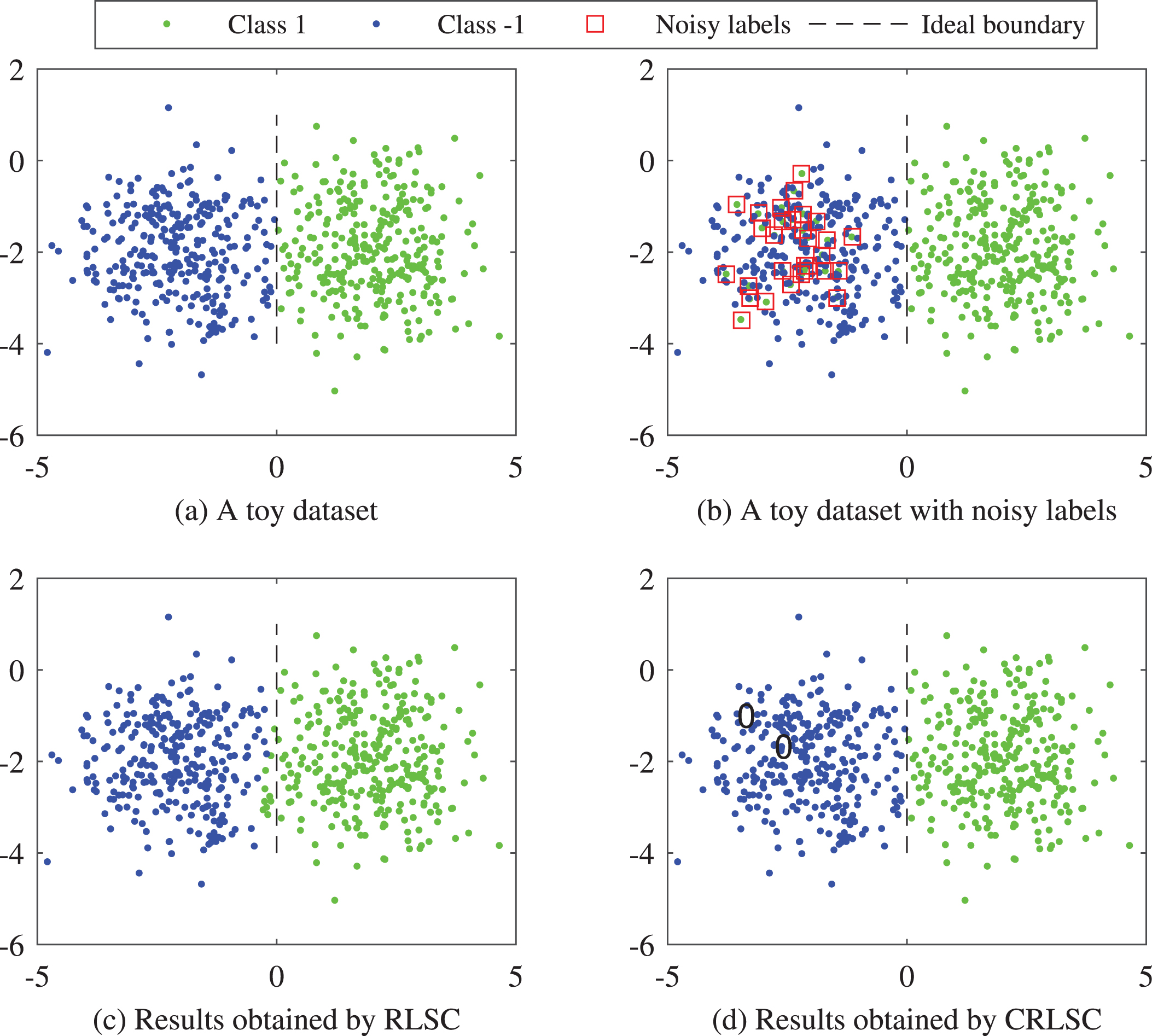
Performance comparison over the toy dataset.
In this subsection, some experiments are carried out on 12 datasets selected from UCI [14]. The statistical information of the datasets is shown in Table 1. In the experiments, 70% of each dataset is used to constitute the training subset and the rest is used as the testing subset. Because the proposed algorithm is designed to deal with label noise, the training subset is contaminated, which means that the given labels are inconsistent with the true labels. The percentage of label noise is selected from 0% to 30% with a step size of 5%. The following state-of-the-art classification methods are used for performance comparisons.
Information regarding the datasets
Information regarding the datasets
In the experiments, the parameter γ for RLSC, KMSE, IKMSE and our algorithm is set to 10-4. The parameter ɛ for our algorithm is set to 90% of the largest loss in each iteration. η in CappedSVM and our algorithm is set through 5-fold cross validation, and the candidate value is {10-4, 10-3, 10-2, 10-1, 1, 10, 102, 103, 104}. The Gaussian kernel width σ for computing the Gram matrix K is determined through 5-fold cross validation from a set {2-4, 2-3, 2-2, 2-1, 1, 2, 22, 23, 24} δ in which δ is the average distance between the instances.
The results are shown in Figs. 5 and 6. From these figures, we can reach the following conclusions: Compared to the other methods, 1-NN obtains the worst performance overall on all datasets. This demonstrates that 1-NN is very sensitive to label noise and that it has the worst stability. If the percentage of label noise is fixed to 0%, CRLSC can obtain comparable, if not better, results than the other methods. Especially, the proposed algorithm can outperform the other methods on the New_thyroid, Sonar, Vehicle, and Water datasets. The reason for this may be that there are other types of noise on these datasets, such as outliers. These results show that the proposed algorithm can deal with such other types of noise to some extent. As the percentage of label noise increases, the performance of all methods decreases. This confirms that label noise can hurt the performance of a trained classifier. The performance of CRLSC and CappedSVM decreases at the slowest pace as the percentage of label noise changes. Therefore, the capped norm is more robust to label noise, and the effectiveness of the proposed algorithm is verified. CRLSC with η = 0 can perform better than CRLSC with the ℓ1 norm and η = 0 in most cases, such as on Dermatology, Ionosphere, and New_thyroid datasets. This means that the capped ℓ1 norm is more robust to label noise than the ℓ1 norm. CRLSC generally outperforms CRLSC with the ℓ1 norm and η = 0 and CRLSC with η = 0. This finding further verifies the effectiveness of the strategy using the graph-based technique to exploit the mislabeled instances.
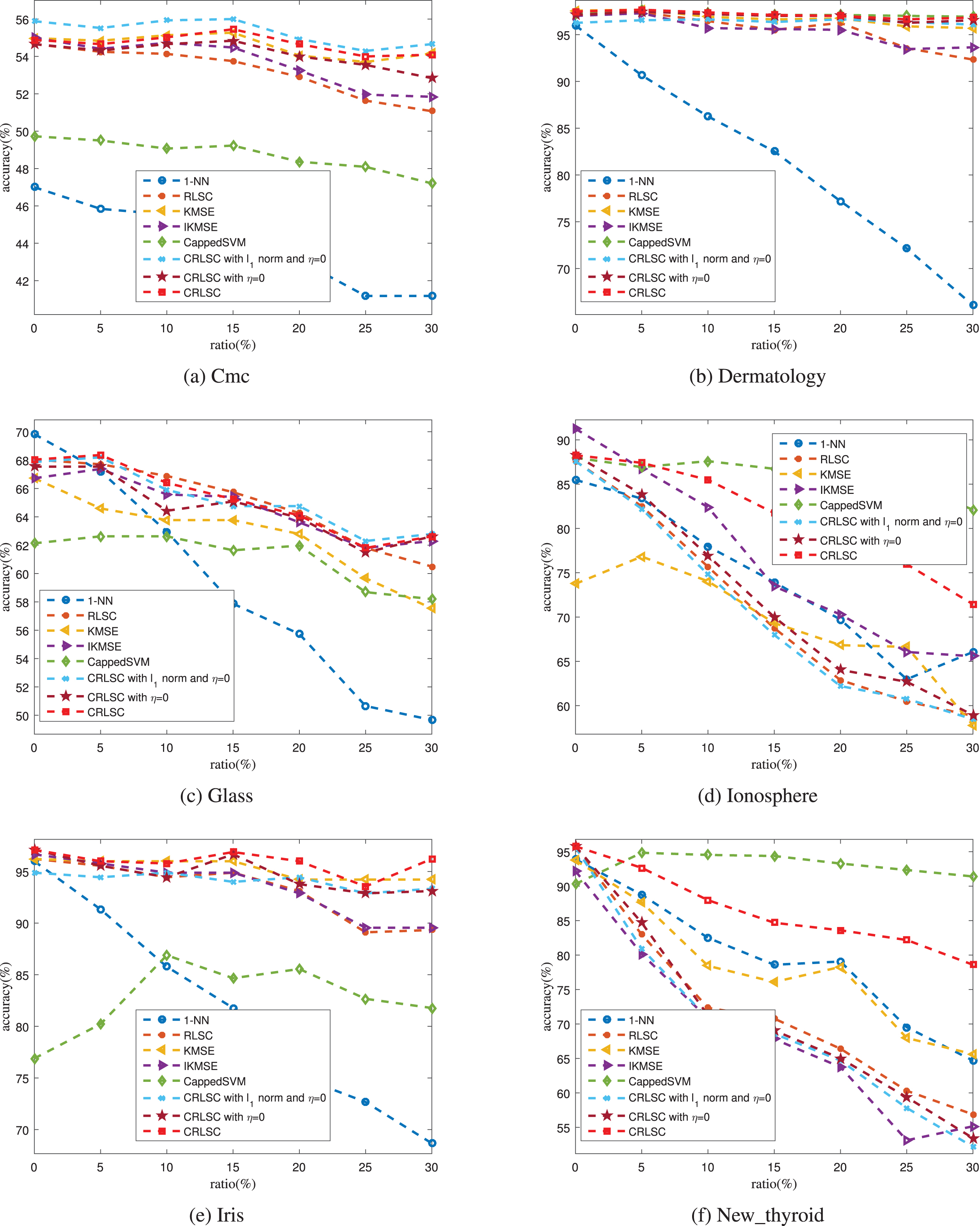
Performance comparison of different methods over the first six datasets.
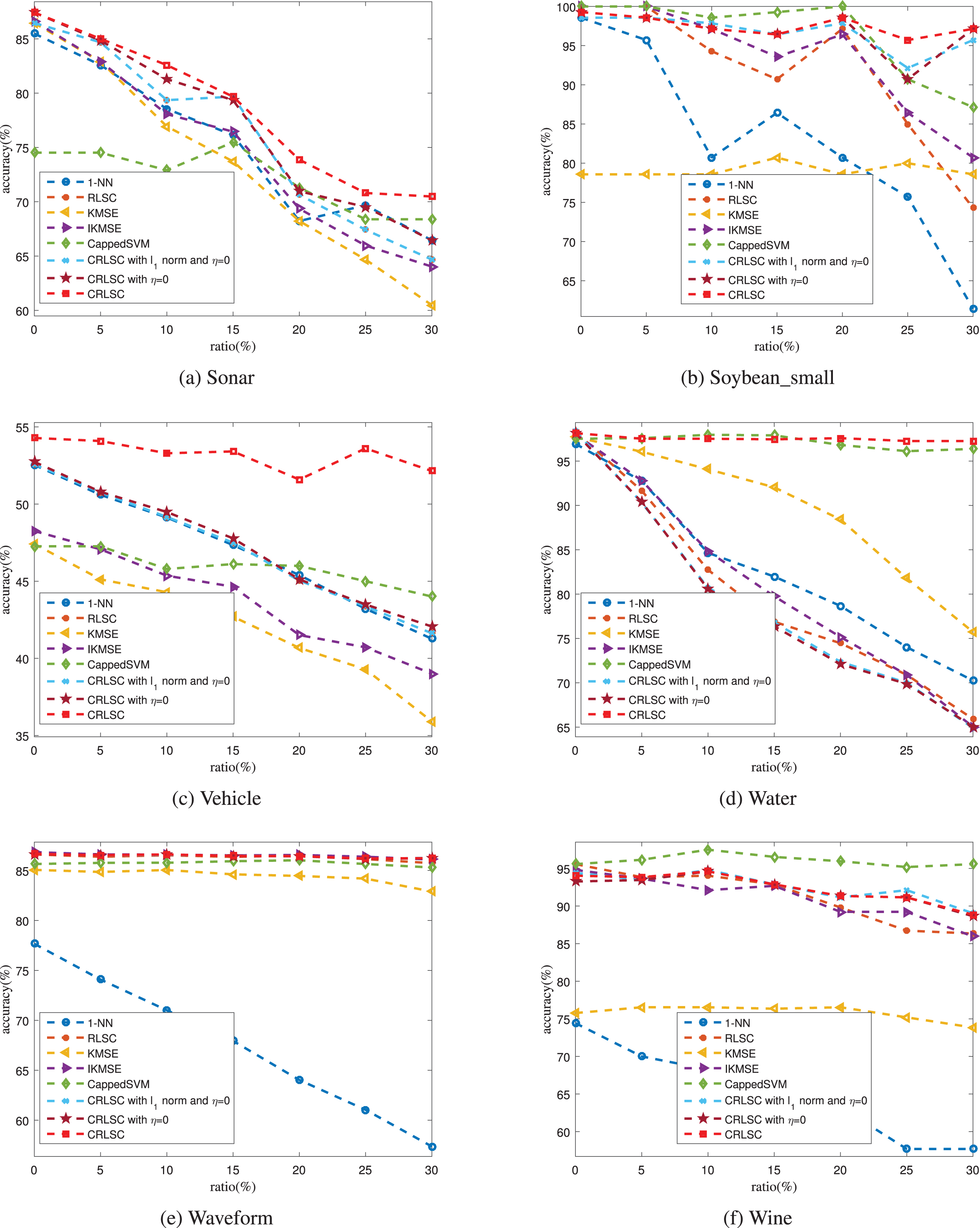
Performance comparison of different methods over the latter six datasets.
Furthermore, we conduct a performance analysis with different parameter settings. Since ɛ was set through a heuristic strategy, we conduct the experiments under different values of η. The analysis plots are shown in Figs. 7 and 8. From these figures, we know that the best performance can be achieved under a small value of η when the noise ratio is 0%. It is because the labeled instances are mainly discovered through the first fidelity term in the objective function. Meanwhile, as the ratio increases, the proposed algorithm often obtains the best performance when the value of η is large; this is especially obvious on the Ionosphere, New_thyroid, Vehicle, and Water datasets when the ratio is 30%. The reason for this may be that the mislabeled instances have large loss and are discovered through the last graph-based term to guarantee the performance. Moreover, the performance of the proposed algorithm on the Waveform dataset is not sensitive to label noise (see Fig. 6(e)). Hence, the performance with different values of η is similar when the noise percentage changes (Fig. 8(e)).
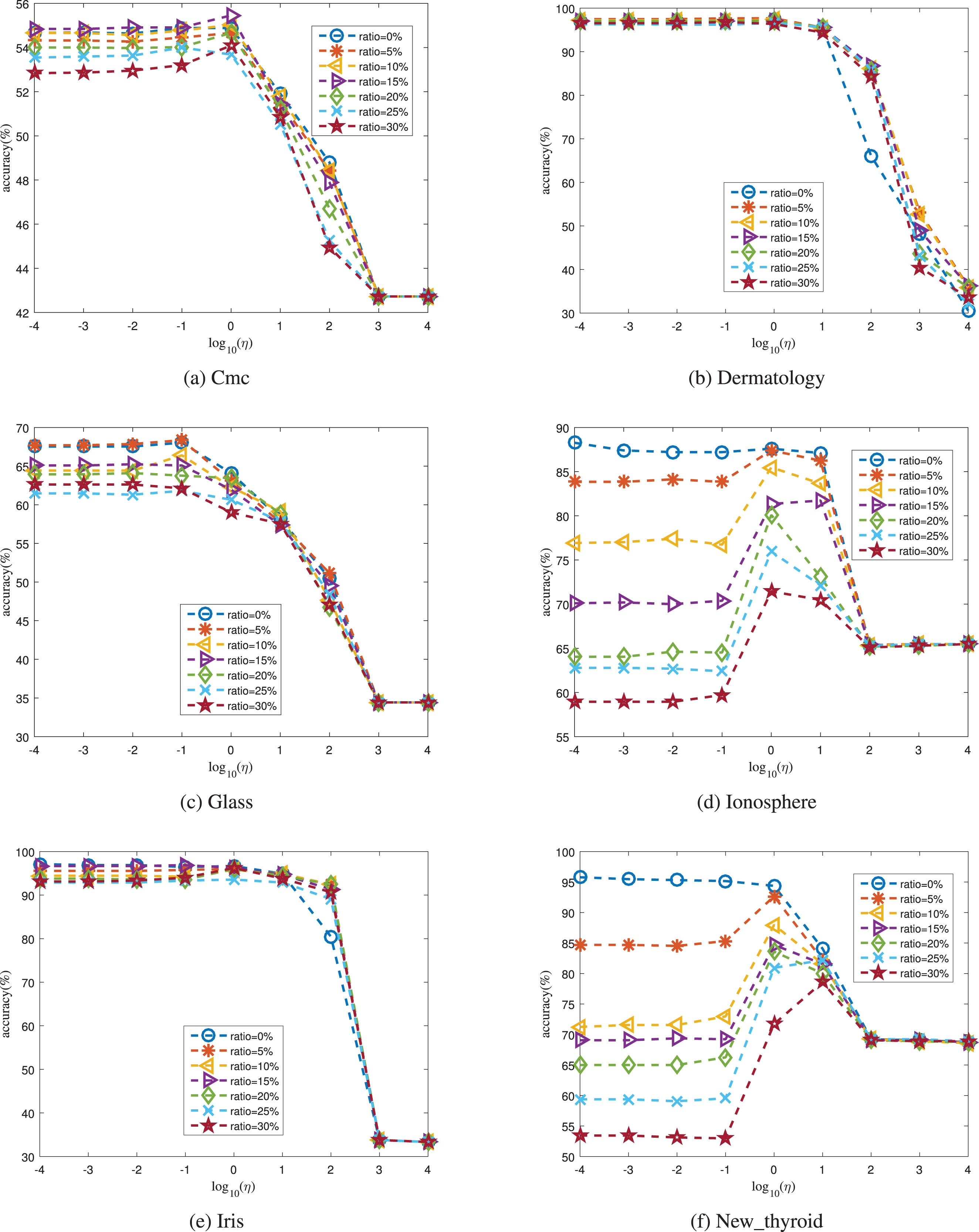
Performance with different values of η over the first six datasets.
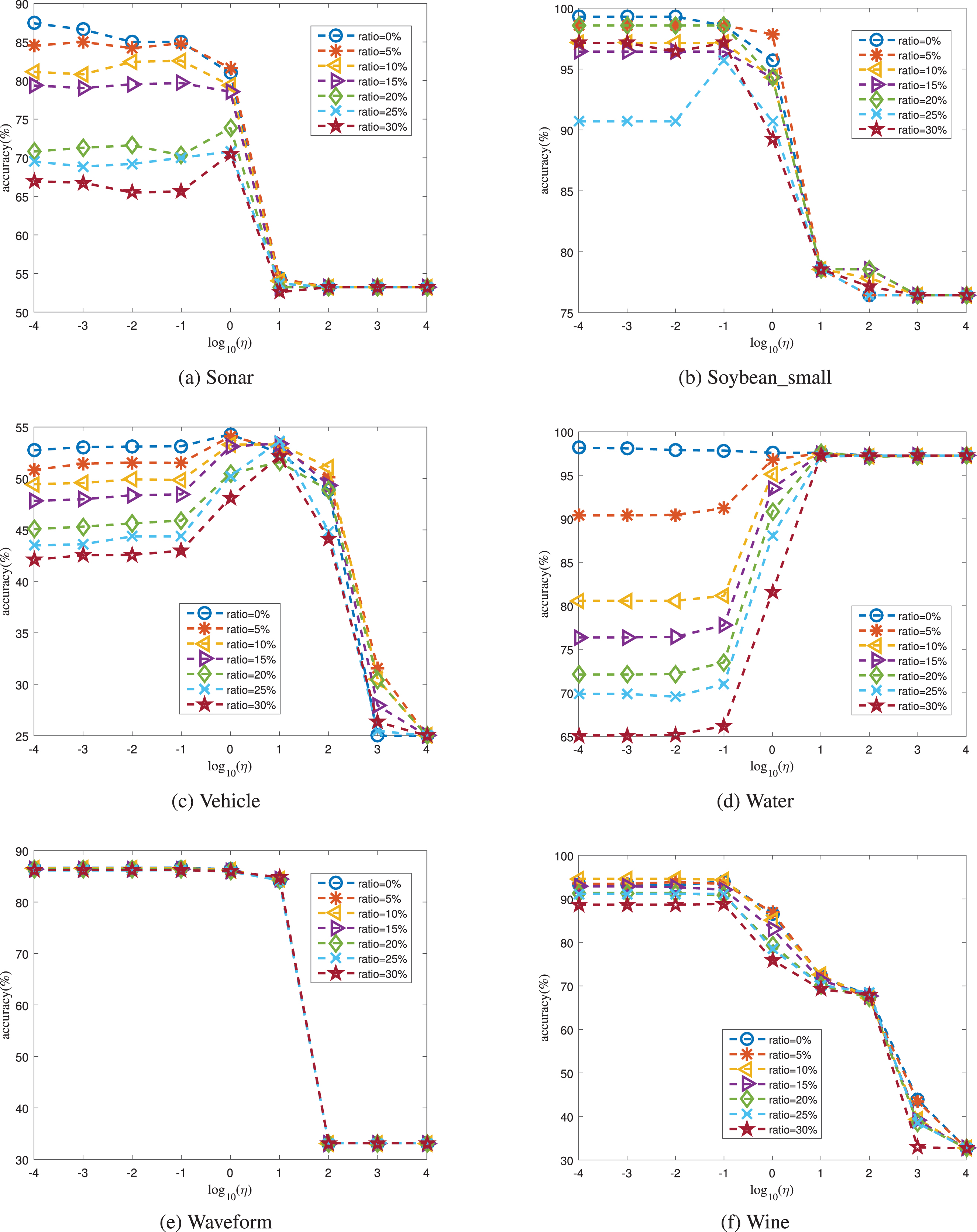
Performance with different values of η over the latter six datasets.
Finally, we present the convergence over different datasets in Fig. 9. From these plots, we can find that our algorithm can converge fast, thus demonstrating the effectiveness of the optimization method used in our algorithm.
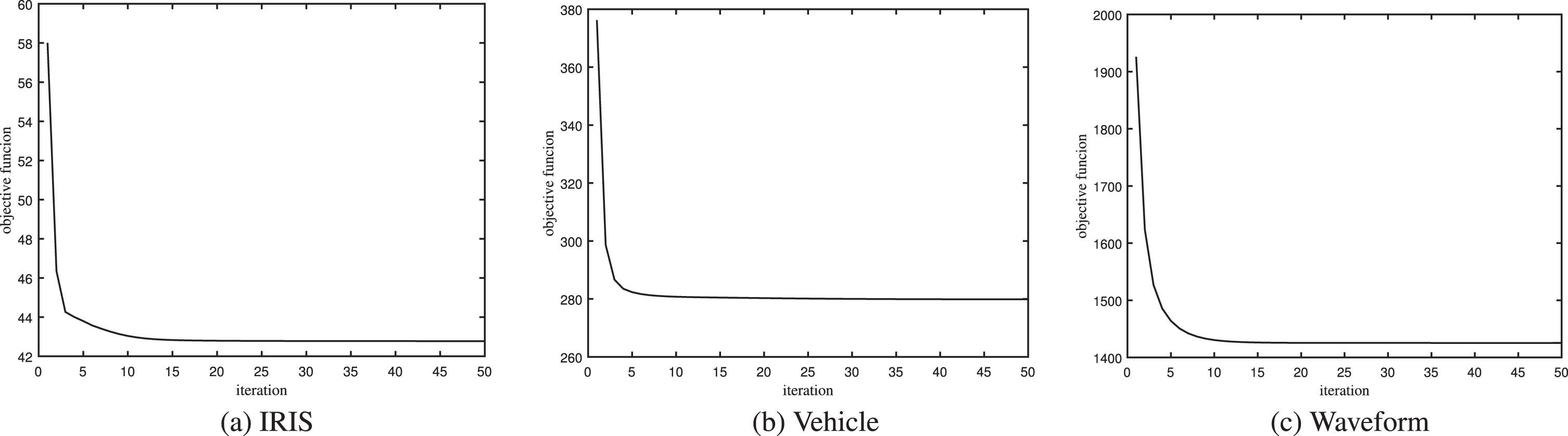
Illustrations of the iterative procedure.
In this paper, we propose a novel classification method to deal with label noise. The proposed algorithm utilizes the capped ℓ1 norm to alleviate the negative influence of label noise. Moreover, the instances that satisfy ||f (x i ) - y i ||2 > ɛ may be the extremely mislabeled ones and exploited by the graph-based approach to avoid wasting instance information. Our experimental results verify the feasibility and usefulness of the proposed algorithm. Further analysis reveals that our algorithm is robust to outliers to some extent. Therefore, our algorithm can extend the practicability of the trained classifier. However, this work mainly focuses on the label noise. In future work, we will try to simultaneously deal with different types of noise, such as outlier and feature noise.
Footnotes
Acknowledgment
This work is supported by the Doctoral Scientific Research Foundation of Hubei University of Technology under grant No. BSQD2015026, the National Natural Science Foundation of China under grant No. 61601162, the Doctoral Scientific Research Foundation of Wuhan Institute of Technology under grant No. K201905, and the Research Project of Hubei Provincial Department of Education under grant No. Q20191510, B2019041.