
Abstract
The characterization of electrical demand patterns for aggregated customers is considered as an important aspect for system operators or electrical load aggregators to analyze their behavior. The variation in electrical demand among two consecutive time intervals is dependent on various factors such as, lifestyle of customers, weather conditions, type and time of use of appliances and ambient temperature. This paper proposes an improved methodology for probabilistic characterization of aggregate demand while considering different demand aggregation levels and averaging time step durations. At first, a probabilistic model based on Weibull distribution combined with generalized regression neural networks (GRNN) is developed to extract the inter-temporal behavior of demand variations and, then, this information is used to regenerate aggregate demand patterns. Average Mean Absolute Percentage Error (AMAPE) is used as a statistical indicator to assess the accuracy and effectiveness of proposed probabilistic modeling approach. The results have demonstrated that the performance of proposed approach is better in comparison with an existing Beta distribution-based method to characterize aggregate electrical demand patterns.
Keywords
Introduction
The characterization of electrical demand for an aggregate of customers such as loading on Distribution Transformers (DTs) is critical for understanding the collective behavior of customers. Inter-temporal evaluation of demand patterns demonstrates variable and uncertain behavior of customers which could follow a certain trend at one time and may be flexible at the other time of the day. In addition to this, characterization of residential customers is a challenging task due to their diverse energy usage behavior during different times of the day. Variations in residential customers demand patterns depend on their lifestyle, types and usage time of appliances and seasonal effects [1].
In general, at DT level, industrial and commercial loads are considered as an individual load while residential loads are fed at different aggregation levels. The contribution of each of them is informative for system operators or electrical load aggregators to study the time evolution of power flow, voltage profile and network losses. Moreover, inter-temporal characterization of residential customers demand is useful for determining the impact of Distributed Energy Resources (DERs) on different aspects of distribution system operation such as Demand Side Management (DSM) [2]. The information extracted from aggregate demand patterns can also be used for devising time based and specific incentive based tariffs related to each group of customers [3]. Furthermore, time step duration and customers’ aggregation are important parameters that may effect on characterization related to their energy usage behavior [4].
In addition, inter-temporal characterization of electrical demand with varying time step duration and different aggregation levels is an important aspect to extract accurate information regarding customer behavior [4–7].
In literature, Artificial Neural Network (ANN) has widely been used for characterization of different complex processes, including its application to identify material properties under diverse conditions [8], soil classification [9], biomedical data and image processing [10] etc. ANN based approaches have also been employed for characterization of demand patterns, but these techniques do not provide statistical relationship between input and output variables [11, 12]. Auto Regressive Integrated Moving Average (ARIMA) based techniques are used for time series analysis [13] but they are time consuming, less efficient, less adaptable and have no structural interpretation towards nonlinear series [14, 15]. Moreover, different probability distributions are also used to model the uncertainties of demand patterns. Beta distribution-based characterization methodology for aggregate residential customers has been presented in [16]. However, in comparison to Beta distribution, other probability distribution techniques such as Gamma & Weibull may perform better for uncertainty modeling [17, 18]. In [19], electricity consumption of different households was estimated by fitting the probability distribution function of Weibull, Rayleigh, Lognormal, Gamma and Inverse Gaussian distribution. The results showed that the Weibull’s probability distribution function provided the best fitting estimation.
Moreover, behavior of residential customers for electrical energy consumption is highly uncertain, therefore, Weibull distribution can be used to model inter-temporal electrical demand uncertainties.
In this paper, a model based on the Weibull probability distribution is developed to characterize inter-temporal behavior for an aggregate of residential customers with different averaging time step durations and, then, this model is used to generate different scenarios based on the estimated characteristics. A moving window-based technique is opted to extract aggregate demand data patterns for estimation of Weibull distribution parameters. These parameters are calculated for each time step duration, which provide inter-temporal variations of aggregated demand patterns. The estimated inter-temporal parameters are then used to generate different scenarios that represent the characteristics of the reference dataset of the aggregated residential customers. Goodness of fit (GOF) assessment indicators such as average mean absolute percentage error (AMAPE) and its variance are used to validate the effectiveness of proposed technique.
The main contributions of this paper are: Implementation of Weibull distribution as a substitute of Beta distribution to model inter-temporal characteristics of aggregate demand patterns. Application of Generalized Regression Neural Network (GRNN) to achieve continuity of Weibull distribution parameters. GRNN has better estimation accuracy in comparison with other techniques [20, 21].
This paper is organized as: Section 2 describes data arrangement and mathematical framework of proposed modeling approach. Section 3 explains curve-fitting technique. Section 4 discusses scenario generation algorithm. Case studies are presented in Section 5, followed by the conclusion and future work suggestions.
Data organization and mathematical framework
The aggregate demand patterns of extra urban residential customers in Italy were constructed in [7] using Monte Carlo Simulations. These demand patterns are based on the characteristics of the occupants’ lifestyle, appliances they use, and time of use of appliances [7]. The aggregate demand patterns are constructed for different time step durations (1, 10, 20, 30 and 60 minutes) of a day. For example, if time step duration (Δt) equals to 1 minute then total time steps (T) are 1440. Similarly, for Δt= 10, 20, 30 and 60 minutes, time steps are T = 144, 72, 48 and 24 respectively. Residential demand patterns for different customer aggregation levels, i.e. A = 20, 50, 75 and 150 houses have been generated and discussed in [7]. For ‘O’ number of aggregate demand observations at specific Δt, data is represented in the form of matrix as given in (1).
Where rows represent different daily observations and column represents demand at a specific time step.
Different customer aggregation levels, i.e., 20, 50, 75 and 150 houses with one-minute time step duration and one hundred demand observations (O) for winter weekdays of extra urban residential customers are shown in Fig. 1. It can be noted that spread of demand data points is reduced with the increase in customers’ aggregation level. Therefore, it is more challenging to model demand variations at lower aggregations in contrast with demand uncertainties at higher aggregations.

Demand patterns with 1-minute time step duration for winter weekdays with an aggregation of (a) 20 houses (b) 50 houses (c) 75 houses (d) 150 houses.
In this proposed work, following two step strategy is used to develop a probabilistic model for characterization and generation of different aggregate demand scenarios: Probability distribution parameters are calculated for each time step linking the following time step by scanning the observations at that time step using a moving window. Different demand patterns have been generated through the estimated probability distribution parameters as calculated in the previous step. Inter-temporal probabilistic characteristics of generated demand patterns must follow the probabilistic characteristics of reference demand patterns. Inter-temporal variations of generated demand pattern have to follow the reference demand pattern variations.
The main aspects that are considered for the construction of the probabilistic model for characterization of demand patterns are:
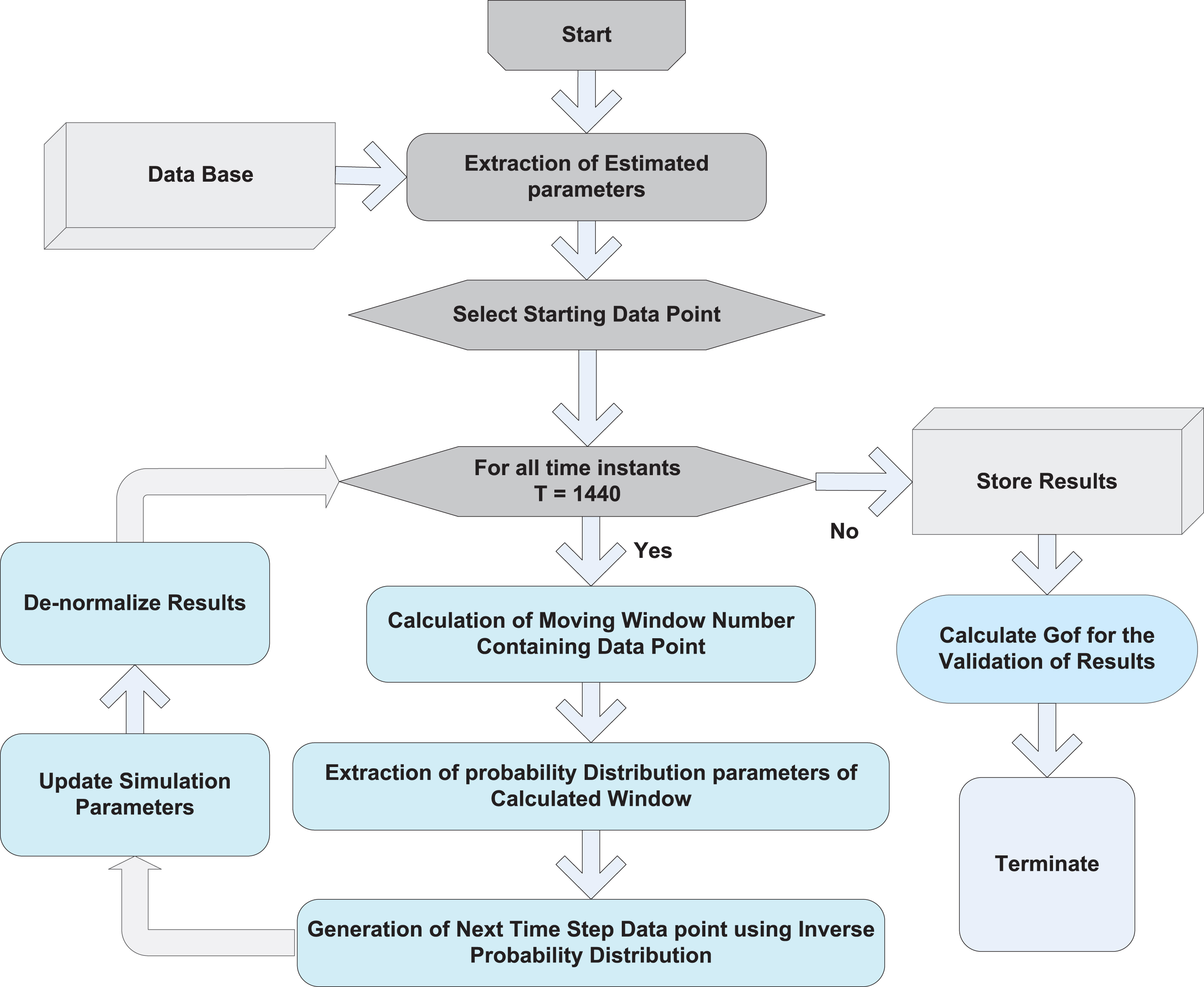
Block diagram of the proposed model for the generation of aggregate electrical demand patterns based on the estimated characteristics of reference dataset is shown in Fig. 2. This figure presents three-stage methodology for the proposed scheme. The first block outlines the procedure to extract inter-temporal change in demand characteristics using the moving window technique, which is based on Weibull distribution and GRNN. The second block depicts the generation of load pattern scenarios. The third block is about the validation part of proposed technique that uses AMAPE for calculating percentage error between reference and generated demand patterns.

Flow diagram for proposed methodology.
To scan the entire range of demand data for applying the probability distribution model, there is a need for an appropriate selection of moving window parameters. The lower and upper bounds of the electrical demand for 100 observations at any time step (t) and t = 1, 2 ... , T defines the starting and the ending point for which the moving window will operate and it is applied using 95% confidence interval of demand data to eliminate incorrect or bad data from aggregated demand patterns [16], as represented in (2) and (3).
The range of data (
The moving window of an appropriate size is selected for the extraction of demand patterns which lie inside the range. The window size can also be controlled by user defined parameter w c .
Window width ‘
Demand patterns at the next time step, i.e. t + 1, linking to the patterns lies inside the moving window of the previous time step are extracted that provides the information of probability distribution of the respective amplitude window. The size of the amplitude window is selected in such a way that it contains some meaningful number of demand points at time step ‘t’ to provide valuable information for the construction of probability distribution. Next moving step of the amplitude window in the vertical direction is calculated in such a way that it contains some portion of the previous window to provide smoothness in the variation of the probability distribution parameters. Shifting step of an amplitude window is calculated as mentioned in (6).
Where w
p
is the number of central points of an amplitude window, and it should be greater than ‘
In order to extract the reference demand patterns at specific time step ‘t’, the central point of moving window lies on lower boundary of the respective time step ‘t’. Values of demand patterns occurred inside the window size
Demand points occurred in the next time step ‘t+1’ and linked with the extracted demand patterns of time step ‘t’ are taken out and stored in vector ‘V
t
’ for specific window. An amplitude window is shifted upward by using (6). For the following step of the moving window, linking demand patterns at successive time step ‘t+1’ are extracted and stored in vector ‘Vt +1’. This process is repeated for all moving windows in vertical direction for specific time step ‘t’. For the following time step‘t+1’ same procedure is repeated for the calculation of window width‘
The above-mentioned procedure is illustrated in Fig. 3.
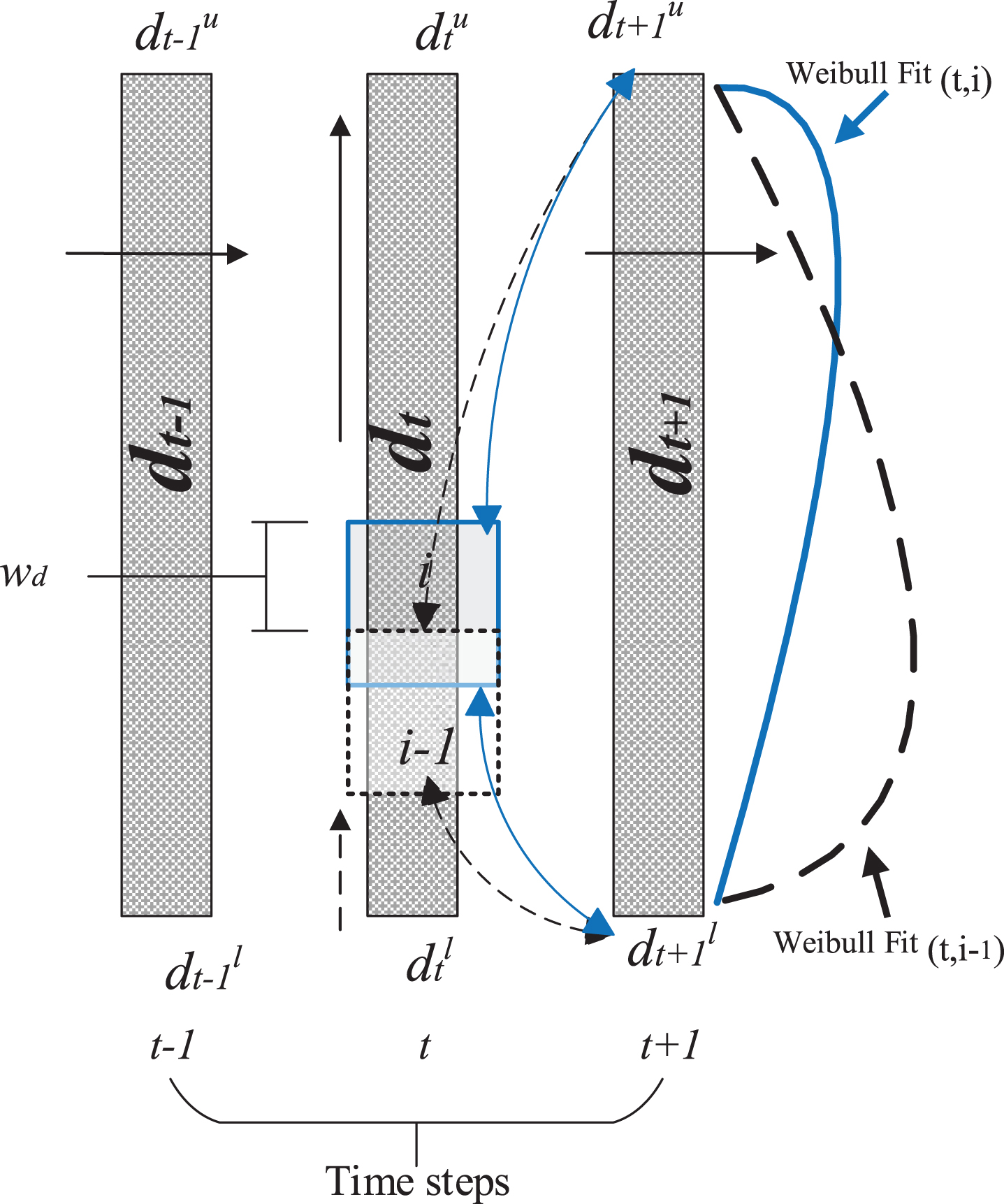
Detailed procedure for the calculation of Weibull distribution parameters.
In [16], a probabilistic approach of beta distribution was used to characterize aggregate residential demand patterns. However, due to the widespread applications of Weibull distribution for uncertainty modeling (as discussed in Section 1), we choose Weibull distribution for probabilistic characterization in this paper.
Detailed flowchart related to the procedure for the extraction of Weibull distribution parameters is shown in Fig. 4. Demand patterns placed at time step ‘t+1’ linking the demand patterns of previous time step ‘t’ occurred inside the specific moving window are extracted. For moving window ‘i’, the extracted demand points lie inside the set ‘Vt,i’ are normalized using (7) in the interval (0, 1) for the estimation of shape and scale parameters.
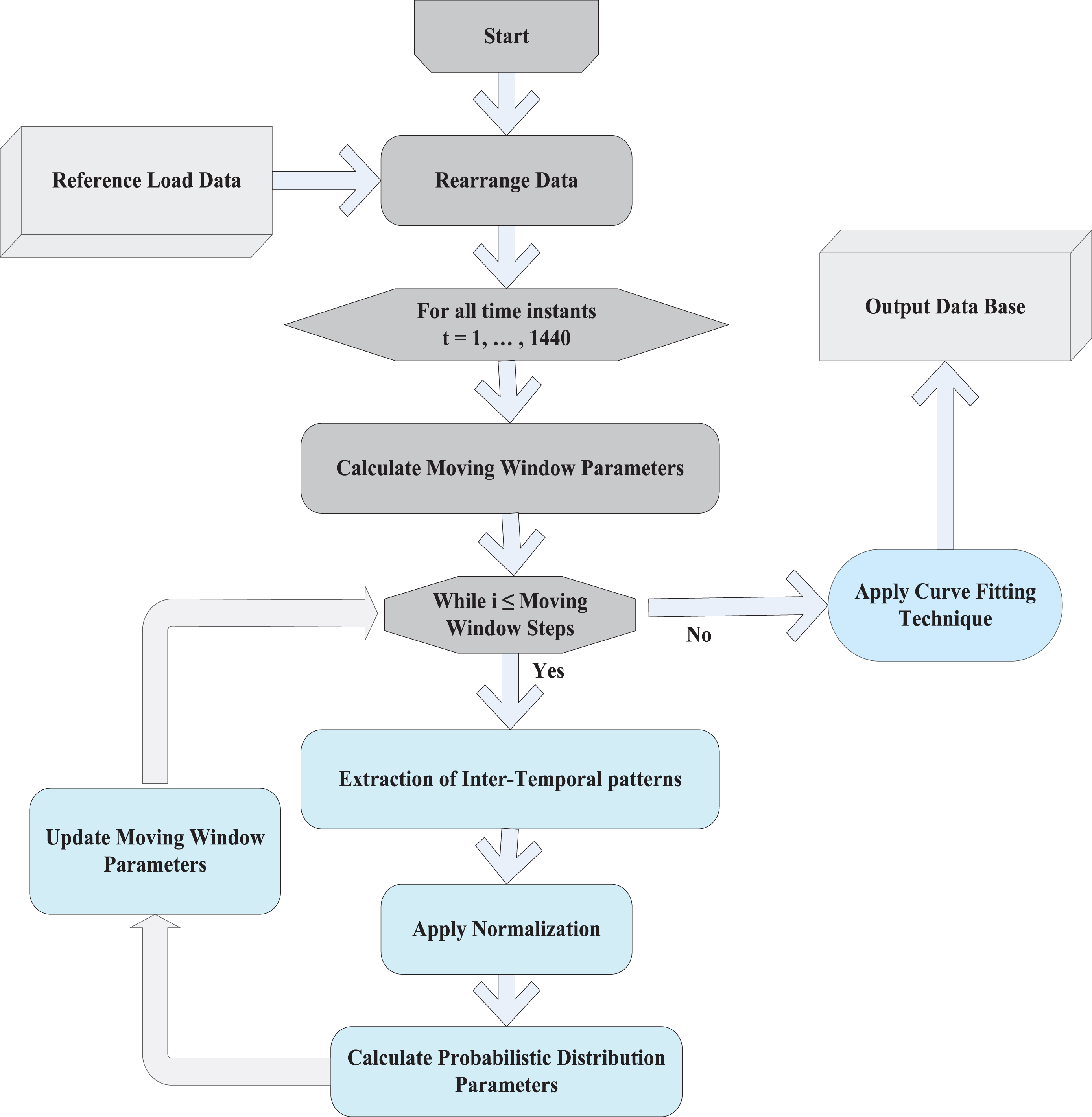
Flowchart of the algorithm for the determination of probabilistic distribution parameters.
After normalization, shape and scale parameters of Weibull distribution are estimated for all moving windows at a specific time step ‘t’, then, the same procedure is repeated for all time steps T.
The methodology presented in this subsection generates the results on discrete steps of moving window. To have continuity in the Weibull distribution parameters, we perform curve fitting between the electrical demand and the Weibull distribution parameters.
Curve fitting is a mathematical process for generating a plot that represents the discrete input data set in the continuous form. Different techniques of curve fitting have been developed which characterize the discrete input data set. Method of linear regression and arbitrage smoothing method have been discussed in [22, 23] which were used as a tool for curve fitting.
Artificial neural network is a computational model inspired by the human brain. A basic structure of artificial neural network consists of three layers: an input layer, an output layer and a middle and hidden layer consisting of a number of neurons. Each layer links with the adjacent layer through defined transfer functions. In [24], an artificial neural network has been used for curve fitting on a coarse data to accurately represent data characteristics. The proposed technique was used to predict the probability distribution curve of available coarse data and the results demonstrated that ANN perform accurately with few data points.
Generalized Regression Neural Network (GRNN)
In ANN domain, GRNN is the simplest neural network in terms of learning algorithm and network architecture. Fig. 5 shows general structure of a GRNN. In [25], performance of Back Propagation Neural Network (BPNN) and GRNN was compared and the results showed that GRNN require very less time for training and executes better results than BPNN. In [26, 27], results from GRNN and BPNN were compared and it was concluded that GRNN has high accuracy and less training time.
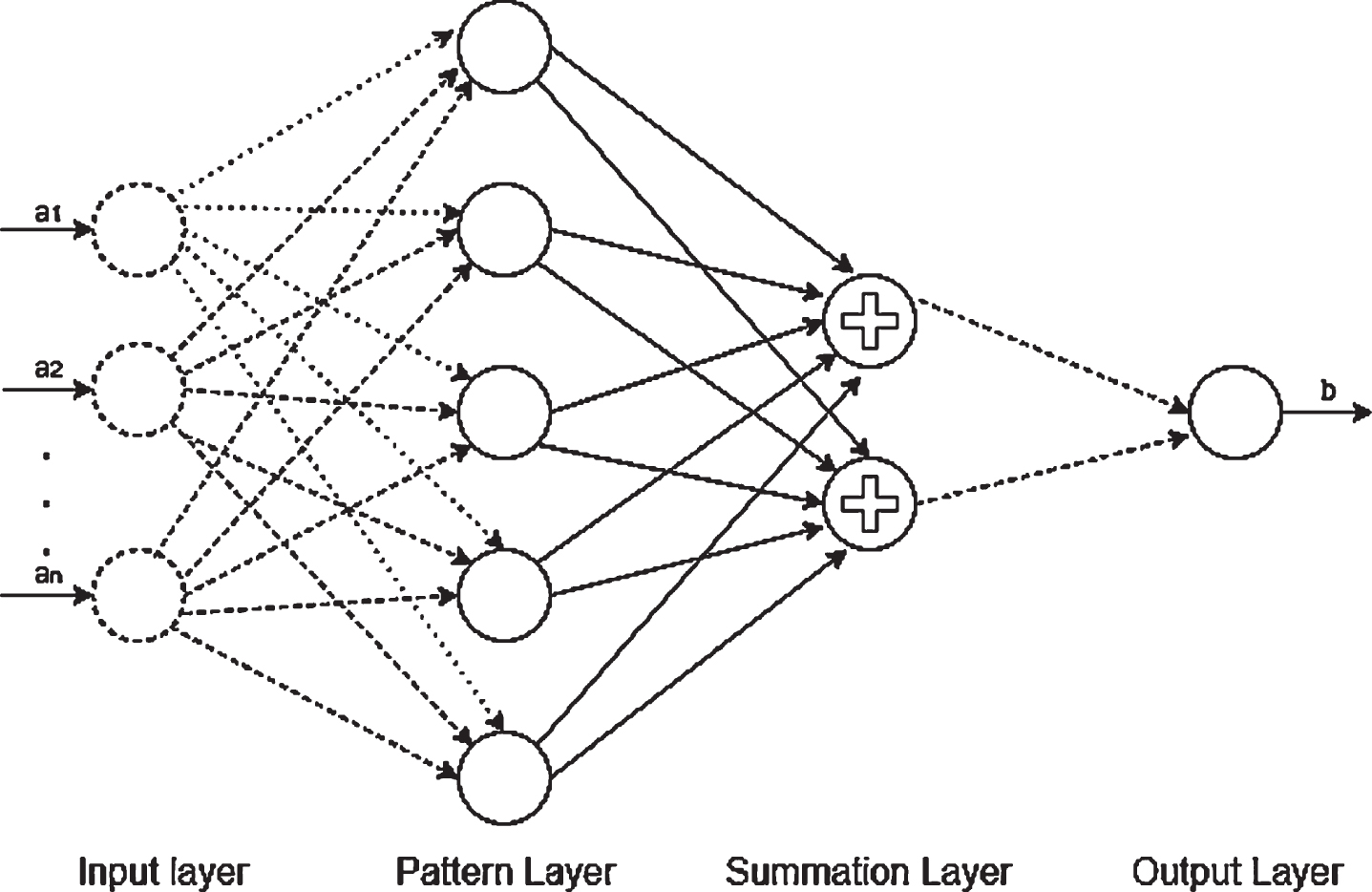
GRNN general structure.
In literature, GRNN is mostly used for for nonlinear mapping, forecasting, building a relation between inputs and outputs, estimating and self-learning application, image processing application [28, 29].
In [16], piece wise cubic hermit interpolation (PCHIP) technique was used for curve fitting. However, in this paper, GRNN is adopted for curve fitting to preserve the shape and monotonicity of the Weibull distribution scale and shape parameters due to its accuracy and effectiveness as discussed in [24, 25] and [29]. The shape and scale parameters of Weibull distribution before and after applying GRNN is shown in Fig. 6. Base formula of GRNN is given in (8).
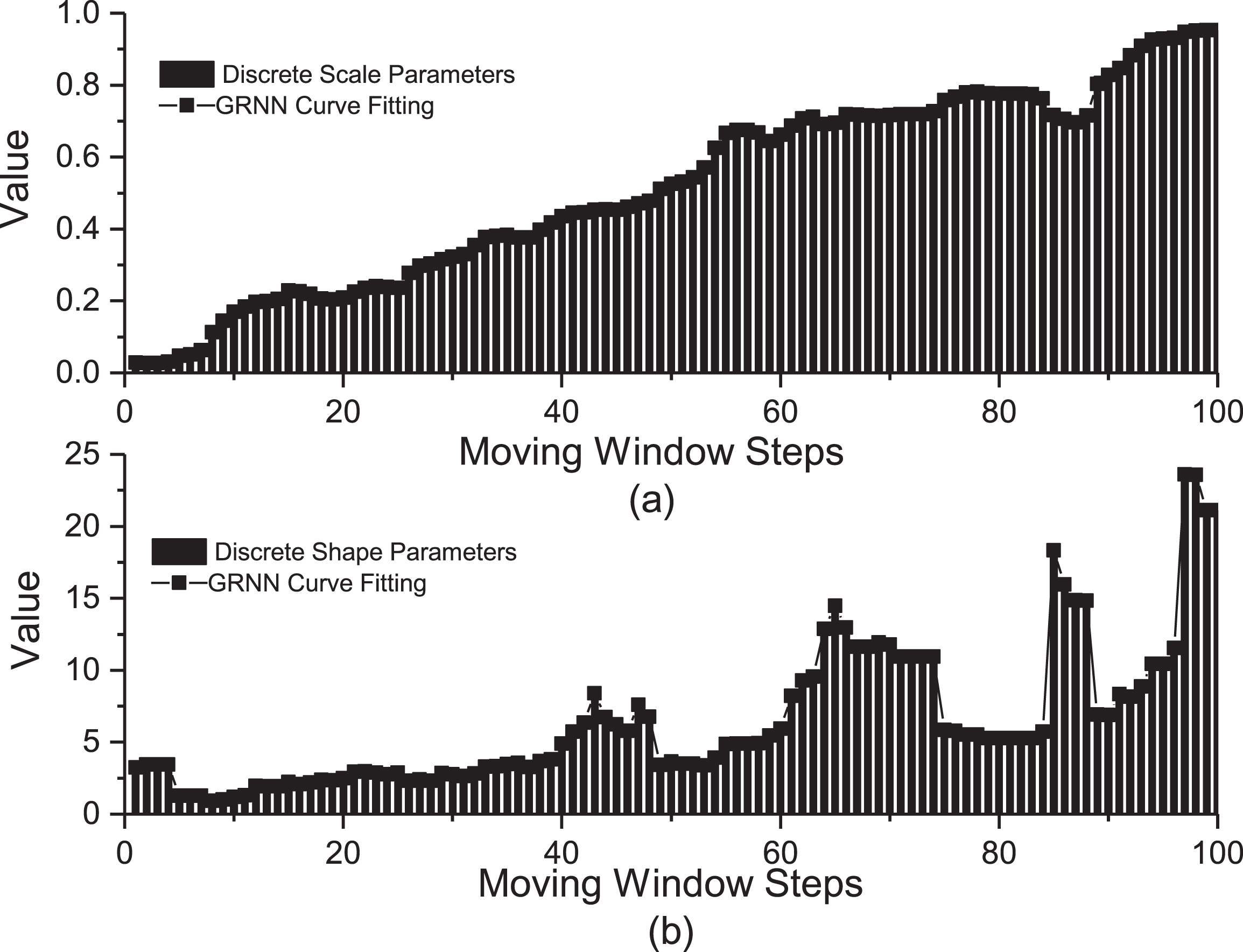
(a) Scale and (b) shape parameters of Weibull distribution before and after applying GRNN curve fitting technique on moving window at time interval 10 with 1-minute time step and 150 aggregation level.
Where ‘b’ is the estimator output, ‘a’ is the input data, E (b/A) is the output expected value, f (a, b) is the joint probability function of a and b. The detailed mathematical model of GRNN that is opted for this paper can be found in [30].
Methodology presented in the previous section has given the Weibull distribution parameters of aggregated residential demand patterns at each time step through the probabilistic link between successive time steps of different time step durations, i.e. Δt= 1, 10, 20, 30 and 60 min. and different levels of aggregation, i.e. A = 20, 50, 75, and 150 houses. The probability distribution and inter-temporal probabilistic links are used to generate aggregate residential demand patterns, whose characteristics resemble reference demand patterns. For this purpose, a random starting demand point at time step ‘t’ is selected. Moving window step number at time step ‘t’ is calculated in which started demand point exists. Both parameters of Weibull distribution for calculated moving window are estimated from GRNN curve fitting technique at a specific time step ‘t’. Fig. 7 shows the detailed flowchart of the algorithm for scenario generation based on the estimated parameters.
Flowchart of the algorithm for scenario generation based on estimated parameters.
Let η j t and β j t be the Weibull scale and shape parameters of starting demand pattern j t and ct+1 be the generated cumulative probability at time step ‘t+1’ then normalized demand point is generated by using inverse Weibull cumulative distribution function (CDF) at time step ‘t+ 1’ and is represented in the mathematical form as given in (9).
Where
Generated demand pattern
Aggregate demand patterns at all time steps, t = 1, 2 ... , 1440, of specific time step duration Δt are generated by repeating above-mentioned procedure. Same process is used for the generation of aggregated demand patterns of all Δt and A.
Since ‘O’ aggregated demand observations are used in the reference data set, so same aggregated demand patterns are generated to compare the performance of the proposed model. The generated dataset is represented in (11).
The reference data sets of aggregated demand patterns used in this study has been presented in [7] and [16]. The reference demand pattern data set consists of 4 aggregation levels and 5 different time step duration, of residential customers for winter weekdays. Reference data consists of 100 observations for a typical winter weekday. The reference data of time step duration Δt= 1 minute for all the aggregation levels, A = 20, 50, 75 and 150, is shown in Fig. 1. Table 1 shows the parameter used for initialization of the proposed method in this study.
Scenario generation model parameters
Scenario generation model parameters
For the calculation of Weibull distribution scale and shape parameters, the detail algorithm presented in Fig. 4 is used. GRNN based curve fitting technique is applied to achieve the continuity of Weibull distribution parameters and the results are shown in Fig. 6.
The extracted Weibull distribution parameters are then used to generate different scenarios of aggregated demand patterns whose characteristics resembles reference demand patterns. The complete flowchart of the procedure for generating scenarios is shown in Fig 7. In scenario generation, inter-temporal variations of generated demand patterns should be similar to the reference demand patterns.
Comparison of mean and standard deviation of generated dataset with the load patterns generated using Beta distribution and reference data is shown in Fig. 8. It can be seen that the mean value is almost the same in all three cases. However, for standard deviation, the performance of proposed Weibull distribution-based method is largely closer to the reference data and outperforms the Beta distribution-based method. To further validate this conclusion, the accuracy of the proposed model is calculated by using well-known goodness of fit (GOF) indicator, i.e. AMAPE, which gives the error between generated demand patterns and reference demand patterns. In literature, different other indicators such as Mean Absolute Percentage Error (MAPE), Mean Square Error (MSE) have also been used to calculate error between actual and estimated values. But, in case of smaller actual value, these indicators show large error term even if difference between estimated and actual value is small [31]. To avoid this effect AMAPE is used in this paper to calculate percentage error. This indicator is applied on the standard deviation and mean of the aggregate reference and generated demand patterns. Moreover, to assess the uncertainty of the proposed probabilistic model variance of AMAPE is also computed. Same indicators have been used in different literature to validate results as given in [16, 32].
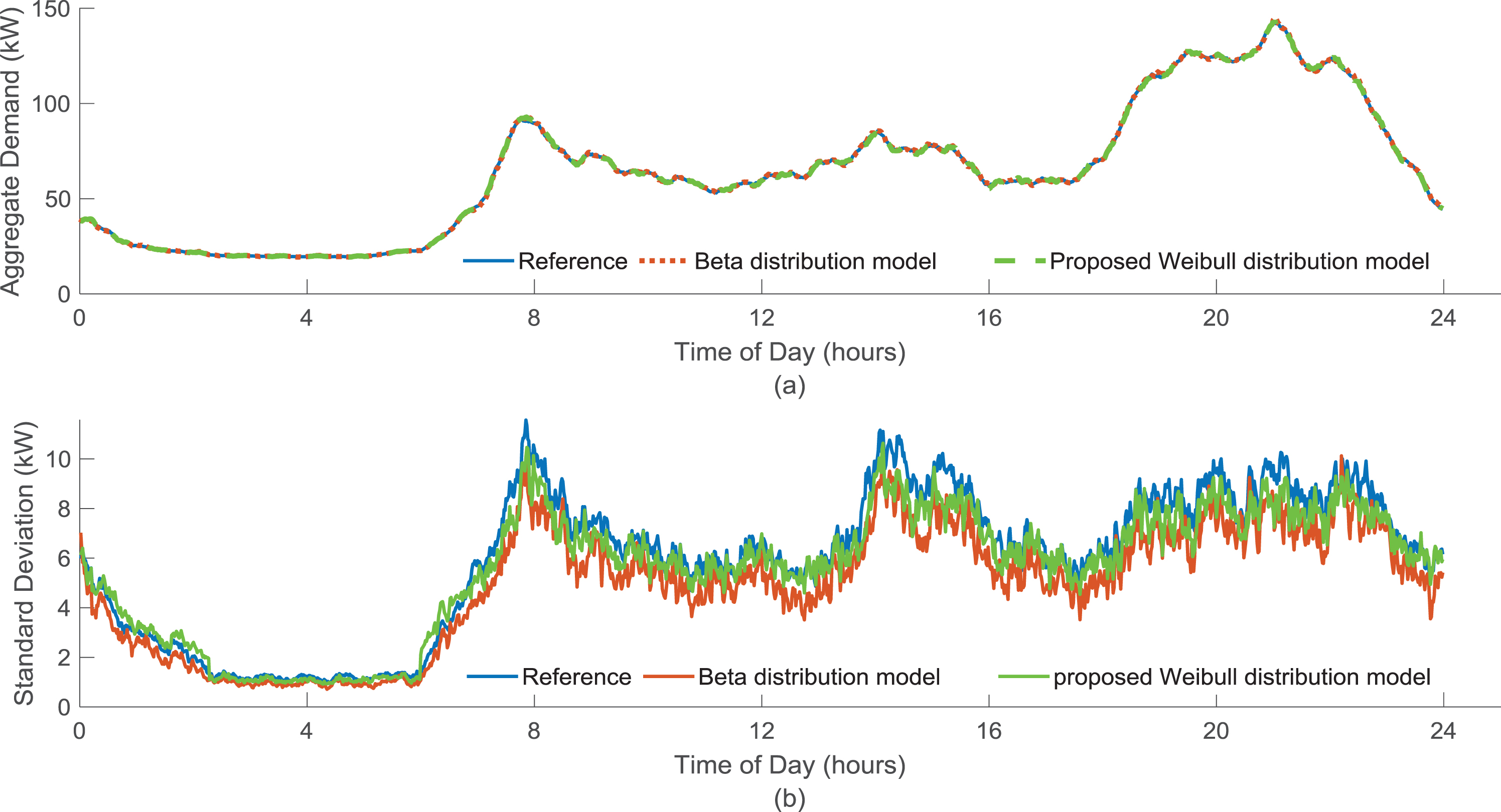
Comparison of (a) mean and (b) standard deviation for generated demand patterns with the results of Beta distribution model [16] and reference data.
Mathematical formulation for AMAPE is given in (12).
Where P is the averaging time period to calculate AMAPE. For this paper, P = 60 minutes is assumed which was also used in [16]. G t and R t represent the mean or standard deviation of the generated and reference datasets respectively.
Similarly, to measure the uncertainty of scenario-generation model, variance of AMAPE is used and its mathematical expression is given in (13).
The proposed Weibull distribution probabilistic model and the beta distribution probabilistic model is applied on 1, 10, 20, 30 and 60 min time step durations and 20, 50, 75 and 150 aggregation levels. The results and percentage improvements of proposed model for the mean and standard deviation of AMAPE and AMAPE Variance σ2 are shown in Fig. 9 and Fig. 10.
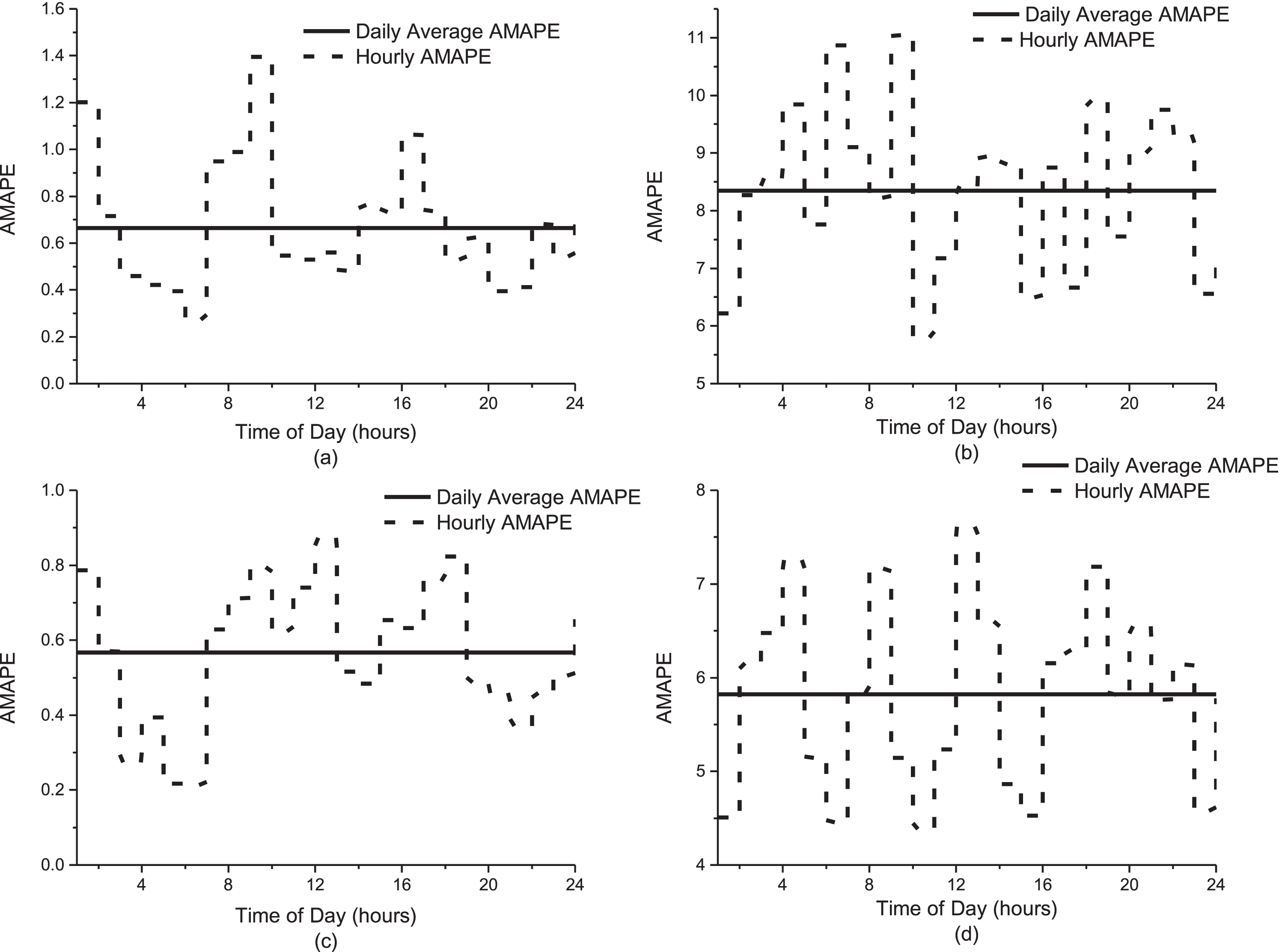
Detailed hourly AMAPE of (a) mean and (b) standard deviation of beta probabilistic model and (c) mean and (d) standard deviation of Weibull probabilistic model.
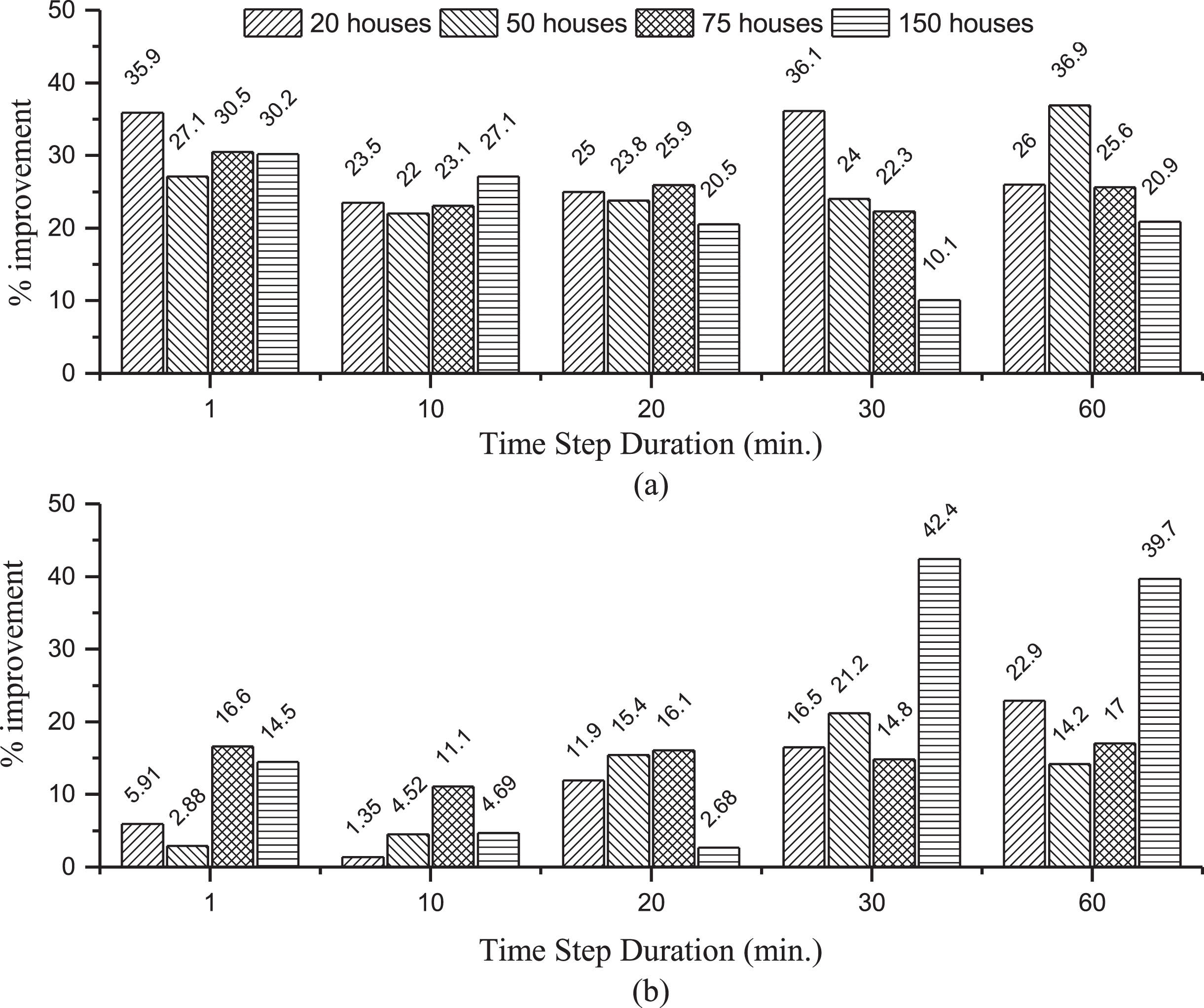
Percentage improvement in AMAPE for (a) standard deviation (b) mean in comparison with [16] for different aggregation levels and time step durations.
Results of AMAPE and AMAPE Variance for the mean or standard deviation of the generated and reference datasets with one minute time step duration and different aggregation levels (20, 50, 75 and 150 houses) are presented in Table 2. In [16], average value of AMAPE for one minute and 150 aggregation level was 0.64 whereas, for the proposed Weibull distribution probabilistic model, this error is 0.56. Percentage improvement of Weibull distribution model for one minute and 150 aggregation level is 14.5% and it is clearly shown in Fig. 9.
Mean and standard deviation of AMAPE and AMAPE Variance
Mean and standard deviation of AMAPE and AMAPE Variance
Standard deviation of AMAPE for one minute time step duration and aggregation of 150 houses as calculated in [16] using beta probability distribution model was 8.54 whereas for the proposed method it is 5.82. Percentage improvement of standard deviation for one minute and 150 houses aggregation is 30.2%.
Detailed results of AMAPE and its Variance are listed in Table 3.
Detailed results of mean and standard deviation of AMAPE and AMAPE Variance of 150 Aggregation at 1-minute time step duration.
Maximum values of AMAPE for mean and standard deviation with one minute time step duration and 150 houses aggregation level were 1.39 and 11.05 respectively as calculated using beta probabilistic model and reported in [16]. Whereas, the maximum values of AMAPE for mean and standard deviation calculated using Weibull distribution based model are 0.87 and 7.61 respectively. Similarly, minimum values calculated using beta distribution model are 0.27 and 5.85 while the minimum value of Weibull distribution model is 0.21 and 4.38.
AMAPE Variance for mean and standard deviation calculated using beta distribution model were 0.0025 (approximately zero) and 0.26 [16]. The respective values calculated using Weibull distribution model are 0.002 and 0.18. Percentage improvement of mean and standard deviation is 20% and 31.1% respectively.
AMAPE Variance for mean and standard deviation is calculated for all aggregation levels and time step durations using beta probability distribution model and Weibull distribution based model. Percentage improvement of Weibull distribution model with respect to beta probabilistic model is shown in Fig. 10. It can be noted that Weibull distribution with GRNN is more effective to model inter-temporal change in demand characteristics. In addition to this, it can also be observed that the performance of the proposed method is better than beta distribution model for different time step durations and demand aggregation levels. The results dictate that this methodology can equally be applied for scenario generations at different customer aggregations with changing time step duration.
In this paper, a new probabilistic model based on Weibull distribution and GRNN has been presented for the inter-temporal characterization of aggregate demand to generate different scenarios based on reference daily load patterns of residential customers. Proposed probabilistic model has been applied on datasets with 1, 10, 20, 30 and 60 minutes of time step duration and 20, 50, 75 and 150 houses aggregation levels. Well known goodness of fit (GOF) techniques have been used for the evaluation of proposed probabilistic model. GOF indicators have validated the accuracy of the Weibull distribution model. Results for the mean and standard deviation of AMAPE and AMAPE Variance show the effectiveness of the proposed model. Moreover, existing methods for the characterization of aggregate demand pattern are supported by this research. This research work can further be extended to the construction of renewable power generation scenarios and power difference patterns between generation and electric demand in a microgrid environment.