
Abstract
Day-ahead electricity tariff prediction is advantageous for both consumers and utilities. This article discusses the home energy management (HEM) scheme consisting of an electricity tariff predictor and appliance scheduler. The random forest (RF) technique predicts a short-term electricity tariff for the next 24 hours using the past three months of electricity tariff information. This predictor provides the tariff information to schedule the appliances at the most preferred time slot of a consumer with minimum electricity tariff, aiming high consumer comfort and low electricity bill for consumers. The proposed approach allows a user to be aware of their demand and their comfort. The proposed approach makes use of present-day (D) tariff and immediate previous 30 days (D-1, D-2, ... , D-30) of tariff information for training achieves minimum error values for next day electricity tariff prediction. The simulation results demonstrate the benefits of the RF approach for tariff prediction by comparing it with the support vector machine (SVM) and decision tree (DT) predicted tariffs against the actual tariff, provided by the utility day-ahead. The outcomes indicate that the RF produces the best results compared to SVM and DT predictions for performance metrics and end-user comfort.
Introduction
Demand Response (DR) shifts the electricity demand from peak periods to off-peak periods, resulting in peak demand reduction [11, 26]. DR encourages users to modify their demand profiles according to the utility company incentives offered [37]. The user’s involvement through a priority-based incentive mechanism is motivated. The incentive mechanism utilizes the frequency of the participation of users in the DR program [21]. The primary motivation behind this is to achieve high-quality energy service with low energy costs. Under DR, pertinent information must be sent to the end-users by the utility, typically as an electrical tariff data. The electrical tariff increase may be ascribable to a rise in demand or buying power and redeeming it. Many researchers have modeled the residential DR under time-based pricing. The primary motivation is to minimize residential users’ electricity bills [1, 2].
Home energy management (HEM) systems in residential communities play a vital part under the DR strategy for the effective participation of end-users in response to the demand. The HEM system uses a scheduling algorithm developed to determine day-ahead appliance scheduling under hourly pricing and peak power-limiting [30]. Residential power utilization was scheduled based on electricity cost and users’ satisfaction of comfort [22]. The primary motivation for scheduling algorithms is to find the best time for appliances’ to be scheduled to cut the electricity bill.
The optimal decision of the HEM system towards appliances schedule is dependent on three key elements: (i) demand for energy, (ii) availability of energy, and (iii) tariff of electricity [9]. To make the optimal decisions, the HEM must have reliable predictors to have accurate predictions of the future considering the past historical data. The precise prediction of electricity tariff is necessary for residential consumers to participate in the DR program [8]. The electricity tariff represents the connexion between the energy supply and the demand, becomes one of the most significant elements of the power sector [27]. Thus, accurate electricity tariff prediction is necessary and relevant for balancing the energy generation by the utility and the energy consumption by the consumer. The electricity tariff prediction is too stochastic, which is not predictive every time with the required precision. The prediction depends upon several factors for example, the demand in energy varies based on the weather condition, the functionality of the energy resources, and daily activities of the consumer, which makes the electricity tariff frequently fluctuate [33]. Therefore, predicting high precision electricity tariff is not very easy.
The electricity tariff prediction has been a hot topic since introducing the dynamic tariffs for DR under the demand-side management umbrella [10, 13]. Prediction aims to fit the predicted data (obtained from past data) with the actual data as tightly as possible [12]. A day-ahead tariff prediction seems to be the best solution for the day-ahead electricity market [6], providing transparency to the utility to facilitate the generation side to balance demand and supply. The prediction can be a short term (ranges from an hour to a day), medium-term (ranges from a day to a month), long term (ranges from a month to a year), and very long term (ranges from a year to several years). Most researchers mostly prefer short-term prediction as it gives better results compared to other terms [25].
In literature, an observation is that the electricity hourly tariff has gotten attention for prediction in recent years [18]. It is observed that the artificial neural network (ANN) model is widely used for predicting electricity tariffs a day-ahead [16, 32]. Authors in [15] employed ANN to predict Ontario electricity tariffs. Authors in [29] projected a predictor consisting of an ANN and an evolutionary algorithm. However, the ANN encounters prediction errors during the testing stage due to the time-varying electricity tariff. A support vector machine (SVM) has been an alternative to the ANN for the data-driven technique suitable for specific scenarios [35]. SVM, also referred to as support vector regression, is used widely for predicting electricity tariffs as it falls into the category of the regression problem [7, 20]. However, there has been an increase in the overfitting problem [28].
The suitable machine learning technique cannot be preferred a priori. Perhaps a more straightforward substitute to ANN and SVM can be regression trees [14]. Nevertheless, regression trees are usually simpler and faster when trained. The authors in [31] tried a regression-tree-based model in the global energy forecasting competition and ranked first. The authors in [17] addressed the classification of short-term energy prices upon the decision tree method. They compared the result with ANN, and they found a decision tree produces a better result for the one-week ahead prediction time horizon. Authors in [4] proposed a random forest electricity prediction model to predict the CAISO market day-ahead. They considered very-short term, short term, long term, temporal, and geographic as features for error reduction towards electricity price prediction. Similarly, in [19] authors proposed a random forest for real-time price forecasting. The model uses three hours ago, one day ago, one week ago, and one month ago pricing information as features for forecasting. They compared the random forest results with an autoregressive moving average model (ARMA) and an ANN model and found that RF produces better prediction results.
Upon the existing literature, the proposed work focuses on predicting electricity tariffs (considering the time of day, day of the week, day of the month, week of the month, weekday/weekend, and immediate 30 days of electricity tariff data as the features) using random forest (RF) in comparison with SVM and decision tree (DT) towards end-user comforts for appliance scheduling at suitable time slots (high consumer comfort and reduced electricity bill of the consumer). The energy-demand differs for the time of the day, day of the week, day of the month, and the week of the month, directly proportional to the environmental conditions of wind, temperature, humidity, and seasons. This paper proposes the electricity tariff prediction algorithm for user comfort and utility constraint-based HEM. In this article, the scheduler follows a predictor to manage the energy within the residential home. The predictor forecasts the tariff closer to actual tariffs using the past tariff information (3 months). The scheduler plans the operation of the appliances during low tariff hours. The predictor and scheduler enable the user to be aware of their demand and comfort ahead of actual tariffs from the utility, creating flexibility for the consumer towards their appliance usage, thereby reducing the user discomforts (delay in appliances operation) in energy management.
The rest of the paper is structured as follows. Section II presents the architecture of the HEM scheme briefly. Section III is devoted to the mathematical formulation and the algorithms. Section IV elucidates the developed system’s simulation results, and finally, Section V provides the conclusion.
Supervised electricity tariff prediction
The predictor module predicts the hourly electricity tariff using past tariff data (3 months) before the day ahead real utility provided hourly tariff is available to the residential consumer. The inputs considered for the prediction techniques are the time of the day, day of the week, day of the month, week of the month, weekday or weekend, and past tariff data (90 sets of training data, each set of training data includes current day tariff (D) and immediate previous 30 days of tariff data (D-1, D-2, ... ., D-30)), as shown in Fig. 1.
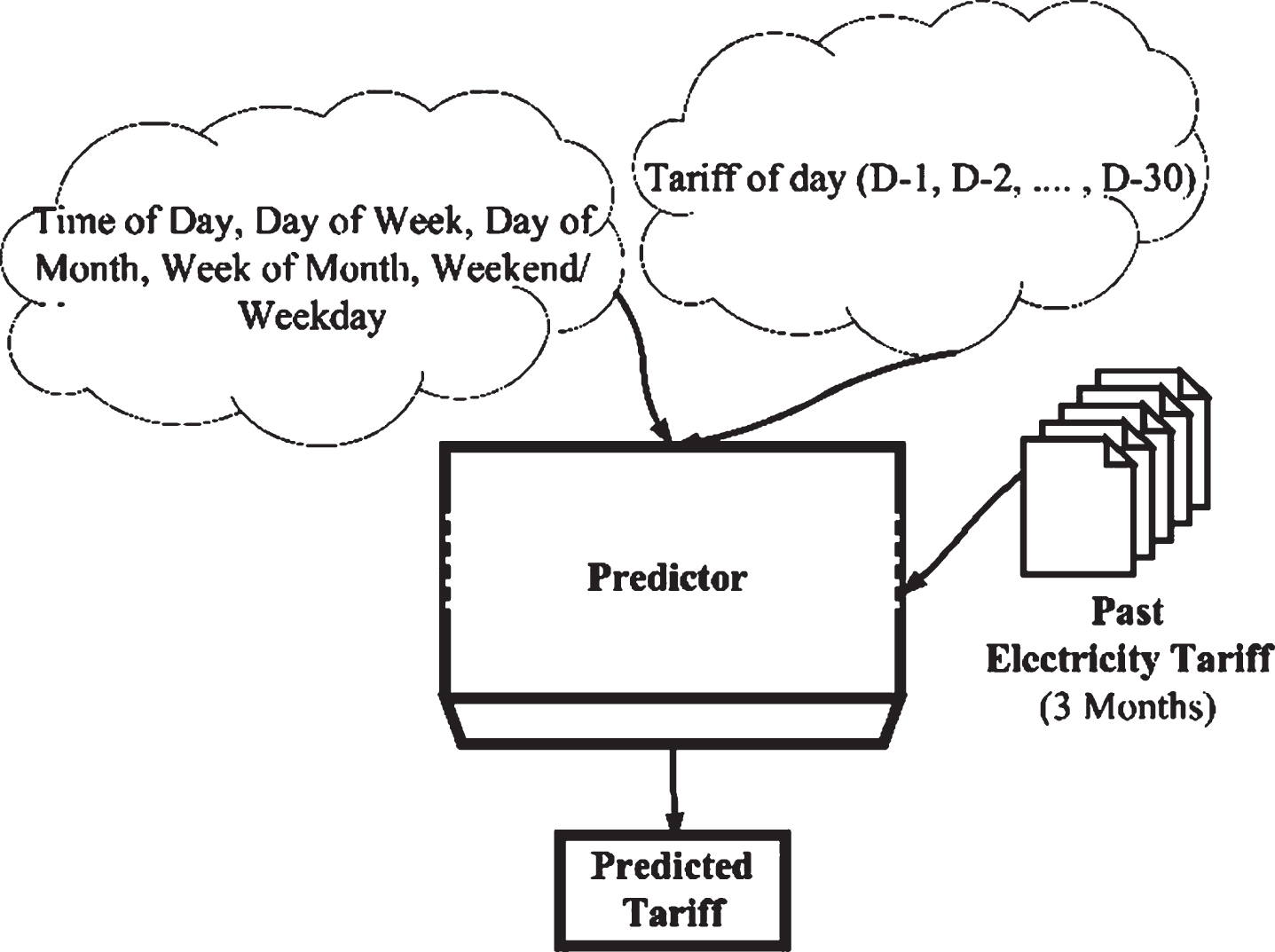
Flow process of the proposed HEM tariff predictor.
For electricity tariff prediction, the input parameters listed in the previous paragraph, from the utility provided past hourly tariff information of the year 2017/18 shown in Fig. 2 taken from ComEd Live Prices (cents converted to rupees) [5]. This data serves as input to the supervised learning algorithm that predicts hourly tariff information as part of the HEM. The parameters derived from hourly tariff data, used as input data variables for any day as part of the immediately previous 90 days of training dataset provided to learning algorithms for predicting the electricity tariff for a particular day, are listed in Table 1.
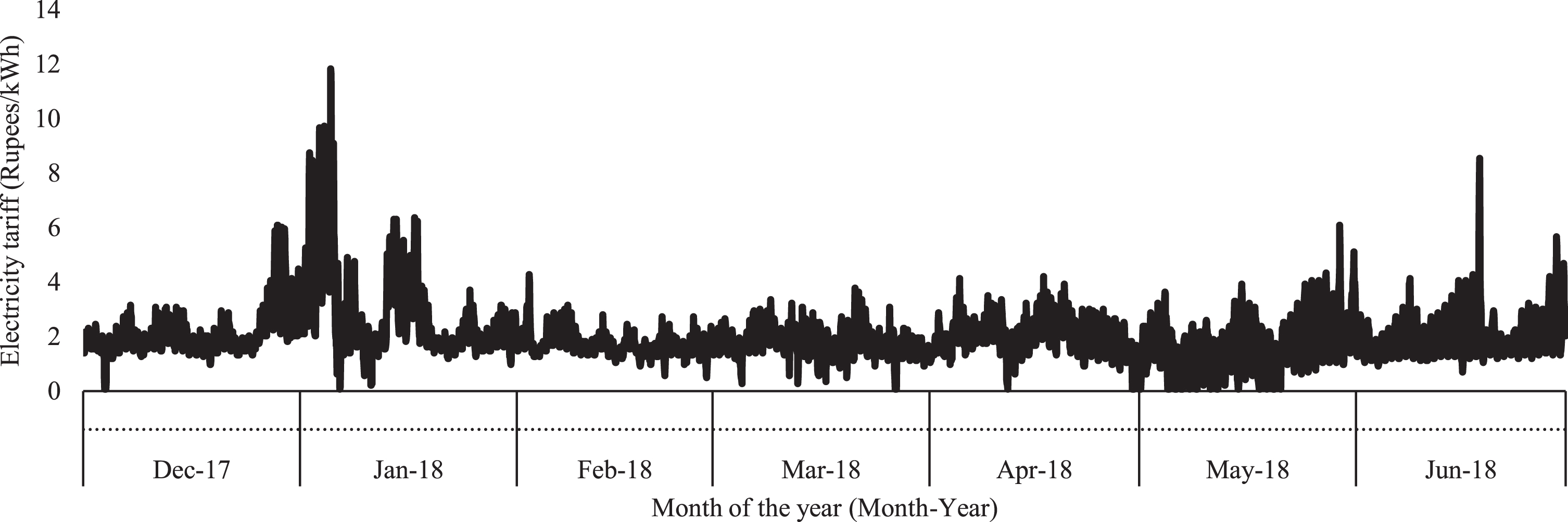
Electricity hourly tariff data considered for analysis.
Input data variables derived from the hourly tariff data and used for electricity tariff prediction
The formulation of the tariff prediction is done and analyzed based on three prediction techniques, namely SVM, DT, and RF (as discussed in algorithm 1).
2.1) Support Vector Machine (SVM):
SVM is a supervised machine learning approach that constructs the hyperplane in n-dimensional space [36]. SVM uses the concept of support vectors to construct the hyper-plane. SVM supports both regression and classification analysis, where the regression function is enabled by support vector regression (SVR), while the support vector classifier enables the classification function. The SVR maps the high dimensional variables with the input training data. The SVR function is shown in Equation 1.
where,
∥a∥ –is the Euclidean Norm.
x m –is the training sample.
y m –is the target value.
a T x m + b –is the prediction for the training sample.
ɛ –is the threshold.
Without knowing the mapping transformation function, the kernel methods are introduced in SVR to solve the mapping function by computing the dot product between two mappings that transforms into the variable space. Kernel functions, including the linear kernel, poly kernel, radial basis function kernel, sigmoid kernel, and the pre-computed kernel, are used for computing the mapping function. The commonly used kernel function for SVM is the radial basis function (RBF) [34]. The RBF is calculated, as shown in Equation 2.
x m –is the training sample
x n –is the testing sample
given that,
2.2) Decision Tree (DT):
DT is a supervised machine learning algorithm representing a flow chart tree structure used for classification and regression problems [24]. In this learning algorithm, during training, the data is segregated into different nodes of the tree. The DT starts with the root node, where the input data are categorized into several groups [38]. There are two main entities in DT; they are decision nodes (points where data splits) and leaf nodes (which makes decisions). Once the decision node is arrived, based on the rule selected, the decision node is split into two child nodes. Further, these child nodes undergo the recursive procedure as a decision node until it reaches some stopping criteria.
For decision tree regressors, there is a need for an impurity metric suitable for continuous variables. Therefore, the impurity measure using the mean absolute error (MAE
DT
) of the child node is defined using Equation 3. The variables with the most considerable mean absolute error reduction is chosen as the decision node to select the best split.
where,
N n –is the number of training samples at node n.
S n –is the training subset at node n.
y m - is the target value
2.3) Random Forest (RF):
RF is a collaborative learning method consisting of more than one DT for decision-making and regression problems [23]. DT can be updated incrementally, whereas RF cannot. Hence, in RF, all training data are likely to be available in advance. RF utilizes bootstrapping (choosing samples from the training set with replacement) and bagging (selection of values arbitrarily from the training values) principles. For any given new value, the prediction is done using either previously trained RF or retrain a whole new RF that includes both old and new data.
The functioning of random forest is as follows: Consider a dataset S., consisting of X rows data and Y. count of features. A few sets of rows x ∈ X. and few features y ∈ Y are selected randomly with replacement [3]. The randomly selected samples are feed to the decision tree. Similarly, multiple decision trees (here, 10 decision trees, are built as we have taken estimators equal to 10) are constructed for several combinations of randomly selected samples. Finally, train all the decision tree and for each decision tree obtain a predicted result. Now, the predicted values of all sample datasets are aggregated, and the predicted values are considered to be the most voted values for classification and the mean for the regression problems.
2.4) Performance Metrics Assessment:
Three months of electricity tariff data are used, with all three techniques (SVM, DT, and RF), and for the next day hourly tariff prediction. To evaluate the performance metrics of the predictor, three scenarios, are taken into consideration as follows, Scenario 1: considers January-March Tariff data, thereby predicting the tariff forthe first day of April. Scenario 2: considers February-April Tariff data, thereby predicting the tariff forthe first day of May. Scenario 3: considers March-May Tariff data, thereby predicting the tariff forthe first day of June.
Figure 3(a) and 3(b) show the “scenario 1” as mentioned above, with and without considering D-1, D-2, ... , D-30 as input for training, respectively. From Fig. 3(a) and 3(b), it is observed that Fig. 3(b) depicts very close prediction from hour 1 to hour 24 (considering D, D-1, D-2, ... , D-30 tariff data). Similarly, from Figs. 4 and 5, it is observed that Figs. 4(b) and 5(b) shows close prediction from hour 1 to 24. However, there exists some error concerning the actual tariff (AT). An observation is that RF predicted tariff values follow the gesture of AT closely.

Comparison between AT and predicted tariff (using SVM, DT, and RF) for 1st April 2018.
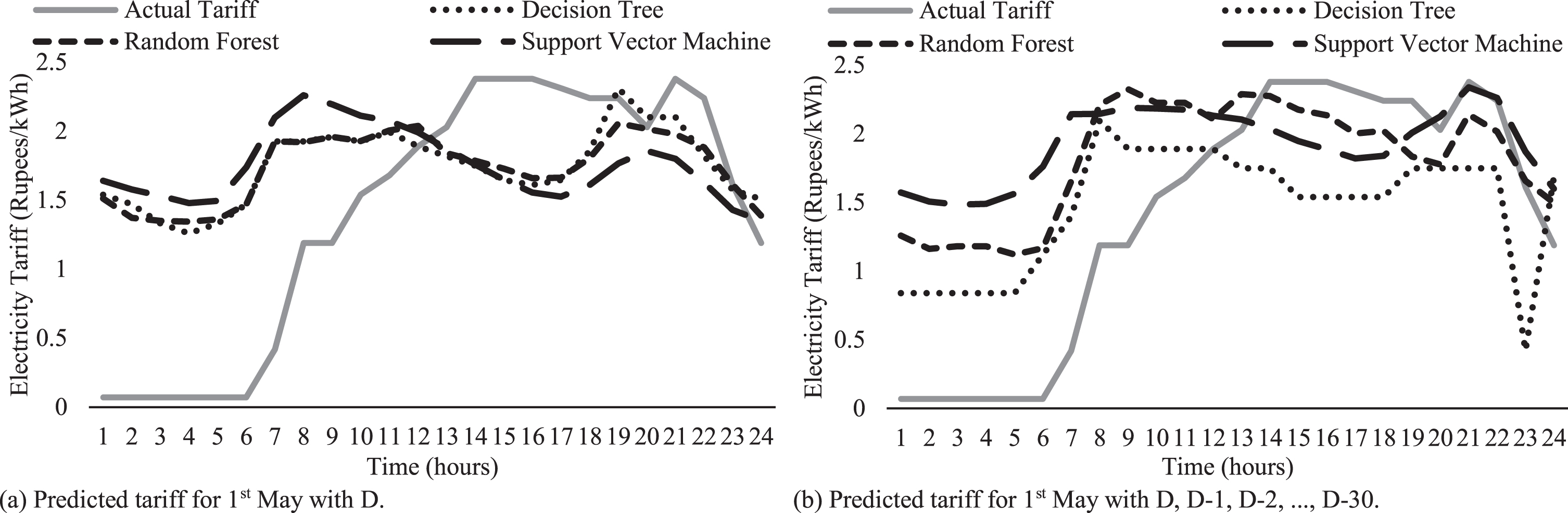
Comparison between AT and predicted tariff (using SVM, DT, and RF) for 1st May 2018.
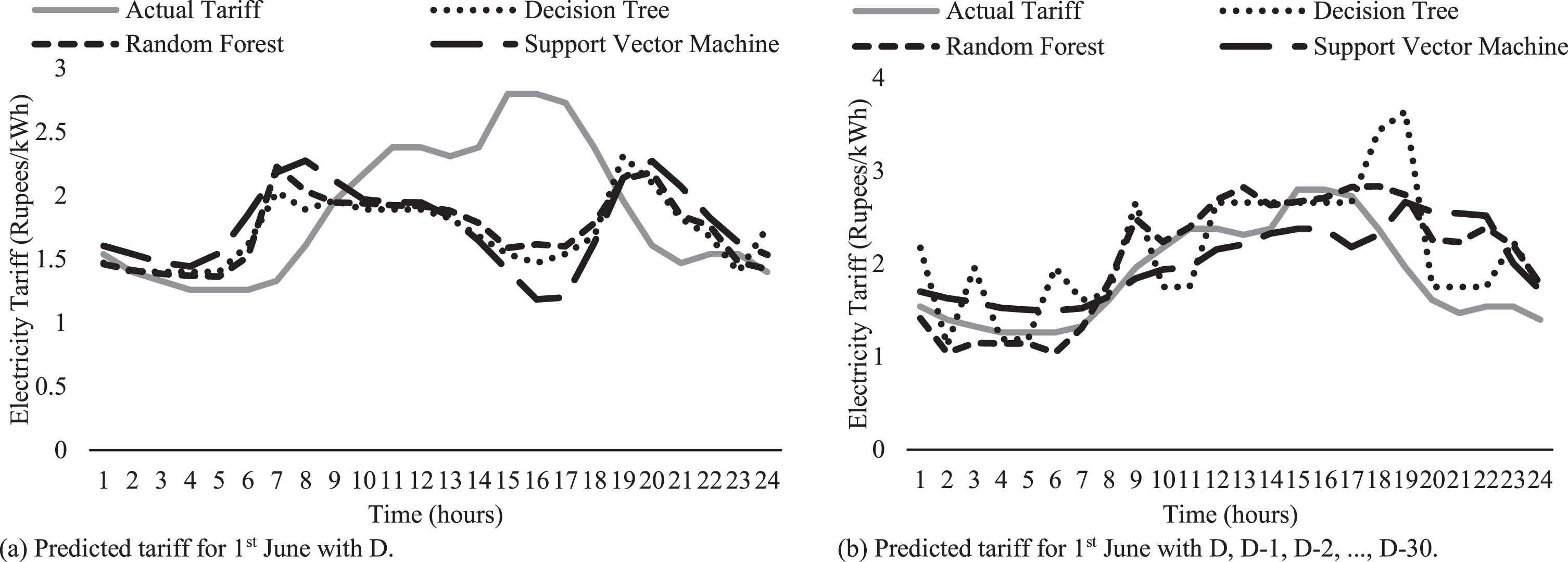
Comparison between AT and predicted tariff (using SVM, DT, and RF) for 1st June 2018.
The predicted values are assessed through performance metrics like Mean Absolute Error (MAE), Mean Square Error (MSE), Root Mean Square Error (RMSE), and Mean Average Percentage Error (MAPE), obtained from Eqs. 5, 6, 7, and 8, and the outcomes, are listed in Table 2.
Performance Metrics of SVM, DT, and RF for predicting electricity tariff through MAE, MSE, RMSE, MAPE
Table 2 infers the reduction in error values upon considering the tariff of the day (D, D-1, D-2,...., D-30) for prediction in comparison with the tariff of the day (D).
The proposed energy management scheme takes into the assumption that every home has both schedulable and non-schedulable appliances. The non-schedulable appliances operate at the user-defined hour of the day and the schedulable appliances during the hours defined through a scheduler.
The scheduler considers the concept of appliance accommodation window (AAW) and soft-constraints (SC), as shown in Fig. 6. The AAW contains a range of time slots assigned for each schedulable appliance by the users. The SC is the maximum power consumption restriction provided by the utility (based on the non-schedulable load of a residential home) to maintain a power demand peaks. The scheduler module receives predicted hourly tariff information from the predictor, maximum power constraint from the utility, and AAW (for each schedulable appliance) as inputs from the user. Upon receiving the data, the scheduler schedules the appliance during the low tariff period within an AAW and SC without compromising user comforts.

Flow process of the proposed HEM appliance scheduler.
HEM’s primary role is to predict the electricity tariff closer to the actual tariff and regulate power demand within the constraint and comfort. The scheduler calculates the respective home’s hourly power consumption and checks whether the consumption exceeds the constraint. If so, then the schedulable appliances are shifted to the next lowest tariff slots, confirming that the power consumption is within the constraint. The next slot is also chosen within the AAW for any particular appliance to remain uncompromised with the user comfort.
The scheduler schedules the appliances so that it minimizes the users’ electricity bills without affecting their comfort. An assumption in this article is that the non-schedulable appliances operate during the hours that belong to AAW. In contrast, schedulable appliances operate during a reasonable low tariff hour that belongs to AAW, as discussed in algorithm 2 in subsequent Section 3.1.
3.1) Mathematical framework for appliance scheduling:
We assume a set of appliances, classified into two broad categories of sets, based on their demand-type schedulable and non- schedulable. These appliances are scheduled to their defined time slots or to an appropriate time slot based on their type. The schedulable appliances SA get schedule by shifting their demand to an appropriate time slot, whereas non- schedulable appliances NA operate at their respective defined time slots without shifting.
For an appliance a, the assumption is that the demand remains constant during its operation. When the rating of an appliance is R
a
, then the demand d
a
per its operational length n
a
is as listed in Equation 9.
where,
R a - Rating of an appliance in terms of kW per hour.
n - number of minutes in an hour (Typically 60).
n a - Total number of minutes an appliance operates.
In this article, we assumed that there is a seamless grid power every hour of the day G h , and its hourly tariff information, from the utility, day-ahead. The scheduler utilizes low tariff hours to reduce EB if demand management is with grid power. However, this can cause demand peaks not appropriate for the grid. Therefore, the article considers an hourly soft-constraint SC h on power drawn from the grid to reduce such peaks.
To demonstrate the effectiveness of our proposed approach, three homes with layouts in Table 3, with a different set of appliances listed in Table 4, with different usage patterns listed in Table 5, are considered.
List of rooms considered for analysis in each home
List of rooms considered for analysis in each home
√ - Available, x - Not Available.
List of household appliances and their rating used for analysis in each home
√ - Used, x - Not Used.
Preferred time slots for each schedulable appliance used in each home
x - Not Used.
Table 6, Table 7, and Table 8 list the scheduled hour of an appliance using Ad-hoc time slots chosen by the user, and the scheduler’s time slots concerning the AT, SVM, DT, and RF tariffs, considering scenarios as discussed in section 2.4. In comparison with an AT-based scheduling hour for all scenarios, the maximum waiting time for an appliance operating range between,
Appliance scheduled time slot (hours) w. r. t. Ad-hoc, AT, SVM, DT, and RF considering scenario 1
x - Not Available.
Appliance scheduled time slot (hours) w. r. t. Ad-hoc, AT, SVM, DT, and RF considering scenario 2
x - Not Available.
Appliance scheduled time slot (hours) w. r. t. Ad-hoc, AT, SVM, DT, and RF considering scenario 3
x - Not Available.
Scenario one: 0 hours to 5 hours in SVM, DT, and RF, techniques. Scenario two: 0 hour to 5 hours for SVM, DT (higher than RF waiting time that ranges between 0 to 3 hours). Scenario three: 0 and 5 for SVM, (higher than both DT and RF waiting time that ranges between 0 to 3 hours).
Also, the average waiting time concerning the RF is fair enough for user satisfaction compared to SVM and DT for home 1, home 2, and home 3.
Table 9, Table 10, and Table 11 list user satisfaction percentage for each appliance using SVM, DT, and RF predicted tariff concerning the AT. The schedulable appliances scheduled time slot concerning predicted electricity tariff is the period at which appliances are schedule initially. Any deviation in that schedule concerning the actual electricity tariff affects user satisfaction (User Sat .) calculated using Equation 10. For all scenarios, the average rate of user satisfaction for RF seems to be comparatively high (97.5%) when compared to DT (97%) and SVM (96.5%). Therefore, towards end-user preferences on the prediction scheme, RF seems to provide more satisfaction to the user.
where,
T d - Total time slots in a day (Typically 24, each slot of one-hour duration).
STS AT - scheduled time slot for each schedulable appliance concerning actual electricity tariff from utility.
STS PT –scheduled time slot for each schedulable appliance concerning predicted electricity tariff (SVM, DT, RF).
User satisfaction in percentage (%) using SVM, DT, and RF w. r. t. AT considering scenario 1
x - Not Available.
User satisfaction in percentage (%) using SVM, DT, and RF w. r. t. AT considering scenario 2
x - Not Available.
User satisfaction in percentage (%) using SVM, DT, and RF w. r. t. AT considering scenario 3
x - Not Available.
This paper focused on day-ahead electricity tariff prediction using an SVM, DT, and RF approaches for the HEM scheme. The set of appliances (non-schedulable and schedulable), an electricity tariff predictor, and appliance scheduler are considered part of the HEM scheme in each home. The three houses with a different set of appliances and their different styles of consumption patterns help in demonstrating the proposed approach. An observation during simulations is that the RF electricity tariff prediction with the next 30 days of electricity tariff data as the features produced the best prediction towards the actual electricity pricing compared to the SVM and DT concerning the performance metrics. The simulation results indicate that the developed algorithm achieves higher user comfort (97.5%) during appliance scheduling while performing energy management.
Conflict of interest
The authors declare that they have no conflict of interest.