
Abstract
Software-defined networking is a new paradigm that overcomes problems associated with traditional network architecture by separating the control logic from data plane devices. It also enhances performance by providing a highly-programmable interface that adapts to dynamic changes in network policies. As software-defined networking controllers are prone to single-point failures, providing security is one of the biggest challenges in this framework. This paper intends to provide an intrusion detection mechanism in both the control plane and data plane to secure the controller and forwarding devices respectively. In the control plane, we imposed a flow-based intrusion detection system that inspects every new incoming flow towards the controller. In the data plane, we assigned a signature-based intrusion detection system to inspect traffic between Open Flow switches using port mirroring to analyse and detect malicious activity. Our flow-based system works with the help of trained, multi-layer machine learning-based classifier, while our signature-based system works with rule-based classifiers using the Snort intrusion detection system. The ensemble feature selection technique we adopted in the flow-based system helps to identify the prominent features and hasten the classification process. Our proposed work ensures a high level of security in the Software-defined networking environment by working simultaneously in both control plane and data plane.
Keywords
Introduction
Computer backbone networks generally consist of numerous switches and routers controlled by a network administrator. Network administrator needs to configure various network policies and update them regularly to adopt the dynamic changes in network traffic. Traditional network architecture is a challenge, and has difficulty handling advanced and dynamic changes in configuration, owing to a lack of automated update mechanisms. To overcome problems in traditional networks and improve the quality of service, a new paradigm termed software-defined networking (SDN) has emerged [1]. SDN reformulates the network control logic as a centralized one. A key characteristic of SDN is the logical separation of the control plane and data (infrastructure) plane. The control plane decides how to handle network data traffic by analysing abstract views of the network. The data plane handles network traffic based on the decisions made by the controller. The data plane comprises network devices like routers, switches, and access points. The controller in the control plane acts as a core part of the network architecture and it is easily programmable. Routing mechanisms and forwarding decisions are implemented in the centralized controller of the software defined network (SDN). The logical separation of the two is made possible by means of a distinct interface between forwarding devices and the application program interface (API) of the controller.
The Open Flow protocol (OF) [1, 2] is a standard API (Application Programming Interface) commonly used in research and academia. The OpenFlow switch is similar to the Ethernet switch which contains one or more flow tables. A flow table is a set of packet handling rules to manage network traffic. For every flow, rules are defined by the centralized controller in the flow table through the OpenFlow protocol. In an SDN context, a flow represents a sequence of packets from source to destination. The controller creates new rules, changes existing rules, or removes certain rules from the flow table by analyzing the overall network. The control logic is programmable through software applications running on the application plane, alongside other applications like load balancing, Firewalls, QoS (Quality of Service), network monitoring etc. Open-source communities have taken on the responsibility of designing SDN controller software [1, 3] such as the NOX, POX, RYU, Floodlight, and OpenDaylight. Such a logical separation between the forwarding devices and controller helps deploy dynamic features and provide utmost flexibility in the network environment.
SDNs, which provide greater flexibility and simplicity than traditional networks, face challenges that are to be addressed in terms of reliability, scalability, and controller placement, as well as security issues like denial-of-service and man-in-the-middle attacks, along with vulnerability scans. This paper focuses on SDN security vulnerabilities. Since the SDN controller is prone to single-point failures, providing the centralized controller adequate security is a major concern. An intrusion detection system (IDS) [4] safeguards the network against all kinds of malicious activity. Integrating an IDS module into an SDN environment potentially secures the network by alerting and detecting unauthorized activity in the network. The IDS, using machine learning techniques, helps detect different kinds of known and unknown attacks with high accuracy [4, 5].
In this paper, we propose a multi-layer machine learning classifier to classify traffic instances in a flow-based IDS. We use an ensemble-based feature selection mechanism to identify essential features from the traffic. Also, we propose a signature-based IDS to monitor traffic in the SDN data plane. To the best of our knowledge, the proposed work is distinct from existing research techniques by providing security measures for both control plane and data plane with the help of IDS.
The major contributions of this research work are: Proposing a flow-based IDS in the control plane and a signature-based IDS in the data plane. Designing a flow-based IDS module using machine learning techniques for both feature selection and classification, and training the same using the standard NSL-KDD (Knowledge Data Discovery) dataset. Creating a signature-based IDS using a rule-based mechanism called Snort to inspect traffic instances in the SDN data plane.
The paper is organized as follows: Section 2 discusses the background and related work. Section 3 describes the flow-based IDS and signature-based IDS. Section 4 explains the evaluation metrics and performance analysis, and Section 5 concludes the paper.
Background and related work
Intrusion detection systems play a vital role in traditional networks in detecting malicious activity. There are two kinds of IDS, signature-based IDS and anomaly-based IDS. The signature-based IDS helps detect known attacks by comparing new data with a previously stored malicious database,whereas an anomaly-based IDS helps detect unknown and new attacks by comparing new data against a model of normal activity. It is crucial to design an anomaly-based IDS to protect the network from all kinds of attacks. An IDS module can be constructed using statistical-based, knowledge-based and machine learning-based mechanisms [5, 6]. Machine learning techniques help identify and analyze complex patterns in real-time traffic and produce quick predictions. By successfully integrating the anomaly-based IDS module into SDN control plane [7, 8], we secure the centralized controller from attacks. Since the SDN deals with huge volumes of traffic flow, it is necessary to identify its essential features so as to be alert to malicious activity and detect it quickly. Identifying essential features in the raw dataset helps reduce data dimension and improve the detection accuracy of attacks [9].
The need for a feature selection technique
An intrusion detection system must deal with large volumes of real-time network traffic to detect and protect the network from malicious activity. It is unnecessary to consider every feature in the dataset for a guaranteed maximized performance. When the number of features increases, the computation cost increases correspondingly. The feature selection technique helps reduce the computational cost of the IDS module by eliminating irrelevant and repeat features from the traffic generated. The feature selection process comprises the three steps of subset generation, evaluation and validation [10]: i) The subset generation module selects subsets of features from the entire feature set. (ii) The subset evaluation module examines the selected subset of features and evaluates them using ranking, correlation, entropy, and accuracy. (iii) Finally, the selected subset of features is considered for validation in a real-time or simulated environment.
Feature selection methods are classified into three types: filter, wrapper and hybrid method [10]. The filter method selects the best subset of features, based on the general characteristics of the dataset. To evaluate the performance of the selected features, an independent machine learning-based classifier is used. The wrapper method uses a classifier as part of the feature selection process. A computationally high and slow process, it performs better than the filter method. The hybrid method uses both the filter and wrapper methods for better performance. Widely-ranging feature selection techniques were used by researchers to identify the best subset of features in both traditional and SDN environments. The outcome of each work depends on factors such as the nature of the dataset as well as feature selection, detection, and validation techniques.
In [11], a support vector machine (SVM) was used as a classifier. Applying the genetic algorithm (GA) and principal component analysis (PCA), essential features in the raw dataset were identified. The KDD CUP’99 dataset was experimented with and the results compared. Their findings showed that minimizing the number of features helps maximize detection accuracy. In [12], the authors proposed a machine learning-based intrusion detection system using feature selection techniques like the linear correlation coefficient(LCC) and cuttlefish algorithm (CFA). A decision tree algorithm was used as a classifier. Their experimental results with the KDD CUP’99 showed that the proposed technique identified essential features in quick time, with a prediction accuracy of 95.03% and a low false alarm rate of 1.65%.
An anomaly-based IDS was advanced in [13], using feature selection analysis and a hybrid classifier model. Key features were selected using the vote scheme and information gain (IG), and hybrid classifiers constructed using the J48, random tree, REPTree, Adaboost and Naive Bayes. The NSL-KDD dataset was experimented with and the results compared with single classifiers like the support vector machine (SVM), Naive Bayes and J48. Their findings showed that identifying essential features and using hybrid classifiers help reduce the false alarm rate and maximize detection accuracy. In [14], feature selection techniques like the IG, gain ratio, correlation-based feature selection, and chi-square test were utilized to select essential features from the NSL-KDD dataset. Their findings showed that the random forest classifier with the gain ratio feature selection technique provides the highest accuracy and hastens the IDS process in the SDN environment.
In [15], feature selection techniques like the principal component analysis (PCA) and genetic algorithm(GA)were investigated to identify the optimal feature subset for accurate traffic classification in the SDN. The authors of [16] used several supervised machine learning techniques as classifiers and the PCA algorithm for feature selection over the NSL-KDD dataset. Their results revealed that the decision tree with the PCA technique provides the highest accuracy and minimum execution time by identifying essential features. Improved information gain (IIG) was proposed in [17] to select essential features. The KDD Cup’99 dataset was experimented with using selected IIG, IG and other features. The IIG features selected provided 96.801% accuracy and a false alarm rate of 1.02%. They found that the feature selection technique helps reduce dataset dimensions and make faster predictions.
In [18], an efficient mechanism was proposed to detect distributed denial-of-service (DDoS) attacks using machine learning-based techniques. Information gain was used for feature selection and the chi-square statistic for feature ranking. The C4.5 and Naive Bayes techniques were used as detection mechanisms. Only 9 of 41 features were used, based on the ranking, and 99.8% accuracy achieved, with a 0.3% false alarm rate. An enhanced support vector decision function (ESVDF) was proposed in [19] to select key features based on the forward feature ranking algorithm. Neural networks and a support vector machine were used as classifiers over the KDD CUP’99 dataset. Their findings showed that the proposed work identifies essential features satisfactorily and offers excellent performance. An efficient IDS mechanism was proposed [20] using a genetic algorithm (GA) as a classifier and a correlation-based feature selection technique, sequential floating selection, the PCA, the IG, and a negative selection approach to pick essential features. Their experimental results showed that sequential floating selection with the GA provides the best accuracy and sensitivity rates.
The literature survey makes it clear that the use of feature selection and a multiple machine learning-based classifier play a critical role in an intrusion detection model. The use of a raw dataset in the classification model leads to poor classification accuracy, owing to redundancy in the dataset. Similarly, every available feature in the input data is not needed to categorize the classes, given that it increases the complexity level of the training as well. Such a problem calls for a feature selection technique that identifies essential features from a high-dimensional feature space.
Hence, in this paper, we propose a flow-based IDS using two mechanisms. Ensemble-based feature selection techniques to select the best set of features, and A multi-layer machine learning classifier to classify attacks and normal instances with high accuracy.
The proposed architecture
In this section, we discuss our proposed flow-based intrusion detection mechanism and signature-based intrusion detection mechanism to detect malicious activity in the SDN environment. In addition, we discuss how our system helps provide both the centralized controller and forwarding devices security in the data plane by analyzing traffic features.
System design
We aim to provide a feasible network-based intrusion detection system to secure the network from real-time attacks by applying a machine learning technique with high accuracy and a low false alarm rate. We propose an effective mechanism which integrates a flow-based IDS in the control plane and a signature-based IDS inthe data plane to detect network intrusions.
The two key elements in the SDN environment are the centralized controller in the control plane and forwarding devices in the data plane. The switches in the data plane forward packets based on decisions made by the controller. An OpenFlow-based switch contains flow tables with a set of rules to handle incoming packets. Each entry in the flow table has three fields: a matching rule field, an action field, and a counter filed. When a new packet (packet_in) reaches the OpenFlow-based switches, it starts the lookup process for matching the rule in the flow table. If a match occurs, it follows the action defined in the flow table and updates the packet statistics in the counter field. If a matching rule is unavailable, it sends the packet to the controller as a table_miss. The controller defines the set of rules for the particular flow and installs it in the flow table of the corresponding switch. We use the flow-based forwarding mechanism to collection formation on traffic flow statistics from the controller and direct it to the flow-based IDS module. Using the machine learning-based classifier, it analyzes and detects malicious activity in the network traffic data and alerts the controller. This module does not overhead the SDN environment because flow collection is already part of the SDN framework.
Once the flow rule is installed in the flow table of the switch, there is no security mechanism to monitor the traffic flow installed in the SDN data plane. If a forwarding device in the data plane is compromised by an attacker [21], the flow rules are modified or dropped or misrouted to the victims [22] and an irrelevant request sent to the controller [22, 23], causing the controller to restrict legitimate incoming flows. To address this problem, we introduce a signature-based IDS in the data plane. Using the concept of port mirroring [24], we monitor traffic between switches by forwarding it to the signature-based IDS module. This module uses a rule-based mechanism to detect abnormal activities in traffic and alert the controller. A system diagram of our proposed work is depicted in Fig. 1.
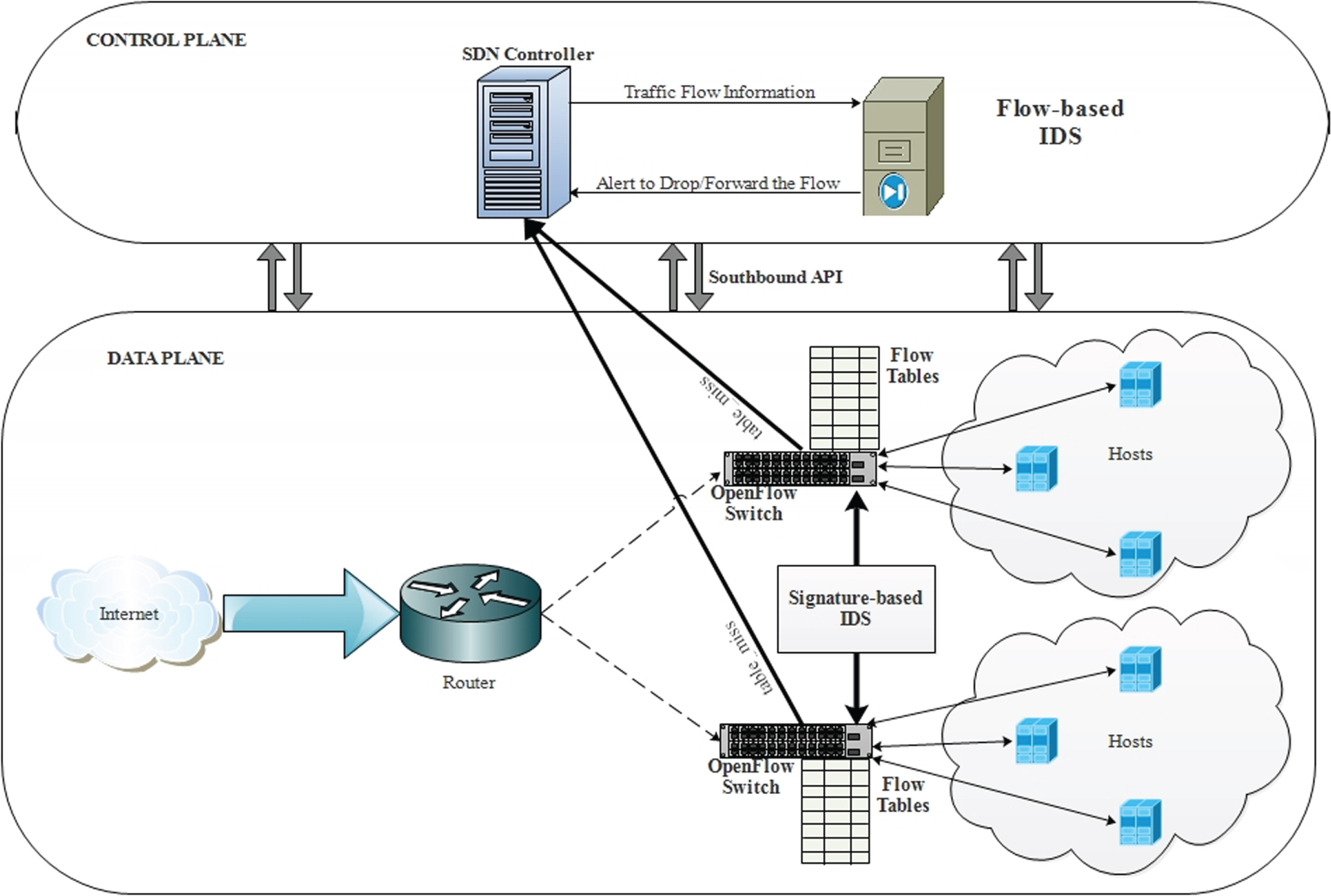
System diagram.
The flow-based IDS module uses the traffic information extracted from the controller and applies it over the machine learning-based classifier to detect malicious activity. When a table_miss occurs in the OpenFlow switch, it directs it to the controller for further action.
The proposed flow-based IDS module collects data on traffic statistics from the controller, and essential features from the data are identified, based on features selected by the trained IDS module for further processing. The data is forwarded to the trained machine learning-based classifier for inspecting and detecting attacks. If an attack is detected, the IDS module alerts the controller to drop the particular flow, else the SDN controller definesnew flow rules based on an abstract view of the network. Thus, this module helps detect real-time attacks by analyzing all the new flows received from the OpenFlow switches to the controller. The collection of flow statistics does not affect the performance of the controller as every new flow rule reaches the controller for further action. The working function of the flow-based IDS is depicted in Fig. 2.

Working function of the flow-based IDS.
To analyze and detect malicious activity in real-time traffic based on the flow information, we build a multi-layer machinelearning-based classifier module. By means of identifying important features in every flow, the module detects intrusions in traffic samples. The classifier uses the support vector machine in Layer-I, and the Naive Bayes and C4.5 decision tree in Layer-II. Based on the results of Layer-I, the naïve Bayes classifier inspects all normal instances classified by the Layer-I SVM. Similarly, the C4.5 decision tree classifier inspects all attack instances classified by the Layer-I SVM. This mechanism helps improve classification accuracy and reduce the false alarm rate. Since we identifyessential features using the ensemble feature selection mechanism, the processing and classification complexity are also low. A system diagram of the ensemble-based feature selection process and multi-layer machine learning-based classifier is depicted in Fig. 3.

A system diagram of the ensemble-based feature selection and multi-layer ML classifier.
Identifying the correct dataset plays a vital role in all classification models [9, 25]. Our aim is to select a dataset with data that is free of errors and redundancies. The KDD CUP’99 and NSL-KDD [5, 25] are commonly used datasets in the machine learning-based intrusion detection environment. The KDD CUP’99 dataset contains masses of data with redundant elements, which increases the computation cost and causes the machine learning algorithm to bias the results of the IDS module. Most researchers [11, 20] have only used 10 to 20% of the KDD CUP-’99 dataset for the training and testing phases. Detection results may change dramatically when a random set of data is chosen. To overcome this problem, the NSL-KDD dataset was filtered and developed from the KDD CUP-’99 with the removal of redundant and erroneous data, resulting in the entire dataset being used for training and testing. The NSL-KDD dataset contains a total of 41 features with attack and normal patterns. Attack patterns in the dataset are classified into four categories: denial-of-service (DoS), user-to-root (U2R), remote-to-local (R2L), and probe attacks. The testing dataset contains 22,554 network traffic samples and the training dataset 125,973. A DoS attack prevents a legitimate user from accessing the system’s resources by overloading it with unnecessary requests. In a U2R attack, a normal user in the network tries to gain access to a root user. In a R2L attack, an attacker tries to gain unauthorized access to a local user’s machine. In a probe attack, an attacker tries to retrieve sensitive information from a victim by scanning an unauthorized local user’s machine. Taking into consideration these advantages, we use the NSL-KDD dataset to test and train our proposed flow-based IDS module. The different types of attacksshowcased in the dataset are tabulated in Table 1.
A description of the NSL-KDD dataset
A description of the NSL-KDD dataset
It is necessary to preprocess and normalize data to make the machine learning-based classifier accurate and compatible. The values in the raw NSL-KDD dataset contain all forms (discrete, continuous and symbolic) of data, each with a different range of values. Therefore, preprocessing and normalization are essential for better accuracy. The preprocessing technique involves the normalization of data by mapping symbolic values to numerical values. Protocols like the ICMP (Internet Control Message Protocol), TCP (Transmission Control Protocol) and UDP (User Datagram Protocol) are mapped to the numeric values 1,2, and 3 respectively. In the NSL-KDD dataset, 39 types of attack patterns are presented under four types of attack categories, as shown in Table 1. The attack patterns are to be mapped under one of four attack classes: normal (0), probe (1), DoS (2), U2R (3), and R2L (4). Similarly, symbolic values for such items as a service (71) and flag (11) are mapped to numeric values, starting with 0 to N-1 values. Next, we scale the values into a linear range for both higher-end and lower-end values. Features like duration [0,58239], count, and srv_count [0–511] fall within a normal integer range, while others like src_bytes and dst-bytes find themselves in a larger integer range of billions. Normal integer values are scaled into 0.0 to 1.0, and long integer values are scaled into 0.0 to 9.14 by applying logarithmic scaling. Finally, all the features values are in the range either of the Boolean (0 or 1), or 0.0 to 1.0, or 0.0 to 9.14.
Feature selection process
The complete array of features in the dataset does not need to be used to elicit the best performance in the IDS. In the NSL-KDD dataset, the 41 available features are grouped into four: intrinsic (1–9), content-based (10–22), time-based (23–31) and host-based (32–41). Intrinsic features hold basic information on packets. Content-based features hold the payload and information on the original packets. Time-based features hold information on traffic, based on the time duration. Host-based features hold information on the number of connections to the same or different hosts in the network.
Identifying prominent features that are best suited to an SDN environment helps provide better accuracy and reduced training time. Selecting random features in the dataset degrades the performance of the IDS module [9, 10]. We select four filter-based feature mechanisms and one best-first feature mechanism to identify prominent features from the dataset, because the filter method works independently of the classification algorithm and is also less expensive than the wrapper method. The filter method is a statistical-based mechanism that uses the concept of feature ranking to identify the best features. It is also easy to use the filter method in a scenario with a huge quantum of data. In our proposed feature selection mechanism, we use an ensemble-based feature selection technique (EFS). The proposed mechanism identifies the best features by combining the output of information gain (IG), sequential feature selection (SFS), correlation feature selection (CFS), chi-square test and mutual information (MI). Each technique delivers a certain set of selected features as output, using which a subset of features is identified from the total of 41 features. From the identified subset of features, we select the best set of features by applying the threshold value (H = 3); that is, a particular feature selected by three or more feature selection techniques is identified as the best feature. We select the best set of features by applying this process repeatedly over all the subset of features. A flow diagram of the proposed ensemble-based feature selection mechanism is depicted in Fig. 4.
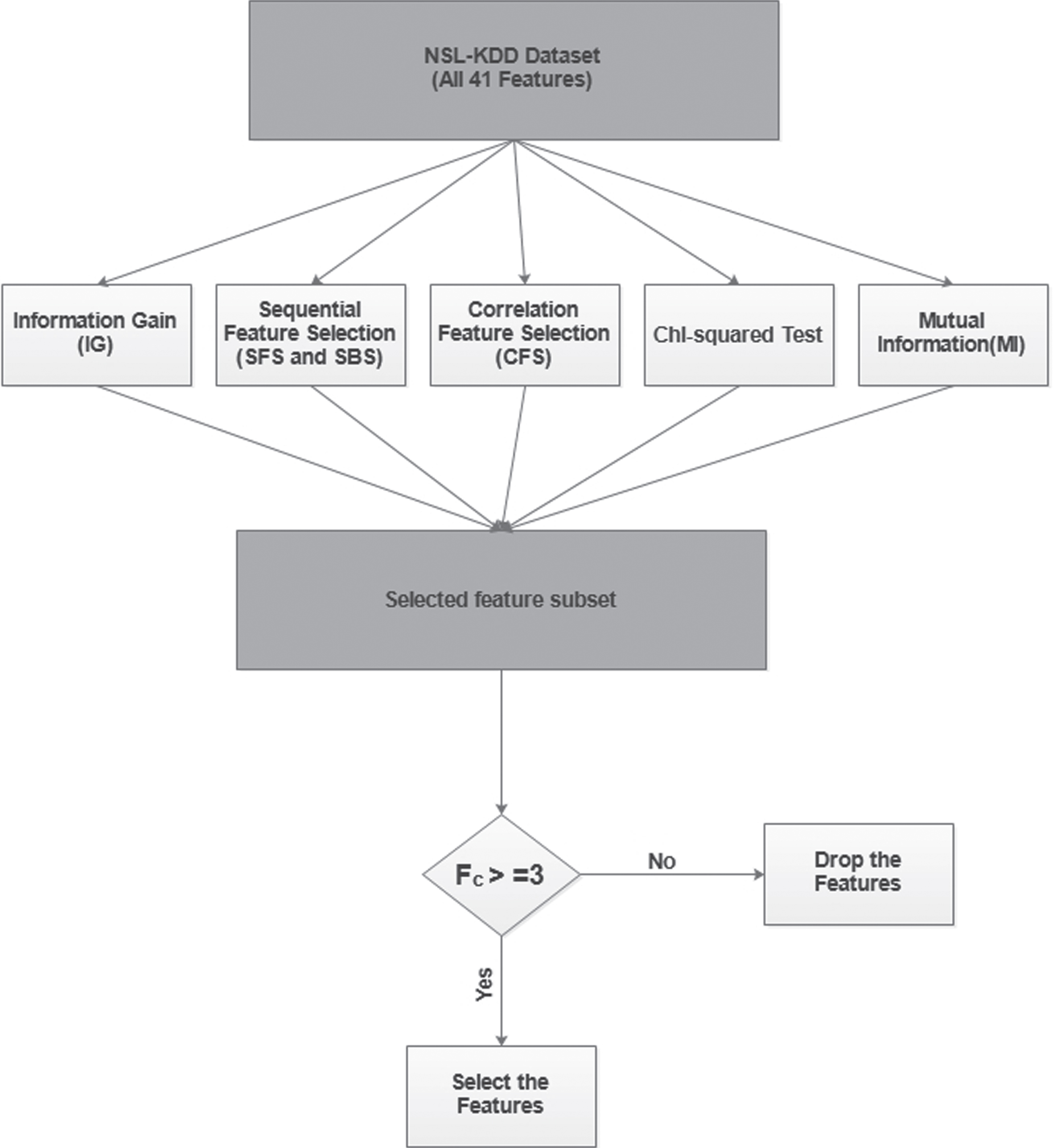
A flow diagram of the ensemble-based feature selection process.
3.2.3.1 Information gain
Information gain (IG) [26, 27] is an entropy-based feature selection technique built on the concept of the information theory and used to identify the key subset of features. If the removal of feature fi affects prediction power, it is said to be relevant; that is, fi contains relevant information about the dataset for prediction. This is done through ranking the subset of features in decreasing order by evaluating the information gain for each variable against the target class. The information gain for the feature is calculated as follows.
Let F represent a set of features (f1,f2,f3, ... ,fi) and G the target class(g1,g2,…,gi). The information gain of features, F, against class labels, G, is calculatedusing Equation (1):
We calculate E(F), the entropy of F and E(G|F),and the entropy of F after observing G through Equations (2) and (3),
Calculating the IG for each feature in the dataset, we rank the features in decreasing order. It is usual for features with a high IG value to possess the most relevant information for data classification.
3.2.3.2 Sequential feature selection
Sequential feature selection [28] is part of greedy search algorithms, and helps select the K set of sub-features from the D set of the original feature set, K < D. The sequential selection method uses the step-optimal method to select a prominent set of features by adding a good feature or removing a bad feature at each step. We select a subset of features using both sequential forward selection (SFS) and sequential backward selection (SBS).
The sequential forward selection (SFS) technique starts with an empty feature set ø and adds an optimal feature with a higher criterion value at each step. Let input F be the whole set of features {f1,f2,f3, ... ,f i } in the dataset and output S the selected subset of features. Also, let the number of features selected in S be k, where k is the predefined value such that k < i. Here, we add a feature, s+, into the feature subset, Sk, in case s+ represents the feature that enhances the criterion function. It is added to S k if associated with the best classifier performance.
Similarly, the sequential backward selection technique starts with a complete feature set, {f1,f2,f3, ... ,f i }, and selects a set of optimal features by removing features with a low criterion value at each step. Let input F be the whole set of features in the dataset and output S the selected subset of features, where the number of features selected in S is the predefined value, k < i. Here, we remove a feature, s-, from our feature subset, Sk, whenever s- represents the feature that reduces the criterion function. It is removed from S k if associated with the best classifier performance. The algorithm for the SFS and SBS is as follows:
Input: F = {f1,f2,f3, ... ,f i } p = 6
Output: S = {s j | j = 1,2 ... k;s j inF} k = {0,1,2 ... i}
Step 1: F0 =ø, k = 0
Step 2: f+ = arg max J(f k +f), where f ∈ S –F k
Sk +1 = S k +f+
k = k+1
Step 3: Repeat step 2 until(k = = p)
Input: F = {f1,f2,f3, ... ,f i }
Output: S = { j | j = 1,2 ... k; s j ∈F} k = {0,1,2 ... i}
Step 1: F0 = S, k = i
Step 2: f- = arg max J (f k –f), where f ∈F k
Sk - 1 = S k –f-
k = k-1
Step 3: Repeat step 2 until(k = = p)
3.2.3.3 Correlation-based feature selection (CFS)
CFS [20, 29] is a simple filter-based feature selection technique that selects a subset of features by calculating the correlation between each feature and the target class. Features with high correlation value areselected to constitute a prominent subset of features. The correlation function for the optimal subset of featuresiscalculated using Equation (4),
3.2.3.4. Chi-square test
The chi-square test [30] selects the best feature by calculating the chi-square score between every feature in the dataset against the target class. The method calculates the score by testing the independence between the feature and the target class. A feature with the best score indicates a higher dependency between the selected feature and the target class. The chi-square score is computed using Equation (5),
3.2.3.5. Mutual information (MI)
In information theory, mutual information evaluates the dependency between two variables [26, 31]. The mutual information between two variables, A and B, is the amount of information on B supplied by A or vice versa. If A and B are dependent, the mutual information between the two variables is 1, and 0 if they are not. We select features from the entire dataset by ranking the MI value against the target class.
The mutual information between the target class and a feature is calculated using Equation (6), where C represents the target class, F the feature, E(C) the entropy of the target class and E(C|F) the conditional entropy.
This function computes how much information is shared between a particular feature and the target class. Features with a high MI value are considered to comprise a prominent set of features.
3.2.3.6 Ensemble feature selection process
Using five different feature selection mechanisms, we identify five different best sets of features from the entire feature set. The final best set of features is selected by a simple ranking mechanism using a predefined threshold value, (H = 3). Once the best sets of selected features are combined, a counter (Fc) is used to count the number of times a particular feature is selected. If a particular feature is chosen by three or more techniques, it is taken into the final best set of features (BS F ). Our proposed ensemble feature selection algorithm is given in 3.2.3.7,
3.2.3.7 Ensemble feature selection algorithm (EFS)
S Best =φ ∖∖ Set of the best features
Best (IG) , Best (SFS) , Best (CFS) , Best (MI) , Best (CHI) =φ
H = 3
Compute Best (IG) , Best (SFS) , Best (CFS) , Best (MI) , Best (CHI)
S Best ←
Best (IG) +Best (SFS) +Best (CFS) +Best (MI)
+Best (CHI)
Compute C F
If C F > = 3
BS F ← f i
where Best (IG) , Best (SFS) , Best (CFS) , Best (MI) , and Best (CHI) represent the best features selected by information gain, sequential feature selection, correlation feature selection, mutual information and the chi-square test respectively, BS F the final best set of selected features, and C F the counter of each feature.
In the NSL-KDD dataset, there are 41 features. By applying five different feature selection mechanisms, we choose five different sets of the best features. The selected features and the search methods are presented in Table 2. After combining all the selected features, the final best set of features, BS F , is selected using the counter function (C F ) based on the threshold value (H = 3). The number of times a particular feature is selected by different techniques is tabulated in Tables 3 and 4. Table 5 features a description of the selected feature set (BS F ).
Different sets of selected features using the feature selection technique
Features and their counter value
The final best selected features (BS F )
Selected feature number, name and description
By applying a feature selection process, we reduce the dimensionality of the feature set from 41 features to 11 essential features. We now train the machine learning-based classifier by applying the best set of features foran enhanced performance. In this section, we discuss our proposed machine learning-based classifier mechanism.
3.2.4.1 Support vector machine (SVM) classifier
The SVM [32, 33] is a supervised machine learning model, primarily used for classification and regression problems. This technique maps the training instances into an n-dimensional feature space and functions by calculating the optimal hyperplane between normal and attack instances in order to classify future instances. Every data point in the SVM is considered a vector in the n-dimensional feature space. Consider that all the data points in the n-dimensional space belong either to class X or class Y. Each training point, ai, is labelled by bi, based on Equation (7).
The training instances can be represented as in Equation (8).
Data instances with label 1 and –1 are referred to as positive and negative points, that is, normal and attack classes. Hyperplanes help separate normal and attack instances. The aim of this algorithm is to choose an optimal hyperplanethat separates attack and normal classes with a high margin. The highest margin of the hyperplane is defined by thesum of the distance from the hyperplane to the closest attack and normal points.
The new data point, x, isclassified using Equation (9),
Where α i is the Lagrangian multiplier of each data point.
The importance of each data point is reflected by αi,and support vectors are identified by the data points closest to the hyperplane (α> 0). For the remaining data points, α = 0. The data points that lie closest to the hyperplane represent the classifier and act as support vectors. Figure 5 represents the SVM with two classes of data points, attack (–1) and normal (+1), with two boundaries or margins. Support vectors (α> 0) are represented by rounded values (1, –1) and non-support vectors (α = 0) by non-rounded values (1, –1). Changes in support vectors affect the margin; that is, adding or removing non-support vectors does not.
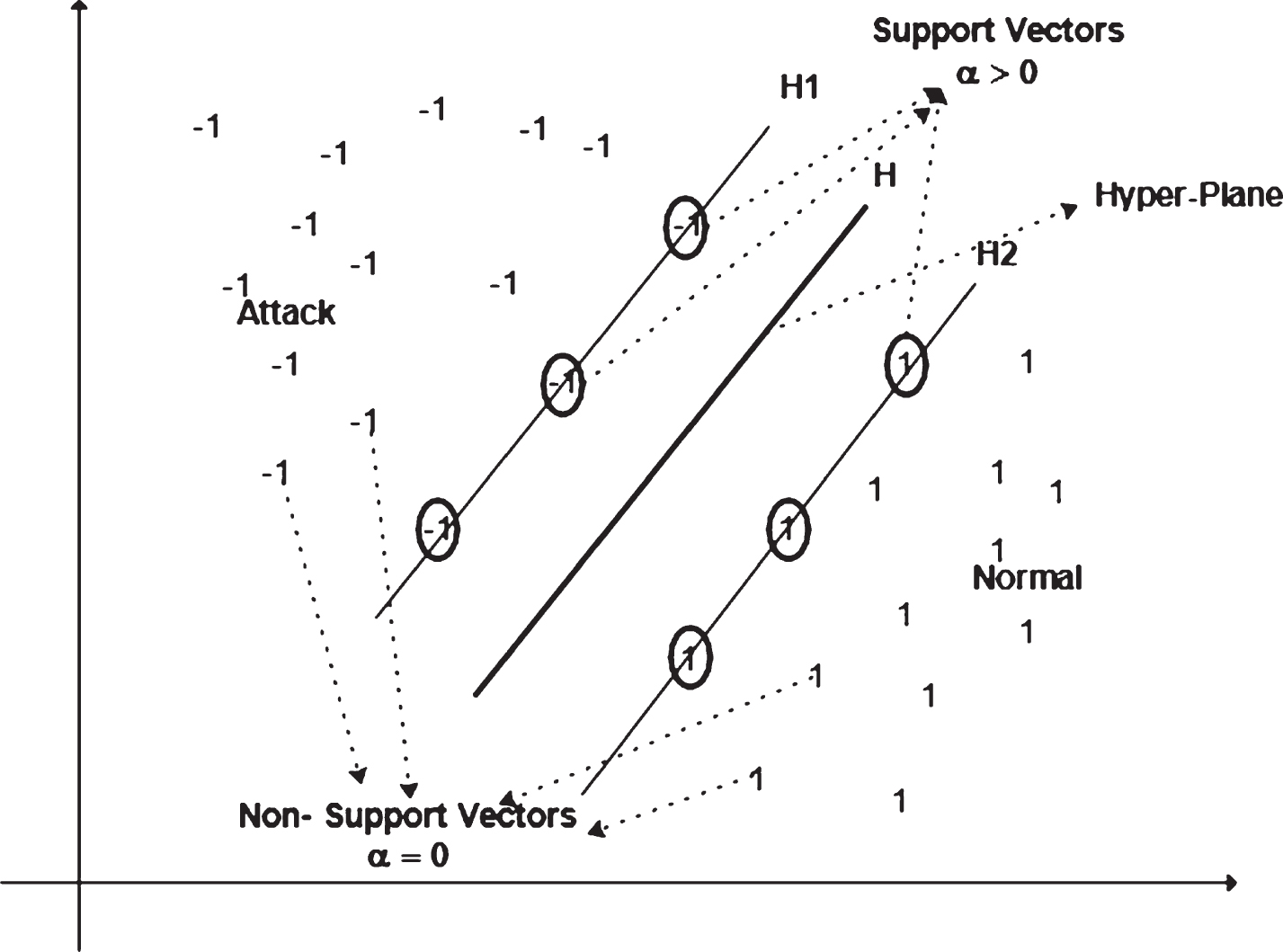
SVM support vectors, non-support vectors and classes.
To compute the optimal hyperplane, H, consider both the closest positive and negative training points as support vectors H1 and H2, respectively, written as Equations (10) and (11),
3.2.4.2 Naïve Bayes classifier
A Naïve Bayes classifier is another commonly used classification technique based on theconcept of Bayes’ theorem [34, 35]. It is a probabilistic model which predicts the class membership probabilities by assuming independence between the predictors. This model works with a large dataset and is also easy to build.
Let TRD = {tr1,tr2,tr3, ... ,tr n }, where tri represents data samples in the training dataset(TRD). Each data sample has values for the M features. Using our proposed feature selection mechanism, we select m, that is, 11 essential features, M = {f1,f2,f3}, ... ,f m }. The training dataset contains two class labels, attack and normal, represented as C = {c1,c2 ... ,c k }. Let TED = {te1,te2,te3, ... ,te n }, where tei represents the data samples in the testing dataset (TED). The trained Naive Bayes classifies te i to belong to l1 or l2 by computing the highest posterior probability.
The Naive Bayes function is computed by Equations (12) and (13),
3.2.4.3 The C4.5 decision tree
In Layer-II, the C4.5 is used to inspect and classify the attack data classified by the Layer-I SVM. In our previous work [35, 36], the C4.5 technique was analyzed and used to detect intrusions in the SDN environment. Based on the results, we have established that the C4.5 works well in terms of both classification accuracy and false alarm rate. The C4.5 classifier inspects attack instances from the SVM and classifies the nature of the attack, categorizing each as a probe, DoS, U2R or R2L.
Ross Quinlan introduced the C4.5 technique, based on the concept of the decision tree. The decision tree [37] is a classification approach that classifies the given input data instances based on the feature values. The task is to select the best feature that correctly partitions the data instances into target classes. The C4.5 uses the information gain ratio as a splitting factor. Information gain is calculated using entropy, which is a measure of the randomness or impurity of data instances. Features with high entropy are selected as the best feature to split the data instances. Information gain for a feature is calculated using Equations 1, 2, and 3. The C4.5 constructs a decision tree by taking the training input data, selecting the best feature as the partition factor, and recursively applying the same to each sub-tree. The leaf nodes of the C4.5 tree represent the target classes. The training data starts at the root node and follows the sub-tree, based on the results of each test, until it reaches a leaf node. The target label of the leaf node is the result of the classification.
Given that the essential features detecting the attack pattern in the feature selection mechanism have been identified already, the computation power of each node is very low, which reduces the process and time complexity. This module helps avert falsely detected attack instances in the Layer-I SVM. The proposed algorithm for the flow-based IDS is given in 3.2.4.5,
3.2.4.5 Multi-layer machine learning classifier algorithm
Extract essential features (fi)
FS ← f i
Forward it to the L1 SVM
Process and classify t i into C attack or C normal
Forward it to the L2C45
Process and classify t i into C attack or C normal
If t i = = C attack
Alert the controller to drop the flow
Else
Flow rules will be developed
Forward it to the L2 NB
Process and classify t i into C attack or C normal
Flow rules will be developed
Alert the controller to drop the flow
where T = {t1,t2, ... tn} represents traffic instances, C = {Cattack, Cnormal} the target class labels, FS the features {f1,f2, ... ,fi}, L1SVM the Layer-I SVM classifier, L2NB the Layer-II Naïve Bayes classifier, and L2C45 the Layer-II C4.5 classifier.
Once an OpenFlow switch receives incoming packets, the switch table lookup process starts. If no match occurs in the table, the switch redirects the request to the controller for new flow rules. If a match is readily available, the switch has a flow rule for the received packet. New packets received in the controller are inspected by the flow-based IDS using the ML-based classifiers. However, for flows defined earlier, there is no mechanism in place to monitor suspicious activity in the data plane. To address this problem, we introduce the signature-based Snort IDS in the data plane. The Snort IDS [24] is a lightweight and open-source IDS that detects abnormal activity by employing rule sets. In traditional networks, Snort is the mechanism commonly used to inspect and detect abnormal activity in the network [38]. OpenFlow switches mirror all the received traffic towards the signature-based IDS module. By applying rule sets, the IDS module monitors network traffic and checks formalicious activity. In the event of an attack, the signature-based IDS module alerts the controller to drop the particular flow.
To mirror the network traffic received in all switches towards the IDS module, our proposed work uses the concept of port mirroring, which duplicates every packet of the switch (in/out) and sends it to the IDS module. Once intrusion occurs, rule sets in the IDS module determine the action to be carried out. Every rule contains two fields, a header and an option. The rule header defines the source, destination IP addresses, port numbers, netmask, and protocol affected by the rule. The rule option defines which part of an IP packet is to be inspected for compliance with a specific rule. This is notified to the controller so that a particular flow can be dropped, following which the controller removes the particular flow from the flow table of the corresponding switch. The working function of the signature-based IDS module is depicted in Fig. 6.
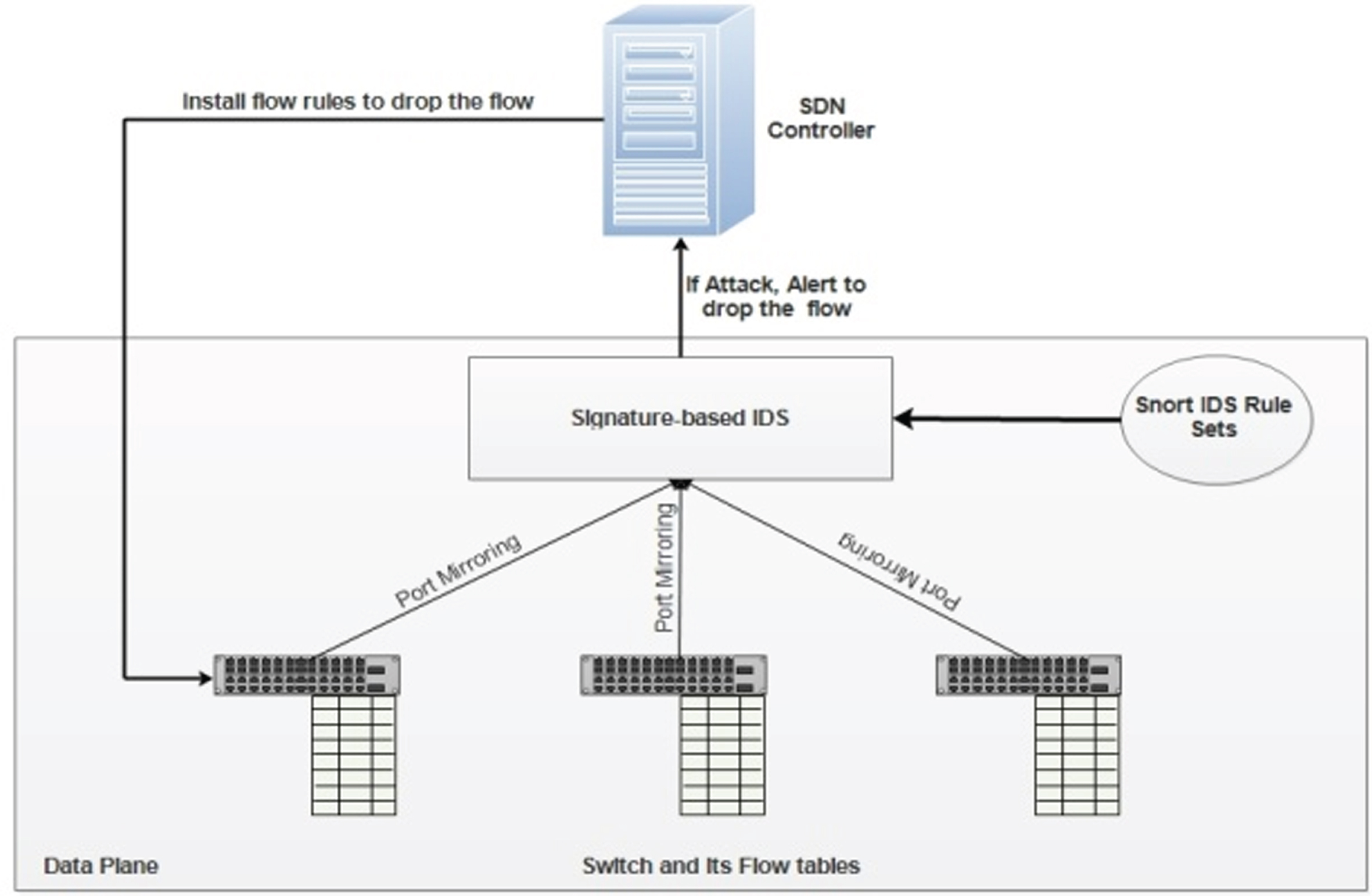
Working function of the signature-based IDS in the data plane.
The performance of our proposed work is evaluated in terms of classification accuracy, false alarm rate (FAR), precision, recall and F-score. To compute these values, metrics such as true positive (TP), true negative (TN), false positive (FP) and false negative (FN) from the confusion matrix are considered. True positive is the measure of the total number of normal instances classified as normal. True negative is the measure of the total number of attack instances classified as attacks. False positive is the measure of the total number of attack instances classified as normal. False negative is the measure of the total number of normal instances classified as attacks.
Accuracy,as given in Equation (14), is the measure of correctly classified attacks and normal instances in the given dataset.
Precision, as expressed in Equation (15), is the measure of correctly classified normal instances by all the classified normal instances.
Recall is the measure of correctly classified normal instances by all the instances available for a particular class. It is calculated using Equation (16).
In case of an uneven class distribution, the F-score is used to identify the balance between precision and recall. As seen in Equation (17), it is the weighted average of precision and recall.
Our proposed multi-layer machine learning-based classifier is trained and tested with the NSL-KDD test and training dataset. The details of the dataset are described in Section 3.2.1. To evaluate the efficiency of the proposed two-layer technique, we have compared our proposed multi-layer classifier with single classifiers like the SVM, Naive Bayes and C4.5 decision tree. To underscore the importance of the feature selection process, we have compared our ensemble feature selection with a full 41-feature dataset.
From Tables 6–9, it is clear that the identification of essential features in the dataset helps enhance classification accuracy and reduce the time taken to train and test the model.
A performance comparison of the ensemble feature selection technique over the training dataset
A performance comparison of the ensemble feature selection technique over the training dataset
A performance comparison of the ensemble feature selection technique over the testing dataset
A performance comparison based on the time taken to build the model
A performance measure of the Layer-I and Layer-II ML classifiers
To improve the results significantly, we have proposed a multi-layer ML classifier mechanismthat helps achieve high classification accuracy by evaluating the data in two different layers. In Layer-I, the SVM classifier classifies the data instances into two, attack or normal. A normal instance is forwarded to the Layer-II Naïve Bayes classifier and an attack instance to the Layer-II C4.5 classifier for further inspection. The proposed multi-layer processing approach achieves thehighest classification accuracy of 98.2%. The performance of themulti-layer classifier over a single classifier is depicted in Table 10. Figure 7 represents the confusion matrix for the Layer-I and Layer-II classifiers. Figure 7 indicates that the Layer-II classifier helps reduce the false alarm rate by processing packets separately in parallel.
A performance measure of the multi-layer ML classifier over the training and testing datasets

Confusion matrix for the Layer-I and Layer-II classifiers (NSL-KDD dataset).
Our experimental results show that the proposed multi-layer ML-classifier mechanism has achieved better classification accuracy and a lower false alarm rate than the single ML-classifier. Ensemble feature selection has played a pivotal role in our proposed work as well by reducing the time complexity through identifying essential features in the initial stage. The time taken to build the proposed model is also reasonable, given that the Layer-II classifiers process the data parallelly for the final classification of data instances as attacks or normal. The trained multi-layer ML-classifier now processes the real-time flow-based information to detect malicious activity.
We have used the Mininet simulation tool [39] to execute our proposed SDN flow-based IDS and signature-based IDS. It is a standard simulation tool which creates an SDN-based environment using virtual OpenFlow switches, links, controllers and hosts. To control and monitor our network, we have used the Python-based controller POX [1, 3]. The OpenFlow switches in the data plane and the POX controller in the control plane communicate through the OpenFlow protocol version 3.0. To monitor network activity in the data plane, we have used the Snort version 2.0.6 [40] as the signature-based IDS in the data plane. It continuously monitors traffic between all the OpenFlow switches and alerts the controller in case of any suspicious activity. In the control plane, the flow statistics of the new incoming flows are directed to the flow-based IDS module from the POX controller. Using the flow statistics, the trained ensemble feature selection-based multi-layer machine learning classifier analyses the data instances and reports to the controller in the event of intrusions or malicious activity. The working function of both the flow-based and signature-based IDS is more precisely explained in Section 3.2, 3.3.
We have created a network topology with three OpenFlow switches (S1, S2, S3), 12 hosts (H1 –H12), and one POX controller (C1), as depicted in Fig. 8.
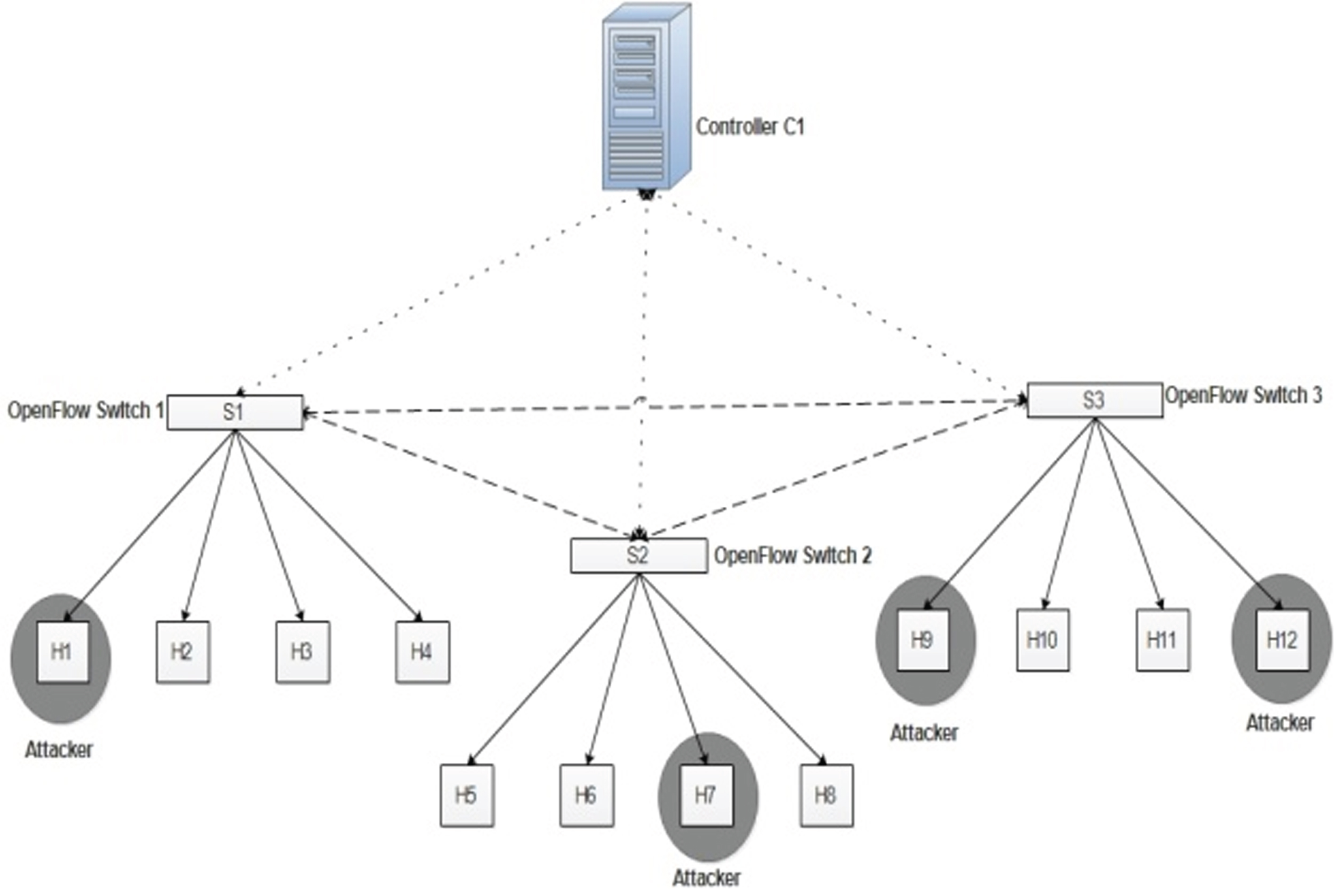
Network topology of the proposed system.
We have generated both attack and normal traffic towards the hosts using Scapy [41], a Python-based packet manipulation tool that helps generate, sniff and modify network packets. It is superior to other packet manipulation tools like the hping3, arping, Nmap, and arpspoof [42]. Given that Scapy sends packets, matches requests and replies, modifies packets, and transmits invalid frames, it is easy to generate different kinds of attacks, along with normal packets. By applying port mirroring, we collect the traffic information transmitted between the three switches. We have usedWireshark to monitor traffic information in the data plane and control plane [43]. Attacks generated using Scapy include flooding attacks like ARP cache poisoning, port scanning, port sweeping, SYN flood, UDP flood and ICMP flood, as well as spoofing attacks like the ARP and DNS. These attacks focus on the forwarding devices in the data plane and the controller in the control plane. For example, flooding attacksstop the victim system from processing legitimate requests by flooding the system with a large number of packets from spoofed IP addresses; spoofing attacks gain access to the local user using spoofed addresses in the network and target the controller with unnecessary flow requests; scanning attacks locate active ports in the network and identify service vulnerability by tracking the victim system. ARP cache poisoning preventsa legitimate user from joining a gateway by poisoning the ARP cache. ICMP flood attacks send an enormous number of echo requests with the victim’s IP address, which results in every host respondingto the said requests. Similarly, we have generated a total of 45,089 attack packets and 72,451 normal packets using Scapy. Table 11 represents the different kinds of packets generated by Scapy. Table 12 shows the performance evaluation of our proposed work in two layers. In Layer-I, the classification accuracy is 94.8%. By splitting attacks and normal into different classifiers (Naïve Bayes and C4.5) in Layer-II, classification accuracy is enhanced to 97.7%. The false alarm rate for the proposed work is comparatively low. In all, 2250 instances (1.91%) in Layer-I and 465 instances (0.39%) in Layer-II are falsely classified as attack instances. Our experimental results clearly show that identifying essential features and processing the data using multiple classifiers improves classification accuracy. Figure 9 depicts the confusion matrix for the Layer-I and Layer-II classifiers using Scapy-generated data instances. It indicates that the false alarm rate is reduced in Layer-II, compared to Layer-I.
Different attack and normal instances generated by Scapy for the flow-based IDS
A performance measure of the proposed model over the Scapy-generated dataset

Confusion matrix for the Layer-I and Layer-II classifiers (Scapy-generated traffic).
To evaluate the performance of the signature-based IDS, we have generated 22,248 attack packets and 27,452 normal packets from eight host systems randomly towards the four victim systems, either on the same switch or a different one. The packets are reflected in the signature-based IDS module by applying the port mirroring technique. Snort IDS rules evaluate the nature of the packet, based on the pre-defined rules set, and alert the controller in case of suspicious activity. The attack instances generated are in the form of UDP, SYN, ICMP and HTTP flood attacks. This is because, by attacking or spoofing host systems,,attackers gain access as local users and try to control the controller by despatching unnecessary flow requests. Our experimental results show that thesignature-based IDS using Snort achieves overall accuracy of 95.26%. Misclassified instances are moderately high in ICMP (5.77%) and UDP flood (6.26%) attacks, and relatively low in TCP SYN (3.29%) and HTTP flood (3.66%) attacks. UDP and ICMP flood attacks are mainly defended using predefined threshold values in Snort rules. This may, however, occasionally cause legitimate traffic to be detected as attack instances.
Table 13 presents the different types of attacks generated by Scapy for the signature-based IDS module. Table 14 represents accuracy for different kinds of flooding attacks, using the signature-based IDS.
Different attacks and normal instances generated by Scapy for the signature-based IDS
A performance analysis of the signature-based IDS
A performance comparison of the proposed work
We have compared our proposed work with related work proposed for both the SDN and traditional networks, and analysed the results in the form of the type of classifier, feature selection mechanism, classifier algorithm, and type of dataset used, which are tabulated in Table 14. Most researchers have used the KDD-CUP’99 and NSL-KDD datasets. The performance of the classifier depends greatly on the identification of essential features, for the random selection of features results in poor classification accuracy [44]. Hybrid and multi-layer classifiers work well compared to single classifiers [36, 45–49]. In [36, 48], the focus was only on DDoS attacks, using a generated dataset and the hping3. The comparison makes it clear that identifying essential features and using multiple classifiers help achieve the best accuracy. Using a multi-layer classifier and an ensemble feature selection technique, we have achieved 97.7% accuracy. Additionally, we have proposed the signature-based IDS using Snort to monitor and detect suspicious activity in the data plane.
Conclusion and future work
In this work, we have proposed a flow-based IDS in the control plane and a signature-based IDS in the data plane to analyse and detect malicious activity. The IDs helps secure both the control plane and data plane effectively in an SDN environment. This impacts the performance overhead of the controller by monitoring the traffic in the control plane and data plane separately. In the flow-based IDS, we used ensemble-based feature selection and a multi-layer machine learning classifier to analyze and classify attack and normal instances. The NSL-KDD dataset was used to train our proposed multi-layer ML-based classifier. The signature-based IDS used the rule-based Snort IDS to inspect and classify attack and normal instances. To evaluate the performance of our proposed work, attack and normal instances were generated using Scapy. The findings of the proposed work show that identifying essential features and using multiple classifiers improves processing time and classification accuracy, with a low false alarm rate. Our experimental results show that the proposed work outperformed existing approaches with 97.7% and 95.26% accuracy in the flow-based IDS and signature-based IDS, respectively. Insider attackers with access to confidential information on network resources degrade SDN performance by sending undesirable connection requests to the controller or other legitimate devices in the network. Consequently, it is necessary to detect insider attackers in the data plane as early as possible. In future, we plan to implement a host-based IDS in the SDN data plane for the early detection of insider attacks using machine learning techniques.